
A Hypered Deep-Learning-Based Model of Hyperspectral Images Generation and Classification for Imbalanced Data

Abstract
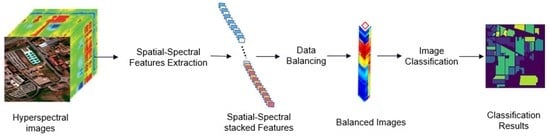
:
1. Introduction
- Existing hyperspectral image datasets have an imbalanced-class issue. There are classes with insufficient samples for training, which makes the classification models biased toward the majority classes and influences the classification accuracy and results.
- Hyperspectral images have high dimensionality. Therefore, feature extraction is another challenging issue. How can we develop a strategy to capture the spatial features and spectral features effectively? Once spatial–spectral features are extracted well, the classification accuracy can be improved, and significant details about the structure of the locations can be obtained.
- During HSI classification, which deals with a huge number of images and their features, traditional models usually adopt a 3D conventional network to perform image classification. However, the 3D conventional-based classifier is a time-consuming method. There is a need to adopt a classifier that can efficiently perform classification tasks with less required time consumption.
- Proposing an innovative 1D_2D convolutional-based method for obtaining the spatial and spectral features from hyperspectral images. A 1D CNN network is adopted to extract the spectral features, whereas a 2D convolutional network is used to capture the spatial features. Finally, the two features are concatenated and stacked into one feature vector.
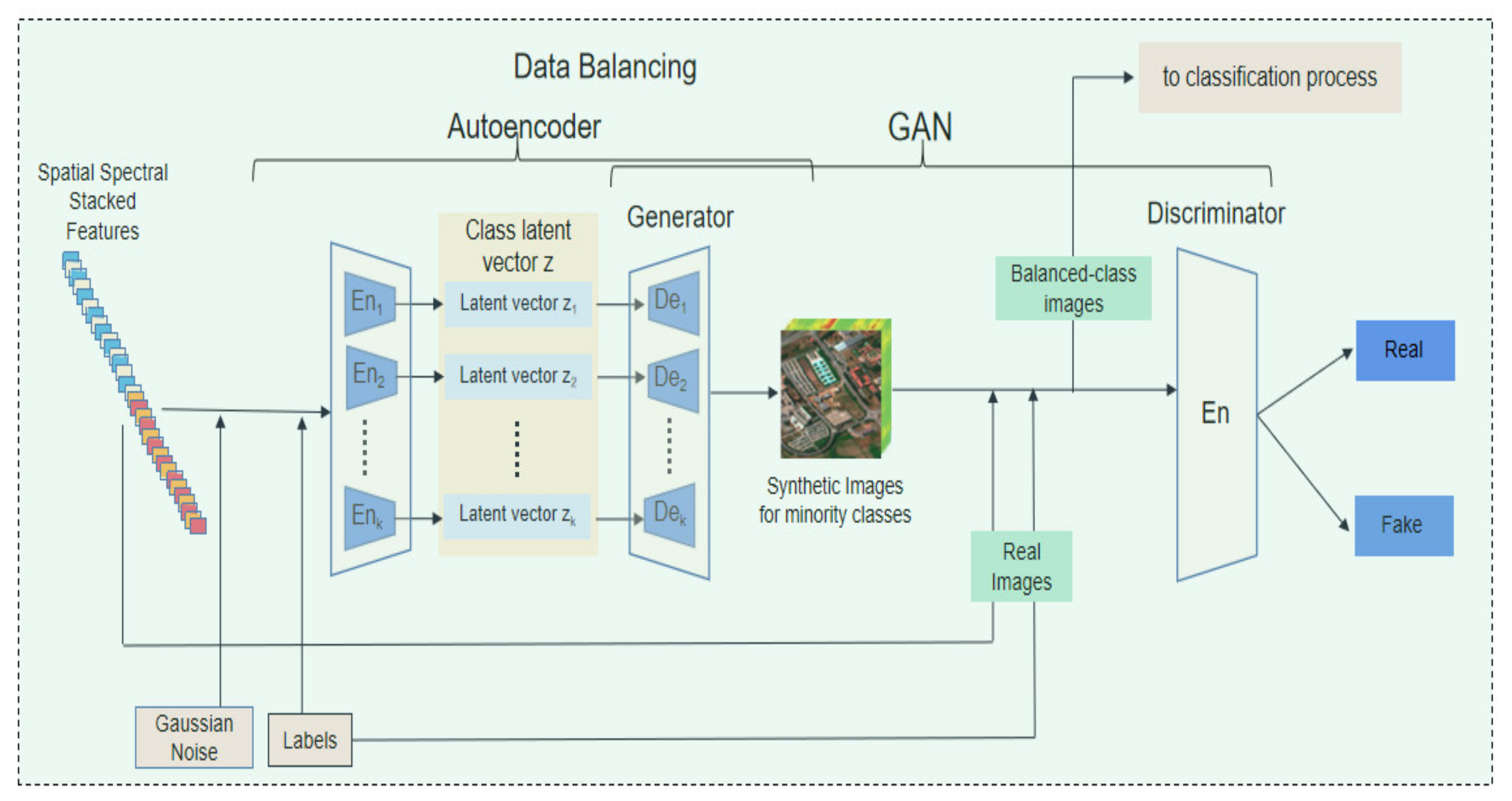
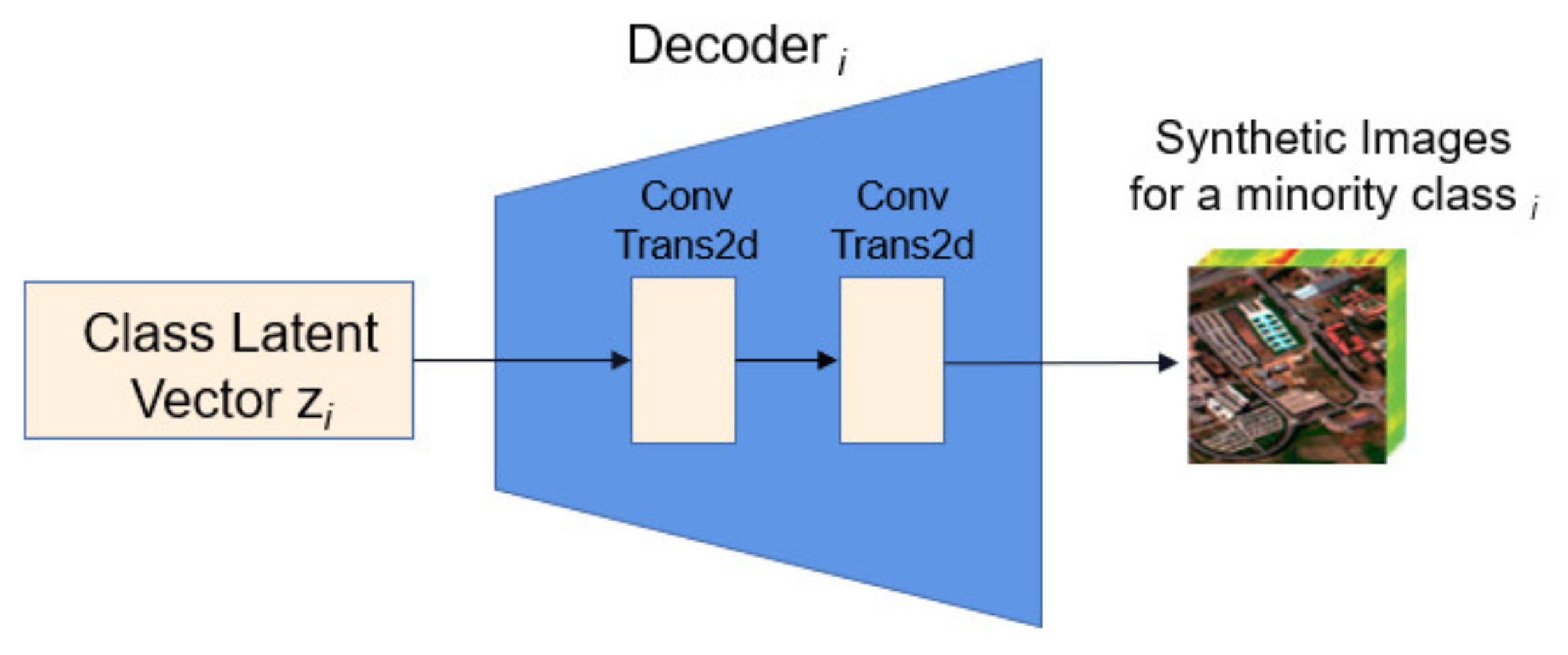
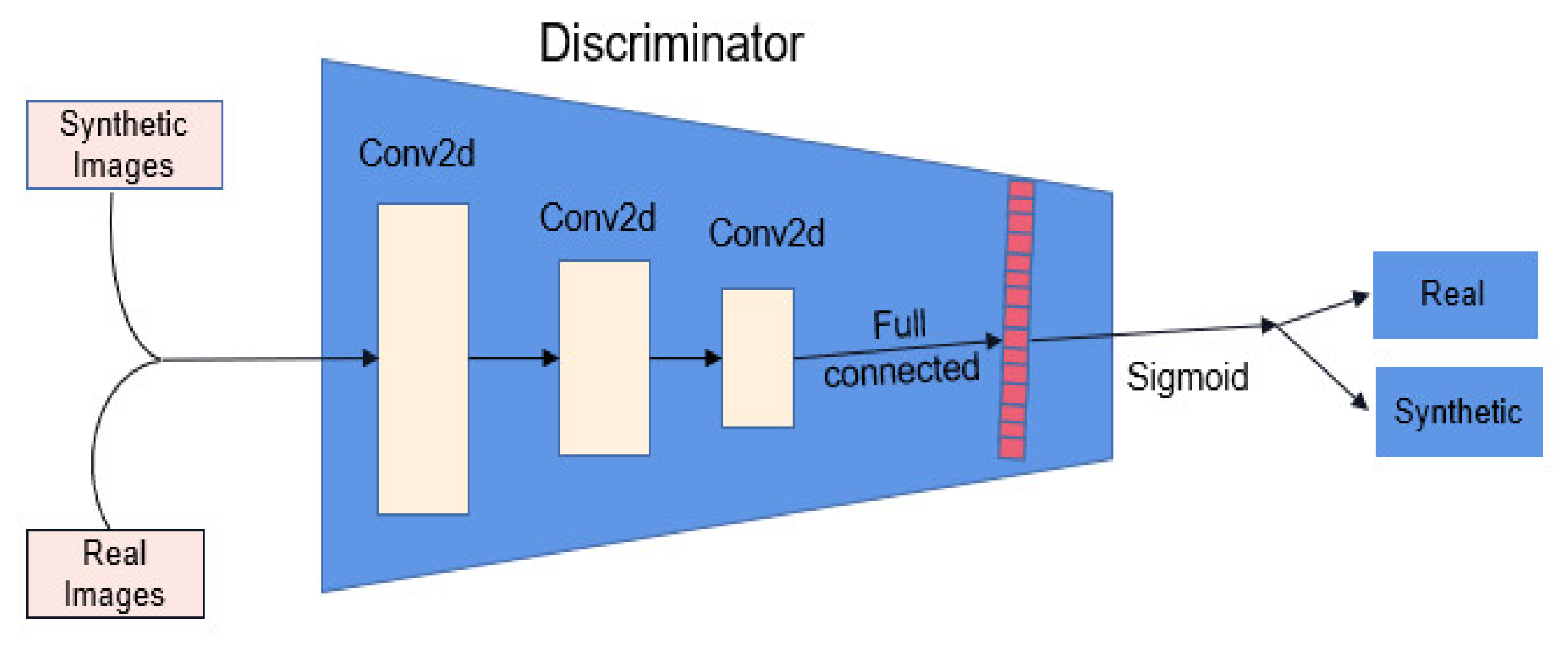
- The autoencoder GAN-based model is proposed to solve the class imbalance issue, and synthetic images are generated to rebalance the minority classes and the datasets. Compared to the sample number in the majority class, an encoder cell would be determined and developed to produce samples for each minority class equal to the sample number in the majority class. The GAN model would be used to recognize the real samples and synthetic samples to enhance the results of the loss function, and improve the training convergence.
- We introduce a simpler and more efficient way of HSI classification. A 2D CNN-based classifier is adopted for classifying hyperspectral images. The 2D convolutional network costs less time consumption and takes less space for the training process. The balanced images, including the synthetic and the real images, are fed into the proposed classifier for performing the image classification task.
- Our model is validated using four hyperspectral datasets, including Salinas, Indian Pines, Botswana, and Kennedy Space Center. Our model is validated and compared with several state-of-the-art classifiers. Statistical significance is also estimated to examine classification performance obtained by the proposed model.
2. Related Work
2.1. Feature Extraction Methods
2.2. Hyperspectral Image Classification on Imbalanced Data
3. The Proposed Model
3.1. Feature Extraction
3.2. Data Balancing
3.2.1. Autoencoder Network
3.2.2. Generative Adversarial Networks (GAN) Network
3.3. Classification Module
4. Experiment
4.1. Datasets
- The Indian Pines dataset is collected using the AVIRIS sensor in the Indian Pines area, Indiana. The dataset includes 224 bands with range wavelength of 0.4–2.5 × 10 −6 m. Image size is 145 × 145 pixels [43]. More details of the classes and samples of Indian Pines are listed Table 3 and displayed om Figure 8.
- The Salinas dataset is collected using AVIRIS sensor in the Salinas area, California. The Salinas dataset includes 204 bands, and the image size is 512 × 217 pixels [43]. Table 4 introduces more details about the land cover classes along with samples in the Salinas dataset, whereas Figure 9 shows the ground truth map and pseudo color image by Salinas dataset.
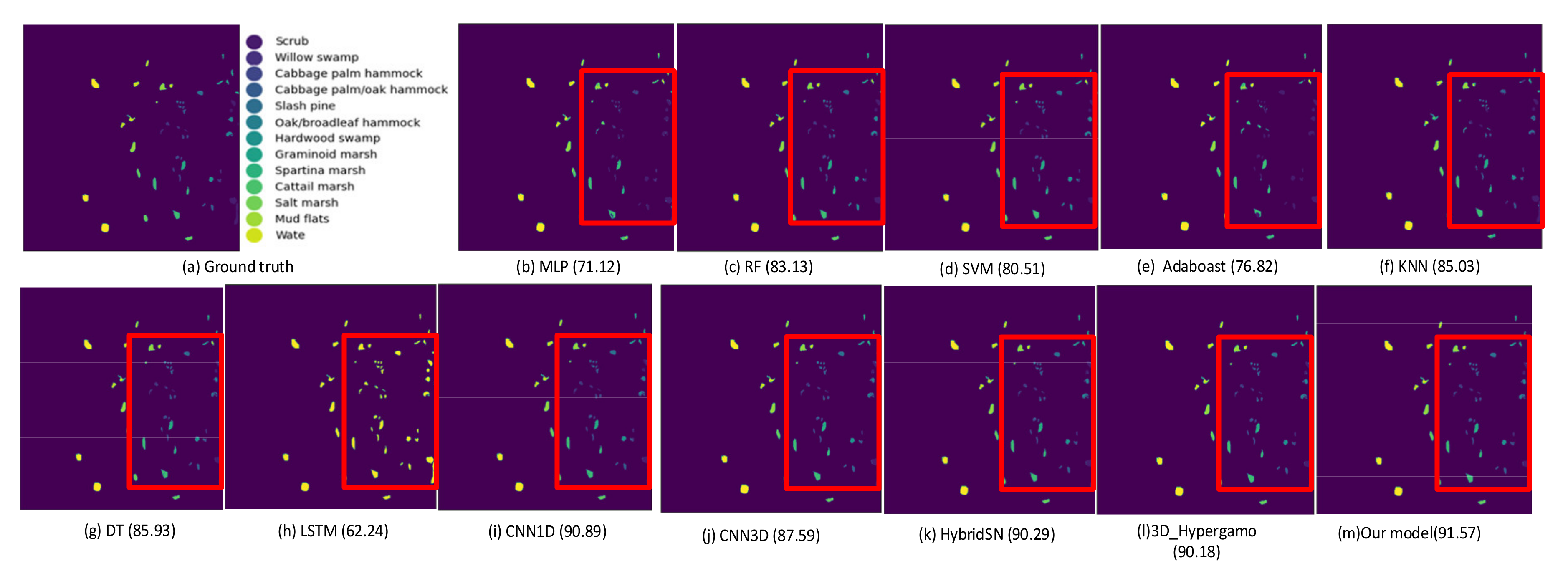
- The Kennedy Space Center dataset is gathered using NASA AVIRIS at the Kennedy Space Center area in Florida. The KSC dataset contains 224 spectral reflectance bands, and image size is 512 × 614 pixels [43]. Table 5 listed the classes and the samples’ information of the KSC dataset, whereas the corresponding ground truth map and pseudo color image are depicted in Figure 10.
- By NASA EO-1 satellite, the Botswana dataset is gathered across the Okavango delta site. The dataset includes 242 spectral reflectance bands, and the image size is 1496 × 256 pixels. Table 6 details the classes and the samples in the Botswana dataset. Figure 11 illustrates the ground truth map along with a pseudo color image for the Botswana dataset.
4.2. Experiment Settings
4.3. Training Settings
4.4. Comparation Models and Evaluation Metrics
5. Experimental Results
5.1. Classification Results with Compared Models
5.2. Training and Complexity Time with the Compared Models
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, M.; Li, W.; Du, Q. Diverse Region-Based CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef] [PubMed]
- Ghamisi, P.; Plaza, J.; Chen, Y.; Li, J.; Plaza, A.J. Advanced Spectral Classifiers for Hyperspectral Images: A review. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–32. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Du, Q.; Li, Y.; Li, W. Hyperspectral Image Classification with Imbalanced Data Based on Orthogonal Complement Subspace Projection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3838–3851. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Wambugu, N.; Chen, Y.; Xiao, Z.; Tan, K.; Wei, M.; Liu, X.; Li, J. Hyperspectral image classification on insufficient-sample and feature learning using deep neural networks: A review. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102603. [Google Scholar] [CrossRef]
- Gao, H.; Chen, Z.; Xu, F. Adaptive spectral-spatial feature fusion network for hyperspectral image classification using limited training samples. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102687. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Beyond the Patchwise Classification: Spectral-Spatial Fully Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Big Data 2019, 6, 492–506. [Google Scholar] [CrossRef]
- Naji, H.A.H.; Xue, Q.; Lyu, N.; Duan, X.; Li, T. Risk Levels Classification of Near-Crashes in Naturalistic Driving Data. Sustainability 2022, 14, 6032. [Google Scholar] [CrossRef]
- Naji, H.A.H.; Xue, Q.; Zhu, H.; Li, T. Forecasting Taxi Demands Using Generative Adversarial Networks with Multi-Source Data. Appl. Sci. 2021, 11, 9675. [Google Scholar] [CrossRef]
- Jia, S.; Jiang, S.; Lin, Z.; Li, N.; Xu, M.; Yu, S. A survey: Deep learning for hyperspectral image classification with few labeled samples. Neurocomputing 2021, 448, 179–204. [Google Scholar] [CrossRef]
- Khan, S.; Rahmani, H.; Shah, S.A.A.; Bennamoun, M. A Guide to Convolutional Neural Networks for Computer Vision. Synth. Lect. Comput. Vis. 2018, 8, 1–207. [Google Scholar] [CrossRef]
- He, N.; Paoletti, M.E.; Haut, J.N.M.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Feature Extraction with Multiscale Covariance Maps for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 755–769. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, K.; Zhu, L.; He, X.; Ghamisi, P.; Benediktsson, J.A. Automatic Design of Convolutional Neural Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7048–7066. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, L.; Ghamisi, P.; Jia, X.; Li, G.; Tang, L. Hyperspectral Images Classification with Gabor Filtering and Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2355–2359. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y.; Zhang, N.; Xu, D.; Luo, H.; Chen, B.; Ben, G. Spectral–Spatial Fractal Residual Convolutional Neural Network with Data Balance Augmentation for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10473–10487. [Google Scholar] [CrossRef]
- Gao, H.; Zhang, Y.; Chen, Z.; Li, C. A Multiscale Dual-Branch Feature Fusion and Attention Network for Hyperspectral Images Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8180–8192. [Google Scholar] [CrossRef]
- Seydgar, M.; Naeini, A.A.; Zhang, M.; Li, W.; Satari, M. 3-D Convolution-Recurrent Networks for Spectral-Spatial Classification of Hyperspectral Images. Remote Sens. 2019, 11, 883. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Hamida, A.B.; Benoit, A.; Lambert, P.; Amar, C.B. 3-D deep learning approach for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Al-Alimi, D.; Cai, Z.; Al-Qaness, M.A.; Alawamy, E.A.; Alalimi, A. ETR: Enhancing transformation reduction for reducing dimensionality and classification complexity in hyperspectral images. Expert Syst. Appl. 2023, 213, 118971. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Al-Alimi, D.; Al-Qaness, M.A.; Cai, Z.; Alawamy, E.A. IDA: Improving distribution analysis for reducing data complexity and dimensionality in hyperspectral images. Pattern Recognit. 2023, 134, 109096. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Ma, A.; Zhang, L. FPGA: Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5612–5626. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Shi, C.; Liao, D.; Zhang, T.; Wang, L. Hyperspectral Image Classification Based on 3D Coordination Attention Mechanism Network. Remote Sens. 2022, 14, 608. [Google Scholar] [CrossRef]
- Al-Alimi, D.; Al-Qaness, M.A.A.; Cai, Z.; Dahou, A.; Shao, Y.; Issaka, S. Meta-Learner Hybrid Models to Classify Hyperspectral Images. Remote Sens. 2022, 14, 1038. [Google Scholar] [CrossRef]
- Ma, W.; Ma, H.; Zhu, H.; Li, Y.; Li, L.; Jiao, L.; Hou, B. Hyperspectral image classification based on spatial and spectral kernels generation network. Inf. Sci. 2021, 578, 435–456. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Shen, L.; Sadka, A.H.; Yang, J. Imbalanced data learning by minority class augmentation using capsule adversarial networks. Neurocomputing 2020, 459, 481–493. [Google Scholar] [CrossRef]
- Du, J.; Zhou, Y.; Liu, P.; Vong, C.-M.; Wang, T. Parameter-Free Loss for Class-Imbalanced Deep Learning in Image Classification. IEEE Trans. Neural Networks Learn. Syst. 2021, 1–7. [Google Scholar] [CrossRef]
- Huang, Y.; Jin, Y.; Li, Y.; Lin, Z. Towards Imbalanced Image Classification: A Generative Adversarial Network Ensemble Learning Method. IEEE Access 2020, 8, 88399–88409. [Google Scholar] [CrossRef]
- Özdemir, A.; Polat, K.; Alhudhaif, A. Classification of imbalanced hyperspectral images using SMOTE-based deep learning methods. Expert Syst. Appl. 2021, 178, 114986. [Google Scholar] [CrossRef]
- Singh, P.S.; Singh, V.P.; Pandey, M.K.; Karthikeyan, S. Enhanced classification of hyperspectral images using improvised oversampling and undersampling techniques. Int. J. Inf. Technol. 2022, 14, 389–396. [Google Scholar] [CrossRef]
- Lv, Q.; Feng, W.; Quan, Y.; Dauphin, G.; Gao, L.; Xing, M. Enhanced-Random-Feature-Subspace-Based Ensemble CNN for the Imbalanced Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3988–3999. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Feng, J.; Yu, H.; Wang, L.; Cao, X.; Zhang, X.; Jiao, L. Classification of Hyperspectral Images Based on Multiclass Spatial–Spectral Generative Adversarial Networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5329–5343. [Google Scholar] [CrossRef]
- Wang, X.; Tan, K.; Du, Q.; Chen, Y.; Du, P. Caps-TripleGAN: GAN-assisted CapsNet for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7232–7245. [Google Scholar] [CrossRef]
- Xue, Z. Semi-supervised convolutional generative adversarial network for hyperspectral image classification. IET Image Process. 2020, 14, 709–719. [Google Scholar] [CrossRef]
- Roy, S.K.; Haut, J.M.; Paoletti, M.E.; Dubey, S.R.; Plaza, A. Generative Adversarial Minority Oversampling for Spectral–Spatial Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Mish, M.D. A self-regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Ge, Z.; Cao, G.; Li, X.; Fu, P. Hyperspectral Image Classification Method Based on 2D–3D CNN and Multibranch Feature Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5776–5788. [Google Scholar] [CrossRef]
- Chen, Z.; Tong, L.; Qian, B.; Yu, J.; Xiao, C. Self-Attention-Based Conditional Variational Auto-Encoder Generative Adversarial Networks for Hyperspectral Classification. Remote Sens. 2021, 13, 3316. [Google Scholar] [CrossRef]
- Hyperspectral Remote Sensing Scenes. Available online: https://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes (accessed on 6 May 2022).
- Meng, Z.; Zhao, F.; Liang, M. SS-MLP: A Novel Spectral-Spatial MLP Architecture for Hyperspectral Image Classification. Remote Sens. 2021, 13, 4060. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef]
- Li, L.; Wang, C.; Li, W.; Chen, J. Hyperspectral image classification by AdaBoost weighted composite kernel extreme learning machines. Neurocomputing 2018, 275, 1725–1733. [Google Scholar] [CrossRef]
- Tu, B.; Wang, J.; Kang, X.; Zhang, G.; Ou, X.; Guo, L. KNN-Based Representation of Superpixels for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4032–4047. [Google Scholar] [CrossRef]
- Hao, S. Application of PCA dimensionality reduction and decision tree in hyperspectral image classification. Comput. Era 2017, 5, 40–43. [Google Scholar]
- Zhou, F.; Hang, R.; Liu, Q.; Yuan, X. Hyperspectral image classification using spectral-spatial LSTMs—ScienceDirect. Neurocomputing 2019, 328, 39–47. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–Spatial Classification of Hyperspectral Imagery with 3D Convolutional Neural Network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input Channels | Output Channels | Kernel Size | Previous Layer |
|---|---|---|---|---|
| Input | 1 | 1 | ||
| 2D CNN 1 | 1 | 32 | 3 × 3 | Input |
| carpooling 1 | 32 | 32 | 2 × 2 | 2D CNN 1 |
| 2D CNN 2 | 32 | 64 | 3 × 3 | carpooling 1 |
| maxpooling 2 | 64 | 64 | 2 × 2 | 2D CNN 2 |
| 2D CNN 3 | 64 | 512 | 3 × 3 | maxpooling 2 |
| FullConnected | 2D CNN 3 |
| Layer | Input Channels | Output Channels | Kernel Size | Previous Layer |
|---|---|---|---|---|
| 2D Conv_1 | 32 | 32 | 3 × 3 | |
| 2D Conv_2 | 32 | 64 | 3 × 3 | 2D Conv_1 |
| 2D Conv_3 | 64 | 512 | 3 × 3 | 2D Conv_2 |
| FullConnected | 2D Conv_3 |
| Number | Land Cover Class | Samples |
|---|---|---|
| 1 | Alfalfa | 46 |
| 2 | Corn notill | 1428 |
| 3 | Corn-mintill | 830 |
| 4 | Corn | 237 |
| 5 | Grass-pasture | 483 |
| 6 | Grass-trees | 730 |
| 7 | Grass-pasture-mowed | 28 |
| 8 | Hay-windrowed | 478 |
| 9 | Oats | 20 |
| 10 | Soybean-notill | 972 |
| 11 | Soybean-mintill | 2455 |
| 12 | Soybean-clean | 593 |
| 13 | Wheat | 205 |
| 14 | Woods | 1265 |
| 15 | Buildings Grass Trees-Drives | 386 |
| 16 | Stone-Steel-Towers | 93 |
| Number | Land Cover Class | Samples |
|---|---|---|
| 1 | Brocoli_green_weeds_1 | 2009 |
| 2 | Brocoli_green_weeds_2 | 3726 |
| 3 | Fallow | 1976 |
| 4 | Fallow_rough_plow | 1394 |
| 5 | Fallow_smooth | 2678 |
| 6 | Stubble | 3959 |
| 7 | Celery | 3579 |
| 8 | Grapes_untrained | 11,271 |
| 9 | Soil_vinyard_develop | 6203 |
| 10 | Corn_senesced_green_weeds | 3278 |
| 11 | Lettuce_romaine_4wk | 1068 |
| 12 | Lettuce_romaine_5wk | 1927 |
| 13 | Lettuce_romaine_6wk | 916 |
| 14 | Lettuce_romaine_7wk | 1070 |
| 15 | Vinyard_untrained | 7268 |
| 16 | Vinyard_vertical_trellis | 1807 |
| Number | Land Cover Class | Samples |
|---|---|---|
| 1 | Scrub | 761 |
| 2 | Willow swamp | 243 |
| 3 | CP hammock | 256 |
| 4 | Slash Pine | 252 |
| 5 | Oak/Broadleaf | 161 |
| 6 | Hardwood | 229 |
| 7 | Swap | 105 |
| 8 | Graminoid marsh | 431 |
| 9 | Spartina marsh | 520 |
| 10 | Cattail marsh | 404 |
| 11 | Salt marsh | 419 |
| 12 | Mud flats | 503 |
| 13 | Water | 927 |
| Number | Land Cover Class | Samples |
|---|---|---|
| 1 | Water | 270 |
| 2 | Hippo Grass | 101 |
| 3 | Floodplain Grasses1 | 251 |
| 4 | Floodplain Grasses2 | 215 |
| 5 | Reeds1 | 269 |
| 6 | Riparian | 269 |
| 7 | Firescar2 | 259 |
| 8 | Island interior | 203 |
| 9 | Accacia woodlands | 314 |
| 10 | Accacia grasslands | 248 |
| 11 | Short mopane | 305 |
| 12 | Mixed mopane | 181 |
| 13 | Exposed soils | 268 |
| No | Indian Pines | Salina | KSC | Botswana | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | |||||||||
| Real | Synth | Total | Real | Synth | Total | Real | Synth | Total | Real | Synth | Total | |||||
| 1 | 46 | 1454 | 1500 | 375 | 2009 | 5491 | 7500 | 1875 | 761 | 139 | 900 | 225 | 270 | 50 | 320 | 80 |
| 2 | 1428 | 72 | 1500 | 375 | 3726 | 3774 | 7500 | 1875 | 243 | 657 | 900 | 225 | 101 | 219 | 320 | 80 |
| 3 | 830 | 670 | 1500 | 375 | 1976 | 5524 | 7500 | 1875 | 256 | 644 | 900 | 225 | 251 | 69 | 320 | 80 |
| 4 | 237 | 1263 | 1500 | 375 | 1394 | 6106 | 7500 | 1875 | 252 | 648 | 900 | 225 | 215 | 105 | 320 | 80 |
| 5 | 483 | 1017 | 1500 | 375 | 2678 | 4822 | 7500 | 1875 | 161 | 739 | 900 | 225 | 269 | 51 | 320 | 80 |
| 6 | 730 | 770 | 1500 | 375 | 3959 | 3541 | 7500 | 1875 | 229 | 671 | 900 | 225 | 269 | 51 | 320 | 80 |
| 7 | 28 | 1472 | 1500 | 375 | 3579 | 3921 | 7500 | 1875 | 105 | 795 | 900 | 225 | 259 | 61 | 320 | 80 |
| 8 | 478 | 1022 | 1500 | 375 | 7500 | 0 | 7500 | 1875 | 431 | 469 | 900 | 225 | 203 | 117 | 320 | 80 |
| 9 | 20 | 1480 | 1500 | 375 | 6203 | 1297 | 7500 | 1875 | 520 | 380 | 900 | 225 | 314 | 6 | 320 | 80 |
| 10 | 972 | 528 | 1500 | 375 | 3278 | 4222 | 7500 | 1875 | 404 | 496 | 900 | 225 | 248 | 72 | 320 | 80 |
| 11 | 1500 | 0 | 1500 | 375 | 1068 | 6432 | 7500 | 1875 | 419 | 481 | 900 | 225 | 305 | 15 | 320 | 80 |
| 12 | 593 | 907 | 1500 | 375 | 1927 | 5573 | 7500 | 1875 | 503 | 397 | 900 | 225 | 181 | 139 | 320 | 80 |
| 13 | 205 | 1295 | 1500 | 375 | 916 | 6584 | 7500 | 1875 | 900 | 0 | 900 | 225 | ||||
| 14 | 1265 | 235 | 1500 | 375 | 1070 | 6430 | 7500 | 1875 | ||||||||
| 15 | 386 | 1114 | 1500 | 375 | 7268 | 232 | 7500 | 1875 | ||||||||
| 16 | 93 | 1407 | 1500 | 375 | 1807 | 5693 | 7500 | 1875 | ||||||||
| Method | Indian Pines | Salinas | Botswana | KSC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OA | AA | Kappa | OA | AA | Kappa | OA | AA | Kappa | OA | AA | Kappa | |
| MLP [44] | 90.21 | 93.11 | 88.72 | 92.17 | 88.38 | 89.59 | 80.34 | 80.19 | 78.67 | 71.12 | 72.79 | 75.58 |
| RF [45] | 83.14 | 85.15 | 81.14 | 83.63 | 81.23 | 78.32 | 83.59 | 84.99 | 82.23 | 83.13 | 76.76 | 81.17 |
| SVM [46] | 88.32 | 93.75 | 87.50 | 86.36 | 84.19 | 81.95 | 86.25 | 87.16 | 85.10 | 80.51 | 79.15 | 78.89 |
| Ada Boost [47] | 92.74 | 96.43 | 92.44 | 83.80 | 71.29 | 77.69 | 78.54 | 77.87 | 76.71 | 76.82 | 77.95 | 78.12 |
| KNN [48] | 91.16 | 95.16 | 89.15 | 89.23 | 86.86 | 85.49 | 89.79 | 90.65 | 88.94 | 85.03 | 78.83 | 83.30 |
| DT [49] | 80.71 | 83.14 | 80.14 | 79.24 | 66.54 | 71.36 | 89.88 | 90.79 | 89.04 | 85.93 | 79.86 | 84.31 |
| LSTM [50] | 60.22 | 58.51 | 59.68 | 91.63 | 88.38 | 88.8 | 78.29 | 77.72 | 76.44 | 62.24 | 62.00 | 63.24 |
| CNN1D [51] | 93.31 | 96.44 | 92.31 | 92.02 | 89.38 | 89.31 | 89.57 | 90.75 | 88.71 | 90.89 | 86.45 | 89.85 |
| CNN3D [52] | 94.04 | 95.57 | 93.89 | 91.56 | 88.3 | 88.71 | 86.29 | 87.18 | 85.15 | 87.59 | 82.08 | 86.17 |
| HybridSN [25] | 92.34 | 95.36 | 91.46 | 95.07 | 93.6 | 93.46 | 90.23 | 91.37 | 89.42 | 90.29 | 85.06 | 89.18 |
| 3D_Hyperamo [39] | 94.24 | 94.64 | 93.69 | 93.71 | 91.08 | 91.56 | 94.22 | 94.81 | 93.74 | 90.18 | 85.02 | 89.06 |
| Our model | 94.47 | 94.92 | 94.09 | 95.48 | 93.87 | 94.01 | 96.74 | 96.31 | 96.57 | 91.57 | 86.42 | 90.48 |
| Dataset | HybridSN | 3D_Hypergamo | Our Model | |||
|---|---|---|---|---|---|---|
| Training (mins) | Testing (sec) | Training (mins) | Testing (sec) | Training (mins) | Testing (sec) | |
| Indian Pines | 2.3 | 2.1 | 2.6 | 2.1 | 2.2 | 1.8 |
| Salinas | 3.1 | 2.9 | 3.2 | 3.2 | 3.6 | 3.25 |
| KSC | 2.63 | 1.9 | 2.8 | 2.91 | 3.7 | 2.81 |
| Botswana | 3.1 | 2.9 | 3.34 | 2.5 | 2.7 | 2.18 |
| Window | Indian Pines (%) | Salinas (%) | KSC (%) | Botswana (%) |
|---|---|---|---|---|
| 19 × 19 | 95.32 | 95.82 | 95.38 | 95.89 |
| 21 × 21 | 96.87 | 96.19 | 96.73 | 97.83 |
| 23 × 23 | 97.92 | 97.45 | 96.66 | 97.38 |
| 25 × 25 | 98.22 | 99.11 | 99.62 | 99.78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naji, H.A.H.; Li, T.; Xue, Q.; Duan, X. A Hypered Deep-Learning-Based Model of Hyperspectral Images Generation and Classification for Imbalanced Data. Remote Sens. 2022, 14, 6406. https://doi.org/10.3390/rs14246406
Naji HAH, Li T, Xue Q, Duan X. A Hypered Deep-Learning-Based Model of Hyperspectral Images Generation and Classification for Imbalanced Data. Remote Sensing. 2022; 14(24):6406. https://doi.org/10.3390/rs14246406
Chicago/Turabian StyleNaji, Hasan A. H., Tianfeng Li, Qingji Xue, and Xindong Duan. 2022. "A Hypered Deep-Learning-Based Model of Hyperspectral Images Generation and Classification for Imbalanced Data" Remote Sensing 14, no. 24: 6406. https://doi.org/10.3390/rs14246406