Figure 1.
The workflow diagram of our proposed model ADA-Es-gcForest.
Figure 1.
The workflow diagram of our proposed model ADA-Es-gcForest.
Figure 2.
The hyperspectral datasets: Indian Pines (IP): (a) the color composite image, (b) the false-color image.
Figure 2.
The hyperspectral datasets: Indian Pines (IP): (a) the color composite image, (b) the false-color image.
Figure 3.
The hyperspectral datasets: Salinas Valley (SV): (a) The color composite image, (b) the false-color image.
Figure 3.
The hyperspectral datasets: Salinas Valley (SV): (a) The color composite image, (b) the false-color image.
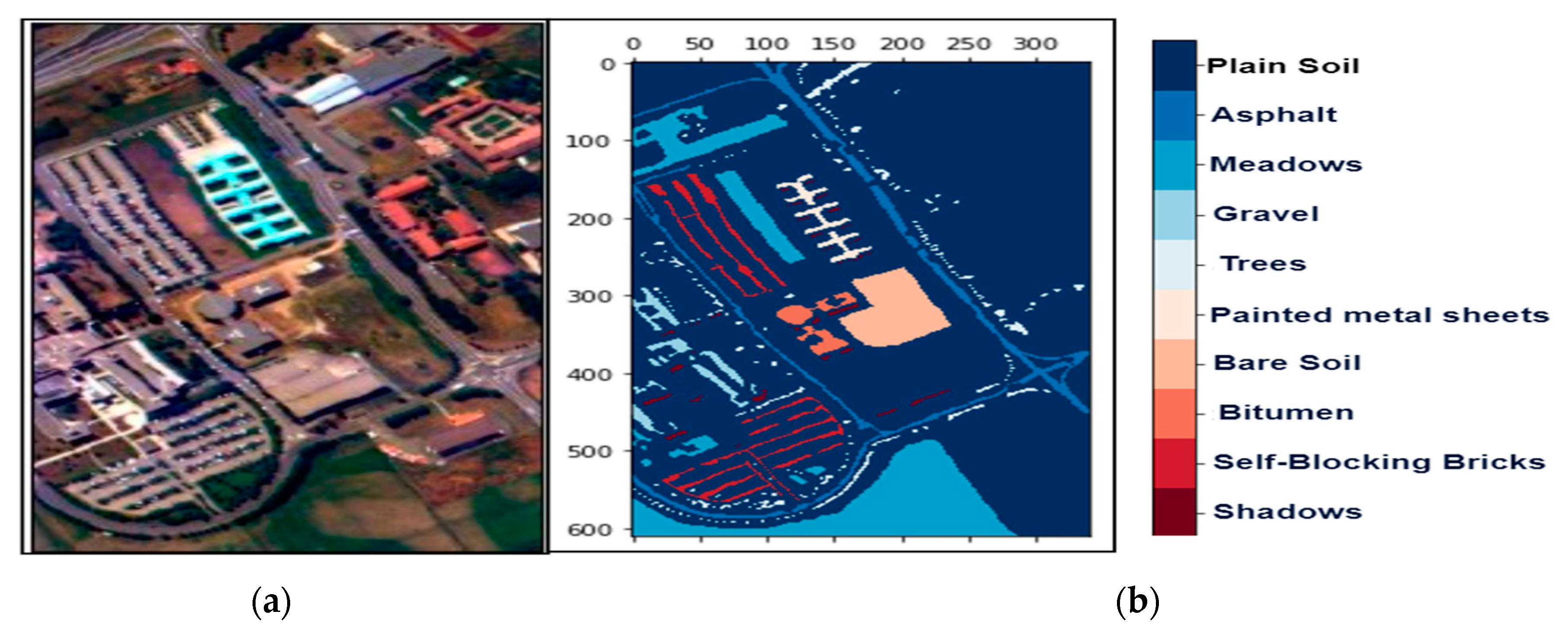
Figure 4.
The hyperspectral datasets: Pavia University (PU): (a) The color composite image, (b) the false-color image.
Figure 4.
The hyperspectral datasets: Pavia University (PU): (a) The color composite image, (b) the false-color image.
Figure 5.
The preprocessing and spectral feature extraction unit for HSI.
Figure 5.
The preprocessing and spectral feature extraction unit for HSI.
Figure 6.
The feature extraction unit for the subsampled multi-grained scanning: subsampling schema for sliding window or granularity size (a) 9 × 9, (b) 18 × 18, (c) 27 × 27.
Figure 6.
The feature extraction unit for the subsampled multi-grained scanning: subsampling schema for sliding window or granularity size (a) 9 × 9, (b) 18 × 18, (c) 27 × 27.
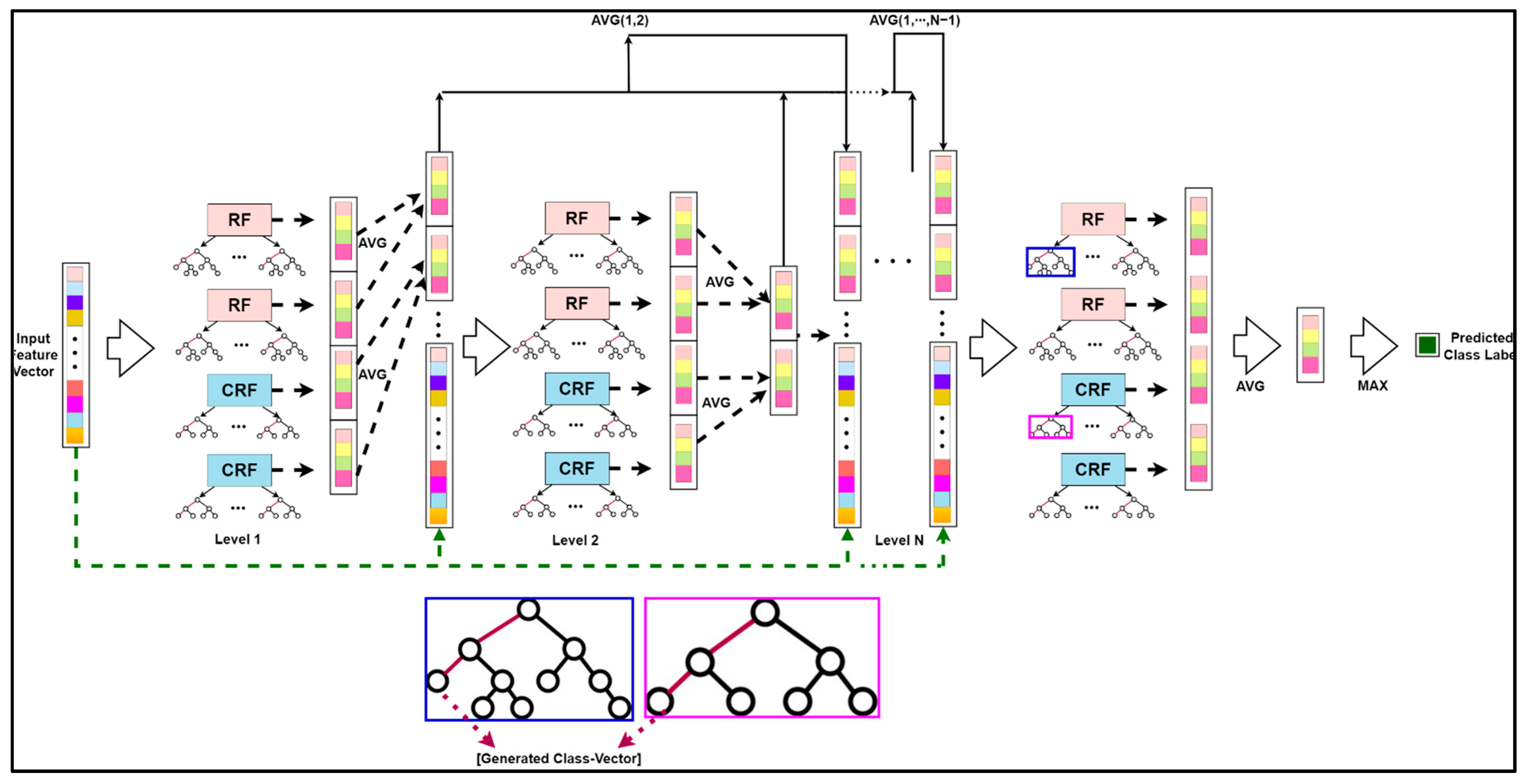
Figure 7.
The classification unit for HSI: The schematic structure for the enhanced deep CF.
Figure 7.
The classification unit for HSI: The schematic structure for the enhanced deep CF.
Figure 8.
The comparison of precision, recall, F_Score, kappa score, and overall accuracy achieved by our proposed model ADA-Es-gcForest for different principal components for (a) IP dataset, (b) SV dataset, (c) PU dataset.
Figure 8.
The comparison of precision, recall, F_Score, kappa score, and overall accuracy achieved by our proposed model ADA-Es-gcForest for different principal components for (a) IP dataset, (b) SV dataset, (c) PU dataset.
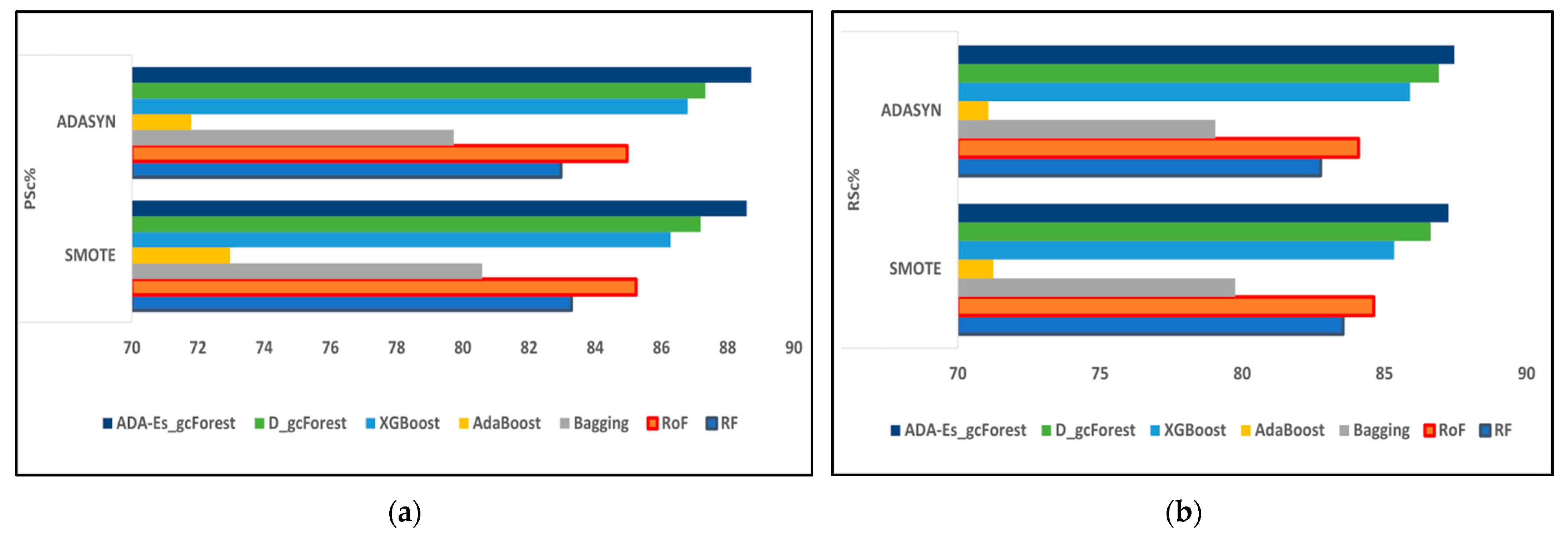
Figure 9.
The comparison of assessment metrics between the classifier models RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest for 40% IP test sets: (a) PSc%, (b) RSc%, (c) FSc%, and (d) KSc%.
Figure 9.
The comparison of assessment metrics between the classifier models RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest for 40% IP test sets: (a) PSc%, (b) RSc%, (c) FSc%, and (d) KSc%.
Figure 10.
The comparison of assessment metrics between the classifier models RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest for 40% SV test sets: (a) PSc%, (b) RSc%, (c) FSc%, and (d) KSc%.
Figure 10.
The comparison of assessment metrics between the classifier models RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest for 40% SV test sets: (a) PSc%, (b) RSc%, (c) FSc%, and (d) KSc%.
Figure 11.
The comparison of assessment metrics between the classifier models RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest for 40% PU test sets: (a) PSc%, (b) RSc%, (c) FSc%, and (d) KSc%.
Figure 11.
The comparison of assessment metrics between the classifier models RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest for 40% PU test sets: (a) PSc%, (b) RSc%, (c) FSc%, and (d) KSc%.
Figure 12.
The classification maps obtained by our proposed model ADA-Es-gcForest for the HSI datasets: (a) IP, (b) SV, and (c) PU.
Figure 12.
The classification maps obtained by our proposed model ADA-Es-gcForest for the HSI datasets: (a) IP, (b) SV, and (c) PU.
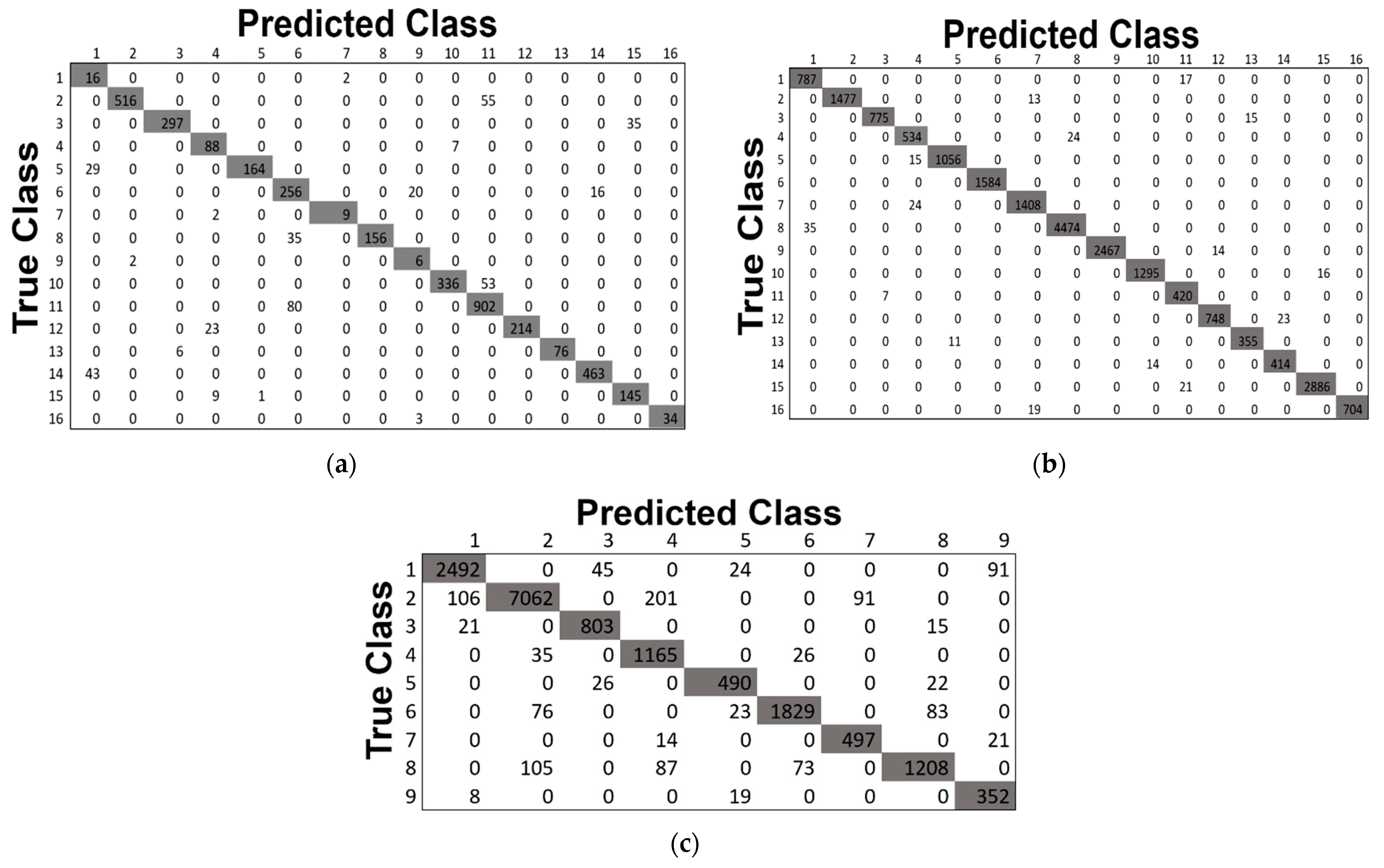
Figure 13.
The confusion matrices obtained by our proposed model ADA-Es-gcForest for the HSI datasets: (a) IP, (b) SV, and (c) PU.
Figure 13.
The confusion matrices obtained by our proposed model ADA-Es-gcForest for the HSI datasets: (a) IP, (b) SV, and (c) PU.
Table 1.
The ground truth for the HSI datasets: IP, SV, and PU.
Table 1.
The ground truth for the HSI datasets: IP, SV, and PU.
| The Dataset | Indian Pines | Salinas Valley |
| Class No. | Class Name | Original | Train | Test | Class Name | Original | Train | Test |
| 1 | Alfalfa | 46 | 28 | 18 | Brocoli_green_weeds_1 | 2009 | 1205 | 804 |
| 2 | Corn-notill | 1428 | 857 | 571 | Brocoli_green_weeds_2 | 3726 | 2236 | 1490 |
| 3 | Corn-mintill | 830 | 498 | 332 | Fallow | 1976 | 1186 | 790 |
| 4 | Corn | 237 | 142 | 95 | Fallow_rough_plow | 1394 | 836 | 558 |
| 5 | Grass-pasture | 483 | 290 | 193 | Fallow_smooth | 2678 | 1607 | 1071 |
| 6 | Corn-trees | 730 | 438 | 292 | Stubble | 3959 | 2375 | 1584 |
| 7 | Corn-pasture-mowed | 28 | 17 | 11 | Celery | 3579 | 2147 | 1432 |
| 8 | Hay-windrowed | 478 | 287 | 191 | Grapes_untrained | 11271 | 6762 | 4509 |
| 9 | Oats | 20 | 12 | 8 | Soil_vinyard_develop | 6203 | 3722 | 2481 |
| 10 | Soybeans-notill | 972 | 583 | 389 | Corn_senesced_green_weeds | 3278 | 1967 | 1311 |
| 11 | Soybeans-mintill | 2455 | 1473 | 982 | Lettuce_romaine_4wk | 1068 | 641 | 427 |
| 12 | Soybeans-clean | 593 | 356 | 237 | Lettuce_romaine_5wk | 1927 | 1156 | 771 |
| 13 | Wheat | 205 | 123 | 82 | Lettuce_romaine_6wk | 916 | 550 | 366 |
| 14 | Woods | 1265 | 759 | 506 | Lettuce_romaine_7wk | 1070 | 642 | 428 |
| 15 | Buildings-Grass-Trees-Drivers | 386 | 231 | 155 | Vinyard_untrained | 7268 | 4361 | 2907 |
| 16 | Stone-steel-Towers | 93 | 56 | 37 | Vinyard_vertical_trellis | 1807 | 1084 | 723 |
| Total | | 10,249 | 6150 | 4099 | | 54,129 | 32,477 | 21,652 |
| The Dataset | Pavia University |
| Class No. | Class Name | Original | Train | Test |
| 1 | Asphalt | 6631 | 3979 | 2652 |
| 2 | Meadows | 18,649 | 11,189 | 7460 |
| 3 | Gravel | 2099 | 1260 | 839 |
| 4 | Trees | 3064 | 1838 | 1226 |
| 5 | Painted metal sheets | 1345 | 807 | 538 |
| 6 | Bare Soil | 5029 | 3018 | 2011 |
| 7 | Bitumen | 1330 | 798 | 532 |
| 8 | Self-Blocking Bricks | 3682 | 2209 | 1473 |
| 9 | Shadows | 947 | 568 | 379 |
| Total | | 42,776 | 25,666 | 17,110 |
Table 2.
Complete hardware/software specification information.
Table 2.
Complete hardware/software specification information.
| Item Name | Specification |
|---|
| Processor | Intel® Core™ i7-11800H (2.3 GHz) |
| RAM | 16GB DDR4 3200MHz |
| GPU | 4GB NVIDIA GeForce RTX 3050 Ti |
| OS | Windows 11 |
| Python Version | 3.9 |
| Python Packages | Tensorflow, Keras, Scikit etc. (latest versions) |
Table 3.
The hyperparameter configuration of PCA.
Table 3.
The hyperparameter configuration of PCA.
| Hyperparameter | Configured Value |
|---|
| Number of components | 20, 40, 50, 60 (for comparison) |
| Whiten | True (ensures uncorrelated products with unit component-wise variances for the input samples) |
| Svd_solver | Auto (default but can be adaptive depending on the input sample size and number of components) |
Table 4.
The hyperparameter configuration of SMOTE and ADASYN.
Table 4.
The hyperparameter configuration of SMOTE and ADASYN.
| Hyperparameter | Configured Value |
|---|
| Sampling strategy | Minority (we have mostly chosen the minor classes to create a similar number of samples as the major classes) |
| k-NN | 5 (count of NNs used to generate synthetic samples) |
Table 5.
The hyperparameter configuration and feature generation of subsampled multi-grained scanning.
Table 5.
The hyperparameter configuration and feature generation of subsampled multi-grained scanning.
| Subsampling Schema Sl No. (i) | Granularity Size (mi) | Stride Step-Size (si) | Sampling Rate (r) | Number of Feature Instances (I) | Subsampled Instance Count (II′) | New Feature Vector Dimension (di) |
|---|
| 1 | 9 | 1 | 0.5 | | | |
| 2 | 18 | 1 | 0.5 | | | |
| 3 | 27 | 1 | 0.5 | | | |
Table 6.
The hyperparameter configuration of improved deep cascade forest.
Table 6.
The hyperparameter configuration of improved deep cascade forest.
| Hyperparameter | Configured Value |
|---|
| Number of Forests | 4 (two RFs and two CRFs) |
| Number of DTs in RF | 500 |
| Number of DTs in CRF | 1000 |
Table 7.
The summarization of the variation of cascade layer count with the number of PCA components for the HSI datasets.
Table 7.
The summarization of the variation of cascade layer count with the number of PCA components for the HSI datasets.
| n-PCA | IP | SV | PU |
|---|
| 20 | 2 | 2 | 2 |
| 40 | 2 | 3 | 3 |
| 50 | 3 | 3 | 4 |
| 60 | 3 | 4 | 4 |
Table 8.
The result in terms of classification accuracies (%) for the IP dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 73.6 and 40% of testing samples.
Table 8.
The result in terms of classification accuracies (%) for the IP dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 73.6 and 40% of testing samples.
T-40%
Classifier | RF | RoF | Bagging | AdaBoost | XGBoost | DgcForest | ADA-Es-gcForest |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| OA% | 80.07 ± 0.63 | 79.88 ± 1.05 | 85.01 ± 1.67 | 84.47 ± 1.03 | 75.82 ± 1.53 | 73.92 ± 0.99 | 68.66 ± 1.43 | 66.04 ± 1.74 | 85.11 ± 1.3 | 81.5 ± 1.02 | 85.08 ± 1.59 | 87.01 ± 1.62 | 85.58 ± 0.76 | 89.7 ± 1.24 |
| AA% | 83.63 ± 0.75 | 81.62 ± 0.68 | 86.29 ± 1.03 | 86.06 ± 0.96 | 78.65 ± 1.68 | 77.62 ± 1.56 | 74.72 ± 0.65 | 72.07 ± 1.37 | 86.9 ± 1.5 | 83.56 ± 0.79 | 85.19 ± 1.22 | 88.95 ± 1.19 | 86.15 ± 0.55 | 91.47 ± 0.98 |
| 1 | 71.26 ± 0.75 | 74.55 ± 0.57 | 70.25 ± 0.88 | 65.66 ± 1.13 | 70.72 ± 1.24 | 81.66 ± 1.57 | 82.18 ± 1.52 | 74.98 ± 1.42 | 85.1 ± 1.58 | 76.03 ± 0.94 | 80.57 ± 1.37 | 84.46 ± 1.69 | 89.77 ± 1.5 | 90.5 ± 1.01 |
| 2 | 81.65 ± 0.68 | 64.24 ± 1.34 | 87.55 ± 0.62 | 68.52 ± 0.57 | 87.62 ± 0.63 | 69.43 ± 0.72 | 83.92 ± 1.71 | 74.92 ± 1.55 | 82.1 ± 1.08 | 71.19 ± 1.61 | 69.87 ± 1.18 | 73.78 ± 1.36 | 89.56 ± 1.72 | 92.64 ± 0.68 |
| 3 | 72.43 ± 0.58 | 87.75 ± 0.55 | 66.33 ± 0.52 | 68.73 ± 0.58 | 77.87 ± 1.23 | 73.53 ± 1.62 | 75.84 ± 1.2 | 67.82 ± 0.66 | 62.86 ± 1.03 | 66.55 ± 1.69 | 85.09 ± 1.4 | 89 ± 1.36 | 87.42 ± 1.14 | 88.78 ± 1.35 |
| 4 | 64.72 ± 0.71 | 85.25 ± 1.79 | 80.82 ± 1.32 | 79.84 ± 1.19 | 66.06 ± 1.2 | 71.95 ± 1.67 | 77.92 ± 1 | 64.04 ± 1.3 | 80.27 ± 1.19 | 82.42 ± 0.71 | 79.73 ± 1.07 | 83.46 ± 1.25 | 88.81 ± 1.1 | 89.56 ± 0.67 |
| 5 | 64.98 ± 1.78 | 83.03 ± 1.67 | 68.41 ± 1.76 | 74.45 ± 0.6 | 81.63 ± 1.61 | 80.73 ± 0.91 | 67.78 ± 0.58 | 85.12 ± 0.7 | 86.86 ± 1.63 | 76.63 ± 1.26 | 77.22 ± 0.54 | 67.12 ± 1.03 | 87.46 ± 1.37 | 90.26 ± 1.2 |
| 6 | 77.02 ± 0.72 | 82.8 ± 0.53 | 70.12 ± 0.76 | 86.92 ± 1.8 | 72.85 ± 0.57 | 81.62 ± 1.7 | 80.11 ± 0.98 | 69.48 ± 0.73 | 65.82 ± 0.85 | 72.22 ± 1.67 | 63.79 ± 0.64 | 82.76 ± 1.71 | 86.2 ± 1.73 | 89.33 ± 0.97 |
| 7 | 69.33 ± 0.85 | 84.12 ± 0.53 | 71.79 ± 0.81 | 73.08 ± 1.21 | 77.91 ± 0.67 | 69.85 ± 1.52 | 71.01 ± 1.27 | 79.17 ± 0.97 | 67.48 ± 0.83 | 87.21 ± 0.53 | 79.66 ± 1.71 | 84.91 ± 1.32 | 89.45 ± 1.46 | 89.5 ± 1.57 |
| 8 | 88.72 ± 1.32 | 65.26 ± 0.6 | 68.41 ± 1.78 | 84.55 ± 0.92 | 88.71 ± 1.78 | 81.8 ± 1.16 | 63.78 ± 0.87 | 78.78 ± 0.97 | 78.91 ± 1.79 | 63.2 ± 1.65 | 83.15 ± 1.15 | 70.19 ± 0.68 | 88.7 ± 1.08 | 91.6 ± 1.17 |
| 9 | 63.1 ± 1.01 | 76.66 ± 0.82 | 62.43 ± 1.7 | 84.71 ± 0.52 | 85.56 ± 0.55 | 65.64 ± 0.97 | 76.41 ± 1.36 | 76.04 ± 1.05 | 68.31 ± 1.04 | 62.56 ± 1.21 | 86.37 ± 1.37 | 74.88 ± 0.53 | 86.69 ± 0.51 | 91.36 ± 1.12 |
| 10 | 76.21 ± 1.44 | 86.38 ± 0.57 | 68.62 ± 1.06 | 68.14 ± 1.27 | 65.16 ± 1.49 | 88.1 ± 1.8 | 79.88 ± 1.21 | 88.47 ± 0.57 | 73.28 ± 1.23 | 74.23 ± 1.12 | 88.36 ± 0.79 | 64.37 ± 1.15 | 87.46 ± 0.67 | 91.06 ± 0.56 |
| 11 | 64.53 ± 0.85 | 63 ± 1.68 | 62.4 ± 1.56 | 68.13 ± 1.17 | 87.24 ± 1.03 | 65.79 ± 1.77 | 75.17 ± 1.57 | 70.01 ± 1.41 | 62.45 ± 1.77 | 64.88 ± 1.1 | 83.34 ± 1.5 | 78.46 ± 1.55 | 88.4 ± 0.87 | 89.16 ± 1.1 |
| 12 | 80.71 ± 0.6 | 86.88 ± 1.62 | 75.41 ± 1.31 | 65.04 ± 0.62 | 86.28 ± 1.52 | 74.26 ± 1.17 | 80.34 ± 1.56 | 62.66 ± 0.95 | 87.03 ± 1.5 | 68.39 ± 0.74 | 77.66 ± 1.53 | 77.08 ± 0.54 | 86.94 ± 1.03 | 90.49 ± 1.28 |
| 13 | 79.3 ± 1.42 | 71.59 ± 1.79 | 77.38 ± 0.8 | 72.43 ± 1.01 | 82.15 ± 0.52 | 71.77 ± 0.73 | 61.27 ± 1.38 | 75.52 ± 0.76 | 73.33 ± 1.66 | 83.98 ± 1.41 | 62.41 ± 1.37 | 88.16 ± 0.91 | 90 ± 1.34 | 91.58 ± 0.62 |
| 14 | 74.59 ± 0.75 | 65.43 ± 1.35 | 80.54 ± 1.49 | 84.27 ± 1.67 | 87.08 ± 1.47 | 83.7 ± 1.53 | 88.5 ± 1.24 | 80.88 ± 1.52 | 63.63 ± 1.64 | 64.34 ± 1.02 | 65.81 ± 0.86 | 89.2 ± 1.32 | 88.01 ± 1.76 | 89.18 ± 0.72 |
| 15 | 78.09 ± 0.96 | 86.67 ± 1.6 | 84.97 ± 0.75 | 74.62 ± 0.77 | 84.68 ± 0.94 | 63.57 ± 1.15 | 79.32 ± 1.25 | 64.94 ± 0.52 | 69.92 ± 1.74 | 89.28 ± 0.62 | 65.49 ± 1.71 | 83.6 ± 1.52 | 86.3 ± 1.71 | 92.7 ± 0.64 |
| 16 | 65.89 ± 1.62 | 86.01 ± 1.18 | 70.44 ± 1.16 | 75.5 ± 0.78 | 64.08 ± 0.93 | 83.85 ± 1.36 | 62.78 ± 0.72 | 71.68 ± 1.25 | 64.72 ± 1.73 | 75.98 ± 0.87 | 74.21 ± 1.15 | 88.88 ± 1.3 | 89.89 ± 1.31 | 89.29 ± 1.48 |
Table 9.
The result in terms of classification accuracies (%) for the IP dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 73.6 and 50% of testing samples.
Table 9.
The result in terms of classification accuracies (%) for the IP dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 73.6 and 50% of testing samples.
T-50%
Classifier | RF | RoF | Bagging | AdaBoost | XGBoost | DgcForest | ADA-Es-gcForest |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| OA% |
79.74 ± 2.25
|
75.95 ± 2.27
|
80.19 ± 1.93
|
78.27 ± 1.04
|
72.15 ± 2.32
|
68.53 ± 2.15
|
64.79 ± 1.8
|
62.99 ± 1.68
|
80.45 ± 0.94
|
77.46 ± 1.37
| 81.97 ± 1.68 | 84.39 ± 1.74 | 82.58 ± 1.09 | 87.29 ± 1.72 |
| AA% |
81.03 ± 2
|
80.1 ± 1.05
|
83.51 ± 2.03
|
81.35 ± 1.79
|
76.29 ± 0.99
|
73.85 ± 2.05
|
70.98 ± 2.22
|
69.06 ± 1.9
|
83.56 ± 0.91
|
80.34 ± 2.01
| 83.2 ± 1.08 | 87.73 ± 1.08 | 84.69 ± 1.09 | 89.59 ± 1.48 |
| 1 |
74.71 ± 2.37
|
64.22 ± 1.26
|
70.42 ± 2.03
|
84.62 ± 1.42
|
86.92 ± 1.26
|
82.54 ± 1.71
|
64.8 ± 1.05
|
88.39 ± 1.58
|
87.46 ± 1.82
|
68.98 ± 1.28
|
80.35 ± 1
|
74.91 ± 1.12
|
83.58 ± 0.99
|
85.55 ± 0.98
|
| 2 |
86.97 ± 1.6
|
82.37 ± 1.47
|
75.8 ± 1.64
|
65.6 ± 0.93
|
75.86 ± 1.33
|
74.52 ± 1.22
|
88.33 ± 1.92
|
80.76 ± 1.61
|
71.15 ± 1.51
|
77.36 ± 1.19
|
79.71 ± 1.73
|
81.16 ± 1.83
|
83.53 ± 1.08
|
82.71 ± 2.14
|
| 3 |
76.53 ± 1.33
|
70.77 ± 2.31
|
76.14 ± 1.3
|
87.56 ± 1.17
|
84.02 ± 1.74
|
88.67 ± 1.59
|
76.52 ± 0.92
|
77.67 ± 2.35
|
86.71 ± 1.31
|
74.61 ± 1.3
|
71.51 ± 1.95
|
78.1 ± 2.23
|
84.24 ± 1.95
|
84.93 ± 1.9
|
| 4 |
86.1 ± 1.48
|
71.91 ± 0.96
|
72.26 ± 1.85
|
71.33 ± 1.3
|
83.21 ± 1.74
|
70.2 ± 1.8
|
77.54 ± 1.24
|
78.83 ± 0.92
|
72.62 ± 1.39
|
68.38 ± 1.92
|
68.37 ± 1.34
|
84.36 ± 1.13
|
83.14 ± 1.23
|
83.55 ± 1.83
|
| 5 |
83.9 ± 1.96
|
88.92 ± 2.21
|
84.49 ± 1.11
|
62.61 ± 2.16
|
77.58 ± 1.99
|
73.82 ± 1.99
|
76.51 ± 1.22
|
80.67 ± 1.77
|
72.98 ± 1.67
|
72.06 ± 1.87
|
76.03 ± 1.49
|
78.03 ± 1.21
|
86.39 ± 2
|
84.44 ± 2.23
|
| 6 |
75.59 ± 2.1
|
79.21 ± 1.17
|
64.48 ± 0.9
|
61.68 ± 1.18
|
85.96 ± 1.98
|
65.71 ± 1.55
|
68.38 ± 2.34
|
62.99 ± 2.11
|
80.17 ± 1.14
|
72.56 ± 1.99
|
71.77 ± 1.07
|
82.28 ± 0.95
|
83.17 ± 1.12
|
86.37 ± 1.78
|
| 7 |
74.2 ± 1.86
|
62.1 ± 2.22
|
77.08 ± 1.17
|
65.43 ± 1.17
|
65.31 ± 1.71
|
77.58 ± 2.28
|
64.14 ± 1.5
|
76.69 ± 1.19
|
80.88 ± 2.23
|
84.02 ± 1.69
|
86.07 ± 1.87
|
76.12 ± 0.93
|
85.55 ± 1.11
|
85.53 ± 2.06
|
| 8 |
70.32 ± 2.05
|
69.17 ± 2.37
|
86.12 ± 1.84
|
72.08 ± 2.21
|
76.77 ± 1.61
|
71.27 ± 1.8
|
80.67 ± 1.42
|
74.27 ± 1.18
|
78.03 ± 1.88
|
77.11 ± 2.11
|
77.94 ± 1.43
|
66.11 ± 1.38
|
82.23 ± 2.36
|
84.27 ± 0.96
|
| 9 |
68.93 ± 1.03
|
63.76 ± 1.43
|
62.81 ± 1.5
|
79.94 ± 0.96
|
88.13 ± 2.01
|
70.58 ± 1.22
|
74.16 ± 2.21
|
87.84 ± 2.32
|
87.58 ± 2.08
|
87.66 ± 1.62
|
73.81 ± 1.41
|
75.4 ± 2
|
86.55 ± 1.7
|
86.71 ± 1.81
|
| 10 |
88.21 ± 1.96
|
76.34 ± 1.8
|
65.41 ± 1.19
|
86.21 ± 1.04
|
69.55 ± 2.35
|
69.05 ± 0.96
|
76.63 ± 1.09
|
75.88 ± 2.36
|
86.9 ± 1.43
|
70.13 ± 1.13
|
69.96 ± 1.52
|
67.1 ± 2.17
|
86.18 ± 1.95
|
85.06 ± 2.13
|
| 11 |
79.9 ± 2.39
|
86.99 ± 1.19
|
77.22 ± 1.45
|
77.92 ± 1.89
|
82.25 ± 1.1
|
74.19 ± 1.53
|
80.14 ± 1.96
|
66.01 ± 1.77
|
88.15 ± 1
|
75.06 ± 1.92
|
77.31 ± 0.92
|
75.45 ± 1.81
|
86.11 ± 2.2
|
84.99 ± 1.48
|
| 12 |
62.65 ± 2.12
|
82.49 ± 1.53
|
84 ± 1.03
|
83.15 ± 1.35
|
81.31 ± 1.33
|
84.19 ± 1.28
|
67.29 ± 1.02
|
81.05 ± 1.04
|
86.52 ± 1.99
|
86.18 ± 1.78
|
87.09 ± 1.67
|
69.5 ± 2.23
|
84.24 ± 1
|
86.79 ± 1.32
|
| 13 |
73.09 ± 1.14
|
69.74 ± 1.31
|
84.01 ± 1.61
|
65.27 ± 2.27
|
71.28 ± 0.97
|
62.5 ± 2.04
|
63.35 ± 2.14
|
66.37 ± 1.88
|
70.13 ± 1.23
|
79.98 ± 2.32
|
79.08 ± 1.55
|
63.25 ± 0.93
|
82.53 ± 2.37
|
85.4 ± 1.65
|
| 14 |
69.6 ± 2.22
|
70.24 ± 1.25
|
70.98 ± 2.18
|
63.22 ± 2.07
|
72.71 ± 1.94
|
86.44 ± 1.07
|
71.81 ± 1.19
|
76.83 ± 0.96
|
87.66 ± 1.1
|
66.86 ± 1.96
|
66.2 ± 1.58
|
82.98 ± 2.03
|
83.35 ± 1.36
|
83.36 ± 1.89
|
| 15 |
87.68 ± 1.36
|
62.22 ± 1.92
|
65.09 ± 1.22
|
82.1 ± 2.15
|
75.56 ± 1.25
|
79.21 ± 1.32
|
66.99 ± 2.33
|
77.09 ± 1.68
|
73.58 ± 1.51
|
67.82 ± 2.25
|
67.4 ± 1.32
|
66.14 ± 1.05
|
85.27 ± 1.22
|
82.72 ± 1.54
|
| 16 |
75.59 ± 2.13
|
71.75 ± 2.29
|
82.95 ± 1.19
|
87.04 ± 1.5
|
67.73 ± 1.65
|
67.44 ± 1.5
|
87.93 ± 1.21
|
71.58 ± 2.24
|
65.85 ± 1.1
|
74.13 ± 1.28
|
79.33 ± 1.11
|
64.53 ± 1.26
|
86.66 ± 1.42
|
82.58 ± 1.74
|
Table 10.
The result in terms of classification accuracies (%) for the IP dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 73.6 and 60% of testing samples.
Table 10.
The result in terms of classification accuracies (%) for the IP dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 73.6 and 60% of testing samples.
T-60%
Classifier | RF | RoF | Bagging | AdaBoost | XGBoost | DgcForest | ADA-Es-gcForest |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| OA% |
76.81 ± 2.59
|
73.76 ± 2.98
|
78.68 ± 2.44
|
77.17 ± 2.77
|
68.74 ± 2.47
|
63.26 ± 1.87
|
63.59 ± 1.76
|
59.17 ± 2.92
|
78.95 ± 2.68
|
74.66 ± 2.82
| 78.38 ± 2.01 | 82.37 ± 3.05 | 80.58 ± 2.22 | 85.33 ± 2.06 |
| AA% |
78.71 ± 3.01
|
77.24 ± 1.79
|
80.75 ± 1.9
|
79.25 ± 1.47
|
73.38 ± 2.24
|
67.48 ± 2.02
|
67.62 ± 1.46
|
65.82 ± 2.83
|
81.05 ± 2.96
|
77.92 ± 1.33
| 81.89 ± 3.1 | 84.76 ± 2.55 | 82.11 ± 2.47 | 87.92 ± 2.72 |
| 1 |
71.17 ± 1.52
|
70.46 ± 1.4
|
78.42 ± 2.28
|
65.58 ± 2.58
|
61.2 ± 1.24
|
76.59 ± 2.58
|
68.71 ± 1.48
|
67.4 ± 2.96
|
63.9 ± 2.89
|
72.28 ± 2.35
|
71.29 ± 1.61
|
62.61 ± 3.07
|
82.36 ± 2.62
|
79.21 ± 2.74
|
| 2 |
71.62 ± 2.33
|
72.89 ± 2.13
|
62.58 ± 2.94
|
79.83 ± 2.33
|
78.42 ± 2.83
|
85.47 ± 2.88
|
67.6 ± 3
|
86.88 ± 2.86
|
66.11 ± 3.1
|
87.8 ± 2.96
|
62.69 ± 1.25
|
77.4 ± 1.78
|
82.11 ± 1.72
|
83.25 ± 2.95
|
| 3 |
67.42 ± 2.15
|
62.09 ± 1.51
|
64.45 ± 1.8
|
74.27 ± 1.71
|
88.92 ± 1.62
|
66.04 ± 2.46
|
69.08 ± 2.8
|
75.71 ± 1.58
|
61.2 ± 1.45
|
62.03 ± 2.21
|
85.93 ± 1.89
|
86.56 ± 2.87
|
81.68 ± 1.8
|
83.73 ± 2.73
|
| 4 |
67.44 ± 1.69
|
71.74 ± 1.19
|
67.3 ± 2.34
|
69.94 ± 2.31
|
82.67 ± 2.19
|
84.72 ± 1.59
|
66.32 ± 3.04
|
65.29 ± 2.04
|
67.22 ± 1.57
|
66.29 ± 2.68
|
77.16 ± 1.83
|
82.89 ± 2.2
|
79.99 ± 1.62
|
82.58 ± 1.46
|
| 5 |
85.16 ± 1.58
|
86.92 ± 2.01
|
79.03 ± 1.4
|
84.09 ± 2.83
|
85.38 ± 2.28
|
80.93 ± 1.54
|
86.03 ± 1.11
|
61.11 ± 1.34
|
66.41 ± 1.33
|
71.67 ± 2.86
|
83.7 ± 2.7
|
81.26 ± 2.89
|
79.7 ± 1.7
|
82.69 ± 1.45
|
| 6 |
86.58 ± 2.59
|
63.31 ± 1.84
|
81.6 ± 2.52
|
80.61 ± 1.92
|
72.19 ± 1.84
|
64.96 ± 1.66
|
73.15 ± 1.37
|
69.2 ± 1.13
|
82.85 ± 2.37
|
62.51 ± 1.78
|
77.41 ± 1.6
|
79.09 ± 1.42
|
80.01 ± 2.7
|
82.71 ± 1.67
|
| 7 |
76.83 ± 1.72
|
69.37 ± 2.09
|
69.63 ± 1.3
|
77.77 ± 1.98
|
83.43 ± 2.47
|
87.75 ± 1.98
|
72.82 ± 2.21
|
66.7 ± 1.96
|
71.59 ± 2.24
|
84.11 ± 2.2
|
77.17 ± 2.66
|
66.65 ± 2.48
|
81.61 ± 2.59
|
79.7 ± 1.49
|
| 8 |
81.56 ± 1.38
|
78.81 ± 1.16
|
61.04 ± 1.73
|
87.76 ± 2.6
|
79.07 ± 1.4
|
73.25 ± 2.95
|
77.61 ± 2.24
|
85.89 ± 3.06
|
67.41 ± 2.29
|
74.44 ± 1.29
|
86.55 ± 2.66
|
88.47 ± 1.26
|
83.29 ± 2.77
|
82.58 ± 2.75
|
| 9 |
77.72 ± 2.59
|
88.21 ± 1.15
|
80.3 ± 1.28
|
76.84 ± 2.38
|
83.78 ± 1.71
|
78.7 ± 2.95
|
78.9 ± 2.05
|
88.86 ± 2.79
|
67.89 ± 1.33
|
71.24 ± 2.64
|
62.19 ± 1.35
|
68.72 ± 2.12
|
79.68 ± 1.5
|
81.78 ± 2.94
|
| 10 |
67.64 ± 1.18
|
75.85 ± 2.66
|
88.78 ± 1.69
|
78.36 ± 1.99
|
70.41 ± 1.63
|
85.29 ± 2.54
|
86.89 ± 1.6
|
78.74 ± 1.83
|
87.63 ± 1.82
|
62.44 ± 1.29
|
72.83 ± 2.05
|
70.6 ± 2.25
|
83.97 ± 1.3
|
79.31 ± 2.1
|
| 11 |
72.85 ± 2.66
|
83.22 ± 1.47
|
65.45 ± 1.44
|
66.8 ± 2.94
|
66.15 ± 2.23
|
76.91 ± 1.3
|
71.41 ± 1.63
|
69.9 ± 3.01
|
80.45 ± 3.03
|
72.34 ± 1.48
|
82.44 ± 2.78
|
77.53 ± 1.53
|
82.39 ± 2.2
|
83.96 ± 2.39
|
| 12 |
75.12 ± 2.75
|
85.56 ± 2.79
|
70.5 ± 2.6
|
73.84 ± 1.56
|
63.55 ± 1.8
|
86.09 ± 1.18
|
63.2 ± 1.18
|
63.16 ± 2.22
|
84.2 ± 2.58
|
83.63 ± 2.15
|
64.76 ± 3.05
|
76.98 ± 1.41
|
81.69 ± 2.75
|
84.57 ± 2.22
|
| 13 |
64.68 ± 1.63
|
64.72 ± 2.37
|
79.93 ± 3.02
|
70.09 ± 2.42
|
88.97 ± 2.56
|
62.42 ± 2.86
|
78.91 ± 1.16
|
75.27 ± 1.84
|
74.51 ± 2.7
|
74.01 ± 3.07
|
68.06 ± 2.55
|
65.6 ± 3.07
|
82.84 ± 2.12
|
80.81 ± 1.67
|
| 14 |
63.26 ± 1.8
|
84.97 ± 2.11
|
65.47 ± 2.9
|
69.24 ± 1.6
|
86.22 ± 2.65
|
87.11 ± 2.88
|
78.82 ± 2.51
|
88.2 ± 1.32
|
85.59 ± 2.96
|
77.25 ± 3.03
|
88.23 ± 1.69
|
74.58 ± 1.49
|
83.7 ± 2.88
|
84.81 ± 2.54
|
| 15 |
86.53 ± 1.19
|
83.63 ± 2.55
|
67.97 ± 1.16
|
81.72 ± 2.44
|
66.65 ± 1.48
|
62.21 ± 1.37
|
77.64 ± 2.11
|
81.76 ± 1.72
|
84.22 ± 1.4
|
86.2 ± 3.05
|
69.53 ± 2.98
|
70.19 ± 2.39
|
82.95 ± 1.84
|
80.09 ± 1.57
|
| 16 |
70.17 ± 1.95
|
80.89 ± 2.11
|
83.93 ± 2.79
|
78.88 ± 2.48
|
72.92 ± 2.78
|
88.67 ± 2.42
|
76.96 ± 1.76
|
65.7 ± 3.03
|
76.01 ± 2.73
|
83.22 ± 1.49
|
80.75 ± 1.63
|
61.47 ± 2.18
|
81.15 ± 1.56
|
81.65 ± 1.79
|
Table 11.
The result in terms of classification accuracies (%) for the SV dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 12.51 and 40% of testing samples.
Table 11.
The result in terms of classification accuracies (%) for the SV dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 12.51 and 40% of testing samples.
T-40%
Classifier | RF | RoF | Bagging | AdaBoost | XGBoost | DgcForest | ADA-Es-gcForest |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| OA% |
90.3 ± 1.4
|
89.58 ± 0.77
|
93.41 ± 0.68
|
90.92 ± 1.17
|
86.76 ± 0.66
|
86.14 ± 1.42
|
78.77 ± 0.6
|
78.43 ± 0.7
|
89.61 ± 1.79
|
89.29 ± 1.08
| 92.35 ± 1.71 | 95.02 ± 0.77 | 95.58 ± 0.97 | 97.54 ± 0.86 |
| AA% |
92.74 ± 1.14
|
90.9 ± 0.51
|
94.58 ± 0.58
|
93.69 ± 1.49
|
88.22 ± 0.52
|
87.58 ± 1.28
|
80.3 ± 0.55
|
79.64 ± 0.91
|
93.72 ± 1.07
|
93.29 ± 1.2
| 94.43 ± 0.68 | 96.49 ± 1.02 | 97.04 ± 1.75 | 98.76 ± 1.26 |
| 1 |
75.02 ± 0.6
|
85.34 ± 0.63
|
70 ± 0.86
|
70.76 ± 1.23
|
78.58 ± 0.75
|
77.47 ± 0.82
|
83.71 ± 1.64
|
82.91 ± 0.88
|
83.44 ± 1.27
|
85.34 ± 0.67
|
81.79 ± 1.64
| 81.84 ± 1.28 |
86.62 ± 0.85
| 89.03 ± 1.16 |
| 2 |
87.64 ± 0.9
|
81.21 ± 0.8
|
87.84 ± 1.36
|
79.67 ± 1.24
|
88.59 ± 1.42
|
76.48 ± 1.06
|
74.88 ± 1.48
|
89.33 ± 1.62
|
75.73 ± 0.75
|
86.71 ± 0.75
|
89.44 ± 1.4
| 84.93 ± 1.23 |
89.92 ± 1.16
| 85.21 ± 0.6 |
| 3 |
86.61 ± 1.07
|
61.58 ± 0.53
|
73.73 ± 1.79
|
78.22 ± 0.85
|
77.33 ± 0.89
|
74.54 ± 0.61
|
74.74 ± 1.69
|
73.55 ± 1.67
|
64.18 ± 1.55
|
66.93 ± 1.15
|
84.78 ± 0.88
| 91.84 ± 1.05 |
81.71 ± 1.31
| 93.84 ± 0.99 |
| 4 |
85.15 ± 1.21
|
74.86 ± 1.06
|
77.1 ± 0.81
|
72.85 ± 0.97
|
80.7 ± 1.79
|
72.91 ± 0.97
|
78.88 ± 1.46
|
69.18 ± 1.32
|
64.54 ± 1.06
|
68.03 ± 0.61
|
80.38 ± 1.05
| 89.28 ± 1.42 |
91.28 ± 1.14
| 90.72 ± 1.47 |
| 5 |
88.68 ± 0.64
|
78.32 ± 1.45
|
71.14 ± 0.78
|
86.85 ± 1.09
|
76.16 ± 1.3
|
75.6 ± 1.27
|
81.52 ± 1.1
|
71.46 ± 0.62
|
70.42 ± 1.5
|
77.97 ± 0.91
|
93.61 ± 1.6
| 96.42 ± 0.53 |
80.29 ± 0.86
| 97.28 ± 0.91 |
| 6 |
67.76 ± 0.68
|
85.73 ± 1.7
|
67.63 ± 0.64
|
66.76 ± 1.3
|
67.79 ± 1.26
|
82.71 ± 1.61
|
72.97 ± 0.56
|
61.6 ± 1.13
|
65.71 ± 1.28
|
78.18 ± 0.96
|
81.44 ± 0.57
| 81.9 ± 1.64 |
83.53 ± 1.65
| 91.62 ± 0.58 |
| 7 |
70.52 ± 0.64
|
87.88 ± 0.96
|
87.19 ± 1.06
|
87.35 ± 1.44
|
70.12 ± 1.51
|
71.26 ± 1.2
|
65.63 ± 0.67
|
69.4 ± 1.73
|
77.13 ± 1.41
|
63.05 ± 1.09
|
84.65 ± 1.77
| 95.68 ± 0.95 |
93.29 ± 1.64
| 97.99 ± 1.4 |
| 8 |
72.33 ± 1.51
|
81.82 ± 1.57
|
65.33 ± 1.18
|
68.23 ± 1.36
|
80.9 ± 0.84
|
81.85 ± 1.79
|
77.69 ± 0.97
|
74.91 ± 0.65
|
88.73 ± 1.26
|
62.85 ± 1.27
|
92.07 ± 0.61
| 94.41 ± 1.41 |
92.83 ± 1.28
| 95.1 ± 0.58 |
| 9 |
70.05 ± 1.65
|
81.16 ± 1.17
|
67.91 ± 1.23
|
64.45 ± 0.75
|
66.12 ± 1.31
|
86.87 ± 0.54
|
79.01 ± 1.44
|
79.3 ± 1.52
|
73.58 ± 1.48
|
61.35 ± 1.33
|
82.73 ± 0.62
| 95.23 ± 1.05 |
83.79 ± 1.03
| 91.94 ± 0.75 |
| 10 |
67 ± 0.76
|
68.4 ± 1.48
|
73.74 ± 0.82
|
76.29 ± 1.61
|
64.91 ± 1.35
|
71.54 ± 1.59
|
80.38 ± 0.71
|
72.54 ± 1.44
|
67.7 ± 0.65
|
69.05 ± 0.68
|
81.22 ± 1.13
| 87.14 ± 0.55 |
89.19 ± 1.13
| 96.98 ± 1.02 |
| 11 |
85.2 ± 1.32
|
70.24 ± 1.14
|
87.28 ± 0.66
|
70.45 ± 0.55
|
83.1 ± 1.58
|
73.6 ± 1.52
|
75.98 ± 0.68
|
69.98 ± 0.9
|
69.31 ± 1.09
|
67.29 ± 1.07
|
87.4 ± 1.24
| 84.85 ± 0.98 |
87.16 ± 1.42
| 97.69 ± 0.71 |
| 12 |
70.52 ± 1
|
70.1 ± 1.15
|
88.87 ± 1.01
|
76.04 ± 1.72
|
67.41 ± 1.15
|
79.92 ± 0.65
|
86.39 ± 0.83
|
64.11 ± 0.7
|
68.31 ± 1.65
|
73.93 ± 1.2
|
80.99 ± 1.43
| 88.93 ± 1.76 |
86.88 ± 1.74
| 93.81 ± 1.55 |
| 13 |
74.11 ± 1.28
|
62.79 ± 1.22
|
73.3 ± 1.78
|
77.29 ± 1.55
|
87.38 ± 0.87
|
84.37 ± 1.06
|
75.51 ± 0.89
|
68.84 ± 0.69
|
61.35 ± 1.45
|
82.06 ± 1.42
|
83.12 ± 1.76
| 92.71 ± 1.52 |
91.79 ± 0.97
| 93.32 ± 1.19 |
| 14 |
84.85 ± 0.83
|
85.54 ± 0.5
|
72.83 ± 1.31
|
82.14 ± 1.08
|
80.2 ± 1.72
|
78.27 ± 1.02
|
71.27 ± 0.5
|
71.72 ± 0.75
|
83.75 ± 1.47
|
70.86 ± 0.9
|
83.79 ± 1.42
| 94.58 ± 1.23 |
85.15 ± 1.5
| 90.99 ± 1.64 |
| 15 |
64.09 ± 1.68
|
71.61 ± 1.15
|
71.44 ± 1.76
|
65.77 ± 0.95
|
85.54 ± 0.83
|
74.95 ± 1.37
|
68.82 ± 0.59
|
67.76 ± 0.68
|
61.78 ± 0.88
|
85.55 ± 1.33
|
84.83 ± 0.58
| 91.29 ± 1.59 |
83.53 ± 1.14
| 81.69 ± 0.61 |
| 16 |
83.6 ± 1.56
|
76.39 ± 1.43
|
67.03 ± 1.17
|
86.53 ± 0.74
|
70.31 ± 1.08
|
66.31 ± 1.26
|
69.77 ± 0.56
|
78.1 ± 0.97
|
66.85 ± 1.45
|
76.16 ± 1.56
|
87.07 ± 1.7
| 85.13 ± 1.43 |
87.8 ± 1.17
| 86.68 ± 1.04 |
Table 12.
The result in terms of classification accuracies (%) for the SV dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 12.51 and 50% of testing samples.
Table 12.
The result in terms of classification accuracies (%) for the SV dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 12.51 and 50% of testing samples.
T-50%
Classifier | RF | RoF | Bagging | AdaBoost | XGBoost | DgcForest | ADA-Es-gcForest |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| OA% |
86.79 ± 0.99
|
85.73 ± 1.52
|
90.89 ± 1.07
|
88.54 ± 1.04
|
83.66 ± 1.85
|
82.93 ± 2.22
|
75.2 ± 2.03
|
74.28 ± 1.62
|
87.16 ± 2.39
|
85.49 ± 1.12
| 92.28 ± 1.21 | 93.99 ± 1.47 | 92.58 ± 2.05 | 95.37 ± 1.34 |
| AA% |
88.51 ± 1.75
|
87.59 ± 1.6
|
92.01 ± 2.12
|
90.54 ± 1.05
|
86.91 ± 0.97
|
85.55 ± 2.32
|
78.59 ± 2.13
|
77.76 ± 1.06
|
89.8 ± 1.38
|
88.22 ± 1.31
| 93.52 ± 1.11 | 95.35 ± 2.39 | 94.69 ± 1.8 | 96.79 ± 2.09 |
| 1 |
71.91 ± 1.55
|
63.76 ± 1.6
|
77.07 ± 0.93
|
88.48 ± 2.29
|
81.56 ± 1.98
|
86.11 ± 1.08
|
79.51 ± 2.24
|
70.91 ± 1.3
|
62.48 ± 1.6
|
63.33 ± 1.45
|
91.68 ± 1.09
|
80.98 ± 1.98
|
80.99 ± 1.95
|
80.63 ± 1.53
|
| 2 |
62.02 ± 1.86
|
78.12 ± 1.7
|
85.19 ± 1.11
|
79.83 ± 1.58
|
64.73 ± 1.35
|
80.98 ± 0.95
|
73.34 ± 0.9
|
86.2 ± 1.44
|
88.72 ± 1.73
|
62.35 ± 1.56
|
87.39 ± 2.35
|
89.48 ± 1.7
|
85.22 ± 1.28
|
86.43 ± 1.44
|
| 3 |
75.66 ± 1
|
86.2 ± 2
|
80.87 ± 1.3
|
73.85 ± 2.22
|
61.67 ± 2.33
|
67.04 ± 1.68
|
66.21 ± 1.18
|
67.01 ± 1.03
|
64.04 ± 1.21
|
87.93 ± 1.57
|
85.12 ± 0.91
|
81.56 ± 2.35
|
91.82 ± 2.37
|
82.26 ± 2.05
|
| 4 |
87.71 ± 2.05
|
71.04 ± 1.86
|
81.03 ± 1.02
|
70.89 ± 1.59
|
82.15 ± 1.22
|
63.83 ± 2.13
|
73.08 ± 1.7
|
84.11 ± 1.87
|
74.83 ± 1.74
|
83.15 ± 1.41
|
84.32 ± 1.86
|
80.27 ± 1.95
|
80.17 ± 2.16
|
87.49 ± 1.97
|
| 5 |
86.67 ± 0.96
|
73.03 ± 1.52
|
67.9 ± 1.52
|
71.99 ± 1.2
|
66.32 ± 1.74
|
68.28 ± 1.83
|
77.12 ± 1.28
|
67.59 ± 1.72
|
85.95 ± 1.75
|
87.15 ± 1.77
|
91.93 ± 1.42
|
84.01 ± 2.2
|
81.37 ± 1.59
|
80.06 ± 2.05
|
| 6 |
88.62 ± 1.06
|
74.42 ± 2.25
|
62.4 ± 1.75
|
75.62 ± 2.13
|
72.88 ± 1.44
|
84.87 ± 2.31
|
72.34 ± 1.75
|
81.49 ± 2.07
|
83.57 ± 2.03
|
85.39 ± 2.37
|
90.41 ± 1.07
|
91.3 ± 1.65
|
89.31 ± 1.23
|
89.02 ± 1.81
|
| 7 |
77.62 ± 1.33
|
61.76 ± 1.42
|
62.36 ± 1.44
|
77.76 ± 1.7
|
79.6 ± 1.72
|
79.17 ± 1.19
|
71.9 ± 2.17
|
72.48 ± 1.26
|
64.81 ± 1.87
|
82.25 ± 1.74
|
81.16 ± 2.21
|
86.8 ± 2.21
|
87.84 ± 2.01
|
92.56 ± 1.3
|
| 8 |
62.56 ± 2.14
|
76.78 ± 1.94
|
71.59 ± 2.15
|
82.35 ± 1.54
|
70.98 ± 0.93
|
75.06 ± 2.38
|
81.48 ± 1.44
|
69.2 ± 1.16
|
68.72 ± 1.99
|
61.99 ± 1.01
|
87.31 ± 1.3
|
82.58 ± 2.35
|
89.49 ± 1.11
|
92.74 ± 1.38
|
| 9 |
64.8 ± 2.04
|
61.09 ± 1.03
|
70.5 ± 2.18
|
78.52 ± 1.55
|
82.18 ± 2.14
|
84.9 ± 2.24
|
64.62 ± 1.45
|
85.58 ± 2.09
|
86.42 ± 1.27
|
83.72 ± 1
|
88.44 ± 1.23
|
84.61 ± 1.41
|
83.82 ± 1.8
|
85.34 ± 2.02
|
| 10 |
82.52 ± 1.16
|
61.82 ± 1.67
|
72.71 ± 2.29
|
88.64 ± 1.37
|
82.8 ± 2.24
|
65.52 ± 1.02
|
88.26 ± 1.85
|
66.77 ± 1.65
|
82.45 ± 1.97
|
65.49 ± 1.63
|
88.25 ± 1.94
|
86.64 ± 1.62
|
83.76 ± 1.93
|
87.9 ± 0.95
|
| 11 |
65.8 ± 2.3
|
61.67 ± 2.27
|
79.94 ± 1.49
|
71.12 ± 1.83
|
65.18 ± 2
|
68.92 ± 1.97
|
66.61 ± 2.06
|
80.3 ± 2.17
|
82.41 ± 2.01
|
88.38 ± 1.88
|
85.41 ± 0.95
|
81.46 ± 1.19
|
83.95 ± 1.69
|
81.06 ± 1.47
|
| 12 |
67.87 ± 1.97
|
69.98 ± 1.36
|
68.66 ± 1.66
|
73.34 ± 1.88
|
72.03 ± 1.57
|
80.06 ± 1.75
|
79.57 ± 1.98
|
87.48 ± 1.19
|
74.44 ± 1.92
|
84.07 ± 1.77
|
89.66 ± 1.59
|
83.93 ± 2.35
|
83.87 ± 2.13
|
80.78 ± 1.75
|
| 13 |
61.25 ± 1.26
|
78.21 ± 0.99
|
65.1 ± 2.08
|
72.82 ± 1.02
|
79.36 ± 1.11
|
71.14 ± 1.26
|
79.91 ± 1.69
|
70.17 ± 2.26
|
66.09 ± 1.9
|
84.05 ± 1.91
|
85.2 ± 1.65
|
91.68 ± 1.68
|
87.82 ± 1.38
|
81.51 ± 1.41
|
| 14 |
62.68 ± 1.51
|
65.42 ± 2.04
|
65.08 ± 1.48
|
69.37 ± 1.95
|
69.76 ± 1.88
|
77.39 ± 2.09
|
74.13 ± 1.56
|
69.25 ± 1.59
|
71.17 ± 1.31
|
84.27 ± 1.97
|
90.32 ± 1.6
|
85.68 ± 2.1
|
90.65 ± 2.04
|
83.92 ± 1.47
|
| 15 |
79.56 ± 1.1
|
78.49 ± 1.97
|
78.63 ± 0.95
|
69.13 ± 1.68
|
64.24 ± 2.34
|
66.49 ± 1.14
|
66.75 ± 1.7
|
69.43 ± 2.23
|
65.77 ± 1.11
|
73.53 ± 2.31
|
86.28 ± 1.66
|
90.65 ± 1.1
|
87.21 ± 0.96
|
92.84 ± 1.18
|
Table 13.
The result in terms of classification accuracies (%) for the SV dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 12.51 and 60% of testing samples.
Table 13.
The result in terms of classification accuracies (%) for the SV dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 12.51 and 60% of testing samples.
T-60%
Classifier | RF | RoF | Bagging | AdaBoost | XGBoost | DgcForest | ADA-Es-gcForest |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| OA% |
83.92 ± 2.03
|
83.71 ± 2.88
|
90.65 ± 3.02
|
87.78 ± 1.32
|
84.79 ± 1.28
|
80.93 ± 1.78
|
71.38 ± 2.14
|
67.77 ± 2.1
|
84.36 ± 3.03
|
83.54 ± 2.28
| 90.06 ± 1.32 | 91.93 ± 1.9 | 91.58 ± 1.7 | 93.18 ± 2.34 |
| AA% |
85.71 ± 1.44
|
85.08 ± 2.82
|
91.27 ± 2.33
|
89.69 ± 1.43
|
86.29 ± 2.07
|
84.28 ± 1.7
|
75.41 ± 1.88
|
72.92 ± 2.32
|
86.01 ± 1.79
|
85.39 ± 1.55
| 91.22 ± 1.82 | 93.04 ± 1.41 | 92.69 ± 1.63 | 94.89 ± 2.53 |
| 1 |
64.6 ± 1.51
|
87.76 ± 1.42
|
78.3 ± 1.28
|
85.32 ± 1.98
|
88.27 ± 1.57
|
85.58 ± 2.4
|
72.6 ± 1.93
|
75.29 ± 1.7
|
77.89 ± 2.23
|
68.14 ± 2.98
|
80.05 ± 2.78
|
83.22 ± 1.25
|
88.24 ± 2.62
|
86.11 ± 1.21
|
| 2 |
81.54 ± 2.85
|
65.17 ± 2.31
|
66.76 ± 2.86
|
88.49 ± 1.85
|
77.57 ± 1.55
|
65.67 ± 1.21
|
75.26 ± 1.19
|
71.55 ± 2.7
|
67.81 ± 2.09
|
72.98 ± 2.46
|
81.82 ± 1.19
|
79.21 ± 2.53
|
82.8 ± 1.23
|
78.72 ± 2.27
|
| 3 |
80.47 ± 1.32
|
67.05 ± 1.3
|
81.15 ± 1.47
|
81.44 ± 2.95
|
79.43 ± 2.15
|
75.32 ± 3.07
|
72.4 ± 2.01
|
81.29 ± 2.19
|
74.44 ± 2.7
|
63.41 ± 2.37
|
77.24 ± 1.81
|
76.19 ± 1.69
|
83.88 ± 1.42
|
80.79 ± 1.27
|
| 4 |
80.96 ± 2.37
|
78.11 ± 2.65
|
81.4 ± 2.16
|
63.28 ± 1.16
|
82.57 ± 1.98
|
88 ± 1.68
|
61.05 ± 3.02
|
68.18 ± 2.29
|
63.21 ± 2.43
|
63.93 ± 1.34
|
85.23 ± 1.82
|
77.93 ± 1.41
|
85.83 ± 1.21
|
80.47 ± 1.49
|
| 5 |
83.57 ± 2.85
|
79.63 ± 1.41
|
70.4 ± 2.23
|
67.27 ± 1.3
|
63.95 ± 3.08
|
81.24 ± 2.62
|
87.43 ± 1.57
|
63.82 ± 2.08
|
79.1 ± 2.83
|
79.64 ± 2.09
|
83.58 ± 2.74
|
76.6 ± 1.3
|
86.96 ± 2
|
88.1 ± 3.08
|
| 6 |
70.27 ± 2.94
|
79.36 ± 1.16
|
64.24 ± 2.79
|
82.09 ± 1.67
|
62.85 ± 1.38
|
70.72 ± 1.72
|
84.11 ± 2.45
|
64.37 ± 2.66
|
81.74 ± 1.25
|
63.9 ± 2.67
|
76.33 ± 1.34
|
77.59 ± 2.2
|
81.97 ± 2.06
|
83.77 ± 2.84
|
| 7 |
72.58 ± 2.98
|
61.26 ± 1.55
|
78.45 ± 2.92
|
69.65 ± 2.33
|
68.86 ± 2.55
|
78.14 ± 2.24
|
84.8 ± 1.23
|
87 ± 2.03
|
63.4 ± 3.08
|
85.05 ± 1.33
|
75.24 ± 1.94
|
86.87 ± 3.03
|
79.4 ± 2.3
|
83.64 ± 2.59
|
| 8 |
80.74 ± 3.1
|
68.5 ± 1.58
|
86.07 ± 1.86
|
87.92 ± 2.4
|
62.62 ± 2.13
|
78.17 ± 2.95
|
75.23 ± 2.25
|
87.34 ± 2.85
|
85.72 ± 2.43
|
84.71 ± 1.36
|
86.65 ± 2.55
|
87.19 ± 1.32
|
82.14 ± 1.86
|
83.76 ± 1.44
|
| 9 |
84.77 ± 1.69
|
68.26 ± 2.57
|
67.03 ± 1.42
|
65.95 ± 2.17
|
63.41 ± 2.72
|
83.58 ± 2.76
|
64.65 ± 1.67
|
62 ± 1.63
|
74.88 ± 1.19
|
72.89 ± 2.35
|
77.65 ± 2.64
|
83.03 ± 1.62
|
80.28 ± 2.9
|
79.64 ± 1.58
|
| 10 |
75.59 ± 2.63
|
75.06 ± 1.11
|
66.77 ± 1.47
|
82.84 ± 1.13
|
80.34 ± 2.95
|
65.06 ± 1.66
|
68.17 ± 1.3
|
64.67 ± 1.88
|
77.38 ± 1.56
|
87.61 ± 1.7
|
76.29 ± 2.89
|
87.72 ± 2.4
|
83.88 ± 1.95
|
86.86 ± 1.65
|
| 11 |
84.64 ± 2.2
|
80.44 ± 1.41
|
72.25 ± 1.78
|
71.01 ± 2.44
|
72.79 ± 2.4
|
65.61 ± 1.96
|
88.14 ± 2.59
|
82.41 ± 1.35
|
61.7 ± 1.56
|
85.44 ± 1.32
|
89.71 ± 2.16
|
77.46 ± 2.28
|
76.8 ± 3.07
|
83.98 ± 2.46
|
| 12 |
75.65 ± 2.07
|
65.5 ± 1.25
|
61.78 ± 2.04
|
75.25 ± 1.12
|
62.52 ± 1.47
|
76.15 ± 1.87
|
79.65 ± 2.68
|
61.03 ± 1.74
|
70.04 ± 1.92
|
77.54 ± 2.22
|
86.22 ± 2.86
|
84.9 ± 2.13
|
75.99 ± 1.57
|
78.46 ± 1.54
|
| 13 |
66.78 ± 2.81
|
71.4 ± 1.16
|
64.89 ± 3.03
|
86.46 ± 2.87
|
61.42 ± 2.69
|
61.8 ± 1.72
|
62.96 ± 2.57
|
87.97 ± 1.67
|
73.65 ± 1.94
|
82.52 ± 1.65
|
84.04 ± 2
|
84.08 ± 2.6
|
85.95 ± 1.18
|
76.93 ± 1.99
|
| 14 |
71.12 ± 1.34
|
66.88 ± 2.69
|
66.18 ± 2.93
|
75.78 ± 2.25
|
82.32 ± 1.63
|
77.96 ± 2.23
|
81.97 ± 2.25
|
88.26 ± 2.73
|
84.33 ± 2.52
|
85.91 ± 2.22
|
86.96 ± 2.65
|
87.76 ± 1.52
|
79.6 ± 1.96
|
89.27 ± 2.29
|
| 15 |
79.92 ± 3.05
|
76.27 ± 1.94
|
72.17 ± 2.32
|
87.32 ± 2.74
|
64.3 ± 2.67
|
69.49 ± 2.99
|
77.44 ± 1.72
|
72.96 ± 1.44
|
84.39 ± 2.9
|
87.9 ± 2.92
|
88.09 ± 1.72
|
84.98 ± 1.58
|
82.58 ± 1.86
|
87.89 ± 1.87
|
| 16 |
76.22 ± 2.18
|
85.85 ± 1.17
|
63.57 ± 2.03
|
78.43 ± 1.45
|
84.72 ± 2.6
|
67.27 ± 2.52
|
75.3 ± 1.13
|
85.1 ± 2.91
|
71.54 ± 2.06
|
63.84 ± 2.87
|
89.34 ± 2.41
|
83.57 ± 1.86
|
84.87 ± 1.37
|
87.86 ± 2.82
|
Table 14.
The result in terms of classification accuracies (%) for the PU dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 19.83 and 40% of testing samples.
Table 14.
The result in terms of classification accuracies (%) for the PU dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 19.83 and 40% of testing samples.
T-40%
Classifier | RF | RoF | Bagging | AdaBoost | XGBoost | DgcForest | ADA-Es-gcForest |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| OA% | 85.78 ± 0.55 | 85.38 ± 0.88 | 88.26 ± 0.74 | 87.74 ± 1.48 | 82.95 ± 0.5 | 92.91 ± 0.69 | 77.26 ± 0.64 | 76.12 ± 0.77 | 86.76 ± 1.73 | 86.58 ± 1.1 | 89.91 ± 0.74 | 90.29 ± 0.54 | 91.4 ± 1.07 | 92.91 ± 0.69 |
| AA% | 88.23 ± 1.32 | 88.18 ± 1.29 | 90.72 ± 1.09 | 90.55 ± 0.52 | 84.56 ± 1.15 | 94.19 ± 1.55 | 81.53 ± 0.79 | 81.45 ± 1.54 | 89.23 ± 0.83 | 88.95 ± 0.98 | 92.32 ± 1.6 | 91.38 ± 1.44 | 92.19 ± 1.45 | 94.19 ± 1.55 |
| 1 | 70.42 ± 0.75 | 71.58 ± 1.28 | 78.44 ± 1.38 | 77.44 ± 0.62 | 68.47 ± 1.67 | 83.11 ± 1.26 | 43.85 ± 0.82 | 44.43 ± 1.36 | 67.24 ± 1.73 | 67.21 ± 1.42 | 86.75 ± 1.26 | 89.51 ± 0.6 |
87.23 ± 1.79
| 83.11 ± 1.26 |
| 2 | 79.67 ± 1.36 | 77.58 ± 0.63 | 82.73 ± 1.58 | 80.68 ± 1 | 76.45 ± 1.44 | 79.97 ± 1.03 | 52.66 ± 1.66 | 60.12 ± 1.54 | 72.95 ± 0.52 | 72.96 ± 1.34 | 85.38 ± 1.52 | 86.01 ± 1.28 |
84.31 ± 0.53
| 79.97 ± 1.03 |
| 3 | 64.39 ± 1.5 | 64.52 ± 1.07 | 61.26 ± 0.68 | 65.5 ± 1.36 | 64.91 ± 0.51 | 77.45 ± 0.68 | 64.34 ± 1.43 | 55.79 ± 1.74 | 66.05 ± 1.02 | 65.78 ± 0.64 | 89.26 ± 0.76 | 89.99 ± 0.65 |
85.4 ± 1.52
| 77.45 ± 0.68 |
| 4 | 79.67 ± 1.45 | 79.8 ± 0.59 | 85.23 ± 1.07 | 82.55 ± 0.89 | 72.12 ± 1.3 | 85.61 ± 0.78 | 55.97 ± 1.06 | 52.34 ± 0.6 | 62.31 ± 1.24 | 61.25 ± 1.23 | 88.63 ± 0.78 | 91.34 ± 0.74 |
78.98 ± 1.78
| 85.61 ± 0.78 |
| 5 | 79.88 ± 1.1 | 80.01 ± 1.57 | 79.37 ± 0.81 | 81.67 ± 0.66 | 79.21 ± 1.03 | 77.29 ± 0.53 | 68.4 ± 0.8 | 61.68 ± 1.24 | 77.74 ± 1.45 | 79.04 ± 1.77 | 82.3 ± 1.09 | 89.65 ± 1.03 |
78.93 ± 1.77
| 77.29 ± 0.53 |
| 6 | 81.21 ± 1.13 | 81.34 ± 1.38 | 81.45 ± 1.77 | 82.52 ± 0.69 | 72.18 ± 0.93 | 77.74 ± 0.86 | 43.97 ± 0.58 | 47.37 ± 1.3 | 58.61 ± 1.4 | 59.87 ± 1.67 | 89.27 ± 0.61 | 91.49 ± 1.48 |
87.8 ± 1.33
| 77.74 ± 0.86 |
| 7 | 72.76 ± 0.85 | 72.89 ± 1.05 | 68.9 ± 0.8 | 63.49 ± 1.34 | 65.24 ± 0.77 | 85.04 ± 1.4 | 55.2 ± 1.55 | 60.3 ± 1.64 | 73.87 ± 1.36 | 74.53 ± 1.03 | 89.12 ± 0.77 | 90.27 ± 1.59 |
77.66 ± 0.63
| 85.04 ± 1.4 |
| 8 | 72.7 ± 1.15 | 72.84 ± 0.89 | 77.42 ± 0.92 | 78.33 ± 0.87 | 60.82 ± 1.73 | 81.13 ± 1.48 | 46.98 ± 0.56 | 50.43 ± 0.75 | 52.16 ± 1.75 | 54.89 ± 1.74 | 78.71 ± 0.65 | 80.08 ± 1.48 |
77.39 ± 0.56
| 81.13 ± 1.48 |
| 9 | 78.04 ± 1.66 | 38.17 ± 1.24 | 32.87 ± 1.23 | 31.8 ± 1.47 | 39.48 ± 0.56 | 40.77 ± 0.59 | 34.22 ± 1.13 | 34.12 ± 1.55 | 41.62 ± 1.23 | 43.9 ± 1.66 | 53.39 ± 1.7 | 54.08 ± 1.56 |
75.19 ± 1.73
| 90.77 ± 0.59 |
Table 15.
The result in terms of classification accuracies (%) for the PU dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 19.83 and 50% of testing samples.
Table 15.
The result in terms of classification accuracies (%) for the PU dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 19.83 and 50% of testing samples.
T-50%
Classifier | RF | RoF | Bagging | AdaBoost | XGBoost | DgcForest | ADA-Es-gcForest |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| OA% | 82.96 ± 1.39 | 82.43 ± 1.64 | 86.36 ± 1.28 | 86.1 ± 1.82 | 81.17 ± 1.65 | 80.05 ± 1.45 | 75.36 ± 2.24 | 74.17 ± 2.34 | 84.51 ± 2.19 | 84.12 ± 1.97 | 88.29 ± 1.4 | 90.27 ± 0.96 | 89.58 ± 2.28 | 91.85 ± 1.01 |
| AA% | 85.06 ± 1.86 | 84.92 ± 1.39 | 88.65 ± 2.27 | 88.13 ± 2.1 | 83.95 ± 2.01 | 82.73 ± 2.02 | 79.05 ± 1.19 | 78.34 ± 1.56 | 86.43 ± 1.27 | 86.09 ± 2.3 | 89.95 ± 2.06 | 91.43 ± 2.21 | 90.47 ± 1.38 | 92.92 ± 2.04 |
| 1 | 71.41 ± 1.83 | 71.47 ± 1.02 | 75.14 ± 1.8 | 78.32 ± 1.43 | 63.26 ± 1.56 | 69.58 ± 2.01 | 42.78 ± 1.73 | 44.76 ± 0.93 | 64.63 ± 1.37 | 68.81 ± 0.97 | 83.56 ± 1.13 | 84.21 ± 1.69 |
72.87 ± 2.22
|
82.62 ± 1.73
|
| 2 | 77.25 ± 1.51 | 77.91 ± 1.45 | 83.24 ± 1.26 | 85.31 ± 2.04 | 76.45 ± 2.3 | 78.17 ± 1.07 | 50.91 ± 1.91 | 57.39 ± 1.71 | 69.06 ± 1.21 | 67.22 ± 1.09 | 78.37 ± 1.04 | 81.04 ± 1.03 |
69.82 ± 1.89
|
69.12 ± 1.65
|
| 3 | 63.48 ± 1.78 | 63.48 ± 1.39 | 54.34 ± 1.12 | 69.23 ± 2.06 | 64.03 ± 0.91 | 64.42 ± 1.71 | 65.23 ± 1.38 | 55.34 ± 1.87 | 71.67 ± 1.37 | 65.76 ± 1.81 | 87.46 ± 1.91 | 87.45 ± 2.31 |
67.68 ± 1.79
|
84.02 ± 1.86
|
| 4 | 74.8 ± 2.32 | 74.8 ± 1.52 | 82.17 ± 1.12 | 81.74 ± 2.23 | 79.19 ± 1.46 | 71.23 ± 2.01 | 53.15 ± 1.83 | 50.29 ± 1.6 | 55.86 ± 1.2 | 60.22 ± 1.26 | 79.36 ± 1.03 | 76.5 ± 2.35 |
73.31 ± 1.9
|
77.95 ± 0.93
|
| 5 | 73.79 ± 0.97 | 74.58 ± 1.13 | 74.39 ± 1.02 | 75.39 ± 1.01 | 80.05 ± 2.2 | 78.34 ± 1.72 | 60.43 ± 1.22 | 62.18 ± 1.56 | 81.86 ± 1.22 | 80.86 ± 2.19 | 82.39 ± 1.1 | 82.39 ± 1.16 |
65.22 ± 1.68
|
66.86 ± 1.99
|
| 6 | 81.29 ± 2.03 | 84.29 ± 1.96 | 76.29 ± 1.23 | 79.49 ± 2.04 | 72.18 ± 2.35 | 70.51 ± 0.93 | 44.39 ± 2.08 | 43.69 ± 1.91 | 56.91 ± 0.9 | 59.99 ± 2.14 | 79.31 ± 1.7 | 88.56 ± 1.27 |
79.44 ± 1.36
|
73.76 ± 1.35
|
| 7 | 72.19 ± 1.63 | 71.56 ± 2.14 | 73.67 ± 1.3 | 71.4 ± 2.03 | 65.24 ± 2.26 | 63.67 ± 2.15 | 54.91 ± 1.01 | 58.34 ± 2.27 | 74.71 ± 0.99 | 87.45 ± 1.63 | 85.36 ± 1.21 | 85.31 ± 1.15 |
66.09 ± 2.34
|
69.12 ± 1.09
|
| 8 | 72.78 ± 1.27 | 72.79 ± 1.64 | 77.96 ± 0.99 | 76.39 ± 2.34 | 60.75 ± 1.44 | 65.43 ± 2.06 | 48.34 ± 1.98 | 47.2 ± 2.05 | 57.45 ± 1.98 | 53.12 ± 2.25 | 78.41 ± 1.43 | 78.32 ± 1.63 |
76.79 ± 2.06
|
66.51 ± 1.11
|
| 9 | 37.23 ± 1.93 | 37.33 ± 2.28 | 31.92 ± 2.22 | 30.52 ± 2.17 | 42.52 ± 1.74 | 34.74 ± 1.06 | 32.19 ± 2.33 | 32.18 ± 1.22 | 41.15 ± 1.82 | 39.98 ± 2.01 | 44.05 ± 1.04 | 45.3 ± 2.15 |
68.9 ± 1.65
|
69.49 ± 1.7
|
Table 16.
The result in terms of classification accuracies (%) for the PU dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 19.83 and 60% of testing samples.
Table 16.
The result in terms of classification accuracies (%) for the PU dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 19.83 and 60% of testing samples.
T-60%
Classifier | RF | RoF | Bagging | AdaBoost | XGBoost | DgcForest | ADA-Es-gcForest |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| OA% | 80.32 ± 1.67 | 79.22 ± 2.31 | 85.29 ± 2.99 | 84.91 ± 1.4 | 82.08 ± 2.96 | 81.99 ± 1.61 | 70.36 ± 1.9 | 68.37 ± 2.62 | 82.26 ± 2.45 | 81.34 ± 2.82 | 86.73 ± 2.89 | 88.86 ± 2.85 | 85.58 ± 1.13 | 89.47 ± 2.24 |
| AA% | 83.74 ± 2.46 | 82.45 ± 2.76 | 86.63 ± 2.92 | 86.1 ± 2.56 | 84.29 ± 2.14 | 83.15 ± 1.51 | 73.04 ± 2.97 | 71.36 ± 2.57 | 85.19 ± 2.3 | 84.79 ± 1.72 | 87.67 ± 1.76 | 89.29 ± 1.45 | 87.69 ± 2.92 | 90.44 ± 2.84 |
| 1 | 69.25 ± 1.61 | 69.87 ± 1.79 | 69.41 ± 2.13 | 74.35 ± 1.2 | 69.34 ± 1.99 | 66.72 ± 1.44 | 47.59 ± 1.99 | 45.85 ± 2.63 | 66.31 ± 1.46 | 66.71 ± 1.8 | 84.16 ± 1.73 | 81.2 ± 2.54 |
75.19 ± 2
|
74.1 ± 2.57
|
| 2 | 78.34 ± 1.54 | 76.56 ± 1.23 | 83.24 ± 1.28 | 85.31 ± 1.69 | 70.7 ± 1.35 | 75.67 ± 2.06 | 51.67 ± 2.61 | 58.97 ± 2.2 | 74.21 ± 2 | 71.5 ± 2.55 | 78.24 ± 1.63 | 84.39 ± 2.97 |
76.96 ± 1.13
|
70.22 ± 2.64
|
| 3 | 68.23 ± 1.41 | 68.21 ± 1.79 | 63.61 ± 2.69 | 65.23 ± 1.65 | 64.91 ± 2.35 | 67.34 ± 1.55 | 66.78 ± 2.46 | 56.98 ± 1.2 | 66.85 ± 2.76 | 68.7 ± 1.15 | 85.39 ± 2.63 | 89.41 ± 1.29 |
66.2 ± 3.05
|
62.52 ± 2.5
|
| 4 | 75.35 ± 2.75 | 75.92 ± 1.59 | 83.47 ± 1.39 | 84.39 ± 2.66 | 71.85 ± 2.78 | 71.25 ± 2.51 | 60.92 ± 1.81 | 49.26 ± 2.11 | 61.7 ± 2.87 | 62.19 ± 1.43 | 79.36 ± 2.76 | 87.35 ± 1.52 |
62.91 ± 2.6
|
79.62 ± 1.78
|
| 5 | 82.31 ± 1.17 | 81.69 ± 2.76 | 71.86 ± 2.08 | 75.88 ± 3.03 | 79.27 ± 2.53 | 79.1 ± 2.97 | 59.45 ± 1.94 | 61.89 ± 1.72 | 68.95 ± 2.78 | 64.87 ± 1.91 | 82.08 ± 1.35 | 81.97 ± 1.52 |
63.04 ± 1.73
|
78.7 ± 1.83
|
| 6 | 87.5 ± 2.62 | 87.5 ± 2.04 | 71.87 ± 1.98 | 77.49 ± 2.94 | 72.18 ± 1.68 | 85.02 ± 2.73 | 44.18 ± 3.09 | 49.24 ± 2.34 | 61.87 ± 2.96 | 61.93 ± 1.32 | 79.31 ± 1.42 | 82.32 ± 2.34 |
76.46 ± 1.54
|
77.87 ± 2.65
|
| 7 | 78.5 ± 2.34 | 75.26 ± 1.47 | 69.37 ± 2.96 | 62.58 ± 2.66 | 66.19 ± 2.16 | 73.34 ± 2.53 | 63.21 ± 1.56 | 59.78 ± 1.81 | 74.91 ± 2.89 | 74.97 ± 3 | 85.36 ± 1.83 | 89.54 ± 2.64 |
62.71 ± 2.66
|
71.14 ± 2.46
|
| 8 | 68.28 ± 1.58 | 68.87 ± 1.32 | 77.12 ± 2.17 | 79.43 ± 2.56 | 60.82 ± 1.49 | 61.09 ± 2.1 | 51.2 ± 2.97 | 49.34 ± 2.95 | 56.59 ± 1.77 | 54.51 ± 1.23 | 79.03 ± 2.33 | 73.48 ± 2.31 |
73.58 ± 2.93
|
71.16 ± 1.17
|
| 9 | 32.84 ± 1.23 | 31.35 ± 1.61 | 30.23 ± 1.15 | 29.86 ± 2.98 | 31.51 ± 2.03 | 31.8 ± 2.53 | 30.56 ± 1.32 | 29.75 ± 3.05 | 41.23 ± 1.38 | 44.72 ± 3.09 | 40.23 ± 2.41 | 45.39 ± 2.24 |
74.65 ± 2.62
|
68.37 ± 1.45
|
Table 17.
The total time elapsed (TTE in seconds) for the IP dataset for the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest training sets by taking 40%, 50%, and 60% respectively, of the original data as training sets.
Table 17.
The total time elapsed (TTE in seconds) for the IP dataset for the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest training sets by taking 40%, 50%, and 60% respectively, of the original data as training sets.
| Training Sample% | 40% | 50% | 60% |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| RF | 423.54 | 467.88 | 675.34 | 714.56 | 828.79 | 847.61 |
| RoF | 5155.34 | 5349.63 | 7183.4 | 7380.61 | 8873.61 | 9091.3 |
| Bagging | 2115.83 | 2256.9 | 3129.86 | 3462.53 | 4029.56 | 4310.08 |
| AdaBoost | 169.92 | 195.14 | 223.65 | 273.8 | 356.89 | 413.62 |
| XGBoost | 235.98 | 248.65 | 376.71 | 403.54 | 549.26 | 584.2 |
| DgcForest | 2167.83 | 2343.69 | 3542.37 | 3903.64 | 4730.78 | 5089.63 |
| ADA-Es-gcForest | 1645.79 | 1789.32 | 2376.41 | 2591.05 | 3689.67 | 3845.8 |
Table 18.
The total time elapsed (TTE in seconds) for the SV dataset for the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest training sets by taking 40%, 50%, and 60% respectively, of the original data as training sets.
Table 18.
The total time elapsed (TTE in seconds) for the SV dataset for the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest training sets by taking 40%, 50%, and 60% respectively, of the original data as training sets.
| Training Sample% | 40% | 50% | 60% |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| RF | 783.65 | 811.39 | 967.81 | 1045.63 | 1389.77 | 1549.64 |
| RoF | 7894.31 | 9067.43 | 13,258.78 | 15,329.06 | 19,555.39 | 21,898.64 |
| Bagging | 3185.88 | 3642.51 | 3942.85 | 4387.57 | 4492.63 | 5211.9 |
| AdaBoost | 238.55 | 297.18 | 403.59 | 497.33 | 584.6 | 629.52 |
| XGBoost | 345.28 | 395.42 | 455.8 | 501.29 | 633.42 | 723.06 |
| DgcForest | 4289.34 | 4562.67 | 5862.44 | 6098.38 | 7290.43 | 7578.9 |
| ADA-Es-gcForest | 3163.92 | 3343.86 | 4472.51 | 4732.11 | 5732.98 | 5922.69 |
Table 19.
The total time elapsed (TTE in seconds) for the PU dataset for the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest training sets by taking 40%, 50%, and 60% respectively, of the original data as training sets.
Table 19.
The total time elapsed (TTE in seconds) for the PU dataset for the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest training sets by taking 40%, 50%, and 60% respectively, of the original data as training sets.
| Training Sample% | 40% | 50% | 60% |
|---|
| Oversampler | SMOTE | ADASYN | SMOTE | ADASYN | SMOTE | ADASYN |
|---|
| RF | 948.26 | 957.68 | 1218.64 | 1250.98 | 1689.63 | 1805.44 |
| RoF | 11,673.67 | 12,539.90 | 14,673.81 | 16,341.11 | 20,341.56 | 23,145.67 |
| Bagging | 4075.62 | 4123.45 | 4823.71 | 4987.34 | 5407.59 | 5622.09 |
| AdaBoost | 389.11 | 394.27 | 515.34 | 598.21 | 697.25 | 766.74 |
| XGBoost | 420.05 | 461.85 | 512.89 | 598.05 | 779.92 | 863.74 |
| DgcForest | 5819.75 | 5893.12 | 6322.85 | 6349.10 | 7717.34 | 7933.89 |
| ADA-Es-gcForest | 4051.45 | 4204.2 | 4925.71 | 5199.07 | 6480.73 | 6628.48 |



 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}