1. Introduction
Multi-view stereo (MVS) is one of the essential tasks in computer vision. It has long been studied by many researchers and has been widely applied in autonomous driving [
1], virtual reality [
2], robotics, and 3D reconstruction [
3,
4]. MVS is also capable of reconstructing ground terrain using aerial photography systems (such as satellites and drones). The core of the multi-view stereo task is to use stereo correspondence from multiple images as the main cue to reconstruct dense 3D representations. Currently, the reconstruction of 3D scenes is mainly based on the depth map method. However, the depth map acquisition is primarily divided into two-view and multi-view scenarios. The two-view scenarios are mainly used to obtain the disparity of corresponding pixels in the rectified image pairs by matching two adjacent views, and then calculating the depth [
5]. However, obtaining the exact rectified image pairs for images with more varying viewpoints is difficult. In multi-view scenarios, multiple unrectified images can be used simultaneously, and depth estimation can be performed directly in depth space without the need to convert by calculating disparity. First, several hypothetical depth planes are proposed in the depth range. Then, the best depth plane is determined for each pixel by the dense correspondence between pixels of different views [
6].
In detail, many conventional MVS methods [
7,
8,
9,
10] have yielded impressive results. Although hand-crafted operators can achieve high accuracy, the completeness of the constructed point cloud is affected by low-texture regions, illumination changes, and reflections, which make these methods usually unable to achieve a satisfactory quality of reconstruction in practical use. Many industrial applications require efficient algorithms, such as the real-time reconstruction of ground details by high-altitude sensors, UAV obstacle avoidance, and automatic driving of cars. Therefore, dense reconstruction with fast inference speed and low GPU memory has broad application prospects.
Recently, the popular learning-based methods [
11,
12,
13,
14,
15,
16,
17] have significantly improved the overall reconstruction quality in challenging scenarios. MVSNet [
11] is the first method that introduced deep learning technology to depth-map-based MVS tasks [
18,
19,
20]. The subsequent learning-based MVS approaches emulate MVSNet [
11] by constructing a 3D cost volume, regularizing it with a 3D CNN, and regressing the depth. Since 3D CNNs usually consume considerable time and GPU memory, some methods [
21] downsample the input during feature extraction and compute the cost volume and depth map at low resolution. However, providing the depth map at low resolution may affect the accuracy since low-resolution depth maps lose much of the original information. Thus, the quality of the reconstructed point cloud is reduced.
To reduce memory consumption, some researchers have separated the memory requirements from the depth range and processed the cost volume sequentially at an additional runtime cost [
14,
22]. Apparently, increasing runtime for lower GPU memory consumption is not reasonable for efficient dense reconstruction. Another research direction [
12,
13] for the lightweight MVS method is to predict a high-resolution depth map from coarse to fine using a cascaded 3D cost volume. However, due to the limitation of 3D convolution, a satisfactory balance of overall reconstruction quality and computational complexity cannot be achieved. In summary, most learning-based MVS methods still experience high memory and computational costs when constructing and adjusting cost volumes, making it difficult to balance computational complexity and overall reconstruction quality.
To address the above problems, PatchmatchNet [
23] and IterMVS [
24] are proposed to solve the challenge of simultaneously maintaining low computational complexity and excellent overall quality. PatchmatchNet extends PatchMatch’s traditional propagation [
5] and cost evaluation steps with adaptive aggregation, which improves accuracy and efficiency. Although PatchmatchNet has made significant progress, the F-scores on the Tanks and Temples benchmark and real-world applications show that its generalization performance is limited. IterMVS [
24] retains PatchMatchNet’s initialization and uses the iterative structure of RAFT [
25] in optical flow estimation. IterMVS [
24] can achieve a better generalization performance while maintaining fast inference speed and low memory consumption and is the most advanced and efficient MVS method. However, these methods still have room for improvement.
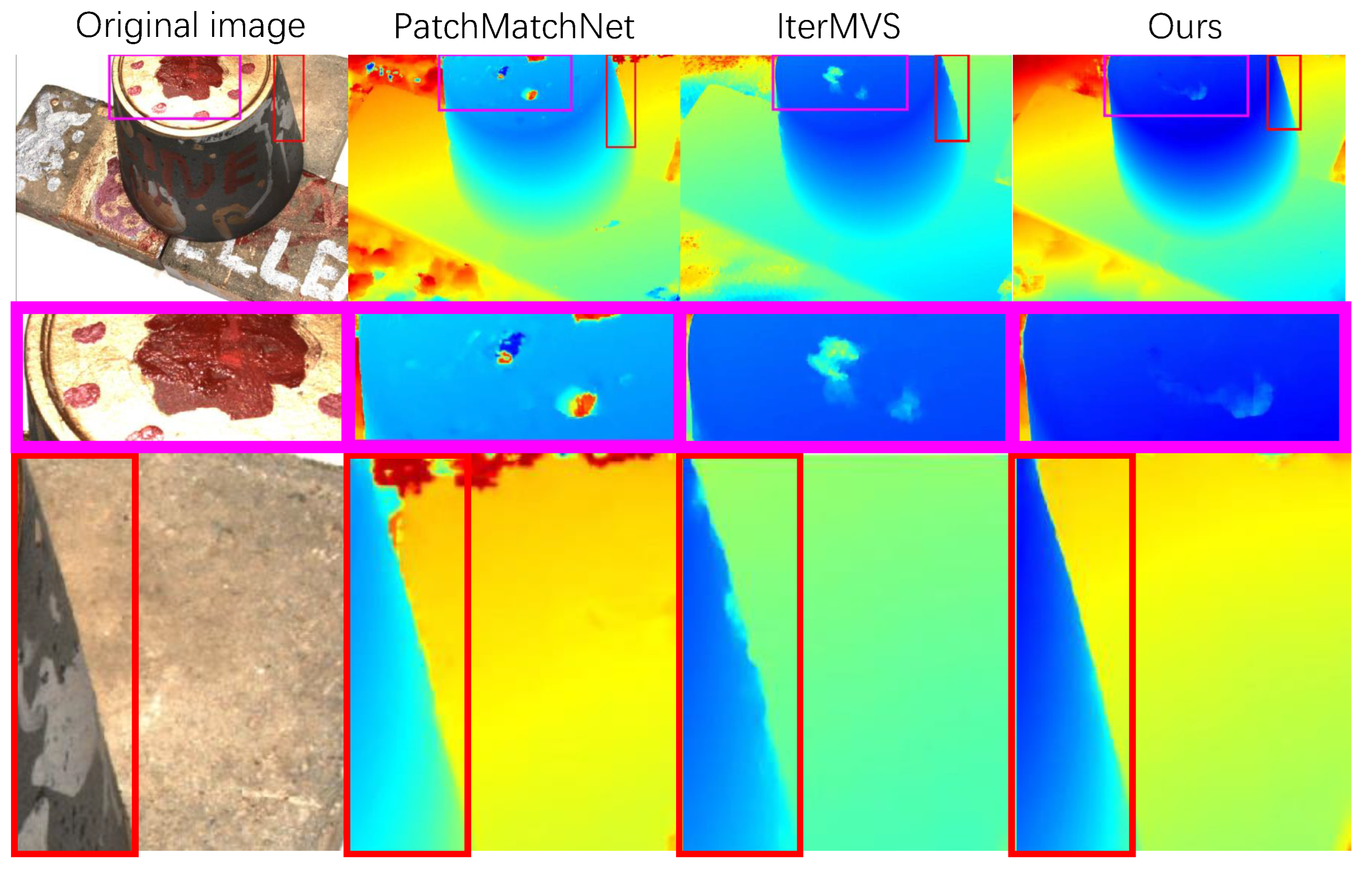
As shown in
Figure 1, the details of the scene reconstructed by the existing efficient methods in the complex environment are not sufficiently satisfactory. Specifically, there are three important issues that have been overlooked. First, most efficient methods [
23,
26] rely too much on attention mechanisms, resulting in limited generalization performance. Second, many efficient approaches [
21,
23,
24] only handle features at a single scale to lower the time complexity and space complexity. Thus, having only a small receptive field limits their ability to reconstruct details at weak and repetitive textures. Third, the efficient MVS methods [
23,
24] generate depth maps with unrefined target edges. When handling large-scale aerial images, this phenomenon is more obvious. The unrefined edges lead to more noise in the corresponding local point cloud, affecting the quality of the final reconstructed point cloud.
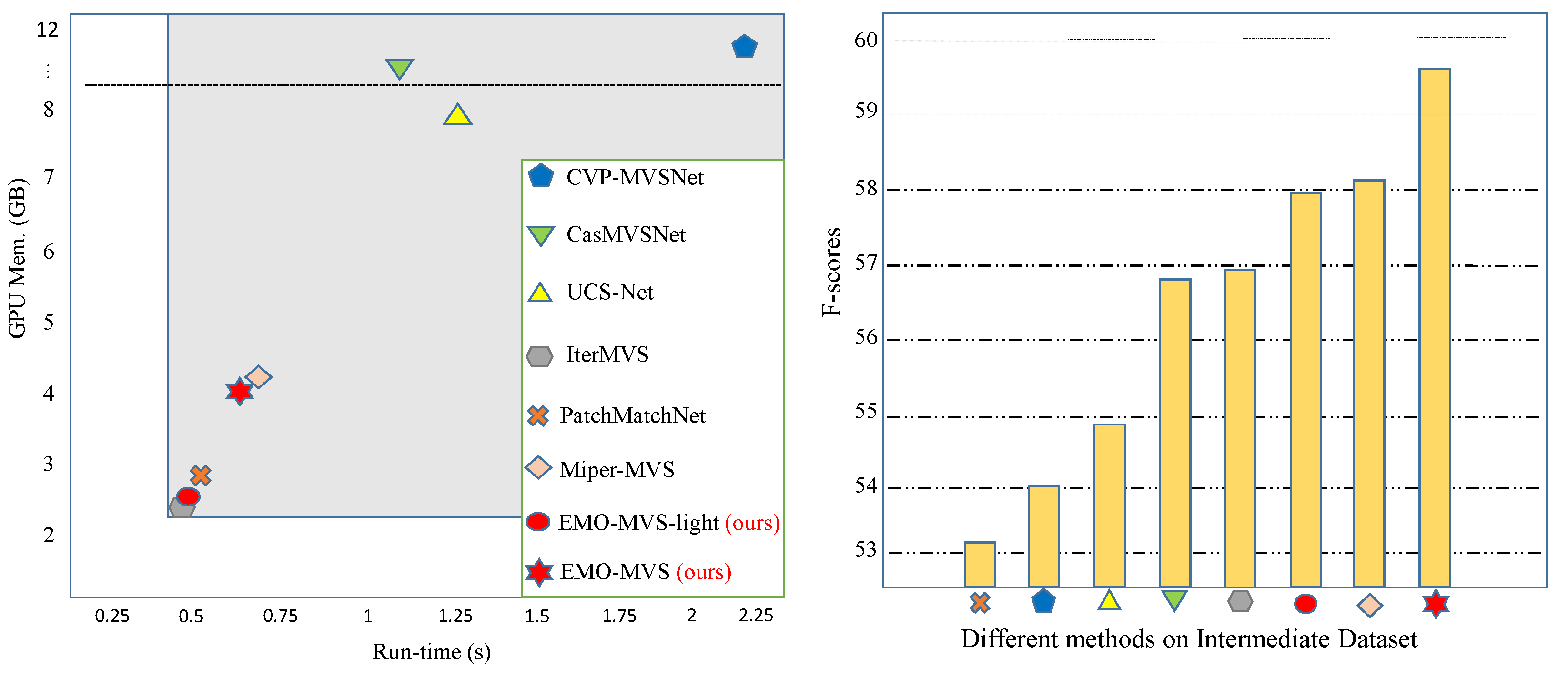
To address these three issues, we propose a high-efficiency multi-view stereo method named EMO-MVS that aims to significantly improve the generalization performance. Our comparison with current state-of-the-art methods is shown in
Figure 2. In detail, EMO-MVS mainly includes three core components. First, we propose an iterative variable optimizer with a modified Conv-LSTM module as the core structure and optimize only the correction amount of the depth information in each iteration. Such a design allows for a more accurate perception of the amount of change in the depth information during depth optimization, thus enriching the depth hierarchy. Updating only the amount of variation instead of directly updating the depth map also better avoids overfitting. Second, modifications to the multilevel absorption unit are implemented with the aim of fusing the multiscale information in a more efficient and satisfactory manner. The updated module permits the expansion of the receptive field, which allows the network to retain its efficiency attributes. Third, we propose an error-aware enhancement module. The initial depth map is obtained by the first and second parts above, and then we project the source images with the initial depth map and calculate the projection error. After that, we optimize the projection error to obtain the residual depth, and the initial depth plus the residual depth is the final depth map. The experimental results show that EMO-MVS significantly improves the generalization performance and is more efficient than most of the previous MVS methods.
In summary, the contributions of this paper include the following:
We propose a low-memory consumption, high-accuracy, and fast-inference-speed EMO-MVS framework for MVS tasks. The previous efficient MVS methods usually produce unrefined depth maps in large-scale aerial datasets, and EMO-MVS dramatically alleviates this problem.
Specifically, we propose three core modules, including an iterative variable estimator that optimizes the depth variation, a multilevel absorption unit for efficient fusion of multiscale information, and an error-aware module that enhances the initial depth map.
We validate our method’s effectiveness on the DTU and Tanks and Temples datasets. The results prove that our approach is the most competitive in terms of balancing performance and efficiency.
This paper is organized as follows.
Section 2 introduces the current research status.
Section 3 presents the proposed EMO-MVS model in detail.
Section 4 conducts the experimental results and corresponding analysis.
Section 5 summarizes our work.
3. Method
3.1. Overview
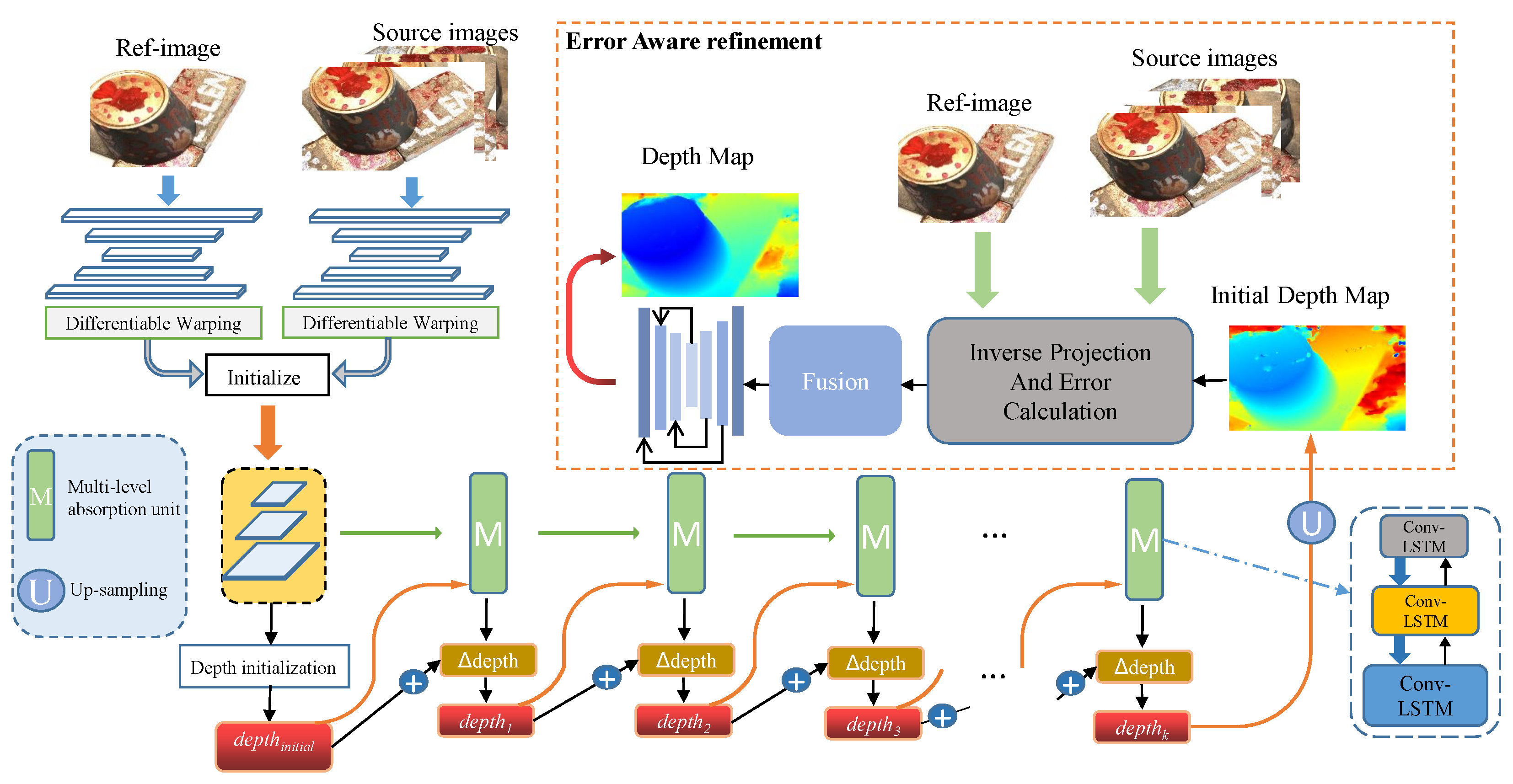
EMO-MVS estimates the depth maps from multiple overlapping RGB images. Specifically, our method accepts one reference image
and N-1 source images
as input and then obtains the depth map of the reference image. First, EMO-MVS constructs a correlation volume and an initial hidden state using the features extracted by FPN. Second, the above results are input into the first-order implicit optimizer at each iteration; this optimizer consists of our modified Conv-LSTM unit, which estimates information about the change in the depth values. In the first-order implicit optimizer, we also use a multilevel absorption unit to fuse the output states of the modified Conv-LSTM at three scales. After optimization, the initial depth map is obtained. Finally, the initial depth map is enhanced by optimizing the pixel error of the geometric projection transformation to obtain the final depth map. Our main structure is shown in
Figure 3.
3.2. Feature Extractor and Initialization
Feature Extractor: The FPN (Feature Pyramid Network) has been proven to have excellent feature extraction results in many visual tasks. Given N input images of size W × H, we adopt and to denote the reference image and the source images. Then, we adopt a feature pyramid network (FPN) for feature extraction of the input reference image and the source images. The feature extraction module generates feature maps at three scales , where , and the channel is , respectively.
Correlation Volume: To find the dense correspondence between different views, we use the extracted features for de-homogenization [
11], following most learning-based MVS methods, we warp the source features into front-to-parallel planes. Specifically, for a pixel
p in the reference view and the
j-th depth hypothesis,
:=
with known intrinsic
and relative transformations
between reference view 0 and source view i, we can compute the corresponding pixel
:=
in the source view as:
After de-homogenization, we obtain the feature
of the source image in the reference image coordinate frame, and we use
and
(which are features of the reference image) to calculate the correlation volume and matching similarity [
23,
24].
Initialization: To initialize the hidden state h of Conv-LSTM, before the iterative update, we use the previously-obtained matching similarity and correlation volume to generate the initial hidden state H and
[
23,
24], which are the inputs to the iterative variable optimizer.
3.3. Iterative Variable Optimizer
In other related fields that utilize 3D vision, iterative structures have proven to be quite effective methods [
25,
41], and most approaches use the GRU as their iterative update unit. However, in our research, Conv-LSTM cells with a finer gate structure have better performance. The GRU-based optimizer has only one hidden state
h transfer between iterations, while the LSTM-based optimizer has two (
h and
C). Since the updated matrix of the depth map is coupled with the hidden state
h, introducing an extra hidden state
C to decouple the update matrix and the hidden state
h can retain more effective semantic information across iterations.
To obtain a strong Conv-LSTM cell, our main improvements to the current Conv-LSTM are as follows: (1) We use a fusion head to simultaneously receive multiscale or single-scale information as needed. This approach allows us to use multiscale information more flexibly when passing through the subsequent multilevel absorbing units. (2) We use dilated convolutions instead of regular convolutions to obtain a larger receptive field, which helps recover challenging details. (3) By removing the bias from the original Conv-LSTM, we avoid redundant computation. Our modified Conv-LSTM is also comparable to the GRU in terms of efficiency.
In detail, we input the initialized hidden state H into our modified Conv-LSTM module, and our Conv-LSTM is as follows:
where
is the sigmoid nonlinearity, and ⊙ is the Hadamard product. The subscript
denotes the index of iterations,
and
are the outputs of the
iteration of our Conv-LSTM module, and the correlation volume and the matching similarity are integrated to obtain
. To simultaneously receive single-scale or multiscale information, we aggregate the input information as follows:
.
In addition, each update of our Conv-LSTM hidden state only contains information about the depth change amount rather than the entire depth map. This design avoids the overfitting that may occur as the number of iterations increases. Our final hidden state
for depth prediction at each iteration is calculated as follows:
We utilize the output
of the iterative variable optimizer for probability regression and depth prediction [
24] to obtain the depth map
of the
k-th iteration.
3.4. Multi-Level Absorption Unit
To achieve low memory consumption and high efficiency, some efficient approaches, such as [
24,
26], often only incorporate feature information from single-scale processing for subsequent depth estimation. A broader receptive field in the MVS task enables the network to deliver more precise depth estimations in areas with poor texture details. The most direct way to expand the receptive field is to use a multiscale fusion strategy. Nonetheless, multiscale strategies usually incur high computational costs, which affect inference speed and memory usage more significantly. Accordingly, we design an accurate and efficient multilevel absorption unit (MAU) that expands the receptive field by interactively absorbing low-scale information through a high-scale Conv-LSTM. MAU effectively balances accuracy, speed, and memory usage.
Specifically, we downsample the initialized hidden states to obtain the medium-scale and low-scale hidden states. We also widen our iterative structure to handle the other two scales of hidden states. In the update stage of multiscale information, the lowest resolution modified Conv-LSTM units are fused across scales by introducing features of medium resolution. These medium-resolution modified Conv-LSTM units are fused by introducing features of low and high resolution, and the highest-resolution units are fused by introducing features of both medium and low resolution.
The multiscale fusion mechanism is as the following formulas:
where
l,
m, and
h denote low, middle, and high resolution, respectively.
is our modified Conv-LSTM module, and
and
denote the downsampling and upsampling methods, respectively.
k is the number of iterations, and
is the integration of the correlation volume and matching similarity. The input to each iteration of our process uses the output of the previous iteration. For the highest resolution, the module not only makes use of upsampled middle and low resolution but also accepts the depth map of the
iteration as input.
A multilevel absorption unit (MAU) can effectively fuse information from multiple scales due to the cross-pollination of information between hidden states at multiple scales, and most of the low- and middle-scale information is absorbed by the high-scale hidden states. On the one hand, since we only output the highest-scale information at the end, the inference speed and memory usage is almost the same as that when using only single-scale information. On the other hand, since we avoid the computational cost of multiscale information fusion for the final output, our computational cost is smaller than that of the common multiscale fusion method. Therefore, our method is faster than the common multiscale update module.
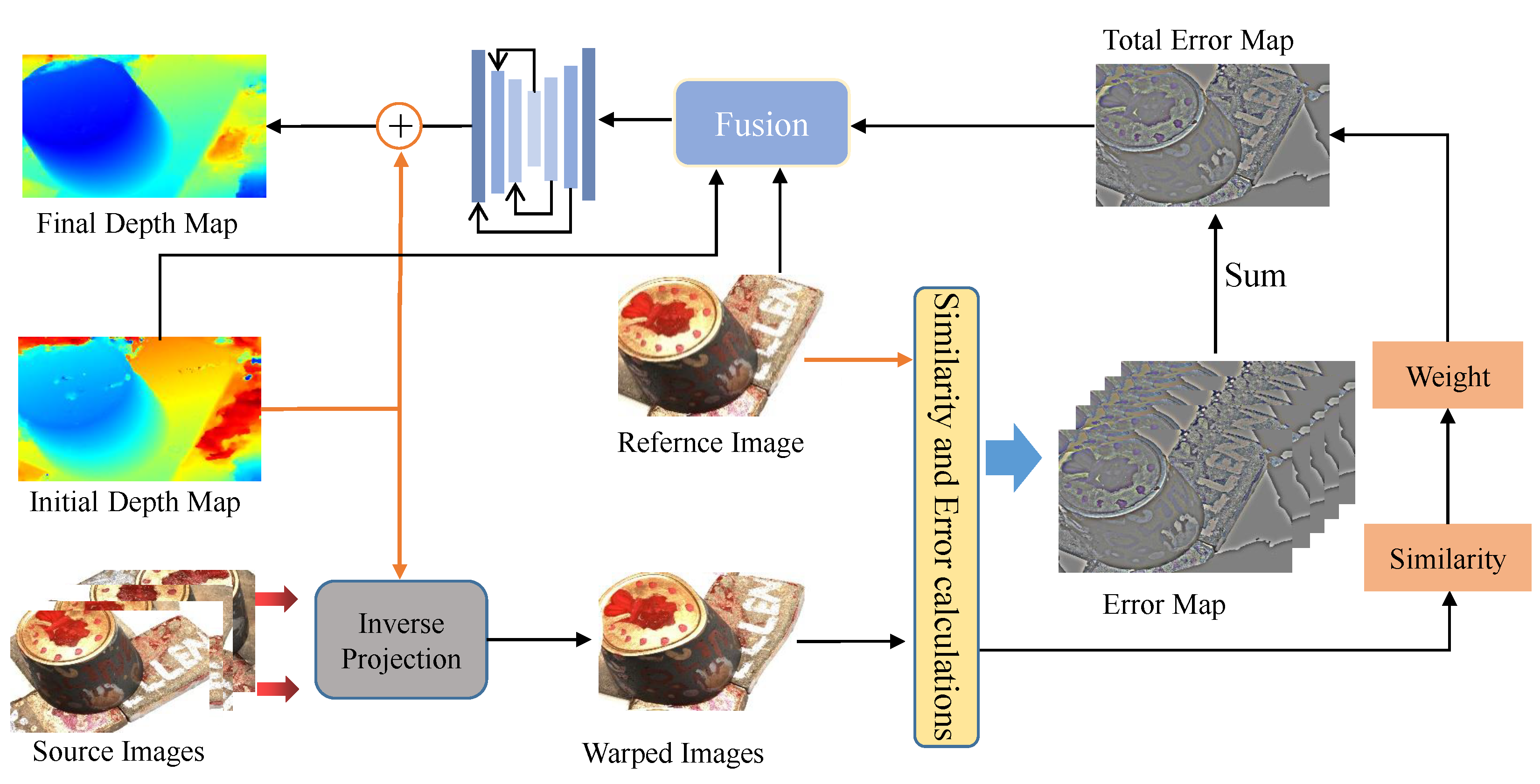
3.5. The Structure of Error-Aware Enhancement
Depth maps with unrefined target edges can result in anomalous noise in the final point cloud during the depth map fusion step [
42,
43]. The filtering process based on geometric restrictions can remove a significant portion of the apparent noise, but it still retains noise near the edge of the target point clouds. Therefore, to improve the accuracy and completeness of the final point cloud, it is necessary to enhance the initial depth map generated by the efficient MVS method. Therefore, we propose error-aware enhancement with the structure shown in
Figure 4.
First, by using inverse-project wrapping, the reconstructed source image can be calculated using the reference image and the initial depth estimate. Then, subtraction is performed to obtain the error map. Finally, the error map, reference image, and initial depth map are fused and input into the hourglass network, and the refined depth map is calculated.
3.5.1. Inverse Projection and Error Calculation
To convert the error of the inaccurate initial depth (
) into a projection error, we project the source images
into the coordinate system of the reference image
by using the initial depth. Then, we calculate the projection error by using the difference between the reference image and the new source image produced by the projection. The mathematical formula is as follows:
where {
,
}, {
,
}, {
,
} denote the cameras intrinsic rotations and translations of the reference image and source images, respectively. A point on the reference image is represented by
p, and the new point that
p warps to on the source image is indicated by
. The depth value predicted by point
p on the initial depth map is denoted by the notation d(
p).
After obtaining the mapping point
, we utilize
(
) to represent the grayscale value of
. The grayscale error between point
p and point
is then available to us and is calculated as follows:
where
and
are the grayscale representations of source image
and reference image
, respectively. After obtaining the grayscale error
of a single pixel, we use
to represent the projected error map between the source image
and the reference image
.
To measure the error between all views, we need to calculate the total projection error for all views, which is obtained by weighting the sum of
for all views. We call it the total error map, and it is denoted by
. The mathematical formula is as follows:
Since the source images from different angles have different target overlap areas relative to the reference image, the weight of each error map in the core error map should also be different. We propose a simplified version of the two-view matching similarity
[
23,
44,
45] for calculating the weight
as follows:
where
r,
g,
b denote the three channels of the original image, and
denotes the dot product.
3.5.2. Information Fusion and Optimization
To further enhance the details of the initial depth map
, we introduce the rich high-frequency features in the reference image
and then fuse this feature information with the initial depth map
and the total error map
as follows:
Finally, we use the hourglass optimizer to optimize the fusion result
to obtain the depth residual map
, and the final result of the depth map
D is computed as follows:
Overall, we apply the projection relationship of geometric mapping between multiple views to the learning-based optimization module, which incurs small computational costs while improving the accuracy. In addition, weighting the projection error of each image in accordance with the variations is implemented through diverse shooting angles, which improves the generalization performance of our module for various scenarios.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}