
Multi-Field Context Fusion Network for Semantic Segmentation of High-Spatial-Resolution Remote Sensing Images

Abstract
:1. Introduction
- We propose a patch selection module for locating poorly segmented local patches in the global image so that further enhancement of segmentation can be performed. It alleviates the burden of segmentation model, and the module can be used with any popular semantic segmentation network.
- We propose a module named FM for aggregating the semantics of multi-field contexts. The module performs adaptive weighting of the local patches selected by PSM with multiple fields of view to enhance the feature representation by aggregating multi-level contextual information.
- We demonstrate the effectiveness of our approach by achieving state-of-the-art semantic segmentation performance on two publicly available high-spatial-resolution re-mote sensing image datasets.
2. Related Work
2.1. Semantic Segmentation
2.2. Multi-Scale Context Aggregation and Refining Segmentation
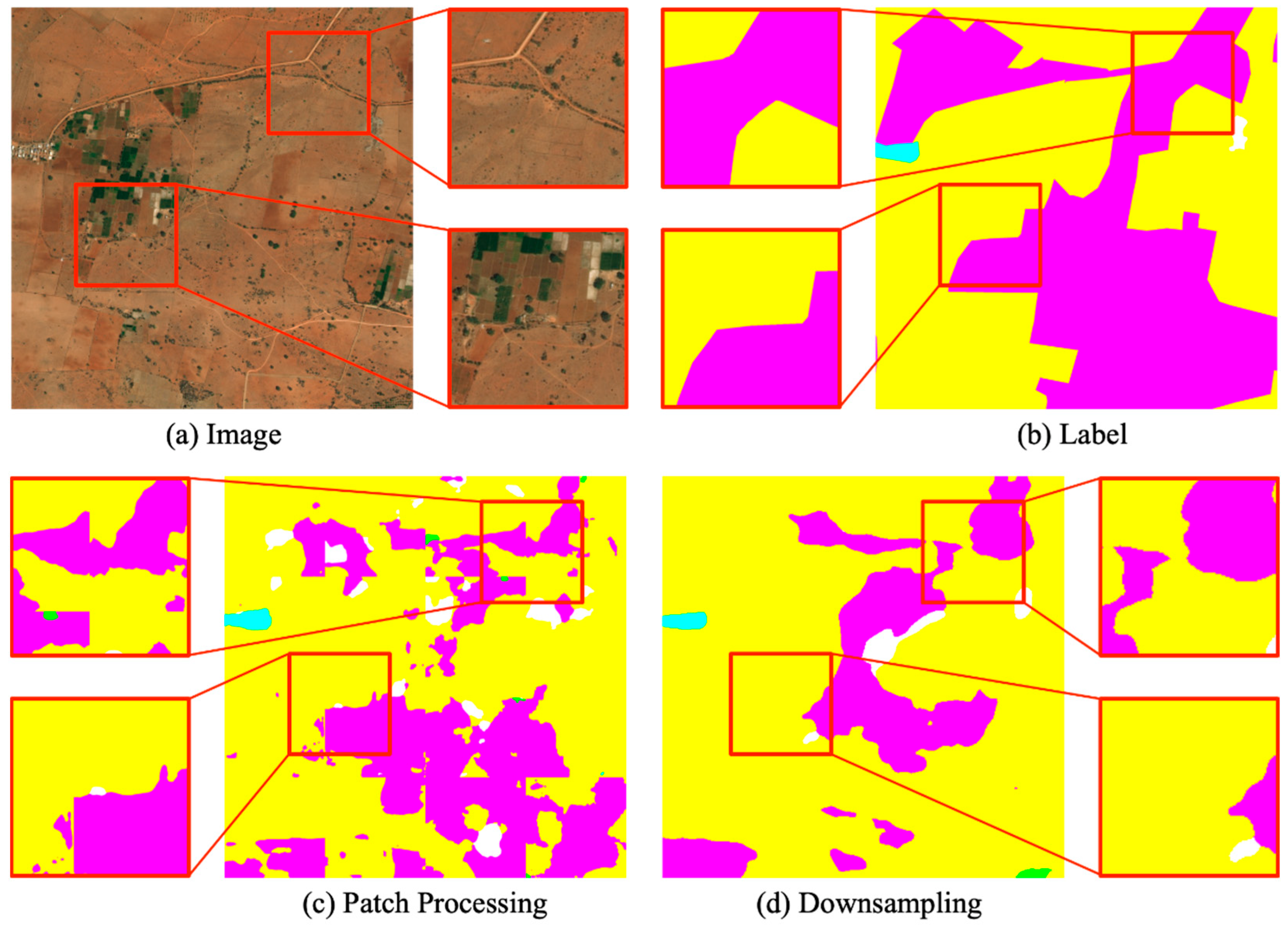
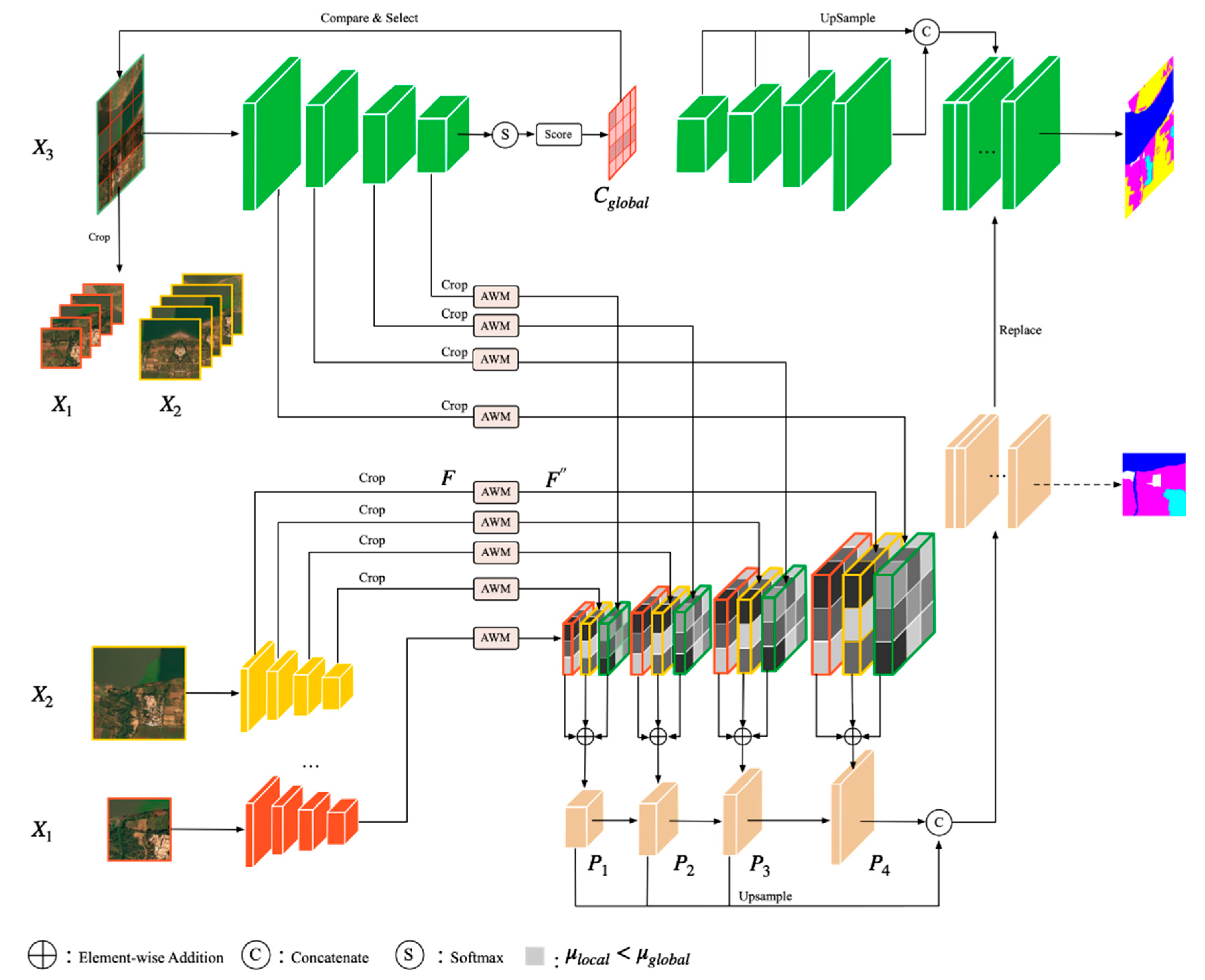
3. Proposed Method
3.1. Overview of Network Architecture

3.2. Backbone Network
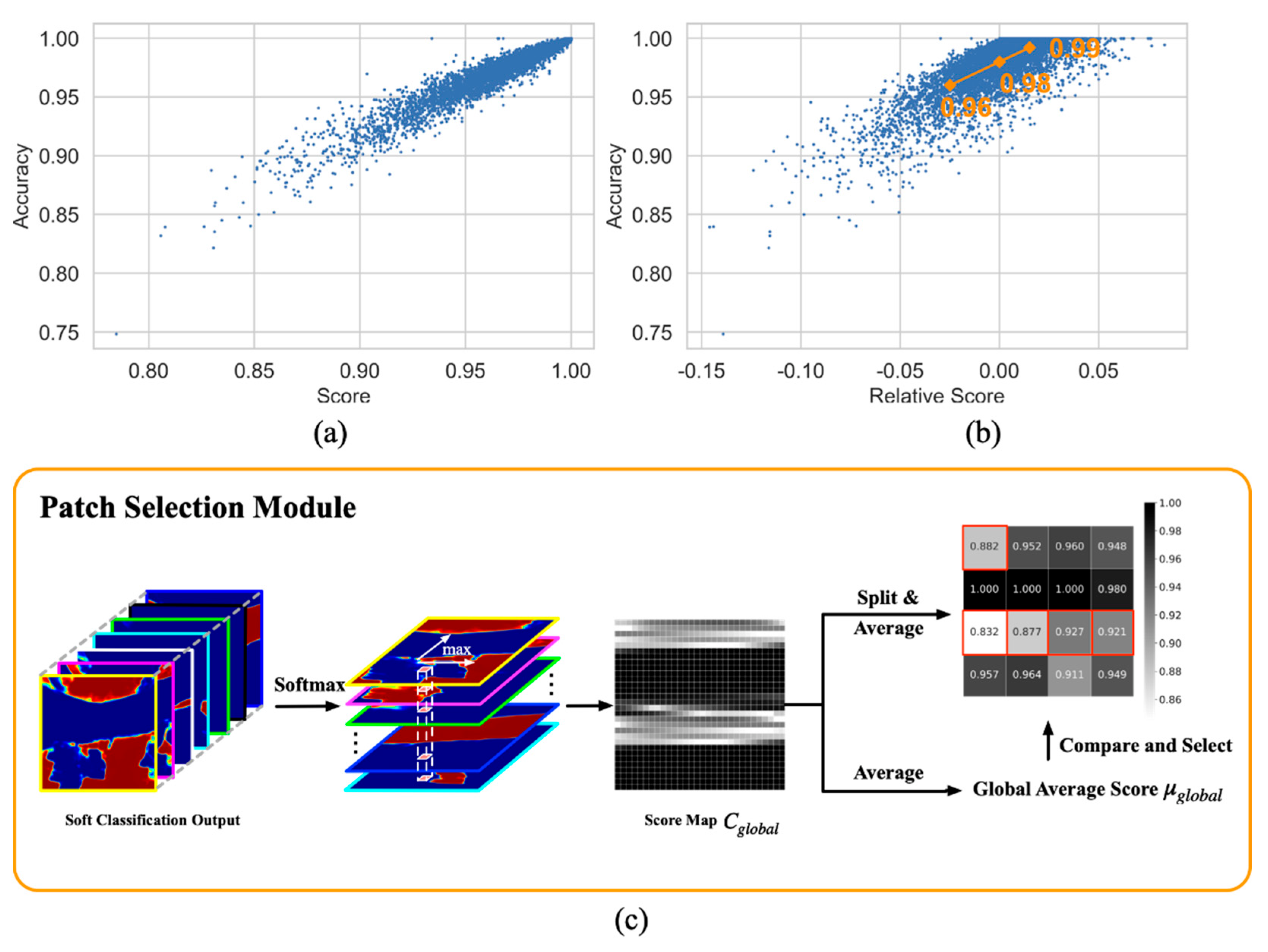
3.3. Patch Selection Module

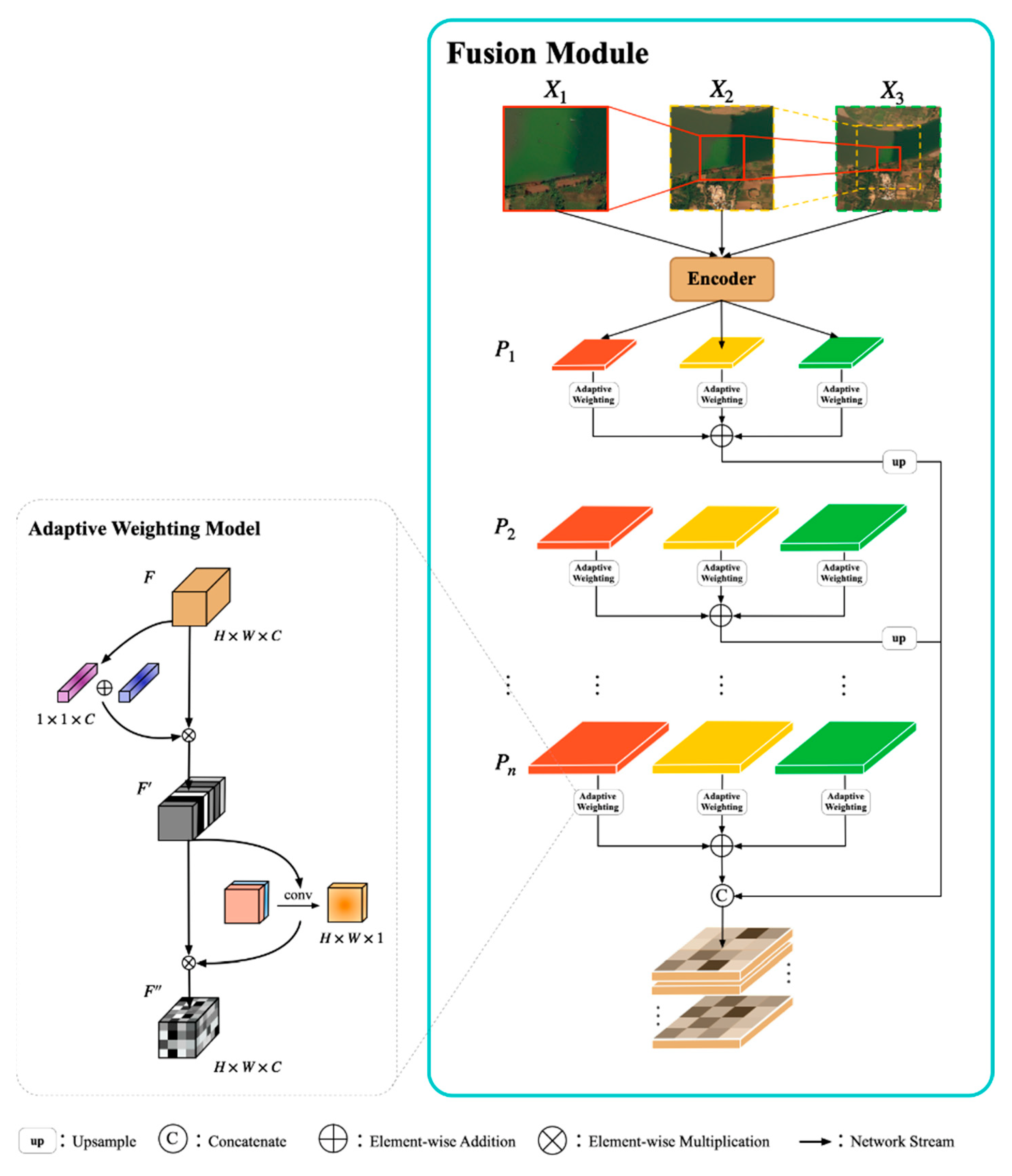
3.4. Multi-Field Context Fusion Module

4. Experiment
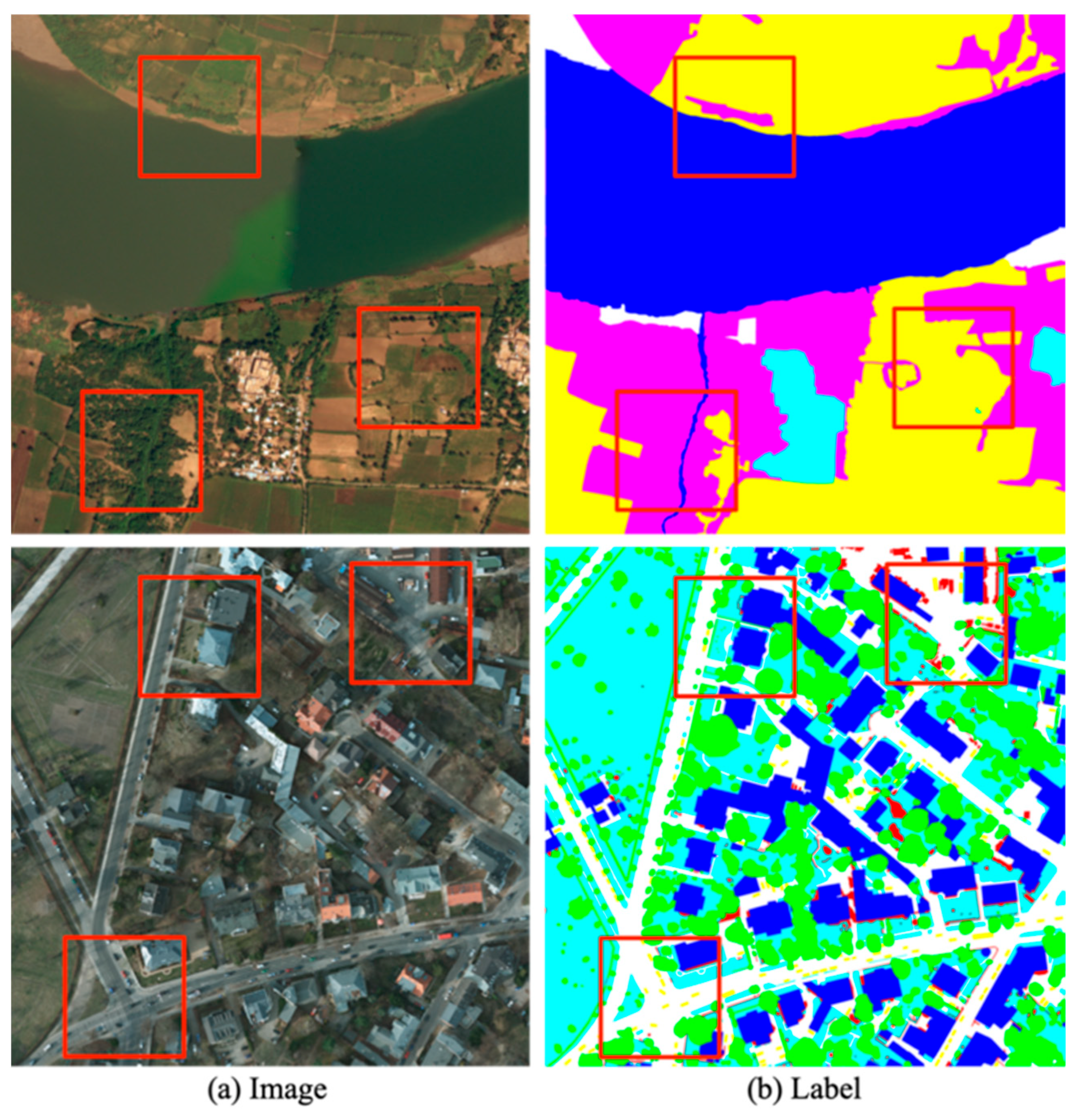
4.1. Datasets
- DeepGlobe: DeepGlobe [56] is a dataset of high-spatial-resolution satellite images. The dataset contains 803 images with a resolution of 2448 × 2448 pixels that have been annotated with seven landscape classes, including one that is an unknown class. Following the evaluation protocol of [10], the unknown class is ignored when calculating mIoU, so there are only six classes to consider. We used the same train/validation/test split as reported in [10], with 455, 207, and 142 images for training, validation, and testing, respectively.
- Potsdam: Potsdam consists of 38 ultra high-spatial-resolution images, each with 6000 × 6000 pixels and it is representative of urban remote sensing data with its large buildings, narrow streets, and dense settlement structures. Tiles are composed of red-green-blue-infrared (RGB-IR) four-channel images. The dataset also includes a Digital Surface Model (DSM) and a normalized DSM (nDSM). In this study, we only used RGB data. We randomly divide images into training, validation and testing sets with 26, 6 and 6 images respectively.

4.2. Experimental Setup
4.3. Evaluation Metrics
4.4. Result
4.4.1. The Result on DeepGlobe Dataset


4.4.2. The result on Potsdam dataset


4.5. Ablation Study

5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tu, W.; Hu, Z.; Li, L.; Cao, J.; Jiang, J.; Li, Q.; Li, Q. Portraying Urban Functional Zones by Coupling Remote Sensing Imagery and Human Sensing Data. Remote Sens. 2018, 10, 141. [Google Scholar] [CrossRef] [Green Version]
- Kang, W.; Xiang, Y.; Wang, F.; You, H. EU-Net: An Efficient Fully Convolutional Network for Building Extraction from Optical Remote Sensing Images. Remote Sens. 2019, 11, 2813. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Wang, B.; Du, X.; Lu, X. Mutual Attention Inception Network for Remote Sensing Visual Question Answering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Zheng, X.; Gong, T.; Li, X.; Lu, X. Generalized Scene Classification From Small-Scale Datasets With Multitask Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Zhao, C.; Lu, Z. Remote Sensing of Landslides—A Review. Remote Sens. 2018, 10, 279. [Google Scholar] [CrossRef] [Green Version]
- Tomás, R.; Li, Z. Earth Observations for Geohazards: Present and Future Challenges. Remote Sens. 2017, 9, 194. [Google Scholar] [CrossRef] [Green Version]
- Yao, H.; Qin, R.; Chen, X. Unmanned Aerial Vehicle for Remote Sensing Applications—A Review. Remote Sens. 2019, 11, 1443. [Google Scholar] [CrossRef] [Green Version]
- Liang, J.; Zhou, J.; Qian, Y.; Wen, L.; Bai, X.; Gao, Y. On the Sampling Strategy for Evaluation of Spectral-Spatial Methods in Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 862–880. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Trans. Geosci. Remote Sens. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Chen, W.; Jiang, Z.; Wang, Z.; Cui, K.; Qian, X. Collaborative Global-Local Networks for Memory-Efficient Segmentation of Ultra-High Resolution Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8916–8925. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention(MICCAI), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging. 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2015, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the ICLR, Viena, Austria, 4 May 2021. [Google Scholar]
- Bello, I.; Zoph, B.; Le, Q.; Vaswani, A.; Shlens, J. Attention Augmented Convolutional Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3285–3294. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar]
- Niu, R.; Sun, X.; Tian, Y.; Diao, W.; Chen, K.; Fu, K. Hybrid Multiple Attention Network for Semantic Segmentation in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A. Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4095–4104. [Google Scholar]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2021, 13, 71. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-Scale Context Aggregation for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision(ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mehta, S.; Rastegari, M.; Shapiro, L.; Hajishirzi, H. ESPNetv2: A Light-Weight, Power Efficient, and General Purpose Convolutional Neural Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.X.; Wang, W.J.; Zhu, Y.K.; Pang, R.M.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019–2 November 2019. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, Y.; Chen, K.; Liu, C.; Qin, Z.; Wang, J. Structured Knowledge Distillation for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, L.C.; Yi, Y.; Jiang, W.; Wei, X.; Yuille, A.L. Attention to Scale: Scale-Aware Semantic Image Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for Object Segmentation and Fine-grained Localization. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Chen, L.C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Li, F.F. Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhong, Z.; Lin, Z.Q.; Bidart, R.; Hu, X.; Wong, A. Squeeze-and-Attention Networks for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Computer Society, Honolulu, HI, USA, 21–26 July 2016. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. Munich, Germany, 8–14 September 2018. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J.D. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Yu, C.; Wang, J.; Gao, C.; Yu, G.; Shen, C.; Sang, N. Context Prior for Scene Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Yan, Y. BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking Wider to See Better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Huynh, C.; Tran, A.T.; Luu, K.; Hoai, M. Progressive Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 21–24 June 2021. [Google Scholar]
- Cheng, H.K.; Chung, J.; Tai, Y.W.; Tang, C.K. CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement. arXiv 2020, arXiv:2005.02551. [Google Scholar]
- Zhang, Q.; Yang, G.; Zhang, G. Collaborative Network for Super-Resolution and Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Chen, L.; Dou, X.; Peng, J.; Li, W.; Sun, B.; Li, H. EFCNet: Ensemble Full Convolutional Network for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Kai, L.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Context | Resolution | Spatial Resolution | No. Classes |
|---|---|---|---|---|
| DeeplGlobe | aerial scene | 2448 × 2448 | 0.5 m | 7 |
| Potsdam | urban scene | 6000 × 6000 | 0.05 m | 6 |
| Model | Patch Inference | Global Inference | ||
|---|---|---|---|---|
| mIoU(%) | Memory(MB) | mIoU(%) | Memory(MB) | |
| UNet | 37.3 | 949 | 38.4 | 5507 |
| ICNet | 35.5 | 1195 | 40.2 | 2557 |
| PSPNet | 53.3 | 1513 | 56.6 | 6289 |
| SegNet | 60.8 | 1139 | 61.2 | 10,339 |
| Deeplabv3+ | 63.1 | 1279 | 63.5 | 3199 |
| FCN-8s | 64.3 | 1963 | 70.1 | 5227 |
| mIoU(%) | Memory(MB) | |||
| GLNet | 71.6 | 1865 | ||
| MCFNet | 72.6 | 1538 | ||
| MCFNet-All Fusion | 73.0 | 1538 | ||
| Class | U. | A. | R. | F. | W. | B. | All |
|---|---|---|---|---|---|---|---|
| Baseline | 78.3 | 87.2 | 39.0 | 78.9 | 82.4 | 59.4 | 70.8 |
| GLNet | 78.1 | 86.8 | 38.6 | 79.8 | 82.6 | 63.6 | 71.6 |
| MCFNet | 78.9 | 87.3 | 41.5 | 80.6 | 83.1 | 64.1 | 72.6 |
| MCFNet-All Fusion | 79.3 | 87.3 | 43.2 | 80.7 | 83.7 | 63.7 | 73.0 |
| Model | mIoU(%) | Memory(MB) |
|---|---|---|
| UNet | 60.4 | 3480 |
| PSPNet | 64.8 | 3108 |
| FCN-8s | 65.9 | 4496 |
| FPN | 66.2 | 4044 |
| Deeplabv3+ | 66.8 | 3424 |
| MCFNet | 70.1 | 2594 |
| MCFNet-All Fusion | 72.2 | 2594 |
| Class | B. | T. | Cl. | V. | C. | S. | All |
|---|---|---|---|---|---|---|---|
| Baseline | 77.0 | 58.1 | 61.0 | 68.3 | 55.9 | 76.4 | 66.2 |
| DeepLab v3+ | 76.2 | 57.1 | 56.9 | 66.4 | 67.3 | 76.9 | 66.8 |
| MCFNet | 78.2 | 65.9 | 61.4 | 71.6 | 63.9 | 79.6 | 70.1 |
| MCFNet-All Fusion | 78.9 | 68.4 | 61.5 | 73.0 | 70.6 | 81.2 | 72.2 |
| Model | Random Select | PSM | FM | mIoU(%) | Time(s) | |
|---|---|---|---|---|---|---|
| DeepGlobe | Baseline | 70.8 | 1.1 | |||
| Ours | √ | √ | 71.1 | 1.6 | ||
| √ | √ | 72.6 | 1.8 | |||
| √ | 73.0 | 2.7 | ||||
| Potsdam | Baseline | 66.2 | 10.3 | |||
| Ours | √ | √ | 68.1 | 12.4 | ||
| √ | √ | 70.1 | 12.4 | |||
| √ | 72.2 | 15.2 |
| Class | U. | A. | R. | F. | W. | B. |
|---|---|---|---|---|---|---|
| Baseline | 78.3 | 87.2 | 39.0 | 78.9 | 82.4 | 59.4 |
| + R.S. & FM | 77.3 | 86.4 | 36.5 | 78.9 | 81.7 | 60.1 |
| + PSM & FM | 78.9 | 87.3 | 41.5 | 80.6 | 83.1 | 64.1 |
| + FM | 79.3 | 87.3 | 43.2 | 80.7 | 83.7 | 63.7 |
| Class | B. | T. | Cl. | V. | C. | S. |
|---|---|---|---|---|---|---|
| Baseline | 77.0 | 58.1 | 61.0 | 68.3 | 55.9 | 76.4 |
| + R.S. & FM | 77.8 | 61.3 | 61.5 | 70.1 | 60.0 | 77.6 |
| + PSM & FM | 78.2 | 65.9 | 61.4 | 71.6 | 63.9 | 79.6 |
| + FM | 78.9 | 68.4 | 61.5 | 73.0 | 70.6 | 81.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, X.; He, S.; Yang, H.; Wang, C. Multi-Field Context Fusion Network for Semantic Segmentation of High-Spatial-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 5830. https://doi.org/10.3390/rs14225830
Du X, He S, Yang H, Wang C. Multi-Field Context Fusion Network for Semantic Segmentation of High-Spatial-Resolution Remote Sensing Images. Remote Sensing. 2022; 14(22):5830. https://doi.org/10.3390/rs14225830
Chicago/Turabian StyleDu, Xinran, Shumeng He, Houqun Yang, and Chunxiao Wang. 2022. "Multi-Field Context Fusion Network for Semantic Segmentation of High-Spatial-Resolution Remote Sensing Images" Remote Sensing 14, no. 22: 5830. https://doi.org/10.3390/rs14225830