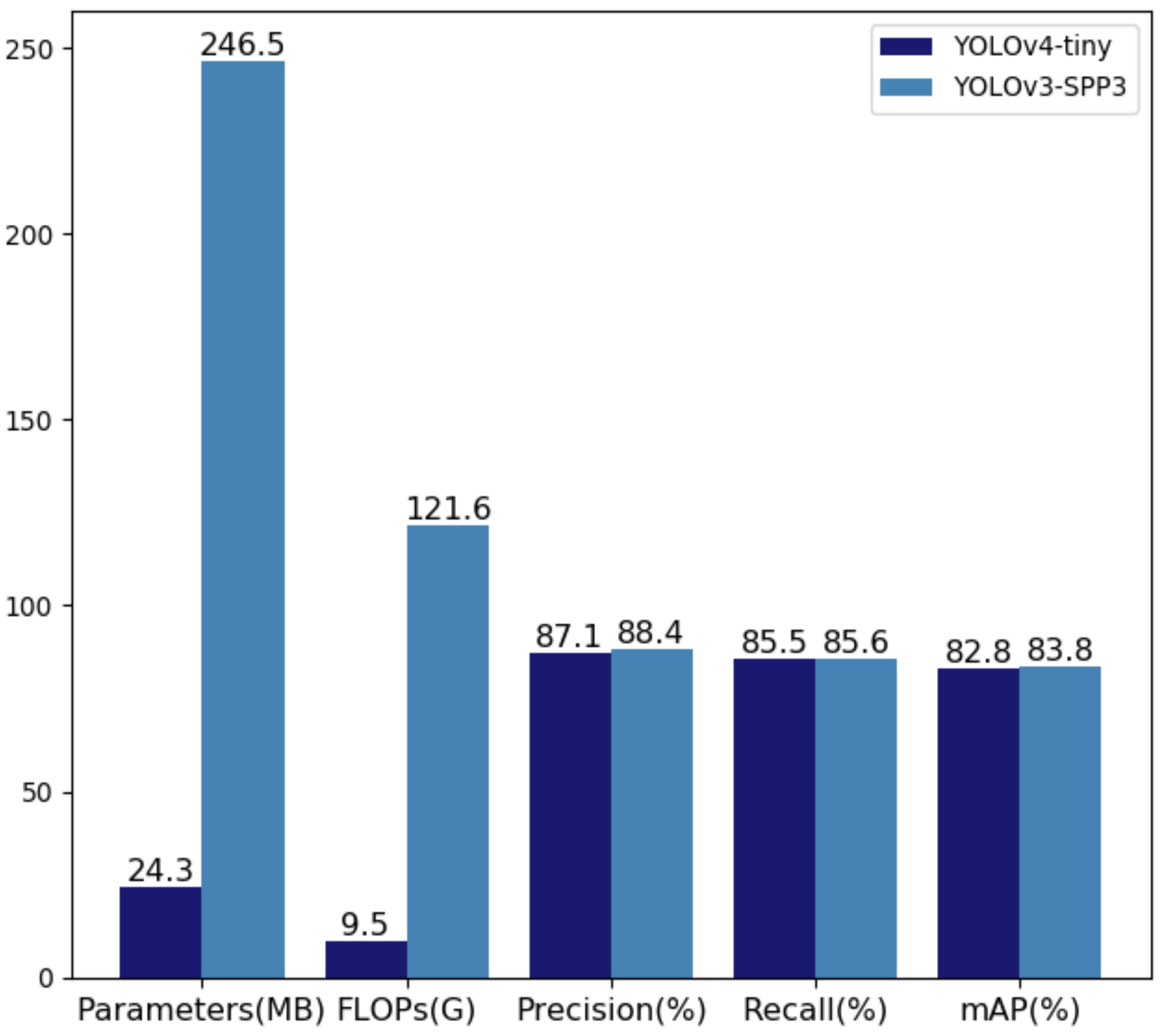
Unlike in previous work, we combine pruning and model distillation to build a network compression framework for remote sensing detection tasks and achieve a large compression of network parameters and computational complexity under the condition of approximately lossless accuracy. The proposed compression architecture is shown in
Figure 1. Specifically, we first iterate pruning on the detector to obtain the minimum pruned model and retain the intermediate model obtained in the pruning process. We take the original model before pruning as the teacher, the intermediate model as the teacher assistant model, and the lightweight model obtained from the last pruning as the student model. The teacher is used to distill the assistant and the assistant is used to distill the student so as to eliminate the differences in capacity and structure between the teacher and the student, thereby effectively improving the performance of the compressed model. The specific implementation process of the algorithm is shown in Algorithm 1. All modules will be described in detail below.
| Algorithm 1 Procedure of the sparse channel pruning + assistant distillation |
- Input:
The original model (T), - Output:
The pruned model (S) - 1:
Initialization by loading the original model - 2:
Add the to the total loss of T - 3:
Obtain test precision by training T with on the training set - 4:
▹ Initial the test of the precision of the model after pruning - 5:
▹ The change in mAP between the pruned model and T - 6:
- 7:
Set - 8:
functionSparse channel pruning() - 9:
- 10:
while do - 11:
Input - 12:
Count the distribution of r of each BN layer in - 13:
Obtain the critical threshold by the ranking exceeding the - 14:
Prune the channels with - 15:
Obtain test precision by fine-tuning the pruned model on the training set - 16:
- 17:
Set.appen d() - 18:
- 19:
the pruned model - 20:
end while - 21:
▹ The final pruned model - 22:
- 23:
Delete models with similar capacity in Set - 24:
for do - 25:
distillation - 26:
end for - 27:
return S - 28:
end function
|
3.1. Network Slimming
A BN layer is proposed to forcibly fix the input feature distribution of each layer so as to accelerate the network training and control gradient and to prevent overfitting. In convolutional neural networks, the BN layer is generally located before the activation function. After adding the BN layer, the convolutional neural network can be expressed as:
where
and
are the input and output feature maps of the
j-th convolution layer, respectively.
is the activation function. The parameters
and
are weights and biases of the convolution kernel. The normalization process of the BN layer is as follows:
m samples are included in a batch to be trained. After linear calculation of the convolution layer, independent normalization with mean = 0 and variance = 1 is required for each feature:
where
is the smoothing factor, which ensures that the denominator is positive, and
and
are the mean and variance of the
m samples, respectively. In order to restore the original expressive ability of the data, the BN layer introduces two learnable parameters,
(scale factor) and
(shift), to scale and translate the normalized parameters:
can determine the value range of each pixel of the output feature map, so we adopt the trainable scale factors in the BN layers as indicators of channel importance. In the process of pruning channels, the part whose scale factor is less than the fixed threshold can be pruned. After removing multiple channels, the model accuracy will be reduced due to the reduction in the parameters. In general, the pruned network should be retrained on the original dataset through the fine-tuning, but the performance of the original model will not be exceeded. Finally, in order to avoid too much reduction in accuracy, the pruning process needs to be repeated many times to achieve a stable pruning network structure.
In the sparse training process, the L1 regularization of the scale factor can be expressed as follows:
where
x and
y represent the input data and the real label of the network.
is the factor used to control the degree of network sparsity. The former part of the above formula represents the loss function of the network, the latter part represents the penalty of the scaling factor introduced to obtain the channel sparsity, and
f is L1 regularization. In addition, the additional regularization rarely affects the performance, which is conducive to improving the generalization ability of the model.
Channel pruning introduces two hyper-parameters: (sparse factor) and a fixed threshold (obtained with the pruning ratio) for deleting the channel. It is necessary to determine a threshold for deleting the channel in the model after training. If the threshold is too low, the compression effect is not obvious; if the threshold is too high, it will cause great damage to the model, and the performance cannot be recovered through fine-tuning. During the training, is used to control the significance of this item. When is too large, the scale factor will become smaller as a whole. At this time, the overall performance of the model will decrease due to the small proportion of the first term; when is too small, the thinning degree of the scale factor is too small, and the compression effect is not obvious.
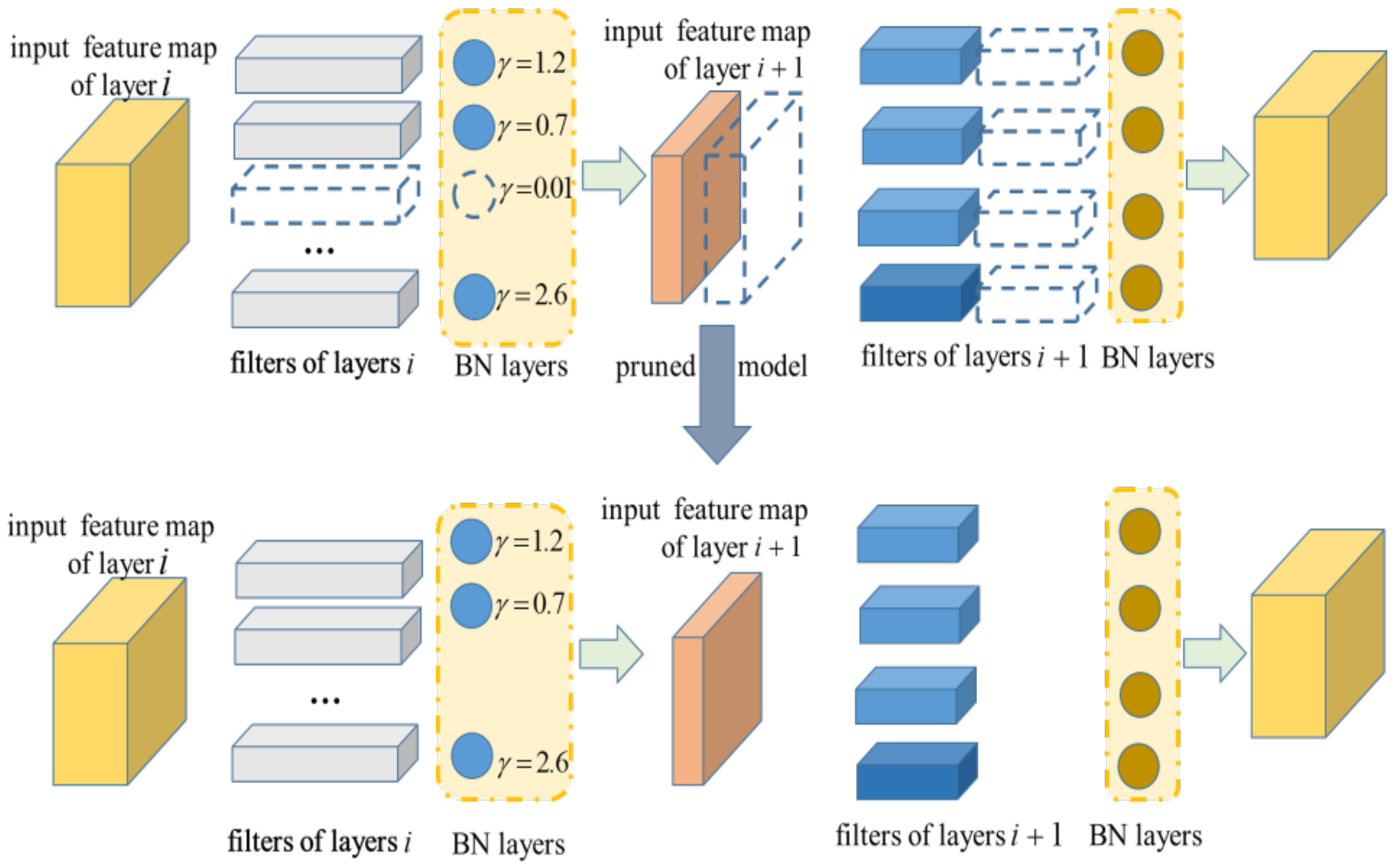
Channel Pruning: After training with channel sparsity, we obtained a model in which many scale factors were close to zero. As shown in
Figure 2, we counted the number (
) of values of
and sorted
from small to large. The corresponding convolution channel whose index was less than
would be deleted.
Fine Tuning: It should be noted that detection performance is usually sensitive to channel pruning. So, this is a necessary step for recovering the generalization ability that has been damaged by channel pruning. However, for large datasets and complex models, this takes a long time. To get an accurate model, more epochs will be executed after all channels are cut.
3.2. Teachers’ Distillation of the Assistants
After the channel pruning, the accuracy of the model will decrease. Although this problem can be alleviated to a certain extent through fine-tuning, it still leads to a partial loss of accuracy. Therefore, this section proposes a method based on model pruning and assistant distillation to stably and effectively compress the detection network.
The difference between the teacher network and the student network lies in the capacity of the network. The capacity can be represented by the number of parameters contained in the network. However, not every teacher network that matches the student network for knowledge distillation can achieve good performance. When the capacity gap between the two networks is large, the accuracy of the student network will decrease. The main reasons are: (1) The teacher network is complex, and the output results are similar to the real labels, resulting in there being too little information in the soft labels. (2) The student network is too simple to simulate the function output from the teacher network.
To meet these challenges, we use networks with different capacities generated in the iterative pruning process as teacher networks. This can not only maintain the similarity in capacity between the teacher and the student, but can also maintain the strong fitting ability of the student network. In summary, the loss function of the general student network
can be summarized as follows:
where
is the input of the softmax layer in the student network,
y is the real label, CE is the cross-entropy function commonly used in loss functions, and
represents the part of the loss function in traditional supervised training.
Assuming that the input of the teacher network into the softmax layer is
, the trained teacher network has much richer information about the target than that of the real label, which is called the soft label (
). It can be represented by a softmax function with a temperature (
):
The corresponding output (
) of the student network is:
Therefore, the KL distance can be used as the loss function of the teacher network information:
where
is an introduced temperature-related hyper-parameter with additional control over the signal output from the teacher network.
represents the process of knowledge transfer and takes the output of the teacher network as part of the loss function for parameter training. The advantage of soft labels is that they contain much useful information, such as different label information for negative samples, and different soft labels for the same type of target. They also include the target intra-class variance and inter-class distance, so the student network can learn the relationships between different labels.
Therefore, the overall loss function of the student network consists of two parts, the real label and the soft label, where
is used to balance the two parts. The specific distillation process is shown in
Figure 3.
Teacher Assistant Knowledge Distillation (TAKD): In the normal distillation process, we usually give a large-scale network that has been trained in advance. We are required to extract its knowledge into a fixed and very small student network. However, the efficiency of such knowledge distillation is low. It is worth noting that since both teachers and students are fixed and given, we cannot choose the teacher size or student size to maximize the efficiency. If the student network is too small, small networks do not have enough capacity to fit the distribution of the teacher networks, which will lead to an ineffective improvement or even a decline in the performance of the student network.
In this paper, we use a medium-sized teacher assistant network (TA) generated through pruning to fill the gap between them. Teacher assistants (TAs) are between teachers and students in terms of scale and ability. First, the TA network is distilled from teachers. Then, the TA plays the role of the teacher and trains students through distillation. This strategy can transfer the compressed knowledge from the TA to the students rather than the teachers. Therefore, students can fit the logit distribution of the TA more effectively than teachers, thus improving the accuracy of the compressed model. We combined the pruning process with the distillation process by retaining the pruned models with different capacities and realized the significant compression of the network and the effective recovery of the accuracy.
Loss Function of TAKD: Target detection includes two different tasks: classification and localization. For the classification branch, the prediction of the teacher network can be directly used to guide the training of the students. Specifically, students are trained according to the following loss function:
where
is the hard loss of the ground truth used by the detector,
is the soft loss predicted by the teachers, and
is used to balance the two parts. Both hard loss and soft loss are cross-entropy loss. The soft tag contains information about the relationships between different classes found by the teacher. By learning from soft labels, student networks inherit such hidden information.
Most object detectors use bounding box regression to adjust the shape and position of the preset box. Generally, learning a great regressor is very important for ensuring good detection accuracy. Unlike the distillation of discrete categories, the regression output of the teacher may provide very incorrect guidance to the student model because the coordinates of the output of the regressor are unbounded. In addition, teachers can provide a regression direction opposite to the ground-truth direction. Therefore, we do not directly use the regression output of teachers as the soft label, but take it as the upper limit that students should reach. Generally speaking, the regression vector of students should be as close to the ground truth as possible, but once the quality of students exceeds the quality of teachers, we will not provide additional losses for students. We call this the teacher’s regression distillation loss
. The total regression loss can be defined as follows:
where
is defined as:
and are the regression outputs of the student and the teacher, and is the weight parameter (set to 0.5 in our experiment). If the network size is too small, it will not be able to fit the objective function. Therefore, by adjusting the performance of the pruned model through knowledge distillation, we achieve stable compression.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}