
An Enhanced Spectral Fusion 3D CNN Model for Hyperspectral Image Classification

Abstract
:1. Introduction
- (1)
- HSI [25]. Due to the rich spectral information and continuity of HSIs, the rich spectral information cannot be handled well or effectively by traditional dimensionality reduction methods. Luo et al. [26]. proposed a multi-structure unified discriminative embedding method to better represent the low-dimensional features of HSIs. With the proposal of the SE module [27], the attention mechanism has received more and more attention. The biggest advantage of the attention mechanism is that it can focus on the useful channel information when facing multiple channels and can directly establish the dependency between input and output, which enhances the parallelization of models [28]. It is an effective attempt to introduce an attention mechanism into his classification. The spectral information of HSIs can be effectively enhanced by weighting each band of HSIs through the channel attention mechanism. Ma et al. [29] went further on this basis and proposed an attention mechanism module using the correlation between spectra obtained by multi-scale convolution, the SeKG module, which further enhanced the spectral information.
- (2)
- HSI classification models [23]. Due to the large number of classification models based on deep learning methods, the study of classification models is one of the research hotspots for HSI classification. Chen et al. [30] used a deep belief network (DBN) to extract features and classify HSIs. Mou et al. [31] used recurrent neural networks (RNN) to achieve classification of HSIs. In the last decade of research on deep learning-based classification models, convolutional neural networks (CNNs) have emerged as one of the main focuses in the research field due to their advantages of feature extraction through local connectivity and weight sharing to reduce the number of parameters. For HSI classification, Zhao et al. [32] first used PCA to reduce the dimension of the original HSI and then extracted features from the reduced image using a CNN model to achieve the classification of the HSI. Zhang et al. [33] input HSIs of different regions into a CNN, expecting better classification results. Guo et al. [34] proposed a CNN-based spatial feature fusion model that can fuse spatial information into spectral information to obtain good classification results. In recent years, other methods used to study hyperspectral image classification using convolutional neural networks or other deep learning methods are FusionNet [35], HSI bidirectional encoder representation from transformers (HSI-BERT) [36], spatial–spectral transformers (SST) [37] and two-stream spectral-spatial residual networks (TSRN) [38]. With the CNN model being studied for a long time, the 3D CNN model was proposed by Tran et al. [39]. The biggest advantage of 3D CNN over 2D CNN is that the features of the channel dimension can be extracted, which is very suitable for HSIs. Chen et al. [40] applied 3D CNN to the classification of HSIs. After that, many researchers have begun using 3D CNN for HSI classification. For example, Ahmad et al. [41] proposed a 3D CNN model that can rapidly classify hyperspectral images. Zhong et al. [42] designed a residual module based on 3D CNN to extract spatial and spectral information and applied it to HSI classification. Laban et al. [43] proposed a 3D deep learning framework which combined PCA and 3D CNN. Due to the advantages of 3D convolution, other models for hyperspectral image study using 3D CNN are: spectral four-branch multi-scale networks (SFBMSN) [44], 3D × 2D CNN [45] and 3D ResNet50 [46]. However, as 3D CNN has the ability to extract both spatial and spectral information, there is no need to extract spatial and spectral features separately.
- (1)
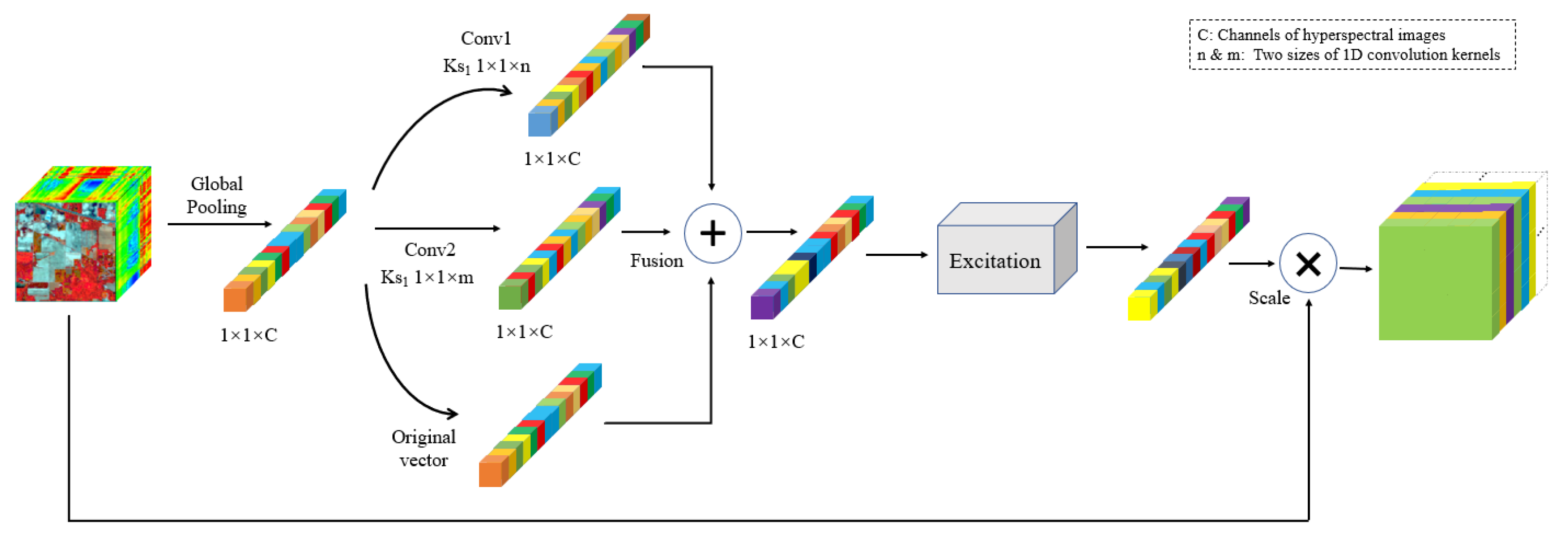
- We optimize the SeKG module [29], termed FsSE. In order to better process and utilize the spectral information while preserving the continuity between spectra as much as possible, we reduce the convolution of multiple scales in the SeKG module to two scales and set the scaling parameter in the excitation layer to 1. These two optimizations allow the module to extract correlations between spectra more efficiently while retaining maximum spectral continuity, so that the classification model can better learn the spectral features.
- (2)
- We propose a new network named the spectral stride fusion network (SSFCNN). The new network implements the fusion of different strides by taking advantage of the fact that 3D CNN can slide in the spectral dimension. This structure not only enhances the learning ability of the model regarding spectral features, but also solves the problem of redundant spectra.
2. Enhanced Spectral Fusion Network (ESFNet)
2.1. FsSE Module
2.2. Spectral Stride Fusion Network (SSFCNN)
2.2.1. 3D Convolution
2.2.2. SSFCNN
3. Experimental Setting
3.1. Dataset
3.2. Running Environment
3.3. Dataset Processing
4. Discussion
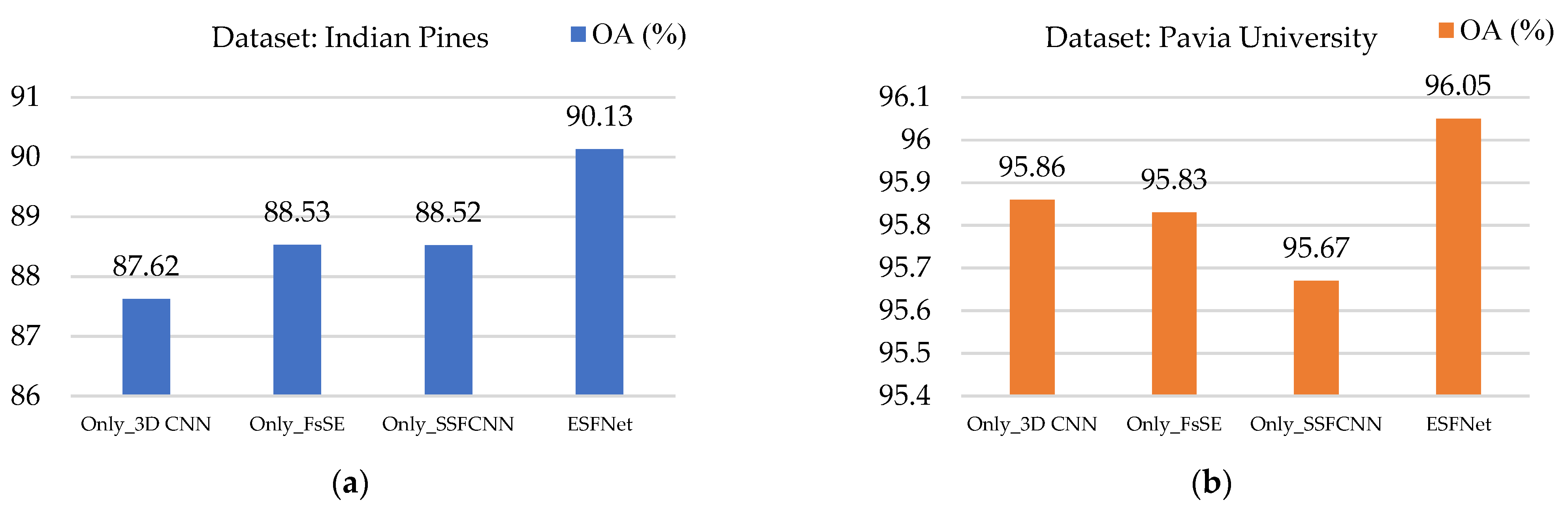
4.1. Comparison of Modules
4.2. Parameter Sensitivity Analysis
4.2.1. Impact of Convolution Kernel Size of the FsSE Module on Model Accuracy
4.2.2. Impact of Patch Size on Model Accuracy
4.2.3. Impact of Stride Combinations on Model Accuracy
4.3. Comparison with Other Baselines
4.3.1. Baseline
- (1)
- SVM: The SVM model in this paper used the radial basis function (RBF kernel), which classifies by raw spectral features. We implemented the model using the SVM function in the Sklearn module.
- (2)
- ANN: The original spectral features are classified by an artificial neural network (ANN), which contains four fully connected layers and a dropout layer, and was trained with a learning rate of 0.0001 using the Adam algorithm.
- (3)
- 1D CNN: We used the same 1D CNN structure as in [24], Pytorch to implement the model and the stochastic gradient descent algorithm to train the model with a learning rate of 0.01.
- (4)
- 3D CNN: A structure proposed in [40] was used for the 3D CNN model, which is a conventional structure consisting of three convolution-pooling layers and one fully connected layer. The model was implemented in Pytorch and trained with a learning rate of 0.003 using the stochastic gradient descent algorithm.
- (5)
- Hamida (3D CNN + 1D classifier) [47]: We implemented the model in Pytorch, where we extracted a 5 × 5 × 200 cube from the image as an input to the model. The characteristic of the model is that it utilizes one-dimensional convolution instead of the usual pooling method and finally utilizes one-dimensional convolution instead of a fully connected layer. The model was trained with a learning rate of 0.01 using the stochastic gradient descent algorithm.
- (6)
- HybridSN: The model used the specific structure proposed in [48], and the model was implemented in Pytorch. The patch size is 25 × 25. The model contains a total of four convolutional layers and two fully connected layers, where the four convolutional layers include three 3D convolutional layers and one 2D convolutional layer, with the 3D convolutional layer for learning spatial-spectral features and the 2D convolutional layer for learning spatial features.
- (7)
- RNN: We used an RNN model for HSI classification, which is similar to [31]. We replaced the activation function with a tanh function and implemented the model in Pytorch.
- (8)
- SpectralFormer (SF): We implemented the model directly using the model code provided in [49]. The model is an improvement of Transformer with the addition of two new modules, GSE and CAF, in order to improve the detail-capturing capacity of subtle spectral discrepancies and enhance the information transitivity between layers, respectively. We implemented it in Pytorch.
4.3.2. Performance Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Goetz, A.F.H. Three decades of hyperspectral remote sensing of the Earth: A personal view. Remote Sens. Environ. 2009, 113, S5–S16. [Google Scholar] [CrossRef]
- Nalepa, J. Recent Advances in Multi- and Hyperspectral Image Analysis. Sensors 2021, 21, 6002. [Google Scholar] [CrossRef] [PubMed]
- Kemker, R.; Kanan, C. Self-Taught Feature Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2693–2705. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.G.; He, Y.H.; Shang, J.L. Recent Advances of Hyperspectral Imaging Technology and Applications in Agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Kruse, F.A. Identification and mapping of minerals in drill core using hyperspectral image analysis of infrared reflectance spectra. Int. J. Remote Sens. 1996, 17, 1623–1632. [Google Scholar] [CrossRef]
- Wang, Z.M.; Du, B.; Zhang, L.F.; Zhang, L.P.; Jia, X.P. A Novel Semisupervised Active-Learning Algorithm for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3071–3083. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zeng, S.; Wang, Z.Y.; Gao, C.J.; Kang, Z.; Feng, D.G. Hyperspectral Image Classification With Global-Local Discriminant Analysis and Spatial-Spectral Context. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 5005–5018. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Blanzieri, E.; Melgani, F. Nearest neighbor classification of remote sensing images with the maximal margin principle. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1804–1811. [Google Scholar] [CrossRef]
- Yager, R.R. An extension of the naive Bayesian classifier. Inf. Sci. 2006, 176, 577–588. [Google Scholar] [CrossRef]
- Zhang, Y.X.; Liu, K.; Dong, Y.N.; Wu, K.; Hu, X.Y. Semisupervised Classification Based on SLIC Segmentation for Hyperspectral Image. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1440–1444. [Google Scholar] [CrossRef]
- Shinde, P.P.; Shah, S. A review of machine learning and deep learning applications. In Proceedings of the 2018 Fourth international conference on computing communication control and automation (ICCUBEA) 2018, Pune, India, 16–18 August 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.C.; Xia, G.S.; Zhang, L.P.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, W.P.; Zhang, J.; Wu, Y.; Jiao, L.C.; Zhu, H.; Zhao, W. A Novel Two-Step Registration Method for Remote Sensing Images Based on Deep and Local Features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4834–4843. [Google Scholar] [CrossRef]
- Ma, J.Y.; Tang, L.F.; Fan, F.; Huang, J.; Mei, X.G.; Ma, Y. SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Zeng, N.Y.; Wang, Z.D.; Zhang, H.; Kim, K.E.; Li, Y.R.; Liu, X.H. An Improved Particle Filter With a Novel Hybrid Proposal Distribution for Quantitative Analysis of Gold Immunochromatographic Strips. IEEE Trans. Nanotechnol. 2019, 18, 819–829. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z.H. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.Y.; Jiang, J.J.; Guo, X.J.; Ling, H.B. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Chen, Y.S.; Lin, Z.H.; Zhao, X.; Wang, G.; Gu, Y.F. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Lv, W.J.; Wang, X.F. Overview of Hyperspectral Image Classification. J. Sens. 2020, 2020, 4817234. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.Y.; Wei, L.; Zhang, F.; Li, H.C. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef] [Green Version]
- Imani, M.; Ghassemian, H. An overview on spectral and spatial information fusion for hyperspectral image classification: Current trends and challenges. Inf. Fusion 2020, 59, 59–83. [Google Scholar] [CrossRef]
- Luo, F.L.; Zou, Z.H.; Liu, J.M.; Lin, Z.P. Dimensionality Reduction and Classification of Hyperspectral Image via Multistructure Unified Discriminative Embedding. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Q.; Cai, X.; Chen, C.; Lv, L.; Chen, M. Commented content classification with deep neural network based on attention mechanism. In Proceedings of the 2017 IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 25–26 March 2017; pp. 2016–2019. [Google Scholar]
- Ma, W.P.; Ma, H.X.; Zhu, H.; Li, Y.T.; Li, L.W.; Jiao, L.C.; Hou, B. Hyperspectral image classification based on spatial and spectral kernels generation network. Inf. Sci. 2021, 578, 435–456. [Google Scholar] [CrossRef]
- Chen, Y.S.; Zhao, X.; Jia, X.P. Spectral-Spatial Classification of Hyperspectral Data Based on Deep Belief Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Mou, L.C.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.Z.; Du, S.H. Spectral-Spatial Feature Extraction for Hyperspectral Image Classification: A Dimension Reduction and Deep Learning Approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- Zhang, M.M.; Li, W.; Du, Q. Diverse Region-Based CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef] [PubMed]
- Guo, A.J.X.; Zhu, F. A CNN-Based Spatial Feature Fusion Algorithm for Hyperspectral Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7170–7181. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.M.; Yang, Y.H.; Yang, J.H.; Zhao, N.Y.; Wu, L.; Wang, L.G.; Wang, T.R. FusionNet: A Convolution-Transformer Fusion Network for Hyperspectral Image Classification. Remote Sens. 2022, 14, 4066. [Google Scholar] [CrossRef]
- He, J.; Zhao, L.N.; Yang, H.W.; Zhang, M.M.; Li, W. HSI-BERT: Hyperspectral Image Classification Using the Bidirectional Encoder Representation From Transformers. IEEE Trans. Geosci. Remote Sens. 2020, 58, 165–178. [Google Scholar] [CrossRef]
- He, X.; Chen, Y.S.; Lin, Z.H. Spatial-Spectral Transformer for Hyperspectral Image Classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Khotimah, W.N.; Bennamoun, M.; Boussaid, F.; Sohel, F.; Edwards, D. A High-Performance Spectral-Spatial Residual Network for Hyperspectral Image Classification with Small Training Data. Remote Sens. 2020, 12, 3137. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 4489–4497. [Google Scholar]
- Chen, Y.S.; Jiang, H.L.; Li, C.Y.; Jia, X.P.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, M.; Khan, A.M.; Mazzara, M.; Distefano, S.; Ali, M.; Sarfraz, M.S. A Fast and Compact 3-D CNN for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhong, Z.L.; Li, J.; Luo, Z.M.; Chapman, M. Spectral-Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Laban, N.; Abdellatif, B.; Ebeid, H.M.; Shedeed, H.A.; Tolba, M.F. Reduced 3-D Deep Learning Framework for Hyperspectral Image Classification. In International Conference on Advanced Machine Learning Technologies and Applications; Springer: Cham, Switzerland, 2020; pp. 13–22. [Google Scholar]
- Shi, C.P.; Sun, J.W.; Wang, L.G. Hyperspectral Image Classification Based on Spectral Multiscale Convolutional Neural Network. Remote Sens. 2022, 14, 1951. [Google Scholar] [CrossRef]
- Diakite, A.; Jiangsheng, G.; Xiaping, F. Hyperspectral image classification using 3D 2D CNN. IET Image Process. 2021, 15, 1083–1092. [Google Scholar] [CrossRef]
- Firat, H.; Hanbay, D. Classification of Hyperspectral Images Using 3D CNN Based ResNet50. In Proceedings of the 2021 29th Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkey, 9–11 June 2021; pp. 1–4. [Google Scholar]
- Ben Hamida, A.; Benoit, A.; Lambert, P.; Ben Amar, C. 3-D Deep Learning Approach for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D-2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Hong, D.F.; Han, Z.; Yao, J.; Gao, L.R.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking Hyperspectral Image Classification With Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures; CRC Press: Boca Raton, FL, USA, 2003. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Training Time/s | Total Params |
|---|---|---|
| 3&5 | 1570 | 249,816 |
| 3&7 | 1455 | 249,818 |
| 5&7 | 1160 | 249,820 |
| Dataset: Indian Pines | Dataset: Pavia University | ||
|---|---|---|---|
| Patch Size | Training Time/s | Patch Size | Training Time/s |
| 5 | 208 | 5 | 703 |
| 7 | 293 | 7 | 962 |
| 9 | 284 | 9 | 865 |
| 11 | 620 | 11 | 1160 |
| 13 | 688 | 13 | 1779 |
| 15 | 1073 | 15 | 1887 |
| 17 | 1021 | 17 | 2223 |
| Combination of Strides | Training Time/s | Overall Accuracy/% |
|---|---|---|
| 1_3&1_3 | 585 | 88.585 |
| 1_3&1_5 | 620 | 90.125 |
| 1_3&1_7 | 506 | 88.770 |
| 1_5&1_3 | 895 | 88.737 |
| 1_5&1_5 | 410 | 88.379 |
| 1_5&1_7 | 736 | 87.902 |
| 1_7&1_3 | 617 | 88.444 |
| 1_7&1_5 | 464 | 87.458 |
| 1_7&1_7 | 474 | 88.466 |
| Combination of Strides | Training Time/s | Overall Accuracy/% |
|---|---|---|
| 1_3&1_3 | 966 | 95.343 |
| 1_3&1_5 | 703 | 95.558 |
| 1_3&1_7 | 991 | 95.979 |
| 1_5&1_3 | 819 | 95.660 |
| 1_5&1_5 | 771 | 95.701 |
| 1_5&1_7 | 1028 | 95.984 |
| 1_7&1_3 | 769 | 95.522 |
| 1_7&1_5 | 754 | 96.044 |
| 1_7&1_7 | 897 | 95.561 |
| Class Name [F1 Scores (%)] | SVM | RNN | ANN | 1D CNN | SF | 3D CNN | Hamida | HybridSN | ESFNet |
|---|---|---|---|---|---|---|---|---|---|
| 1. Alfalfa | 36.1 | 8.7 | 82.1 | 0.0 | 10.9 | 95.3 | 74.2 | 100.0 | 75.8 |
| 2. Corn-notill | 74.8 | 63.3 | 79.3 | 52.8 | 69.2 | 90.2 | 89.4 | 93.7 | 93.5 |
| 3. Corn-mintill | 72.6 | 44.9 | 70.4 | 31.1 | 68.7 | 54.5 | 77.9 | 59.2 | 85.6 |
| 4. Corn | 64.4 | 44.1 | 71.0 | 2.7 | 64.5 | 55.4 | 76.3 | 46.2 | 88.3 |
| 5. Grass-pasture | 86.5 | 75.6 | 91.0 | 8.6 | 84.0 | 70.2 | 92.5 | 73.6 | 93.0 |
| 6. Grass-trees | 93.8 | 89.3 | 93.0 | 76.1 | 91.6 | 97.2 | 98.3 | 99.5 | 97.2 |
| 7. Grass-pasture-mowed | 85.7 | 60.0 | 95.8 | 0.0 | 86.3 | 93.6 | 35.3 | 83.7 | 93.6 |
| 8. Hay-windrowed | 94.7 | 91.7 | 97.6 | 87.3 | 93.3 | 67.7 | 96.8 | 74.1 | 95.8 |
| 9. Oats | 52.6 | 0.0 | 71.4 | 0.0 | 66.7 | 80.0 | 86.5 | 94.7 | 50.0 |
| 10. Soybean-notill | 73.2 | 56.1 | 77.4 | 34.7 | 71.9 | 83.9 | 87.6 | 87.0 | 91.4 |
| 11. Soybean-mintill | 80.4 | 67.0 | 82.6 | 66.6 | 78.9 | 90.4 | 90.3 | 92.2 | 94.1 |
| 12. Soybean-clean | 82.1 | 57.2 | 74.8 | 15.8 | 68.6 | 75.0 | 81.0 | 79.2 | 88.8 |
| 13. Wheat | 93.7 | 90.2 | 96.2 | 81.9 | 95.7 | 100.0 | 99.2 | 97.6 | 99.5 |
| 14. Woods | 91.8 | 90.2 | 94.5 | 82.2 | 91.5 | 82.5 | 95.5 | 85.0 | 97.9 |
| 15. B-G-T-D | 62.8 | 56.1 | 69.5 | 12.9 | 53.5 | 37.5 | 76.5 | 39.5 | 68.5 |
| 16. Stone-Steel-Towers | 91.0 | 81.0 | 86.7 | 90.3 | 90.3 | 74.1 | 97.6 | 91.1 | 97.6 |
| OA(%) | 81.0 | 68.9 | 83.2 | 59.6 | 78.3 | 72.9 | 88.5 | 76.3 | 90.1 |
| Kappa × 100 | 0.783 | 0.645 | 0.808 | 0.522 | 0.751 | 0.698 | 0.869 | 0.735 | 0.888 |
| Class Name [F1 Scores (%)] | SVM | RNN | ANN | 1D CNN | SF | 3D CNN | Hamida | HybridSN | ESFNet |
|---|---|---|---|---|---|---|---|---|---|
| 1. Asphalt | 91.5 | 90.5 | 95.8 | 90.2 | 92.9 | 90.8 | 97.2 | 93.5 | 97.9 |
| 2. Meadows | 95.1 | 95.3 | 97.1 | 91.2 | 94.3 | 83.9 | 95.5 | 86.8 | 96.9 |
| 3. Gravel | 79.3 | 73.3 | 85.8 | 56.3 | 73.1 | 83.4 | 93.0 | 87.2 | 93.4 |
| 4. Trees | 92.8 | 93.4 | 96.3 | 90.5 | 92.7 | 93.6 | 96.7 | 94.6 | 98.4 |
| 5. Painted metal sheets | 99.2 | 99.5 | 99.6 | 99.1 | 99.4 | 100.0 | 100.0 | 99.8 | 100.0 |
| 6. Bare Soil | 84.5 | 88.8 | 93.4 | 70.3 | 83.0 | 94.5 | 94.6 | 100.0 | 99.6 |
| 7. Bitumen | 71.2 | 73.5 | 91.8 | 80.1 | 84.7 | 95.4 | 95.2 | 100.0 | 96.6 |
| 8. Self-Blocking Bricks | 85.8 | 80.6 | 88.5 | 81.6 | 78.8 | 98.2 | 95.5 | 98.8 | 96.4 |
| 9. Shadows | 99.9 | 99.6 | 99.6 | 99.9 | 99.9 | 97.9 | 99.9 | 98.8 | 100.0 |
| OA(%) | 91.2 | 90.5 | 94.7 | 86.3 | 89.9 | 83.2 | 94.5 | 86.2 | 96.1 |
| Kappa × 100 | 0.882 | 0.875 | 0.930 | 0.816 | 0.866 | 0.792 | 0.927 | 0.828 | 0.948 |
| Class Name | SVM | RNN | ANN | 1D CNN | SF | 3D CNN | Hamida | HybridSN | ESFNet |
|---|---|---|---|---|---|---|---|---|---|
| 1. Alfalfa | 6 | 8 | 3 | 9 | 7 | 2 | 5 | 1 | 4 |
| 2. Corn-notill | 6 | 8 | 5 | 9 | 7 | 3 | 4 | 1 | 2 |
| 3. Corn-mintill | 3 | 8 | 4 | 9 | 5 | 7 | 2 | 6 | 1 |
| 4. Corn | 5 | 8 | 3 | 9 | 4 | 6 | 2 | 7 | 1 |
| 5. Grass-pasture | 4 | 6 | 3 | 9 | 5 | 8 | 2 | 7 | 1 |
| 6. Grass-trees | 5 | 8 | 6 | 9 | 7 | 3.5 | 2 | 1 | 3.5 |
| 7. Grass-pasture-mowed | 5 | 7 | 1 | 9 | 4 | 2.5 | 8 | 6 | 2.5 |
| 8. Hay-windrowed | 4 | 6 | 1 | 7 | 5 | 9 | 2 | 8 | 3 |
| 9. Oats | 6 | 8.5 | 4 | 8.5 | 5 | 3 | 2 | 1 | 7 |
| 10. Soybean-notill | 6 | 8 | 5 | 9 | 7 | 4 | 2 | 3 | 1 |
| 11. Soybean-mintill | 6 | 8 | 5 | 9 | 7 | 3 | 4 | 2 | 1 |
| 12. Soybean-clean | 2 | 8 | 6 | 9 | 7 | 5 | 3 | 4 | 1 |
| 13. Wheat | 7 | 8 | 5 | 9 | 6 | 1 | 3 | 4 | 2 |
| 14. Woods | 4 | 6 | 3 | 9 | 5 | 8 | 2 | 7 | 1 |
| 15. B-G-T-D | 4 | 5 | 2 | 9 | 6 | 8 | 1 | 7 | 3 |
| 16. Stone-Steel-Towers | 4 | 8 | 7 | 5.5 | 5.5 | 9 | 1.5 | 3 | 1.5 |
| Total Rank | 77 | 118.5 | 63 | 138 | 92.5 | 82 | 45.5 | 68 | 35.5 |
| Class Name | SVM | RNN | ANN | 1D CNN | SF | 3D CNN | Hamida | HybridSN | ESFNet |
|---|---|---|---|---|---|---|---|---|---|
| 1. Asphalt | 6 | 8 | 3 | 9 | 5 | 7 | 2 | 4 | 1 |
| 2. Meadows | 5 | 4 | 1 | 7 | 6 | 9 | 3 | 8 | 2 |
| 3. Gravel | 6 | 7 | 4 | 9 | 8 | 5 | 2 | 3 | 1 |
| 4. Trees | 7 | 6 | 3 | 9 | 8 | 5 | 2 | 4 | 1 |
| 5. Painted metal sheets | 8 | 6 | 5 | 9 | 7 | 2 | 2 | 4 | 2 |
| 6. Bare Soil | 7 | 6 | 5 | 9 | 8 | 4 | 3 | 1 | 2 |
| 7. Bitumen | 9 | 8 | 5 | 7 | 6 | 3 | 4 | 1 | 2 |
| 8. Self-Blocking Bricks | 6 | 8 | 5 | 7 | 9 | 2 | 4 | 1 | 3 |
| 9. Shadows | 3.5 | 6.5 | 6.5 | 3.5 | 3.5 | 9 | 3.5 | 8 | 1 |
| Total Rank | 57.5 | 59.5 | 37.5 | 69.5 | 60.5 | 46 | 25.5 | 34 | 15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Zeng, S.; Xiao, Z.; Zhou, J.; Li, H.; Kang, Z. An Enhanced Spectral Fusion 3D CNN Model for Hyperspectral Image Classification. Remote Sens. 2022, 14, 5334. https://doi.org/10.3390/rs14215334
Zhou J, Zeng S, Xiao Z, Zhou J, Li H, Kang Z. An Enhanced Spectral Fusion 3D CNN Model for Hyperspectral Image Classification. Remote Sensing. 2022; 14(21):5334. https://doi.org/10.3390/rs14215334
Chicago/Turabian StyleZhou, Junbo, Shan Zeng, Zuyin Xiao, Jinbo Zhou, Hao Li, and Zhen Kang. 2022. "An Enhanced Spectral Fusion 3D CNN Model for Hyperspectral Image Classification" Remote Sensing 14, no. 21: 5334. https://doi.org/10.3390/rs14215334