
Multiscale Object Detection in Remote Sensing Images Combined with Multi-Receptive-Field Features and Relation-Connected Attention


Abstract
:
1. Introduction
2. Related Work
2.1. Deep-Network-Based Object Detection
2.2. Multiscale Object Detection in Remote Sensing Images
2.3. Attention Mechanism
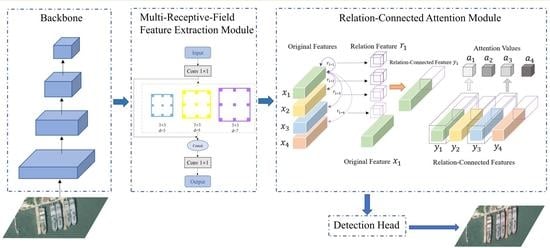
3. Proposed Method
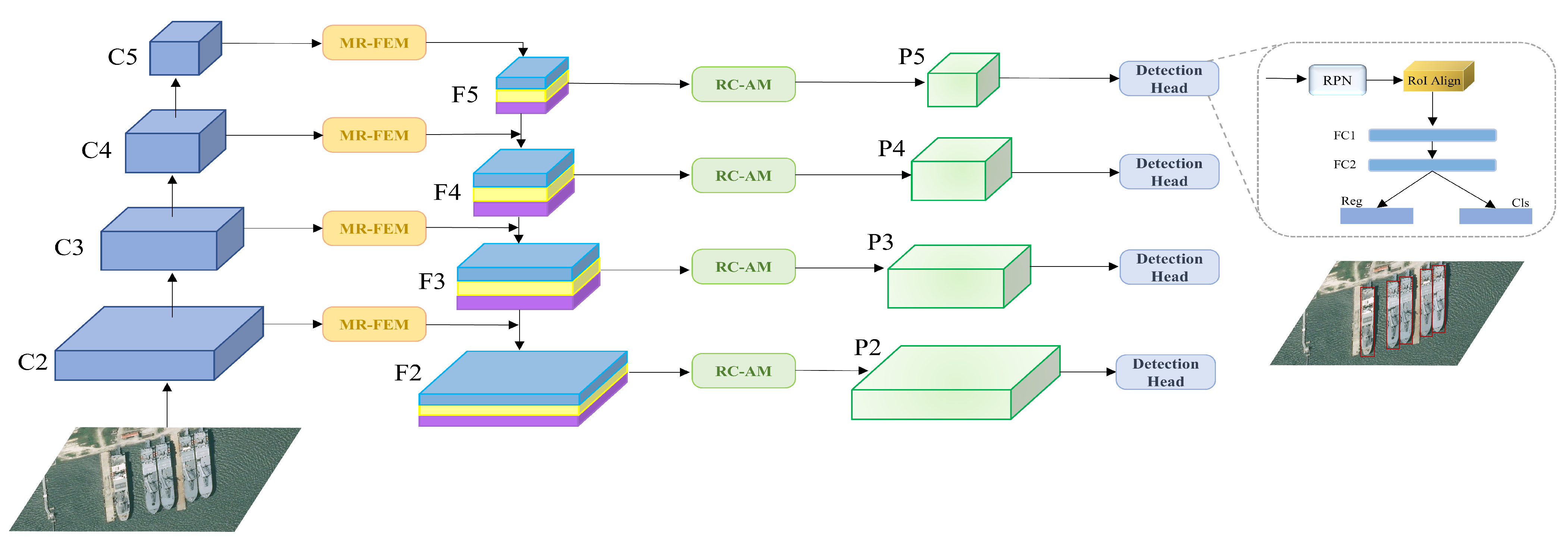
3.1. Overview
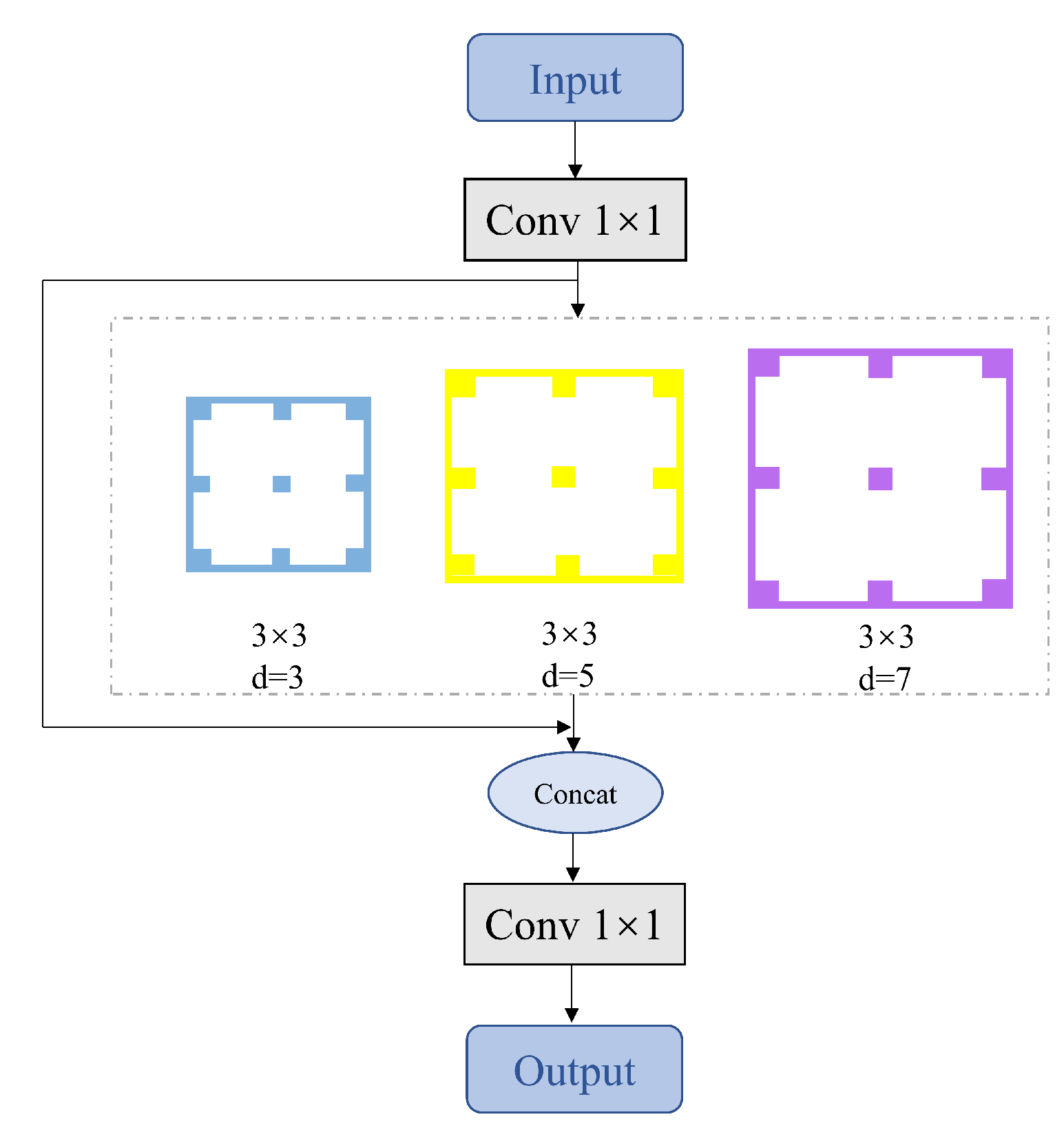
3.2. Multi-Receptive-Field Feature Extraction Module
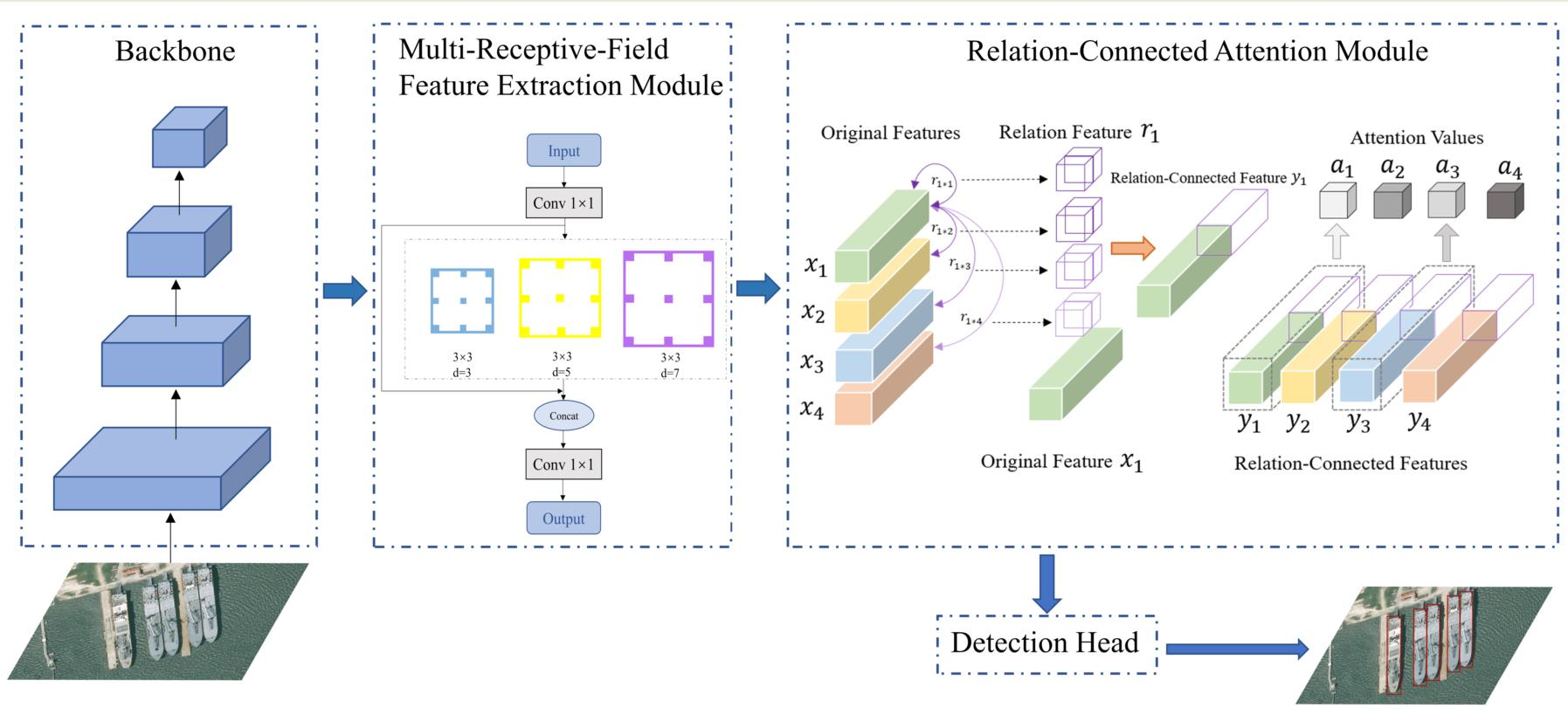
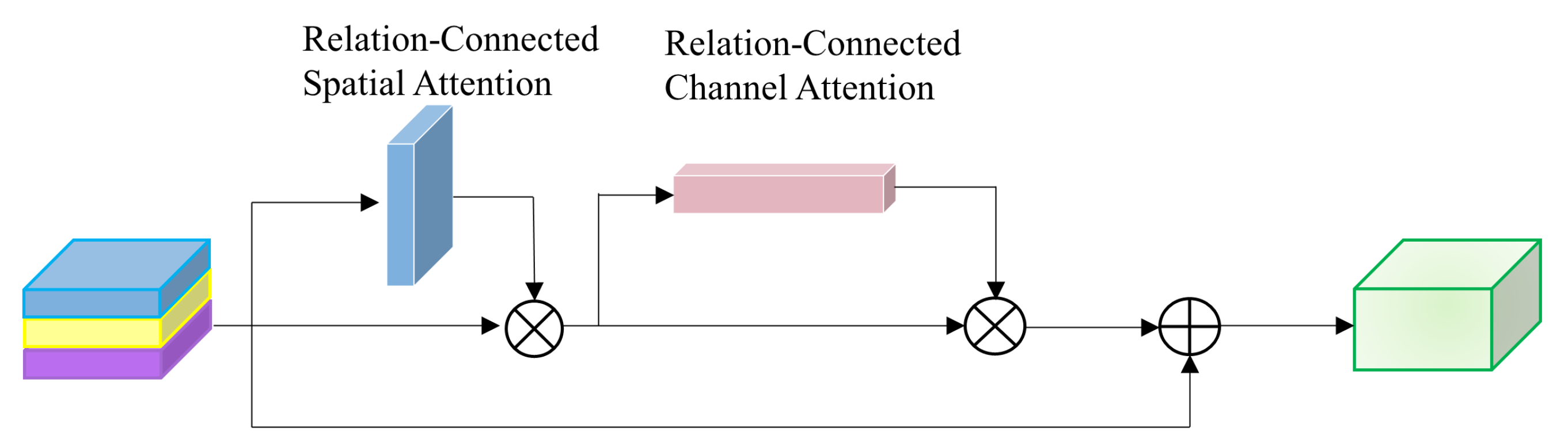
3.3. Relation-Connected Attention Module
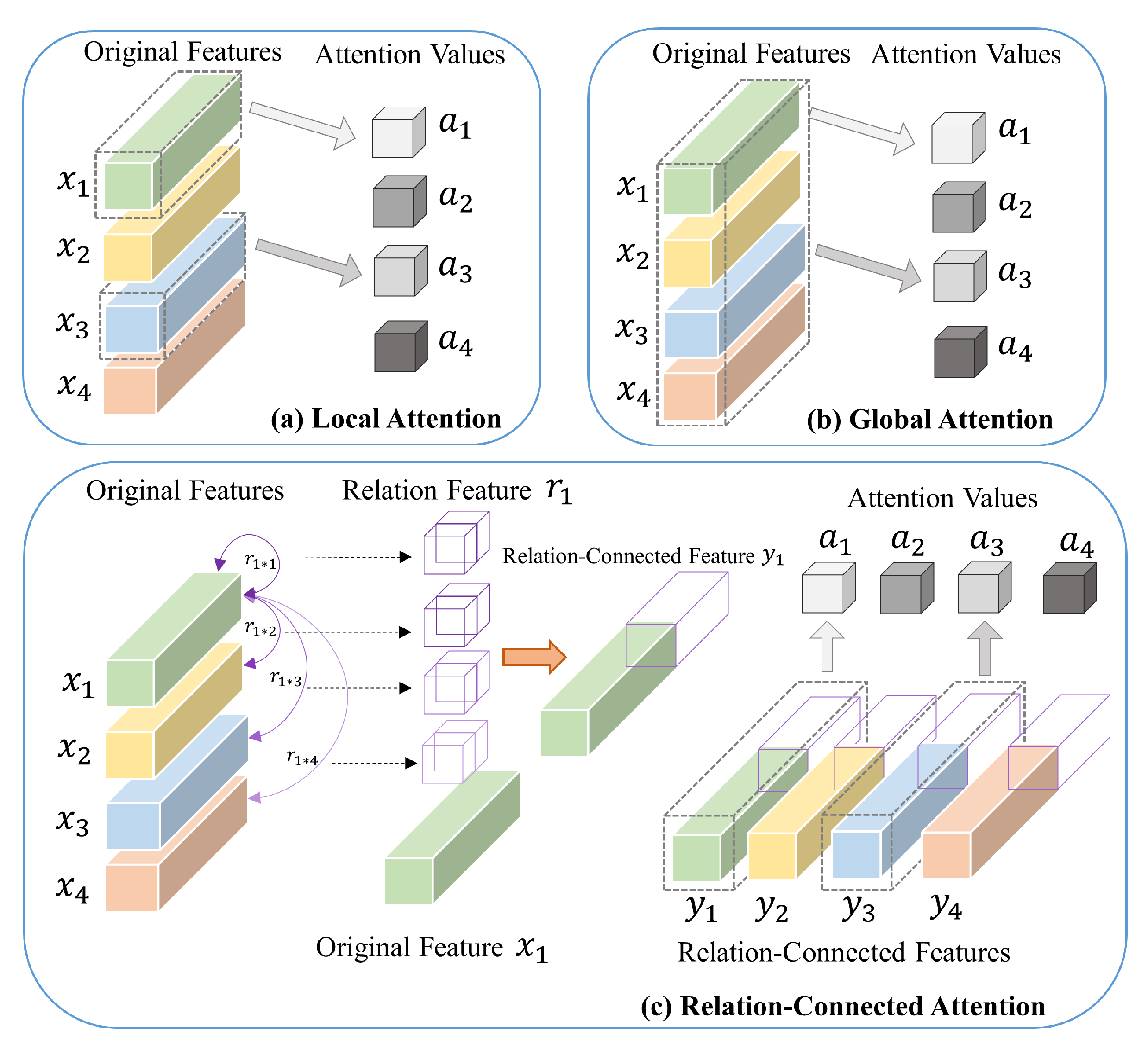
3.3.1. Main Idea of RC-AM
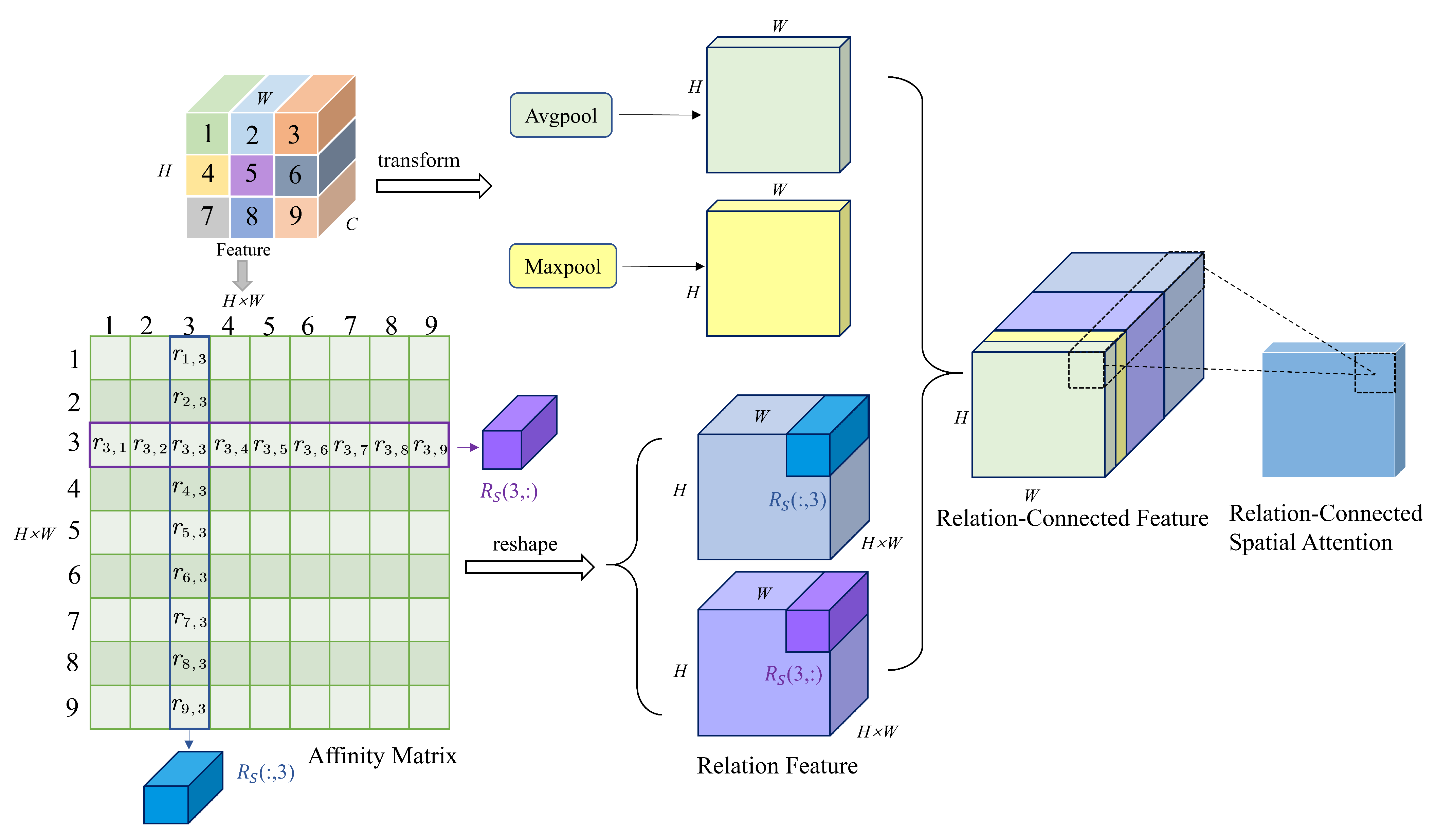
3.3.2. Relation-Connected Spatial Attention Module
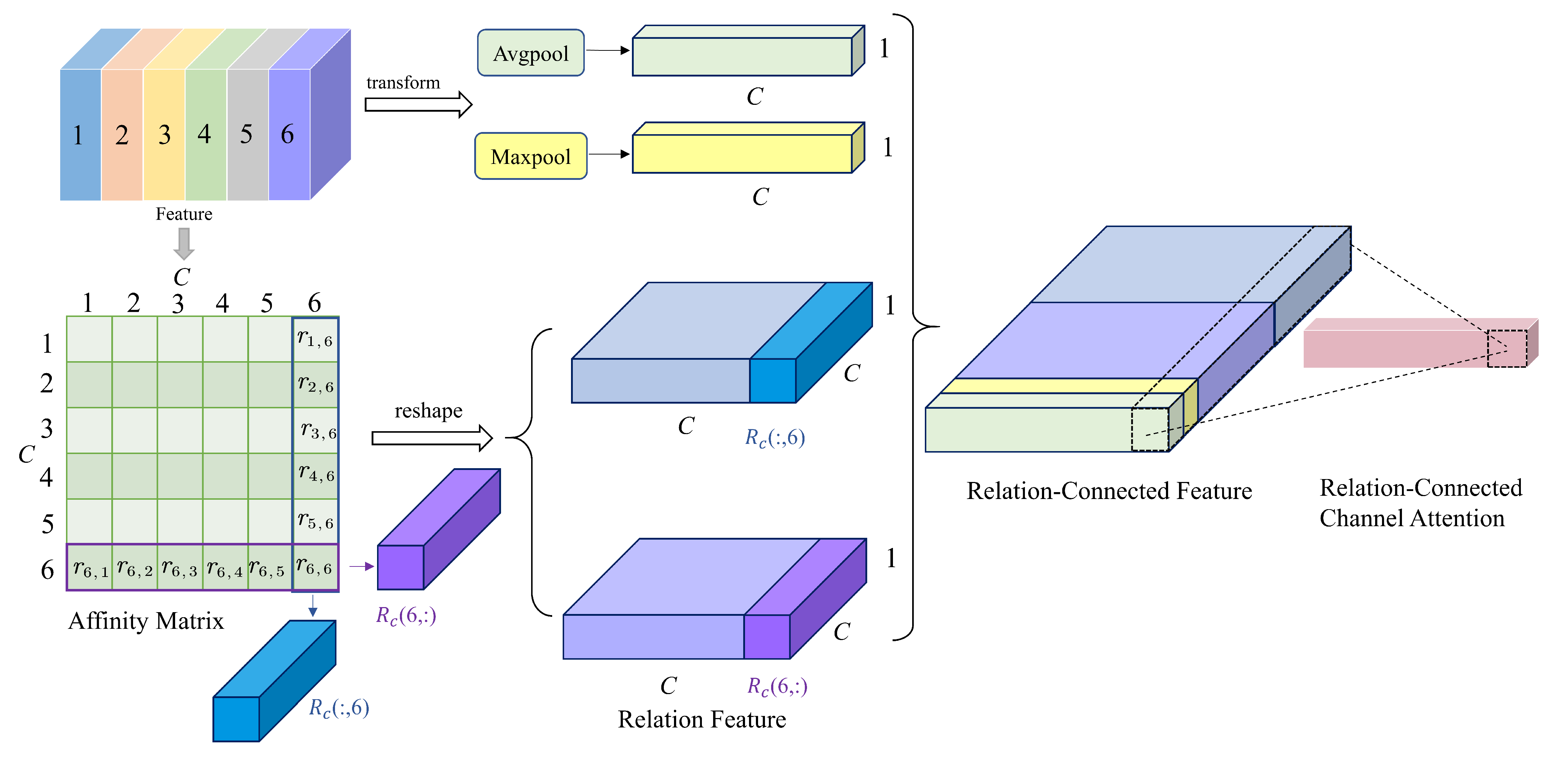
3.3.3. Relation-Connected Channel Attention Module
3.4. Loss Function
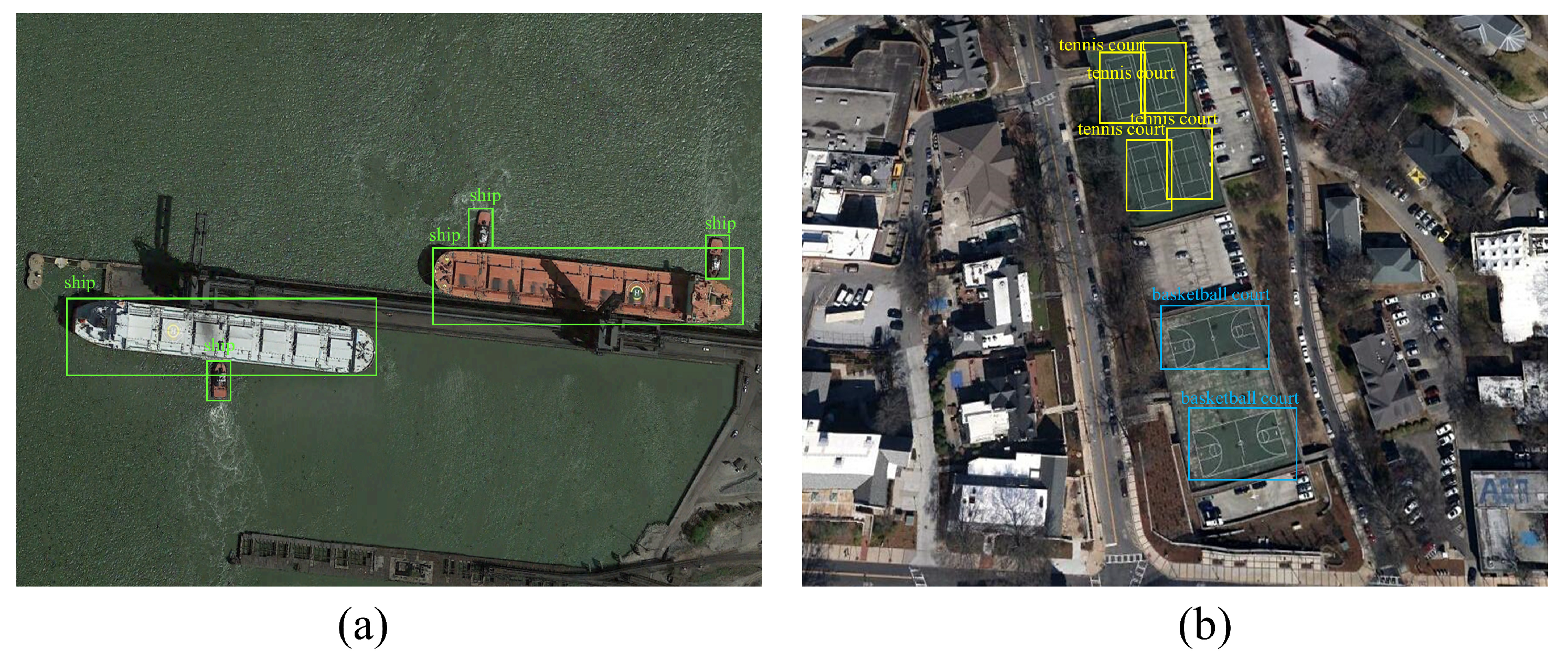
4. Experiments and Results
4.1. Dataset
4.2. Implementation Details
4.3. Evaluation Criteria
4.4. Comparisons with State-of-the-Art Methods
4.4.1. NWPU VHR-10 Dataset Results
4.4.2. HRSC2016 Dataset Results
4.5. Discussion
4.5.1. Ablation Study on NWPU VHR-10 Dataset
4.5.2. Ablation Study on HRSC2016 Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Su, H.; Wei, S.; Liu, S.; Liang, J.; Wang, C.; Shi, J.; Zhang, X. HQ-ISNet: High-quality instance segmentation for remote sensing imagery. Remote Sens. 2020, 12, 989. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Liu, J.; Xu, F. Ship detection in optical remote sensing images based on saliency and a rotation-invariant descriptor. Remote Sens. 2018, 10, 400. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 30 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 2117–2125. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 28–22 June 2018; pp. 4203–4212. [Google Scholar]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection snip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 28–22 June 2018; pp. 3578–3587. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. Sniper: Efficient multi-scale training. arXiv 2018, arXiv:1805.09300. [Google Scholar]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-merged single-shot detection for multiscale objects in large-scale remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3377–3390. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 28–22 June 2018; pp. 8759–8768. [Google Scholar]
- Guan, W.; Zou, Y.; Zhou, X. Multi-scale object detection with feature fusion and region objectness network. In Proceedings of the2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2596–2600. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 8232–8241. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6054–6063. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 28–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11531–11539. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 28–22 June 2018; pp. 7794–7803. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, SCITEPRESS, Porto, Portugal, 24–26 February 2017; Volume 2, pp. 324–331. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2cnn: Rotational region cnn for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimedia 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Airplane | Ship | ST | BD | TC | BC | GTF | Harbor | Bridge | Vehicle | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RICNN [30] | 88.35 | 77.34 | 85.27 | 88.12 | 40.83 | 58.45 | 86.73 | 68.60 | 61.51 | 71.70 | 72.63 |
| SSD512 [6] | 90.40 | 60.90 | 79.80 | 89.90 | 82.60 | 80.60 | 98.30 | 73.40 | 76.70 | 52.10 | 78.40 |
| R-FCN [13] | 81.70 | 80.60 | 66.20 | 90.30 | 80.20 | 69.70 | 89.80 | 78.60 | 47.80 | 78.30 | 76.30 |
| Faster R-CNN [5] | 94.60 | 82.30 | 65.32 | 95.50 | 81.90 | 89.70 | 92.40 | 72.40 | 57.50 | 77.80 | 80.90 |
| FMSSD [18] | 99.70 | 89.90 | 90.30 | 98.20 | 86.00 | 96.80 | 99.60 | 75.60 | 80.10 | 88.20 | 90.40 |
| Ours | 99.50 | 88.40 | 90.20 | 98.70 | 89.20 | 95.40 | 99.20 | 89.60 | 82.20 | 92.90 | 92.50 |
| Method | Backbone | Image Size | mAP |
|---|---|---|---|
| R2CNN [33] | ResNet101 | 800 × 800 | 73.07 |
| RRPN [34] | ResNet101 | 800 × 800 | 79.08 |
| SCRDet [21] | ResNet101 | 512 × 800 | 83.41 |
| RoI Trans [35] | ResNet101 | 512 × 800 | 86.20 |
| Gliding Vertex [36] | ResNet101 | 512 × 800 | 88.20 |
| Ours | ResNet50 | 800 × 800 | 88.92 |
| Ours | ResNet101 | 800 × 800 | 89.24 |
| Method | Airplane | Ship | ST | BD | TC | BC | GTF | Harbor | Bridge | Vehicle | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 94.60 | 82.30 | 65.32 | 95.50 | 81.90 | 89.70 | 92.40 | 72.40 | 57.50 | 77.80 | 80.90 |
| +MR-FEM | 95.84 | 86.36 | 80.64 | 95.62 | 82.40 | 89.82 | 92.62 | 82.10 | 64.20 | 86.42 | 85.60 |
| +RC-AM | 98.40 | 85.20 | 86.20 | 96.20 | 87.32 | 93.44 | 92.46 | 83.42 | 77.34 | 83.50 | 88.35 |
| Ours | 99.50 | 88.40 | 90.20 | 98.70 | 89.20 | 95.40 | 99.20 | 89.60 | 82.20 | 92.90 | 92.50 |
| Method | Precision | Recall | F1-Score | mAP |
|---|---|---|---|---|
| Baseline (ResNet-50) | 85.42 | 86.88 | 86.14 | 84.20 |
| +MR-FEM | 87.30 | 88.25 | 87.77 | 85.44 |
| +RC-AM | 90.87 | 90.24 | 90.55 | 87.68 |
| +MR-FEM+RC-AM | 92.68 | 91.52 | 92.10 | 88.92 |
| Method | Precision | Recall | F1-Score | mAP |
|---|---|---|---|---|
| Baseline + MR-FEM | 87.30 | 88.25 | 87.77 | 85.44 |
| +SE [23] | 87.92 | 89.02 | 88.47 | 87.29 |
| +CBAM [24] | 88.54 | 89.24 | 88.89 | 87.64 |
| +Non-local [26] | 89.81 | 90.36 | 90.08 | 87.95 |
| +ECA [25] | 88.63 | 89.30 | 88.96 | 87.70 |
| +RC-AM (ours) | 92.68 | 91.52 | 92.10 | 88.92 |
| Method | Precision | Recall | F1-Score | mAP |
|---|---|---|---|---|
| Baseline + MR-FEM | 87.30 | 88.25 | 87.77 | 85.44 |
| +RC-AM_C | 88.67 | 88.82 | 88.74 | 87.05 |
| +RC-AM_S | 88.25 | 88.70 | 88.47 | 86.20 |
| +RC-AM_S//C | 89.23 | 89.78 | 89.50 | 87.62 |
| +RC-AM_CS | 90.80 | 90.24 | 90.52 | 88.76 |
| +RC-AM_SC (ours) | 92.68 | 91.52 | 92.10 | 88.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Yang, D.; Hu, F. Multiscale Object Detection in Remote Sensing Images Combined with Multi-Receptive-Field Features and Relation-Connected Attention. Remote Sens. 2022, 14, 427. https://doi.org/10.3390/rs14020427
Liu J, Yang D, Hu F. Multiscale Object Detection in Remote Sensing Images Combined with Multi-Receptive-Field Features and Relation-Connected Attention. Remote Sensing. 2022; 14(2):427. https://doi.org/10.3390/rs14020427
Chicago/Turabian StyleLiu, Jiahang, Donghao Yang, and Fei Hu. 2022. "Multiscale Object Detection in Remote Sensing Images Combined with Multi-Receptive-Field Features and Relation-Connected Attention" Remote Sensing 14, no. 2: 427. https://doi.org/10.3390/rs14020427