
Small Object Detection Method Based on Adaptive Spatial Parallel Convolution and Fast Multi-Scale Fusion

 , , ,
, , ,
Abstract
:
1. Introduction
- This paper proposes an adaptive feature extraction method using multi-scale receptive fields. Due to the small proportion in the image and inconspicuous features, the spatial information of small objects is always missing. The proposed method divides the input feature map equally among the channels and performs feature extraction on the separated feature channels in parallel. Additionally, the cascading relationship of multiple convolution kernels is used to achieve the effective extraction of local context information for different channels. Therefore, the features related to small objects with multi-scale spatial environmental information can be obtained by fusing the extracted information.
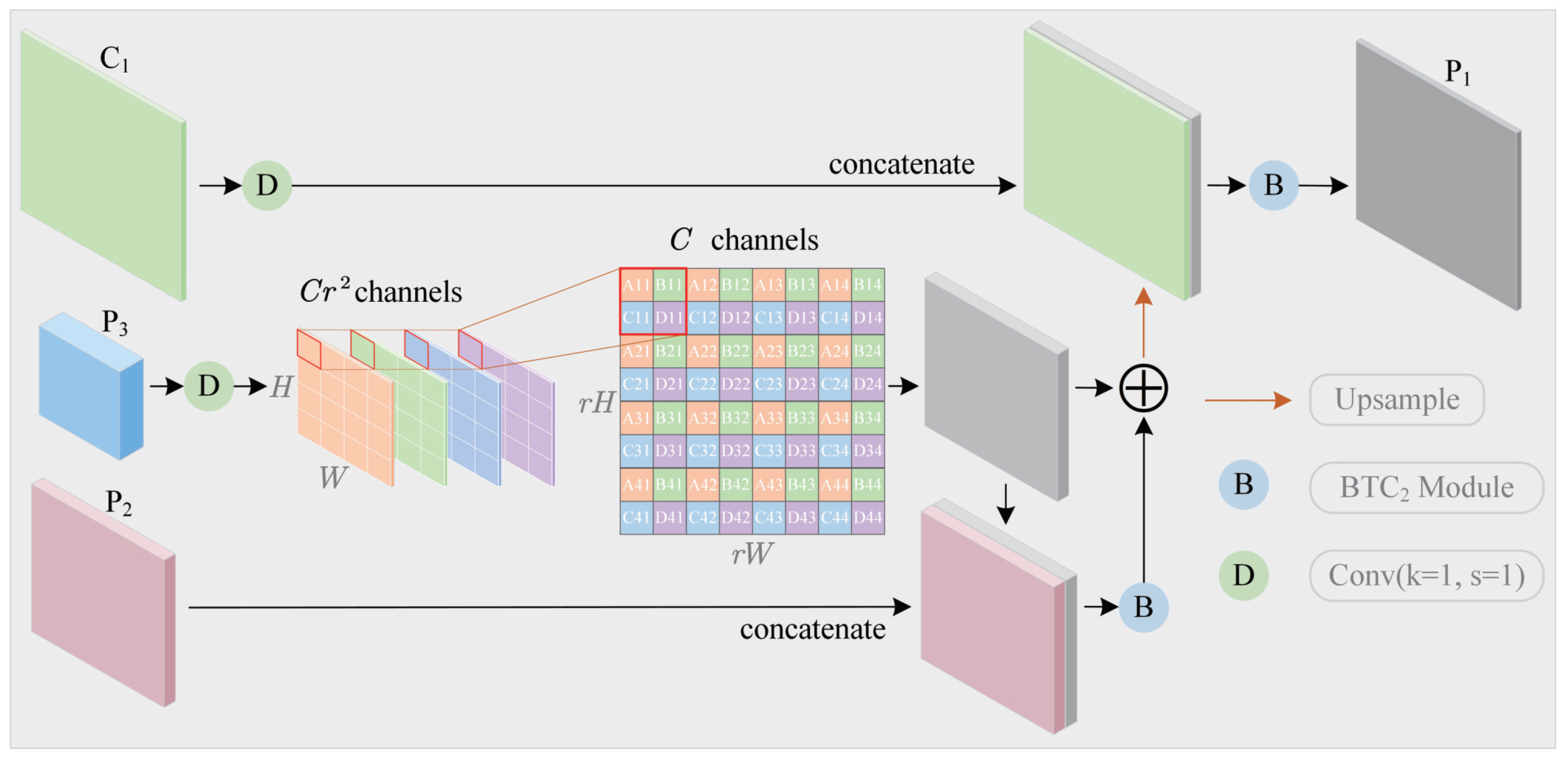
- This paper proposes a new feature map upsampling and multi-scale feature fusion method. This method uses both nearest-neighbor interpolation and sub-pixel convolution algorithm to map a low-resolution feature map with rich semantic information to a high-resolution space, thereby constructing a high-resolution feature map with rich semantic features. A feature map with sufficient spatial and semantic information is obtained by the fusion of the constructed feature map and a feature map with rich spatial information, thereby improving the detection ability of small objects.
- This paper designs a one-stage, real-time detection framework of small objects. The ASPConv module is proposed to extract image features from multiple channels in parallel, which effectively reduces the time complexity of feature extraction to achieve real-time small object detection. The FMF module is proposed to apply both nearest-neighbor interpolation and sub-pixel convolution to achieve a fast upsampling. The processing time of multi-scale feature map fusion is reduced by improving upsampling efficiency to ensure real-time small object detection.
2. Related Work
3. The Proposed Method
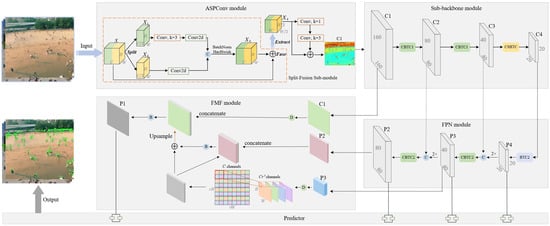
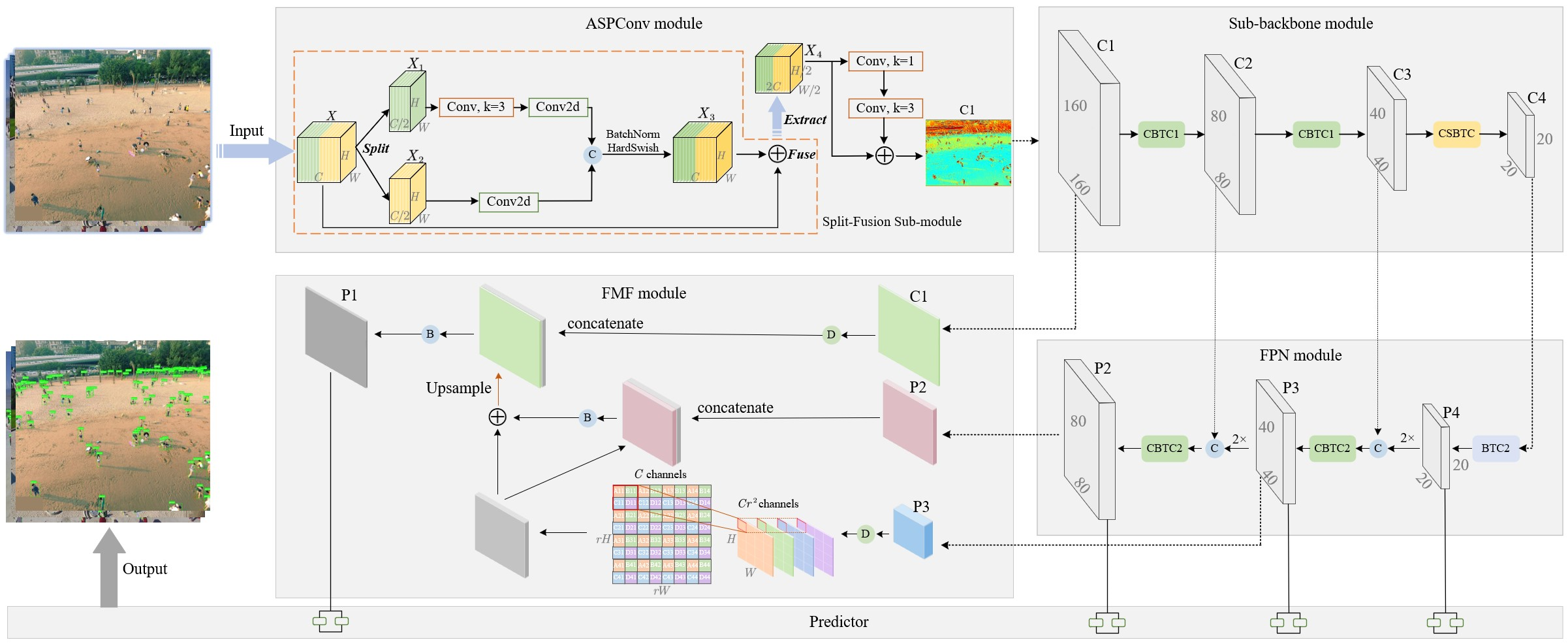
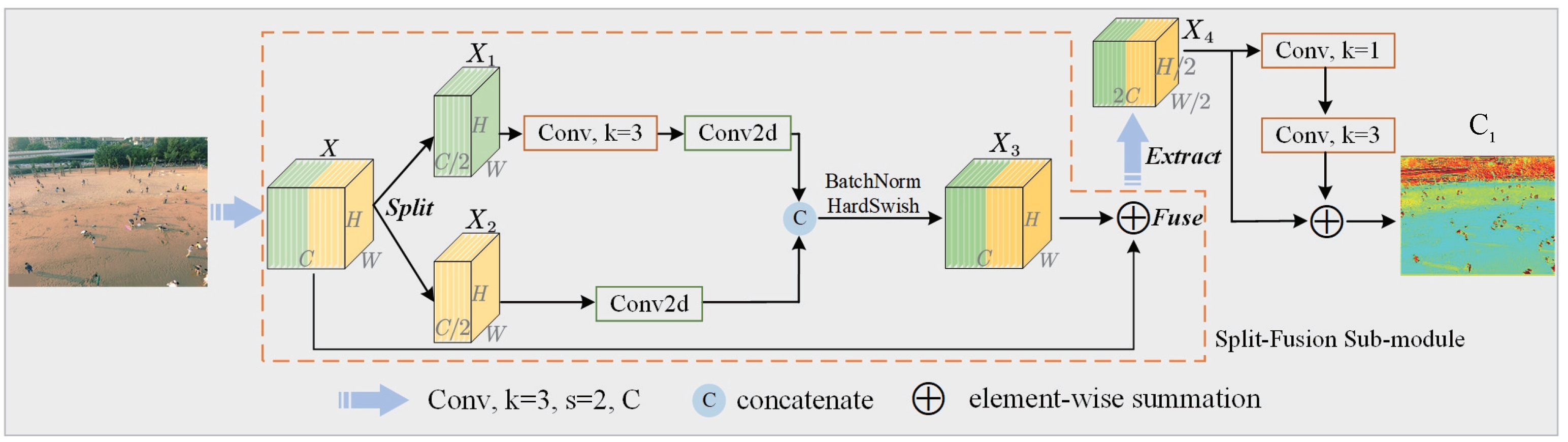
3.1. Adaptively Spatial Parallel Convolution Module
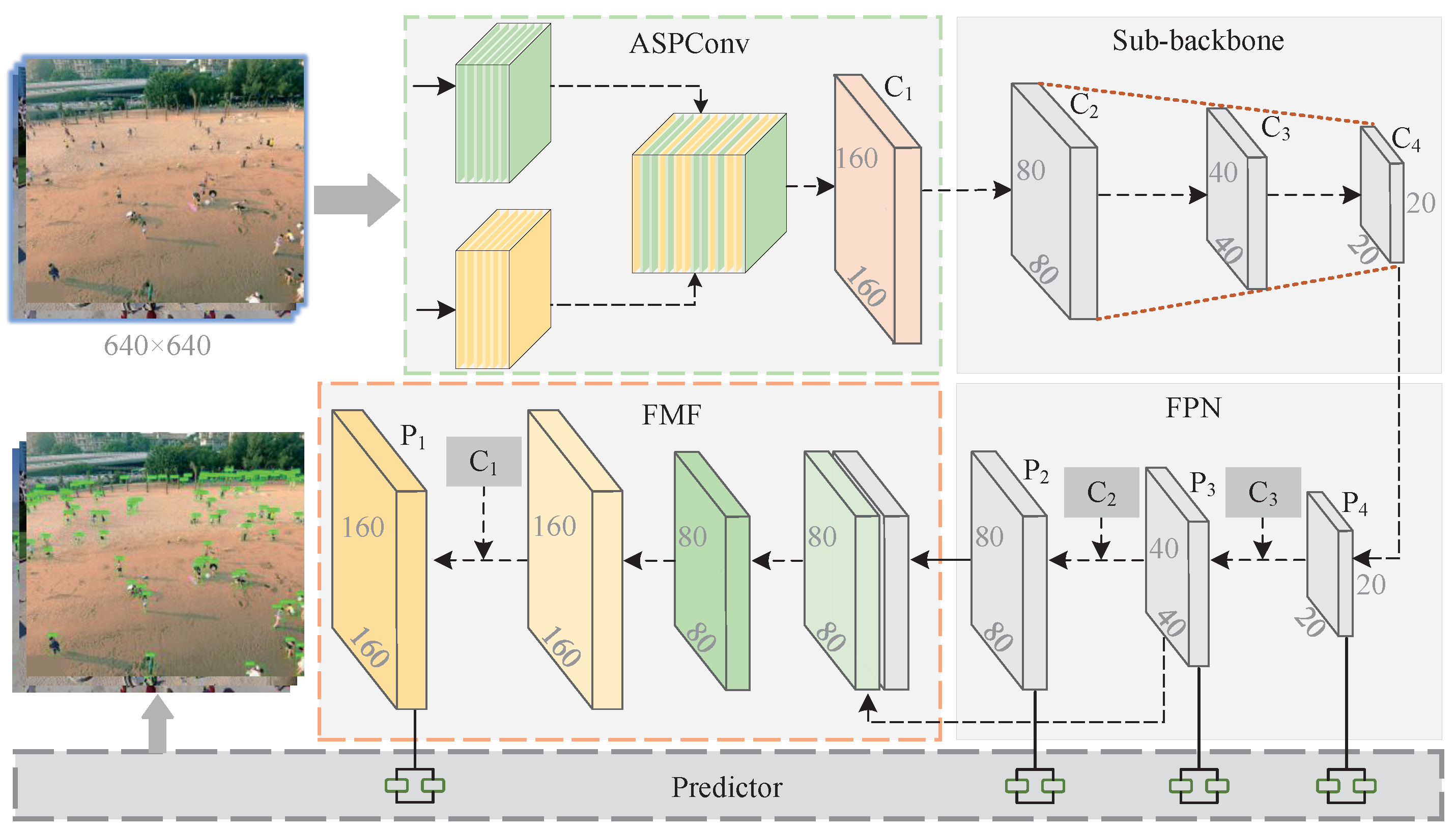
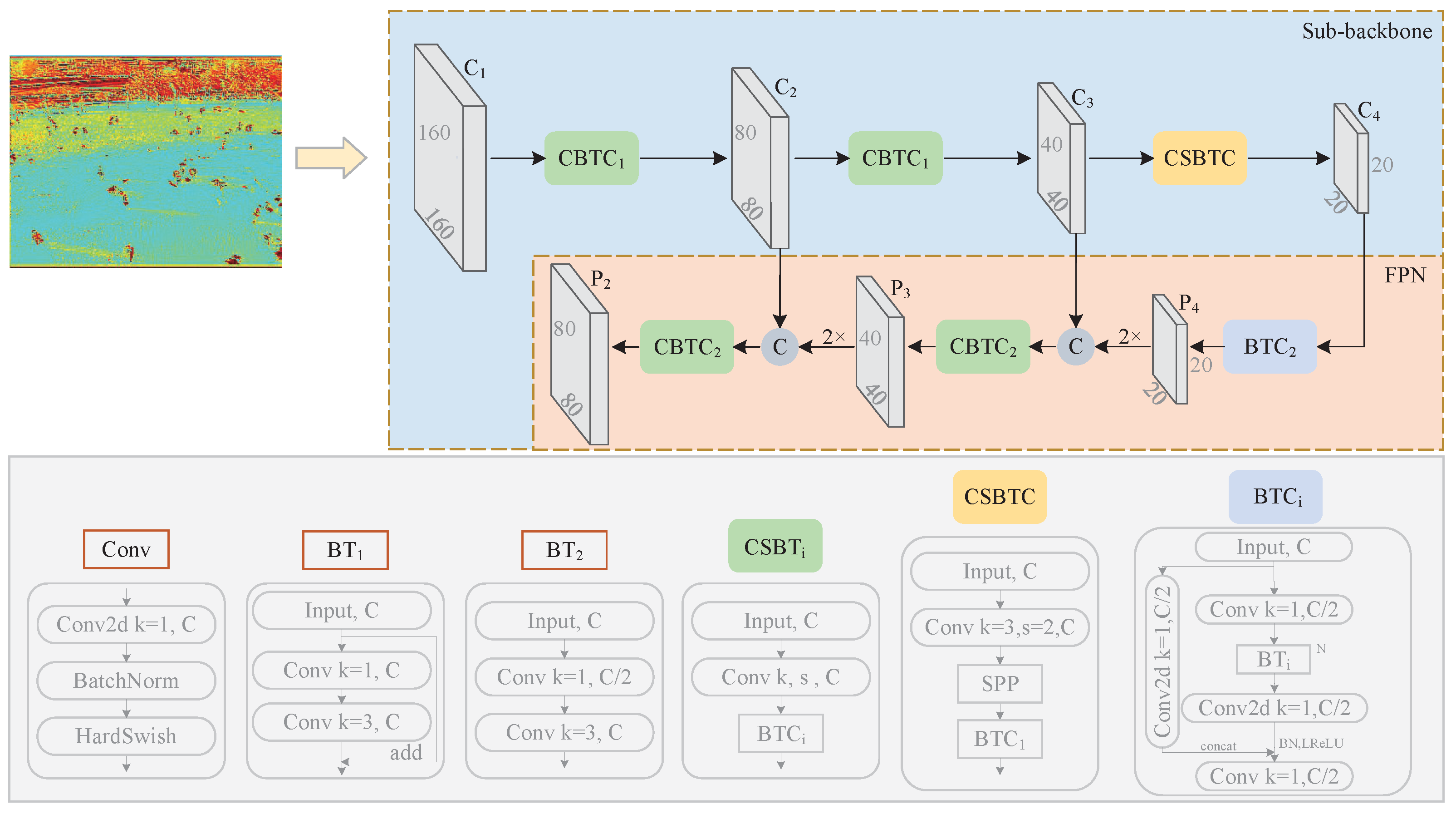
3.2. Proposed Backbone Module
3.3. Fast Multi-Scale Fusion Module
3.4. Predictor
4. Experiments
4.1. Experiment Preparation
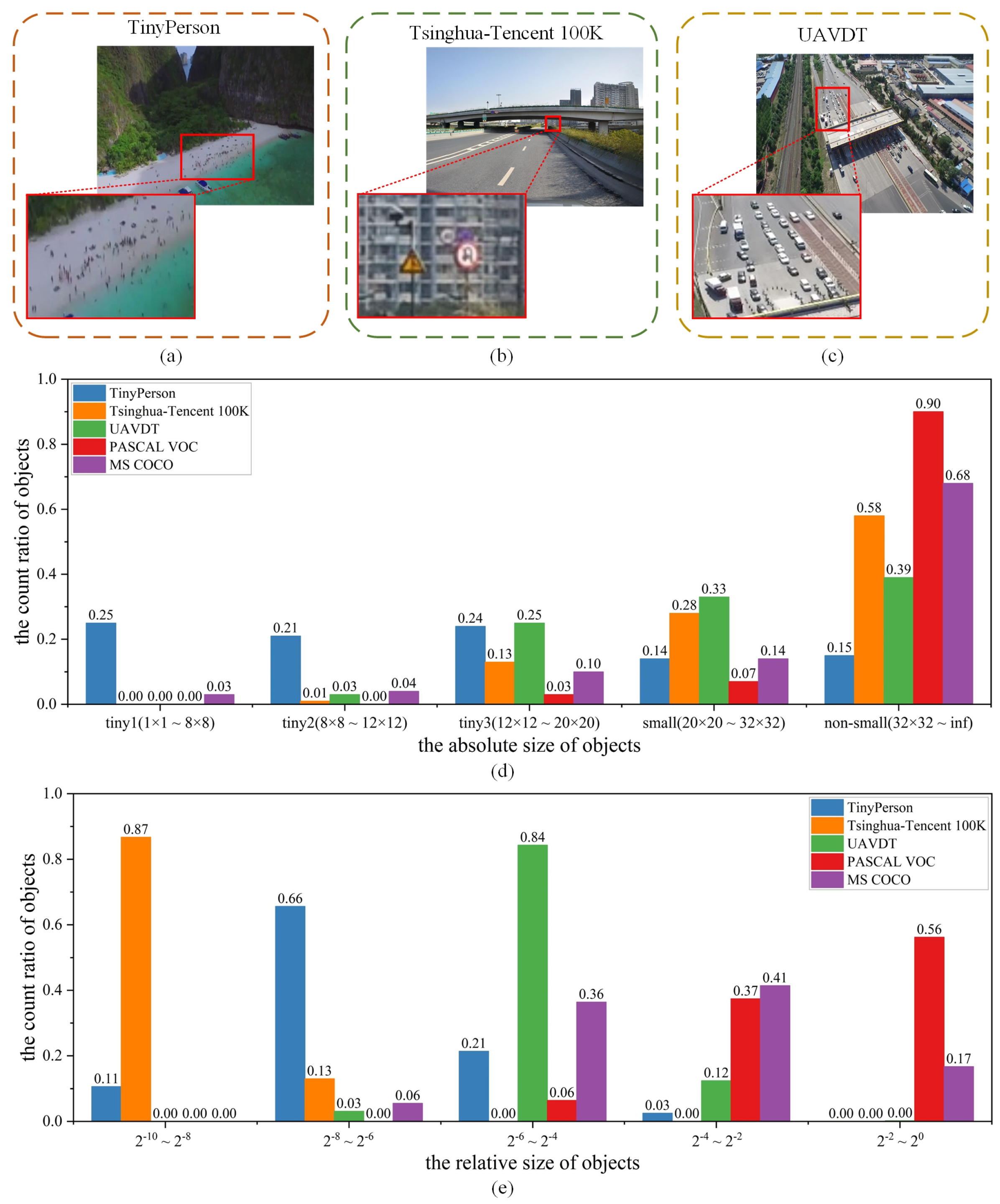
4.1.1. Datasets and Evaluation Metrics
4.1.2. Implementation Details
4.2. Experiment Preparation
4.3. Real-Time Comparison
4.4. Ablation Study
4.5. Qualitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7363–7372. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-yolov4: Scaling cross stage partial network. arXiv 2011, arXiv:2011.08036. [Google Scholar]
- Jocher, G.; Nishimura, K.; Mineeva, T. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 September 2021).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Qi, G.; Wang, H.; Haner, M.; Weng, C.; Chen, S.; Zhu, Z. Convolutional neural network based detection and judgement of environmental obstacle in vehicle operation. CAAI Trans. Intell. Technol. 2019, 4, 80–91. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 2980–2988. [Google Scholar]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale match for tiny person detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1246–1254. [Google Scholar]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2110–2118. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Shuang, K.; Lyu, Z.; Loo, J.; Zhang, W. Scale-balanced loss for object detection. Pattern Recognit. 2021, 117, 107997. [Google Scholar] [CrossRef]
- Ma, W.; Wu, Y.; Cen, F.; Wang, G. Mdfn: Multi-scale deep feature learning network for object detection. Pattern Recognit. 2020, 100, 107149. [Google Scholar] [CrossRef] [Green Version]
- Bosquet, B.; Mucientes, M.; Brea, V.M. Stdnet-st: Spatio-temporal convnet for small object detection. Pattern Recognit. 2021, 116, 107929. [Google Scholar] [CrossRef]
- Kong, Y.; Feng, M.; Li, X.; Lu, H.; Liu, X.; Yin, B. Spatial context-aware network for salient object detection. Pattern Recognit. 2021, 114, 107867. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Qi, G.-J. Hierarchically gated deep networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2267–2275. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Zhu, Z.; Luo, Y.; Wei, H.; Li, Y.; Qi, G.; Mazur, N.; Li, Y.; Li, P. Atmospheric Light Estimation Based Remote Sensing Image Dehazing. Remote Sens. 2021, 13, 2432. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Zheng, M.; Qi, G.; Zhu, Z.; Li, Y.; Wei, H.; Liu, Y. Image Dehazing by an Artificial Image Fusion Method Based on Adaptive Structure Decomposition. IEEE Sens. J. 2020, 20, 8062–8072. [Google Scholar] [CrossRef]
- Zhu, Z.; Luo, Y.; Qi, G.; Meng, J.; Li, Y.; Mazur, N. Remote Sensing Image Defogging Networks Based on Dual Self-Attention Boost Residual Octave Convolution. Remote Sens. 2021, 13, 3104. [Google Scholar] [CrossRef]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 1222–1230. [Google Scholar]
- Noh, J.; Bae, W.; Lee, W.; Seo, J.; Kim, G. Better to follow, follow to be better: Towards precise supervision of feature super-resolution for small object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9725–9734. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Zhang, Z.; Wang, Z.; Lin, Z.; Qi, H. Image super-resolution by neural texture transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7982–7991. [Google Scholar]
- Zhu, Z.; Wei, H.; Hu, G.; Li, Y.; Qi, G.; Mazur, N. A Novel Fast Single Image Dehazing Algorithm Based on Artificial Multiexposure Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–23. [Google Scholar] [CrossRef]
- Islam, M.A.; Rochan, M.; Bruce, N.D.; Wang, Y. Gated feedback refinement network for dense image labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 3751–3759. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. arXiv 2017, arXiv:1701.04128. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. Dc-spp-yolo: Dense connection and spatial pyramid pooling based yolo for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef] [Green Version]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y. Extended feature pyramid network for small object detection. arXiv 2003, arXiv:2003.07021. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Gong, Y.; Yu, X.; Ding, Y.; Peng, X.; Zhao, J.; Han, Z. Effective fusion factor in fpn for tiny object detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual, 5–9 January 2021; pp. 1160–1168. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Liang, X.; Zhang, J.; Zhuo, L.; Li, Y.; Tian, Q. Small object detection in unmanned aerial vehicle images using feature fusion and scaling-based single shot detector with spatial context analysis. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1758–1770. [Google Scholar] [CrossRef]
- Meng, Z.; Fan, X.; Chen, X.; Chen, M.; Tong, Y. Detecting small signs from large images. In Proceedings of the 18th IEEE International Conference on Information Reuse and Integration (IRI), San Diego, CA, USA, 4–6 August 2017; pp. 217–224. [Google Scholar]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. Ron: Reverse connection with objectness prior networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 5936–5944. [Google Scholar]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered object detection in aerial images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8311–8320. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Layer Components | |
|---|---|---|
| Yolov5s [9] | SODNet (Proposed) | |
| Focus [9] | ASPConv (Proposed) | |
| CBTC1 () | ||
| () | () | |
| () | () | |
| () | () | |
| // | PANet [28] | FPN [27] |
| - | FMF (Proposed) | |
| Methods | |||||||
|---|---|---|---|---|---|---|---|
| Libra RCNN [5] | 89.22 | 90.93 | 84.64 | 81.62 | 74.86 | 82.44 | 98.39 |
| Grid RCNN [7] | 87.96 | 88.31 | 82.79 | 79.55 | 73.16 | 78.27 | 98.21 |
| FRCNN-FPN [27] | 87.57 | 87.86 | 82.02 | 78.78 | 72.56 | 76.59 | 98.39 |
| FRCNN-FPN-SM [14] | 86.22 | 87.14 | 79.60 | 76.14 | 68.59 | 74.16 | 98.28 |
| FRCNN-FPN-SM [47] | 85.96 | 86.57 | 79.14 | 77.22 | 69.35 | 73.92 | 98.30 |
| FCOS [48] | 96.28 | 99.23 | 96.56 | 91.67 | 84.16 | 90.34 | 99.56 |
| SSD512 [4] | 93.56 | 94.55 | 90.42 | 85.54 | 76.79 | 82.80 | 99.23 |
| FS-SSD512 [49] | 94.01 | 93.98 | 91.18 | 86.01 | 78.10 | 83.78 | 99.35 |
| RetinaNet [13] | 92.66 | 94.52 | 88.24 | 86.52 | 82.84 | 81.95 | 99.13 |
| RetinaNet-MSM [14] | 88.39 | 87.80 | 79.23 | 79.77 | 72.18 | 76.25 | 98.57 |
| RetinaNet-SM [47] | 87.00 | 87.62 | 79.47 | 77.39 | 69.25 | 74.72 | 98.41 |
| Scaled-YOLOv4-CSP [8] | 86.77 | 87.36 | 79.76 | 76.04 | 67.69 | 73.03 | 98.25 |
| YOLOv5s [9] | 85.98 | 87.73 | 80.09 | 75.26 | 68.77 | 72.32 | 98.23 |
| SODNet (Proposed) | 83.30 | 82.99 | 76.30 | 72.29 | 68.05 | 67.52 | 98.04 |
| Methods | |||||||
|---|---|---|---|---|---|---|---|
| Libra RCNN [5] | 44.68 | 27.08 | 49.27 | 55.21 | 62.65 | 64.77 | 6.26 |
| Grid RCNN [7] | 47.14 | 30.65 | 52.21 | 57.21 | 62.48 | 68.89 | 6.38 |
| FRCNN-FPN [27] | 47.35 | 30.25 | 51.58 | 58.95 | 63.18 | 68.43 | 5.83 |
| FRCNN-FPN-SM [14] | 51.33 | 33.91 | 55.16 | 62.58 | 66.96 | 71.55 | 6.46 |
| FRCNN-FPN-SM [47] | 51.76 | 34.58 | 55.93 | 62.31 | 66.81 | 72.19 | 6.81 |
| FCOS [48] | 17.90 | 2.88 | 12.95 | 31.15 | 40.54 | 41.95 | 1.50 |
| SSD512 [4] | 34.00 | 13.54 | 35.16 | 48.73 | 57.14 | 61.21 | 2.52 |
| FS-SSD512 [49] | 34.10 | 14.11 | 36.17 | 49.50 | 56.37 | 61.58 | 2.13 |
| RetinaNet [13] | 33.53 | 12.24 | 38.79 | 47.38 | 48.26 | 61.51 | 2.28 |
| RetinaNet-MSM [14] | 49.59 | 31.63 | 56.01 | 60.78 | 63.38 | 71.24 | 6.16 |
| RetinaNet-SM [47] | 52.56 | 33.90 | 58.00 | 63.72 | 65.69 | 73.09 | 6.64 |
| Scaled-YOLOv4-CSP [8] | 51.25 | 33.07 | 56.04 | 61.94 | 65.39 | 73.31 | 7.04 |
| YOLOv5s [9] | 49.61 | 32.21 | 52.11 | 60.95 | 64.23 | 71.51 | 6.63 |
| SODNet (Proposed) | 55.55 | 40.53 | 59.52 | 64.62 | 66.22 | 75.98 | 7.61 |
| Methods | Small | Medium | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|
| FRCNN [2] +ResNet101 [41] | 80.3 | 81.6 | 80.9 | 94.5 | 94.8 | 94.7 | 89.1 | 89.7 | 89.4 |
| Zhu et al. [15] | 87.0 | 82.0 | 84.4 | 94.0 | 91.0 | 92.5 | - | - | - |
| Perceptual GAN [33] | 89.0 | 84.0 | 86.4 | 96.0 | 91.0 | 93.4 | - | - | - |
| EFPN [45] | 87.1 | 83.6 | 85.3 | 95.2 | 95.0 | 95.1 | - | - | - |
| SOS-CNN [50] | - | - | - | - | - | - | 93.0 | 90.0 | 91.5 |
| Noh et al. [34] | 92.6 | 84.9 | 88.6 | 97.5 | 94.5 | 96.0 | 95.7 | 90.6 | 93.1 |
| YOLOv5s [9] | 88.7 | 84.1 | 86.3 | 95.6 | 94.7 | 95.2 | 92.9 | 90.0 | 91.4 |
| SODNet (Proposed) | 90.0 | 85.5 | 87.6 | 96.6 | 95.8 | 96.2 | 94.0 | 91.2 | 92.6 |
| Methods | ||||
|---|---|---|---|---|
| R-FCN [1] | 7.0 | 17.5 | 3.9 | 4.4 |
| SSD512 [4] | 9.3 | 21.4 | 6.7 | 7.1 |
| RON [51] | 5.0 | 15.9 | 1.7 | 2.9 |
| FRCNN [2] | 5.8 | 17.4 | 2.5 | 3.8 |
| FRCNN-FPN [27] | 11.0 | 23.4 | 8.4 | 8.1 |
| ClusDet [52] | 13.7 | 26.5 | 12.5 | 9.1 |
| YOLOv5s [9] | 12.3 | 22.4 | 12.4 | 9.8 |
| SODNet (Proposed) | 17.1 | 29.9 | 18.0 | 11.9 |
| Methods | ||||||
|---|---|---|---|---|---|---|
| R-FCN [1] | 29.9 | 51.9 | - | 10.8 | 32.8 | 45.0 |
| SSD512 [4] | 28.8 | 48.5 | 30.3 | 10.9 | 31.8 | 43.5 |
| YOLOv3 [3] | 33.0 | 57.9 | 34.4 | 18.3 | 35.4 | 41.9 |
| FRCNN [2] | 34.9 | 55.7 | 37.4 | 15.6 | 38.7 | 50.9 |
| FRCNN-FPN [27] | 36.2 | 59.1 | 39.0 | 18.2 | 39.0 | 48.2 |
| Noh et al. [34] | 34.2 | 57.2 | 36.1 | 16.2 | 35.7 | 48.1 |
| YOLOv5s [9] | 35.2 | 53.9 | 37.8 | 18.8 | 39.1 | 44.0 |
| SODNet (Proposed) | 36.4 | 56.2 | 39.4 | 20.1 | 40.1 | 45.7 |
| Methods | Default Input Size | FPS | Uniform Input Size | FPS |
|---|---|---|---|---|
| FRCNN-FPN [27] | 13 | 24 | ||
| FRCNN-FPN-SM [14] | 13 | 22 | ||
| SSD512 [4] | 33 | 33 | ||
| FS-SSD512 [49] | 30 | 30 | ||
| RetinaNet-MSM [14] | 10 | 23 | ||
| Scaled-YOLOv4-CSP [8] | 33 | 39 | ||
| YOLOv5s [9] | 88 | 96 | ||
| SODNet (Proposed) | 81 | 91 |
| Methods | TinyPerson | UAVDT | ||||||
|---|---|---|---|---|---|---|---|---|
| Input Size | FPS | Input Size | FPS | |||||
| Baseline YOLOv5s | 85.98 | 49.61 | 88 | 12.3 | 9.8 | 49 | ||
| + ASPConv | 85.46 | 51.60 | 78 | 13.4 | 10.2 | 43 | ||
| + FMF | 84.63 | 53.95 | 92 | 15.1 | 10.8 | 50 | ||
| + ASPConv + FMF | 83.30 | 55.55 | 81 | 17.1 | 11.9 | 45 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, G.; Zhang, Y.; Wang, K.; Mazur, N.; Liu, Y.; Malaviya, D. Small Object Detection Method Based on Adaptive Spatial Parallel Convolution and Fast Multi-Scale Fusion. Remote Sens. 2022, 14, 420. https://doi.org/10.3390/rs14020420
Qi G, Zhang Y, Wang K, Mazur N, Liu Y, Malaviya D. Small Object Detection Method Based on Adaptive Spatial Parallel Convolution and Fast Multi-Scale Fusion. Remote Sensing. 2022; 14(2):420. https://doi.org/10.3390/rs14020420
Chicago/Turabian StyleQi, Guanqiu, Yuanchuan Zhang, Kunpeng Wang, Neal Mazur, Yang Liu, and Devanshi Malaviya. 2022. "Small Object Detection Method Based on Adaptive Spatial Parallel Convolution and Fast Multi-Scale Fusion" Remote Sensing 14, no. 2: 420. https://doi.org/10.3390/rs14020420