

SEAN: A Simple and Efficient Attention Network for Aircraft Detection in SAR Images

Abstract
:1. Introduction
- (1)
- The proposed SEAN is a SAR aircraft target detection network with a simple structure, high accuracy, and high speed. Compared with the typical target detection algorithms from recent years, SEAN has apparent advantages in detection accuracy and speed on the Gaofen-3 dataset.
- (2)
- An appropriate network size is selected to balance the detection accuracy and speed. Then, the backbone network’s depth is explored, proving that the C4 feature of the backbone network is more suitable for aircraft target detection. Furthermore, this paper uses a structural re-parameterization technique on the shallowed backbone to effectively enhance the feature extraction capability.
- (3)
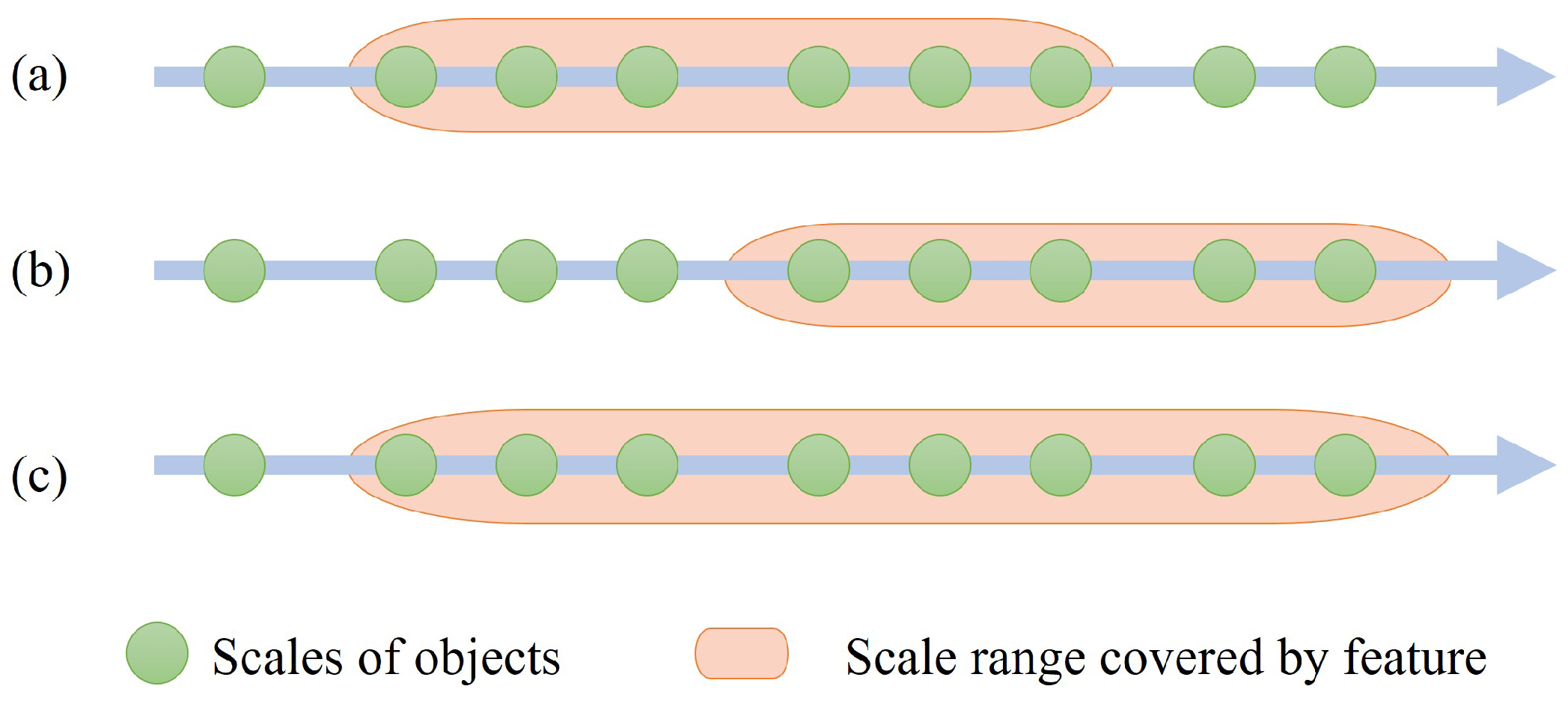
- A simple and efficient neck of the network is designed, discarding the complex feature pyramid network design. It mainly consists of three modules. One is a residual dilated module (RDM) that integrates the multi-scale receptive field. The second is a low-level semantic enhancement module (LSEM) that enhances the scattered information of SAR images. Furthermore, the third is a location attention module (LAM) that refines the multi-feature information after fusion.
2. Related Work
2.1. Deep Learning-Based Object Detection Algorithm
2.2. Structure of the Detector Neck
2.3. Attention Mechanism
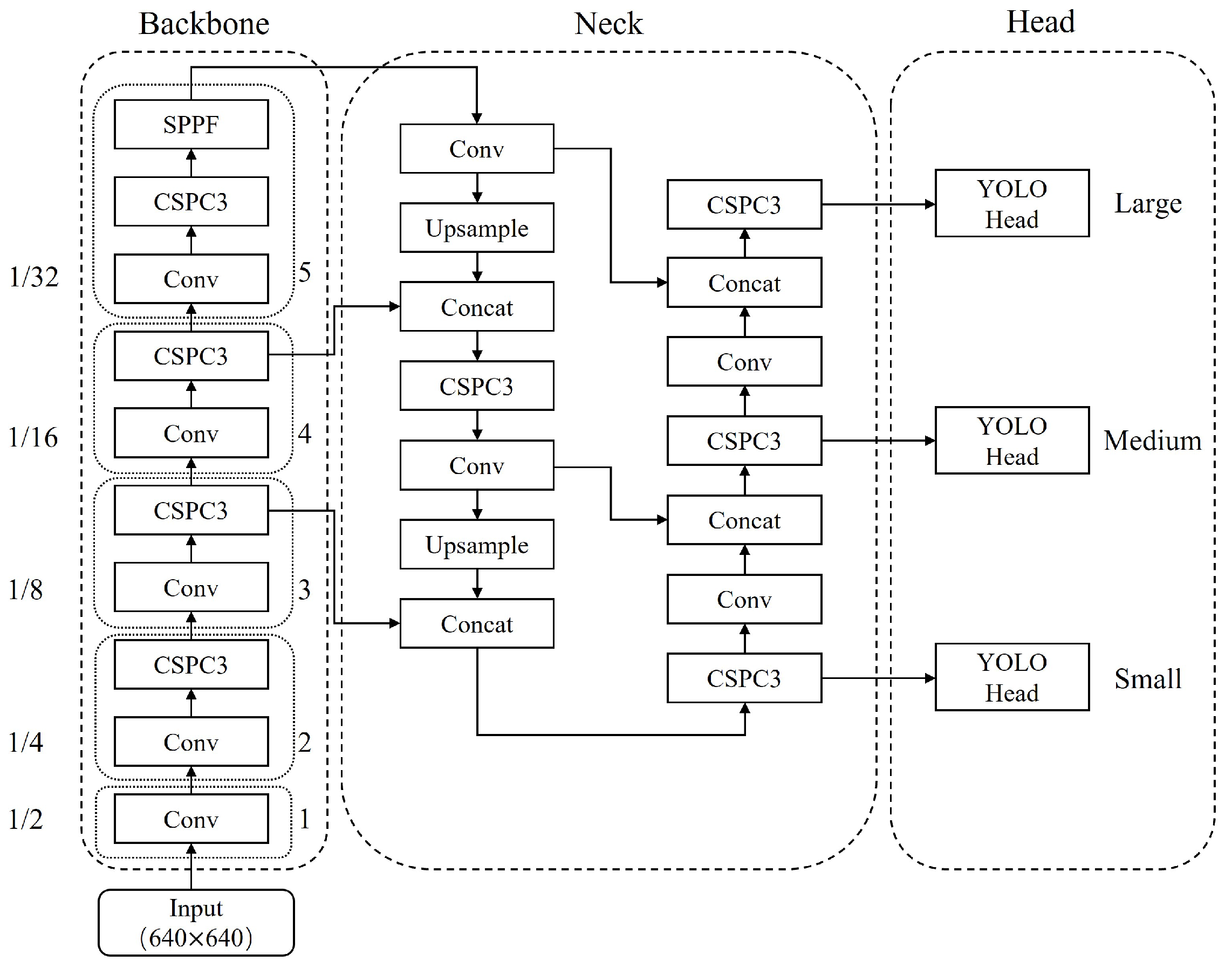
3. Methodology
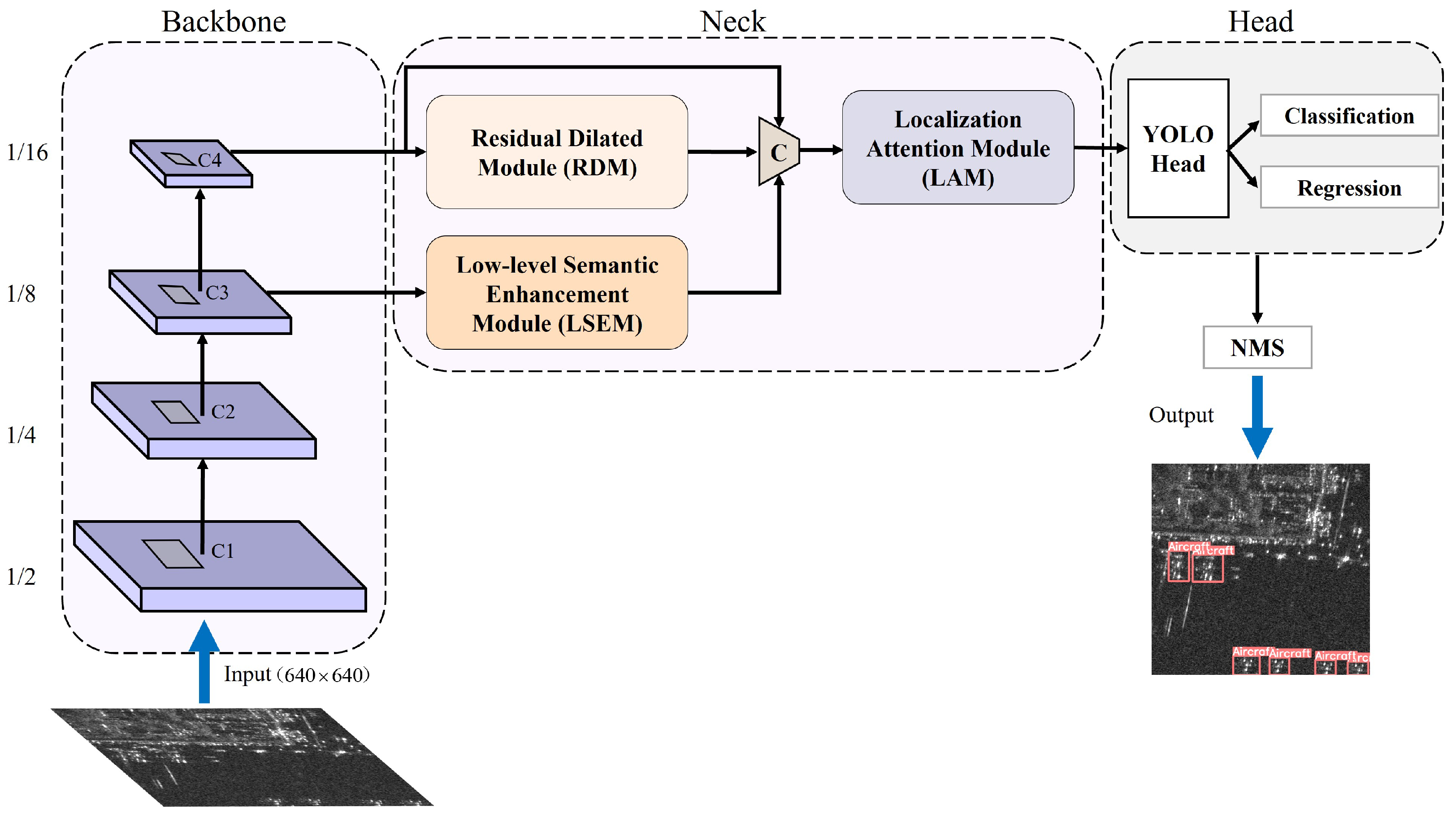
3.1. Overview of the Architecture of the Proposed SEAN
3.2. Optimization of Backbone Network
3.2.1. Shallow Backbone
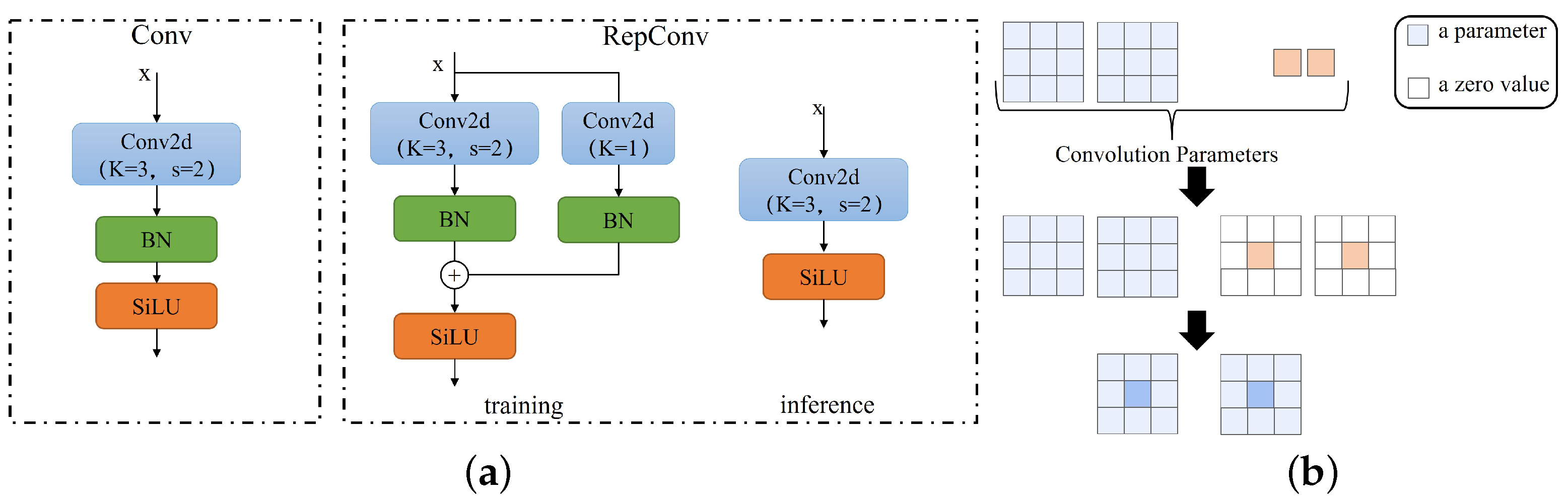
3.2.2. Backbone Re-Parameterization
3.3. Neck Design of SEAN
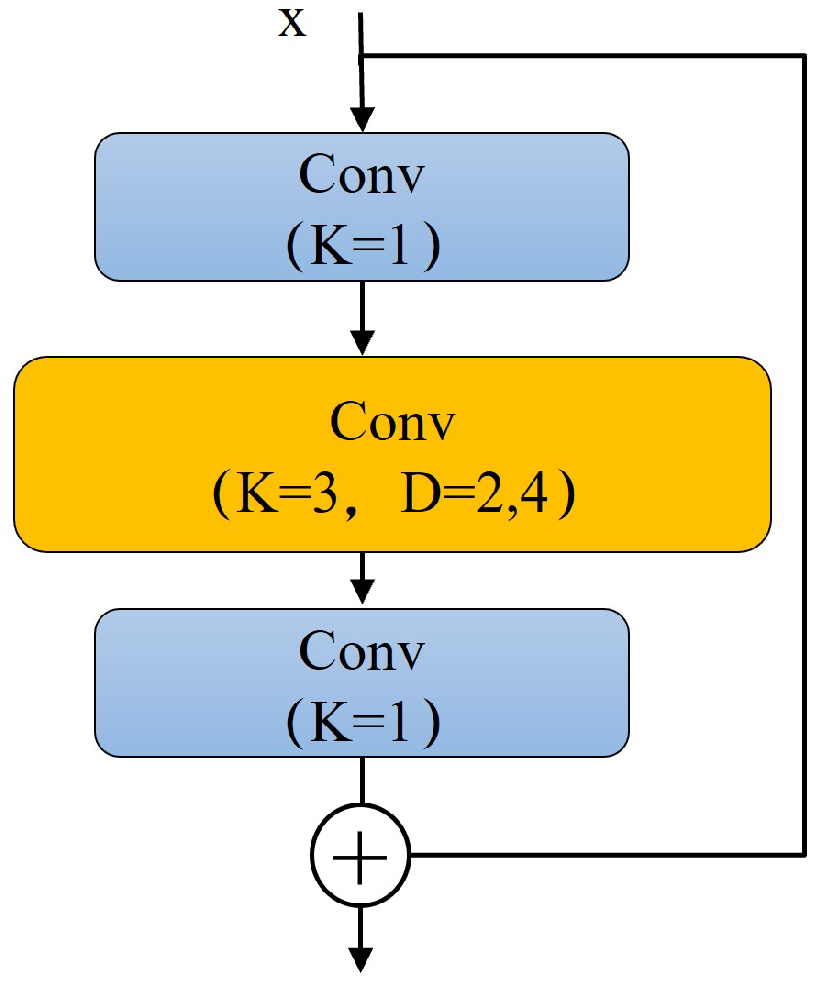
3.3.1. Residual Dilated Module (RDM)
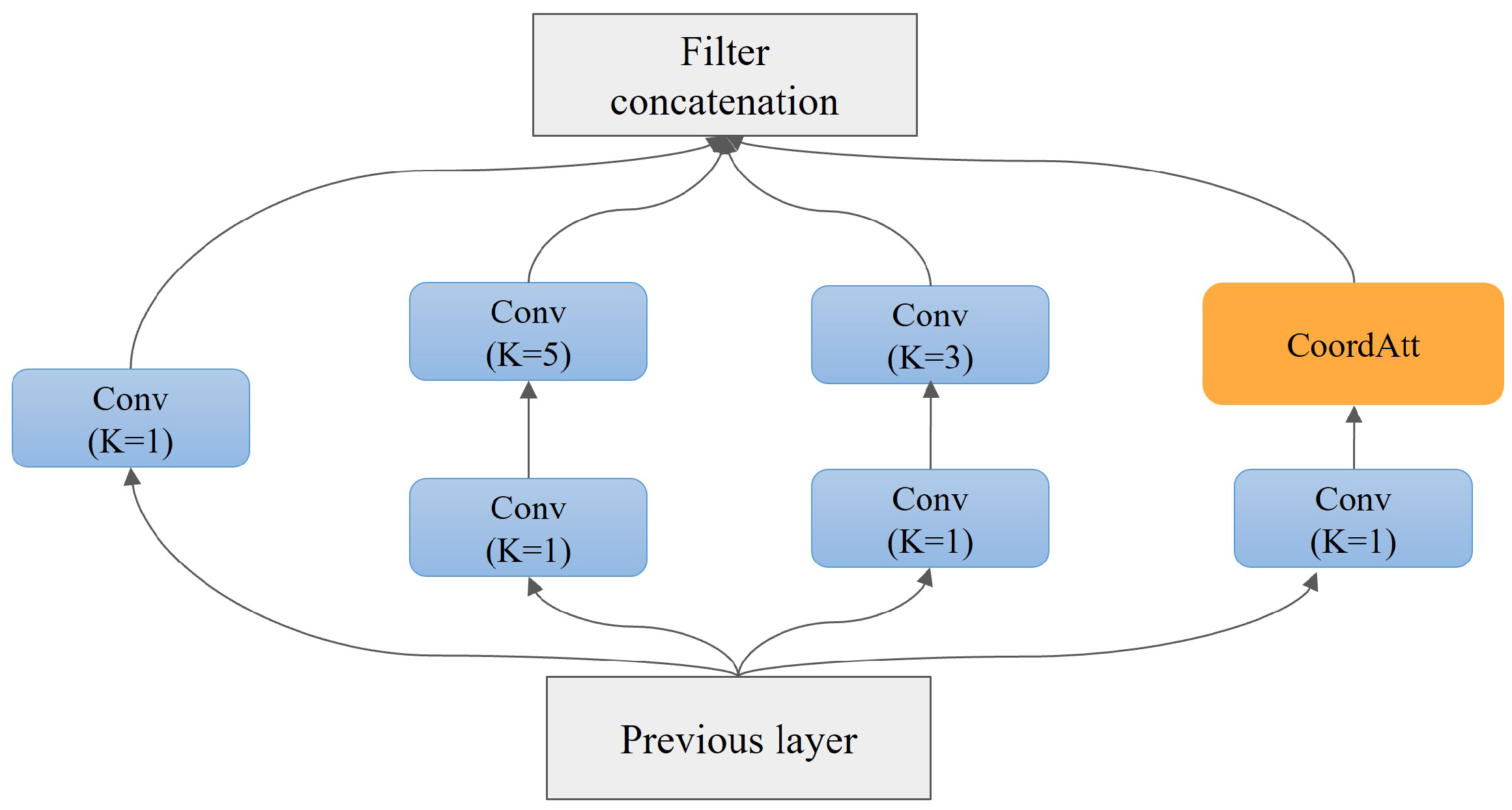
3.3.2. Low-Level Semantic Enhancement Module (LSEM)
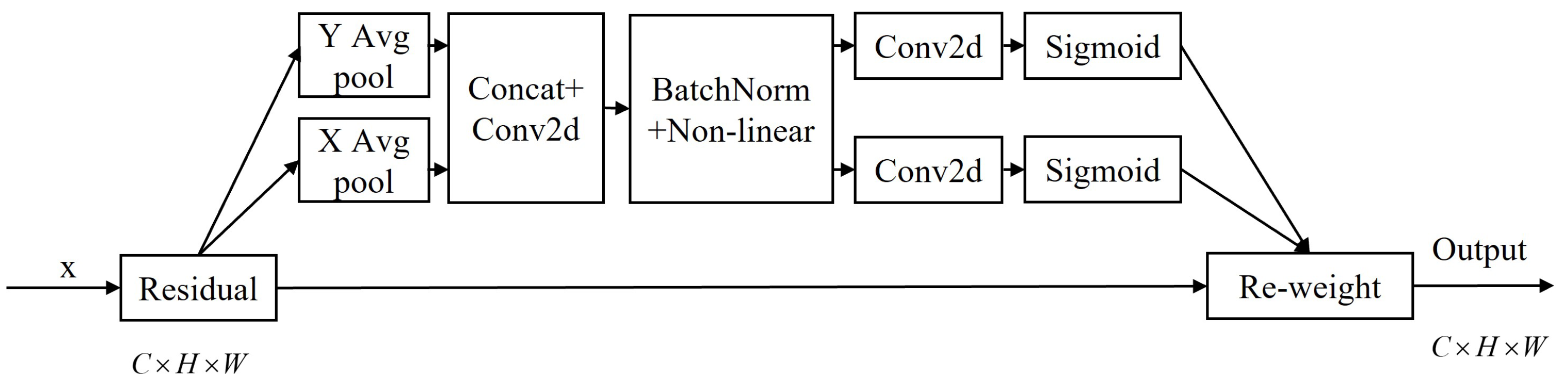
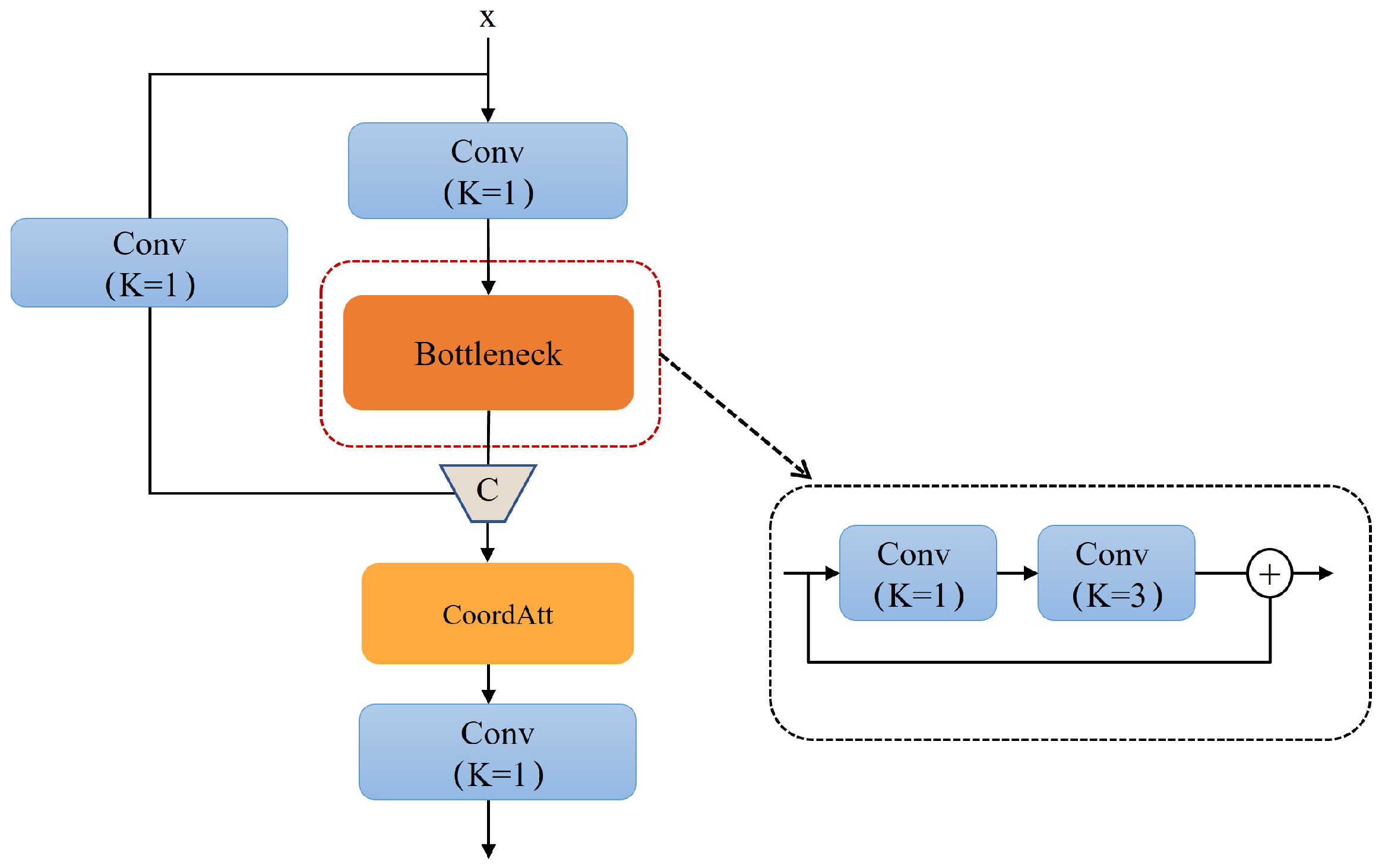
3.3.3. Localization Attention Module (LAM)
4. Experiments and Analysis
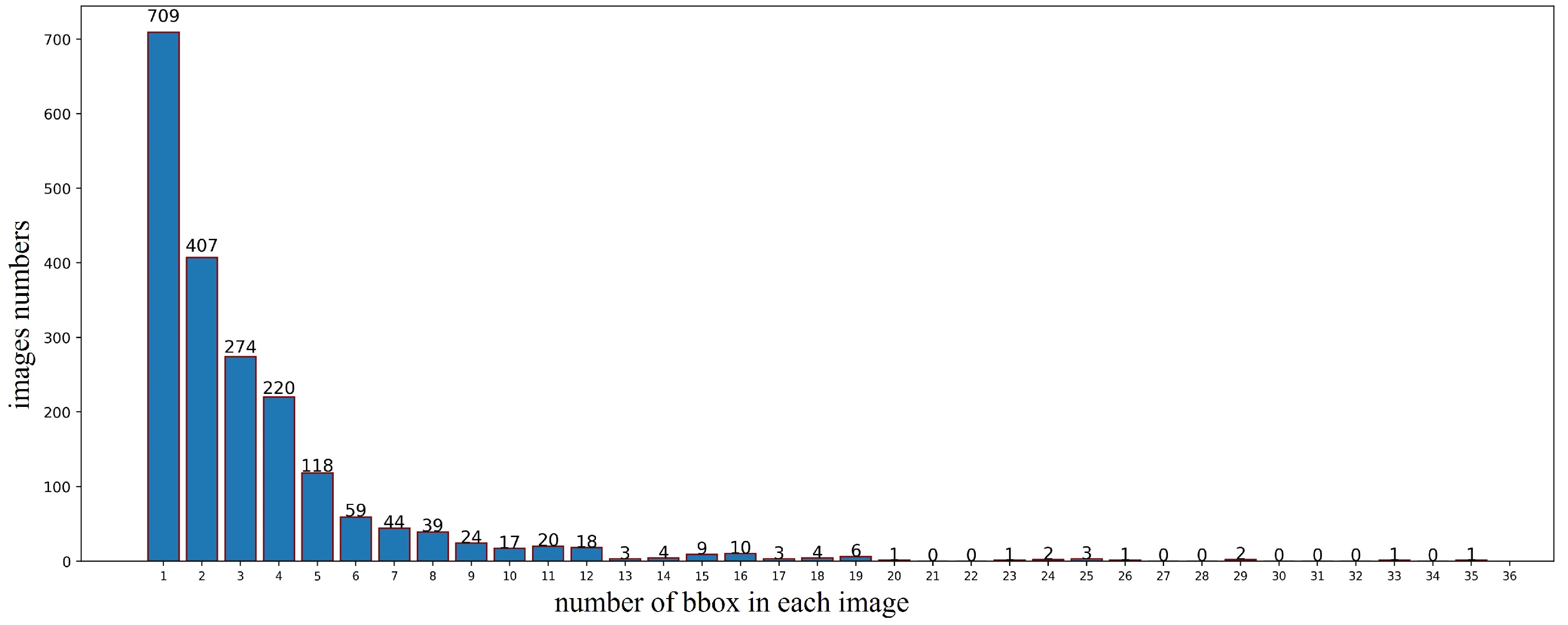
4.1. Dataset Description
4.2. Experimental Parameter Settings
4.3. Evaluation Metrics
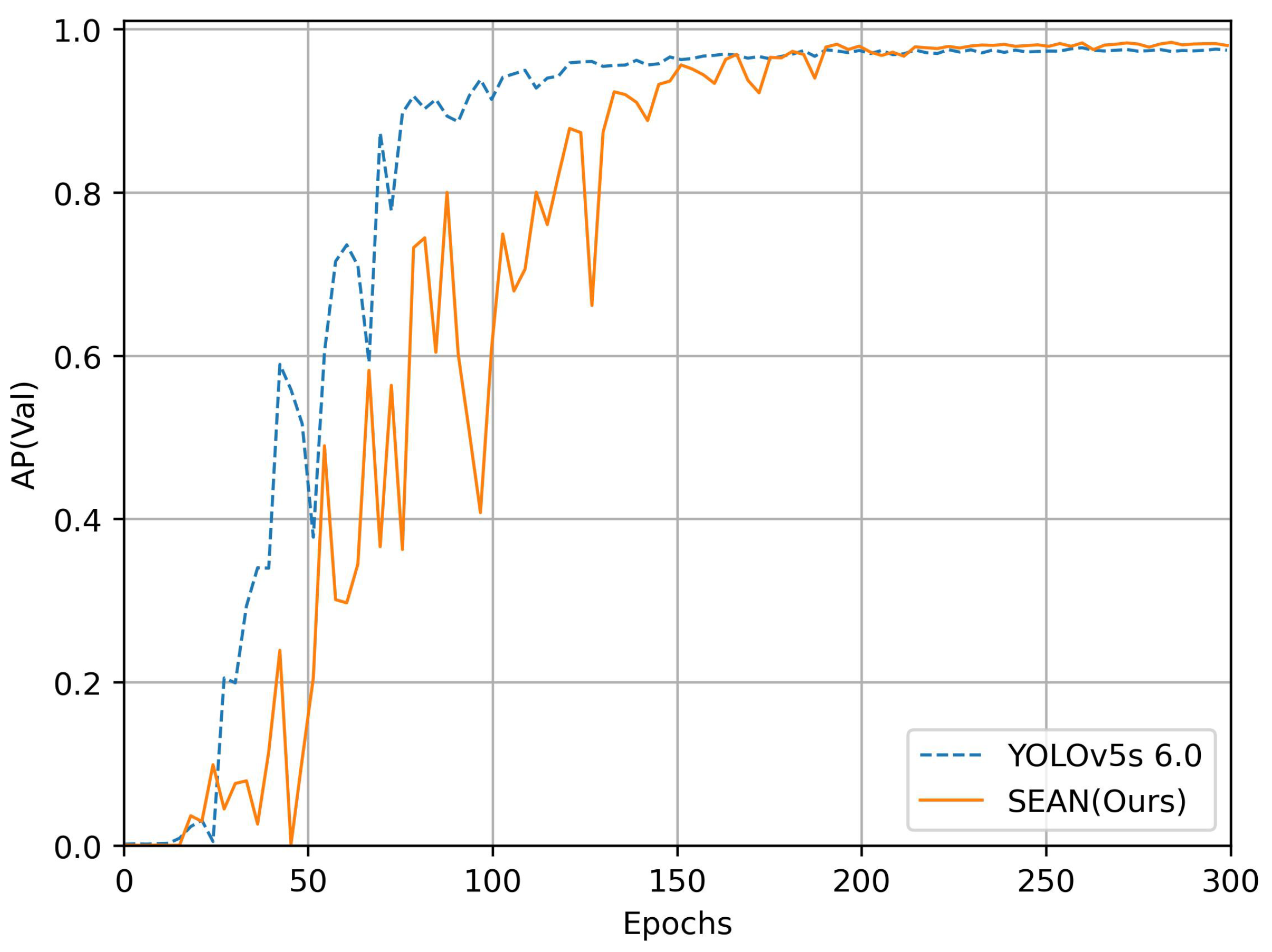
4.4. Experimental Results and Analysis
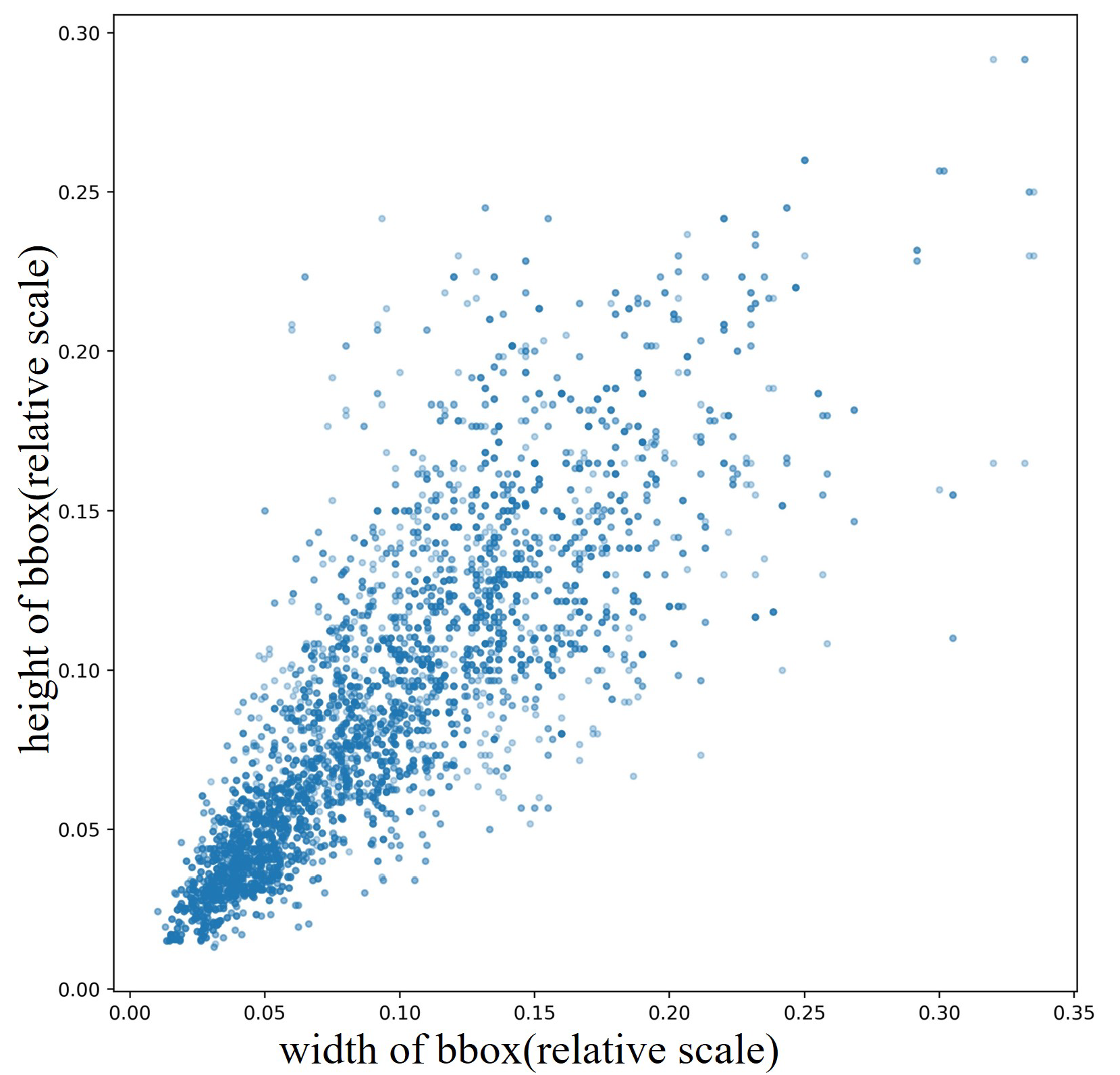
4.4.1. Selection of Preset Anchor Boxes
4.4.2. Ablation Experiments and Analysis
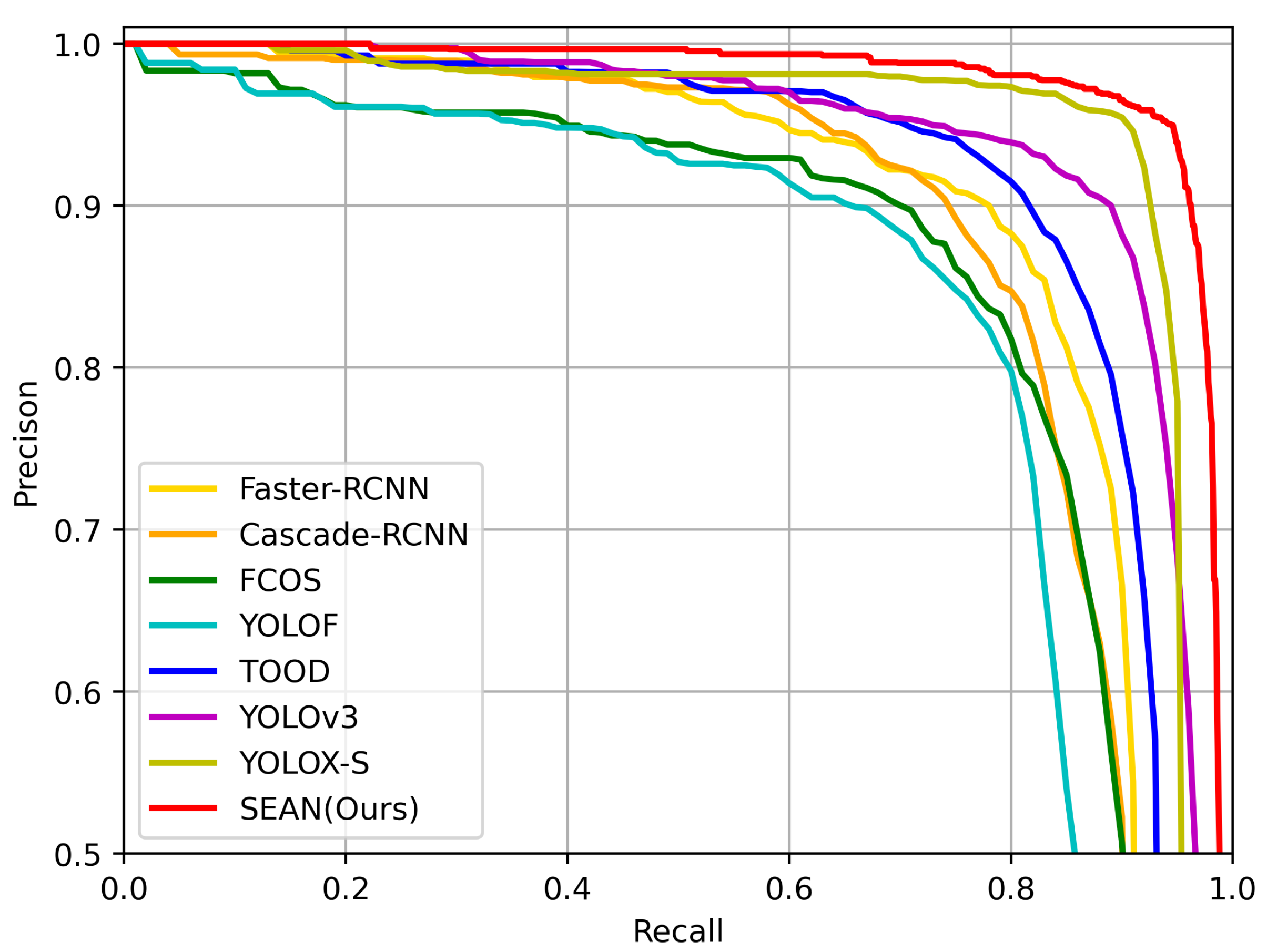
4.4.3. Comparative Experiments and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, J.S.; Pottier, E. Polarimetric Radar Imaging: From Basics to Applications; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Guo, Q.; Wang, H.; Xu, F. Research progress on aircraft detection and recognition in SAR imagery. J. Radars 2020, 9, 497–513. [Google Scholar]
- Finn, H.M. Adaptive detection mode with threshold control as a function of spatially sampled clutter level estimates. RCA Rev. 1968, 29, 414–463. [Google Scholar]
- Gao, G.; Liu, L.; Zhao, L.; Shi, G.; Kuang, G. An Adaptive and Fast CFAR Algorithm Based on Automatic Censoring for Target Detection in High-Resolution SAR Images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1685–1697. [Google Scholar] [CrossRef]
- Zhang, H.; Hao, M.; Zhang, C.; Su, X. Aircraft target detection algorithm based on high resolution spaceborne SAR imagery. In Proceedings of the MIPPR 2017: Remote Sensing Image Processing, Geographic Information Systems, and Other Applications, Xiangyang, China, 28–29 October 2017; SPIE: Bellingham, WA, USA, 2018; Volume 10611, pp. 193–198. [Google Scholar]
- Han, P.; Wu, R.; Wang, Z.; Wang, Y. SAR automatic target recognition based on KPCA criterion. J. Electron. Inf. Technol. 2003, 25, 1297–1301. [Google Scholar]
- Ma, F.; Zhang, F.; Yin, Q.; Xiang, D.; Zhou, Y. Fast SAR image segmentation with deep task-specific superpixel sampling and soft graph convolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5214116. [Google Scholar] [CrossRef]
- Huang, Z.; Dumitru, C.O.; Pan, Z.; Lei, B.; Datcu, M. Classification of large-scale high-resolution SAR images with deep transfer learning. IEEE Geosci. Remote Sens. Lett. 2020, 18, 107–111. [Google Scholar] [CrossRef]
- Kang, Y.; Wang, Z.; Fu, J.; Sun, X.; Fu, K. SFR-Net: Scattering feature relation network for aircraft detection in complex SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5218317. [Google Scholar] [CrossRef]
- He, C.; Tu, M.; Xiong, D.; Tu, F.; Liao, M. A component-based multi-layer parallel network for airplane detection in SAR imagery. Remote Sens. 2018, 10, 1016. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Scattering enhanced attention pyramid network for aircraft detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7570–7587. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Li, C.; Kuang, G. Pyramid attention dilated network for aircraft detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 662–666. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 Octomber–2 November 2019; pp. 9627–9636. [Google Scholar]
- Zhao, Y.; Zhao, L.; Kuang, G. Fast detection aircrafts in complex large scene SAR images. Chin. J. Radio Sci. 2020, 35, 594–602. [Google Scholar]
- Zhang, L.; Li, C.; Zhao, L.; Xiong, B.; Quan, S.; Kuang, G. A cascaded three-look network for aircraft detection in SAR images. Remote Sens. Lett. 2019, 11, 57–65. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhang, P.; Xu, H.; Tian, T.; Gao, P.; Tian, J. SFRE-Net: Scattering Feature Relation Enhancement Network for Aircraft Detection in SAR Images. Remote Sens. 2022, 14, 2076. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.-J.; Kuang, G.-Y. Attention feature fusion network for rapid aircraft detection in SAR images. ACTA Electonica Sin. 2021, 49, 1665. [Google Scholar]
- Luo, R.; Xing, J.; Chen, L.; Pan, Z.; Cai, X.; Li, Z.; Wang, J.; Ford, A. Glassboxing Deep Learning to Enhance Aircraft Detection from SAR Imagery. Remote Sens. 2021, 13, 3650. [Google Scholar] [CrossRef]
- Wang, J.; Xiao, H.; Chen, L.; Xing, J.; Pan, Z.; Luo, R.; Cai, X. Integrating Weighted Feature Fusion and the Spatial Attention Module with Convolutional Neural Networks for Automatic Aircraft Detection from SAR Images. Remote Sens. 2021, 13, 910. [Google Scholar] [CrossRef]
- Luo, R.; Chen, L.; Xing, J.; Yuan, Z.; Tan, S.; Cai, X.; Wang, J. A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network. Remote Sens. 2021, 13, 2940. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; IEEE: Washington, DC, USA, 2017; pp. 1–6. [Google Scholar]
- Liao, L.; Du, L.; Guo, Y. Semi-supervised SAR target detection based on an improved faster R-CNN. Remote Sens. 2021, 14, 143. [Google Scholar] [CrossRef]
- Niu, S.; Qiu, X.; Lei, B.; Ding, C.; Fu, K. Parameter extraction based on deep neural network for SAR target simulation. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4901–4914. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13728–13737. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.B.; He, K. Exploring Plain Vision Transformer Backbones for Object Detection. arXiv 2022, arXiv:2203.16527. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Kwon, Y.; Michael, K.; Liu, C.; Fang, J.; Abhiram, V.; Skalski, S.P. Ultralytics/yolov5: V6.0—YOLOv5n ‘Nano’ models, Roboflow integration, TensorFlow export, OpenCV DNN support. Zenodo Tech. Rep. 2021. Available online: https://zenodo.org/record/5563715#.YyglfLRByUk (accessed on 10 July 2022).
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10778–10787. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Pang, R.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 7029–7038. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-level Feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13034–13043. [Google Scholar]
- Gao, Z.; Wang, L.; Han, B.; Guo, S. AdaMixer: A Fast-Converging Query-Based Object Detector. arXiv 2022, arXiv:2203.16507. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Chen, X.; Gong, Z. YOLOv5-Lite: Lighter, Faster and Easier to Deploy. 2021. Available online: https://zenodo.org/record/5241425/export/hx#.YyglU7RByUk (accessed on 10 July 2022).
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for Small Object Detection. In Proceedings of the ACCV, Taipei, Taiwan, 20–24 November 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- 2021 Gaofen Challenge on Automated High-Resolution Earth Observation Image Interpretation. Available online: http://gaofen-challenge.com (accessed on 10 July 2022).
- Sun, X.; Lv, Y.; Wang, Z.; Fu, K. SCAN: Scattering Characteristics Analysis Network for Few-Shot Aircraft Classification in High-Resolution SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5226517. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3139–3148. [Google Scholar]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2019, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Mao, H.; Wu, C.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 11976–11986. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. TOOD: Task-Aligned One-Stage Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE Computer Society: Washington, DC, USA, 2021; pp. 3490–3499. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | From | n | Module | Arguments | |
|---|---|---|---|---|---|
| 1 | −1 | 1 | Conv | [3, 32, 6, 2, 2] | |
| 2 | −1 | 1 | RepConv | [32, 64, 3, 2] | |
| 3 | −1 | 1 | CSPC3 | [64, 64] | |
| Backbone | 4 | −1 | 1 | RepConv | [64, 128] |
| 5 | −1 | 2 | CSPC3 | [128, 128] | |
| 6 | −1 | 1 | RepConv | [128, 256, 3, 2] | |
| 7 | −1 | 3 | CSPC3 | [256, 256] | |
| 8 | −1 | 1 | RDM | [256, 256] | |
| 9 | 5 | 1 | LSEM | [128, 128] | |
| Neck | 10 | −1 | 1 | RepConv | [128, 256, 3, 2] |
| 11 | [−1, 7, 8] | 1 | Concat | [1] | |
| 12 | −1 | 1 | LAM | [756, 512] | |
| Head | 13 | −1 | 1 | YOLOHead | [512, 1] |
| Method | P (%) | R (%) | F1 (%) | AP (%) | Params (M) | FLOPs (G) | T-Time (h) | FPS |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 93.8 | 91.6 | 92.7 | 95.6 | 1.77 | 4.2 | 0.84 | 123.3 |
| YOLOv5s | 93.7 | 92.4 | 93.0 | 96.4 | 7.01 | 16.0 | 1.15 | 74.6 |
| YOLOv5m | 93.5 | 94.2 | 93.8 | 96.5 | 20.87 | 48.0 | 2.60 | 36.1 |
| YOLOv5l | 94.1 | 93.8 | 94.0 | 96.4 | 46.11 | 107.8 | 4.67 | 22.7 |
| YOLOv5x | 93.4 | 95.3 | 94.4 | 96.6 | 86.12 | 204.2 | 9.19 | 13.1 |
| Method | P (%) | R (%) | F1 (%) | AP (%) | Params (M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|---|
| C3+Head | 81.8 | 72.4 | 76.8 | 81.1 | 0.23 | 5.1 | 58.8 |
| C4+Head | 93.3 | 92.1 | 92.7 | 95.4 | 1.15 | 8.0 | 107.5 |
| C5+Head | 94.4 | 87.3 | 90.7 | 94.3 | 3.52 | 9.9 | 104.2 |
| Method | P (%) | R (%) | F1 (%) | AP (%) | Params (M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv5s | 93.7 | 92.4 | 93.0 | 96.4 | 7.01 | 16.0 | 74.6 |
| C4+Head | 93.3 | 92.1 | 92.7 | 95.4 | 1.15 | 8.0 | 107.5 |
| +RepConv | 91.6 | 94.1 | 92.8 | 96.0 (+0.6) | 1.15 | 8.0 | 107.5 |
| +RDM | 94.7 | 92.7 | 93.7 | 96.3 (+0.3) | 1.16 | 8.1 | 103.2 |
| +LSEM | 93.7 | 93.5 | 93.6 | 96.7 (+0.4) | 1.51 | 9.6 | 92.6 |
| +LAM (ours) | 95.6 | 94.2 | 94.9 | 97.7 (+1.0) | 2.84 | 13.8 | 83.3 |
| +SIoU [54] | 94.2 | 95.5 | 94.9 | 97.3 (−0.4) | 2.84 | 13.8 | 82.6 |
| Method | P (%) | R (%) | F1 (%) | AP (%) |
|---|---|---|---|---|
| LAM (Basic) | 94.6 | 94.5 | 94.5 | 97.2 |
| LAM (SE [51]) | 94.9 | 94.4 | 94.6 | 97.3 |
| LAM (CBAM [54]) | 93.7 | 94.6 | 94.1 | 97.5 |
| LAM (TripletAtt [55]) | 93.9 | 95.1 | 94.5 | 97.2 |
| LAM (CoordAtt [47]) | 95.6 | 94.2 | 94.9 | 97.7 |
| Method | Backbone | Neck | F1 (%) | AP (%) | Params (M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|---|
| SEAN (ours) | Modified CSPDarknet | Ours | 94.9 | 97.7 | 2.84 | 13.8 | 83.3 |
| YOLOv5s | CSPDarknet | PANet | 93.0 | 96.4 | 7.01 | 16.0 | 74.6 |
| CSPDarknet | FPN | 92.7 | 96.0 | 6.85 | 15.8 | 78.2 | |
| CSPDarknet | BiFPN | 93.6 | 96.5 | 7.07 | 16.1 | 74.2 | |
| ConvNeXt [57] | PANet | 93.8 | 97.0 | 25.3 | 52.7 | 16.9 |
| Method | Backbone | Neck | F1 (%) | AP (%) | Params (M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | ResNet50 | FPN | 88.9 | 86.1 | 41.12 | 182.3 | 11.2 |
| Cascade R-CNN | ResNet50 | FPN | 87.3 | 84.5 | 68.93 | 237.6 | 7.3 |
| FCOS | ResNet50 | FPN | 89.1 | 83.5 | 31.84 | 153.7 | 15.3 |
| YOLOF | ResNet50 | D-en | 83.8 | 79.4 | 42.06 | 78.5 | 22.3 |
| TOOD [59] | ResNet50 | FPN | 91.1 | 88.8 | 31.79 | 144.3 | 12.9 |
| YOLOv3 | MobileNetv2 [60] | FPN | 94.8 | 92.7 | 3.74 | 13.5 | 44.2 |
| YOLOX-s | CSPDarknet | PANet | 94.0 | 93.0 | 8.94 | 26.3 | 41.2 |
| SEAN (ours) | Modified CSPDarknet | Ours | 94.9 | 97.7 | 2.84 | 13.8 | 83.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, P.; Liao, D.; Han, B.; Cheng, Z. SEAN: A Simple and Efficient Attention Network for Aircraft Detection in SAR Images. Remote Sens. 2022, 14, 4669. https://doi.org/10.3390/rs14184669
Han P, Liao D, Han B, Cheng Z. SEAN: A Simple and Efficient Attention Network for Aircraft Detection in SAR Images. Remote Sensing. 2022; 14(18):4669. https://doi.org/10.3390/rs14184669
Chicago/Turabian StyleHan, Ping, Dayu Liao, Binbin Han, and Zheng Cheng. 2022. "SEAN: A Simple and Efficient Attention Network for Aircraft Detection in SAR Images" Remote Sensing 14, no. 18: 4669. https://doi.org/10.3390/rs14184669