
Landslide Susceptibility Prediction Considering Neighborhood Characteristics of Landslide Spatial Datasets and Hydrological Slope Units Using Remote Sensing and GIS Technologies

 , ,
, ,
Abstract
:1. Introduction
2. Methods
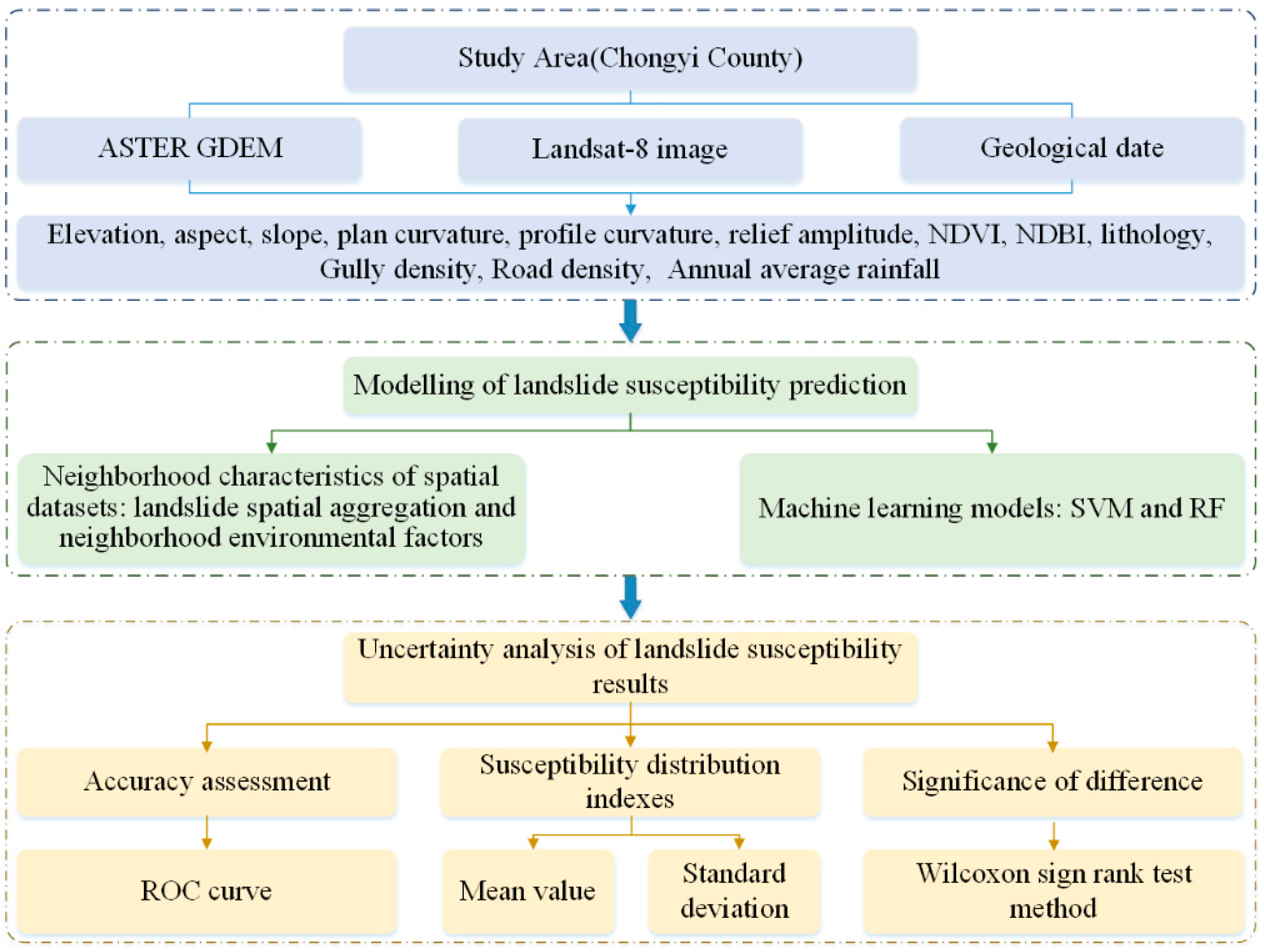
2.1. LSP Modeling Process
- (1)
- Landslide inventory and related environmental factors in the study area were obtained to build the spatial datasets for LSP modelling, and the FR method is adopted to calculate their correlation;
- (2)
- Neighborhood characteristics were performed on spatial datasets (the LAI was considered, and neighborhood analysis was performed). The LAI is an improvement compared to FR. The neighborhood analysis used the obtained neighborhood environmental factors as the extended environmental factors; other topographic and hydrologic environmental factors were extracted based on elevation. Then, the FRs of each environmental factor were calculated under the original spatial datasets, as well as the spatial datasets considering the neighborhood characteristics;
- (3)
- The FRs of environmental factors under 10 combination conditions were taken as input variables. The 10 combination conditions were described as the following models, namely the slope and grid-based machine learning model, the slope–neighborhood factors, slope–landslide aggregation, and the slope–neighborhood datasets-based machine learning model;
- (4)
- Uncertainty analysis was carried out for the LSP results under various combination conditions, including the accuracy evaluation, statistical differences, and the distribution patterns of the LSIs.
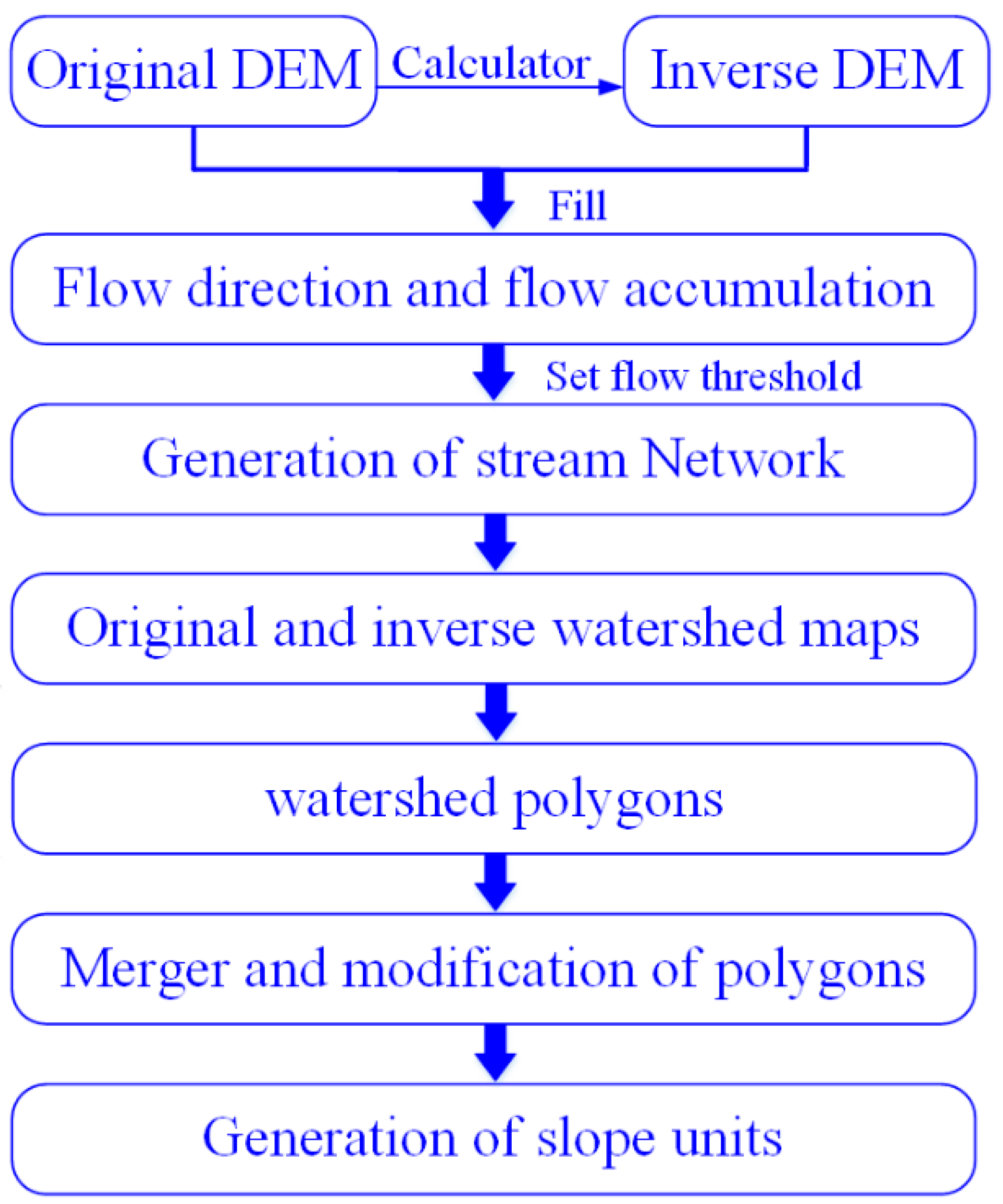
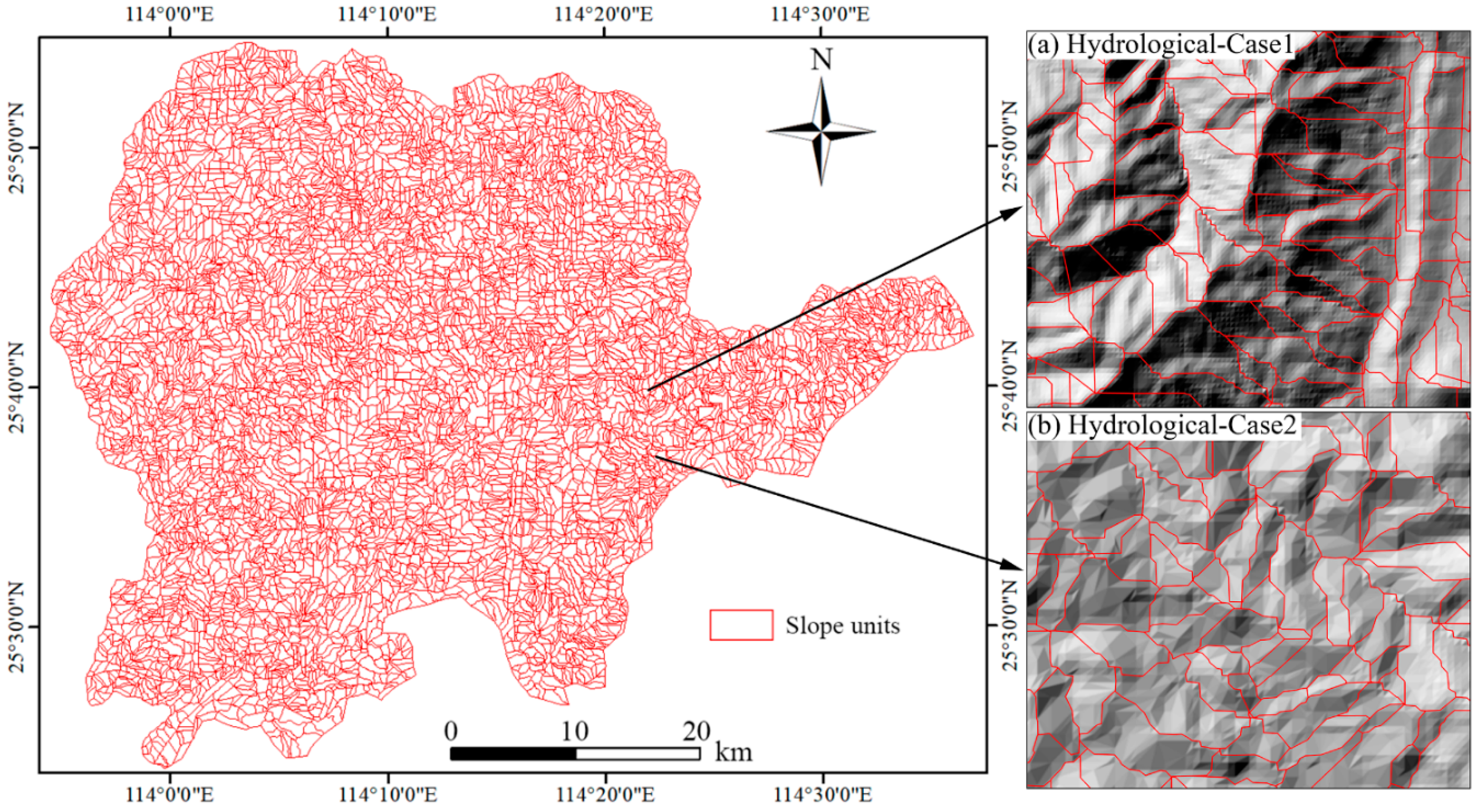
2.2. Mapping Unit
2.3. Neighborhood Characteristics of Spatial Datasets
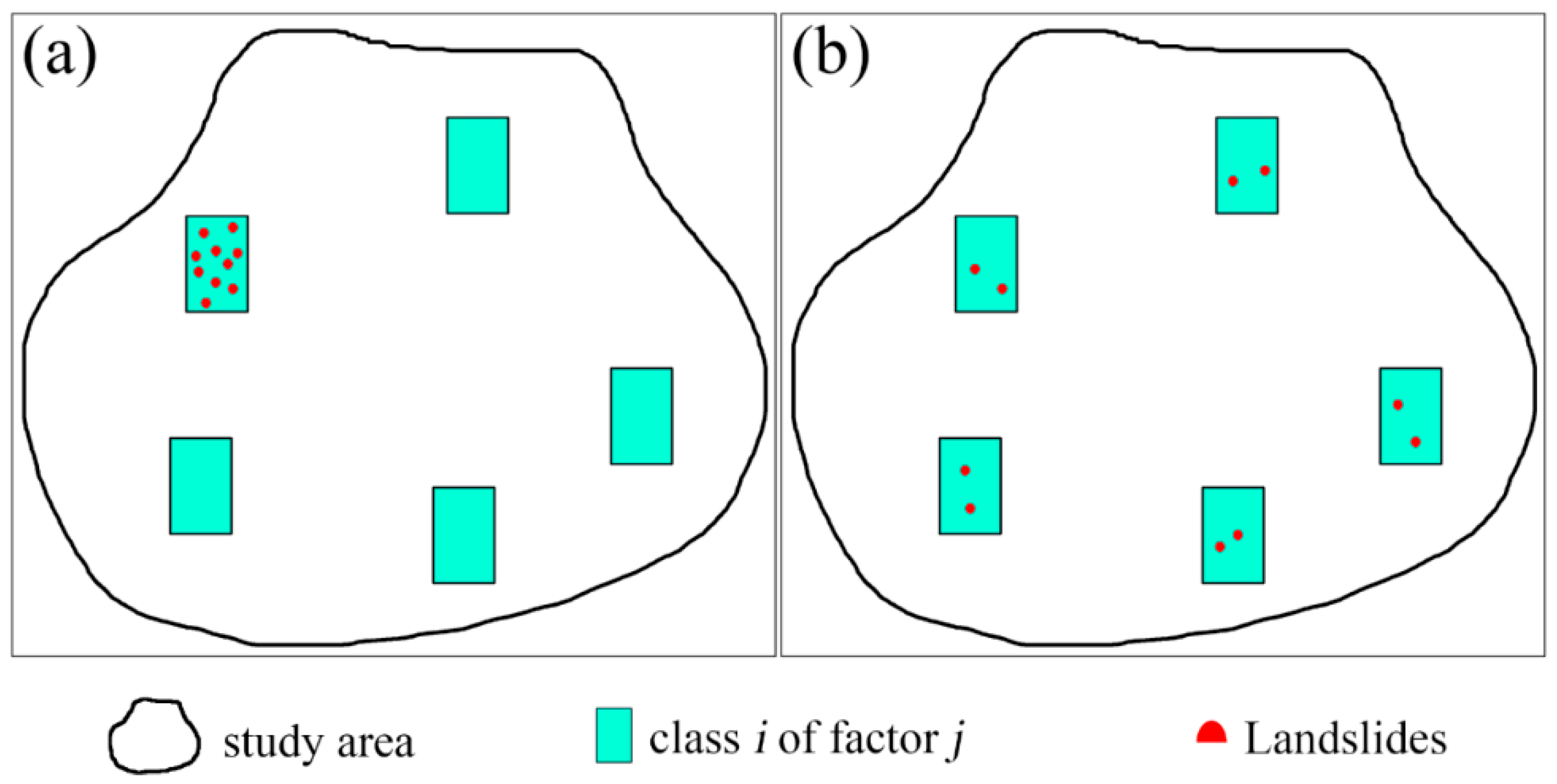
2.3.1. Landslide Aggregation Index
2.3.2. Neighborhood Analysis
2.4. Acquisition of Environmental Factors Based on Remote Sensing and GIS
2.4.1. Acquisition of Topographic Factors
2.4.2. Acquisition of Geological and Hydrological Environment Factors
2.4.3. Acquisition of Surface Cover Factors
2.5. Machine Learning Models
2.5.1. SVM
2.5.2. RF Model
2.6. Uncertainty Evaluation Indexes
2.6.1. ROC
2.6.2. Distribution Patterns of LSIs
2.6.3. Statistical Differences
3. Materials
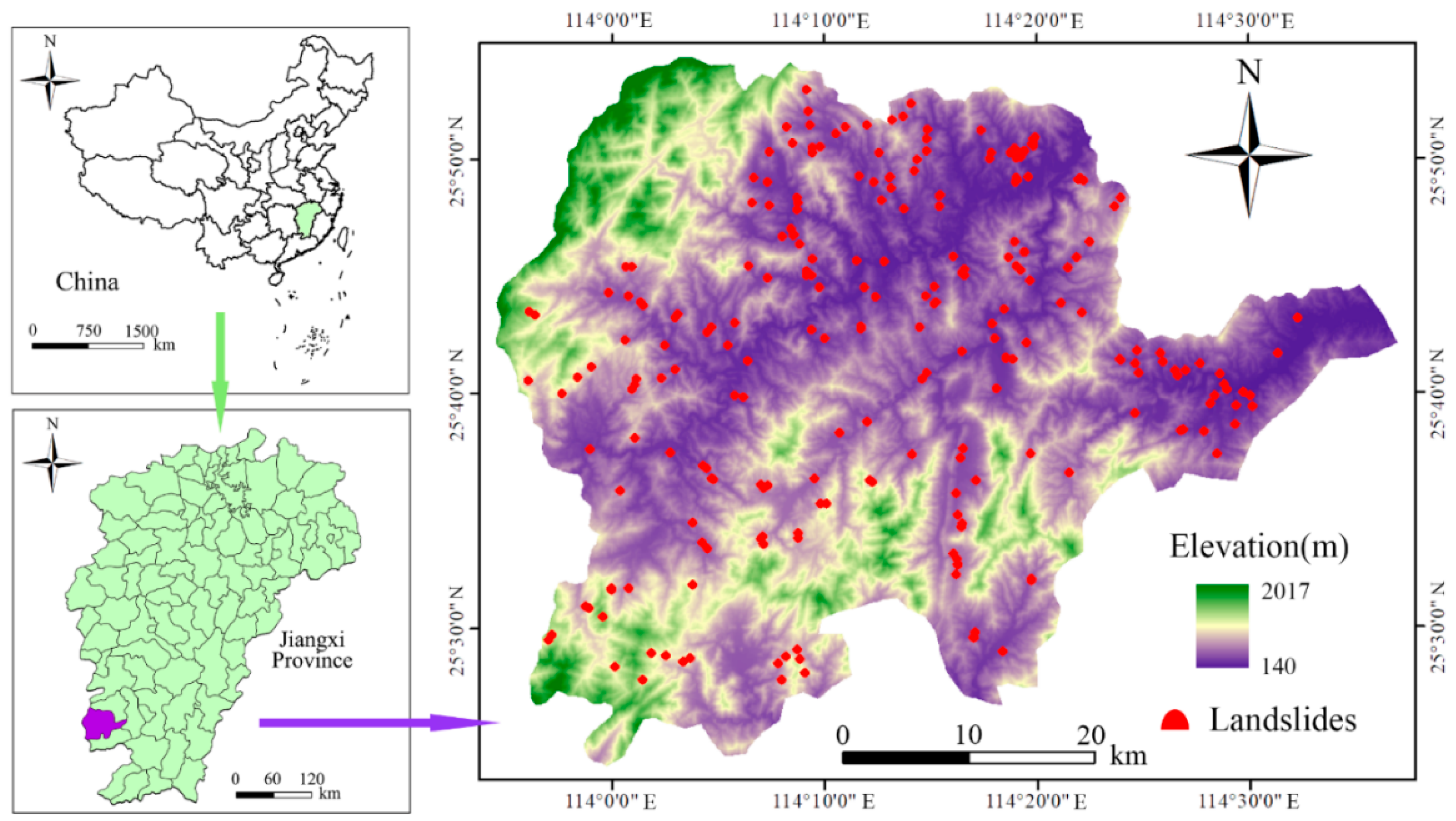
3.1. Description of Chongyi County
3.2. Landslide Inventory Information
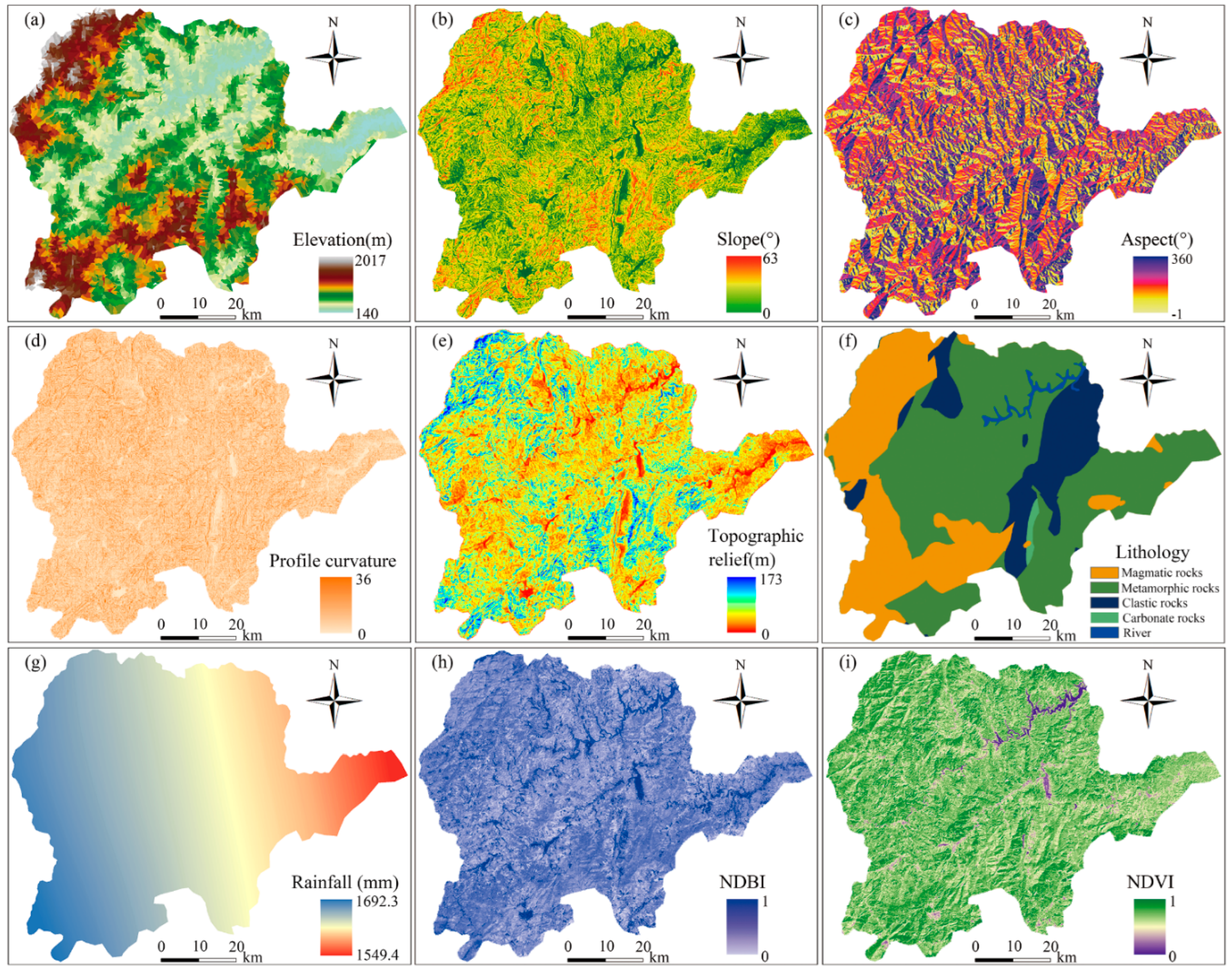
3.3. Landslide Environmental Factors
3.3.1. Topographic Factors
3.3.2. Hydrological and Geological Factors
3.3.3. Surface Cover Factors
4. LSP Results
4.1. Spatial Datasets Preparation
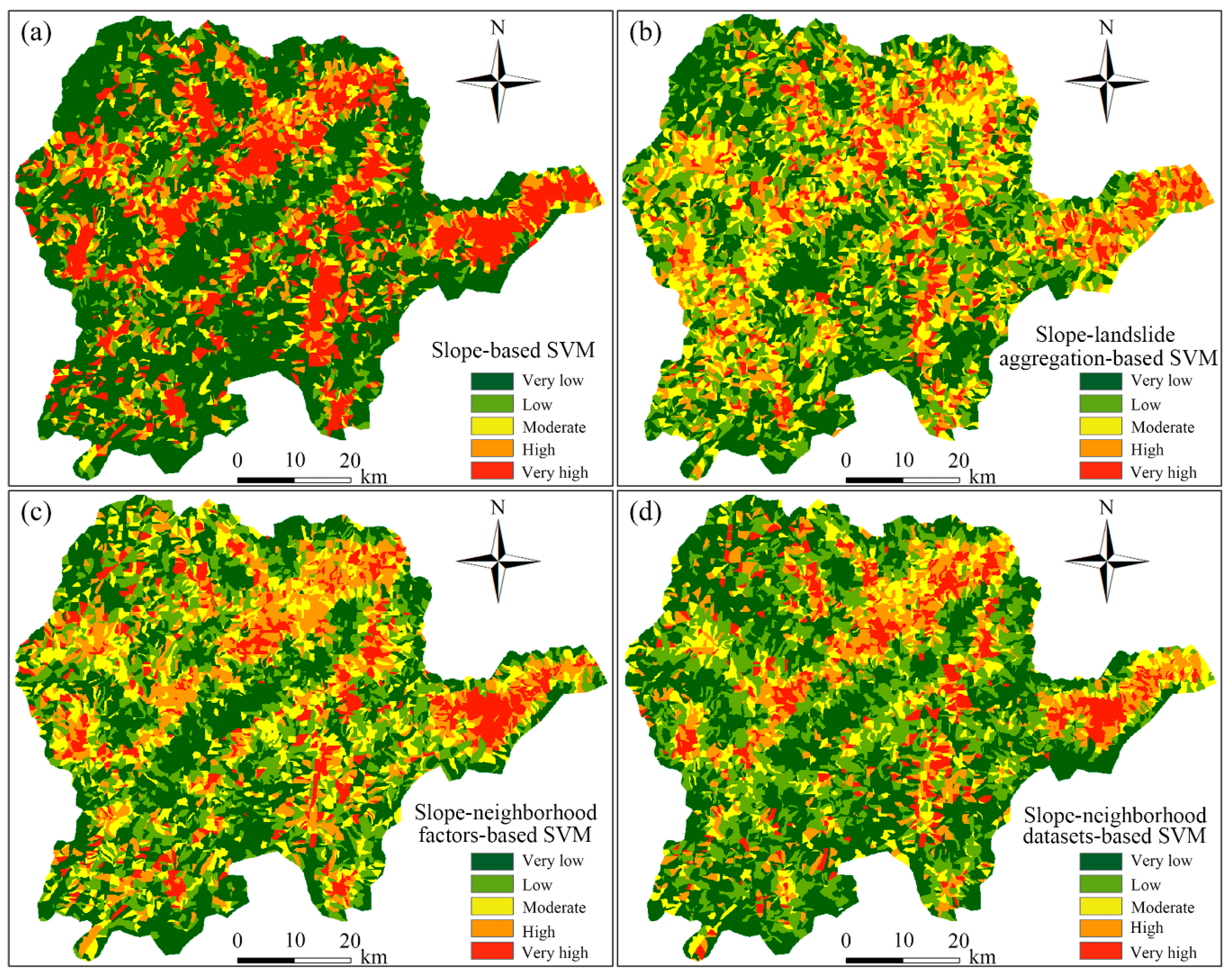
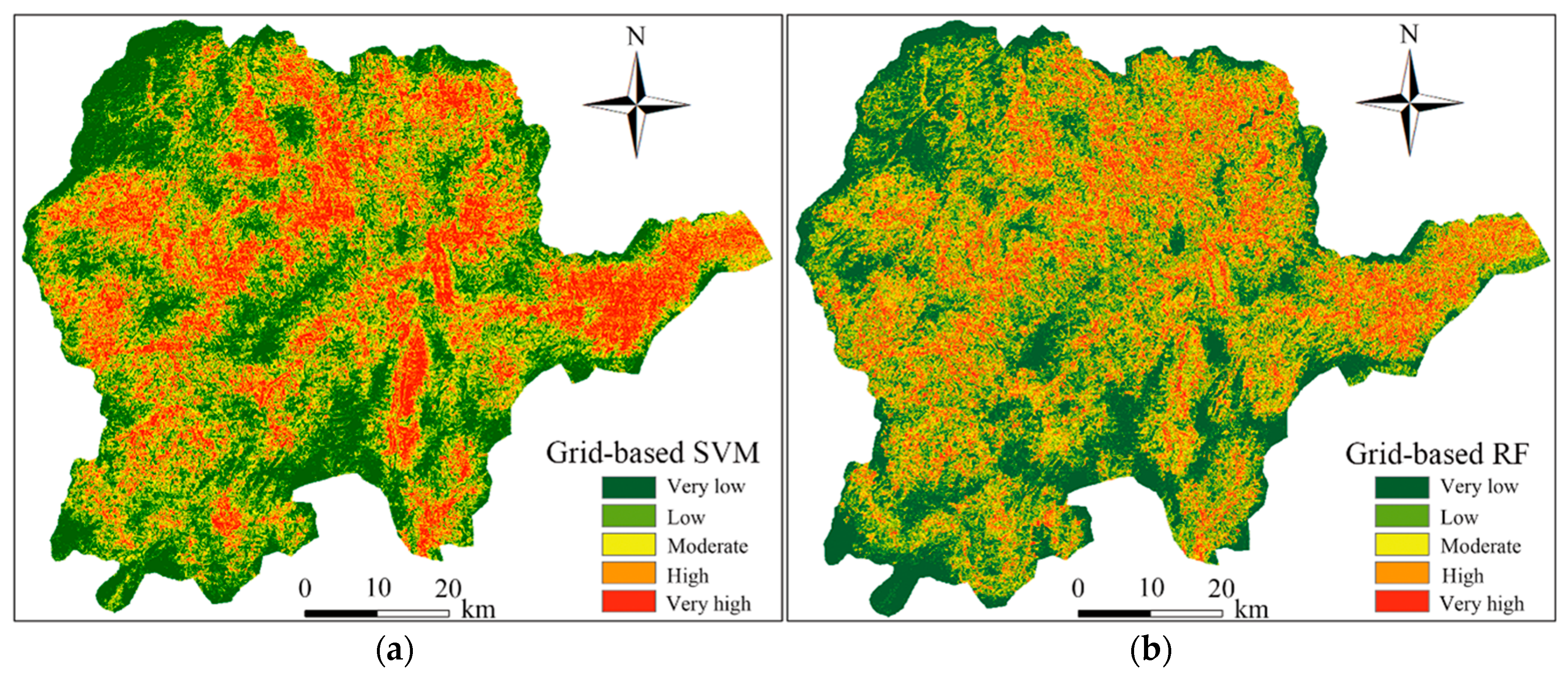
4.2. LSP by SVM Model
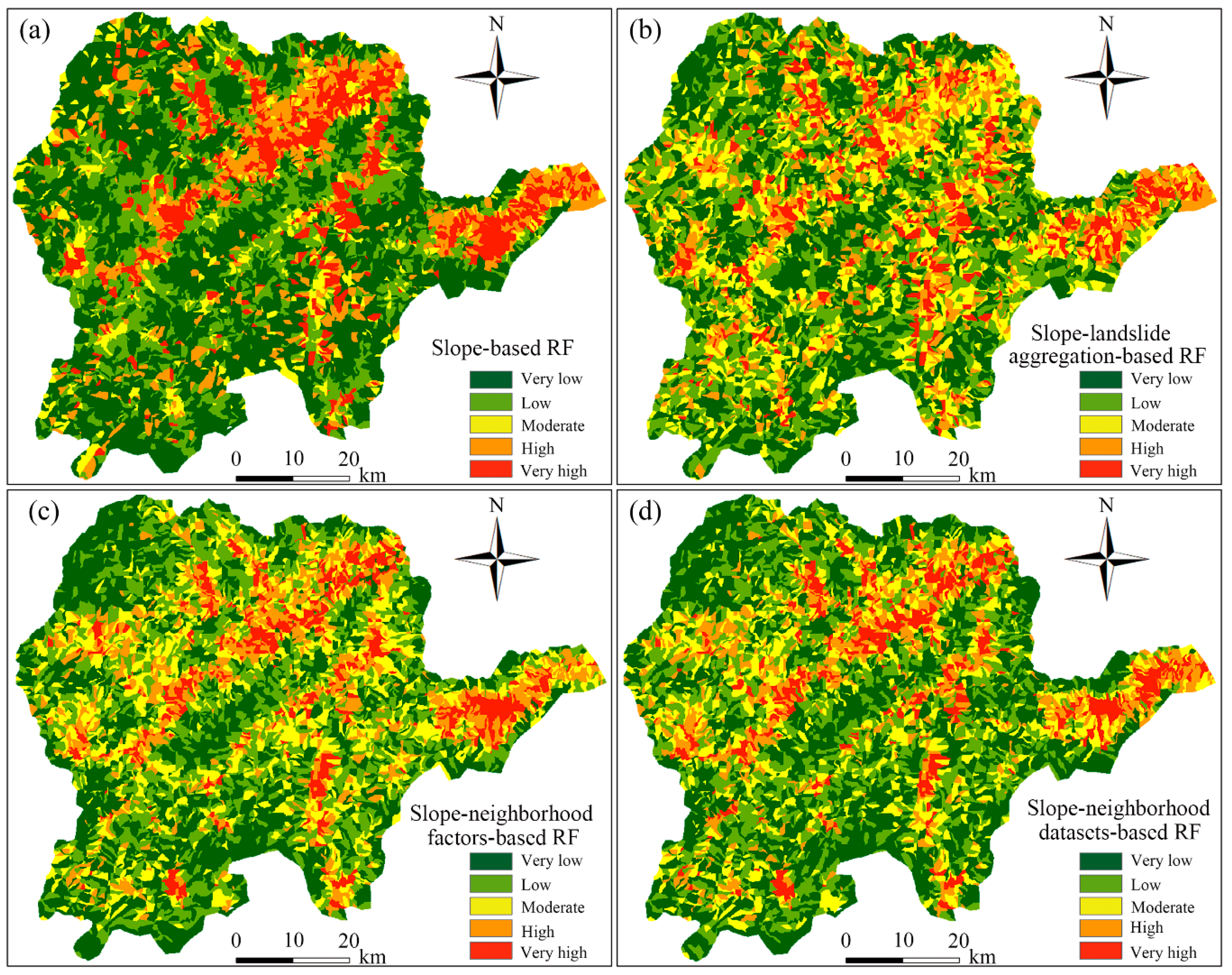
4.3. LSP by RF Model
5. Discussion
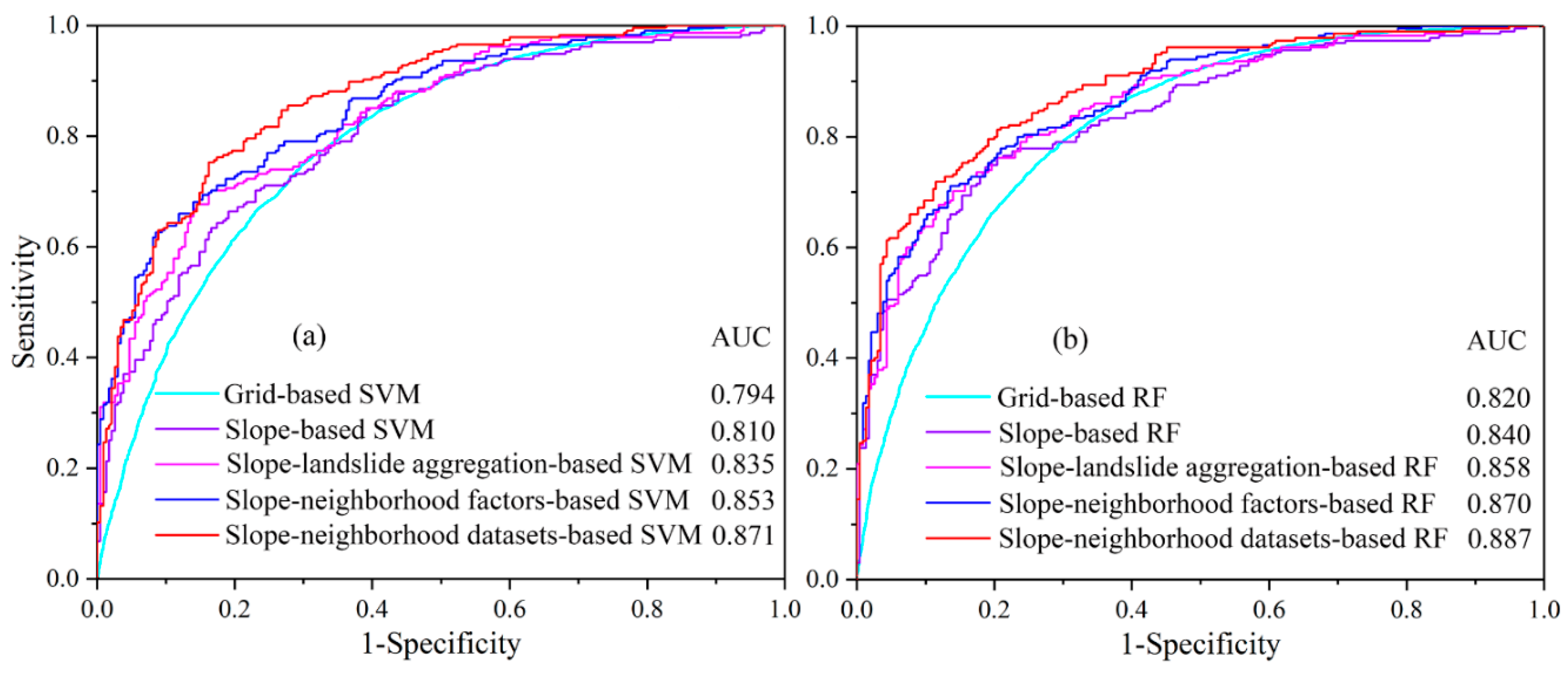
5.1. Comparative Analysis of AUC Accuracy
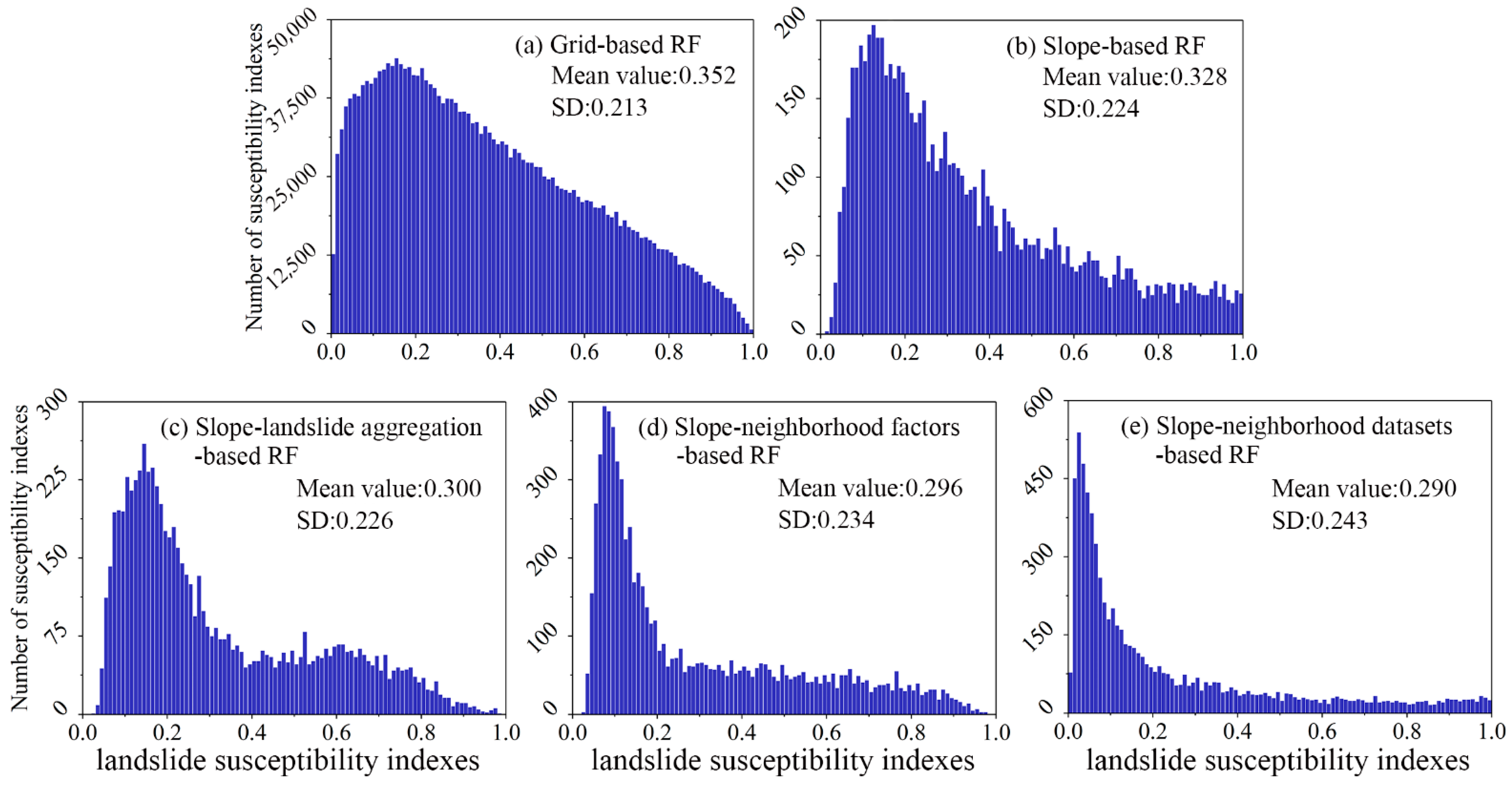
5.2. Distribution Patterns of LSIs
5.3. Analysis of Statistical Differences in LSP Results
5.4. Influence of Evaluation Units on LSP Results
5.5. Comprehensive Discussion of LSP Results
5.6. For Further Study
- (1)
- High-resolution RS images, satellite-borne interferometric radar measurements, lidar, and airborne laser altimeters are expected to be used to improve the identification and monitoring of landslides, and more advanced remote sensing interpretation technology will be combined with a local geological field survey to improve the landslide inventory information in the study area [62,63]. Manual mapping will be introduced on the basis of GIS spatial analysis to improve the professional level of interpreters. Then, a comprehensive verification of the obtained landslide inventory and the actual situation of landslide occurrence will be carried out to further improve the accuracy of landslide samples [64].
- (2)
- The nonlinear correlation analysis between landslides and environmental factors is an important link between the occurrence of landslides and the environmental factors of landslides, and the coupling values can be directly used as the input variables of the LSP modelling [65]. The frequency ratio, information value, and weight of evidence are commonly used connection methods [20]. Each connection method has its own data processing principle, and different connection methods can be used for the LSP modelling in further studies to avoid the uncertainty caused by environmental factor connection methods.
- (3)
- The hydrologic slope units can effectively reflect the physical relationship between landslides and basic topographic elements and, as such, have received extensive attention in terms of LSP modelling. Although the hydrological method has been used to extract slope units, an effective and automatic extraction of slope units is difficult and urgent. To overcome this problem, an innovative multi-scale segmentation (MSS) method [30,47] is proposed to extract slope units.
- (4)
- Shortcomings still exist in the LSP modelling with conventional machine learning models, such as the insufficient landslide samples and low accuracy of non-landslide samples selected randomly and subjectively. The existing studies show that a combination with more advanced semi-supervised machine learning models and deep learning can improve the prediction ability of landslide susceptibility [66].
- (5)
- In previous studies, neighborhood analysis is seldom considered in the LSP modelling. Ten types of statistical analysis can be carried out based on neighborhood, including majority, maximum, mean, standard deviation, etc. [40]. In this study, the standard deviation is taken within the range of 3 × 3 rectangles. Different values, such as the mean and extreme value, can be taken into account for the LSP modelling in different shape ranges in the next study.
6. Conclusion
- (1)
- The models based on hydrological slope units that consider the neighborhood characteristics of spatial datasets have a higher prediction accuracy and a lower uncertainty than the models that consider a certain neighborhood characteristic alone or not at all. It can be seen that, compared with directly performing the LSP modelling on original datasets, considering the neighborhood characteristics of spatial datasets can predict more accurate and reliable susceptibility results, and the predicted LSIs are more consistent with the actual landslide probability distribution.
- (2)
- For the LSP modelling, the uncertainty patterns of the LSP results predicted by the RF and SVM models are consistent. However, compared with SVM models, RF models have a higher prediction accuracy under various combination conditions, with smaller mean values and larger standard deviations. Moreover, the slope–neighborhood datasets-based RF model reflects a more accurate distribution pattern of landslide susceptibility than other models.
Author Contributions
Funding
Conflicts of Interest
References
- Li, Q.; Huang, D.; Pei, S.; Qiao, J.; Wang, M. Using physical model experiments for hazards assessment of rainfall-induced debris landslides. J. Earth Sci. 2021, 32, 1113–1128. [Google Scholar] [CrossRef]
- Jiang, S.-H.; Huang, J.; Huang, F.; Yang, J.; Yao, C.; Zhou, C.-B. Modelling of spatial variability of soil undrained shear strength by conditional random fields for slope reliability analysis. Appl. Math. Model. 2018, 63, 374–389. [Google Scholar] [CrossRef]
- Luo, X.; Lin, F.; Zhu, S.; Yu, M.; Zhang, Z.; Meng, L.; Peng, J. Mine landslide susceptibility assessment using IVM, ANN and SVM models considering the contribution of affecting factors. PLoS ONE 2019, 14, e0215134. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.K.; Raval, S.; Banerjee, B. A robust approach to identify roof bolts in 3D point cloud data captured from a mobile laser scanner. Int. J. Min. Sci. Technol. 2021, 31, 303–312. [Google Scholar] [CrossRef]
- Arabameri, A.; Saha, S.; Roy, J.; Chen, W.; Blaschke, T.; Bui, D.T. Landslide susceptibility evaluation and management using different machine learning methods in the gallicash river watershed, Iran. Remote Sens. 2020, 12, 475. [Google Scholar] [CrossRef]
- Luti, T.; Segoni, S.; Catani, F.; Munafò, M.; Casagli, N. Integration of remotely sensed soil sealing data in landslide suscep-tibility mapping. Remote Sens. 2020, 12, 1486. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support vector machine versus random forest for remote sensing image classification: A meta-analysis and systematic review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Schlögel, R.; Marchesini, I.; Alvioli, M.; Reichenbach, P.; Rossi, M.; Malet, J.-P. Optimizing landslide susceptibility zonation: Effects of DEM spatial resolution and slope unit delineation on logistic regression models. Geomorphology 2017, 301, 10–20. [Google Scholar] [CrossRef]
- Bunn, M.; Leshchinsky, B.; Olsen, M.J. Estimates of three-dimensional rupture surface geometry of deep-seated landslides using landslide inventories and high-resolution topographic data. Geomorphology 2020, 367, 107332. [Google Scholar] [CrossRef]
- Liu, P.; Di, L.; Du, Q.; Wang, L. Remote sensing big data: Theory, methods and applications. Remote Sens. 2018, 10, 711. [Google Scholar] [CrossRef] [Green Version]
- Zêzere, J.; Pereira, S.; Melo, R.; Oliveira, S.; Garcia, R.A. Mapping landslide susceptibility using data-driven methods. Sci. Total Environ. 2017, 589, 250–267. [Google Scholar] [CrossRef] [PubMed]
- Panahi, M.; Gayen, A.; Pourghasemi, H.R.; Rezaie, F.; Lee, S. Spatial prediction of landslide susceptibility using hybrid support vector regression (SVR) and the adaptive neuro-fuzzy inference system (ANFIS) with various metaheuristic algorithms. Sci. Total Environ. 2020, 741, 139937. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Zhang, L.; Wang, S.; Lari, S. Regional landslide susceptibility zoning with considering the aggregation of landslide points and the weights of factors. Landslides 2013, 11, 399–409. [Google Scholar] [CrossRef]
- Li, C.; Ma, T.; Sun, L.; Li, W.; Zheng, A. Application and verification of fractal approach to landslide susceptibility mapping. In Terrigenous Mass Movements; Springer: Berlin/Heidelberg, Germany, 2012; pp. 91–107. [Google Scholar] [CrossRef]
- Tobler, W. On the first law of geography: A reply. Ann. Assoc. Am. Geogr. 2004, 94, 304–310. [Google Scholar] [CrossRef]
- Klippel, A.; Hardisty, F.; Li, R. Interpreting spatial patterns: An inquiry into formal and cognitive aspects of tobler’s first law of geography. Ann. Assoc. Am. Geogr. 2011, 101, 1011–1031. [Google Scholar] [CrossRef]
- Liu, L.; Li, S.; Li, X.; Jiang, Y.; Wei, W.; Wang, Z.; Bai, Y. An integrated approach for landslide susceptibility mapping by considering spatial correlation and fractal distribution of clustered landslide data. Landslides 2019, 16, 715–728. [Google Scholar] [CrossRef]
- Du, G.-L.; Zhang, Y.-S.; Iqbal, J.; Yang, Z.-H.; Yao, X. Landslide susceptibility mapping using an integrated model of information value method and logistic regression in the bailongjiang watershed, Gansu province, China. J. Mt. Sci. 2017, 14, 249–268. [Google Scholar] [CrossRef]
- Huang, Y.; Xu, C.; Zhang, X.; Xue, C.; Wang, S. An updated database and spatial distribution of landslides triggered by the Milin, Tibet Mw6.4 earthquake of 18 November 2017. J. Earth Sci. 2021, 32, 1069–1078. [Google Scholar] [CrossRef]
- Regmi, A.D.; Devkota, K.C.; Yoshida, K.; Pradhan, B.; Pourghasemi, H.R.; Kumamoto, T.; Akgun, A. Application of frequency ratio, statistical index, and weights-of-evidence models and their comparison in landslide susceptibility mapping in Central Nepal Himalaya. Arab. J. Geosci. 2013, 7, 725–742. [Google Scholar] [CrossRef]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Bui, D.T.; Lofman, O.; Revhaug, I.; Dick, O. Landslide susceptibility analysis in the Hoa Binh province of Vietnam using statistical index and logistic regression. Nat. Hazards 2011, 59, 1413–1444. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R. Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha basin, Asir region, Saudi Arabia. Geosci. Front. 2020, 12, 639–655. [Google Scholar] [CrossRef]
- Kamran, K.V.; Feizizadeh, B.; Khorrami, B.; Ebadi, Y. A comparative approach of support vector machine kernel functions for GIS-based landslide susceptibility mapping. Appl. Geomat. 2021, 13, 837–851. [Google Scholar] [CrossRef]
- Jennifer, J.J.; Saravanan, S. Artificial neural network and sensitivity analysis in the landslide susceptibility mapping of Idukki district, India. Geocarto Int. 2021, 37, 1–23. [Google Scholar] [CrossRef]
- Sun, D.; Xu, J.; Wen, H.; Wang, Y. An optimized random forest model and its generalization ability in landslide susceptibility mapping: Application in two areas of three gorges reservoir, China. J. Earth Sci. 2020, 31, 1068–1086. [Google Scholar] [CrossRef]
- Qiao, X.; Chang, F. Underground location algorithm based on random forest and environmental factor compensation. Int. J. Coal Sci. Technol. 2021, 8, 1108–1117. [Google Scholar] [CrossRef]
- Liu, R.; Li, L.; Pirasteh, S.; Lai, Z.; Yang, X.; Shahabi, H. The performance quality of LR, SVM, and RF for earthquake-induced landslides susceptibility mapping incorporating remote sensing imagery. Arab. J. Geosci. 2021, 14, 1–15. [Google Scholar] [CrossRef]
- Ba, Q.; Chen, Y.; Deng, S.; Yang, J.; Li, H. A comparison of slope units and grid cells as mapping units for landslide susceptibility assessment. Earth Sci. Inform. 2018, 11, 373–388. [Google Scholar] [CrossRef]
- Chang, Z.; Catani, F.; Huang, F.; Liu, G.; Meena, S.R.; Huang, J.; Zhou, C. Landslide susceptibility prediction using slope unit-based machine learning models considering the heterogeneity of conditioning factors. J. Rock Mech. Geotech. Eng. 2022. [Google Scholar] [CrossRef]
- Yu, C.; Chen, J. Landslide susceptibility mapping using the slope unit for southeastern Helong city, Jilin province, China: A comparison of ANN and SVM. Symmetry 2020, 12, 1047. [Google Scholar] [CrossRef]
- Sun, X.; Chen, J.; Han, X.; Bao, Y.; Zhou, X.; Peng, W. Landslide susceptibility mapping along the upper Jinsha river, south-western China: A comparison of hydrological and curvature watershed methods for slope unit classification. Bull. Eng. Geol. Environ. 2020, 79, 4657–4670. [Google Scholar] [CrossRef]
- Liang, Z.; Wang, C.; Duan, Z.; Liu, H.; Liu, X.; Khan, K.U.J. A hybrid model consisting of supervised and unsupervised learning for landslide susceptibility mapping. Remote Sens. 2021, 13, 1464. [Google Scholar] [CrossRef]
- Eeckhaut, M.V.D.; Hervás, J. State of the art of national landslide databases in Europe and their potential for assessing landslide susceptibility, hazard and risk. Geomorphology 2012, 139, 545–558. [Google Scholar] [CrossRef]
- Waters, N. Tobler’s first law of geography. Int. Encycl. Geogr. 2017, 94, 1–13. [Google Scholar]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More diverse means better: Multimodal deep learning meets remote-sensing imagery classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4340–4354. [Google Scholar] [CrossRef]
- Huang, F.; Chen, J.; Liu, W.; Huang, J.; Hong, H.; Chen, W. Regional rainfall-induced landslide hazard warning based on landslide susceptibility mapping and a critical rainfall threshold. Geomorphology 2022, 408, 108236. [Google Scholar] [CrossRef]
- Zhang, X.R.; Dong, K. Neighborhood analysis-based calculation and analysis of multi-scales relief amplitude. In Advanced Materials Research; Trans Tech Publications: Bäch, Switzerland, 2012; pp. 2086–2089. [Google Scholar] [CrossRef]
- Davoodi, S.M.R.; Goli, A. An integrated disaster relief model based on covering tour using hybrid Benders decomposition and variable neighborhood search: Application in the Iranian context. Comput. Ind. Eng. 2019, 130, 370–380. [Google Scholar] [CrossRef]
- Gorsevski, P.; Jankowski, P. An optimized solution of multi-criteria evaluation analysis of landslide susceptibility using fuzzy sets and kalman filter. Comput. Geosci. 2010, 36, 1005–1020. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Valente, J.; van der Voort, M.; Tekinerdogan, B. Effect of attention mechanism in deep learning-based remote sensing image processing: A systematic literature review. Remote Sens. 2021, 13, 2965. [Google Scholar] [CrossRef]
- Gong, W.; Juang, C.H.; Wasowski, J. Geohazards and human settlements: Lessons learned from multiple relocation events in Badong, China–Engineering geologist’s perspective. Eng. Geol. 2021, 285, 106051. [Google Scholar] [CrossRef]
- Yin, Y.; Wang, L.; Zhang, W.; Zhang, Z.; Dai, Z. Research on the collapse process of a thick-layer dangerous rock on the reservoir bank. Bull. Eng. Geol. Environ. 2022, 81, 1–11. [Google Scholar] [CrossRef]
- Cantarino, I.; Carrion, M.A.; Goerlich, F.; Martinez Ibañez, V. A roc analysis-based classification method for landslide susceptibility maps. Landslides 2019, 16, 265–282. [Google Scholar] [CrossRef]
- Huang, F.; Chen, J.; Du, Z.; Yao, C.; Huang, J.; Jiang, Q.; Chang, Z.; Li, S. Landslide susceptibility prediction considering regional soil erosion based on machine-learning models. ISPRS Int. J. Geo Inf. 2020, 9, 377. [Google Scholar] [CrossRef]
- Jaafari, A.; Panahi, M.; Mafi-Gholami, D.; Rahmati, O.; Shahabi, H.; Shirzadi, A.; Lee, S.; Bui, D.T.; Pradhan, B. Swarm intelligence optimization of the group method of data handling using the cuckoo search and whale optimization algorithms to model and predict landslides. Appl. Soft Comput. 2022, 116, 108254. [Google Scholar] [CrossRef]
- Huang, F.; Tao, S.; Chang, Z.; Huang, J.; Fan, X.; Jiang, S.-H.; Li, W. Efficient and automatic extraction of slope units based on multi-scale segmentation method for landslide assessments. Landslides 2021, 18, 3715–3731. [Google Scholar] [CrossRef]
- Huang, F.; Pan, L.; Fan, X.; Jiang, S.-H.; Huang, J.; Zhou, C. The uncertainty of landslide susceptibility prediction modeling: Suitability of linear conditioning factors. Bull. Eng. Geol. Environ. 2022, 81, 182. [Google Scholar] [CrossRef]
- Singh, P.; Sharma, A.; Sur, U.; Rai, P.K. Comparative landslide susceptibility assessment using statistical information value and index of entropy model in Bhanupali-Beri region, Himachal Pradesh, India. Environ. Dev. Sustain. 2020, 23, 5233–5250. [Google Scholar] [CrossRef]
- Tao, Z.; Shu, Y.; Yang, X.; Peng, Y.; Chen, Q.; Zhang, H. Physical model test study on shear strength characteristics of slope sliding surface in nanfen open-pit mine. Int. J. Min. Sci. Technol. 2020, 30, 421–429. [Google Scholar] [CrossRef]
- Chen, W.; Peng, J.; Hong, H.; Shahabi, H.; Pradhan, B.; Liu, J.; Zhu, A.-X.; Pei, X.; Duan, Z. Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren county, Jiangxi province, China. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef]
- Pokharel, B.; Althuwaynee, O.F.; Aydda, A.; Kim, S.-W.; Lim, S.; Park, H.-J. Spatial clustering and modelling for landslide susceptibility mapping in the north of the Kathmandu Valley, Nepal. Landslides 2020, 18, 1403–1419. [Google Scholar] [CrossRef]
- Zhao, H.; Tian, Y.; Guo, Q.; Li, M.; Wu, J. The slope creep law for a soft rock in an open-pit mine in the Gobi region of Xinjiang, China. Int. J. Coal Sci. Technol. 2020, 7, 371–379. [Google Scholar] [CrossRef]
- Medina, V.; Hürlimann, M.; Guo, Z.; Lloret, A.; Vaunat, J. Fast physically-based model for rainfall-induced landslide susceptibility assessment at regional scale. Catena 2021, 201, 105213. [Google Scholar] [CrossRef]
- Guo, Z.; Shi, Y.; Huang, F.; Fan, X.; Huang, J. Landslide susceptibility zonation method based on C5.0 decision tree and K-means cluster algorithms to improve the efficiency of risk management. Geosci. Front. 2021, 12, 101249. [Google Scholar] [CrossRef]
- Huang, F.; Tang, C.; Jiang, S.-H.; Liu, W.; Chen, N.; Huang, J. Influence of heavy rainfall and different slope cutting conditions on stability changes in red clay slopes: A case study in south China. Environ. Earth Sci. 2022, 81, 1–16. [Google Scholar] [CrossRef]
- Pradhan, B.; Oh, H.-J.; Buchroithner, M. Weights-of-evidence model applied to landslide susceptibility mapping in a tropical hilly area. Geomat. Nat. Hazards Risk 2010, 1, 199–223. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Kutlug Sahin, E.; Colkesen, I. An assessment of multivariate and bivariate approaches in landslide susceptibility mapping: A case study of duzkoy district. Nat. Hazards 2015, 76, 471–496. [Google Scholar] [CrossRef]
- Basu, T.; Pal, S. RS-GIS based morphometrical and geological multi-criteria approach to the landslide susceptibility mapping in Gish River basin, West Bengal, India. Adv. Space Res. 2018, 63, 1253–1269. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Kornejady, A.; Kerle, N.; Shabani, F. Investigating the effects of different landslide positioning techniques, landslide partitioning approaches, and presence-absence balances on landslide susceptibility mapping. Catena 2020, 187, 104364. [Google Scholar] [CrossRef]
- Saha, A.; Saha, S. Application of statistical probabilistic methods in landslide susceptibility assessment in Kurseong and its surrounding area of Darjeeling Himalayan, India: RS-GIS approach. Environ. Dev. Sustain. 2021, 23, 4453–4483. [Google Scholar] [CrossRef]
- Zhu, A.-X.; Miao, Y.; Liu, J.; Bai, S.; Zeng, C.; Ma, T.; Hong, H. A similarity-based approach to sampling absence data for landslide susceptibility mapping using data-driven methods. CATENA 2019, 183, 104188. [Google Scholar] [CrossRef]
- Huang, F.; Wu, P.; Ziggah, Y. GPS monitoring landslide deformation signal processing using time-series model. Int. J. Signal Process. Image Process. Pattern Recognit. 2016, 9, 321–332. [Google Scholar] [CrossRef]
- Xu, C.; Xu, X.; Dai, F.; Wu, Z.; He, H.; Shi, F.; Wu, X.; Xu, S. Application of an incomplete landslide inventory, logistic regression model and its validation for landslide susceptibility mapping related to the 12 May 2008 Wenchuan earthquake of China. Nat. Hazards 2013, 68, 883–900. [Google Scholar] [CrossRef]
- Li, W.; Fan, X.; Huang, F.; Chen, W.; Hong, H.; Huang, J.; Guo, Z. Uncertainties analysis of collapse susceptibility prediction based on remote sensing and GIS: Influences of different data-based models and connections between collapses and environmental factors. Remote Sens. 2020, 12, 4134. [Google Scholar] [CrossRef]
- Huang, F.; Cao, Z.; Jiang, S.-H.; Zhou, C.; Huang, J.; Guo, Z. Landslide susceptibility prediction based on a semi-supervised multiple-layer perceptron model. Landslides 2020, 17, 2919–2930. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Conditional Factors | Values | FR | LAI | FRa |
|---|---|---|---|---|
| Elevation (m) | 143~329 | 2.559 | 0.072 | 0.183 |
| 329~452 | 0.920 | 0.027 | 0.025 | |
| 452~582 | 0.470 | 0.015 | 0.007 | |
| 582~724 | 0.538 | 0.017 | 0.009 | |
| 724~866 | 0.484 | 0.014 | 0.007 | |
| 866~1015 | 0.308 | 0.010 | 0.003 | |
| 1015~1218 | 0.101 | 0.003 | 0.000 | |
| >1218 | 0.000 | 0.000 | 0.000 | |
| Slope (°) | 0~4 | 1.324 | 0.042 | 0.055 |
| 4~8 | 2.249 | 0.069 | 0.155 | |
| 8~13 | 1.352 | 0.038 | 0.052 | |
| 13~17 | 0.678 | 0.021 | 0.014 | |
| 17~22 | 0.837 | 0.026 | 0.022 | |
| 22~26 | 0.562 | 0.018 | 0.010 | |
| 26~31 | 0.642 | 0.020 | 0.013 | |
| >31 | 0.000 | 0.000 | 0.000 | |
| Lithology | Magmatic rocks | 0.577 | 0.016 | 0.009 |
| Metamorphic rocks | 1.135 | 0.032 | 0.037 | |
| Clastic rocks | 1.038 | 0.033 | 0.034 | |
| Carbonate rocks | 4.332 | 0.136 | 0.591 | |
| Water | 0.349 | 0.011 | 0.004 | |
| NDVI | 0.02~0.13 | 0.000 | 0.000 | 0.000 |
| 0.13~0.21 | 1.765 | 0.056 | 0.098 | |
| 0.21~0.26 | 3.012 | 0.092 | 0.276 | |
| 0.26~0.30 | 1.852 | 0.055 | 0.102 | |
| 0.30~0.32 | 0.930 | 0.029 | 0.027 | |
| 0.32~0.34 | 0.794 | 0.024 | 0.019 | |
| 0.34~0.37 | 0.782 | 0.025 | 0.019 | |
| 0.37~0.44 | 0.335 | 0.011 | 0.004 | |
| Gully density | 0~0.23 | 0.177 | 0.006 | 0.001 |
| 0.23~0.42 | 0.448 | 0.011 | 0.005 | |
| 0.42~0.59 | 0.973 | 0.028 | 0.028 | |
| 0.59~0.74 | 1.174 | 0.032 | 0.038 | |
| 0.74~0.89 | 0.722 | 0.022 | 0.016 | |
| 0.89~1.04 | 1.398 | 0.041 | 0.057 | |
| 1.04~1.22 | 1.399 | 0.043 | 0.060 | |
| 1.22~1.60 | 2.004 | 0.060 | 0.120 | |
| Road density | 0~0.24 | 0.222 | 0.005 | 0.001 |
| 0.24~0.52 | 0.681 | 0.019 | 0.013 | |
| 0.52~0.77 | 0.778 | 0.022 | 0.017 | |
| 0.77~1.02 | 0.790 | 0.023 | 0.019 | |
| 1.02~1.28 | 1.352 | 0.041 | 0.055 | |
| 1.28~1.57 | 1.332 | 0.040 | 0.053 | |
| 1.57~1.97 | 2.219 | 0.066 | 0.146 | |
| 1.97~2.75 | 2.634 | 0.078 | 0.205 |
| Neighborhood Factors | Values | FR | LAI | FRa |
|---|---|---|---|---|
| Standard deviation of elevation (m) | 0.000~3.355 | 1.727 | 0.0735 | 0.127 |
| 3.355~4.959 | 2.116 | 0.0274 | 0.058 | |
| 4.959~6.272 | 0.917 | 0.0127 | 0.012 | |
| 6.272~7.511 | 0.755 | 0.0169 | 0.013 | |
| 7.511~8.824 | 0.713 | 0.0122 | 0.009 | |
| 8.824~10.283 | 0.994 | 0.0117 | 0.012 | |
| 10.283~12.179 | 0.439 | 0.0032 | 0.001 | |
| 12.179~18.596 | 0.340 | 0.0000 | 0.000 | |
| Standard deviation of slope (°) | 0.000~1.334 | 2.845 | 0.0417 | 0.119 |
| 1.334~1.990 | 2.643 | 0.1089 | 0.288 | |
| 1.990~2.387 | 1.406 | 0.0346 | 0.049 | |
| 2.387~2.738 | 0.831 | 0.0182 | 0.015 | |
| 2.738~3.066 | 0.788 | 0.0196 | 0.015 | |
| 3.066~3.417 | 0.345 | 0.0129 | 0.004 | |
| 3.417~3.909 | 0.743 | 0.0505 | 0.038 | |
| 3.909~5.968 | 0.916 | 0.0000 | 0.000 | |
| Standard deviation of NDVI | 0.001~0.017 | 0.725 | 0.0213 | 0.015 |
| 0.017~0.021 | 0.750 | 0.1204 | 0.090 | |
| 0.021~0.024 | 0.764 | 0.0917 | 0.070 | |
| 0.024~0.027 | 0.844 | 0.0480 | 0.041 | |
| 0.027~0.030 | 0.745 | 0.0258 | 0.019 | |
| 0.030~0.036 | 2.356 | 0.0203 | 0.048 | |
| 0.036~0.045 | 4.256 | 0.0197 | 0.084 | |
| 0.045~0.069 | 3.177 | 0.0363 | 0.115 | |
| Standard deviation of gully density | 0.000~0.005 | 2.104 | 0.0056 | 0.012 |
| 0.005~0.008 | 0.861 | 0.0132 | 0.011 | |
| 0.008~0.011 | 0.571 | 0.0278 | 0.016 | |
| 0.011~0.014 | 0.680 | 0.0324 | 0.022 | |
| 0.014~0.017 | 0.464 | 0.0244 | 0.011 | |
| 0.017~0.021 | 1.348 | 0.0379 | 0.051 | |
| 0.021~0.026 | 1.371 | 0.0453 | 0.062 | |
| 0.026~0.052 | 8.321 | 0.0601 | 0.500 | |
| Standard deviation of road density | 0.000~0.004 | 0.955 | 0.0047 | 0.004 |
| 0.004~0.008 | 1.137 | 0.0180 | 0.020 | |
| 0.008~0.011 | 1.028 | 0.0230 | 0.024 | |
| 0.011~0.014 | 0.588 | 0.0220 | 0.013 | |
| 0.014~0.017 | 0.861 | 0.0426 | 0.037 | |
| 0.017~0.021 | 1.236 | 0.0395 | 0.049 | |
| 0.021~0.027 | 1.615 | 0.0619 | 0.100 | |
| 0.027~0.044 | 3.389 | 0.0829 | 0.281 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, F.; Tao, S.; Li, D.; Lian, Z.; Catani, F.; Huang, J.; Li, K.; Zhang, C. Landslide Susceptibility Prediction Considering Neighborhood Characteristics of Landslide Spatial Datasets and Hydrological Slope Units Using Remote Sensing and GIS Technologies. Remote Sens. 2022, 14, 4436. https://doi.org/10.3390/rs14184436
Huang F, Tao S, Li D, Lian Z, Catani F, Huang J, Li K, Zhang C. Landslide Susceptibility Prediction Considering Neighborhood Characteristics of Landslide Spatial Datasets and Hydrological Slope Units Using Remote Sensing and GIS Technologies. Remote Sensing. 2022; 14(18):4436. https://doi.org/10.3390/rs14184436
Chicago/Turabian StyleHuang, Faming, Siyu Tao, Deying Li, Zhipeng Lian, Filippo Catani, Jinsong Huang, Kailong Li, and Chuhong Zhang. 2022. "Landslide Susceptibility Prediction Considering Neighborhood Characteristics of Landslide Spatial Datasets and Hydrological Slope Units Using Remote Sensing and GIS Technologies" Remote Sensing 14, no. 18: 4436. https://doi.org/10.3390/rs14184436