
Assessment Analysis of Flood Susceptibility in Tropical Desert Area: A Case Study of Yemen

 ,
,  ,
,  ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Methods and Data
2.1. Study Area
2.2. Flood Susceptibility Mechanism and Conceptual Framework
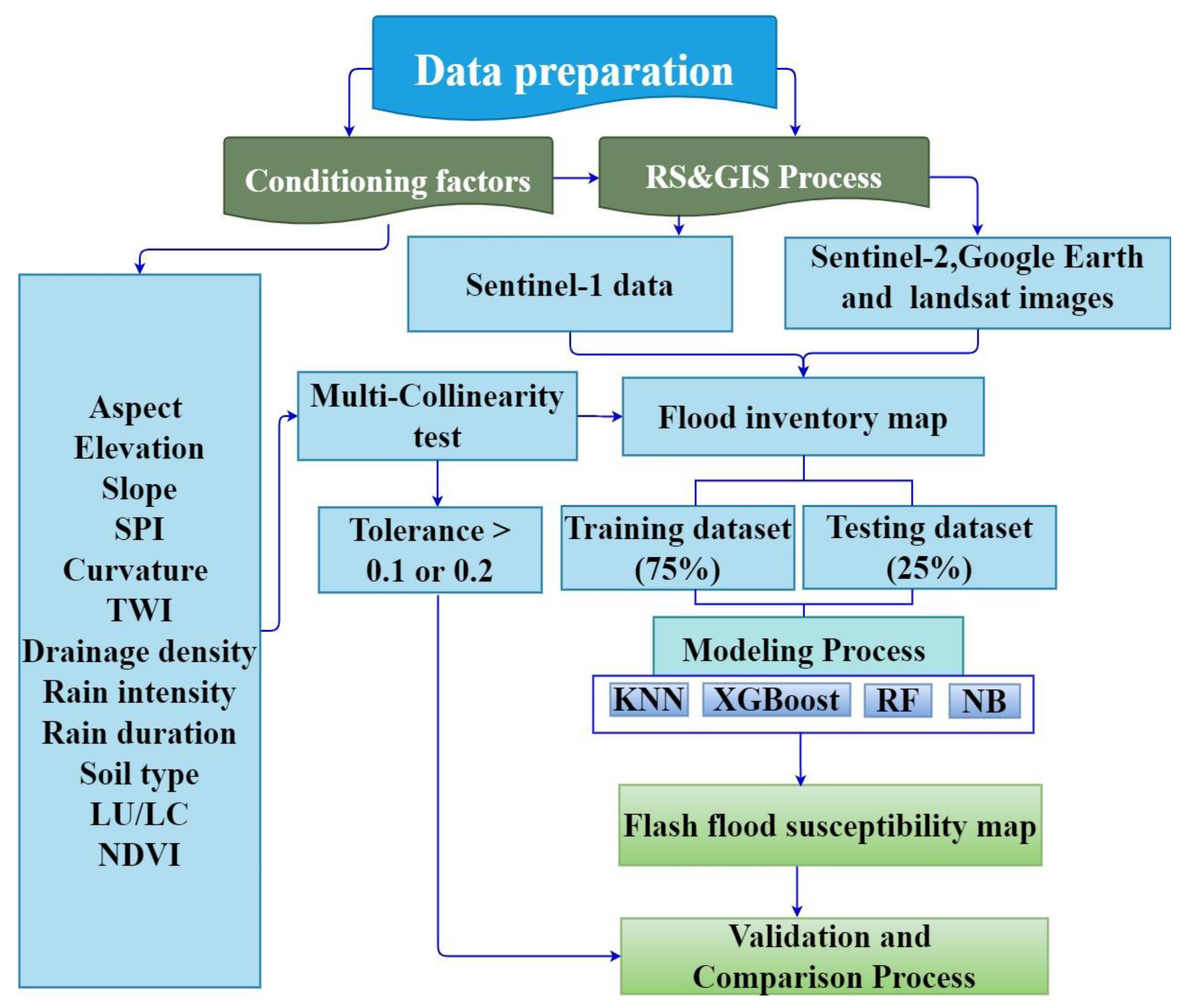
2.3. Multicollinearity Assessment
2.4. Detection of Flood-Prone Area by Sentinel-1
2.5. Data Pre-Processing and Processing
2.6. Methods
2.6.1. Random Forest (RF)
2.6.2. K-Nearest Neighbor (KNN)
2.6.3. Naïve Bayes (NB)
2.6.4. Extreme Gradient Boosting (XGBoost)
2.7. Model Validation
2.8. Factor System of Flood Susceptibility and Model Building
2.8.1. Flash Flood Conditioning Factors
2.8.2. Flood Inventory Map
2.8.3. Applied ML Models for Flood Susceptibility Mapping
3. Results
3.1. Multicollinearity Analysis
3.2. Flood Detection Results Using Sentinel-1 Data
3.3. Variable’s Importance
3.4. Flash Flood Susceptibility Mapping
3.5. Performance and Validation of Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hu, P.; Zhang, Q.; Shi, P.; Chen, B.; Fang, J. Flood-Induced Mortality Across the Globe: Spatiotemporal Pattern and Influencing Factors. Sci. Total Environ. 2018, 643, 171–182. [Google Scholar] [CrossRef] [PubMed]
- World Bank Group. Vulnerability, Risk Reduction, and Adaptation to Climate Change: Climate Risk and Adaptation Country Profile’ Yemen. Global Facility for Disaster Risk Reduction and Recovery. 2011. Available online: https://climateknowledgeportal.worldbank.org/sites/default/files/2018-10/wb_gfdrr_climate_change_country_profile_for_YEM.pdf (accessed on 17 July 2022).
- Breisinger, C.; Ecker, O.; Thiele, R.; Wiebelt, M. The Impact of the 2008 Hadramout Flash Flood in Yemen on Economic Performance and Nutrition: A Simulation Analysis; Kiel Working Paper; Kiel Institute for the World Economy (IfW): Kiel, Germany, 2012; pp. 1–28. [Google Scholar]
- Wilby, R.L.; Yu, D. Mapping Climate Change Impacts on Smallholder Agriculture in Yemen Using GIS Modeling Approaches; Final Technical Report on Behalf of the International Fund for Agricultural; IFAD: Rome, Italy, 2013. [Google Scholar]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A Comparative Assessment of Decision Trees Algorithms for Flash Flood Susceptibility Modeling at Haraz Watershed, Northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef] [PubMed]
- Costache, R.; Bui, D.T. Identification of Areas Prone to Flash-Flood Phenomena Using Multiple-Criteria Decision-Making, Bivariate Statistics, Machine Learning and Their Ensembles. Sci. Total Environ. 2020, 712, 136492. [Google Scholar] [CrossRef] [PubMed]
- Tehrany, M.S.; Kumar, L.; Jebur, M.N.; Shabani, F. Evaluating the Application of The Statistical Index Method in Flood Susceptibility Mapping and Its Comparison with Frequency Ratio and Logistic Regression Methods. Geomat. Nat. Hazards Risk 2018, 10, 79–101. [Google Scholar] [CrossRef]
- Band, S.; Janizadeh, S.; Pal, S.C.; Saha, A.; Chakrabortty, R.; Melesse, A.; Mosavi, A. Flash Flood Susceptibility Modeling Using New Approaches of Hybrid and Ensemble Tree-Based Machine Learning Algorithms. Remote Sens. 2020, 12, 3568. [Google Scholar] [CrossRef]
- Edouard, S.; Vincendon, B.; Ducrocq, V. Ensemble-Based Flash-Flood Modelling: Taking into Account Hydrodynamic Parameters and Initial Soil Moisture Uncertainties. J. Hydrol. 2018, 560, 480–494. [Google Scholar] [CrossRef]
- Kourgialas, N.; Karatzas, G.P. Flood Aanagement and a GIS Modelling Method to Assess Flood-Hazard Areas—A Case Study. Hydrol. Sci. J. 2011, 56, 212–225. [Google Scholar] [CrossRef]
- Lin, L.; Wu, Z.; Liang, Q. Urban Flood Susceptibility Analysis Using a GIS-Based Multi-Criteria Analysis Framework. Nat. Hazards 2019, 97, 455–475. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood Susceptibility Analysis and Its Verification Using a Novel Ensemble Support Vector Machine and Frequency Ratio Method. Stoch. Environ. Res. Risk Assess. 2015, 29, 1149–1165. [Google Scholar] [CrossRef]
- Malik, S.; Pal, S.C.; Arabameri, A.; Chowdhuri, I.; Saha, A.; Chakrabortty, R.; Roy, P.; Das, B. GIS-Based Statistical Model for the Prediction of Flood Hazard Susceptibility. Environ. Dev. Sustain. 2021, 23, 16713–16743. [Google Scholar] [CrossRef]
- Opolot, E. Application of Remote Sensing and Geographical Information Systems in Flood Management: A Review. Res. J. Appl. Sci. Eng. Technol. 2013, 6, 1884–1894. [Google Scholar] [CrossRef]
- Sanyal, J.; Lu, X.X. Remote Sensing and GIS-Based Flood Vulnerability Assessment of Human Settlements: A Case Study of Gangetic West Bengal, India. Hydrol. Process. 2005, 19, 3699–3716. [Google Scholar] [CrossRef]
- Konadu, D.D.; Fosu, C. Digital Elevation Models and GIS For Watershed Modelling and Flood Prediction—A Case Study of Accra Ghana. In Appropriate Technologies for Environmental Protection in the Developing World; Springer: Berlin/Heidelberg, Germany, 2009; pp. 325–332. [Google Scholar] [CrossRef]
- Cheng, C.-T.; Zhao, M.-Y.; Chau, K.; Wu, X.-Y. Using Genetic Algorithm and TOPSIS For Xinanjiang Model Calibration with A Single Procedure. J. Hydrol. 2006, 316, 129–140. [Google Scholar] [CrossRef]
- de Brito, M.M.; Evers, M.; Almoradie, A.D.S. Participatory Flood Vulnerability Assessment: A Multi-Criteria Approach. Hydrol. Earth Syst. Sci. 2018, 22, 373–390. [Google Scholar] [CrossRef]
- Al-Juaidi, A.E.M.; Nassar, A.M.; Al-Juaidi, O.E.M. Evaluation of Flood Susceptibility Mapping Using Logistic Regression and GIS Conditioning Factors. Arab. J. Geosci. 2018, 11, 765. [Google Scholar] [CrossRef]
- Hussain, M.; Tayyab, M.; Zhang, J.; Shah, A.; Ullah, K.; Mehmood, U.; Al-Shaibah, B. GIS-Based Multi-Criteria Approach for Flood Vulnerability Assessment and Mapping in District Shangla: Khyber Pakhtunkhwa, Pakistan. Sustainability 2021, 13, 3126. [Google Scholar] [CrossRef]
- Chowdary, V.M.; Chakraborthy, D.; Jeyaram, A.; Murthy, Y.V.N.K.; Sharma, J.R.; Dadhwal, V.K. Multi-Criteria Decision-Making Approach for Watershed Prioritization Using Analytic Hierarchy Process Technique and GIS. Water Resour. Manag. 2013, 27, 3555–3571. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Jones, S.; Shabani, F. Identifying the Essential Flood Conditioning Factors for Flood Prone Area Mapping Using Machine Learning Techniques. Catena 2019, 175, 174–192. [Google Scholar] [CrossRef]
- Panahi, M.; Dodangeh, E.; Rezaie, F.; Khosravi, K.; Van Le, H.; Lee, M.-J.; Lee, S.; Pham, B.T. Flood Spatial Prediction Modeling Using a Hybrid of Meta-Optimization and Support Vector Regression Modeling. Catena 2021, 199, 105114. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel Forecasting Approaches Using Combination of Machine Learning and Statistical Models for Flood Susceptibility Mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef]
- Costache, R. Flash-Flood Potential Assessment in the Upper and Middle Sector of Prahova River Catchment (Romania). A Comparative Approach Between Four Hybrid Models. Sci. Total Environ. 2018, 659, 1115–1134. [Google Scholar] [CrossRef] [PubMed]
- Costache, R.; Hong, H.; Pham, Q.B. Comparative Assessment of The Flash-Flood Potential Within Small Mountain Catchments Using Bivariate Statistics and Their Novel Hybrid Integration with Machine Learning Models. Sci. Total Environ. 2020, 711, 134514. [Google Scholar] [CrossRef] [PubMed]
- Ullah, K.; Zhang, J. GIS-Based Flood Hazard Mapping Using Relative Frequency Ratio Method: A Case Study of Panjkora River Basin, Eastern Hindu Kush, Pakistan. PLoS ONE 2020, 15, e0229153. [Google Scholar] [CrossRef] [PubMed]
- Rahmati, O.; Pourghasemi, H.R.; Zeinivand, H. Flood Susceptibility Mapping Using Frequency Ratio and Weights-Of-Evidence Models in The Golastan Province, Iran. Geocarto Int. 2016, 31, 42–70. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H.; Costache, R.; Tang, X. Flood Susceptibility Mapping by Integrating Frequency Ratio and Index of Entropy with Multilayer Perceptron and Classification and Regression Tree. J. Environ. Manag. 2021, 289, 112449. [Google Scholar] [CrossRef]
- Costache, R.; Bui, D.T. Spatial Prediction of Flood Potential Using New Ensembles of Bivariate Statistics and Artificial Intelligence: A Case Study at the Putna River Catchment of Romania. Sci. Total Environ. 2019, 691, 1098–1118. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Kumar, L.; Shabani, F. A novel GIS-Based Ensemble Technique for Flood Susceptibility Mapping Using Evidential Belief Function and Support Vector Machine: Brisbane, Australia. PeerJ 2019, 7, e7653. [Google Scholar] [CrossRef]
- Kia, M.B.; Pirasteh, S.; Pradhan, B.; Mahmud, A.R.; Sulaiman, W.N.A.; Moradi, A. An Artificial Neural Network Model for Flood Simulation Using GIS: Johor River Basin, Malaysia. Environ. Earth Sci. 2012, 67, 251–264. [Google Scholar] [CrossRef]
- Abedi, R.; Costache, R.; Shafizadeh-Moghadam, H.; Pham, Q.B. Flash-Flood Susceptibility Mapping Based on Xgboost, Random Forest and Boosted Regression Trees. Geocarto Int. 2021, 1–18. [Google Scholar] [CrossRef]
- Ma, M.; Zhao, G.; He, B.; Li, Q.; Dong, H.; Wang, S.; Wang, Z. XGBoost-Based Method for Flash Flood Risk Assessment. J. Hydrol. 2021, 598, 126382. [Google Scholar] [CrossRef]
- Pham, B.T.; Van Phong, T.; Nguyen, H.D.; Qi, C.; Al-Ansari, N.; Amini, A.; Ho, L.S.; Tuyen, T.T.; Yen, H.P.H.; Ly, H.-B.; et al. A Comparative Study of Kernel Logistic Regression, Radial Basis Function Classifier, Multinomial Naïve Bayes, and Logistic Model Tree for Flash Flood Susceptibility Mapping. Water 2020, 12, 239. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H.; Peng, L. Flood Susceptibility Mapping Using Convolutional Neural Network Frameworks. J. Hydrol. 2020, 582, 124482. [Google Scholar] [CrossRef]
- Costache, R.; Ngo, P.T.T.; Bui, D.T. Novel Ensembles of Deep Learning Neural Network and Statistical Learning for Flash-Flood Susceptibility Mapping. Water 2020, 12, 1549. [Google Scholar] [CrossRef]
- Shahabi, H.; Shirzadi, A.; Ghaderi, K.; Omidvar, E.; Al-Ansari, N.; Clague, J.J.; Geertsema, M.; Khosravi, K.; Amini, A.; Bahrami, S.; et al. Flood Detection and Susceptibility Mapping Using Sentinel-1 Remote Sensing Data and a Machine Learning Approach: Hybrid Intelligence of Bagging Ensemble Based on K-Nearest Neighbor Classifier. Remote Sens. 2020, 12, 266. [Google Scholar] [CrossRef]
- Khosravi, K.; Pourghasemi, H.R.; Chapi, K.; Bahri, M. Flash flood susceptibility analysis and its mapping using different bivariate models in Iran: A comparison between Shannon’s entropy, statistical index, and weighting factor models. Environ. Monit. Assess. 2016, 188, 1–21. [Google Scholar] [CrossRef]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.-B.; Gróf, G.; Ho, H.L.; et al. A Comparative Assessment of Flood Susceptibility Modeling Using Multi-Criteria Decision-Making Analysis and Machine Learning Methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Arabameri, A.; Saha, S.; Mukherjee, K.; Blaschke, T.; Chen, W.; Ngo, P.; Band, S. Modeling Spatial Flood using Novel Ensemble Artificial Intelligence Approaches in Northern Iran. Remote Sens. 2020, 12, 3423. [Google Scholar] [CrossRef]
- AlThuwaynee, O.F.; Kim, S.-W.; Najemaden, M.A.; Aydda, A.; Balogun, A.-L.; Fayyadh, M.M.; Park, H.-J. Demystifying Uncertainty in PM10 Susceptibility Mapping Using Variable Drop-Off in Extreme-Gradient Boosting (XGB) And Random Forest (RF) Algorithms. Environ. Sci. Pollut. Res. 2021, 28, 43544–43566. [Google Scholar] [CrossRef]
- Choubin, B.; Soleimani, F.; Pirnia, A.; Sajedi-Hosseini, F.; Alilou, H.; Rahmati, O.; Melesse, A.M.; Singh, V.P.; Shahabi, H. Effects of Drought on Vegetative Cover Changes: Investigating Spatiotemporal Patterns. In Extreme Hydrology and Climate Variability; Elsevier: Amsterdam, The Netherlands, 2019; pp. 213–222. [Google Scholar]
- Lei, X.; Chen, W.; Avand, M.; Janizadeh, S.; Kariminejad, N.; Shahabi, H.; Costache, R.; Shahabi, H.; Shirzadi, A.; Mosavi, A. GIS-Based Machine Learning Algorithms for Gully Erosion Susceptibility Mapping in a Semi-Arid Region of Iran. Remote Sens. 2020, 12, 2478. [Google Scholar] [CrossRef]
- Arabameri, A.; Pal, S.C.; Costache, R.; Saha, A.; Rezaie, F.; Danesh, A.S.; Pradhan, B.; Lee, S.; Hoang, N.-D. Prediction of Gully Erosion Susceptibility Mapping Using Novel Ensemble Machine Learning Algorithms. Geomat. Nat. Hazards Risk 2021, 12, 469–498. [Google Scholar] [CrossRef]
- Arabameri, A.; Pal, S.C.; Rezaie, F.; Chakrabortty, R.; Chowdhuri, I.; Blaschke, T.; Ngo, P.T.T. Comparison of Multi-Criteria and Artificial Intelligence Models for Land-Subsidence Susceptibility Zonation. J. Environ. Manag. 2021, 284, 112067. [Google Scholar] [CrossRef] [PubMed]
- Abu El-Magd, S.A.; Ali, S.A.; Pham, Q.B. Spatial Modeling and Susceptibility Zonation of Landslides Using Random Forest, Naïve Bayes and K-Nearest Neighbor in A Complicated Terrain. Earth Sci. Informatics 2021, 14, 1227–1243. [Google Scholar] [CrossRef]
- Ma, Z.; Mei, G.; Piccialli, F. Machine Learning for Landslides Prevention: A Survey. Neural Comput. Appl. 2020, 33, 10881–10907. [Google Scholar] [CrossRef]
- Van Phong, T.; Pham, B.T.; Trinh, P.T.; Ly, H.; Vu, Q.H.; Ho, L.S.; Van Le, H.; Phong, L.H.; Avand, M.; Prakash, I. Groundwater Potential Mapping Using GIS -Based Hybrid Artificial Intelligence Methods. Ground Water 2021, 59, 745–760. [Google Scholar] [CrossRef] [PubMed]
- Debnath, P.; Chittora, P.; Chakrabarti, T.; Chakrabarti, P.; Leonowicz, Z.; Jasinski, M.; Gono, R.; Jasińska, E. Analysis of Earthquake Forecasting in India Using Supervised Machine Learning Classifiers. Sustainability 2021, 13, 971. [Google Scholar] [CrossRef]
- Madhuri, R.; Sistla, S.; Raju, K.S. Application of Machine Learning Algorithms for Flood Susceptibility Assessment and Risk Management. J. Water Clim. Chang. 2021, 12, 2608–2623. [Google Scholar] [CrossRef]
- Root, K.; Papakos, T.H. Flooding Impacts and Modeling Challenges of Tropical Storms in Eastern Yemen. In Proceedings of the World Environmental and Water Resources Congress 2010: Challenges of Change, Providence, RI, USA, 16–20 May 2010; pp. 1970–1979. [Google Scholar]
- United Nations Development Program. Water Resources Management Studies in the Hadramaut Region Draft Final Report; UNDP: Washington, DC, USA, 2002. [Google Scholar]
- Soliman, M.M.; El Tahan, A.H.M.H.; Taher, A.H.; Khadr, W.M.H. Hydrological Analysis and Flood Mitigation at Wadi Hadramawt, Yemen. Arab. J. Geosci. 2015, 8, 10169–10180. [Google Scholar] [CrossRef]
- Al-Masawa, M.I.; Manab, N.A.; Omran, A. The Effects of Climate Change Risks on the Mud Architecture in Wadi Hadhramaut, Yemen. In The Impact of Climate Change on Our Life; Springer: Wadi Dawan, Yemen, 2018; pp. 57–77. [Google Scholar] [CrossRef]
- El Tahan, A.H.M.H.; Elhanafy, H.E.M. Statistical Analysis of Morphometric and Hydrologic Parameters in Arid Regions, Case Study of Wadi Hadramaut. Arab. J. Geosci. 2016, 9, 88. [Google Scholar] [CrossRef]
- UN OCHA YEMEN: Flood Update; United Nations Office for the Coordination of Humanitarian Affairs: Hadramaut, Yemen, 2021; pp. 1–2.
- Arabameri, A.; Saha, S.; Roy, J.; Chen, W.; Blaschke, T.; Bui, D.T. Landslide Susceptibility Evaluation and Management Using Different Machine Learning Methods in The Gallicash River Watershed, Iran. Remote Sens. 2020, 12, 475. [Google Scholar] [CrossRef]
- Bui, D.T.; Lofman, O.; Revhaug, I.; Dick, O. Landslide Susceptibility Analysis in the Hoa Binh Province of Vietnam Using Statistical Index and Logistic Regression. Nat. Hazards 2011, 59, 1413–1444. [Google Scholar] [CrossRef]
- Pradhan, B.; Seeni, M.I.; Nampak, H. Integration of LiDAR and QuickBird data for automatic landslide detection using object-based analysis and random forests. In Laser Scanning Applications in Landslide Assessment; Springer: Berlin/Heidelberg, Germany, 2017; pp. 69–81. [Google Scholar] [CrossRef]
- Arabameri, A.; Pourghasemi, H.R. Spatial modeling of gully erosion using linear and quadratic discriminant analyses in GIS and R. In Spatial Modeling in GIS And R for Earth and Environmental Sciences; Elsevier: Amsterdam, The Netherland, 2019; pp. 299–321. [Google Scholar]
- Miles, J. Tolerance and variance inflation factor. In Encyclopedia of Statistics in Behavioral Science; Everitt, B.S., Howell, D.C., Eds.; John Wiley and Sons: Hoboken, NJ, USA, 2005; pp. 2055–2056. [Google Scholar]
- DeVries, B.; Huang, C.; Armston, J.; Huang, W.; Jones, J.W.; Lang, M.W. Rapid and Robust Monitoring of Flood Events Using Sentinel-1 and Landsat Data on the Google Earth Engine. Remote Sens. Environ. 2020, 240, 111664. [Google Scholar] [CrossRef]
- Geudtner, D.; Torres, R.; Snoeij, P.; Davidson, M.; Rommen, B. Sentinel-1 System Capabilities and Applications. In Proceedings of the 2014 Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 1457–1460. [Google Scholar]
- Abbot, J.; Marohasy, J. Input Selection and Optimisation for Monthly Rainfall Forecasting in Queensland, Australia, Using Artificial Neural Networks. Atmospheric Res. 2014, 138, 166–178. [Google Scholar] [CrossRef]
- Mohammadi, A.; Kamran, K.V.; Karimzadeh, S.; Shahabi, H.; Al-Ansari, N. Flood Detection and Susceptibility Mapping Using Sentinel-1 Time Series, Alternating Decision Trees, and Bag-ADTree Models. Complexity 2020, 2020, 4271376. [Google Scholar] [CrossRef]
- Filipponi, F. Sentinel-1 GRD Preprocessing Workflow. Multidiscip. Digital Publ. Inst. Proc. 2019, 18, 11. [Google Scholar] [CrossRef]
- Gašparović, M.; Klobučar, D. Mapping Floods in Lowland Forest Using Sentinel-1 and Sentinel-2 Data and an Object-Based Approach. Forests 2021, 12, 553. [Google Scholar] [CrossRef]
- Kaplan, G.; Avdan, U. Monthly Analysis of Wetlands Dynamics Using Remote Sensing Data. ISPRS Int. J. Geo-Inf. 2018, 7, 411. [Google Scholar] [CrossRef]
- Twele, A.; Cao, W.; Plank, S.; Martinis, S. Sentinel-1-Based Flood Mapping: A Fully Automated Processing Chain. Int. J. Remote Sens. 2016, 37, 2990–3004. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Boehmke, B.; Greenwell, B. Hands-On Machine Learning with R; Chapman and Hall/CRC: London, UK, 2019; ISBN 0367816377. [Google Scholar]
- Zhu, R.; Hu, X.; Hou, J.; Li, X. Application of Machine Learning Techniques for Predicting the Consequences of Construction Accidents in China. Process. Saf. Environ. Prot. 2020, 145, 293–302. [Google Scholar] [CrossRef]
- Pradhan, A.M.S.; Kim, Y.-T. Rainfall-Induced Shallow Landslide Susceptibility Mapping at Two Adjacent Catchments Using Advanced Machine Learning Algorithms. ISPRS Int. J. Geo-Inf. 2020, 9, 569. [Google Scholar] [CrossRef]
- Kramer, O. Dimensionality Reduction with Unsupervised Nearest Neighbors; Springer: Berlin/Heidelberg, Germany, 2013; ISBN 3642386520. [Google Scholar]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine Learning Methods for Landslide Susceptibility Studies: A Comparative Overview of Algorithm Performance. Earth-Science Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Leung, K.M. Naive Bayesian Classifier. Polytech. Univ. Dep. Comput. Sci. Financ. Risk Eng. 2007, 2007, 123–156. [Google Scholar]
- Kelly, D.L.; Kolstad, C.D. Bayesian Learning, Growth, And Pollution. J. Econ. Dyn. Control 1999, 23, 491–518. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Remondo, J.; González-Díez, A.; De Terán, J.R.D.; Cendrero, A.; Fabbri, A.; Chung, C.-J.F. Validation of Landslide Susceptibility Maps; Examples and Applications from a Case Study in Northern Spain. Nat. Hazards 2003, 30, 437–449. [Google Scholar] [CrossRef]
- Frattini, P.; Crosta, G.; Carrara, A. Techniques for Evaluating the Performance of Landslide Susceptibility Models. Eng. Geol. 2010, 111, 62–72. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Foody, G.M. Status of Land Cover Classification Accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, H.; Chen, W.; Li, S.; Panahi, M.; Khosravi, K.; Shirzadi, A.; Shahabi, H.; Panahi, S.; Costache, R. Flood Susceptibility Mapping in Dingnan County (China) Using Adaptive Neuro-Fuzzy Inference System with Biogeography Based Optimization and Imperialistic Competitive Algorithm. J. Environ. Manag. 2019, 247, 712–729. [Google Scholar] [CrossRef]
- Yalcin, A.; Reis, S.; Aydinoglu, A.C.; Yomralioglu, T. A GIS-Based Comparative Study of Frequency Ratio, Analytical Hierarchy Process, Bivariate Statistics and Logistics Regression Methods for Landslide Susceptibility Mapping in Trabzon, NE Turkey. Catena 2011, 85, 274–287. [Google Scholar] [CrossRef]
- Roy, P.; Pal, S.C.; Chakrabortty, R.; Chowdhuri, I.; Malik, S.; Das, B. Threats of Climate and Land Use Change on Future Flood Susceptibility. J. Clean. Prod. 2020, 272, 122757. [Google Scholar] [CrossRef]
- Chakrabortty, R.; Pal, S.C.; Janizadeh, S.; Santosh, M.; Roy, P.; Chowdhuri, I.; Saha, A. Impact of Climate Change on Future Flood Susceptibility: An Evaluation Based on Deep Learning Algorithms and GCM Model. Water Resour. Manag. 2021, 35, 4251–4274. [Google Scholar] [CrossRef]
- Funk, C.; Peterson, P.; Landsfeld, M.; Pedreros, D.; Verdin, J.; Shukla, S.; Husak, G.; Rowland, J.; Harrison, L.; Hoell, A.; et al. The Climate Hazards Infrared Precipitation with Stations—A New Environmental Record for Monitoring Extremes. Sci. Data 2015, 2, 150066. [Google Scholar] [CrossRef] [PubMed]
- Kopecký, M.; Macek, M.; Wild, J. Topographic Wetness Index Calculation Guidelines Based on Measured Soil Moisture and Plant Species Composition. Sci. Total Environ. 2021, 757, 143785. [Google Scholar] [CrossRef] [PubMed]
- Beven, K.J.; Kirkby, M.J. A physically based, variable contributing area model of basin hydrology/Un modèle à base physique de zone d’appel variable de l’hydrologie du bassin versant. Hydrol. Sci. J. 1979, 24, 43–69. [Google Scholar] [CrossRef]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital Terrain Modelling: A Review of Hydrological, Geomorphological, And Biological Applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Moore, I.D.; Wilson, J.P. Length-Slope Factors for the Revised Universal Soil Loss Equation: Simplified Method of Estimation. J. Soil Water Conserv. 1992, 47, 423–428. [Google Scholar]
- Meraj, G.; Romshoo, S.; Yousuf, A.R.; Altaf, S.; Altaf, F. Assessing the Influence of Watershed Characteristics on the Flood Vulnerability of Jhelum Basin in Kashmir Himalaya. Nat. Hazards 2015, 77, 153–175. [Google Scholar] [CrossRef]
- Rimba, A.B.; Setiawati, M.D.; Sambah, A.B.; Miura, F. Physical Flood Vulnerability Mapping Applying Geospatial Techniques in Okazaki City, Aichi Prefecture, Japan. Urban Sci. 2017, 1, 7. [Google Scholar] [CrossRef]
- Pham, B.T.; Luu, C.; Van Phong, T.; Trinh, P.T.; Shirzadi, A.; Renoud, S.; Asadi, S.; Van Le, H.; von Meding, J.; Clague, J.J. Can Deep Learning Algorithms Outperform Benchmark Machine Learning Algorithms in Flood Susceptibility Modeling? J. Hydrol. 2021, 592, 125615. [Google Scholar] [CrossRef]
- Islam, A.R.M.T.; Talukdar, S.; Mahato, S.; Kundu, S.; Eibek, K.U.; Pham, Q.B.; Kuriqi, A.; Linh, N.T.T. Flood Susceptibility Modelling Using Advanced Ensemble Machine Learning Models. Geosci. Front. 2020, 12, 101075. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, J.R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systemsin the Great Plains Witherts. In Proceedings of the 3rd ERTS Symposium, Washington, DC, USA, 1 January 1974; Volume 1. [Google Scholar]
- Almeshreki, D.; Mohamed, H.A. Renewable Natural Resources Research Center (RNRRC) in the Agricultural Research & Extension Authority (AREA), Dhamar, Yemen. Geocarto Int. 2006. [Google Scholar]
- Carlston, C.W. Drainage Density and Streamflow; United States Department of the Interior, Geological Survey: Washington, DC, USA, 1963.
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood Susceptibility Mapping Using a Novel Ensemble Weights-Of-Evidence and Support Vector Machine Models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Ullah, K.; Wang, Y.; Fang, Z.; Wang, L.; Rahman, M. Multi-Hazard Susceptibility Mapping Based on Convolutional Neural Networks. Geosci. Front. 2022, 13, 101425. [Google Scholar] [CrossRef]
- Ali, S.A.; Khatun, R.; Ahmad, A.; Ahmad, S.N. Application of GIS-Based Analytic Hierarchy Process and Frequency Ratio Model to Flood Vulnerable Mapping and Risk Area Estimation at Sundarban Region, India. Model. Earth Syst. Environ. 2019, 5, 1083–1102. [Google Scholar] [CrossRef]
- Mind’Je, R.; Li, L.; Amanambu, A.C.; Nahayo, L.; Nsengiyumva, J.B.; Gasirabo, A.; Mindje, M. Flood Susceptibility Modeling and Hazard Perception in Rwanda. Int. J. Disaster Risk Reduct. 2019, 38, 101211. [Google Scholar] [CrossRef]
- Shahabi, H.; Shirzadi, A.; Ronoud, S.; Asadi, S.; Pham, B.T.; Mansouripour, F.; Geertsema, M.; Clague, J.J.; Bui, D.T. Flash Flood Susceptibility Mapping Using a Novel Deep Learning Model Based on Deep Belief Network, Back Propagation and Genetic Algorithm. Geosci. Front. 2020, 12, 101100. [Google Scholar] [CrossRef]
- Khosravi, K.; Nohani, E.; Maroufinia, E.; Pourghasemi, H.R. A GIS-Based Flood Susceptibility Assessment and Its Mapping in Iran: A Comparison Between Frequency Ratio and Weights-of-Evidence Bivariate Statistical Models with Multi-Criteria Decision-Making Technique. Nat. Hazards 2016, 83, 947–987. [Google Scholar] [CrossRef]
- Khosravi, K.; Panahi, M.; Golkarian, A.; Keesstra, S.D.; Saco, P.M.; Bui, D.T.; Lee, S. Convolutional Neural Network Approach for Spatial Prediction of Flood Hazard at National Scale of Iran. J. Hydrol. 2020, 591, 125552. [Google Scholar] [CrossRef]
- Costache, R.; Pham, Q.B.; Avand, M.; Linh, N.T.T.; Vojtek, M.; Vojteková, J.; Lee, S.; Khoi, D.N.; Nhi, P.T.T.; Dung, T.D. Novel Hybrid Models Between Bivariate Statistics, Artificial Neural Networks and Boosting Algorithms for Flood Susceptibility Assessment. J. Environ. Manag. 2020, 265, 110485. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood Susceptibility Assessment Using GIS-Based Support Vector Machine Model with Different Kernel Types. CATENA 2015, 125, 91–101. [Google Scholar] [CrossRef]
- El-Magd, A.; Ahmed, S. Random Forest and Naïve Bayes Approaches as Tools for Flash Flood Hazard Susceptibility Prediction, South Ras El-Zait, Gulf of Suez Coast, Egypt. Arab. J. Geosci. 2022, 15, 217. [Google Scholar] [CrossRef]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An Ensemble Prediction of Flood Susceptibility Using Multivariate Discriminant Analysis, Classification and Regression Trees, And Support Vector Machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef] [PubMed]
- Hong, H.; Panahi, M.; Shirzadi, A.; Ma, T.; Liu, J.; Zhu, A.-X.; Chen, W.; Kougias, I.; Kazakis, N. Flood Susceptibility Assessment in Hengfeng Area Coupling Adaptive Neuro-Fuzzy Inference System with Genetic Algorithm and Differential Evolution. Sci. Total Environ. 2018, 621, 1124–1141. [Google Scholar] [CrossRef]
- Termeh, S.V.R.; Kornejady, A.; Pourghasemi, H.R.; Keesstra, S. Flood Susceptibility Mapping Using Novel Ensembles of Adaptive Neuro Fuzzy Inference System and Metaheuristic Algorithms. Sci. Total Environ. 2018, 615, 438–451. [Google Scholar] [CrossRef] [PubMed]
- Satarzadeh, E.; Sarraf, A.; Hajikandi, H.; Sadeghian, M.S. Flood Hazard Mapping in Western Iran: Assessment of Deep Learning Vis-À-Vis Machine Learning Models. Nat. Hazards 2021, 111, 1355–1373. [Google Scholar] [CrossRef]
- Çelik, H.E.; Coskun, G.; Cigizoglu, H.K.; Ağıralioğlu, N.; Aydın, A.; Esin, A.I.; Agiralioglu, N. The Analysis of 2004 Flood on Kozdere Stream in Istanbul. Nat. Hazards 2012, 63, 461–477. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Yue, J.; Tu, T. Mapping Flood Susceptibility in Mountainous Areas on a National Scale in China. Sci. Total Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B. Modeling Flood Susceptibility Using Data-Driven Approaches of Naïve Bayes Tree, Alternating Decision Tree, And Random Forest Methods. Sci. Total Environ. 2020, 701, 134979. [Google Scholar] [CrossRef]
- Janizadeh, S.; Avand, M.; Jaafari, A.; Van Phong, T.; Bayat, M.; Ahmadisharaf, E.; Prakash, I.; Pham, B.T.; Lee, S. Prediction Success of Machine Learning Methods for Flash Flood Susceptibility Mapping in the Tafresh Watershed, Iran. Sustainability 2019, 11, 5426. [Google Scholar] [CrossRef]
- Ahmadisharaf, E.; Kalyanapu, A.J.; Chung, E.-S. Sustainability-Based Flood Hazard Mapping of the Swannanoa River Watershed. Sustainability 2017, 9, 1735. [Google Scholar] [CrossRef]
- Ahmadisharaf, E.; Camacho, R.A.; Zhang, H.X.; Hantush, M.M.; Mohamoud, Y.M. Calibration and Validation of Watershed Models and Advances in Uncertainty Analysis in TMDL Studies. J. Hydrol. Eng. 2019, 24, 3119001. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dates | Product Type | Sensor Mode | Platform | Path |
|---|---|---|---|---|
| 12 April 2021 6 May 2021 | Ground range detected (GRD) | Interferometry Wide swath (IW) | S1A | Ascending |
| No | Data Type | Source | Period | Mapping Output |
|---|---|---|---|---|
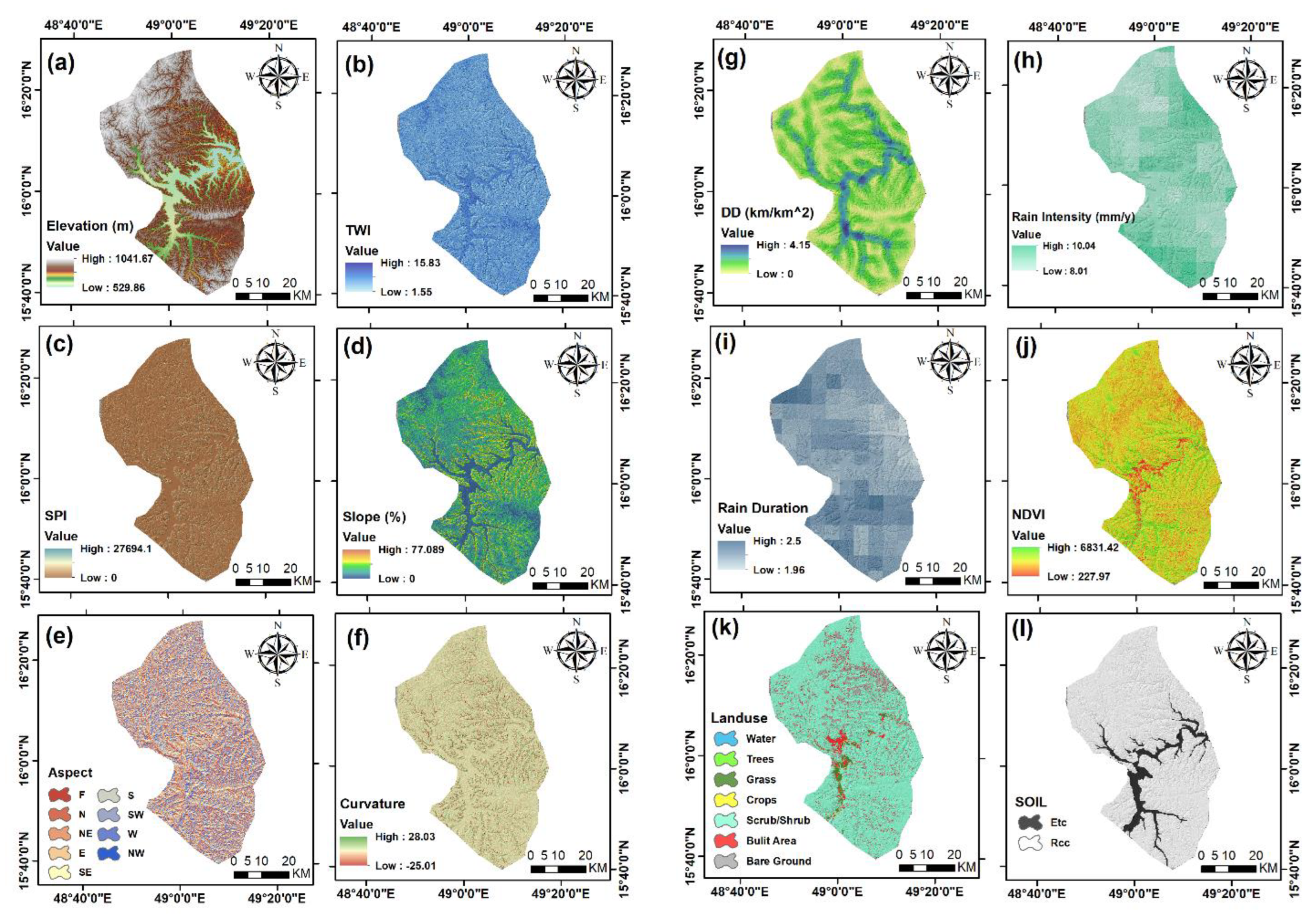
| 1 | ALOSPALSAR (D.E.M./12.5 m) | Alaska satellite facility (ASF) https://search.asf.alaska.edu (accessed on 1 January 2021) | 2021 | Elevation, Slope, Aspect, Curvature, SPI, Drainage Density, and TWI. |
| 2 | Sentinel 2 (10 m) | https://scihub.copernicus.eu (accessed on 6 May 2021) | 2021 | NDVI map |
| 3 | Land use/Land cover (10 m) | https://livingatlas.arcgis.com/landcover (accessed on 26 June 2021) | 2021 | LU/LC map |
| 4 | Rainfall data | https://code.earthengine.google.com (accessed on 1 January 2021) | 1996–2021 | Rain Intensity, Rain Duration maps |
| 5 | Soil Data | (RNRRC.) in (AREA), Dhamar, Yemen | 2006 | Soil type |
| No. | Factors | Collinearity Statistics |
|---|---|---|
| Tolerance | ||
| 1 | Aspect | 0.916 |
| 2 | Curvature | 0.905 |
| 3 | Drainage density | 0.514 |
| 4 | Elevation | 0.393 |
| 5 | LANDUSE | 0.775 |
| 6 | NDVI | 0.726 |
| 7 | Rain duration | 0.565 |
| 8 | Rain intensity | 0.592 |
| 9 | Slope | 0.292 |
| 10 | SOIL | 0.497 |
| 11 | SPI | 0.871 |
| 12 | TWI | 0.369 |
| Parameter | RF | KNN | NB | XGBoost |
|---|---|---|---|---|
| Positive predictive value (%) | 0.9494 | 0.8202 | 0.7308 | 0.9487 |
| Negative predictive value (%) | 0.9437 | 0.9016 | 0.9348 | 0.9306 |
| Sensitivity (%) | 0.9494 | 0.9241 | 0.962 | 0.9367 |
| Specificity (%) | 0.9437 | 0.7746 | 0.6056 | 0.9437 |
| Accuracy (%) | 0.9467 | 0.8533 | 0.7933 | 0.9402 |
| Models | AUC | 95% of Confidence Interval (CI) | Kappa Index |
|---|---|---|---|
| RF | 0.982 | 0.8976–0.9767 | 0.893 |
| KNN | 0.928 | 0.7864–0.9057 | 0.7037 |
| NB | 0.920 | 0.7197–0.8551 | 0.578 |
| XGBoost | 0.979 | 0.8892–0.9722 | 0.8797 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Aizari, A.R.; Al-Masnay, Y.A.; Aydda, A.; Zhang, J.; Ullah, K.; Islam, A.R.M.T.; Habib, T.; Kaku, D.U.; Nizeyimana, J.C.; Al-Shaibah, B.; et al. Assessment Analysis of Flood Susceptibility in Tropical Desert Area: A Case Study of Yemen. Remote Sens. 2022, 14, 4050. https://doi.org/10.3390/rs14164050
Al-Aizari AR, Al-Masnay YA, Aydda A, Zhang J, Ullah K, Islam ARMT, Habib T, Kaku DU, Nizeyimana JC, Al-Shaibah B, et al. Assessment Analysis of Flood Susceptibility in Tropical Desert Area: A Case Study of Yemen. Remote Sensing. 2022; 14(16):4050. https://doi.org/10.3390/rs14164050
Chicago/Turabian StyleAl-Aizari, Ali R., Yousef A. Al-Masnay, Ali Aydda, Jiquan Zhang, Kashif Ullah, Abu Reza Md. Towfiqul Islam, Tayyiba Habib, Dawuda Usman Kaku, Jean Claude Nizeyimana, Bazel Al-Shaibah, and et al. 2022. "Assessment Analysis of Flood Susceptibility in Tropical Desert Area: A Case Study of Yemen" Remote Sensing 14, no. 16: 4050. https://doi.org/10.3390/rs14164050