
A Detection Approach for Floating Debris Using Ground Images Based on Deep Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Method
2.2.1. YOLOv5
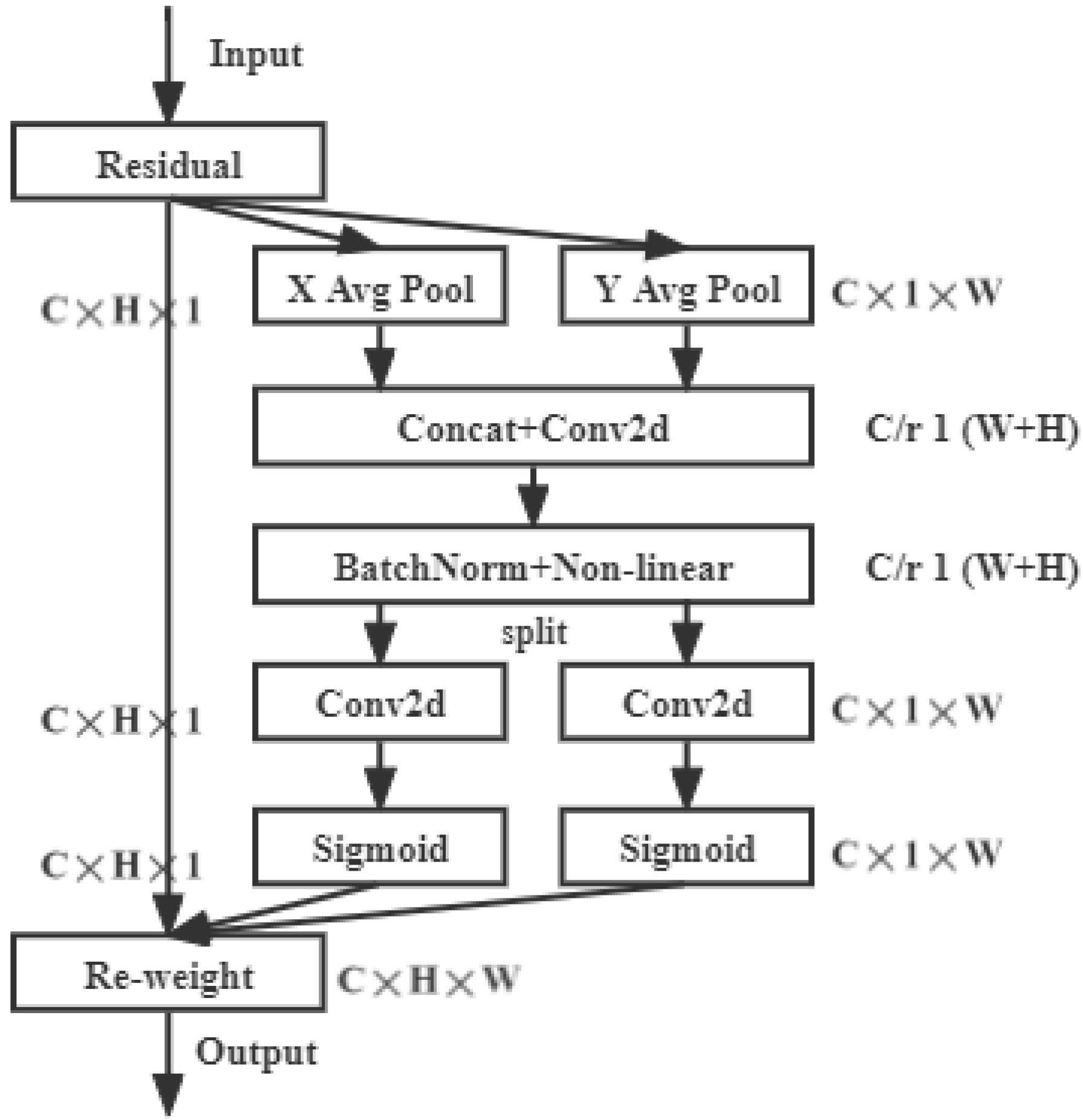
2.2.2. Improved Backbone Network
2.2.3. Multi-Scale Feature Fusion with BiFPN
2.2.4. Improved YOLOv5
3. Results and Discussion
3.1. Comparative Methods and Metrics
3.2. Results on SWFD Dataset
3.3. Ablation Studies
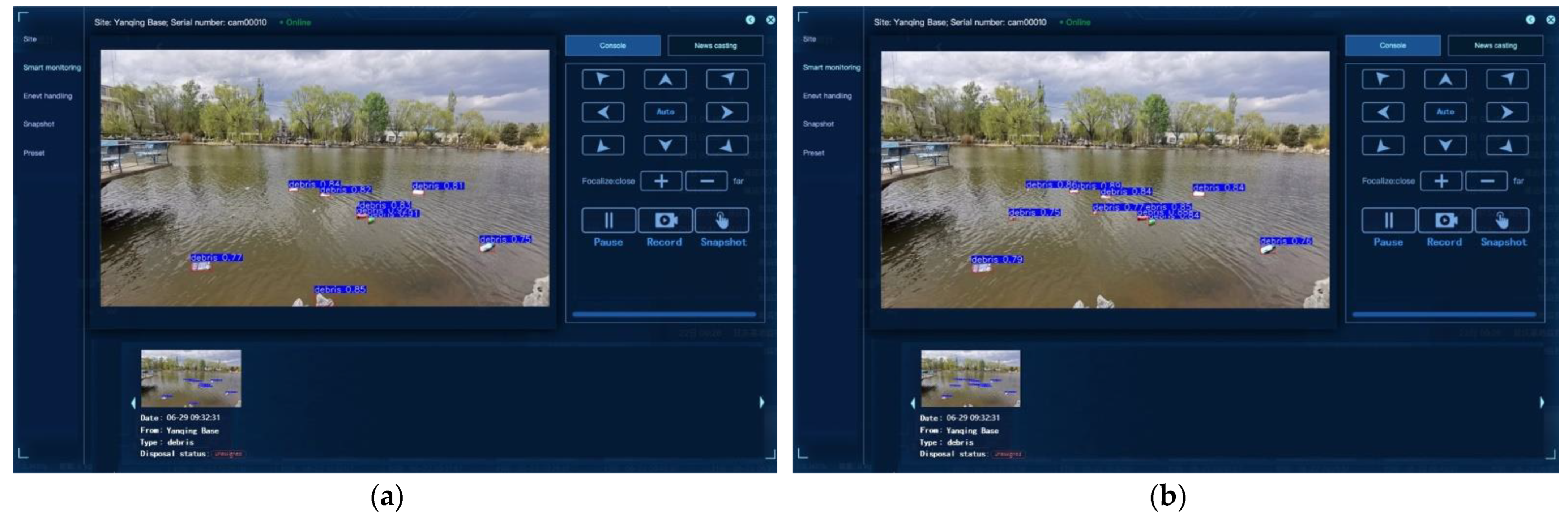
3.4. Validate with the Published System
3.5. Importance of Analysis of Lightweight Models in Floating Debris Detection
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gasperi, J.; Dris, R.; Bonin, T.; Rocher, V.; Tassin, B. Assessment of floating plastic debris in surface water along the Seine River. Environ. Pollut. 2014, 195, 163–166. [Google Scholar] [CrossRef]
- Jang, S.W.; Kim, D.H.; Seong, K.T.; Chung, Y.H.; Yoon, H.J. Analysis of floating debris behaviour in the Nakdong River basin of the southern Korean peninsula using satellite location tracking buoys. Mar. Pollut. Bull. 2014, 88, 275–283. [Google Scholar] [CrossRef] [PubMed]
- Grbić, J.; Helm, P.; Athey, S.; Rochman, C.M. Microplastics entering northwestern Lake Ontario are diverse and linked to urban sources. Water Res. 2020, 174, 115623. [Google Scholar] [CrossRef] [PubMed]
- Wagner, S.; Klöckner, P.; Stier, B.; Römer, M.; Seiwert, B.; Reemtsma, T.; Schmidt, C. Relationship between Discharge and River Plastic Concentrations in a Rural and an Urban Catchment. Environ. Sci. Technol. 2019, 53, 10082–10091. [Google Scholar] [CrossRef]
- Zheng, W.; Han, Z.; Zhao, Z. A study on the current situation of floating debris in Haihe River of Tianjin and the Counter-measures. Environ. Sanit. Eng. 2001, 3, 123–126. [Google Scholar]
- Jeevan, G.; Zacharias, G.C.; Nair, M.S.; Rajan, J. An empirical study of the impact of masks on face recognition. Pattern Recogn. 2022, 122, 108308. [Google Scholar] [CrossRef]
- Liu, L.; Lu, S.; Zhong, R.; Wu, B.; Yao, Y.; Zhang, Q.; Shi, W. Computing Systems for Autonomous Driving: State of the Art and Challenges. IEEE Internet Things J. 2021, 8, 6469–6486. [Google Scholar] [CrossRef]
- Xie, J.; Pang, Y.; Khan, M.H.; Anwer, R.M.; Khan, F.S.; Shao, L. Mask-Guided Attention Network and Occlusion-Sensitive Hard Example Mining for Occluded Pedestrian Detection. IEEE Trans. Image Process. 2021, 30, 3872–3884. [Google Scholar] [CrossRef]
- Zeng, Z.; Liu, B.; Fu, J.; Chao, H. Reference-Based Defect Detection Network. IEEE Trans. Image Process. 2021, 30, 6637–6647. [Google Scholar] [CrossRef]
- Han, P.; Ma, C.; Li, Q.; Leng, P.; Bu, S.; Li, K. Aerial image change detection using dual regions of interest networks. Neurocomputing 2019, 349, 190–201. [Google Scholar] [CrossRef]
- Tsai, J.; Hung, I.Y.; Guo, Y.L.; Jan, Y.; Lin, C.; Shih, T.T.; Chen, B.; Lung, C. Lumbar Disc Herniation Automatic Detection in Magnetic Resonance Imaging Based on Deep Learning. Front. Bioeng. Biotechnol. 2021, 9, 708137. [Google Scholar] [CrossRef] [PubMed]
- Ojha, S.; Sakhare, S. Image processing techniques for object tracking in video surveillance—A survey. In Proceedings of the 2015 International Conference on Pervasive Computing (ICPC), Pune, India, 8–10 January 2015. [Google Scholar]
- Lin, Y.; Zhu, Y.; Shi, F.; Yin, H.; Yu, J.; Huang, P.; Hou, D. Image Processing Techniques for UAV Vision-Based River Floating Contaminant Detection. In Proceedings of the 2019 Chinese Automation Congress (CAC2019), Hangzhou, China, 22–24 November 2019; pp. 89–94. [Google Scholar]
- Zhang, L.; Wei, Y.; Wang, H.; Shao, Y.; Shen, J. Real-Time Detection of River Surface Floating Object Based on Improved RefineDet. IEEE Access 2021, 9, 81147–81160. [Google Scholar] [CrossRef]
- Lin, F.; Hou, T.; Jin, Q.; You, A. Improved YOLO Based Detection Algorithm for Floating Debris in Waterway. Entropy 2021, 23, 1111. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–18 June 2013. [Google Scholar]
- Zhu, L.; Geng, X.; Li, Z.; Liu, C. Improving YOLOv5 with Attention Mechanism for Detecting Boulders from Planetary Images. Remote Sens. 2021, 18, 3776. [Google Scholar] [CrossRef]
- Jin, S.; Sun, L. Application of Enhanced Feature Fusion Applied to YOLOv5 for Ship Detection. In Proceedings of the 33rd Chinese Control and Decision Conference (CCDC 2021), Kunming, China, 22–24 May 2021. [Google Scholar]
- Shi, X.; Hu, J.; Lei, X.; Xu, S. Detection of Flying Birds in Airport Monitoring Based on Improved YOLOv5. In Proceedings of the 2021 6th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 9–11 April 2021; pp. 1446–1451. [Google Scholar]
- Chai, E.H.; Zhi, M. Rapid Pedestrian Detection Algorithm Based on Deformable Part Model. In Proceedings of the Ninth International Conference on Digital Image Processing (ICDIP 2017), Hong Kong, China, 19–22 May 2017; Volume 10420. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Dai, J.F.; Li, Y.; He, K.M.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Advances in Neural Information Processing Systems 29 (NIPS 2016), Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; NeurIPS: San Diego, CA, USA, 2016; Volume 29, p. 29. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.F.; Shi, J.P.; Jia, J.Y. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. [Google Scholar]
- Jie, H.; Li, S.; Gang, S.; Albanie, S. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. 2020, 42, 2011–2023. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.; Kweon, I.S. BAM: Bottleneck Attention Module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018, PT VII, Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. arXiv 2019, arXiv:1911.09070. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | From | N | Params | Module | Arguments |
|---|---|---|---|---|---|
| 0 | −1 | 1 | 3520 | Conv | [3, 32, 6, 2, 2] |
| 1 | −1 | 1 | 18,560 | Conv | [32, 64, 3, 2] |
| 2 | −1 | 1 | 18,816 | C3 | [64, 4, 1] |
| 4 | −1 | 1 | 73,984 | Conv | [64, 128, 3, 2] |
| 5 | −1 | 2 | 115,712 | C3 | [128, 128, 2] |
| 7 | −1 | 1 | 295,424 | Conv | [128, 256, 3, 2] |
| 8 | −1 | 3 | 625,152 | C3 | [256, 256, 3] |
| 10 | −1 | 1 | 1,180,672 | Conv | [256, 512, 3, 2] |
| 11 | −1 | 1 | 1,182,720 | C3 | [512, 512, 1] |
| 12 | −1 | 1 | 25,648 | CA | [512, 512, 32] |
| 13 | −1 | 1 | 656,896 | SPPF | [512, 512, 5] |
| 14 | −1 | 1 | 131,584 | Conv | [512, 256, 1, 1] |
| 15 | −1 | 1 | 0 | Upsample | [None, 2, ‘nearest’] |
| 16 | [−1, 6] | 1 | 65,794 | Concat_BiFPN | [256, 256] |
| 17 | −1 | 1 | 296,448 | C3 | [256, 256, 1, False] |
| 18 | −1 | 1 | 33,024 | Conv | [256, 128, 1, 1] |
| 19 | −1 | 1 | 0 | Upsample | [None, 2, ‘nearest’] |
| 20 | [−1, 4] | 1 | 16,514 | Concat_BiFPN | [128, 128] |
| 21 | −1 | 1 | 74,496 | C3 | [128, 128, 1, False] |
| 22 | −1 | 1 | 295,424 | Conv | [128, 128, 3, 2] |
| 23 | [−1, 14, 6] | 1 | 65,795 | Concat_BiFPN | [256, 256] |
| 24 | −1 | 1 | 296,448 | C3 | [256, 256, 1, False] |
| 25 | −1 | 1 | 590,336 | Conv | [256, 256, 3, 2] |
| 26 | [−1, 11] | 1 | 65,794 | Concat_BiFPN | [256, 256] |
| 27 | −1 | 1 | 1,051,648 | C3 | [256, 512, 1, False] |
| Label | Methods | Recall (%) | AP (%) | AP50 (%) | AP75 (%) | Weights/MB |
|---|---|---|---|---|---|---|
| debris | Faster R-CNN | 90.1 | 90.2 | 92.8 | 90.7 | 158.5 |
| SSD | 77.9 | 80.8 | 84.3 | 81.4 | 102.3 | |
| YOLOv3 | 83.8 | 88.6 | 91.7 | 89.9 | 322.5 | |
| YOLOv5s | 93.9 | 92.4 | 95.1 | 93.8 | 14.1 | |
| Proposed | 96.5 | 95.8 | 97.9 | 97.1 | 15.9 |
| Label | Methods | CA | BiFPN | Recall (%) | AP (%) |
|---|---|---|---|---|---|
| debris | YOLOv5s | √ | 90.1 | 92.4 | |
| CA-YOLOv5 | √ | 92.2 | 91.4 | ||
| Bi-YOLOv5 | √ | 93.1 | 92.9 | ||
| Proposed | √ | √ | 96.5 | 95.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, G.; Yang, M.; Wang, H. A Detection Approach for Floating Debris Using Ground Images Based on Deep Learning. Remote Sens. 2022, 14, 4161. https://doi.org/10.3390/rs14174161
Qiao G, Yang M, Wang H. A Detection Approach for Floating Debris Using Ground Images Based on Deep Learning. Remote Sensing. 2022; 14(17):4161. https://doi.org/10.3390/rs14174161
Chicago/Turabian StyleQiao, Guangchao, Mingxiang Yang, and Hao Wang. 2022. "A Detection Approach for Floating Debris Using Ground Images Based on Deep Learning" Remote Sensing 14, no. 17: 4161. https://doi.org/10.3390/rs14174161