1. Introduction
Remote sensing imagery (RSI) is collected by intermediate imaging sensors, commonly equipped on satellite, aircraft, and unmanned aerial vehicles (UAVs), observing ground objects without direct physical contact [
1]. Therefore, an exhaustive semantic understanding of RSI impacts profoundly for downstream tasks, such as water resource management [
2,
3], land cover classification [
4,
5,
6], urban planning [
7,
8,
9], hazard assessment [
10,
11], and so forth. Striving to produce semantic labels of each pixel with a specific class, semantic segmentation [
12], which is incipiently developed for natural image processing, has been implemented to remote sensing imagery with outstanding performance.
Conventional segmentation approaches principally deployed handcrafted features as the guidance for recognizing the pixels. Initially, classical methods, such as logistic regression [
13] and distance measures [
14], were taken because of stability and ease-of-use. Latterly, some superior models, such as support vector machine (SVM) [
15], Markov random fields (MRFs) [
16], random forest (RF) [
17], and conditional random fields (CRFs) [
18], were developed to boost the classifier. However, despite introducing robust classifiers, the artificially selected features inherently constrain the overall performance, especially the unsatisfactory accuracy.
Recently, deep convolutional neural networks (DCNNs) have expressed salient benefits in computer vision tasks [
19]. Concretely, DCNNs enable automatically derived features tailored for the targeted classification tasks, making such methods better choices for handling complicated scenarios. Then, the DCNNs intrigued the remote sensing community to study their application to RSI processing. As a result, various DCNN-based RSI interpretation methods were devised, demonstrating the flexibility and adaptability in understanding multi-sources and multi-resolution RSI [
20,
21]. Beyond simultaneously learning representation and training the classifier, as for semantic segmentation, fully convolutional networks (FCNs) were pioneeringly designed for semantic segmentation tasks [
22]. Three stages are involved in FCNs: multiple convolutional layers, deconvolution, and fusion. Therefore, FCNs perform as an end-to-end trainable segmentation network. Subsequently, Badrinarayanan et al. [
23] defined and extended the encoder–decoder architecture within the proposed SegNet, which remedies the transformation loss in shrinking and expanding feature maps. To further introduce the contextual information, several skip connections are incorporated in U-Net, enhancing the fidelity and distinguishability of learnt representations [
24]. Nevertheless, ascribing to the fixed geometry structure of CNN, these methods are inherently limited by local receptive fields and short-range context. Moreover, RSI with a wide range, diverse objects, and jagged resolutions is more challenging than natural imagery.
After reviewing the studies, it can be concluded that context utilization is a feasible solution for boosting the discriminative ability of learnt representations. Two alternatives were introduced to aggregate rich contextual information, augmenting the pixel-wise representations in segmentation networks. First, different-scale dilated convolutional layers or pooling functions are appended in several works from the perspective of encoding multi-scale features. For RSI semantic segmentation, MLCRNet was proposed and reached preferable performance on ISPRS Potsdam and Vaihingen benchmarks with multi-level context aggregation [
25]. Likewise, Shang et al. also designed a multi-scale feature fusion network based on atrous convolutions [
26]. Du et al. devised a similar semantic segmentation network to map urban functional zones [
27].
Another skillful manipulation is embedding attention modules designed to capture long-range dependencies. Attention is a behavioral and cognitive process of focusing selectively on a discrete aspect of information, whether subjective or objective, while ignoring other perceptible information, playing an essential role in human cognition and living beings’ survival [
28]. Benefitting from the attention mechanism, the network can focus on where more information lies, improving the representation of essential areas. Thus, the segmentation accuracy has risen significantly with the emerging attention-based methods [
29]. For RSI, Li et al. [
30] proposed dual attention and deep fusion strategies to address the problem of segmenting large-scale satellite RSI. Li et al. proposed a multi-attention network to extract contextual dependencies while retaining efficiency [
31]. HCANet was proposed to hybridize cross-level contextual and attentive representations via the attention mechanism [
32]. EDENet attentively learned edge distributions by designing a distribution attention module to inject edge information in a learnable fashion [
33]. HMANet [
34] adaptively captures the correlations that lie in space, channel, and category domains effectively. Lei et al. [
35] proposed LANet to bridge the gap between high-level and low-level features by embedding the local focus with a patch attention module. In general, the attention mechanism has been proved to be superior in the task of the RSI field, helping the models recognize and accept the diverse intra-class variance and inconspicuous inter-class variance.
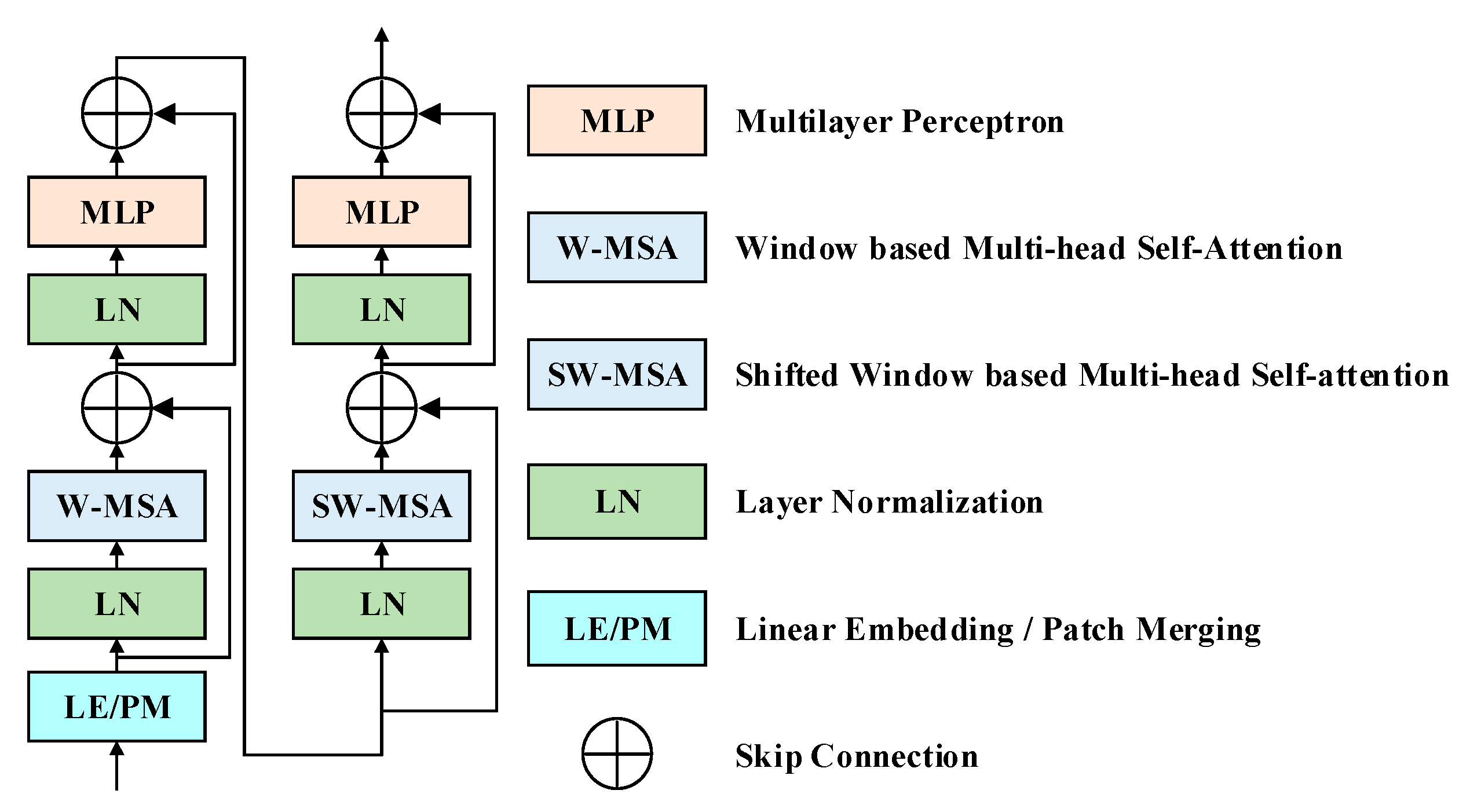
Transformers have recently revolutionized natural language processing (NLP) and computer vision (CV) tasks based on multi-head self-attention [
36]. Semantic segmentation is inevitably ignited by transformers, which performed the capability of modeling rich interactions between pixels. SEgmentation Transformer (SETR) [
37] treated the semantic segmentation as a sequence-to-sequence prediction task, encoding an image as a sequence of patches for natural imagery. Therefore, the global context is modeled and contributes to generating dense predictions. Specifically, powerful capability makes the results state-of-the-art. SegFormer started from the efficiency optimization by comprising an encoder and avoiding decoder [
38]. Meanwhile, to eliminate the computational costs and perpetuate the sufficient context, Swin Transformer (ST) has been presented [
39]. The hierarchical architecture has the flexibility to model at various scales and has linear computational complexity concerning image size. Consequently, this model surpassed previous state-of-the-art dense prediction approaches by a large margin.
Predominantly, CNNs and transformers both blossomed and demonstrated exemplary performance. CNNs emphasize extracting local patterns, while transformers focus on global ones. From the essence perspective of a digital image, the 2D local structure is ubiquitous. For example, spatially neighboring pixels are usually highly correlated. CNNs’ local receptive fields, shared weights, and spatial subsampling force the capture of local patterns. Transformers tokenized the image and sequentially computed the long-range dependencies (also known as global context) to compensate information for inferencing pixels. Accordingly, uniquely forming RSI segmentation models by CNNs or transformers will lead to the deficiency of locality or globality. Detailedly, we summarize the current issues as two aspects.
- (1)
Pure transformers have demonstrated astounding performance on computer vision tasks with their impressive and robust scalability in establishing long-range dependencies. However, pure transformers flatten the raw image into single-dimensional signals for high-resolution remote sensing imagery, breaking the inherent structures and missing countless details. After revisiting convolutions, CNNs enable the learning of the locality that supplies complementary geometric and topologic information from low-level features fundamentally. Therefore, it is necessary to sufficiently coalesce the convolved local patterns and attentive affinity, which greatly enriches local and distant contextual information, strengthening the distinguishability of learnt representations.
- (2)
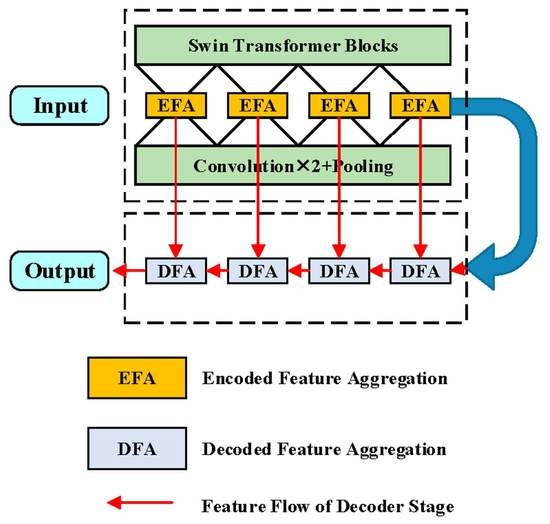
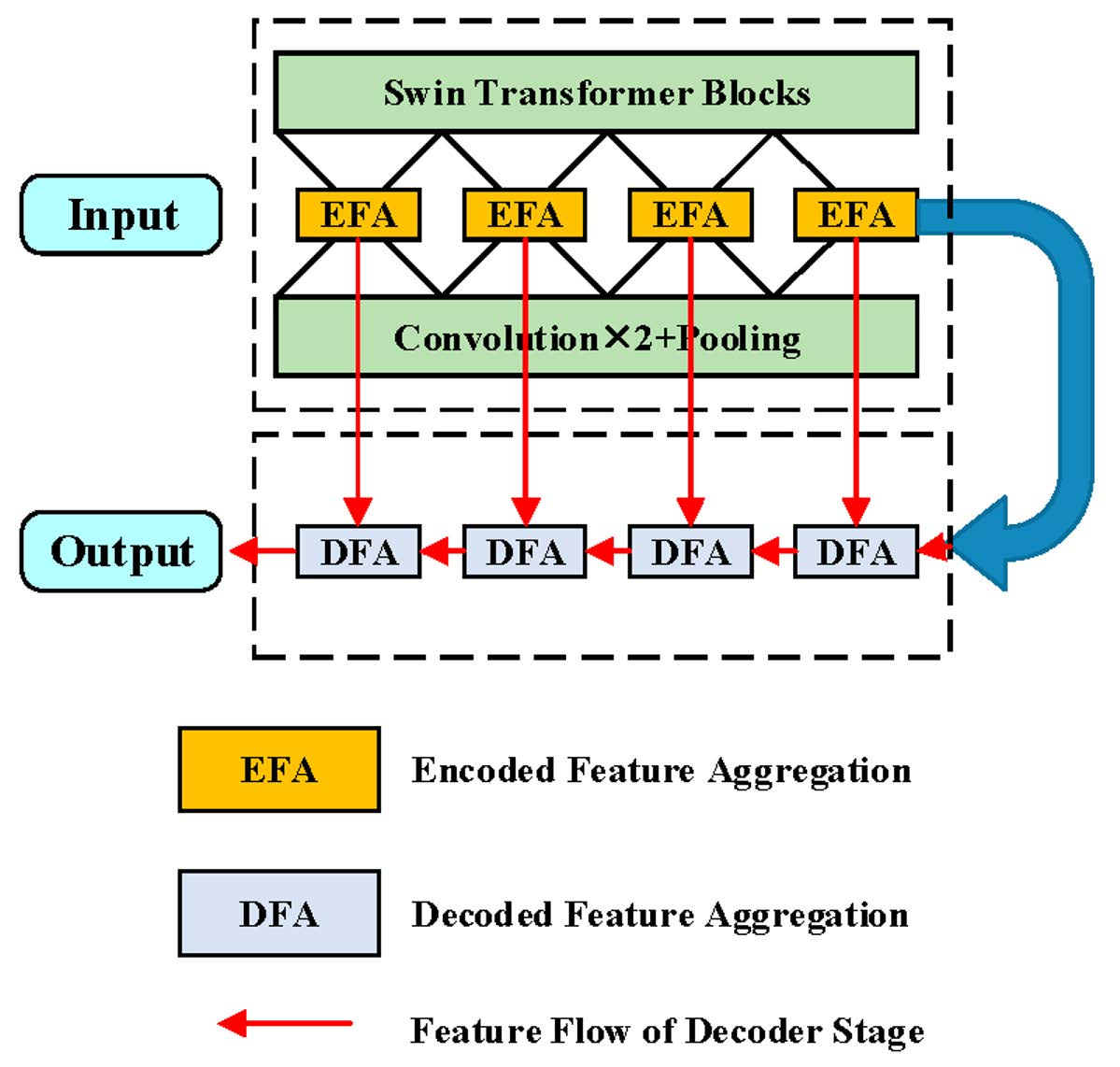
Apart from encoding distinguishable pixel-wise representations, the decoder also plays a vital role in recovering feature maps while preserving the fundamental features. However, the transform loss is inevitable as the network deepens. The existing decoders deploy multiple stages to constantly enlarge the spatial resolution from former layers by bilinear upsampling. Moreover, the shallow layers’ low-level features that contain valuable clues for predictions are not aggregated with relevant decoded ones.
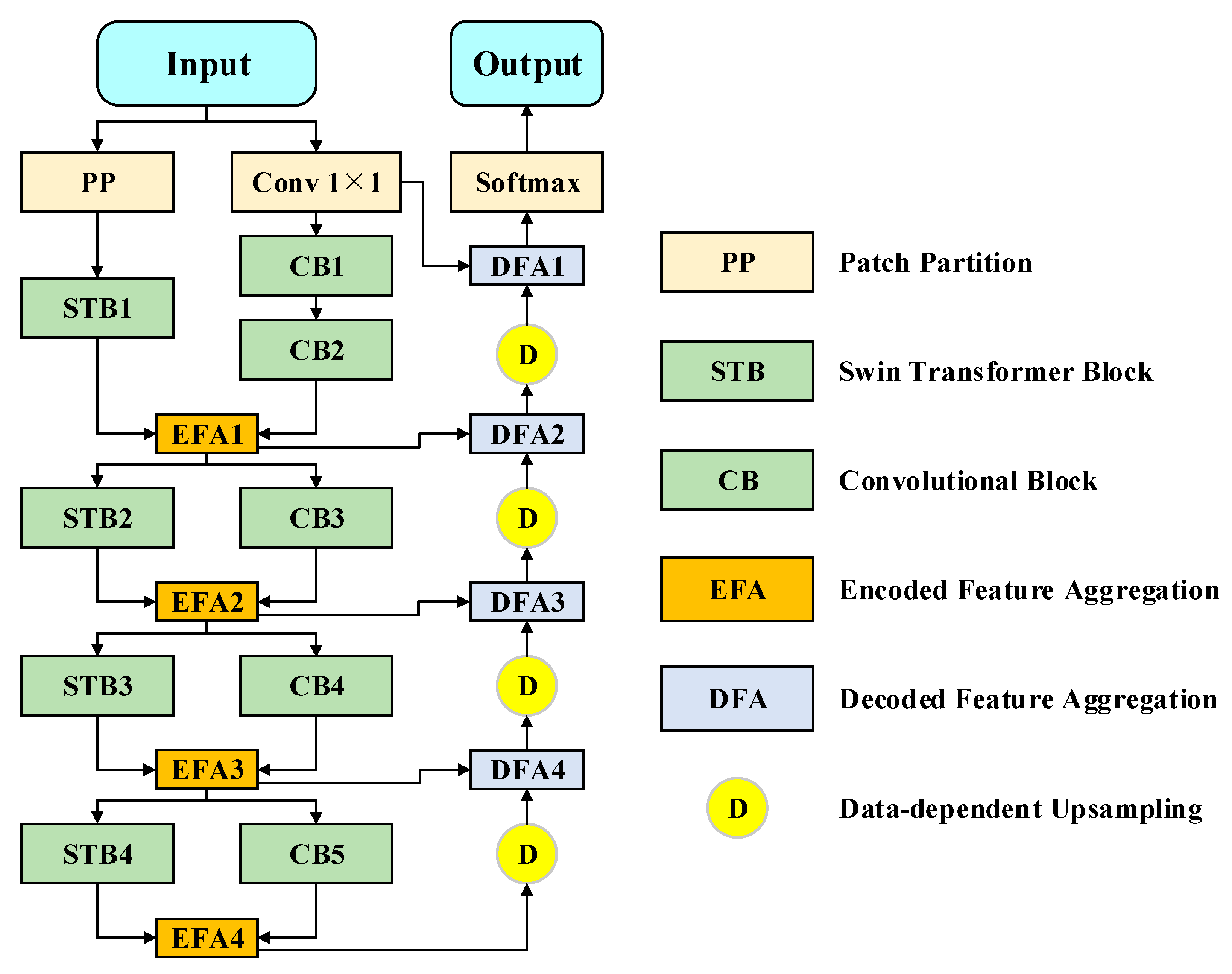
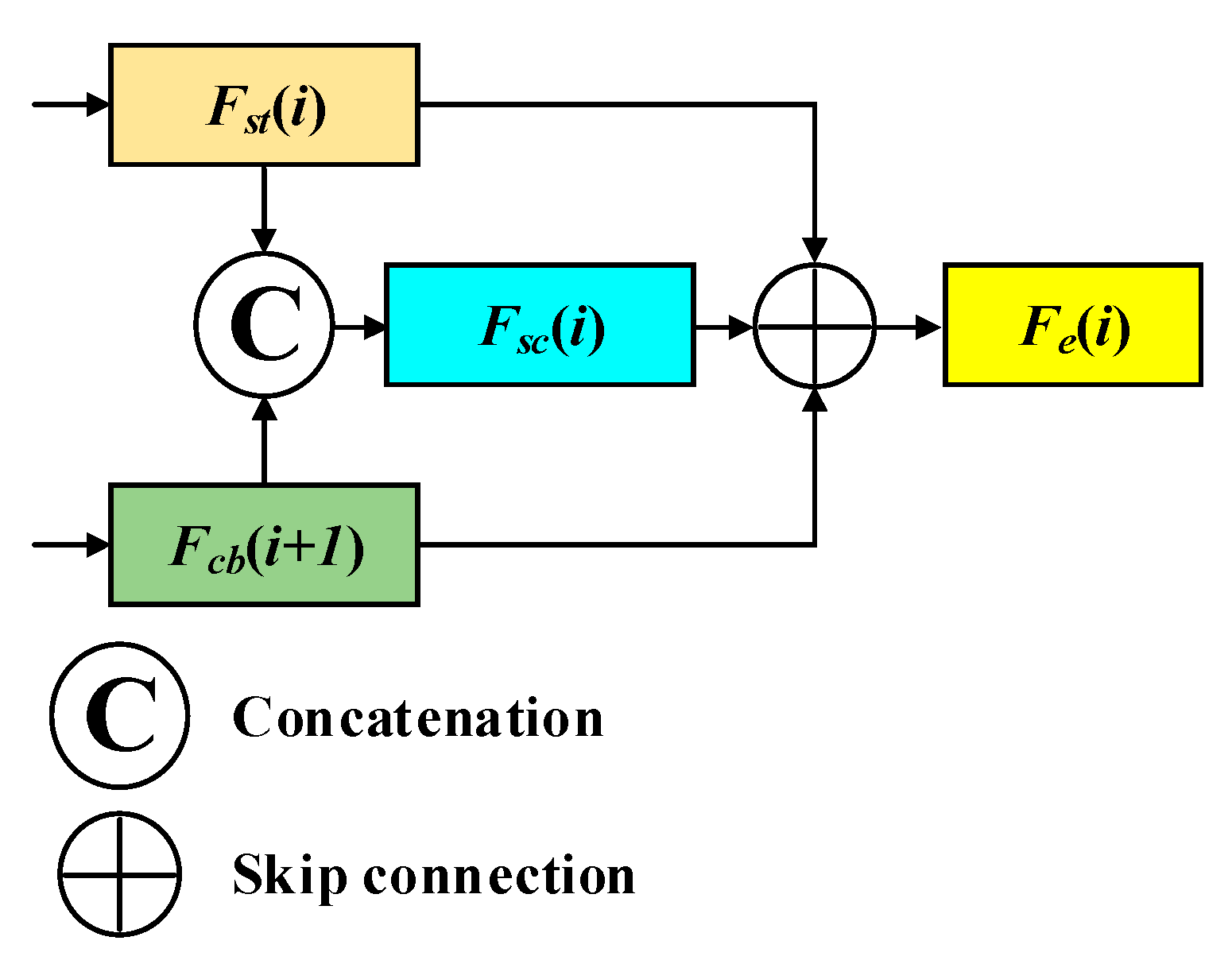
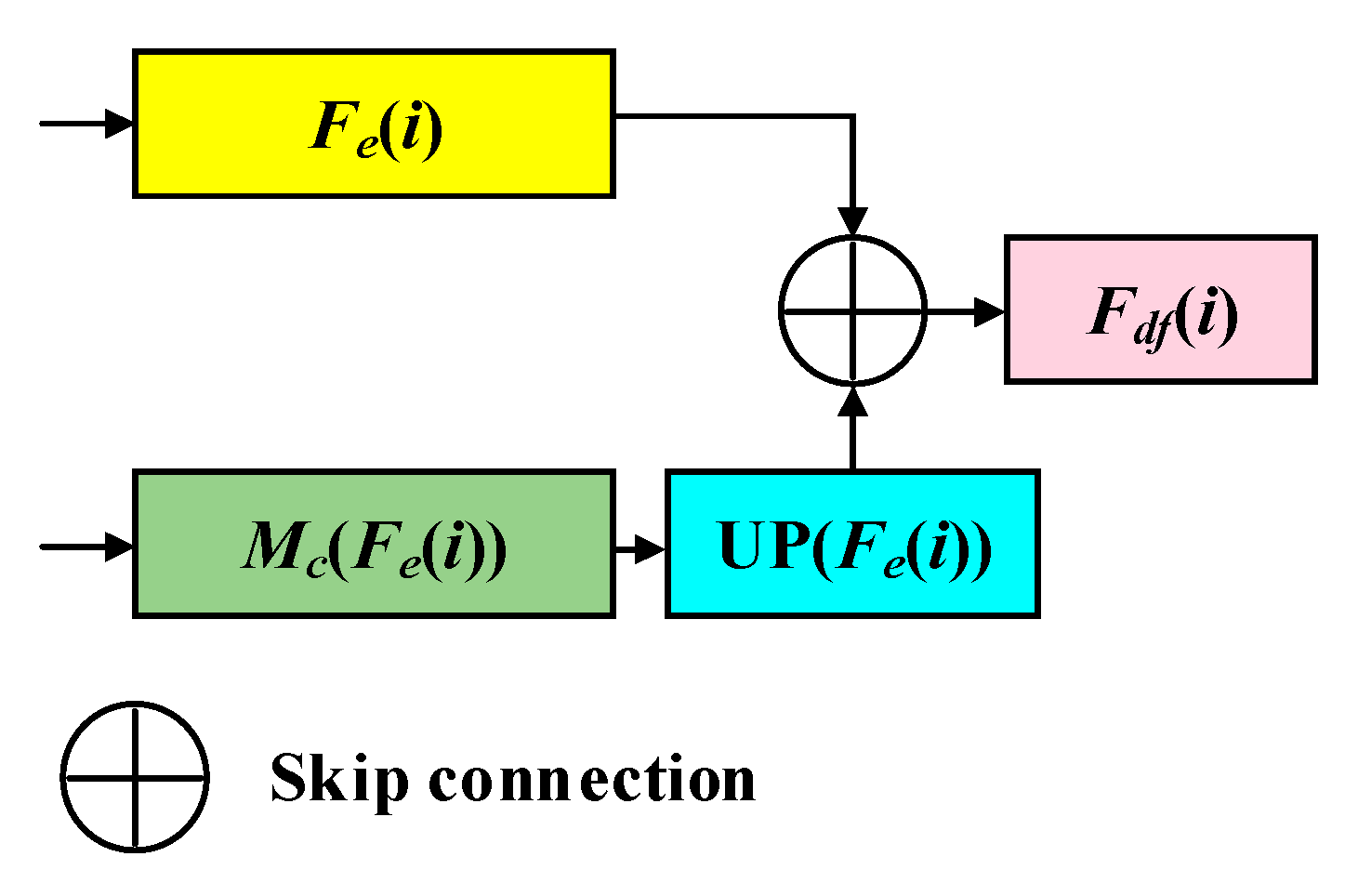
Attempting to confront the deficiencies mentioned above, ICTNet is devised to properly encode contextual dependencies in the encoder stage and recover learnt feature maps without information sacrifice. Explicitly speaking, we creatively propose a context encoder (CE) by interlacing CNNs and ST modules for producing demanding representations, which possess plentiful global and local contextual details. Along with the crafted loss-free decoder, which involves data-dependent upsampling (DUP) [
40] modules and multi-scale feature fusion strategy, the feature maps that support the dense prediction are eventually generated with dependable inference clues. In a nutshell, three contributions are summarized as follows:
- (1)
To leverage long-range visual dependencies and local patterns simultaneously, a typical encoder that interlaces convolution and transformer hierarchically is proposed to produce fine-grained features with high representativeness and distinguishability. This design of gradually integrating convolved and transformed representations facilitates the network to exploit the advantages of convolutions in extracting low-level features, strengthening locality, and the advantages of transformers in modeling distant visual dependencies at multiple scales.
- (2)
Striving to recover the features losslessly and efficiently, in the decoder stage, DUP followed by fusing with a corresponding encoded feature map is devised as the basic unit for constantly expanding spatial resolution. Instead of multiple convolutions and upsampling operations, one-step matrix projection refers to DUP enabling well-preserved details while enlarging spatial size with an arbitrary spatial ratio.
- (3)
Concerning the variants and heterogeneity of aerial and satellite imagery, extensive experiments are conducted on three typical semantic segmentation benchmarks of remote sensing imagery, including ISPRS Vaihingen [
41], ISPRS Potsdam [
42], and DeepGlobe [
43]. Quantitative and qualitative evaluations are compared and analyzed to validate the effectiveness and superiority. Furthermore, the ablation study is implemented to verify the efficacy of incorporating the transformer and the designed decoder.
The rest of the paper is organized as follows.
Section 2 presents the related works of semantic segmentation of RSI and transformers.
Section 3 introduces the devised overall network architecture and each sub-module associated with the formulation.
Section 4 collects and compares the results on three representative RSI datasets to validate the performance of the proposed ICTNet, followed by necessary discussions. Finally,
Section 5 draws the conclusions and points out the future directions.
4. Experiments and Discussion
In this section, extensive experiments are conducted on three benchmarks. We first present the experimental settings, data descriptions, and numerical metrics. Next, the qualitative and quantitative evaluations are compared. Moreover, the ablation study of DFA is implemented.
4.1. Settings
In this section, we present the settings of experiments. First of all, three benchmarks are introduced. Nets, the implement details, and comparative methods are presented. Finally, the numerical metrics are given.
4.1.1. Datasets
Three benchmarks are used to evaluate the performance, including aerial and satellite imagery. The details are given as follows.
The ISPRS Vaihingen dataset is acquired from an aerial platform, observing the town of Vaihingen in Germany. The spatial resolution is 9 cm. Six categories are labeled, including impervious surfaces, buildings, low vegetation, trees, cars, and clutter. Specifically, clutter is served as a background class and ignored in accuracy evaluation. The publicly available data consist of 33 true orthophoto (TOP) tiles with an average spatial size of 2494 × 2064. Three spectral bands, red (R), green (G), and near-infrared (NIR), are involved in forming the false-color image. There are 14 images of the earlier shared data for training and 2 images for validation. Moreover, the other 17 images are for test. An example of this dataset is illustrated in
Figure 5.
- 2.
ISPRS Potsdam Benchmark
The ISPRS Potsdam dataset is acquired from an aerial platform with a spatial resolution of 5 cm. Ground truth contains the same six categories as the ISPRS Vaihigen benchmark. Four bands, R, G, blue (B), and NIR, are available, in which R, G, and B bands form the raw input imagery. The spatial size of each image is 6000 × 6000. There are 26 images for training, 4 images for validation and 8 images for test. An example of this dataset is illustrated in
Figure 6.
- 3.
DeepGlobe Land Cover Dataset
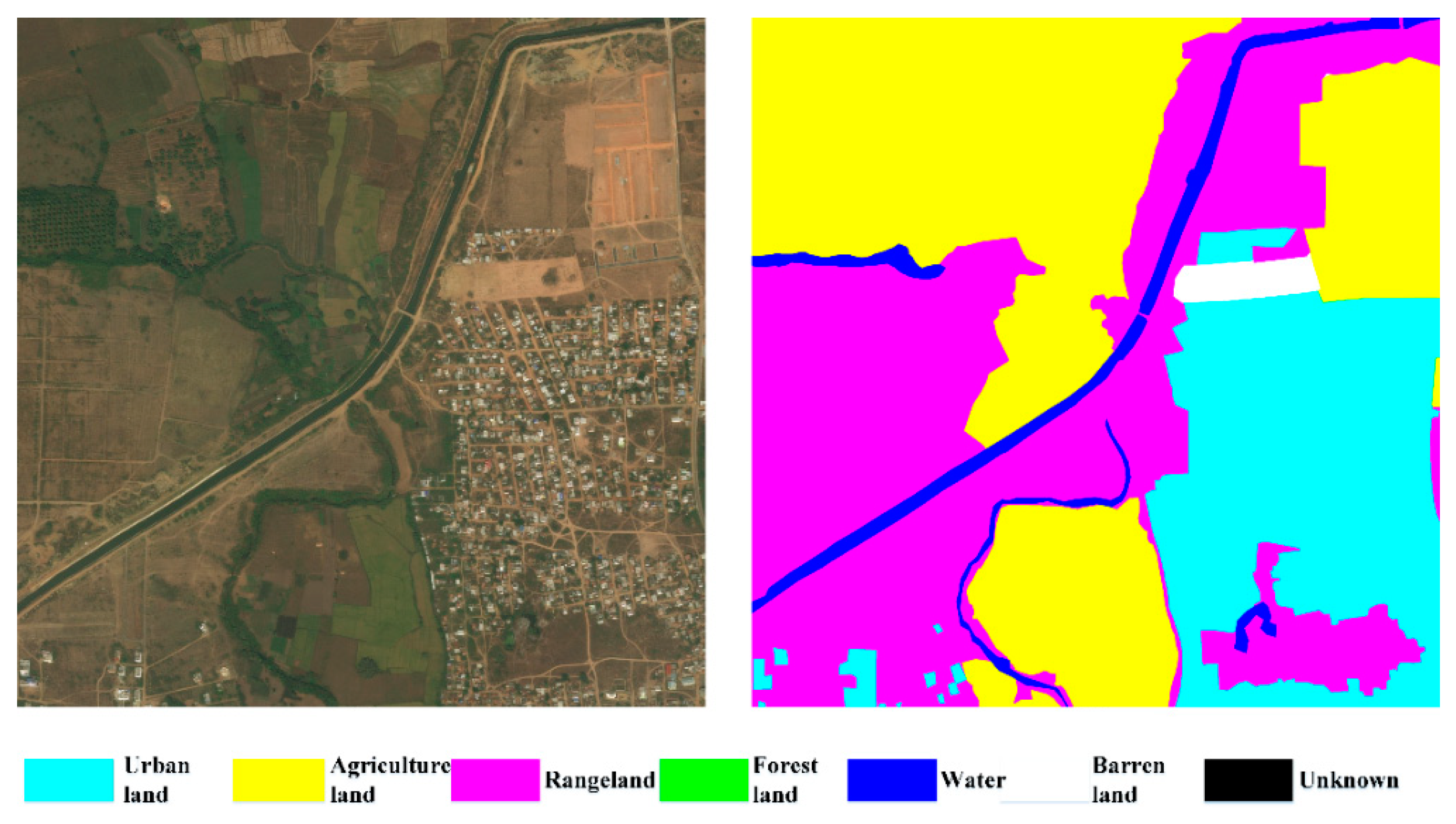
The DeepGlobe Land Cover Classification Dataset is acquired from a satellite with a spatial resolution of 0.5 m, formed of R, G, and B bands. The associated ground truth labels seven categories. They are urban land, agriculture land, rangeland, forest land, water, barren land, and unknown. A wider range and more complex scenarios are exhibited than aerial imagery. A total of 1146 scenes with a spatial size of 2448 × 2448 can be used. A total of 803 images are trained, 171 images are validated, and 172 images are for test. An example of this dataset is illustrated in
Figure 7.
4.1.2. Implement Details
The experiments are implemented using PyTorch with NVIDIA Tesla V100-32GB under Linux OS. The hyperparameters are listed in
Table 1. The CBs are referred to ResNet 101 under U-Net architecture. STBs come from Swin-S, which is a variant of Swin Transformer.
Moreover, several methods are compared. FCN-8s [
22], SegNet [
23], U-Net [
24], DeepLab V3+ [
60], CBAM [
46], DANet [
48], ResUNet-a [
61], SCAttNet [
51], and HCANet [
32] are re-produced under the same environments and parameter settings. Specifically, DeepLab V3+ and ResUNet-a have multiple versions. In this study, we adopt rate = 2 and rate = 4 to the last two blocks, respectively, for output stride = 8 of DeepLab V3+. As for ResUNet-a, the version of d6 cmtsk is re-produced (see [
61] for more details).
4.1.3. Numerical Metrics
Two commonly used numerical metrics, OA (Overall Accuracy) and F1-score, are used. Formally:
where
TP denotes the number of true positives,
FP denotes the number of false positives,
FN denotes the number of false negatives,
TN denotes the number of true negatives,
is the number of class number. In addition, Mean F1-score is an average of class-wise F1-score.
4.2. Compare to State-of-the-Art Methods
As outlined before, our intention was to enrich the contextual information with local patterns and long-range dependencies. Since ICTNet is a segmentation network that inherits the advantages of the Swin Transformer and conventional convolution encoder, the numerical evaluation of segmentation accuracy is investigated experimentally.
4.2.1. Results on Vaihingen Benchmark
As reported in
Table 2, the numerical results are collected and compared. It is apparent that both the mean F1-score and OA of ICTNet reveal a significant improvement with the comparative methods. The mean F1-score reaches more than 92%, performing surprising correctness and completeness in segmentation. Moreover, the OA peaks at more than 90%, leading to a more than 1% increase compared to HCANet and ResUNet-a. Compared to FCN-8s and SegNet, the OA sharply rises by a margin of more than 20%. With the incorporation of the attention mechanism, CBAM and DANet further enhance the representations with long-range dependencies, yielding a remarkable amelioration that about an 8% increase in OA is obtained compared to U-Net. ResUNet-a hybridizes multiple strategies and multi-task inference, considerably amplifying the encoder–decoder network. The complex procedure and massive parameters realize a state-of-the-art performance with a 91.54% mean F1-score and 88.90% OA. Apart from general metrics, the class-wise F1-score is also presented. Distinctly, almost all the class-wise F1-scores of ICTNet are the highest, except for low vegetation. We suppose that the uncertainty of the initialization of neural networks makes this happen. HCANet provides a hybrid context fusion pipeline, adjusting to the visual patterns of trees. Specifically, only 0.31% is degraded. This is acceptable for overall evaluation. In summary, the numerical results indicate the robust learning capability of discriminative representation and certainly predict the dense labels.
Visualization of random samples from the test set is plotted in
Figure 8. All distributed objects have their latent patterns, in which locality and distant affinity are involved. The better the extraction and utilization of local features and long-range context, the higher the accuracy. Unquestionably, ICTNet segments most pixels with high consistency with ground truth. The main parts and edges of objects are well-distinguished visually. Whether with discrete-distributed small objects or consistent areas, ICTNet exhibits satisfactory scalability and adaptability.
The results of the ISPRS Vaihingen benchmark indicate that ICTNet enables well-rounded context together with the convolved local patterns. Furthermore, qualitative and quantitative evaluations vigorously support the superiority of ICTNet.
4.2.2. Results on Potsdam Benchmark
The ISPRS Potsdam benchmark has a finer spatial resolution and observes the Potsdam city of Germany. This benchmark provides more images that could train a model with better performance. Surprisingly, the mean F1-score of 93.00% and OA of 91.57% are showcased by ICTNet according to
Table 3. Although ResUNet-a scores 91.47% for OA, there is an increase of 0.1% by ICTNet. Specifically, only the F1-score of impervious surfaces is 0.1% behind ResUNet-a. As to other RSI-specific methods, ICTNet precedes remarkably. Compared to conventional encoder–decoder variants, including FCN-8s, SegNet, U-Net, and DeepLab V3+, a large margin of OA can be observed. Especially for cars, ICTNet recognizes the objects with an F1-score of 96.70%, which is more than twice that of FCN-8s. The complete results reveal that aggregating local patterns and long-range dependencies efficiently benefits the learned representations. Whether the ground objects are sparse or dense, ICTNet lends a solid foundation for feature refinement and pixel-wise predictions. To sum up, the quantitative evaluations on the ISPRS Potsdam benchmark validate the outstanding performance of ICTNet.
Figure 9 plots the predicted results of two random samples from the test set. Similar trends are observed with the ISPRS Vaihingen benchmark. Although different coverages and spatial resolution make the two benchmarks heterogonous, the visual features are potentially related. Specifically, ICTNet has good transferability and is robust to various data properties. Consequently, the test results are in good agreement with ground truth labels. Moreover, a majority of areas predicted by ICTNet are almost identical to referred labels.
The results indicate that ICTNet is well-suited for aerial imagery with desired performance. Furthermore, numerical and visual comparisons validate that comprehensive context can boost segmentation accuracy.
4.2.3. Results on DeepGlobe Benchmark
Apart from ISPRS benchmarks, the DeepGlobe benchmark is acquired from a satellite. Visually, the covered range and spatial resolution are different. Therefore, a more heightened capability of the segmentation network is required.
Table 4 provides the results of the test set of the DeepGlobe benchmark. There was a lower accuracy than ISPRS benchmarks, deriving from the heterogeneous data property. Even so, ICTNet owns the minimum-amplitude degradation. A total of 86.95% of pixels are well-distinguished correctly by ICTNet, while others are below 82%. FCN-8s only correctly classified about 63% of pixels. With the introduction of atrous convolution and pyramid spatial pooling, DeepLab V3+ rises about 4% of OA. However, long-range contextual information plays a pivotal role in satellite imagery. Therefore, the perceptible field of DeepLab V3+ is scarce. Interestingly, the attention mechanisms alleviate this drawback by few computations, capturing long-range dependencies effectively. As can be seen, CBAM and DANet strikingly level up the OA to more than 77%. Compared to SCAttNet and HCANet, which are the RSI-specific attention-based segmentation networks, our ICTNet enacts a great success. Over 5% improvement of OA is displayed with the two counterparts. In a nutshell, ICTNet expresses competitive capability.
The difficulty of segmenting satellite imagery lies in the easy-prone pixels. These pixels are always found around contours with low certainty. Moreover, the uncorrected classified pixels may lead to more correlated pixels being misclassified. The diversity of ground objects is much more than a scene of an aerial platform. Hence, the predicted results are slightly coarse. However, a striking prediction by ICTNet is illustrated in
Figure 10. Compared to conventional and state-of-the-art methods, the segmentation quality is excellent. Easily confused edges are well segmented, and the inner consistency of extensive areas is meritorious.
In addition to aerial imagery, the results of the DeepGlobe benchmark further evaluate the predominance of ICTNet. The encoded features by STBs and CBs contribute to aggregating available clues. Both numerical results and visualizations corroborate the efficacy and efficiency of ICTNet when segmenting satellite imagery.
4.3. Ablation Study of DFA
In this section, the ablation study of DFA is implemented. For simplicity, we denote ICTNet-S as the version that replaces DFAs with decoder blocks of SegNet. Therefore, the decoder can be considered a universal expansion path by gradually recovering spatial size. Ultimately, we trained these two models on three benchmarks for comparison.
As shown in
Table 5, replacing DFAs with the decoder block that consists of convolutional layers implies a degree of attenuation in accuracy. For ISPRS benchmarks, about 2% of mean F1-score and 2.5% of OA are witnessed. With the coarser spatial resolution, the performance degradation of DeepGlobe drops from 86.95% to 80.01%, and about a 6% decrease in OA is examined. For more details of the training procedure, see
Appendix A.
In a word, the DFAs are used to reduce the transformation loss during spatial recovery. Moreover, injecting encoded features is beneficial for preserving some essential details. As a result, the numerical results lend fundamental support to this conclusion.
4.4. Ablation Study of DUP
The DUPs are incorporated in the decoder for losslessly recovering the spatial size of feature maps. Instead of pooling variants, DUP provides a matrix projection fashion to meet this target. Moreover, one-time matrix projection is affordable in the network. To analyze the effects of DUPs, we re-built two versions for the ablation study. ICTNet-B adopts the bilinear upsampling as the substitution of DUP. ICTNet-M embeds max unpooling for upsampling. As previously discussed, the DUPs induce less loss in expansion. We compare the performance on three benchmarks for comparisons.
As reported in
Table 6, the mean F1-score and OA are collected on three benchmarks. Notably, ICTNet provides the most competitive performance compared with the other two designs. ICTNet-B exhibits the disadvantages in the spatial expansion of feature maps. A gap of about 7% of OA on the ISPRS Vaihingen dataset is presented by ICTNet-B compared to ICTNet. Although max-pooling indices from the encoder stage help the decoder recover features with necessary guidance, the recovered results still suffer from inevitable missing information. ICTNet-M narrows the gap from 7% to about 3%. Likewise, the results from the other two benchmarks express that ICTNet is superior to ICTNet-B and ICTNet-M.
4.5. Ablation Study of STB and CB
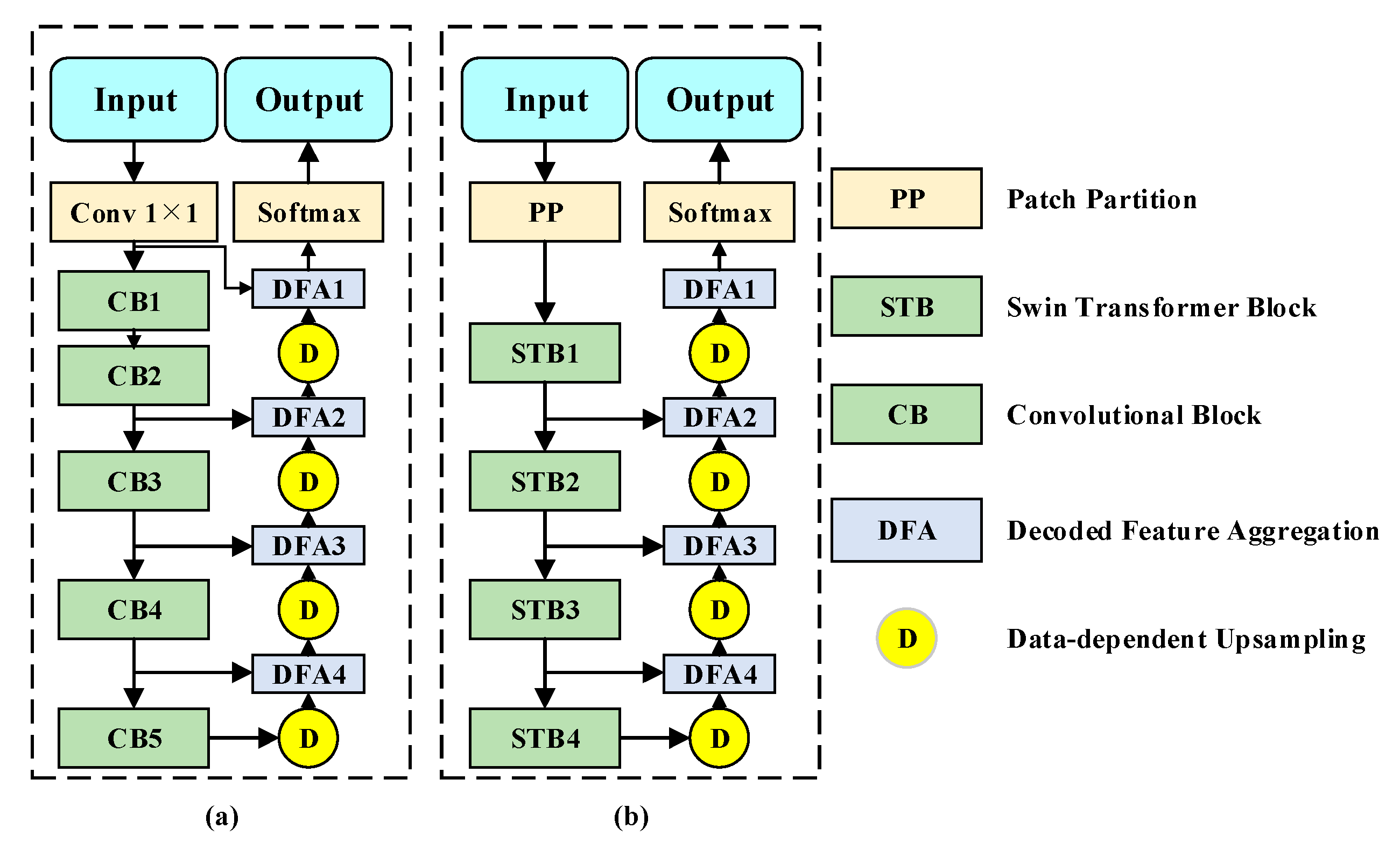
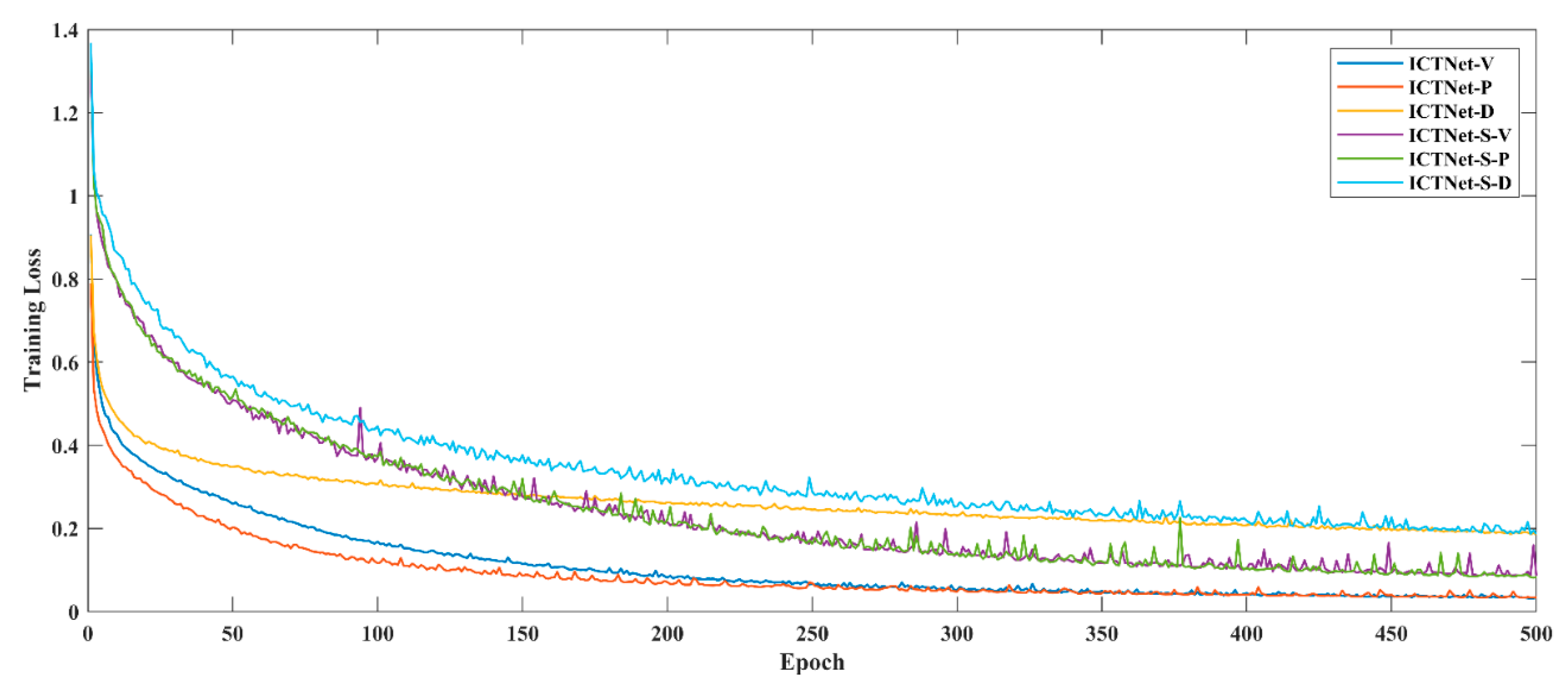
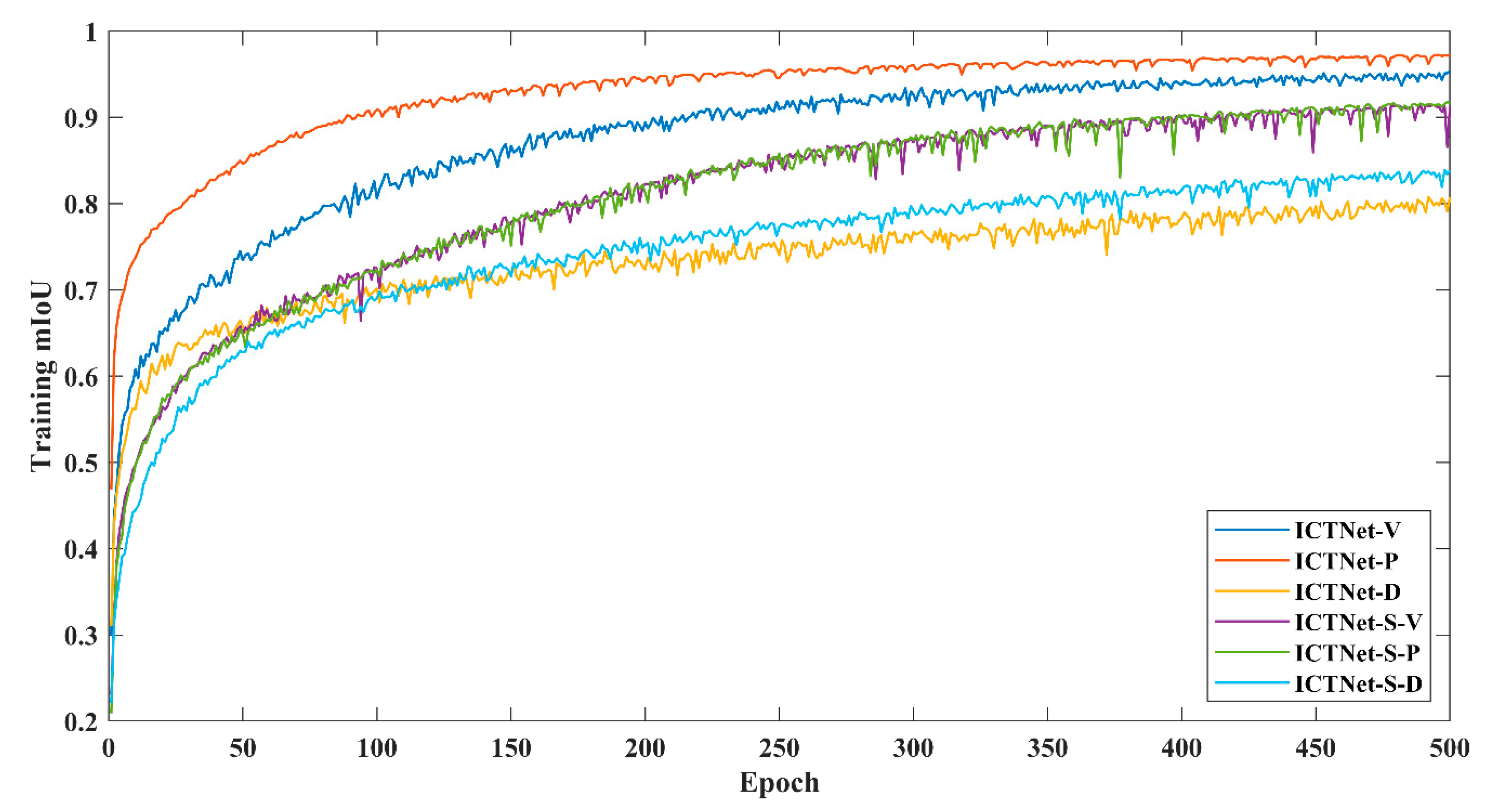
We adjust two versions of ICTNet to examine the effects of STB and CB. As shown in
Figure 11, (a) removes STBs from the encoder while (b) removes CBs. Under the same parameter settings, we trained the two versions on three benchmarks to 500 epochs and collected the mean F1-score and overall accuracy of corresponding test sets. Notably, the experiments were deployed simultaneously on three servers equipped with Tesla V100-32GB with respect to three benchmarks.
As presented in
Table 7, ICTNet demonstrates the most competitive performance, with STB-only second and CB-only the worst. As we all know, pixels cannot be reliably judged using only the information within the local receptive field, and STB-only inherits the non-local information aggregation capability of the self-attention mechanism, which provides more helpful clues for prediction, resulting in a significant improvement in accuracy compared to CB-only.
However, we find that the STB-only stretches the local region into a vector, losing a large amount of structural and textural information while incorporating the non-local information. Attempting to preserve such local information, convolution paves an effective way in nature. Therefore, an encoder incorporating CBs and STBs can extract and aggregate such information. Considering the scale variation, feature aggregations are performed at each stage of the encoder to ensure the interaction of non-local and local information at each scale.
In summary, the ablation study validates the efficacy and efficiency of interlacing STBs and CBs, making the encoded feature with sufficient contextual information.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










