
Local-Global Based High-Resolution Spatial-Spectral Representation Network for Pansharpening


Abstract
:
1. Introduction
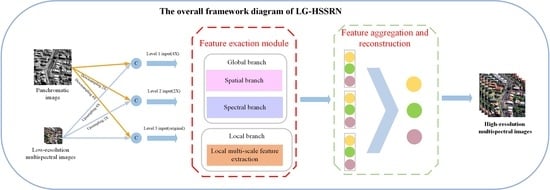
- The LG-HSSRN that can effectively obtain local and global dependencies is proposed. At the same time, the information at different scales is mapped to the output scale layer, which maintains a high-resolution representation and can obtain better contextual information.
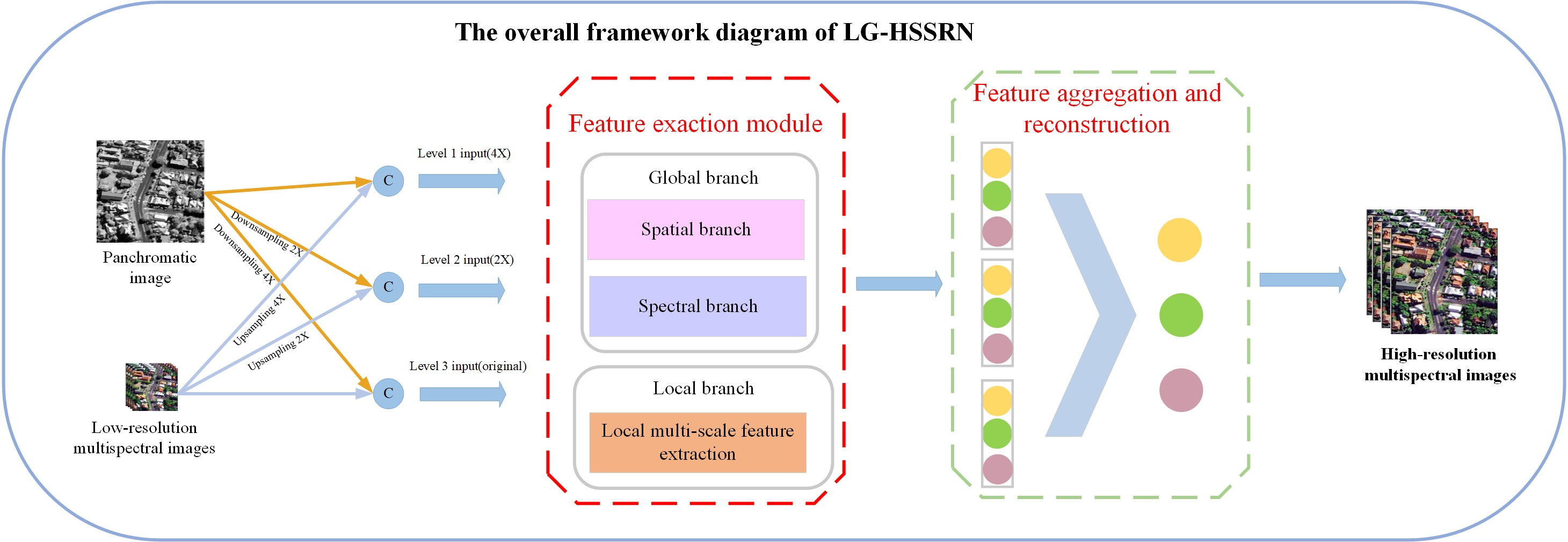
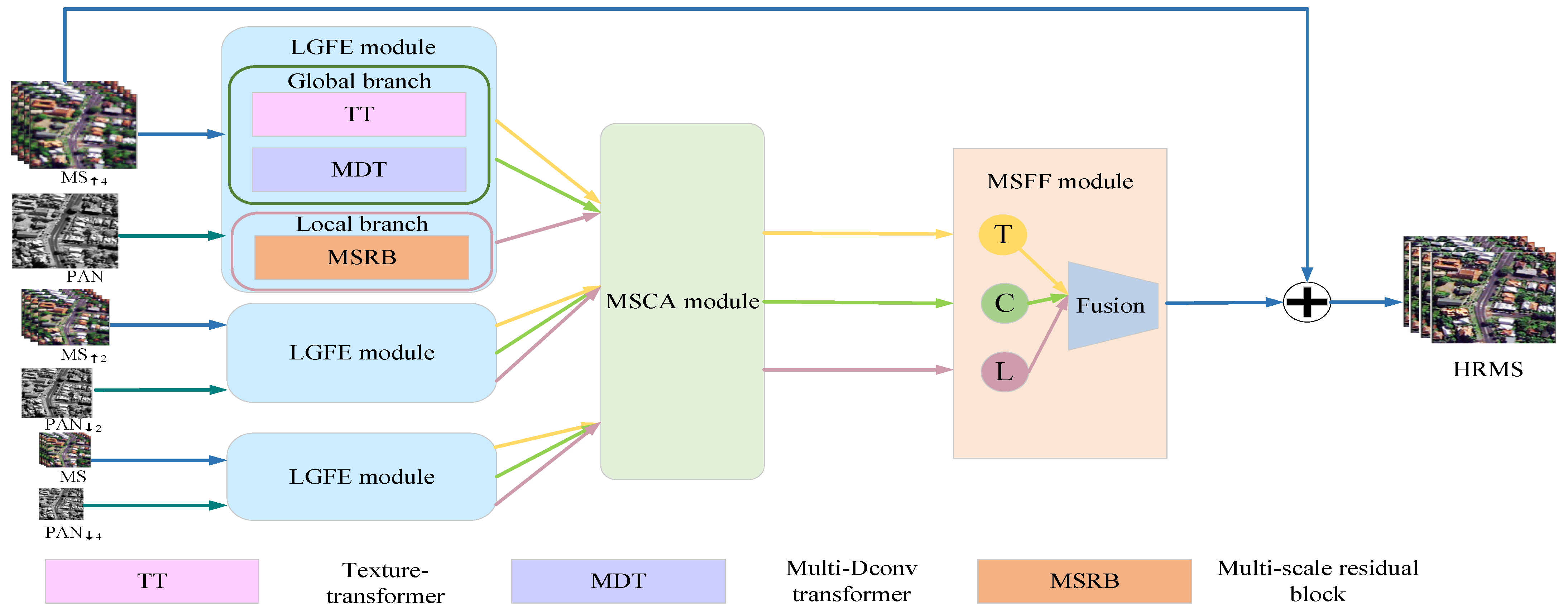
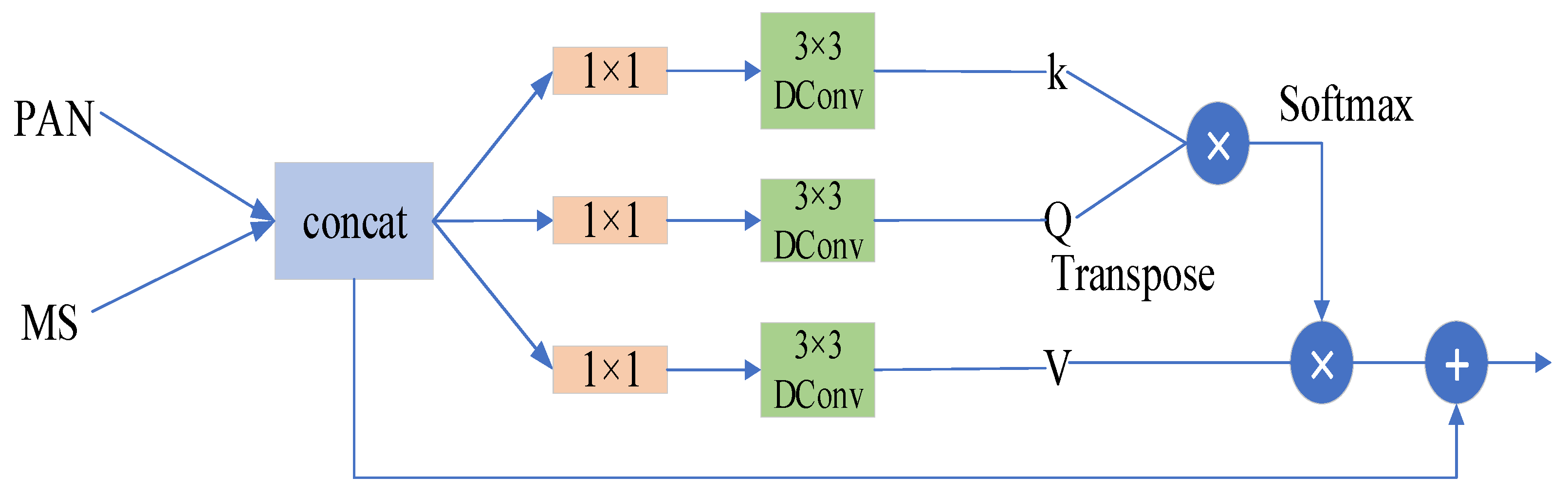
- Considering the complementary characteristics of the information contained in PAN and MS images, the LGFE module is designed, which can effectively obtain local and non-local information from images. Among others, we designed a texture-transformer to extract long-range texture details and cross-feature spatial dependencies from a spatial perspective. A Multi-Dconv transformer module is designed to learn contextual image information across channels using a self-attentive mechanism and is able to aggregate local and non-local pixel interactions.
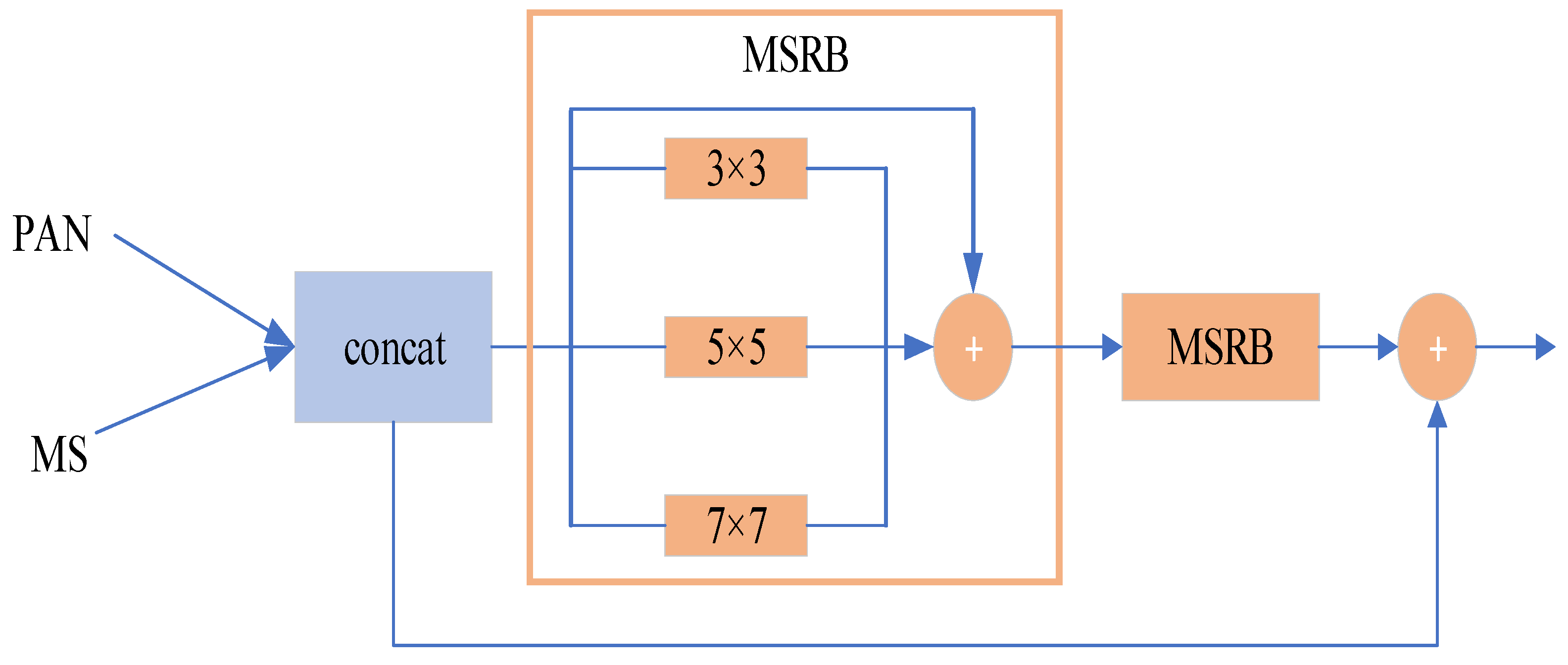
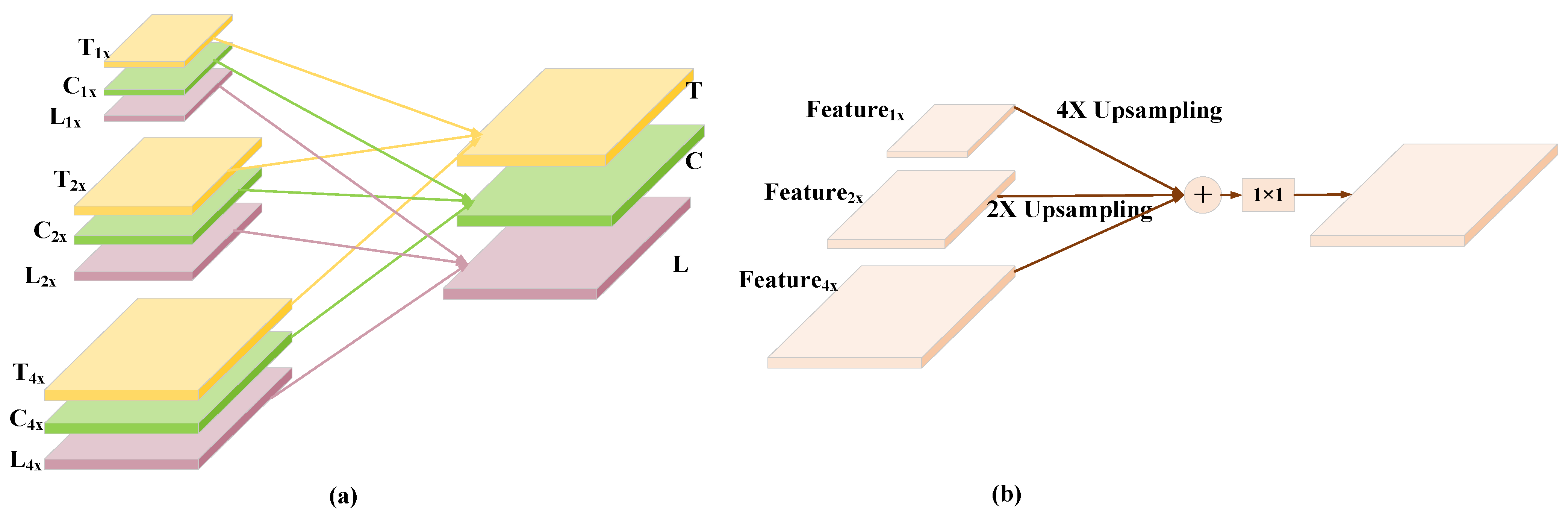
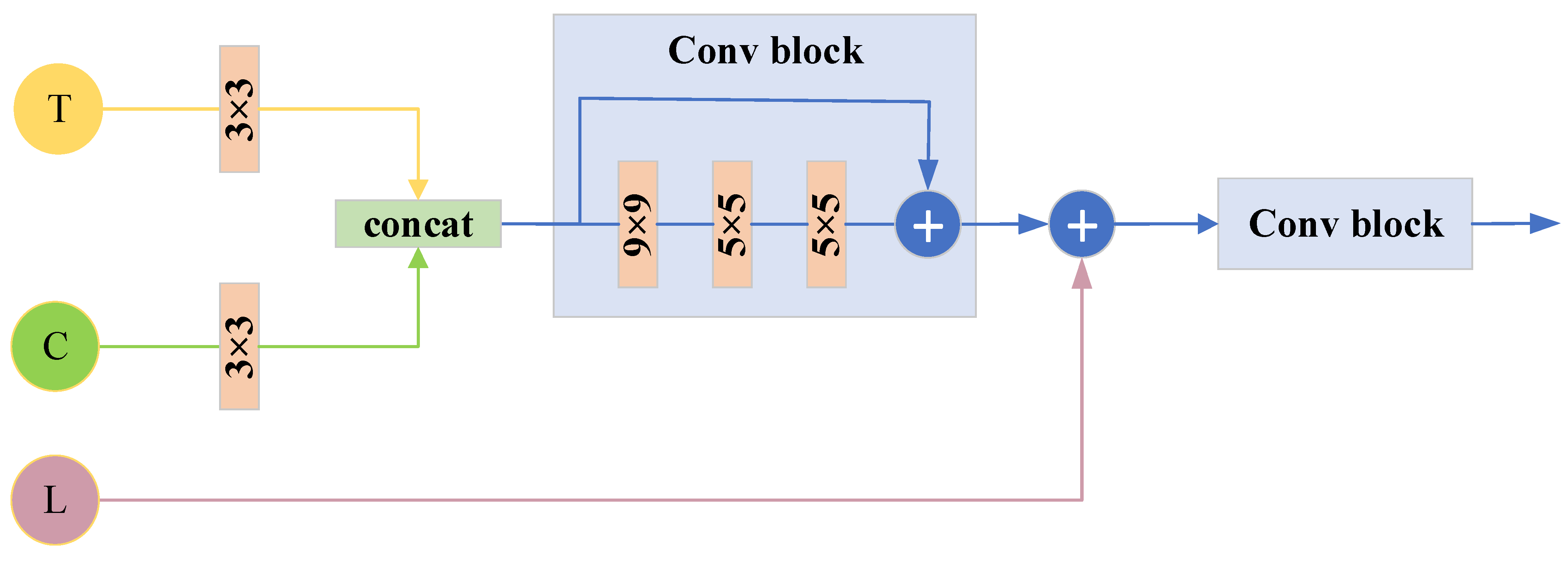
- The MSCA module is proposed to map all low-level features and mid-level feature information to the high level. The final feature fusion is completed with a high-resolution feature representation while fully obtaining the hierarchical information.
2. Proposed Method
2.1. LGFE Module
2.1.1. Global Feature Exaction Module
- (1)
- Texture-transformer Module
- (2)
- Multi-Dconv Transformer Module
2.1.2. Local Feature Exaction Module
2.2. MSCA Module
2.3. MSFF Module
2.4. Loss Function
3. Experiments and Results
3.1. Experimental Data
3.2. Comparison Methods
3.3. Evaluation Metrics
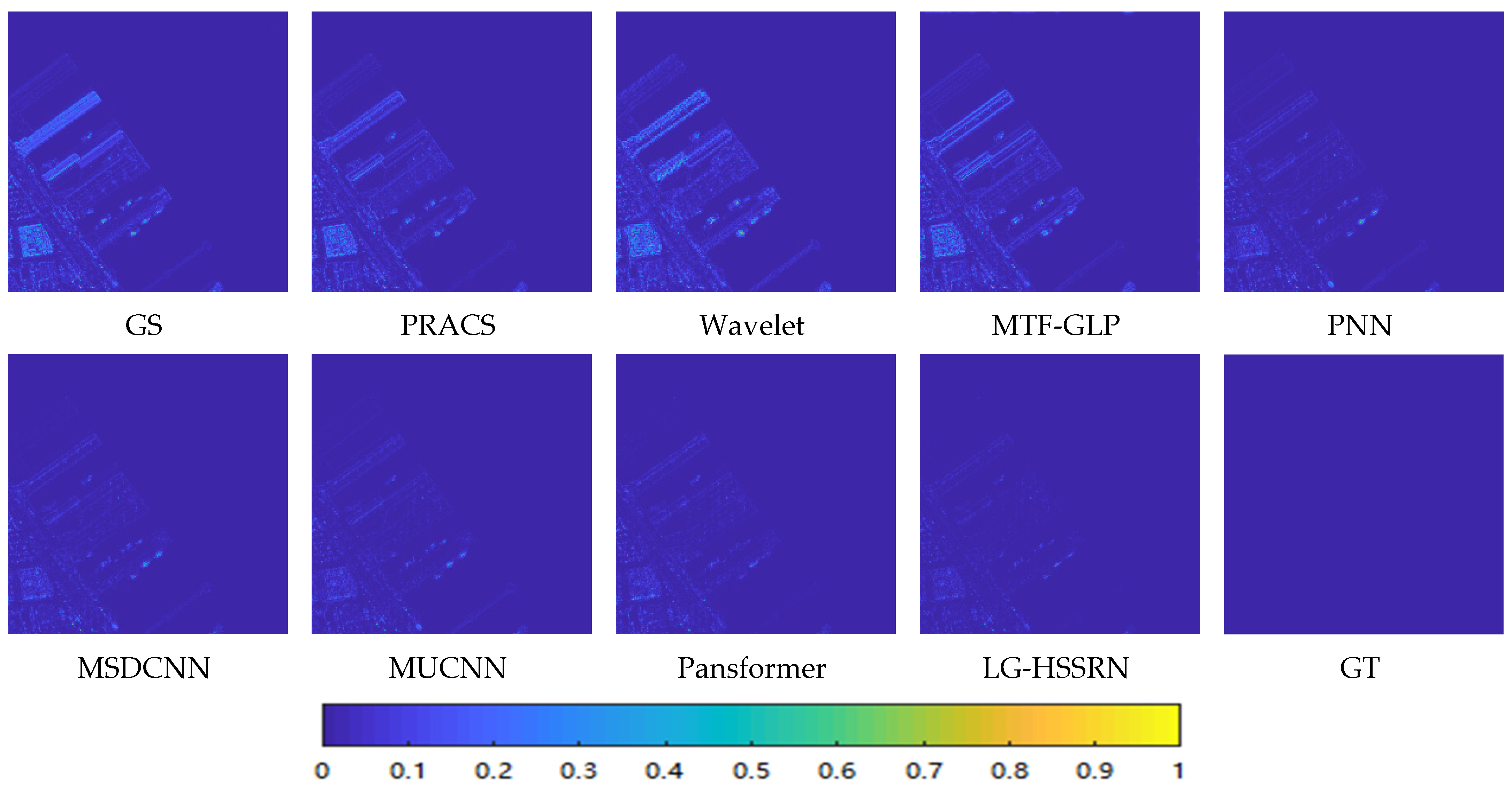
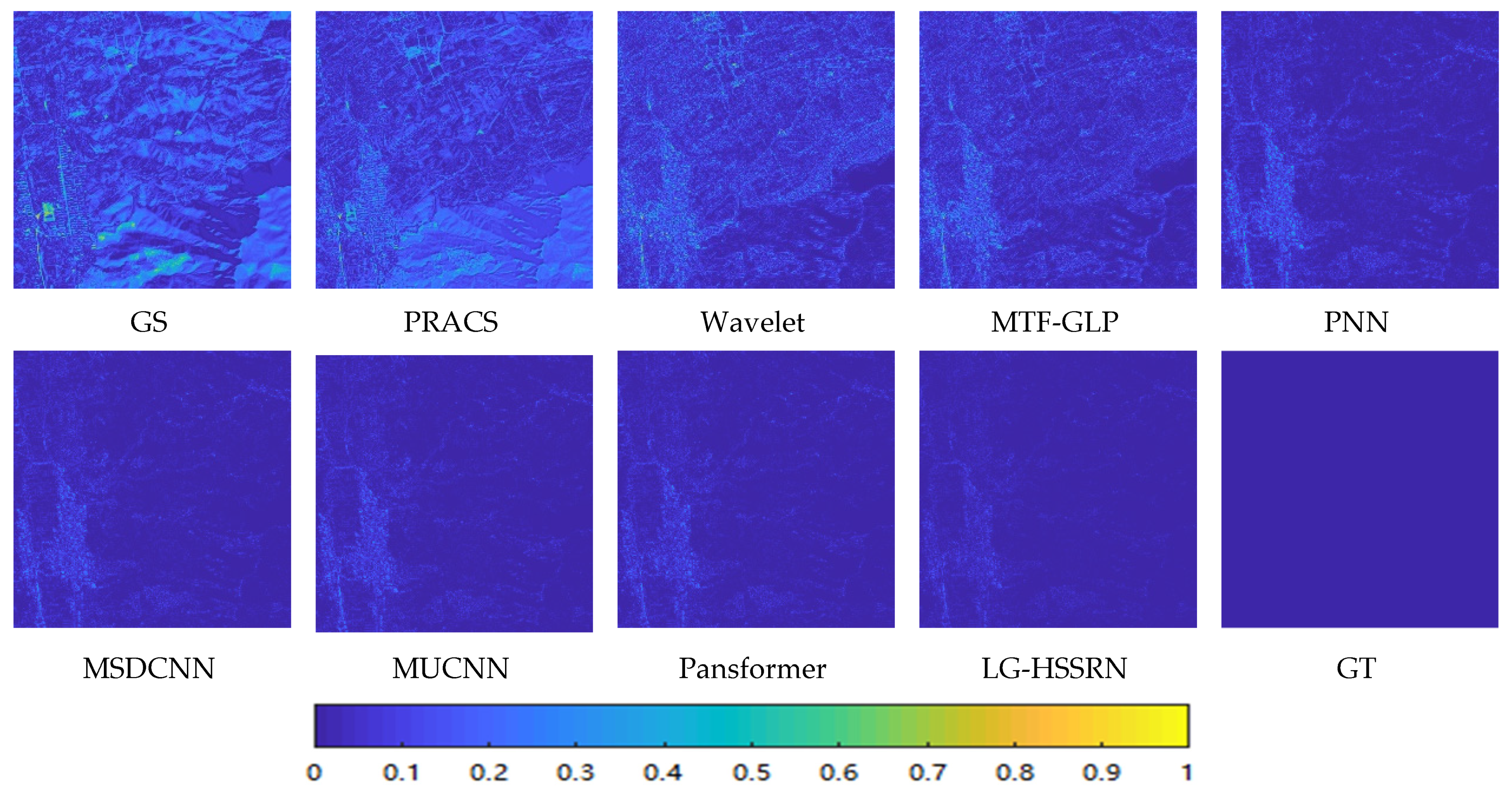
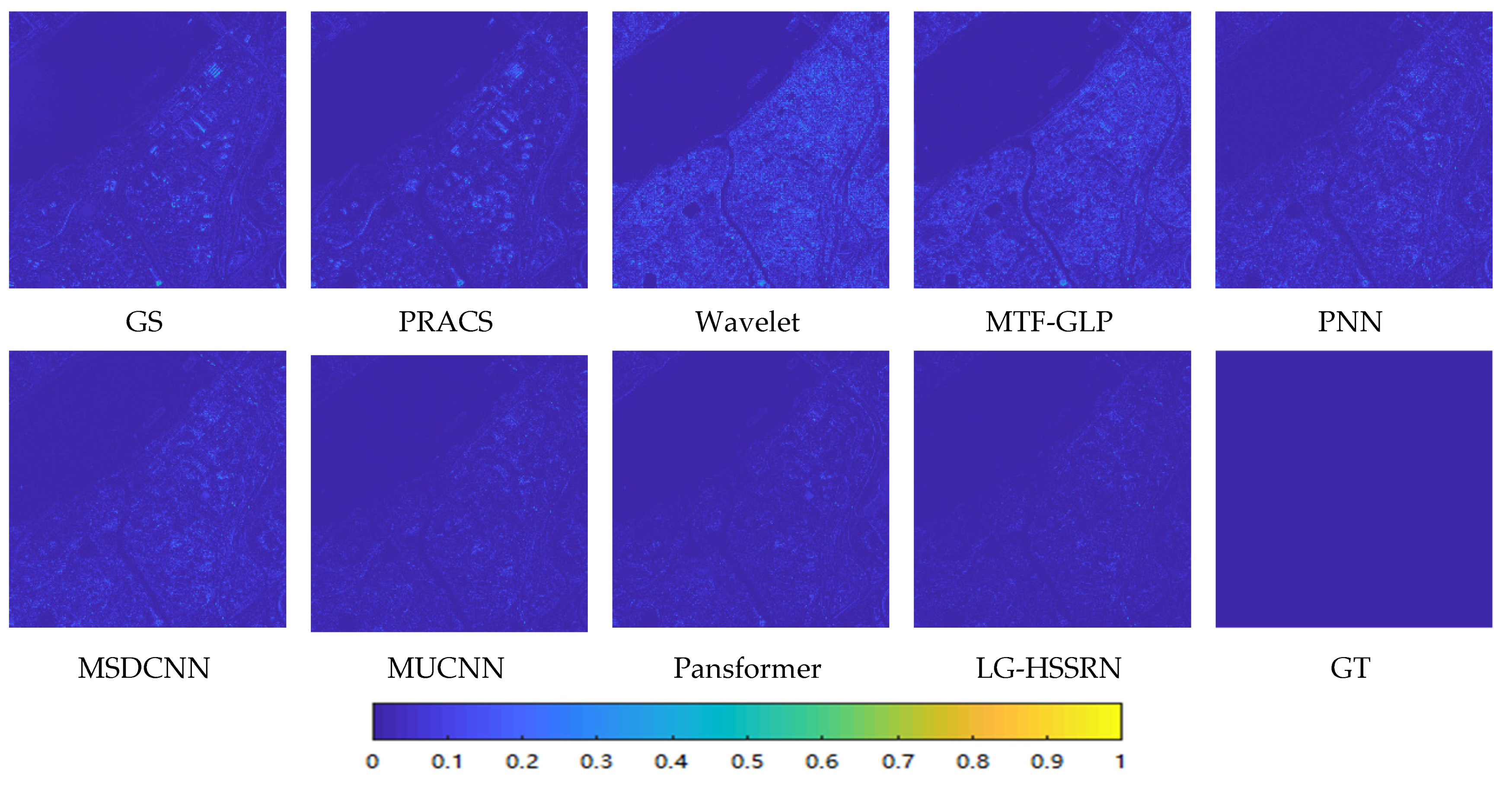
3.4. Simulation Experiment Results and Analysis
3.5. Real Experiment Results and Analysis
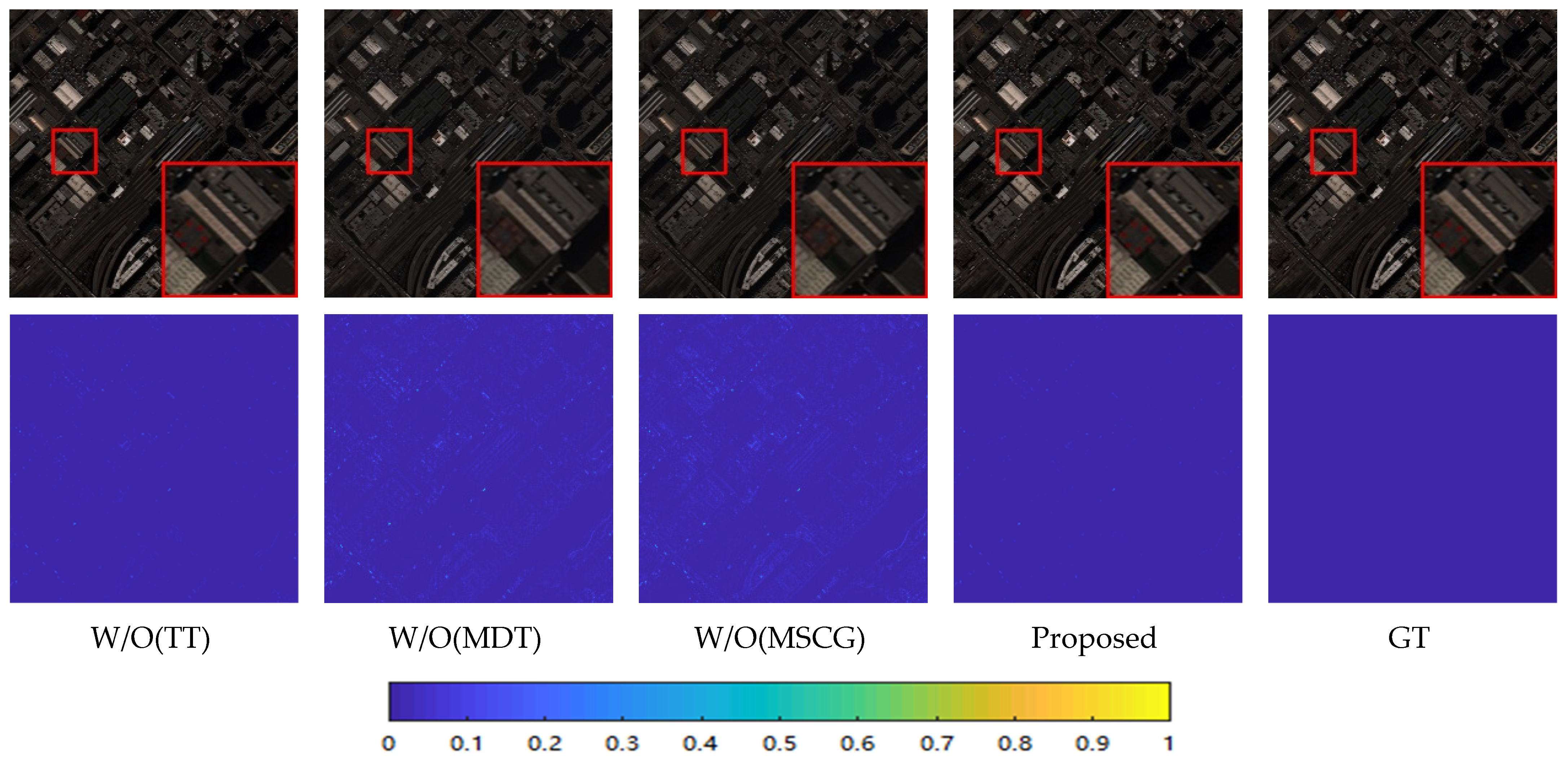
3.6. Performance Verification of Network Modules
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MS | Multispectral |
| PAN | Panchromatic |
| HRMS | High-resolution multispectral |
| LRMS | Low-resolution multispectral |
| CNN | Convolutional neural network |
| LG-HSSRN | Local-global based high-resolution spatial-spectral representation network |
| LGFE | Local-global feature extraction |
| MSCA | Multi-scale context aggregation |
| MSFF | Multi-stream feature fusion |
| TT | Texture-transformer |
| MDT | Multi-Dconv Transformer |
| MSRB | Multi-scale residual block |
| Dconv | Deep convolution |
| ERGAS | The relative global synthesis error |
| SAM | Spectral angle mapper |
| CC | Correlation coefficient |
| UIOI/Q4 | Universal image quality index and its extended index |
| QNR | Reference-free quality index |
References
- Vivone, G.; Dalla Mura, M.; Garzelli, A.; Restaino, R.; Scarpa, G.; Ulfarsson, M.O.; Chanussot, J. A new benchmark based on recent advances in multispectral pansharpening: Revisiting pansharpening with classical and emerging pansharpening methods. IEEE Geosci. Remote Sens. Mag. 2021, 9, 53–81. [Google Scholar] [CrossRef]
- Chang, C. An Effective Evaluation Tool for Hyperspectral Target Detection: 3D Receiver Operating Characteristic Curve Analysis. IEEE Trans. Geosci. Electron. 2021, 59, 5131–5153. [Google Scholar] [CrossRef]
- Gilbertson, J.K.; Kemp, J.A.; Van Niekerk, A. Effect of pansharpening multi-temporal Landsat 8 imagery for crop type differentiation using different classification techniques. Comput. Electron. Agric. 2017, 134, 151–159. [Google Scholar] [CrossRef] [Green Version]
- Duran, J.; Buades, A. Restoration of pansharpened images by conditional filtering in the PCA domain. IEEE Geosci. Remote Sens. Lett. 2018, 16, 442–446. [Google Scholar] [CrossRef] [Green Version]
- Choi, J.; Yu, K.; Kim, Y. A new adaptive component-substitution-based satellite image fusion by using partial replacement. IEEE Trans. Geosci. Remote Sens. 2010, 49, 295–309. [Google Scholar] [CrossRef]
- Garzelli, A.; Nencini, F.; Capobianco, L. Optimal MMSE pan sharpening of very high resolution multispectral images. IEEE Trans. Geosci. Remote Sens. 2008, 46, 228–236. [Google Scholar] [CrossRef]
- Carper, W.J.; Lillesand, T.M.; Kiefer, R.W. The use of intensity-hue-saturation transformations for merging SPOT panchromatic and multispectral image data. Photogramm. Eng. Remote Sens. 1990, 56, 459–467. [Google Scholar]
- Laben, C.A.; Brower, B.V. Process for Enhancing the Spatial Resolution of Multispectral Imagery Using Pan-Sharpening. U.S. Patent 6011875, 1 April 2000. [Google Scholar]
- Otazu, X.; González-Audícana, M.; Fors, O.; Núñez, J. Introduction of sensor spectral response into image fusion methods. Application to wavelet-based methods. IEEE Trans. Geosci. Remote Sens. 2005, 43, 2376–2385. [Google Scholar] [CrossRef] [Green Version]
- Vivone, G.; Alparone, L.; Chanussot, J.; Mura, M.D.; Garzelli, A.; Licciardi, G.A.; Restaino, R.; Wald, L. A Critical Comparison Among Pansharpening Algorithms. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2565–2586. [Google Scholar] [CrossRef]
- Vivone, G.; Marano, S.; Chanussot, J. Pansharpening: Context-Based Generalized Laplacian Pyramids by Robust Regression. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6152–6167. [Google Scholar] [CrossRef]
- Alparone, L.; Baronti, S.; Aiazzi, B.; Garzelli, A. Spatial methods for multispectral pansharpening: Multiresolution analysis demystified. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2563–2576. [Google Scholar] [CrossRef]
- Cunha, D.; Arthur, L.; Zhou, J.; Minh, N. The Nonsubsampled Contourlet Transform: Theory, Design, and Applications. IEEE Trans. Image Process. 2006, 15, 3089–3101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shensa, M.J. Discrete wavelet transform: Wedding the àtrous and mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Liang, S. Pan-sharpening using a guided filter. ISPRS J. Photogramm. Remote Sens. 2016, 37, 1777–1800. [Google Scholar] [CrossRef]
- Wang, T.; Fang, F.; Li, F.; Zhang, G. High-Quality Bayesian Pansharpening. IEEE Trans. Image Process. 2019, 28, 227–239. [Google Scholar] [CrossRef]
- Zhu, X.X.; Bamler, R. A sparse image fusion algorithm with application to pan-sharpening. IEEE Trans. Geosci. Electron. 2012, 51, 2827–2836. [Google Scholar] [CrossRef]
- Ballester, C.; Caselles, V.; Igual, L.; Verdera, J.; Rougé, B. A variational model for P+ XS image fusion. Int. J. Comput. Vis. 2006, 69, 43–58. [Google Scholar] [CrossRef]
- Fu, X.; Lin, Z.; Huang, Y.; Ding, X. A variational pan-sharpening with local gradient constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10265–10274. [Google Scholar]
- Huang, W.; Xiao, L.; Liu, H.; Wei, Z.; Tang, S. A New Pan-Sharpening Method With Deep Neural Networks. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1037–1041. [Google Scholar] [CrossRef]
- Giuseppe, M.; Davide, C.; Luisa, V.; Giuseppe, S. Pansharpening by Convolutional Neural Networks. Remote Sens. 2016, 8, 594. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Wei, Y.; Yuan, Q.; Shen, H.; Zhang, L. Boosting the Accuracy of Multispectral Image Pansharpening by Learning a Deep Residual Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1795–1799. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Fu, X.; Hu, Y.; Huang, Y.; Ding, X.; Paisley, J. PanNet: A Deep Network Architecture for Pan-Sharpening. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1753–1761. [Google Scholar]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A Multi-Scale and Multi-Depth Convolutional Neural Network for Remote Sensing Imagery Pan-Sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 978–989. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Yu, W.; Chen, C.; Liang, P.; Guo, X.; Jiang, J. Pan-GAN: An unsupervised pan-sharpening method for remote sensing image fusion. Inf. Fusion 2020, 62, 110–120. [Google Scholar] [CrossRef]
- Liu, L.; Wang, J.; Zhang, E.; Li, B.; Zhu, X.; Zhang, Y.; Peng, J. Shallow–deep convolutional network and spectral-discrimination-based detail injection for multispectral imagery pan-sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1772–1783. [Google Scholar] [CrossRef]
- Wei, J.; Xu, Y.; Cai, W.; Wu, Z.; Chanussot, J.; Wei, Z. A Two-Stream Multiscale Deep Learning Architecture for Pan-Sharpening. IEEE J. Sel. T op. Appl. Earth Obs. Remote Sens. 2020, 13, 5455–5465. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, L.J.; Zhang, T.J. SSconv: Explicit Spectral-to-Spatial Convolution for Pansharpening. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 4472–4480. [Google Scholar]
- Deng, L.J.; Vivone, G.; Jin, C. Detail Injection-Based Deep Convolutional Neural Networks for Pansharpening. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6995–7010. [Google Scholar] [CrossRef]
- Zhou, M.; Fu, X.; Huang, J.; Zhao, F.; Liu, A.; Wang, R. Effective Pan-Sharpening With Transformer and Invertible Neural Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Nithin, G.R.; Kumar, N.; Kakani, R.; Venkateswaran, N.; Garg, A.; Gupta, U.K. Pansformers: Transformer-Based Self-Attention Network for Pansharpening. TechRxiv, 2021; preprint. [Google Scholar] [CrossRef]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5790–5799. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient Transformer for High-Resolution Image Restoration. arXiv 2021, arXiv:2111.09881. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Xiao, B. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [Green Version]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolutions: Assessing the quality of resulting images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A. Context-driven fusion of high spatial and spectral resolution images based on oversampled multiresolution analysis. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2300–2312. [Google Scholar] [CrossRef]
- Wald, L. Data Fusion: Definitions and Architectures—Fusion of Images of Different Spatial Resolutions; Les Presses de l’École des Mines: Paris, France, 2002. [Google Scholar]
- Yuhas, R.H.; Goetz, A.; Boardman, J. Discrimination among semi-arid landscape endmembers using the Spectral Angle Mapper (SAM) algorithm. In Proceedings of the Summaries 3rd Annual JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 1 June 1992; pp. 147–149. [Google Scholar]
- Wang, Z.; Bovik, A.C. A universal image quality index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Alparone, L.; Baronti, S.; Garzelli, A.; Nencini, F. A global quality measurement of pan-sharpened multispectral imagery. IEEE Geosci. Remote Sens. Lett. 2004, 1, 313–317. [Google Scholar] [CrossRef]
- Alparone, L.; Aiazzi, B.; Baronti, S.; Garzelli, A. Multispectral and panchromatic data fusion assessment without reference. Photogramm. Eng. Remote Sens. 2008, 74, 193–200. [Google Scholar] [CrossRef] [Green Version]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Band | Resolution (m) |
|---|---|---|
| GaoFen-2 | MS | 4 |
| PAN | 1 | |
| WorldView-2 | MS | 1.6 |
| PAN | 0.4 | |
| QuickBird | MS | 2.4 |
| PAN | 0.6 |
| Dataset | Kind | Satellite | Size | Number |
|---|---|---|---|---|
| Training dataset | Simulated experiment | GaoFen-2 | 16 × 16, MS | Training, 6812 |
| 64 × 64, PAN | Validation, 1703 | |||
| WorldView-2 | 16 × 16 | Training, 1819 | ||
| 64 × 64 | Validation, 452 | |||
| QuickBird | 16 × 16 | Training, 2779 | ||
| 64 × 64 | Validation, 694 | |||
| Testing dataset | Simulated experiment | GaoFen-2 | 128 × 128, MS 512 × 512, PAN | 52 |
| WorldView-2 | 128 × 128 512 × 512 | 33 | ||
| QuickBird | 128 × 128 512 × 512 | 33 | ||
| Real experiment | GaoFen-2 | 256 × 256 1024 × 1024 | 100 | |
| WorldView-2 | 256 × 256 1024 × 1024 | 100 | ||
| QuickBird | 256 × 256 1024 × 1024 | 100 |
| Iterations | Batch Size | Optimizer | Learning Rate | Decay Rate |
|---|---|---|---|---|
| 1200 | 16 | Adam | 0.001 | (0.9, 0.999) |
| Method | SAM | ERGAS | CC | UIQI | Q4 |
|---|---|---|---|---|---|
| Reference | 0 | 0 | 1 | 1 | 1 |
| GS | 4.7293 | 6.4284 | 0.8385 | 0.7770 | 0.7626 |
| PRACS | 5.965 | 3.7119 | 0.9031 | 0.8216 | 0.8042 |
| MTF-GLP | 3.2137 | 6.7711 | 0.8887 | 0.8649 | 0.8351 |
| Wavelet | 2.6919 | 6.8493 | 0.8749 | 0.8057 | 0.7843 |
| PNN | 3.9862 | 5.6703 | 0.9661 | 0.8913 | 0.8805 |
| MSDCNN | 3.9734 | 5.6449 | 0.9776 | 0.9257 | 0.9159 |
| MUCNN | 3.2673 | 4.2673 | 0.9838 | 0.9482 | 0.9375 |
| Pansformer | 2.7412 | 3.8938 | 0.9826 | 0.9590 | 0.9453 |
| LG-HSSRN | 1.5060 | 2.9222 | 0.9882 | 0.9731 | 0.9645 |
| Method | SAM | ERGAS | CC | UIQI | Q4 |
|---|---|---|---|---|---|
| Reference | 0 | 0 | 1 | 1 | 1 |
| GS | 2.5771 | 3.3413 | 0.8922 | 0.8556 | 0.8384 |
| PRACS | 3.7160 | 3.2467 | 0.9033 | 0.8020 | 0.8018 |
| MTF-GLP | 2.2970 | 3.0897 | 0.8922 | 0.8665 | 0.8448 |
| Wavelet | 2.9142 | 3.8819 | 0.9114 | 0.8793 | 0.8582 |
| PNN | 2.1781 | 2.3802 | 0.9590 | 0.9555 | 0.9307 |
| MSDCNN | 2.1383 | 2.3538 | 0.9614 | 0.9614 | 0.9404 |
| MUCNN | 1.6530 | 2.5389 | 0.9707 | 0.9631 | 0.9432 |
| Pansformer | 1.7299 | 1.9183 | 0.9766 | 0.9739 | 0.9593 |
| LG-HSSRN | 1.2598 | 1.4595 | 0.9817 | 0.9813 | 0.9783 |
| Method | SAM | ERGAS | CC | UIQI | Q4 |
|---|---|---|---|---|---|
| Reference | 0 | 0 | 0 | 1 | 1 |
| GS | 4.3427 | 3.0762 | 0.9058 | 0.7836 | 0.7718 |
| PRACS | 3.1412 | 2.2663 | 0.9336 | 0.8433 | 0.8229 |
| MTF-GLP | 5.5898 | 3.7469 | 0.8607 | 0.7839 | 0.7639 |
| Wavelet | 3.0123 | 2.0967 | 0.9538 | 0.8437 | 0.8238 |
| PNN | 2.1483 | 1.9285 | 0.9754 | 0.9252 | 0.9034 |
| MSDCNN | 1.6763 | 1.1271 | 0.9755 | 0.9373 | 0.9221 |
| MUCNN | 1.0477 | 0.7888 | 0.9819 | 0.9591 | 0.9305 |
| Pansformer | 1.5306 | 1.0487 | 0.9822 | 0.9670 | 0.9414 |
| LG-HSSRN | 1.0759 | 0.7026 | 0.9834 | 0.9679 | 0.9487 |
| WorldView-2 | GaoFen-2 | QuickBird | |||||||
|---|---|---|---|---|---|---|---|---|---|
| QNR | Dλ | DS | QNR | Dλ | DS | QNR | Dλ | DS | |
| Reference | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| GS | 0.7875 | 0.0765 | 0.1471 | 0.8387 | 0.0254 | 0.1393 | 0.7973 | 0.0279 | 0.1797 |
| PRACS | 0.8577 | 0.0497 | 0.0973 | 0.8298 | 0.0596 | 0.1175 | 0.8073 | 0.0592 | 0.1417 |
| Wavelet | 0.8670 | 0.0805 | 0.0569 | 0.8226 | 0.0806 | 0.1051 | 0.7917 | 0.1616 | 0.0556 |
| MTF-GLP | 0.8094 | 0.0176 | 0.1759 | 0.7865 | 0.0234 | 0.1945 | 0.8133 | 0.0647 | 0.1303 |
| PNN | 0.9089 | 0.0215 | 0.0710 | 0.8794 | 0.3540 | 0.0882 | 0.8923 | 0.0366 | 0.0737 |
| MSDCNN | 0.9206 | 0.0326 | 0.0482 | 0.8916 | 0.0627 | 0.0486 | 0.9135 | 0.0381 | 0.0502 |
| MUCNN | 0.9520 | 0.0304 | 0.0179 | 0.9327 | 0.0162 | 0.0518 | 0.9292 | 0.0327 | 0.0392 |
| Pansformer | 0.9545 | 0.0304 | 0.0154 | 0.9455 | 0.0182 | 0.0369 | 0.9351 | 0.0261 | 0.0396 |
| LG-HSSRN | 0.9750 | 0.0110 | 0.0140 | 0.9592 | 0.0153 | 0.0258 | 0.9479 | 0.0145 | 0.0380 |
| TT | MDT | MSCG | SAM | ERGAS | CC | UIQI | Q4 | ||
|---|---|---|---|---|---|---|---|---|---|
| (1) | W/O(TT) | ✓ | ✓ | 1.8094 | 3.3359 | 0.9742 | 0.9624 | 0.9532 | |
| (2) | W/O(MDT) | ✓ | ✓ | 3.5611 | 3.4647 | 0.9860 | 0.9526 | 0.9467 | |
| (3) | W/O(MSCG) | ✓ | ✓ | 2.9203 | 4.1828 | 0.9728 | 0.9517 | 0.9426 | |
| LG-HSSRN | All | ✓ | ✓ | ✓ | 1.5060 | 2.9222 | 0.9882 | 0.9731 | 0.9645 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Ju, M.; Zhao, Z.; Wu, Q.; Tian, E. Local-Global Based High-Resolution Spatial-Spectral Representation Network for Pansharpening. Remote Sens. 2022, 14, 3556. https://doi.org/10.3390/rs14153556
Huang W, Ju M, Zhao Z, Wu Q, Tian E. Local-Global Based High-Resolution Spatial-Spectral Representation Network for Pansharpening. Remote Sensing. 2022; 14(15):3556. https://doi.org/10.3390/rs14153556
Chicago/Turabian StyleHuang, Wei, Ming Ju, Zhuobing Zhao, Qinggang Wu, and Erlin Tian. 2022. "Local-Global Based High-Resolution Spatial-Spectral Representation Network for Pansharpening" Remote Sensing 14, no. 15: 3556. https://doi.org/10.3390/rs14153556