Earth observation technology has evolved considerably, and remote sensing (RS) images represent the core method of technical analysis. RS is highly applicable to a variety of fields such as agricultural production, ecological construction, military reconnaissance, and geological surveys. However, the reflected light from ground objects captured by optical sensors inevitably undergoes absorption and scattering from the atmosphere. Detected RS data may be partially or even completely obscured by clouds, which impedes the implementation of global surveying and mapping missions, thereby weakening the potential of RS to explore the earth. Currently, approaches for reconstructing cloud-contaminated images have been heavily investigated in this research area and can be categorized as conventional or deep learning-based approaches.
1.1. Conventional Cloud Removal Approaches
Depending on whether ground objects are completely obscured by clouds, conventional cloud removal processing can be further classified into two cases: thin and thick cloud removal. Thin clouds do not entirely block the transmission of electromagnetic waves reflected from the earth. This is a prerequisite for reconstructing distorted regions utilizing spatial correlation, frequency differences, and spectral complementarity between cloudy and non-cloudy regions. Interpolation is a representative technique for cloud removal using spatial characteristics, such as Kriging interpolation [
1,
2] and neighborhood pixel interpolation [
3,
4]. Others have used frequency-domain filtering for RS image processing to enhance the spectral information of ground objects in the high-frequency range and suppress clouds in the low-frequency range [
5,
6,
7]. Bands with high cloud transmittance and high correlation with neighboring bands exist in multi-spectral images. A haze-optimized transformation (HOT) method, as proposed by reference [
8], aims to correct the band value deviation caused by clouds by virtue of the high correlation of red and blue bands in the clear regions. Nonetheless, these clear regions require manual selection and for this reason, Xu et al. [
9] developed a linear cloud removal method using a cirrus band. Simultaneously, these methods [
10,
11] rely on spectral analysis to remove the thin cloud component from the visible spectrum. In addition, He et al. [
12] proposed a dark channel prior (DCP) defogging algorithm, and this work was gradually developed to remove thin clouds [
13].
However, if surface radiation is absorbed by thick, concentrated clouds before reaching the sensor and the spectral information from a single image is insufficient to achieve a detailed reconstruction of the ground object, the above methods are no longer applicable. Instead, conventional thick cloud removal methods integrate the complementary advantages of multiple images to supply the missing information. These methods are mainly divided into multi-temporal methods [
14,
15,
16,
17,
18,
19,
20,
21] and multi-source methods [
22,
23,
24,
25]. Multi-temporal methods introduce additional observations from different acquisition times to reassemble RS images; however, such methods require consistent land cover types in all images. Cheng et al. [
15] proposed a spatio-temporal Markov to determine the optimal clean pixels of the replaceable cloud in the auxiliary images. Li et al. [
18] presented two expanded multitemporal dictionary learning-based algorithms to recover the missing information from MODIS data. Based on the low ranks of multi-temporal image sequences, a discriminative robust principal component analysis (RPCA) model was devised, which assigns penalty weights to cloud pixels and then reconstructs cloudy images [
19]. Ji et al. [
20] and Lin et al. [
21] introduced the sparse function to describe the cloud component and exploit the latent multi-temporal relationship to estimate the missing pixels. Essentially, multi-source methods mostly rely on data obtained from different sensors for a given location to reconstruct RS images. Synthetic aperture radar (SAR) can work in all-time and the radiation waves have a strong penetrating ability. The collected SAR images are rich in spatial detail features and are used as auxiliary data for innovative cloud removal methods. Using the cloud-penetrating properties of SAR signals, Eckardt et al. [
22], Li et al. [
23], and Zhu et al. [
24] combined the intact structural information in SAR images to reconstruct regions with missing optical information. Moreover, Landsat-MODIS data fusion was used to fill the missing holes and be consistent with the context [
25].
The above conventional methods have achieved good performance but suffer from some deficiencies. For thin cloud removal methods, due to their reliance on prior assumptions, their modeling performance is limited and it is difficult to moderately remove clouds. Most reconstructions combined with multiple image methods fail to consistently achieve high-quality and timely results, and cannot address the increasing demand for high-quality RS images from cloud removal. Moreover, due to the differences in imaging principles and spatial resolutions, images obtained by different sensors are prone to spectral distortion and texture information loss during the fusion process.
1.2. Deep Learning-Based Cloud Removal Approaches
Nowadays, deep learning has been widely applied to cloud removal in RS images and has significantly improved the cloud removal effect compared with conventional methods. Specifically, restoring cloud-contaminated images simulates a nonlinear mapping from cloud-contaminated images to cloud-free images using deep learning-based methods. The convolution neural network (CNN) has shown impressive performance in image processing tasks and some corresponding methods have been applied to cloud removal. Zhang et al. [
26] proposed the unified spatial-temporal-spectral deep convolutional neural network (STSCNN) to remove thick clouds. Similarly, a CNN model based on the U-Net [
27] architecture to estimate a thickness coefficient map and achieve cloud removal [
28]; however, details of the image are inevitably lost due to the up-sampling and down-sampling operations. In Li et al. [
29], residual convolutional and deconvolutional operations were utilized to better preserve useful information. Chen et al. [
30] presented the content-texture-spectral CNN (CTS-CNN) to reconstruct regions under clouds in ZY-3 satellite images. Dai et al. [
31] used a novel gated convolution to process cloud pixels and clear pixels separately, achieving consistency in deep and shallow features between global and local areas.
This is a breakthrough in cloud removal and uses the powerful image generation capabilities of the generative adversarial network (GAN) to reconstruct the cloud-contaminated regions. The integration of the CNN model into the generator has now become mainstream. A multi-spectral conditional generative adversarial network (McGAN) [
32] integrated the visible image (Red, Green, Blue) and the near-infrared (NIR) band to remove thin clouds and accurately predict the color of ground objects. This work was further extended by the introduction of edge filtering [
33]. Singh et al. [
34] designed a cloud removal model (Cloud-GAN) based on the cycle-consistent generative adversarial network (CycleGAN) [
35] using the bidirectional mapping relationship between the cloudy image and the cloud-removed image to reconstruct the missing information without requiring cloudy and cloud-free image pairs as the dataset. The method provided in Sarukkai et al. [
36] captures the correlation of multi-temporal images by using a spatio-temporal generator network (STGAN) to efficiently restore images. Subsequently, some advanced techniques have been employed to optimize the network performance, for example, Pan [
37], Yu et al. [
38], and Xu et al. [
39] embedded the attention mechanism into GAN to better characterize the distribution and features of clouds and to improve the restoration of cloudy regions.
SAR images and optical image fusion have also been borrowed for some deep learning-based cloud removal methods, and the larger differences between images are well attenuated by the deep learning models. Sentinel-1 SAR images were used as auxiliary data in Meraner et al. [
40] and Ebel et al. [
41] to remove clouds from Sentinel-2 images. A new idea for multi-source image fusion involved the translation of the SAR image into the corresponding simulated optical image, then the adoption of a fusion network to fuse the cloudy image, SAR image, and simulated optical image to obtain a cloud-removed image [
42,
43]. There are also other strategies that approach cloud removal from a novel perspective. Wen et al. [
44] achieved thin cloud removal in the YUV color space, while Zhang et al. [
45] uploaded a trained CNN-based fusion model onto Google Earth Engine (GEE) and removed the clouds in Sentinel-2 images.
Although various deep learning-based cloud removal methods have emerged and facilitated the widespread use of RS images, some critical issues remain to be overcome. Specifically, the development of deep learning-based cloud removal frameworks has not yet fully matched the properties of RS images. These methods [
26,
28,
29,
30,
32,
33,
34,
35,
36,
37,
38,
39,
44] fit the unidirectional mapping from cloudy images to cloud-free images without distinguishing between cloudy and non-cloudy regions, then use plain convolution layers to extract features, thus neglecting the reconstruction of local regions. Meanwhile, with exception of [
31,
40,
41,
42,
43], other approaches use per-pixel loss functions in the network training process, which constrain the global generation of pixels without additional attention to the reconstructed regions. There is no guarantee that the reconstructed regions will be semantically compatible with the surrounding clear regions. To mitigate this problem, the cloud mask is introduced in these methods [
31,
40,
41,
42,
43] to participate in the loss function to guide the reconstruction of local regions. However, in [
31,
42], the treatment of cloudy and non-cloudy regions only partitions the corresponding region mapping from a global view without maximizing the original information of non-cloudy regions. Another point worth considering is that the direct fusion of SAR images and RS images aggravates the burden on the network because of the lower resolution and speckle noise of SAR images.
To address these problems, we propose a GAN-based framework, dubbed DC-GAN-CL, which incorporates both a distortion coding network and compound loss functions for RS image restoration tasks. The main contributions of the proposed approach are presented as follows.
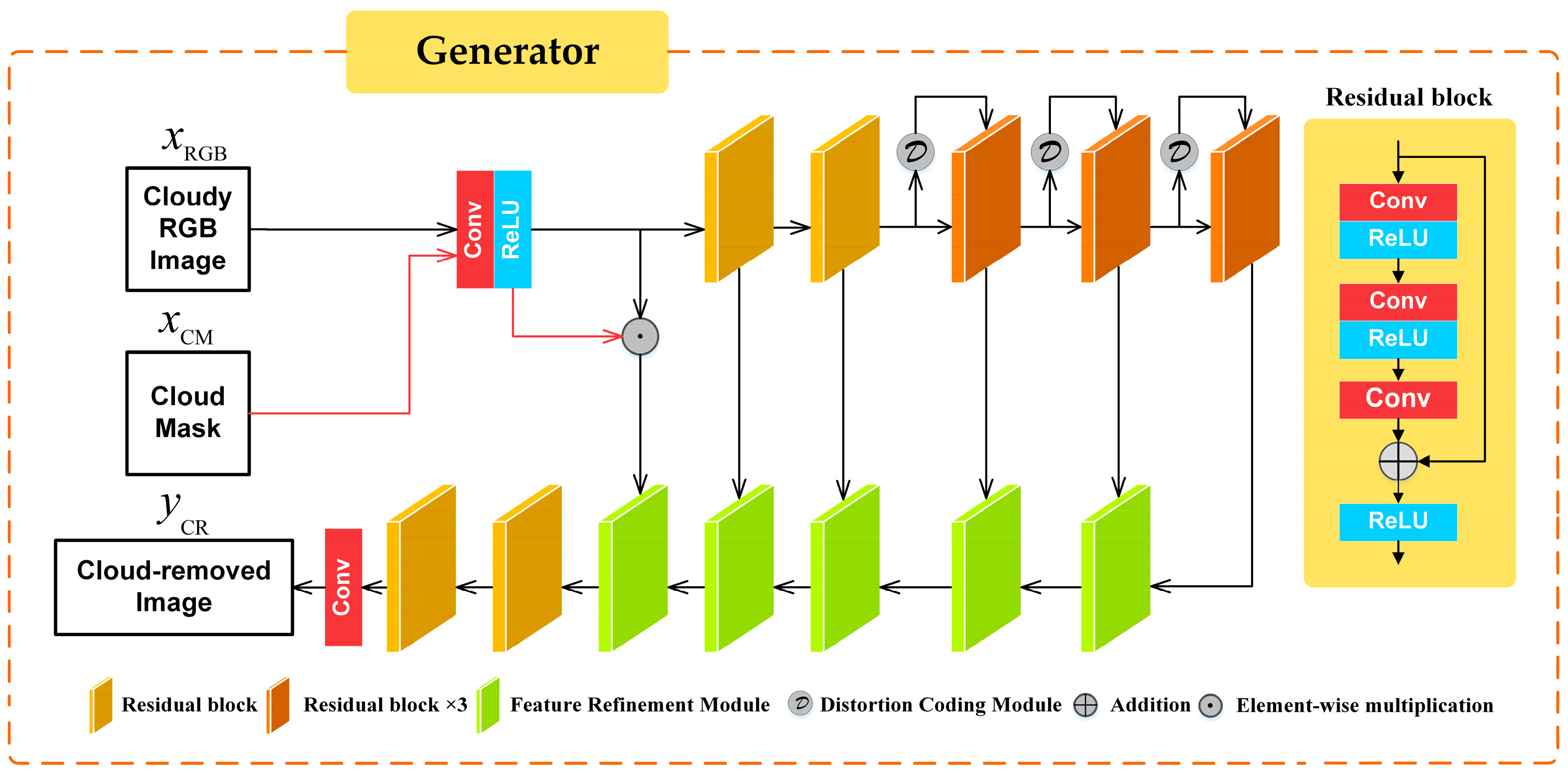
A new methodology for cloud removal from RS images is proposed with a novel generator employing the symmetric cascade structure of U-Net and two fresh embedded modules for better reconstruction results, and the multitask loss function is designed to restore repetitive details and complex textures.
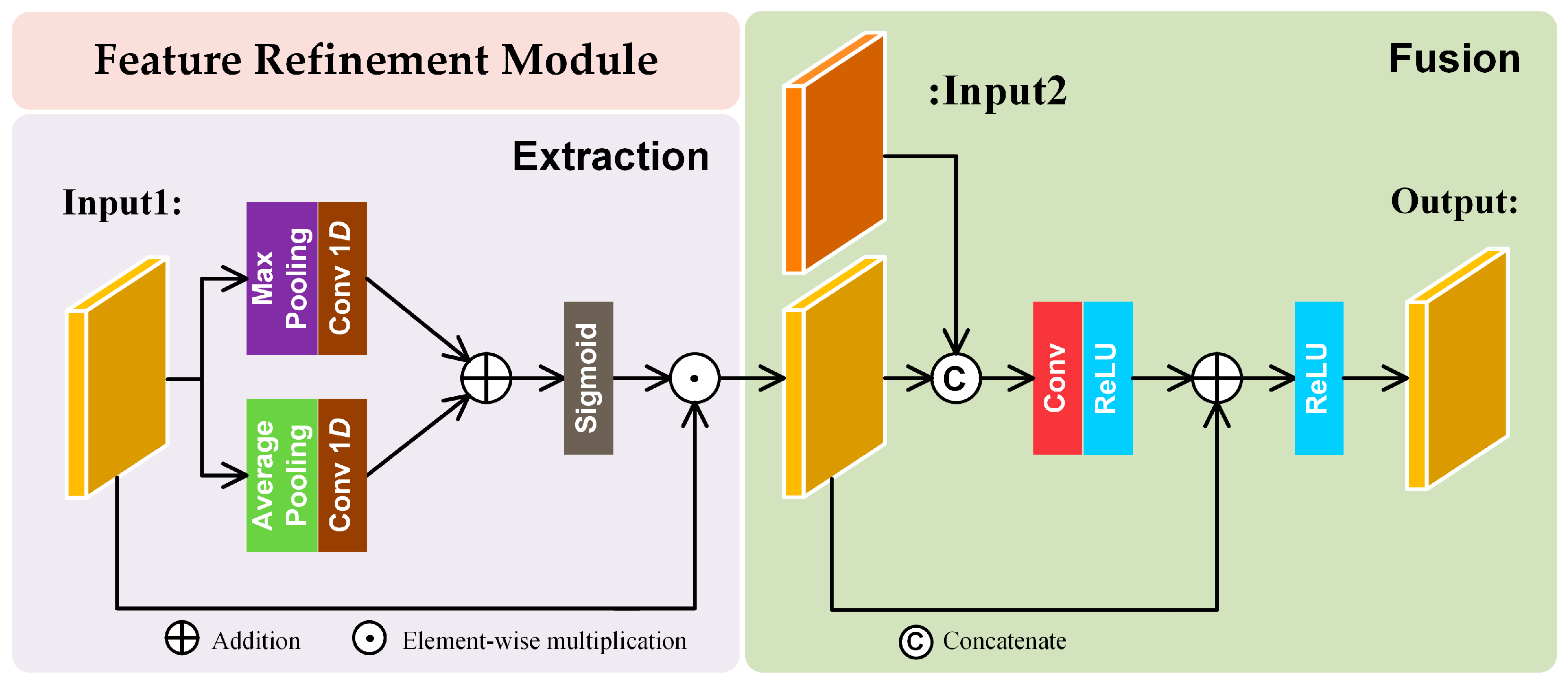
We convert the implicit data prior learned in the image to an explicit network prior and a distortion coding module for cloud pixels is introduced in the generator for encoding distortion factors in cloudy images into parameters that can be used for network training. A feature refinement module is applied to optimize the integration and transmission of optical information and consists of two tandem phases: extraction and fusion.
Dedicated to exploiting the properties of RS images, we develop the compound loss functions that maximally adapt to cloud removal in RS images in three main aspects, namely, model training, constraints on coherent image semantics, and local adaptive reconstruction.
The remainder of this work is structured as follows.
Section 2 describes the proposed method in detail, including the network architecture, additional modules, and loss functions. The experimental setting, results, ablation study, and parameter sensitivity analysis are provided in
Section 3.
Section 4 reiterates and discusses the previous experiments, and adds additional datasets to demonstrate the generalization capability of the proposed method. Finally, the conclusion is given in
Section 5.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}