1. Introduction
The spatial distribution pattern of crops in the farmland area is important for macro agricultural policy formulation, farmers’ production guidance, food production detection, and prediction [
1,
2,
3]. Traditional crop classification methods require a large amount of manual field research, and the timeliness of the data is low, so monitoring regional crops in real-time is in demand [
4,
5]. In recent years, the rapid development of agricultural remote sensing technology has provided effective technical support for realizing the quick identification and monitoring of large areas of crops.
Presently, a series of studies have verified the feasibility of remote sensing images for crop classification. Li et al. [
6] achieved high-precision identified winter wheat based on spectral features. Jiang et al. [
7] effectively extracted rice information based on the spectral features of Landsat images and analyzed the changes in the rice planting system in Southern China. The analysis of the above research confirms that spectral features can be used for crop recognition. In addition, the accuracy of multi-crop classification based on single spectral features is limited due to the widespread phenomenon of “same matter different spectrum” and “foreign matter same spectrum”, especially in regions with complex planting structures. Remote sensing images contain abundant textural features reflecting the spatial distribution structure of ground objects, which can increase the separation between multiple crops and improve classification accuracy [
8]. For example, some scholars analyzed different textural feature extraction methods in their research and confirmed that textural features could be used as a reference for crop classification [
9,
10]. In addition, environmental characteristics remarkably affect the growth characteristics of crops. Therefore, environmental characteristic indicators can be used to identify crops considering the difference driven by the environment, thus improving classification accuracy [
11]. Zhang et al. [
12] used spectral and environmental indexes for crop classification, and the results showed excellent accuracy. Therefore, how to construct an effective strategy by fusing the three types of information to carry out multi-crop classification to meet practical needs remains worthy of further study.
Machine learning (ML) models have been widely used in the field of crop recognition, such as random forest (RF) [
13], support vector machine (SVM) [
14], K-nearest neighbor (KNN) [
15], naïve Bayes (NB) [
16], artificial neural network (ANN) [
17], and Extreme Gradient Boost (XGBoost) [
18]. Xu et al. [
13] and Liu et al. [
19] adopted RF to monitor winter wheat and discussed the influence of different feature combinations on classification accuracy. Rashmi et al. [
20] demonstrated that the XGBoost result had a better performance than RF and SVM in crop mapping based on spectral features of different crops. Prins and Niekirk [
21] used multiple data sources and classifiers for crop classification, and RF and XGBoost each provide the highest classification accuracy in different data sets. The effectiveness of ML classifiers on crop classification has been verified by existing studies. In addition, deep learning is also widely used in the field of crop identification. Deep-learning-based crop classification can be classified into two types. The first type is a classification based on samples, such as a one-dimensional convolutional neural network (1D-CNN) [
22]. Another is a classification based on images, but it is limited by its requirement for massive data and high image resolution, which makes it difficult to be effectively applied under the conditions of low precision data sources in large areas and limited sample size. Therefore, the 1D-CNN method is adopted in this study for comparison [
23,
24].
However, the classification feature types and the number of classification indexes affect the performance of ML classifiers. If a mass of classification indexes is included in the model, then the efficiency and accuracy of model prediction will be affected. If only a few indexes are considered, crop characteristics cannot be adequately reflected, and model accuracy will be reduced. Therefore, to optimize the ML classifier, the feature selection (FS) method is generally used for index screening to reduce data redundancy and obtain the critical indexes for crop recognition. The FS methods commonly used in the literature include random forest average accuracy (RFAA), random forest average impurity (RFAI), and recursive feature elimination (RFE). Masoud et al. [
25] optimized the crop classification index set based on RFAA, and the optimized index subset showed an evident improvement in crop classification. Mahboobeh et al. [
26] selected the optimal subset of independent variables using RFE to reduce the number of input variables and obtain a substantial effect on model performance. In summary, FS classification methods have many options, but which FS classification method is optimal remains unclear. Furthermore, the effect of different FS methods on ML classifiers remains unknown [
27].
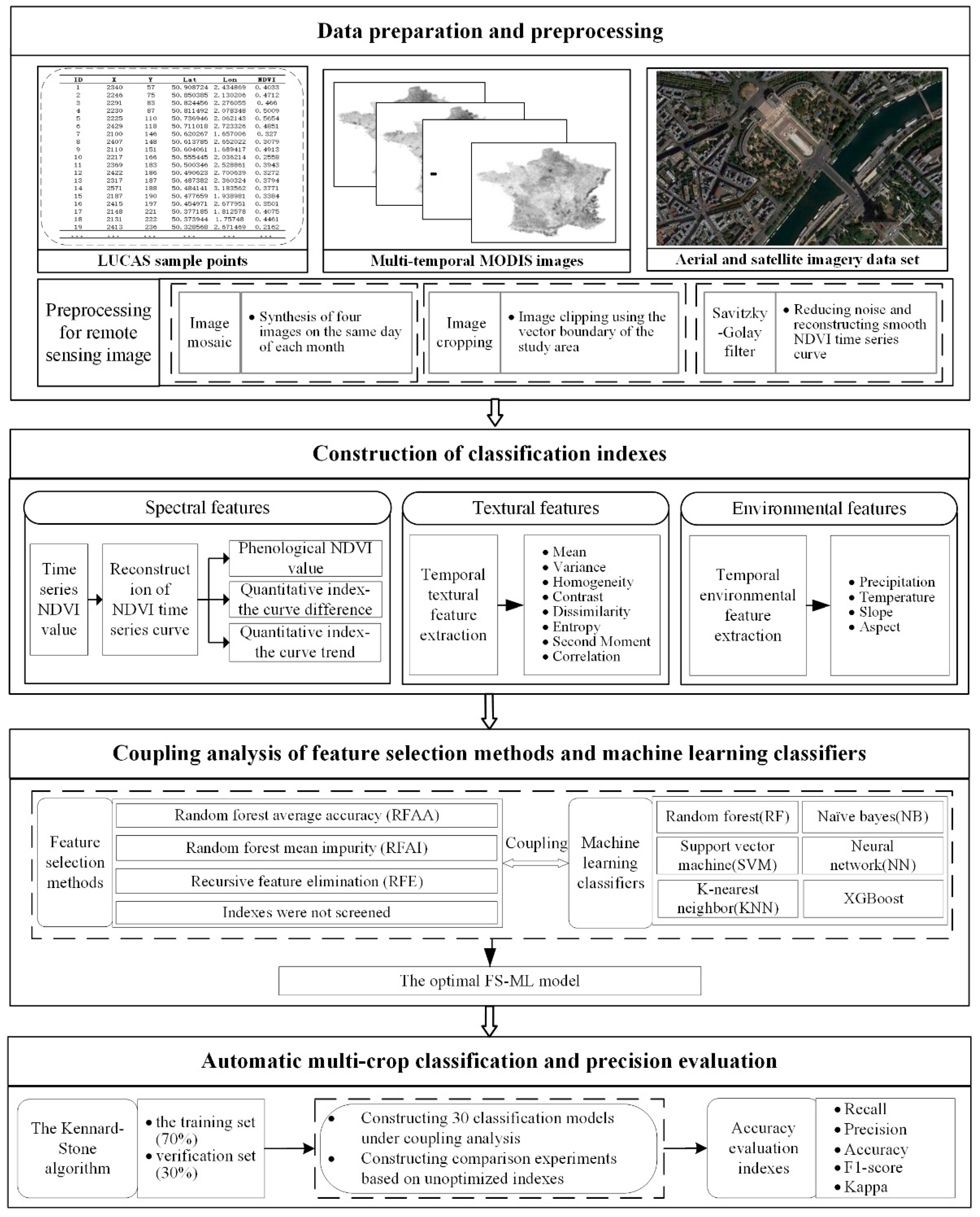
To sum up, this paper aims to address the above issues by a systematic comparative study on the various coupling of FS methods and ML classifiers, which is limited in existing studies to the best of our knowledge. This paper intends to merge spectral, textural, and environmental features to construct a more accurate and effective multiple crop classification method by selecting an optimal coupling model (FS–ML) based on the FS methods and the ML classifiers. A series of multi-crop FS–ML models are constructed by coupling six classifiers (namely, RF, SVM, KNN, NB, ANN, and XGBoost) and a series of typical FS methods. Agriculture in France is flourishing, which is chosen as the study area. Spectral, textural, and environmental variables are used to quantify the crop growth characteristics, and the coupling classification methods for recognizing multiple crops are constructed. The results are assessed by Kappa coefficient, F1-score, accuracy, and other indicators.
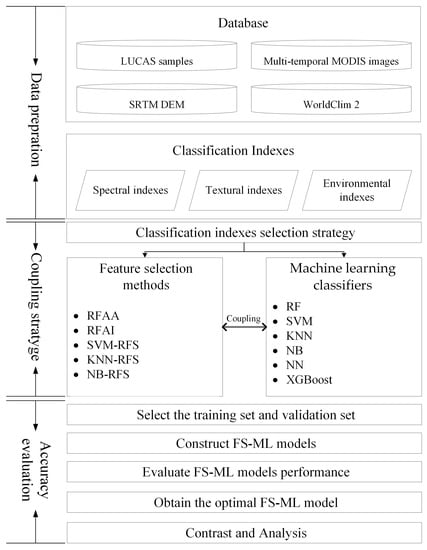
3. Methodology
Until now, making a breakthrough in the problem of limited accuracy caused by “the same object with different spectra” and “the same spectra of foreign matter” remains challenging. To address the above problem, spectral, textural, and environmental indexes that can measure crop growth characteristics from different aspects are fused to be the classification index set, aiming at classifying crop types with high precision. The calculation of classification indexes is described in
Section 3.1. To reduce data redundancy and select the optimal classification index combination, the indexes calculated in
Section 3.1 need to be optimized. However, the classification results depend not only on the index optimization strategy but also on the classifiers. As the optimal option of the index optimization methods and classifiers remains unknown, the influence of index optimization strategy on classifiers is also unclear. Hence, the coupling analysis of index optimization methods and classifiers is carried out and elaborated in
Section 3.2. Additionally, the classification model is constructed and evaluated by the training set and the validation set, respectively, as described in
Section 3.3. The evaluation indicators are elaborated in
Section 3.4. The whole workflow of this study is illustrated in
Figure 4.
3.1. Construction of Classification Indexes
3.1.1. Construction of Spectral Indexes
Several studies indicated that the different growth characteristics between crops are mainly reflected in the time series of the NDVI values [
6,
7]. NDVI can be calculated based on images in
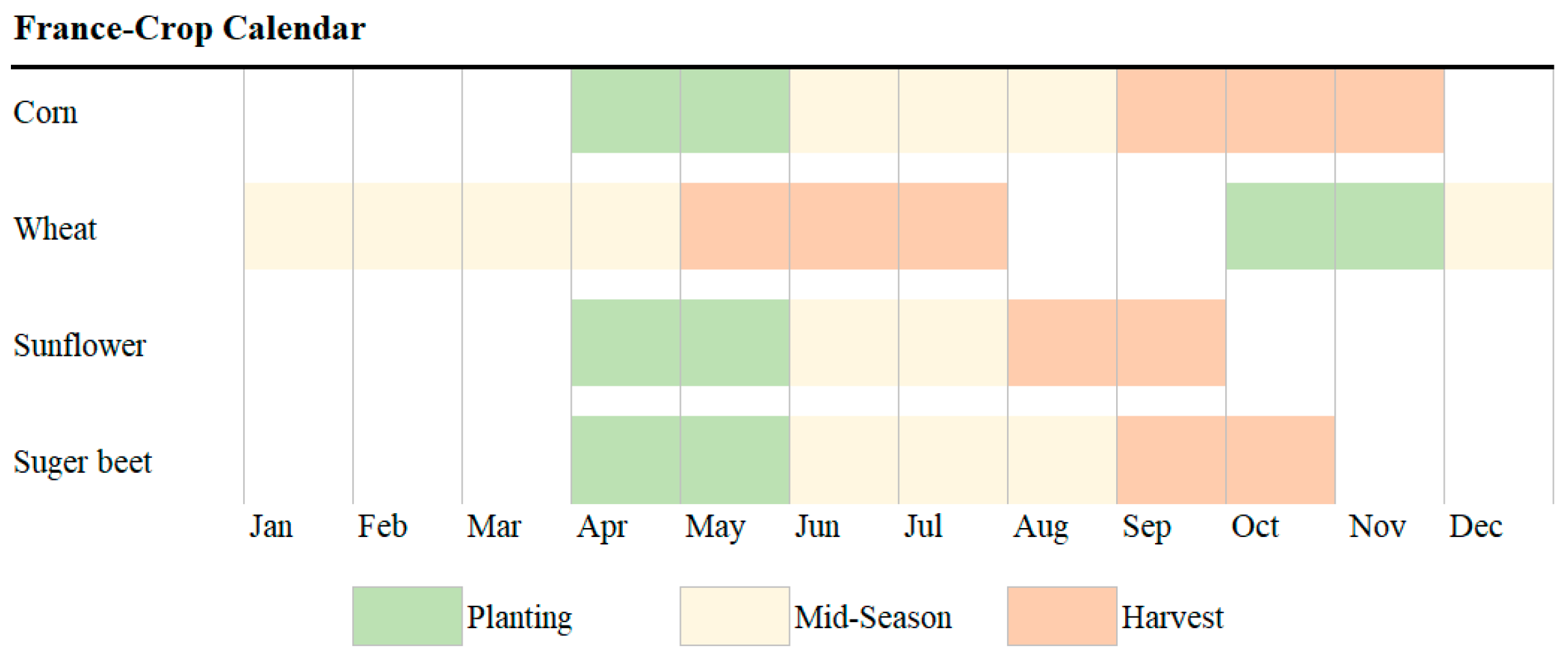
Figure 2. The phenological periods of the studied four crops in
Figure 3 cover the whole year. Therefore, 12-month NDVI values are calculated and set as potential spectral indexes. Additionally, existing studies verified that the curve trend
and the curve difference
shown in
Table 1 can further help uncover the differences between crops and were also adopted in this study. Curve trend
reflects the fluctuation trend of crop growth changes and measures the correlation between curves [
32]. The curve difference
measures the distance difference between curves and judges the dissimilarities between the curves [
33]. A higher
indicates that the spectral features of sample
are more similar to the spectral features of crop type
. A lower
means the differences between the spectral features of sample
and the spectral features of crop type
are smaller.
3.1.2. Construction of Textural Indexes
The grey level co-occurrence matrix (GLCM) [
24] is one of the commonly used texture algorithms and was adopted to measure texture information from images in
Figure 2 for multiple crop classification. Eight GLCM based textural indexes (in
Table 2) including mean (
), variance (
), homogeneity (
), contrast (
), dissimilarity (
), Entropy (
), second moment (
), and correlation (
) were calculated using ENVI/IDL software. The mean value reflects the brightness relationship between the pixels and the surrounding pixels. Variance reflects the degree of gray change in the local area of the image. Homogeneity reflects the concentration of pixels in the matrix. Contrast shows the degree of gray difference in the local area. Dissimilarity is the linear correlation of the local pixel contrast. Entropy measures the richness of textural information. The richer the textural information is, the greater the entropy is. Second moment was used to describe the distribution of image brightness. Correlation reflects the relationship between the pixels and the surrounding pixels.
3.1.3. Construction of Environmental Indexes
Crop growth highly relies on environmental conditions. Crop growth characteristics will be obviously different in different environmental conditions. Therefore, adding environmental variables as potential classification indexes was expected to improve classification accuracy. Climate factors and topographic factors are two typical environmental factors related to crop growth and were calculated as potential classification indexes in this study (
Table 3). For topographic factors, slope and aspect are potential indexes leading to crop growth characteristics varying with the environment. For climate factors, precipitation and temperature are clearly related to crop growth. As precipitation and temperature change over time, precipitation and temperature were calculated at three scales, including monthly, quarterly, and annual precipitation and temperature indexes.
3.2. Coupling Strategy Based on Feature Selection Methods and Machine Learning Classifiers
Substantial differences in textural features between crops are usually concentrated on some specific features. To reduce data redundancy and improve accuracy, classification indexes need to be optimized to obtain the optimal combination. To further explore the effects of the FS methods on different classifiers, coupling analysis was conducted based on the typical FS methods and six ML classifiers in this paper.
3.2.1. Feature Selection Methods
Feature selection can not only reduce the redundancy of indexes and improve the efficiency of the classification model but can also eliminate some noise features to improve the prediction ability of models. In this study, a wrapped feature selection method, RFE, was considered for feature selection. In addition, embedded feature selection methods, RFAI and RFAA, were also adopted to examine the suitability for optimizing machine learning classifiers.
The main principle of recursive feature elimination (RFE) is to obtain the optimal feature set by repeatedly constructing a model [
11,
34]. Through iterative loops, the size of the feature set was continuously reduced to select the required features. In each loop, the feature with the smallest score was removed, and the model based on the updated feature set was constructed. This tuning process selected the base function for constructing the model with the minimum error rate, and the 10-fold validation strategy was used to select the best basis function.
RF provides two methods for feature selection [
35,
36]. One is random forest average impurity (RFAI), which selects indexes by measuring the average of each characteristic error reduction. The other is average accuracy reduction (RFAA), which selects indexes by measuring the change in model performance when the order of each feature is disturbed. RFAI and RFAA will provide a feature ranking based on the weight of each feature. The hyperparameters in RFAI and RFAA were adjusted in order to construct models with the minimum error rate. The substantial feature selection methods based on the weights of features by RFAI and RFAA were labelled as RFAI+ and RFAA+. The implementation process was as follows: (1) Add the feature with the maximum weight in the model; (2) Construct an RF model based on the updated feature set and obtain the kappa coefficient of the model; (3) continue step (1) to (2) and save the feature set constructed from the model with maximum kappa coefficient as the final selected features.
3.2.2. Machine Learning Classifiers
The classifiers used in this paper include RF, SVM, KNN, NB, ANN, and XGBoost. The optimal hyperparameters of the classifiers were also evaluated by the acknowledged error rate and identified using cross-validation [
37].
Random forest (RF) is an integrated learning algorithm based on decision trees, which constructs multiple decision trees for classifying data sets. RF has been widely used in various classification and pattern recognition fields [
13,
19]. To perform the RF classifier, two important hyperparameters, including the number of decision trees (ntree) and the number of variables randomly sampled when building a decision tree (mtry), should be established [
37].
A support vector machine (SVM) is a potential nonlinear algorithm for classification. As the crop types are various, and the relationships between the data and crop types are complex, simple linear classifiers can be inapplicable. Hence, SVM, as a promising nonlinear classifier, was adopted. The SVM was constructed with the selection of the kernel function (e.g., linear, polynomial, sigmoid, and radial kernels) and the tuning of two hyperparameters: (1) gamma, which will affect the shape of the class-dividing hyperplane; (2) cost, which refers to the parameter used to penalize the misclassification [
37].
K-nearest neighbor classification (KNN) is a nonparametric classification technique according to distances between samples. It works on the assumption that the instances of samples of each class are surrounded almost completely by samples of the same class. The class number k is the key hyperparameter and was chosen to determine the class of unknown samples by calculating the class of k neighboring samples in KNN [
37].
The naïve Bayes (NB) classifier is a simple probabilistic classifier used for classification tasks that is based on the Bayes theorem [
16]. In the NB classifier, the crop type with the largest posterior probability is set as the classification type of the sample. To perform tuning for the NB classifier, the hyperparameter Laplace was considered [
38].
Artificial neural networks (ANNs) have been widely used to perform classification tasks in recent years. They contain an input layer, multiple hidden intermediate layers, and an output layer. Each hidden intermediate layer contains multiple neurons and computes related mathematical functions to discover complex relationships between the data in the input layer and the data in the output layer. An ANN is constructed with the tuning of two hyperparameters: (1) size, which is the number of nodes in the hidden layer; (2) maxit, which is the number of control iterations [
39].
Extreme Gradient Boost (XGBoost) is an extension of the traditional boosting technique. The basic idea of XGBoost is to construct a strong classifier by superposing the results of several weak classifiers [
40]. XGBoost mainly involves the tuning of the following hyperparameters: (1) nrounds, which refers to the number of trees; (2) eta, which is the learning rate; (3) depth, which indicates the depth of the tree [
41].
3.3. Construction of Training Set and Validation Set
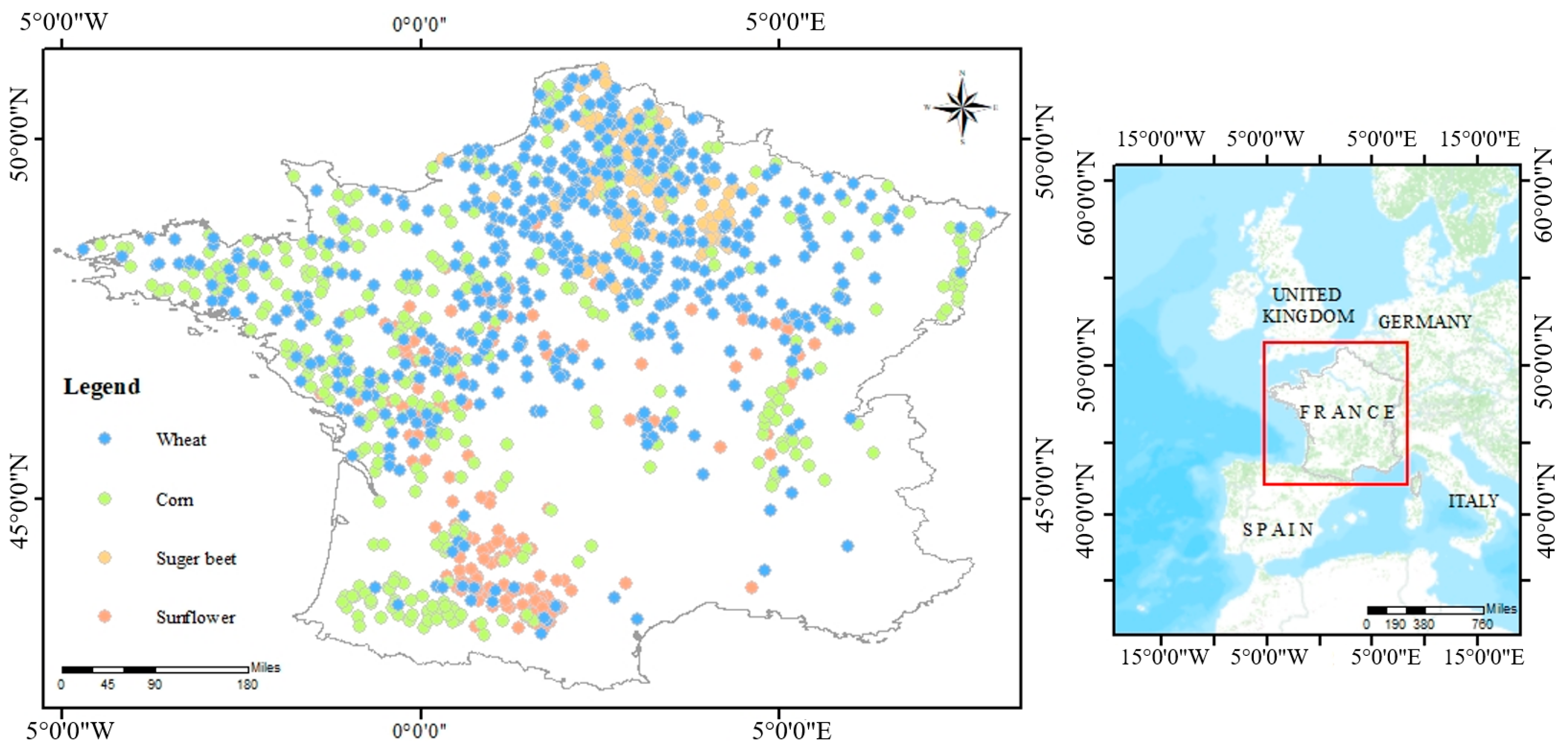
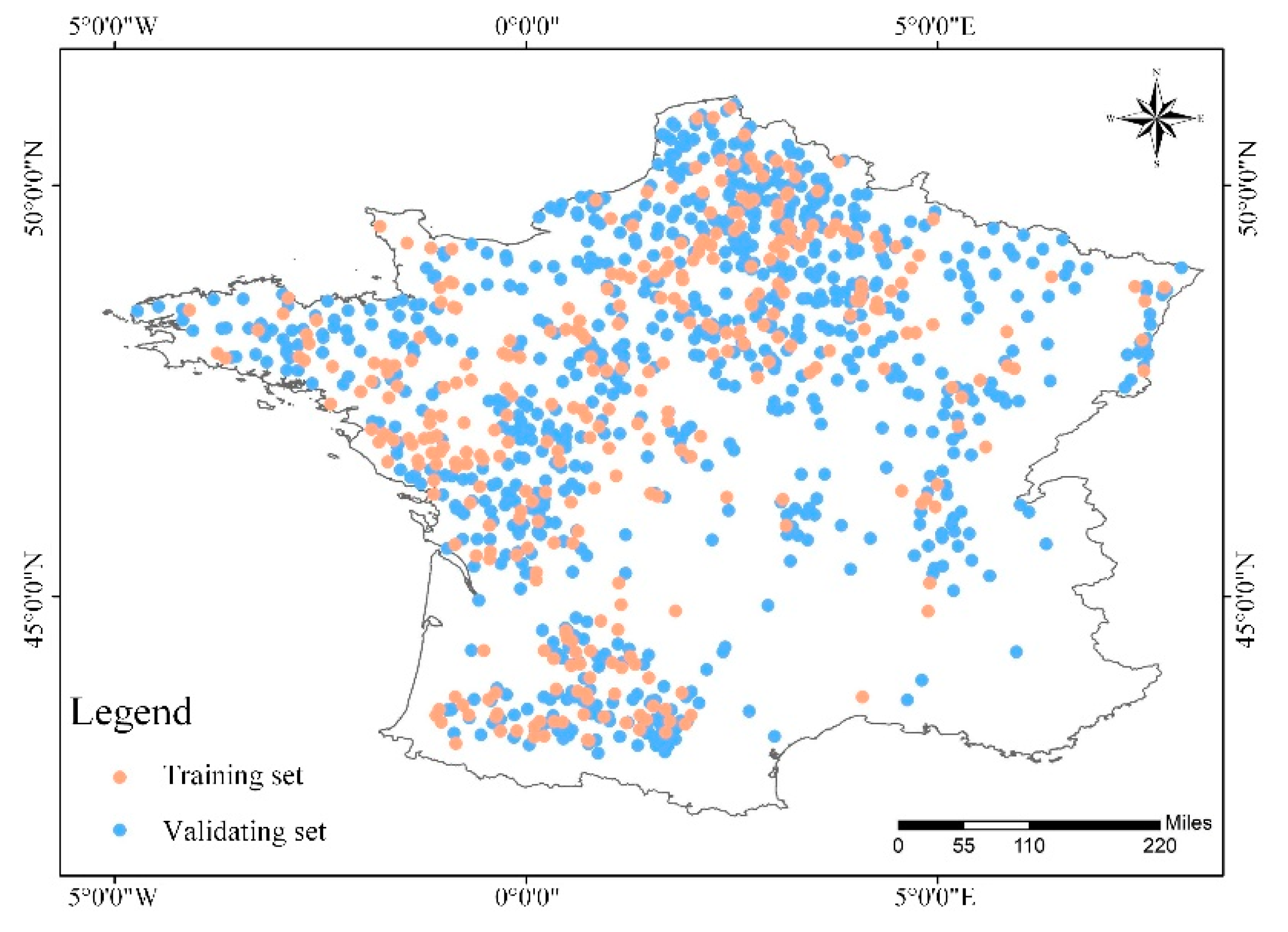
From
Figure 1, we can see that sample sizes between crop types in the study area are imbalanced. SMOTE, an inspired approach to counter the issue of class imbalance, was adopted to balance the difference between class sizes within 3 times (
Table 4) [
42]. Additionally, the performance of the crop classification model is greatly affected by the regional representativeness of the samples. In the existing research, sample selection mostly adopts random selection, which easily leads to insufficient representativeness of the selected sample area and overfitting or underfitting of the model. The Kennard–Stone (KS) algorithm can select samples with substantial differences in classification characteristics into the training set to ensure that it has sufficient regional representation. Existing studies have confirmed that the KS algorithm effectively addresses the problem of overfitting and underfitting of the model [
43]. Additionally, the accuracy of the prediction model depends on the size of the training set and the validation set. In general, if the size of the validation set is greater than 60% of the total sample, the model will have higher precision. Therefore, in this paper, 30% and 70% of the samples were chosen as the validation set and the training set, respectively.
3.4. Accuracy Evaluation
Accuracy, recall, precision, and F1-score were applied to evaluate the precision of the proposed classification strategy in this paper [
44]. Recall indicates the proportion of correctly predicted positive samples in the positive samples. Precision indicates how many of the predicted samples are true positive samples, and the F1-score represents the correctly predicted rate of positive samples. However, high recall with low precision, and high precision with low recall are ubiquitous, which is inconvenient for discriminating the classification effectiveness of positive samples. For example, when the recall is 0.4 and precision is 0.7 with an F1-score ≈ 5.1, or when the recall is 0.6 and precision is 0.5 with an F1-score ≈ 0.55, the results based on recall and precision are incomparable. The F1-score can solve this problem, which is introduced as the harmonic value of recall and precision [
45]. Hence, the F1-score was adopted as an evaluation indicator instead of recall and precision. Additionally, accuracy signifies the proportion of the correctly predicted rate of the whole sample (in Equation (1)).
where
is the crop type;
is the number of samples of crop type
correctly classified as crop type
;
is the number of samples of the other crop type correctly classified as the other crop type;
is the number of samples of crop type
mistakenly classified as the other crop type;
is the number of samples of the other crop type mistakenly classified as crop type
.
Given that F1-score is aimed at dichotomies and reflects the classification effect of single-type crops and is unable to evaluate the results of multiple crop classification, the kappa coefficient was introduced to evaluate the overall classification efficiency of the multi-crop classification model. The comprehensive use of the F1-score and kappa coefficient can fully reflect the overall multi-crop situation in the model and the classification effects. Referring to previous studies, if the kappa coefficient is less than 0.2, then the effect of the model is deemed slight. If the kappa coefficient is between 0.21 and 0.40, the classification ability of the model is considered to be fair. If the kappa coefficient is larger than 0.40 but less than 0.60, then the model exhibits a moderate classification ability. If the kappa coefficient is between 0.61 and 0.80, then the model is regarded as substantial. If the kappa coefficient is larger than 0.80, then the model is identified as almost perfect [
46]. Generally, kappa coefficient, F1-score, and accuracy were adopted to evaluate the effectiveness of the classification results.
5. Discussion
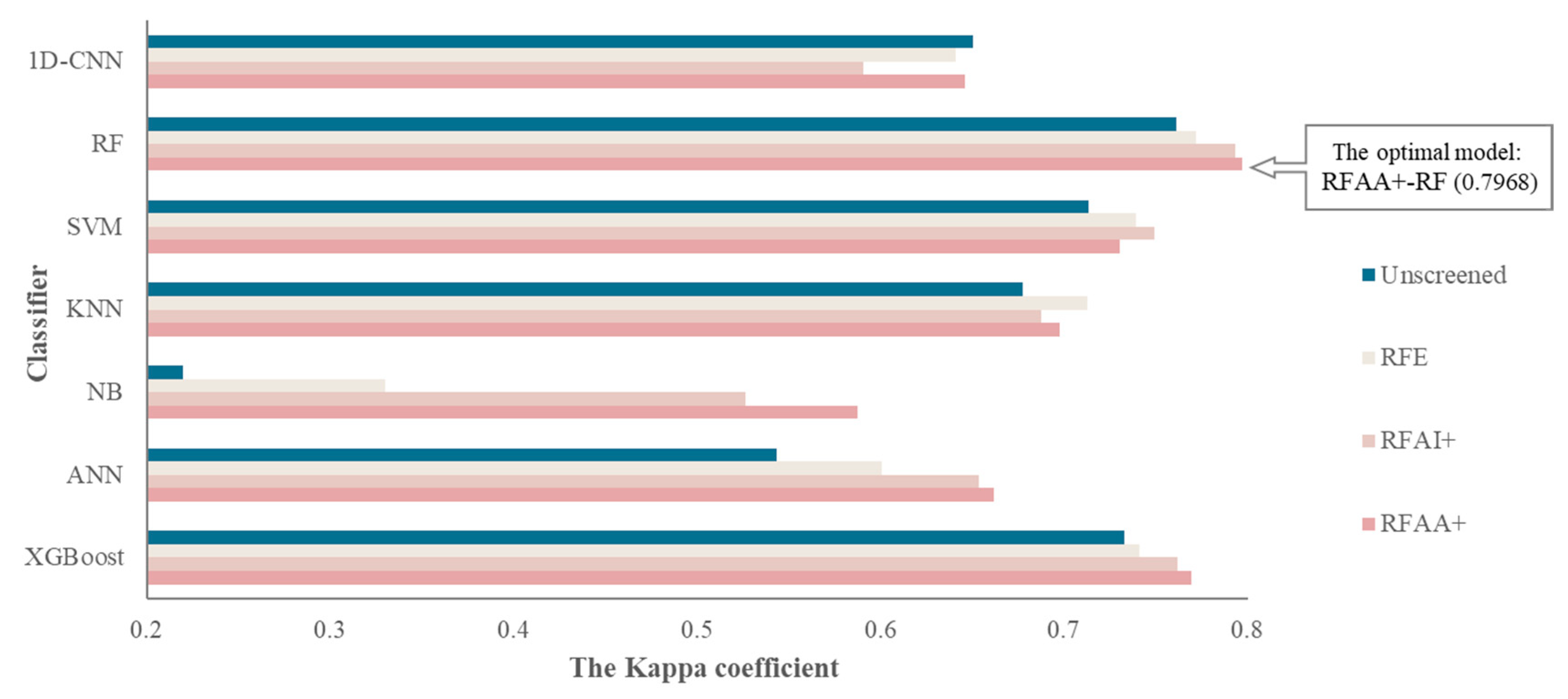
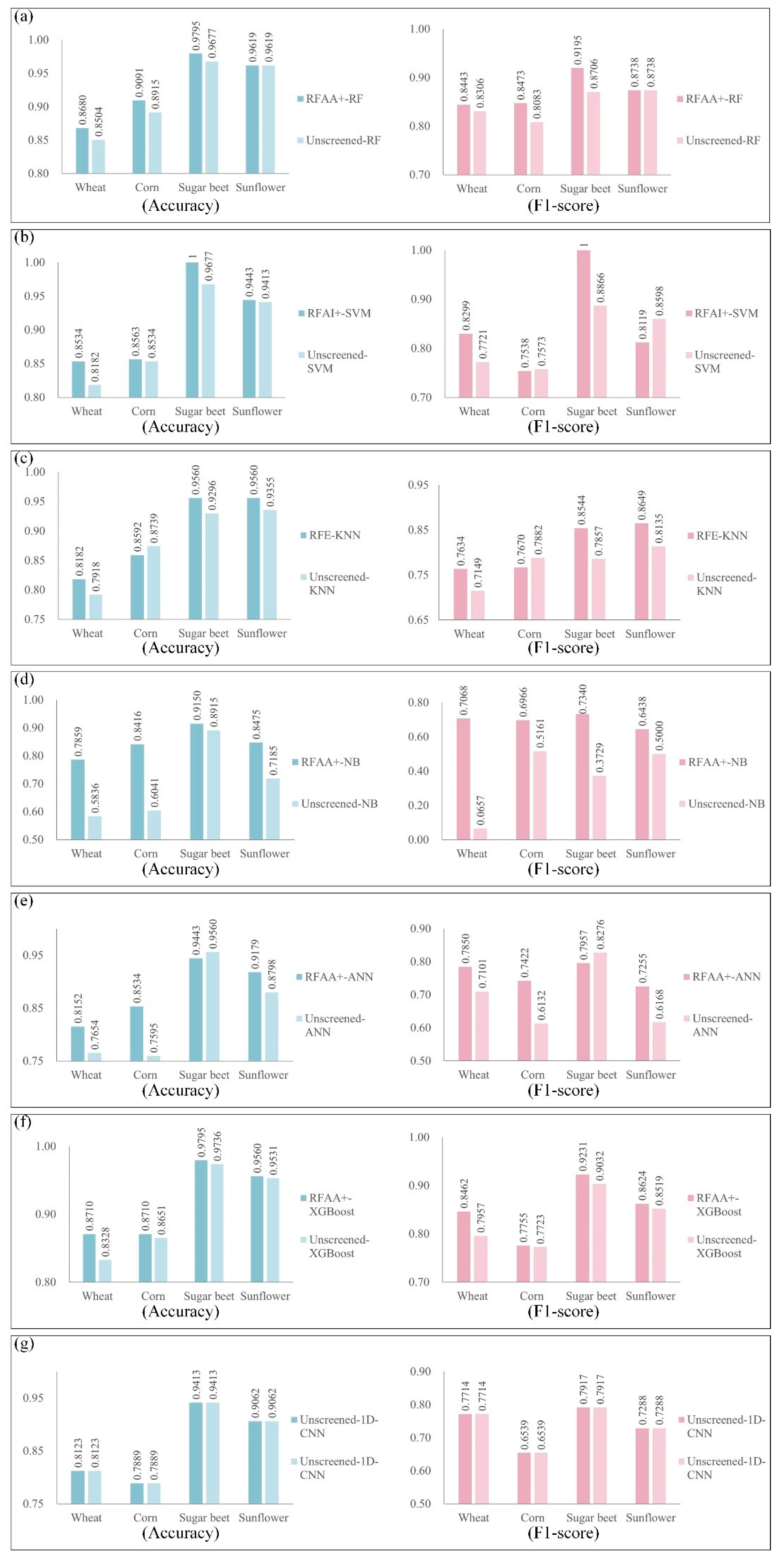
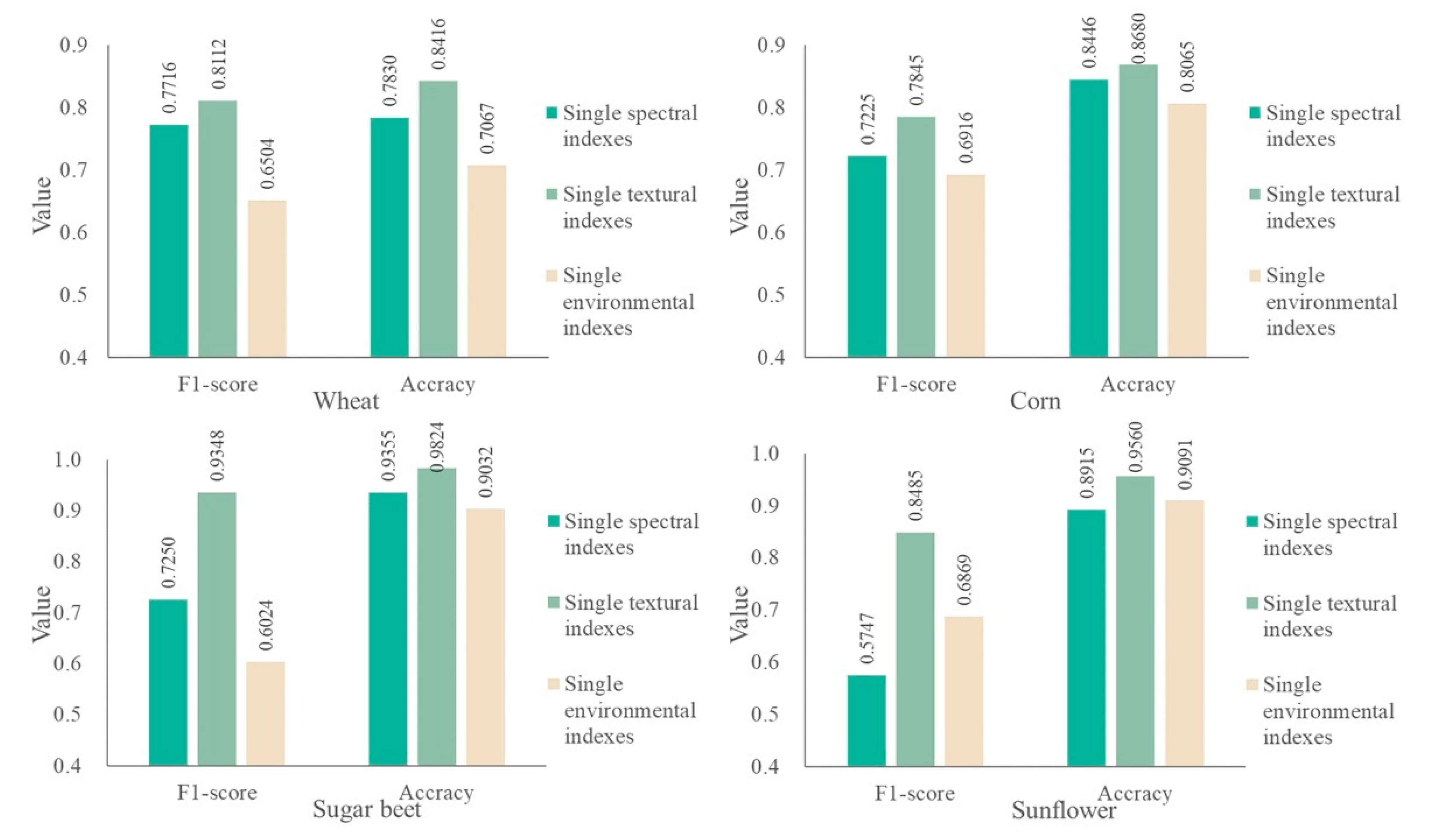
Considering that different FS methods have dissimilar effects on various classifiers, this paper merges spectral, textural, and environmental features to construct a more accurate and effective multi-crop classification method by selecting an optimal FS–ML model with a coupling strategy based on FS methods and ML classifiers, with the aim of obtaining the best FS–ML model and achieving high-precision multi-crop classification. The following interesting findings are obtained: (i) A high degree of similarity is observed in the index sets under different FS methods. These index subsets under different FS methods retain the indexes under months with considerable differences in crop growth characteristics. Moreover, classification accuracy by using these indexes for multi-crop situations is considerably improved. (ii) The results show that coupling FS–ML methods can substantially improve the classification accuracy of the models. In this study area, the best classification model is RFAA+-RF, and the kappa coefficient of multi-crop classification can reach 0.7968, which is 0.33–46.67% higher than that of other classification models. (iii) In terms of a single crop, the RFAA+-RF model based on fusion indexes of spectral, textural, and environmental indexes has a relatively satisfactory classification effect in the study area, and the optimal FS–ML model of each crop can be found effectively through the proposed coupling strategy. (iv) The optimal FS–ML model based on single spectral and textural indexes is the RFAA+-RF, which also performs well under single environmental indexes. The classification effect of four crop types based on fusing indexes is considerably higher than the effect based on single spectral, textural, or environmental indexes under all FS–ML models. In summary, RFAA+-RF based on fusing indexes can preferably meet the demands of crop classification in a large area with limited samples.
6. Conclusions
Multi-crop classification in France is incredibly difficult because of the large area and limited sample size. In this study, a coupling classification strategy that combines the feature selection methods and machine learning models based on timing spectral, textural, and environmental indexes is proposed to mine the coupling features and obtain the optimal classification method. The strategy shares the following advantages: (1) It can explore the effects of feature selection methods on machine learning models and obtain the optimal multi-crop classification strategy. In this study, RFAA+-RF is confirmed as the optimal crop classification method in the study area with a limited sample size and large area. (2) Temporal spectral, textural, and environmental indexes can reflect crop characteristics from different perspectives, and fusing these three types of indexes can measure the crop characteristics more comprehensively. The results make clear that crop classifications based on fused indexes have higher precision than classifications based on a single type of indexes. (3) Combining feature selection methods can retain valuable indexes, reduce data redundancy, and improve classification accuracy. The results also verify that the classification combined with feature selection methods is superior to classification based on unscreened indexes. (4) The coupling crop classification operation can automatically obtain results without sufficient prior knowledge of the study area, making the optimal classification method have the potential to be a widely applicable method for crop classification.
Future work will focus on the application of the proposed coupling strategy based on FS methods and ML classifiers. In this paper, the study area is wide with large-scale crop distribution. If the study area is small with broken crops, the proposed classification method based on high–resolution satellite images can also serve as a potential technique to recognize the crop distribution. In addition, the proposed method can be applied to other crops except for the four crop types in the study, such as rice or even greenhouse crops in practice.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}