1. Introduction
The most important uses of water resources are for water supply, irrigation, agriculture, industrial requirements, and other purposes. The easy accessibility of waste discharge, and dynamic nature of river systems, lead to their exposure to the adverse effects of environmental contamination [
1]. In recent decades, the improper management of water resources systems has caused their extensive pollution. ‘Total dissolved solids’ (TDS) indicates the total amount of inorganic salts or organic matter that has been dissolved in a water system. In a measurement test of TDS, the sum of the cations and anions in the sample is counted, and mainly includes inorganic minerals, various salts, and organic matter [
2]. Aesthetic problems can be found in water systems by increasing TDS concentration, which may be caused by stains or precipitation [
3]. The pollutant load of the aquatic system is generally due to the amount of TDS concentration. TDS concentration is considered a prominent factor for determining the water quality index [
4]. Therefore, it is essential to present a precise model for forecasting TDS, since it has important practical and social values. Similar to biological, chemical, and physical factors for prediction of water quality parameters (WQPs), non-mechanical computer training models that are strongly nonlinear are needed for TDS modeling. In this regard, TDS modeling is a complicated scientific problem.
Nowadays, artificial intelligence models are more extensively employed in modeling complex systems than physical process-oriented and numerical modeling methods due to their superiority: this is because their simple model-building procedure leads to reduced computational time. Recently, artificial intelligence (AI) models such as extreme learning machine (ELM) [
5,
6], adaptive neuro fuzzy inference system (ANFIS) [
7,
8], gene expression programming (GEP) [
9,
10], support vector machine (SVM) [
11,
12], model tree (MT) [
13], artificial neural network (ANN) [
14,
15], and group method of data handling (GMDH) [
16,
17] have been employed for solving a wide range of environmental problems.
The existing body of literature already encompasses several studies of water quality parameters (WQPs) predicting, based on both standalone AI models and optimization-based AI models. For instance, ANN, ARIMA, and transfer function-noise techniques were used by Abudu, King, and Sheng for the monthly TDS modeling of the Rio Grande in El Paso, Texas [
18]. In a similar study, Khaki et al. [
19] assessed the potential of the ANFIS and ANN models for the prediction of TDS in the Langat Basin, Malaysia. Asadollahfardi et al. [
20] and Mustafa [
21] investigated the utility of the ANN model in TDS modeling and strengthened their study by applying the Box-Jenkins time series and multilayer perceptron (MLP) models for forecasting TDS in the Zayande Rud River, Iran. Moreover, Pan et al. [
22] studied the performance of an integrated model, principal component regression (PCR), backpropagation neural networks (BPNN), and dual-step multiple linear regression (MLR) to estimate the TDS for an aquatic system in Canada. Whilst robust approaches with high capability have been presented so far, developing a precise modeling framework has remained a challenging issue in TDS prediction. Sun et al. [
23] applied integrated machine learning to forecast TDS at two stations in Iran. Crow search algorithm was used to optimize the AI model’s parameters. They finally found that the hybridized model outperformed other standalone models and an empirical equation in predicting TDS at the Tajan basin.
Although there are extensive civil engineering problems which were successfully solved using the abovementioned AI models, most of them used crisp input variables to model the target variables, and that can be a weakness of their modeling. To address this weakness, Fuzzy set theory, as an extension of the crisp logic in classic form into a multivariate form, was introduced by Zadeh [
24]. One of the main advantages of this procedure over the crisp procedure is that it has suitably flexible decision boundaries, and because of this characteristic, its ability to adjust to a specific domain of application is higher and accordingly reflects its particularities more accurately [
25]. Gradual transitions between defined sets in crisp sets, in contrast to their fuzzy counterparts, cause the uncertainty problem. In other words, the mapping of inputs onto targets can be defined as a set of IF–THEN rules after building a model with a series of overlapping fuzzy sets. Defining fuzzy sets can be identified from data, or from expert knowledge [
26]. In contrast to neural networks, neuro fuzzy models are prone to a rule explosion, and the number of rules can be exponentially increased by increasing the number of variables. In this regard, specifying the entire model from expert knowledge will be difficult [
27]. Therefore, defining the model structure with a rule-based system in fuzzy modeling is one of the main characteristics of using a fuzzy set. In this sense, several linear models can be collected locally in the fuzzy system based on the rule premises, and using interpolation, the final model is developed [
28].
In addition, tuning the AI model parameters is often difficult. As a result, meta-heuristic algorithms have been widely applied in engineering optimization, parameter solving, and other areas like data mining model optimization for WQP modeling. Thus, in recent years, hybrid AI models that are coupled with meta-heuristic algorithms such as particle swarm optimization (PSO) [
29], genetic algorithm (GA) [
30], gray wolf optimization (GWO) [
31,
32], crow search algorithm (CSA) [
33], gravitational search algorithm (GSA) [
34,
35], and whale optimization algorithm (WOA) [
14,
36] are preferable compared to standalone AI models because of their abilities and promising ability to model and predict hydro-climatology parameters.
Regarding the aforementioned: the aim of this study is developing a Fuzzy integrated model for prediction of TDS in the Tajan river basin. The three main contributions of this paper are outlined as follows.
- (1)
The literature review showed that the application of GMDH integrated with Fuzzy set theory and grasshopper optimization algorithm (GOA) in WQPs modeling had not been investigated and evaluated. It is worth mentioning that GOA belongs to the category of multi-solution-based algorithms (population-based), exploring a larger portion of the search space compared to single-solution-based ones that modify and improve a single candidate solution, so the global optimum can probably be found more easily. Multi-solution-based algorithms like GOA intrinsically have higher local optima avoidance, due to their improving multiple solutions during optimization. Also, information about the search space can be exchanged between multiple solutions, which results in quick movement towards the optimum. In this regard, the feasibility of Fuzzy-GMDH-GOA in TDS prediction was explored in the present research.
- (2)
GOA as the standard algorithm is applied to the optimized model’s parameters to validate the capability and reliability of the Fuzzy-GMDH-GOA model. In addition, some standalone AI models such as ANN, ELM, ANFIS, and GMDH have been considered as benchmarks to evaluate the feasibility of the hybrid fuzzy-based AI model in the prediction of TDS at a monthly scale.
- (3)
For further assessment, to compare the results of expected and observation event data, an external validation was performed. Besides, a sensitivity analysis was performed to identify the most influential parameters linked to TDS variations in the Tajan river basin.
The structure of the paper is laid out as follows. In
Section 2, the functionality of ANN, ELM, ANFIS, and GMDH as the AI models, and PSO and GOA as the metaheuristic algorithms, are briefly introduced. In addition, the combination frameworks of the NF-GMDH-GOA/PSO predictive models are explained, along with study area description. The prediction performance of those hybrid and standalone models for TDS prediction of stations in monthly scale is described in
Section 3.
Section 4 concludes with a summary of the findings and a discussion of the study limitations.
2. Materials and Methods
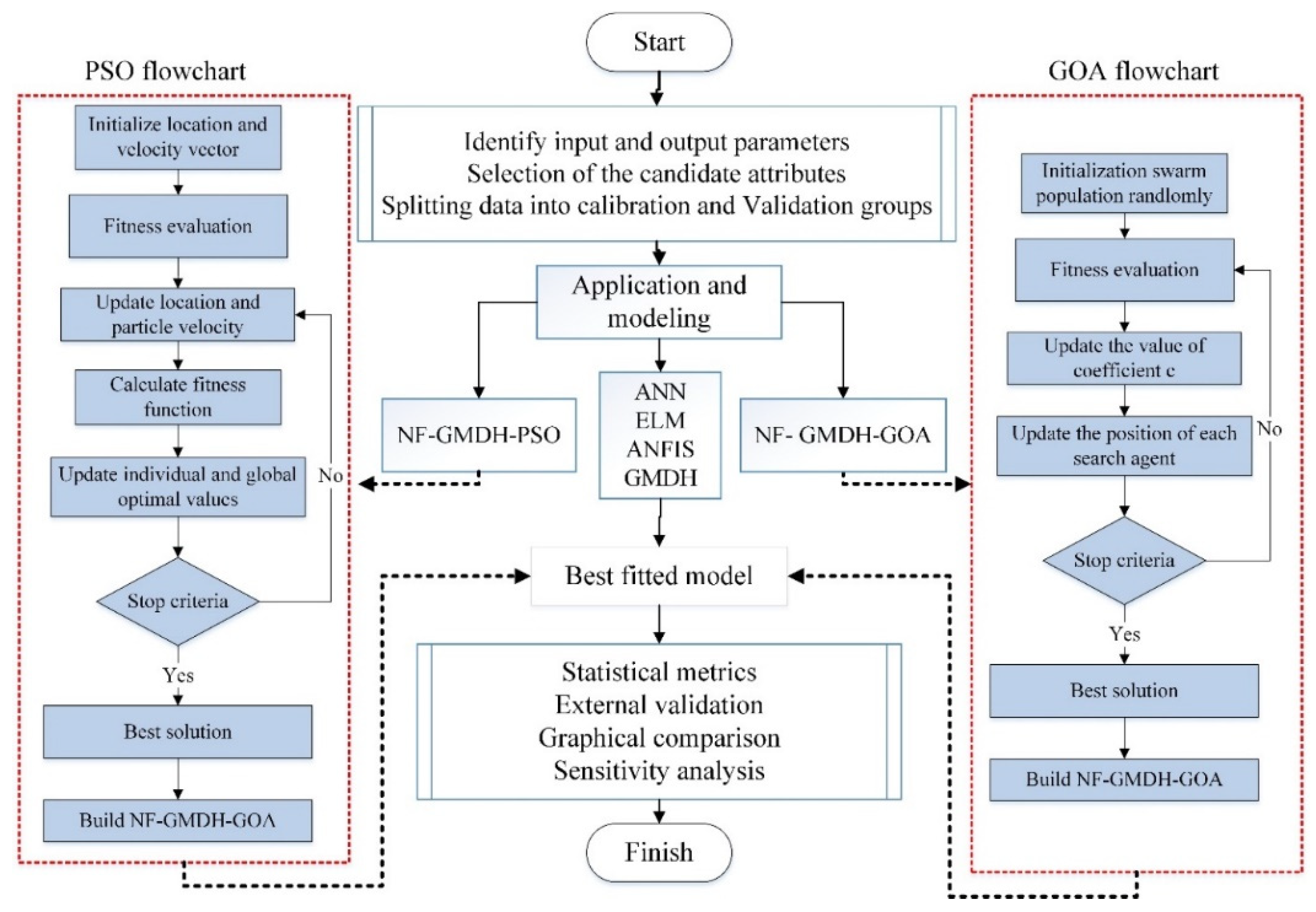
In the present research, various AI techniques like ANN, ELM, ANFIS, GMDH, and hybridized NF-GMDH with HOA/PSO algorithms for modeling of the monthly TDS at two stations were implemented. In this subsection the development of those standalone and hybrid AI models is described in detail. In addition,
Figure 1 shows the implementation steps of the workflow of the present research.
2.1. Artificial Neural Network (ANN)
Artificial neural networks (ANNs) are intelligent models derived from biological structures in the brain [
37]. ANN models are based on how the neural systems in the human body interact with each other and have a parallel processing architecture. In such a network, nodes (neurons) are connected with links, and layers are structured as nodes and links. Each link is given a specific weight, which can be considered a numerical representation of its strength. The summation value of input weights is transformed into a target using a transfer function, which is typically a sigmoid function. As an example,
y can be expressed as follows for the second layer
j [
38]:
In this equation,
represents the
ith output for the previous layer,
represents the weights among layers one and two, and
represents the bias of the node
j. A nonlinear activation function was used to estimate
y, and afterward an output function
f(y) was calculated from each node in layers two and three [
39].
2.2. Extreme Learning Machine (ELM)
Huang et al. [
40] proposed an algorithm, known as Extreme Learning Machine (ELM), that defines hidden nodes’ weights. Model structure selection and model training could be done faster using this approach. In addition, the method is easy to implement since it is relatively simple and straightforward [
41]. The
i-th output of a network at time
t with
p input variables,
q hidden nodes, and
c targets can be calculated as follows:
In this equation,
represents the hidden node vector output related to suggested input pattern
by a data set
and
, denotes weight vector that makes links between hidden nodes and the
i-th output node. Consider Vector
h(
t) as:
In this equation
represents a sigmoidal activation function,
represents the weight vector for the
l-th hidden node, and b
l indicates the bias for the
l-th hidden node. Weight vectors w
l can be calculated from uniform distributions or random samples from normal distributions. Furthermore,
is a matrix with a dimension of
where the
t-th column represents the output vector of the hidden layer,
,
is a matrix with a dimension of
where the
t-th column represents the target or desired vector
associated with the input pattern
, and
is a matrix with a dimension of
, where the
i-th column represents the weight vector
. Linear mapping is related to these matrices:
In this equation, both
D and
H are known and received from data, while
M is determined by applying the Moore–Penrose pseudo-inverse method, as below.
Based on the assumption that the number of output nodes and classes are equal, it is possible to determine the class index
i* related to a new input pattern applying the following decision rule:
where
is determined by Equation (5) [
42,
43].
2.3. Adaptive Neuro-Fuzzy Inference System (ANFIS)
ANFIS is a sub-branch of ANN that combines fuzzy logic principles with neural networks. The ANFIS model was developed by Jang [
44] for solving nonlinear functions, predicting chaotic time series, and identifying nonlinear components. By applying the Fuzzy IF–THEN rules of the Takagi–Sugeno fuzzy inference system, ANFIS can build an input-target mapping. ANFIS is popular with engineers because of its fast learning and adaptability characteristics, as well as its capability to capture the nonlinear formation of processes [
7,
45].
An integral part of ANFIS is the Fuzzy Inference System (FIS). The first layer is fed with inputs and then membership functions (MFs) return fuzzy values. The rule base consists of two sets of Fuzzy IF–THEN rules, which are both Sugeno and Takagi types:
All nodes in this layer are selected as adaptive nodes by node functions,
where
represents the membership function related to
, while
represents a linguistic label. Since Gaussian functions are highly capable of regressing nonlinear datasets, they are frequently used in ANFIS models. According to Equation (8), a value for a Gaussian membership type function ranging from zero to one can be obtained:
In this equation, represents the input and {} are considered as the parameters set. Upon entering the second layer, signals are multiplied, and outputs are sent to the subsequent layer. In the third or rule layer, the value for the th node indicates the strength of the rule in relation to other nodes.
Defuzzification is the fourth layer that builds functions for each node. Using the summation of the signals from the previous layer, the last layer calculates the overall output. In order to compute the errors in a model, a threshold limit is considered between the output of the model and actual real values during the training process. As a result of errors greater than the threshold, a gradient descent algorithm is used to update the premise parameters. This process continues until the parameters with error remain below the threshold calculated by two algorithms of least squares or gradient descent [
38,
46,
47].
2.4. Group Method of Data Handling (GMDH)
The first GMDH algorithm was developed by Ivakhnenko. The GMDH is organized in accordance with self-organizing systems. In this model, partial descriptions (PDs) are generated as quadratic polynomials in each node to select the best values for filtering. Additionally, the GMDH uses a tree-like structure to solve highly complex problems as well as to compute the error criteria that should be used as the termination criteria during the training procedure [
48,
49].
To find an accurate solution to system identification problems, the function
can replace the actual function
f. As a result, the final output of a complicated system,
, is predicted near observation
y for a given model input considered as
. If there is more than one variable in observations, an output variable can be obtained thus:
Therefore, the GMDH model is capable of predicting the final output,
, given
as input vector. In order to find a correlation between the inputs and the output, it is possible to consider the following function:
In the following equation, the error values resulting from observations and predictions are determined:
In the GMDH model, independent and dependent relationships are expressed as follows:
Additionally, Equation (12) is referred to as the Kolmogorov–Gabor polynomial. Unlike other kinds of polynomials, quadratic polynomials offer a relatively low error, since their weighting coefficients are calculated by the least squares method. Thus, for each pair of input variables
and
, the calculated error value between predictions,
, and actual values,
, should be minimized. In addition, a number of nodes in each layer are also eliminated with the least-squares method by using this function, which calculates quadratic polynomial performance,
. The following is the definition of this function:
Creating the regression quadratic polynomial takes into account all possibilities that might exist for two different independent variables. The weighting coefficients are therefore derived using the least squares method. As a general rule, the number of nodes in all layers is calculated by
, where
is the number of inputs in the prior layer. However, the PDs can be generated in the first layer for different pairs of
from observation
. As a result,
triples
could be built from n observations applying
as input–output systems.
M matrix can be obtained thus [
27]:
Here, the set of quadratic polynomials’ weighting coefficients is
, and
is the output vector. Consequently, the mathematical matrix equation can be defined by
AW =
Y. As a result, by combining the two inputs, the final matrix can be expressed as:
The coefficients vector of
can be obtained by applying the least-squares method [
50,
51].
2.5. Particle Swarm Optimization (PSO)
In PSO, which is an evolutionary algorithm, an answer to a problem is iteratively optimized to find the best solution. To create a new population, PSO shifts the population positions in every iteration. In addition to affecting individuals’ trajectory, shifting tasks also have an impact on their neighbors’ trajectory. In the search space, the vector x
i represents the position for a particle. This vector represents a possible particle or solution, whose dimension is determined by the number of existing parameters. The parameters, x
i0 and v
i0, indicate randomly chosen numbers associated with the position and velocity at iteration 0, related to particle i, respectively. Afterward, the vectors of particles are updated according to the fitness function. According to Equations (16) and (17), the vectors are updated [
52,
53]:
Factors affecting velocity include:
First, the value of velocity from the prior iteration multiplied by the inertia weight constant, ,
Second, the difference between the particle’s current position and the best global position , which is also known as social learning, and
Third, the difference between the particle’s current position and the local best particle’s position up to this point, , which is also known as cognitive learning.
The second and third factors are influenced by equations
,
. In these equations, r
x represents a real randomly selected number of a uniformly distributed function between [0,1], and c
x represents a constant value for x = 1,2. The particles cover the entire search space in the first iteration. With the increase in the number of iterations, the search space decreases. Therefore, PSO analyzes plausible zones first and ultimately improves its best solution. Over the years, there have been several versions of PSO in the literature. In this study, the standard version of PSO proposed in 2011 with the subsequent parameters was chosen:
Swarm topology determines how particles communicate with each other on a global scale by defining their connectivity and how they exchange information with each other. Communication between particles usually involves three (k) random particles [
30].
2.6. Grasshopper Optimization Algorithm (GOA)
A grasshopper swarm algorithm, developed by Saremi et al. [
54], simulates natural grasshopper swarm behavior and is used in many different engineering fields. Adult grasshoppers and nymphs (larvae) both engage in swarming behavior. The swarm behavior of grasshoppers has two key characteristics: first, exploration and exploitation to find food sources; and second, the movement of grasshoppers, including the slow movement of larvae and the long, abrupt movements of adults. The search agents tend to move abruptly during exploration, although their behavior develops local movement during exploitation [
55,
56].
It is the adults’ responsibility to explore the entire search space and discover suitable food sources (exploration), while the nymphs work at exploiting a specific region or neighborhood in a particular position (exploitation) [
54]. Through this algorithm, exploration and exploitation phases are smoothly balanced and mathematically incorporated into a less complex algorithm structure. According to this algorithm, the following steps are taken [
12]:
Step 1: First, for GOA, a population of size
Sc is generated by applying Equation (19).
where
Sc indicates the population size and
N represents the problem’s dimension. Moreover,
lj and
uj are the lower and upper limits for the
jth variable.
Step 2: Based on the fitness value, the best position can be determined in this step.
In this equation f(xj) is the fitness function, which in this article is the Mean Square Error (MSE).
Step 3: The exploitation and exploration parameters of the GOA are balanced with the
c parameter, which can change over time, depending on the number of iterations (
iter). The
c parameter is calculated by:
In this equation, MI is the maximum value of the cycle number.
Step 4: By applying Equation (22), the new positions can be obtained.
where
is:
In these equations, f represents the attraction intensity, Td indicates the best discovered solution, and l represents the attraction length. According to Equation (22), the normalized distance between the best discovered solution and the real search space position can be determined. The better position is saved after evaluating the newfound position with Equation (21). It should be noted that Equation (22) is modified by changing the c parameter, resulting in later iterations focusing on exploration and earlier iterations focusing on exploitation. Algorithm accuracy is improved by using this tuning procedure.
Step 5: In the final step, the algorithm is repeated considering a counter known as the iteration counter (iter).
Step 6: The optimization is complete when the number of iterations (iter) gets to the maximum loop number (MI).
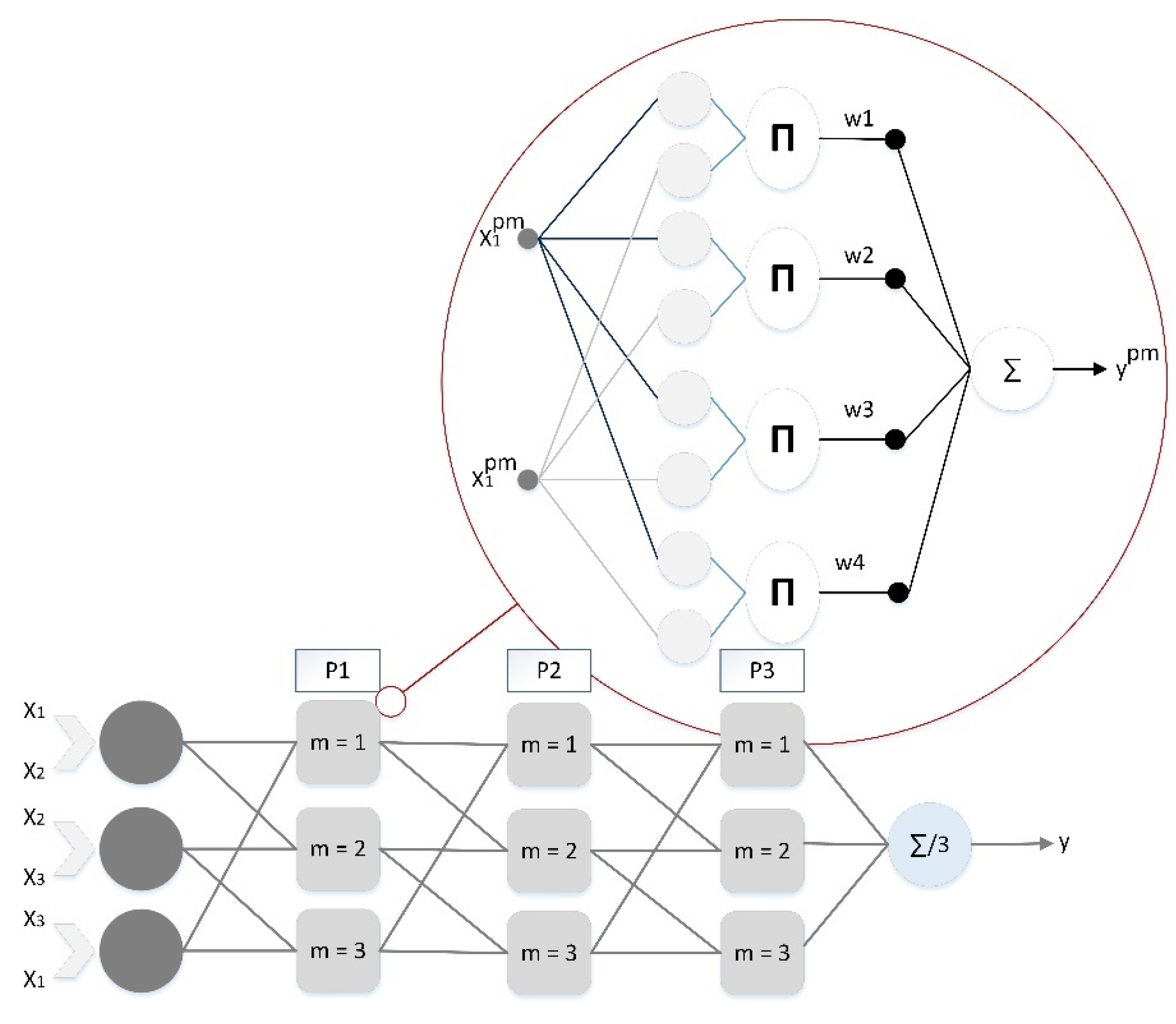
2.7. Development of an Adaptive Fuzzy-GMDH Using PSO/GOA
Ivakhnenko created the GMDH neural network, which is a type of self-organizing model that can perform a variety of processes. An integration of input parameters, based on the complex theorem of Ivakhnenko, is introduced in the first operation to build PDs or polynomial neurons [
57]. The seeds selection is done in the second operation regarding error criteria, depending on the filtering process in each layer. Moreover, this is done using the means of evolutionary computing methods, which, combined with parallel mechanisms, leads to the enhancement of the optimal NF-GMDH structure. As a matter of significant importance, NF-GMDH model is flexible enough to be effectively applied as a conjunction model by other evolutionary and iterative algorithms [
27].
A review of the literature showed that the Gaussian membership function,
, has been extensively used for building neural-Fuzzy systems due to producing more accurate results in the NF-GMDH model. Indeed, the number (
) of Fuzzy rules is introduced by
which is applied in the bound of the
th input vector (
):
where actual values of
and
indicate the constant coefficients of the Gaussian membership function called the Fuzzy rule. Moreover, output vector,
, is computed as the result of a neural-Fuzzy network using Equation (25):
where
and
are the observed values for
th Fuzzy rules. Each PD or neuron has mainly one output and two inputs through the NF-GMDH model. As seen in
Figure 2, the input vector in the next layer is the output vector for each PD in the current layer. The average of outputs in the last layer gives the final output of the NF-GMDH method. The inputs from the
th layer and the
th neuron in the
layer are considered as the output of the
th and
th PDs which create input vector in the
th layer
th PD. The mathematical relationship between
,
and
is obtained from Equation (26):
where
is a mathematical expression to compute the
th Gaussian function. Finally, the NF-GMDH network output is as below:
The trial–error process computes the weighted coefficients and Gaussian functions [
57,
58].
In the hybrid NF-GMDH model, associated parameters in partial descriptions act as a form of Gaussian function. Fuzzy MFs parameters need to be tuned using a back-propagation algorithm. This conventional trainer has a vital problem wherein this algorithm cannot find which PD or link desires to be excluded; hence, the network structure has some needless PDs and links. For tuning and optimization of Fuzzy MFs parameters, as well as attaining optimal weighting coefficients related to PDs in GMDH over the NF-GMDH model’s complex topology, an effective and robust algorithm is essential. In the present study, the GOA algorithm is applied due to its superiority in exploitation and exploration for seeking the best solution for complex problems. This novel approach has the potential to be simultaneously implemented for training network parameters and structural identification [
16,
57].
Adjustable variables in the GOA algorithm can control the best solution to provide minimum difference from the objective function. Equation (28) is the objective function of the optimization operation in the NF-GMDH based on GOA:
Table 1 shows the values of the GOA and PSO algorithms’ setting parameters. All weighting factors are determined after the model optimization. Consequently, NF-GMDH based on GOA and PSO gives the Gaussian functions.
2.8. Case Study Description
The Tajan River basin, as a river in Mazandaran, has a mostly humid or semi-humid climate. The annual rainfall, average river discharge, and area slope are 539 mm, 20 m
3/s, and 85%, respectively. The difference between minimum and maximum level of the Tajan basin is approximately 3700 m; 90% of the forest surface is covered by brown soil and the remainder is covered by widespread types such as alluvial soil [
6] Various agricultural, aquacultural, aquafarming, and industrial activities are implemented in this river basin. Moreover, different operations, including damming and sand mining, are done in the river, which affect the average amount of measured TDS. Due to the high rate of rainfall and the beginning of agricultural production, TDS monitoring is needed annually in the fall and winter [
23]. In the basin, there are nine active hydrometric gauging stations. For TDS modeling, data from the Soleyman Tange and Rig-Cheshme stations were collected as shown in
Figure 3.
The characteristics of the physiochemical parameters of the case study are shown in
Table 2. TDS reached its peaks at two suggested stations based on observations (Rig-Cheshmeh (1270) and Soleyman-Tangeh (650)). According to
Table 1, the standard deviation of TDS records was distributed over a wide range compared to input variables. Although there are various parameters which have a significant effect on TDS estimating, monthly magnesium (Mg), calcium (Ca), bicarbonate (HCO
3), and sodium (Na), which are provided from the Meteorological Organization of Mazandaran Province (MOMP) during March 1984–August 2016 and March 1974–August 2016 at Soleyman-Tangeh (390 monthly data record) and Rig-Cheshmeh (505 monthly data record) gauging stations, respectively, were used in the TDS modeling. In this regard, about 75% of the total dataset was used for training and the rest was set aside for testing the AI’s networks.
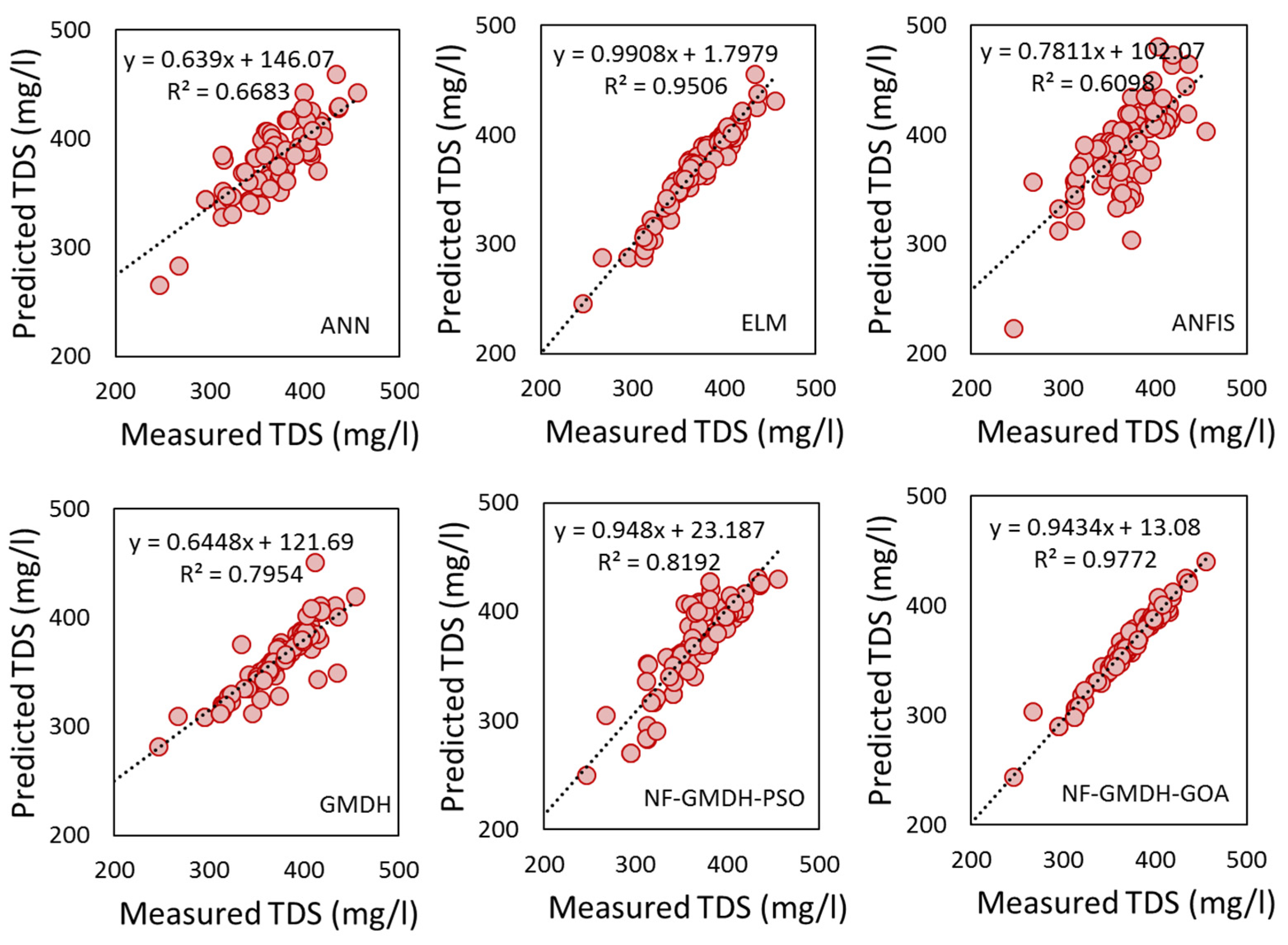
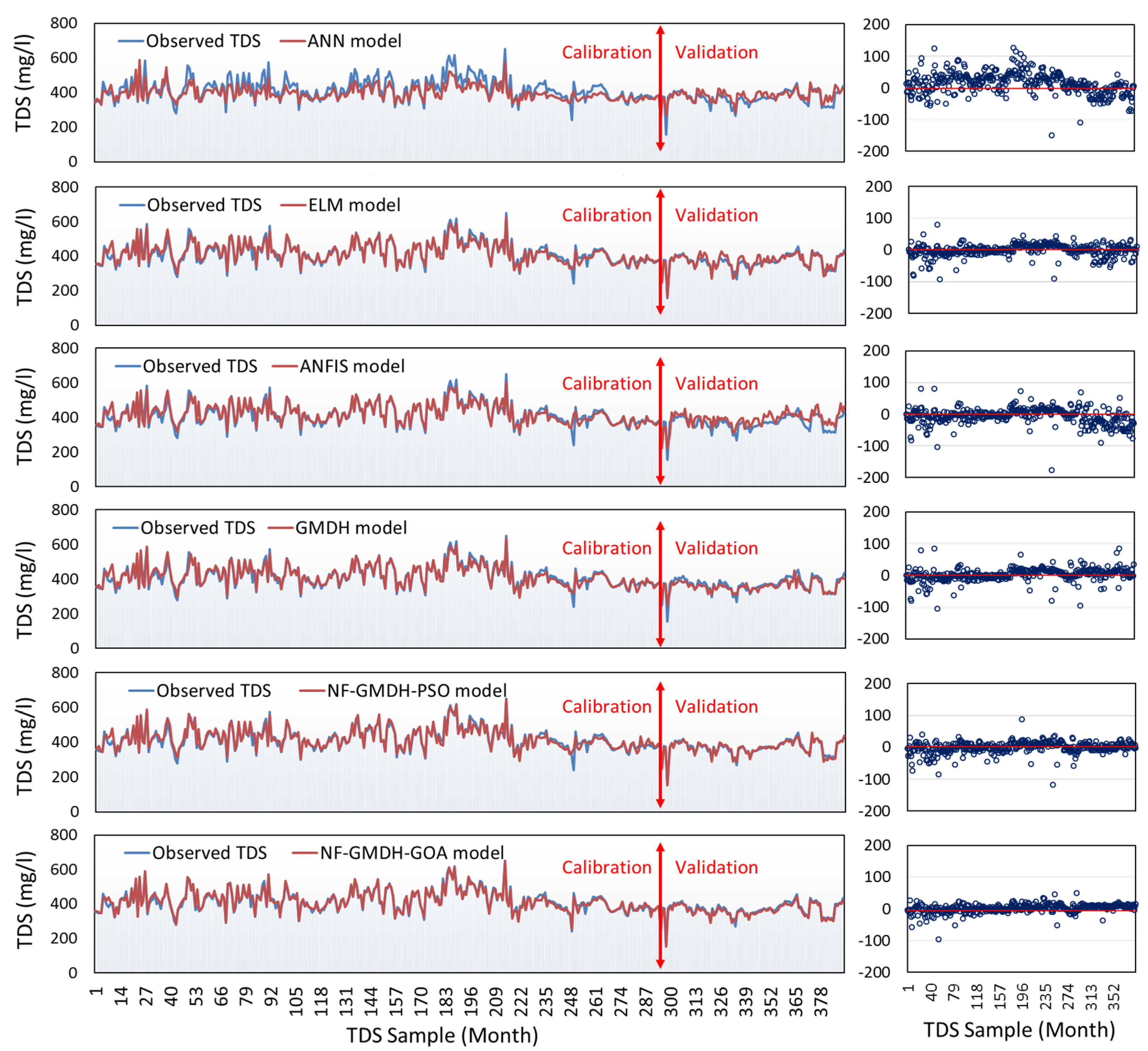
2.9. Model Performance Criteria
For assessing the model’s robustness, correlation coefficient (R), root mean square error (RMSE), Nash-Sutcliffe efficiency (NSE), and ratio of RMSE to standard deviation (RSD) were used,
In the above equations and represent the observations and predictions, respectively. and are the means of the observations and predictions, respectively. The R index was used for selecting suitable predictors for predicting the target variable. In addition, N stands for the total number of datasets. NSE evaluates the model’s output using a set of (−∞, 1) and an ideal value of unity. As a result, perfect fitting between observations and predictions has NSE equal to 1, and NSE with a negative value indicates that the model performs poorly in terms of the arithmetic mean of the models tested. With a range of (0 to +), RSD and RMSE are calculated, and an ideal value of zero indicates the model accuracy.
After model optimization, the testing dataset is used for the model validation. Validation measures are adopted in this study [
59]. For the projections based on observations, the gradients of the regression line through the origin (
k), or for the predictions via observations (
k′), at least one needs to be near to 1.
Additionally, the coefficient of determination for the regression lines through the origin
m′ and
n′ should be less than 0.1.
Moreover, the cross-validation coefficient
Rm should satisfy:
Between the observed and predicted values, the determination coefficients through the origin
and conversely (the estimated and observed values)
are calculated thus:
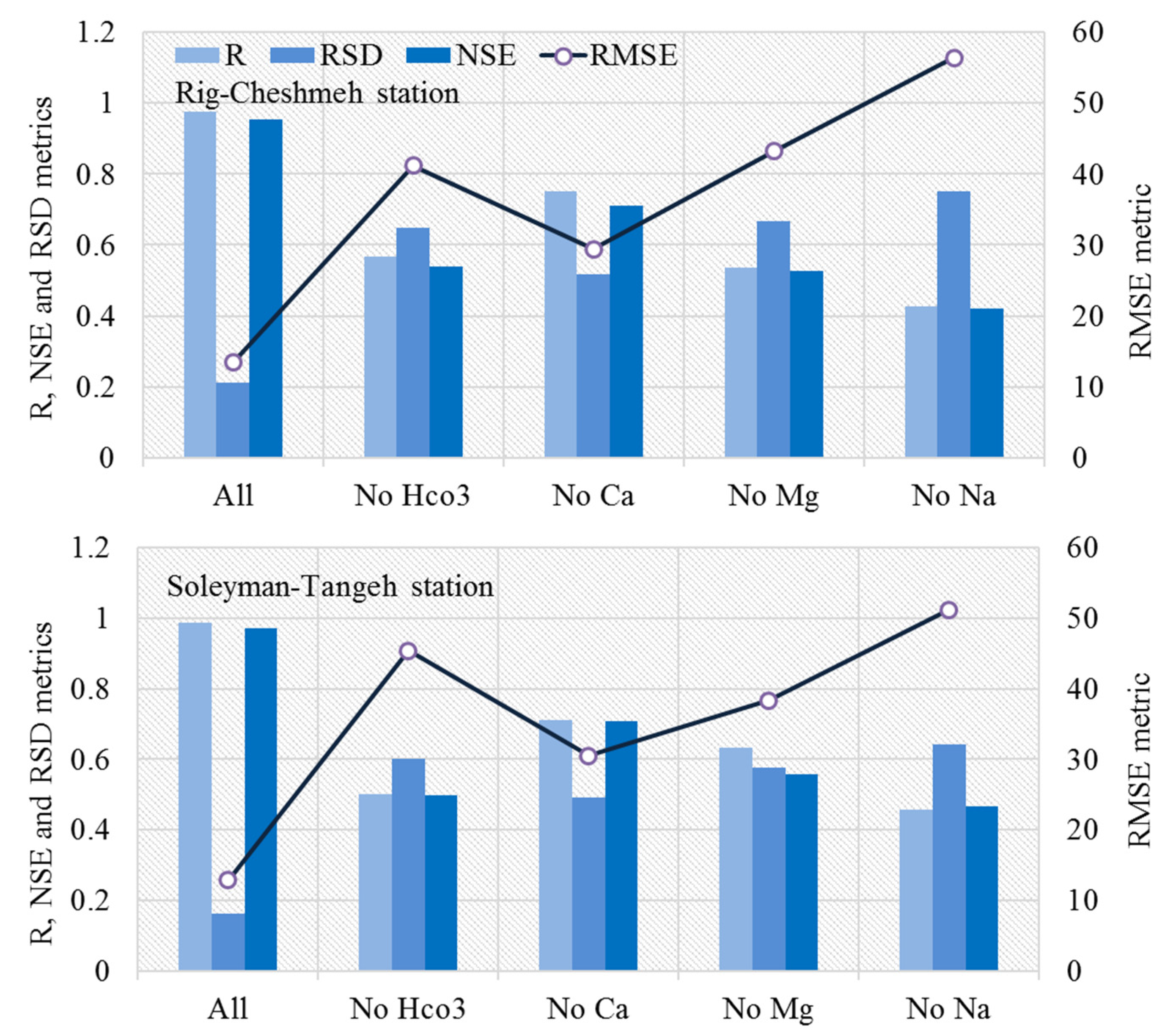
A sensitivity analysis may be used to assign the effect of input variables on TDS using the best suited model. In this study, one input variable parameter was eliminated at a time to assess the impact of that input on output. The following relationships are used to measure the percentage of sensitivity of each output variable to each input variable:
where
is the maximum and
is the minimum of the predicted output over the
ith input domain, whilst other variables have mean values.
4. Concluding Remarks
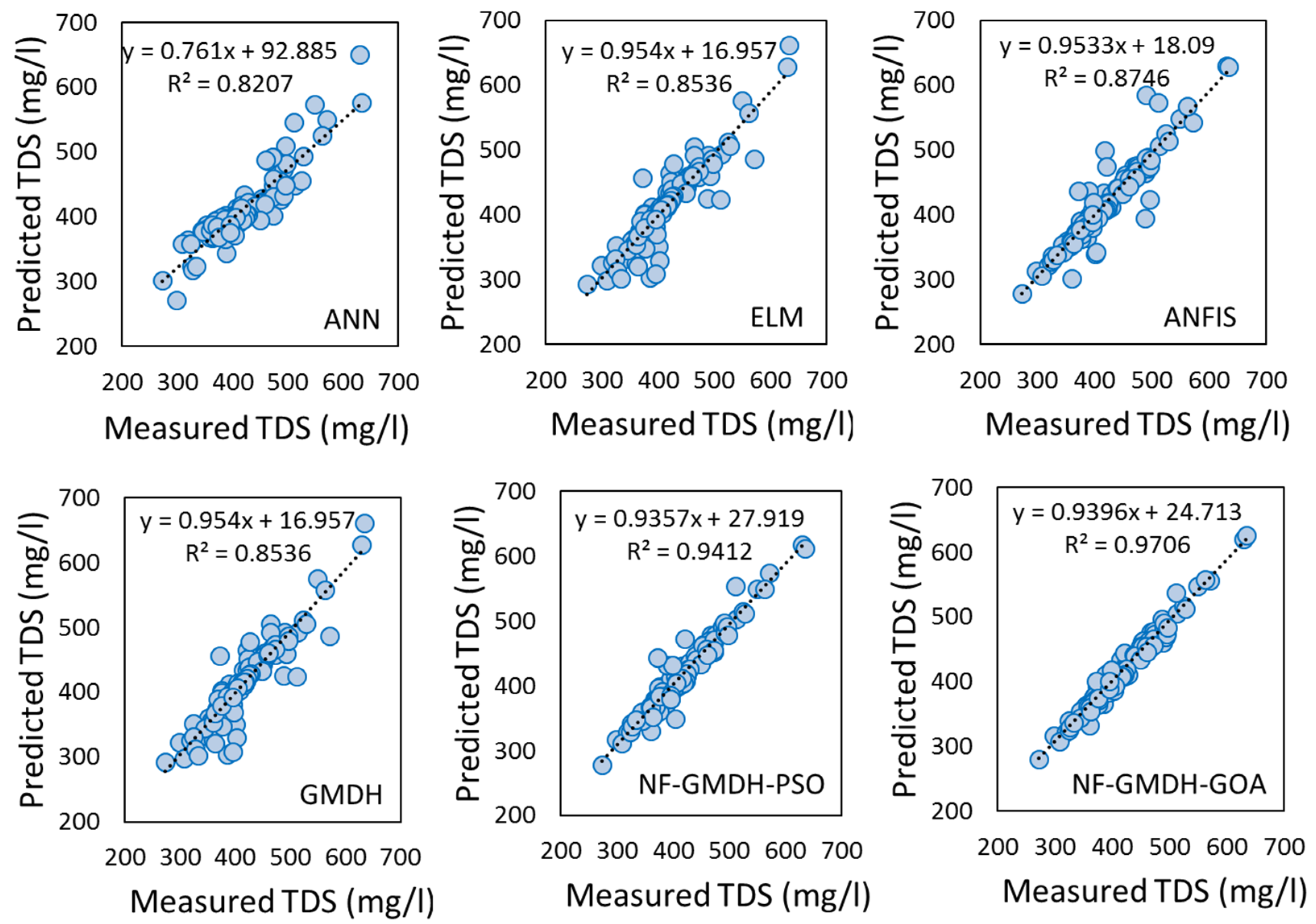
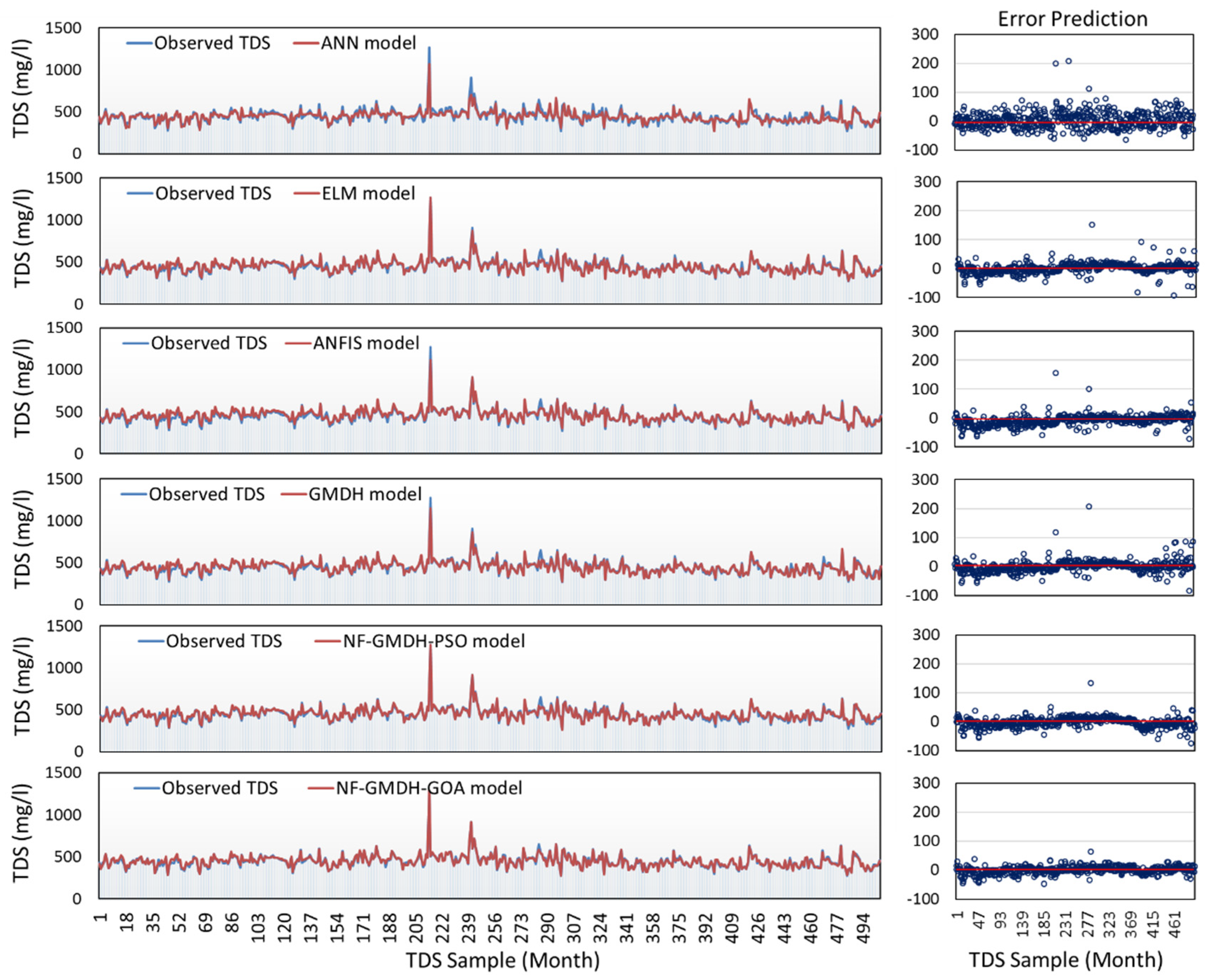
In this study, the capability of the neuro-fuzzy group method of data handling systems-based grasshopper optimization algorithm (NF-GMDH-GOA) was studied in forecasting monthly TDS at the Soleyman-Tangeh and Rig-Cheshmeh stations located in the Tajan River basin, Iran. The most significant parameters of water quality, such as Ca, Mg, Na, and HCO3, were included in the model. Comparing the results of the hybrid and standalone models showed that the grasshopper optimization algorithm has a major effect on the performance of NF-GMDH. At the Soleyman-Tangeh station, NF-GMDH-GOA could predict TDS with more accuracy in terms of NSE (0.948), RSD (0.223) and RMSE (9.687 mg/L) in comparison to other models at the validation stage. The accuracy of GMDH and NF-GMDH-GOA revealed that the coefficient of determination was raised from 0.892 to 0.989 for the Soleyman-Tangeh gauging station. For the Rig-Cheshmeh station, the outcomes showed that NF-GMDH-GOA showed the best performance in forecasting TDS in terms of RSD (0.174) and RMSE (10.744 mg/L). Furthermore, sensitivity analysis was utilized to determine the most significant parameters on the TDS modeling and fairy justification of the relative effectiveness of independent variables. The results of the sensitivity analysis demonstrated that Na was the effective factor on TDS values at two proposed stations.
In the same scale of the input/output parameters used in this study, as well as watershed physical characteristics, the presented methodology is recommended for optimization-based methods for different TDS assessments to study the generalization of the AI approaches. However, this kind of evaluation imposes a negative computational burden, and can be useful for large and complicated river systems modeling; dynamic and/or nonlinear AI programming, depending on the modeling approach, can be employed to seek the contributors to the TDS in the river system. Moreover, the presented methodology may help in providing the size of the training dataset to build an optimum approach to model water quality parameters. It could be better to train and validate the model’s capability with smaller scales of hydrological datasets, such as daily water quality parameters; this was the main limitation of the current study. Regarding influential input parameters: it should be noted that the findings of the current study are only based on the available dataset that could be collected from the relevant organizations. Based on the above-mentioned explanations, the area is potentially contaminated by various cations and anions from agricultural, aquacultural, aquafarming, industrial, and other activities like damming and sand mining, and there is a high potential for other major components of TDS, such as chloride, sulfates and potassium, to get into the river. Another limitation of the current study is related to the length of the prediction: it was not possible to provide a long-term prediction of TDS due to the accumulation of errors, and this reduced the accuracy of the prediction.
The scale of the training dataset has a high impact on the prediction accuracy for AI models. The prediction is improved by increasing the size of the training dataset, and this enables the model to predict TDS variations over time. The future of TDS modeling using soft computing techniques seems remarkable and bright with upgrading AI techniques, which provide novel and more intelligent algorithms. In addition, TDS prediction depends on the appropriate selection of water quality parameters. In this regard, it is suggested to use feature selection methods such as pointwise mutual information, mutual information, relief-based algorithms, and minimum-redundancy-maximum-relevance in order to improve the model’s capability.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}