
A Study on the Deployment of Mesoscale Chemical Hazard Area Monitoring Points by Combining Weighting and Fireworks Algorithms

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
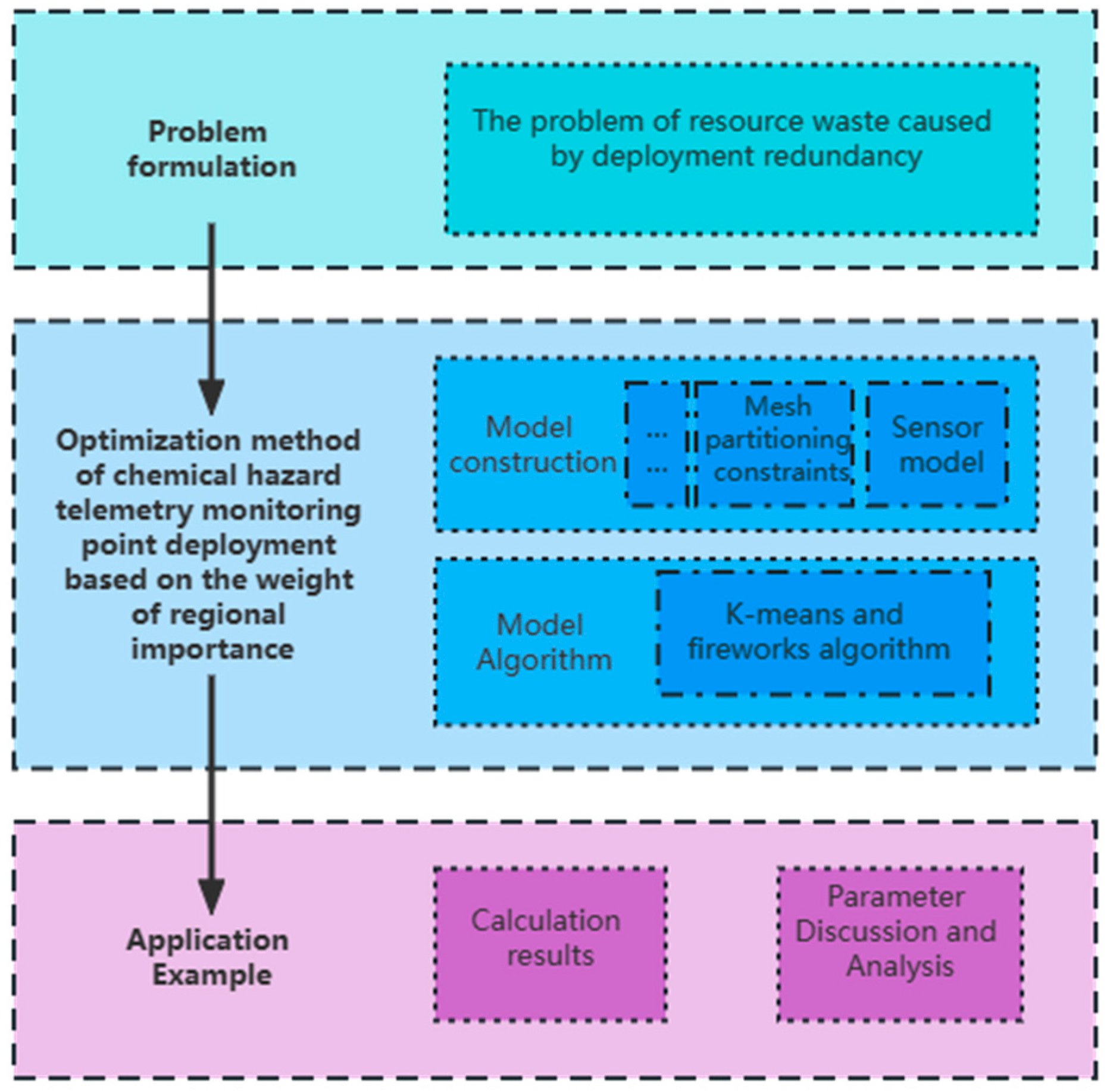
:1. Introduction
- A novel method for constructing a model for the deployment of mesoscale chemical hazard monitoring points considering weights is proposed to achieve the intensive monitoring of mesoscale chemical hazards through the correspondence between regional importance and coverage, which solves the problem of monitoring redundancy;
- Combined with the existing optimization methods and the characteristics of chemical hazard areas, the deployment optimization method of telemetry chemical monitoring equipment suitable for mesoscale gas diffusion monitoring and early warning is found, and the influence of each parameter on the model and algorithm is discussed;
- This method can be applied to other mesoscale monitoring models, and the solution algorithm for the deployment of mesoscale chemical hazard monitoring points can also be improved by combining with other heuristic algorithms.
2. Related Work
3. The Deployment Model for Mesoscale Chemical Hazard Area Monitoring Point Considering Weight
3.1. Sensing Model
3.2. Mesh Generation and Mesh Importance
3.3. Regional Importance and Coverage Threshold
3.4. The Definition of Chemical Hazard Monitoring Points Deployment Model Considering Weight
4. Model Solution Algorithms
4.1. k-Means Clustering Algorithm and Fireworks Algorithm
4.2. Middle-Scale Chemical Hazard Monitoring Point Model Solution Steps Considering Weights
5. Experiment Analysis
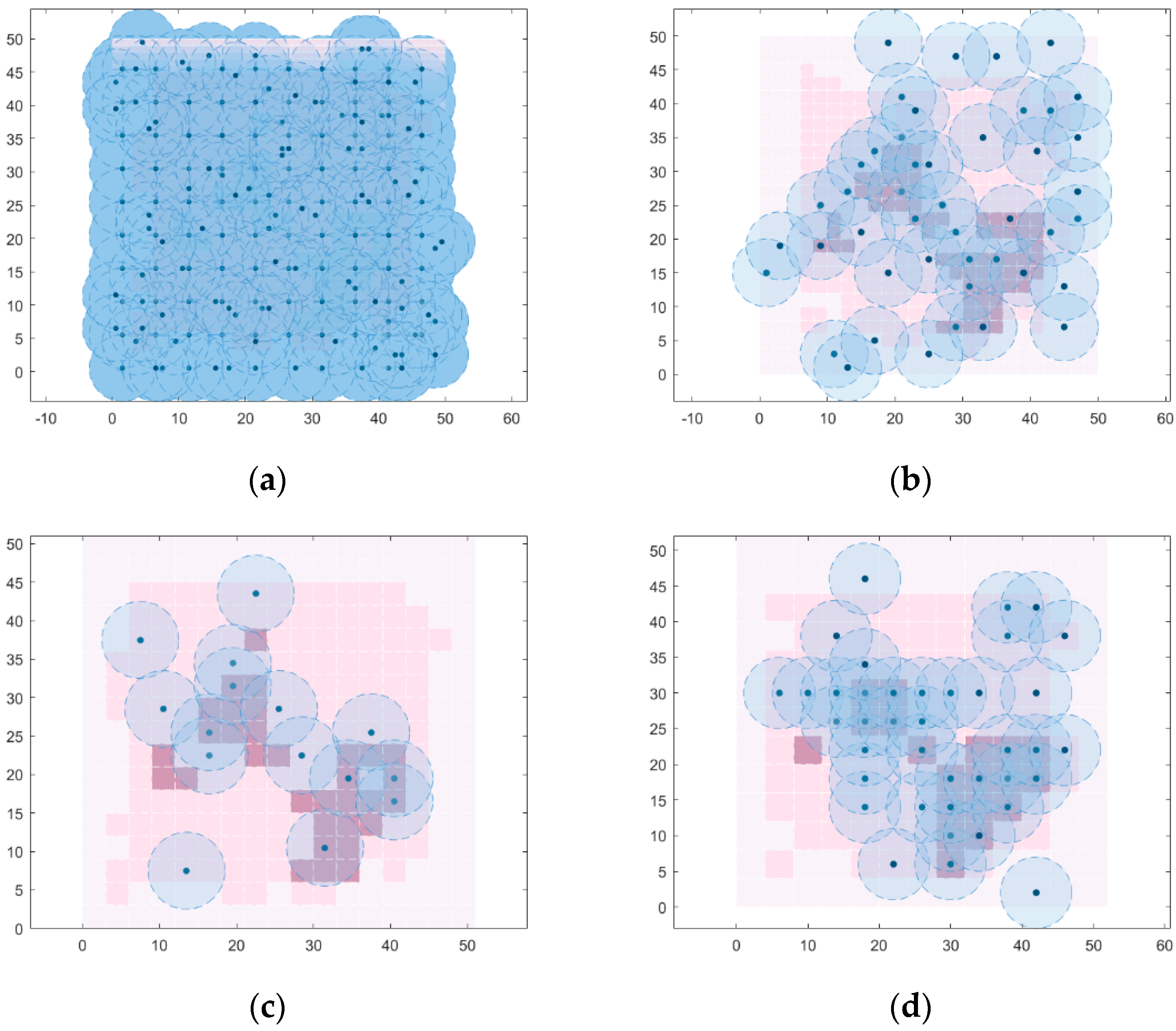
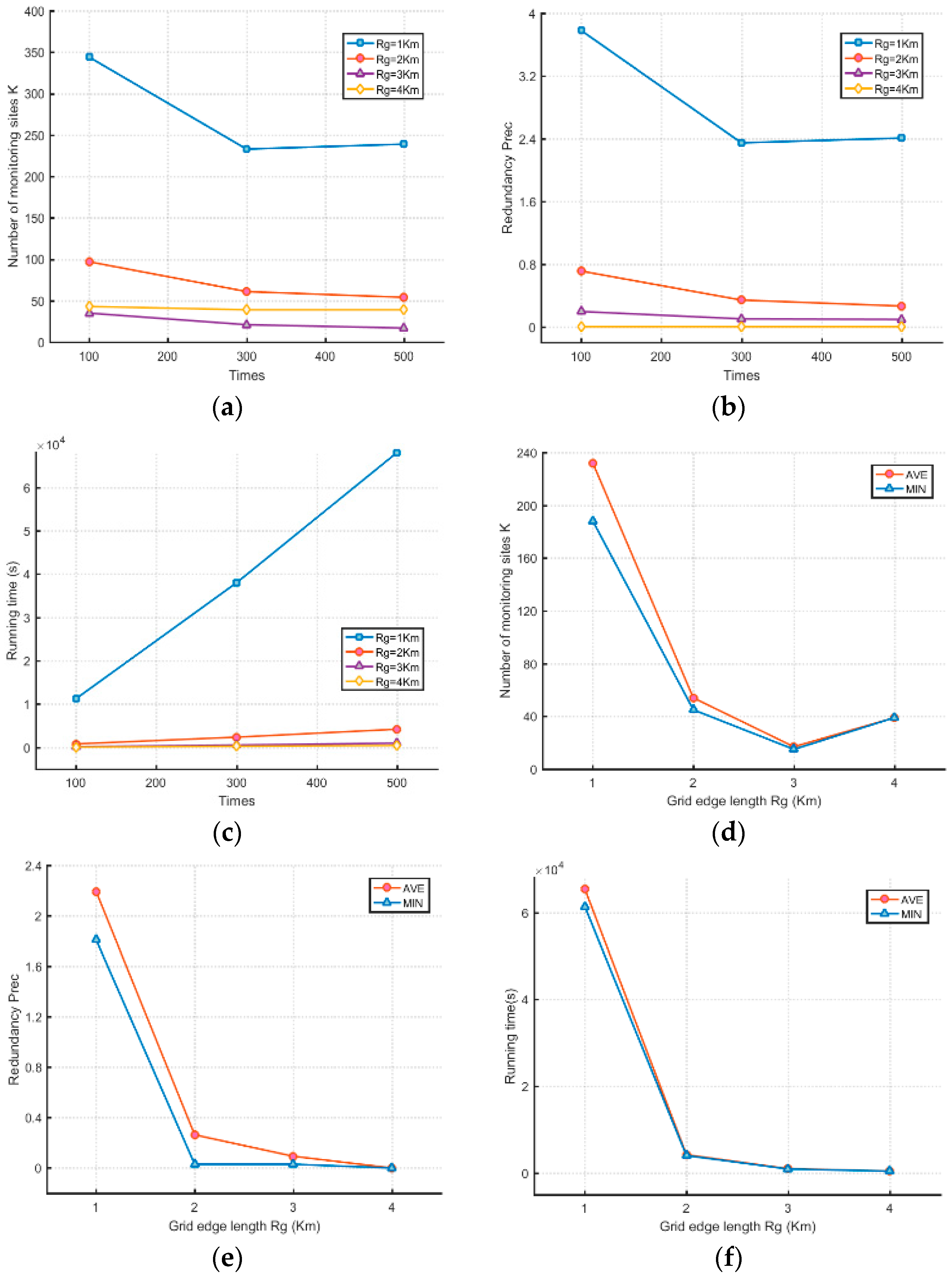
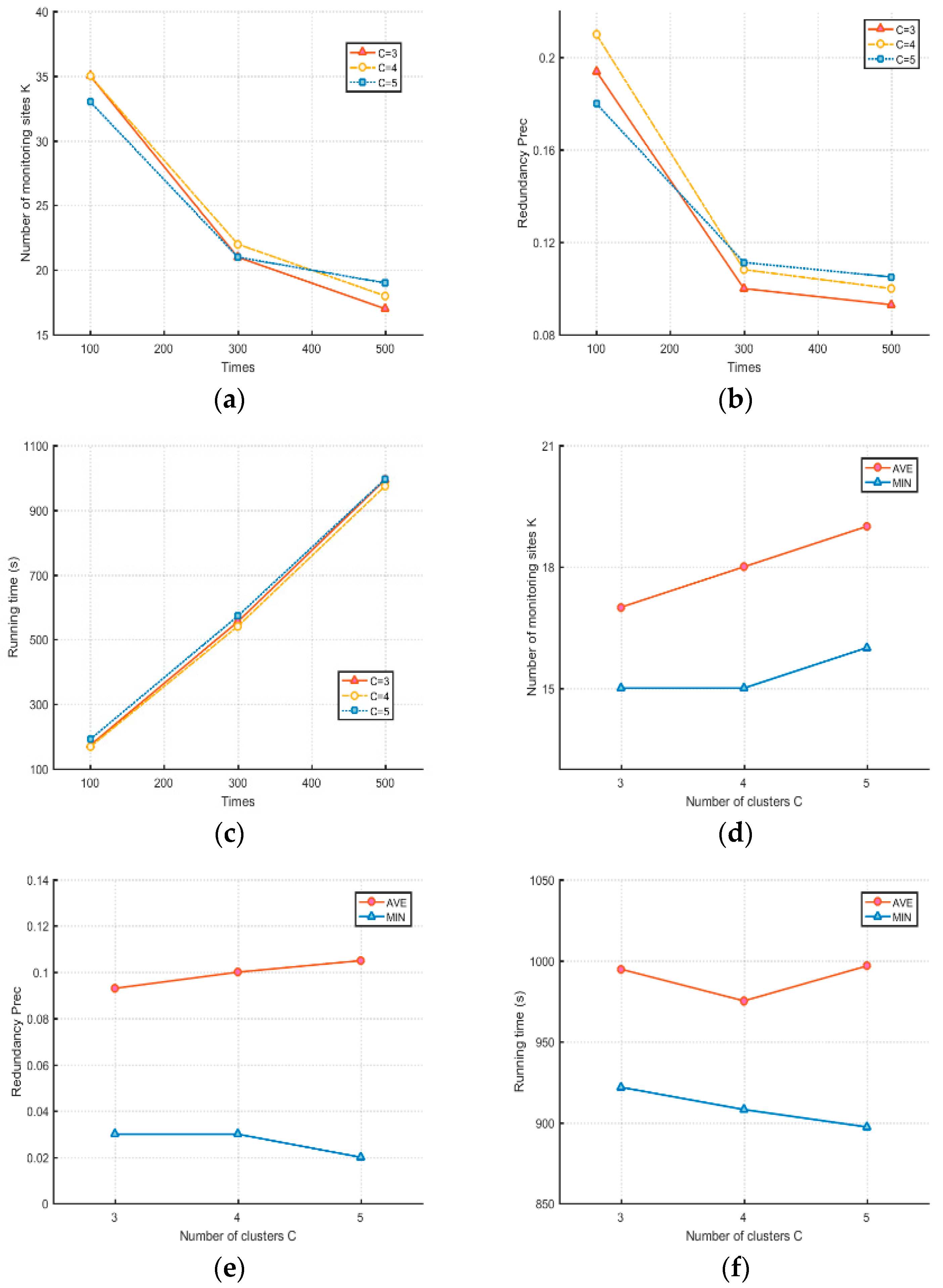
5.1. Effect of Grid Edge Length
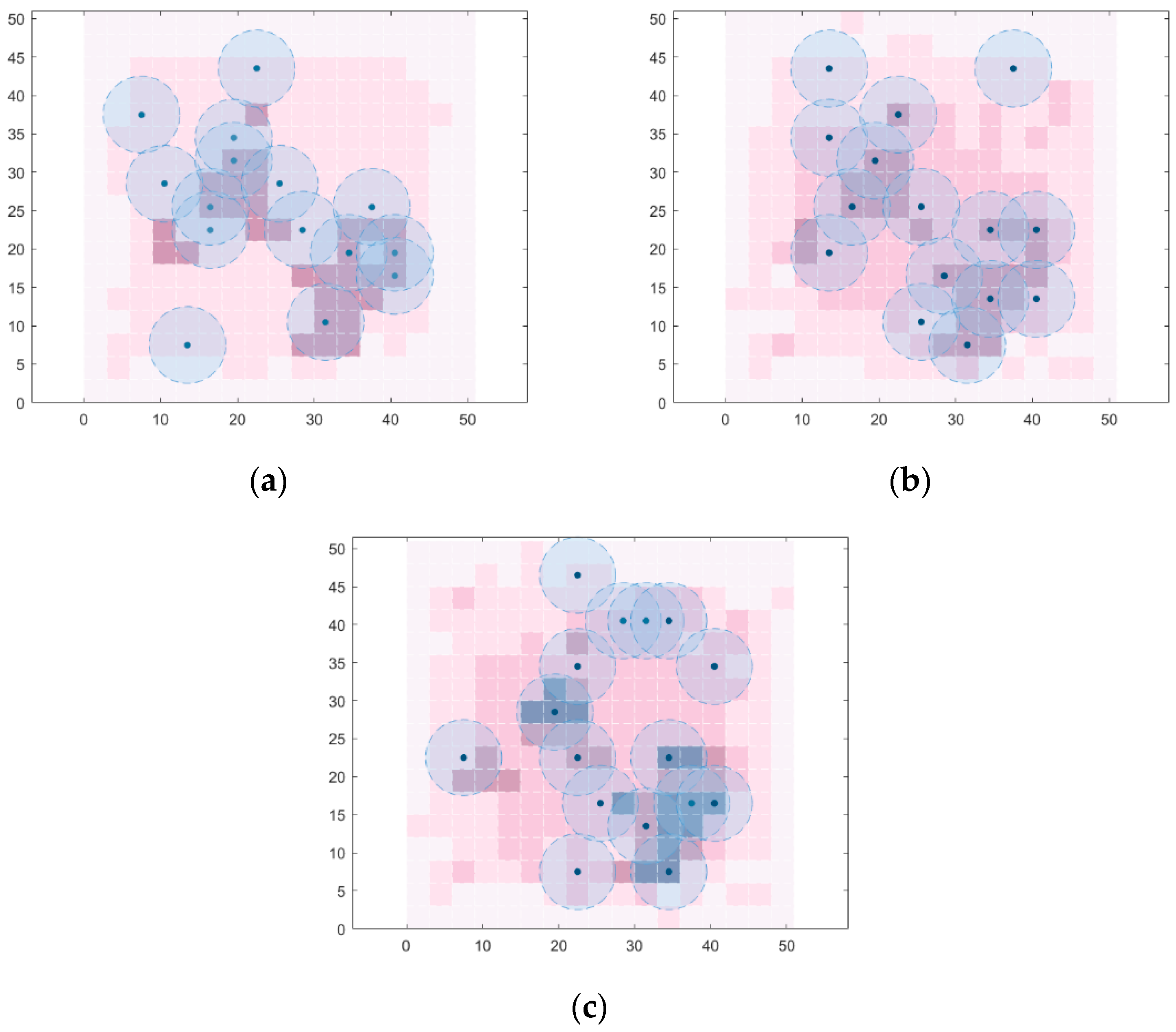
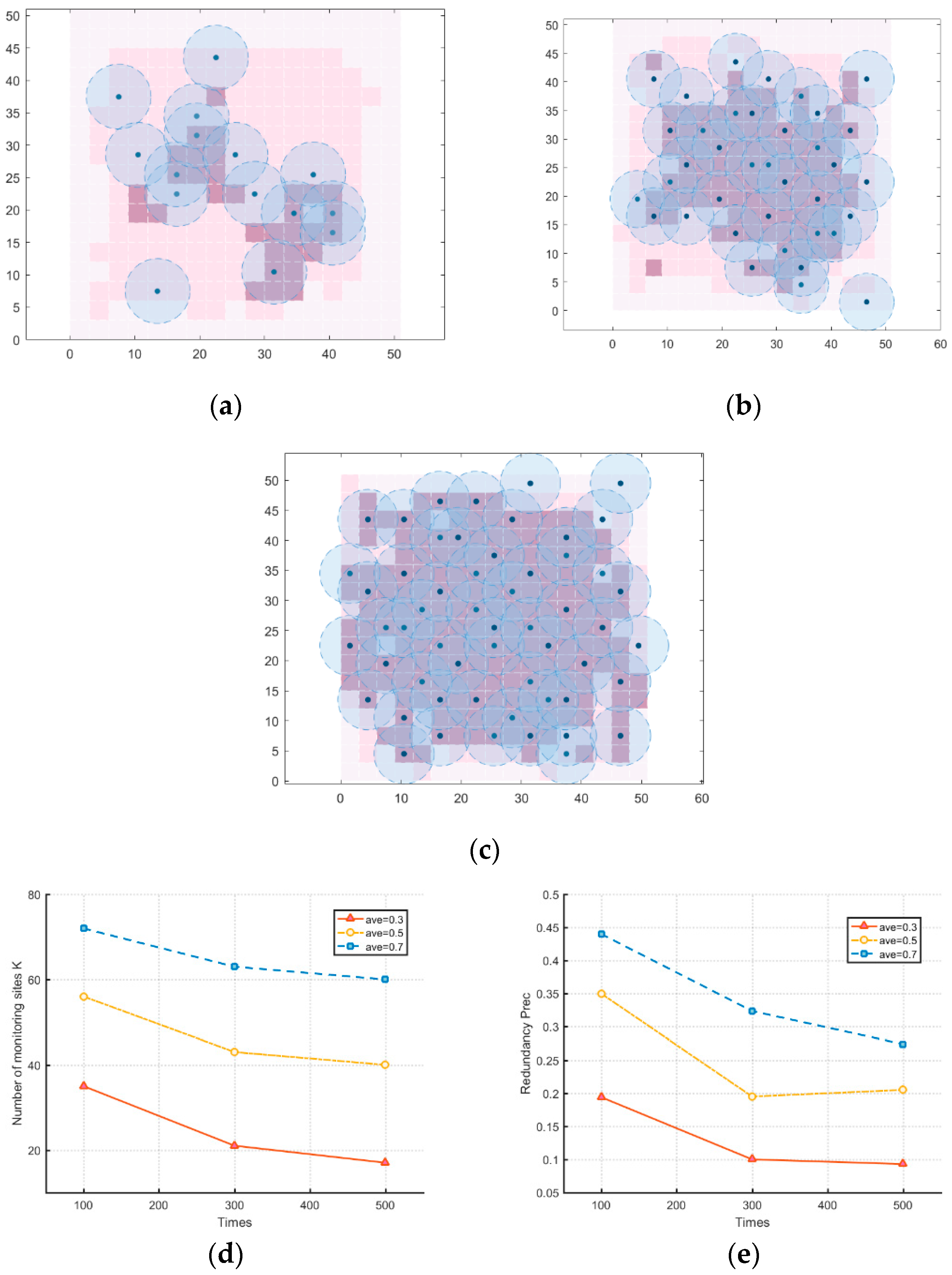
5.2. Effect of the Number of Bunches of Clustering
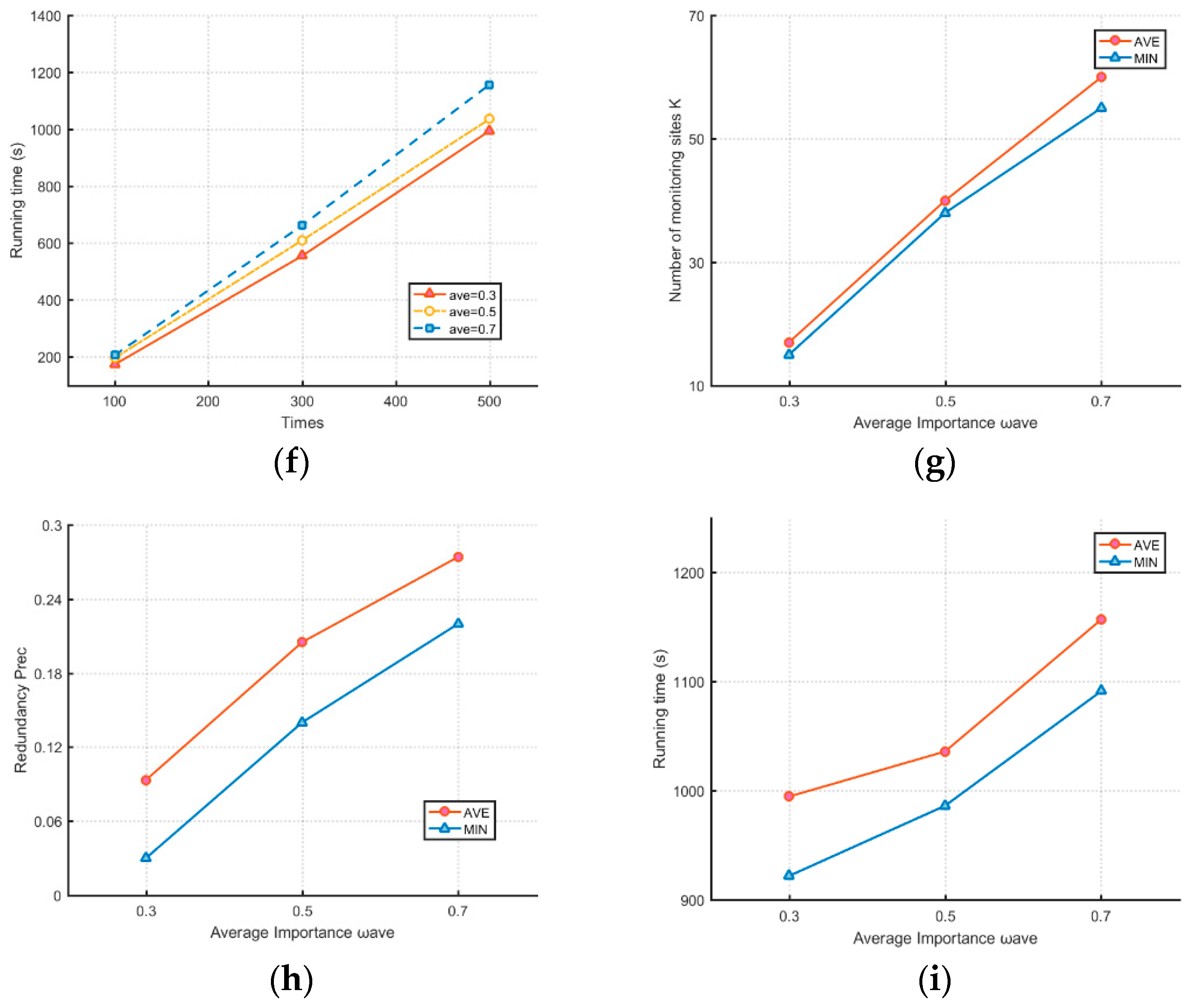
5.3. Effect of Average Importance of Monitoring Areas
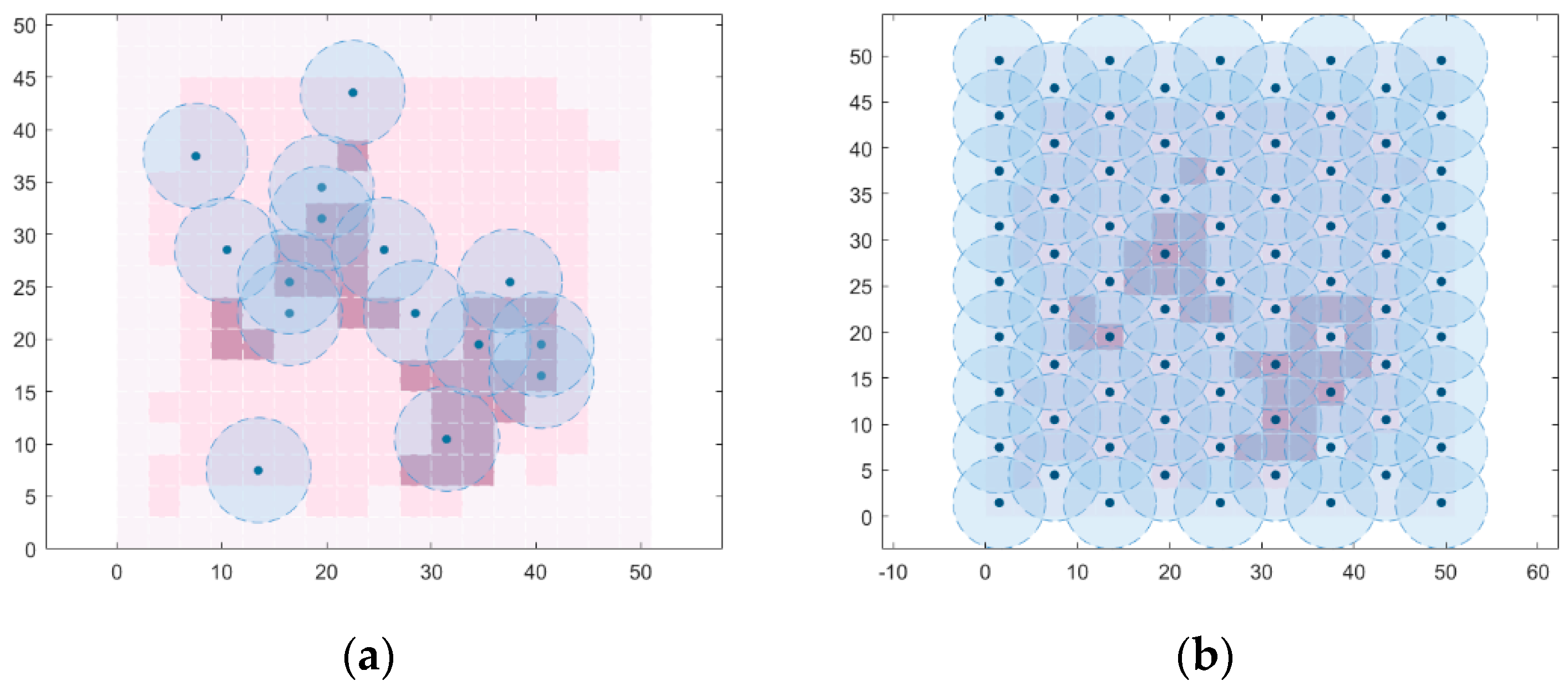
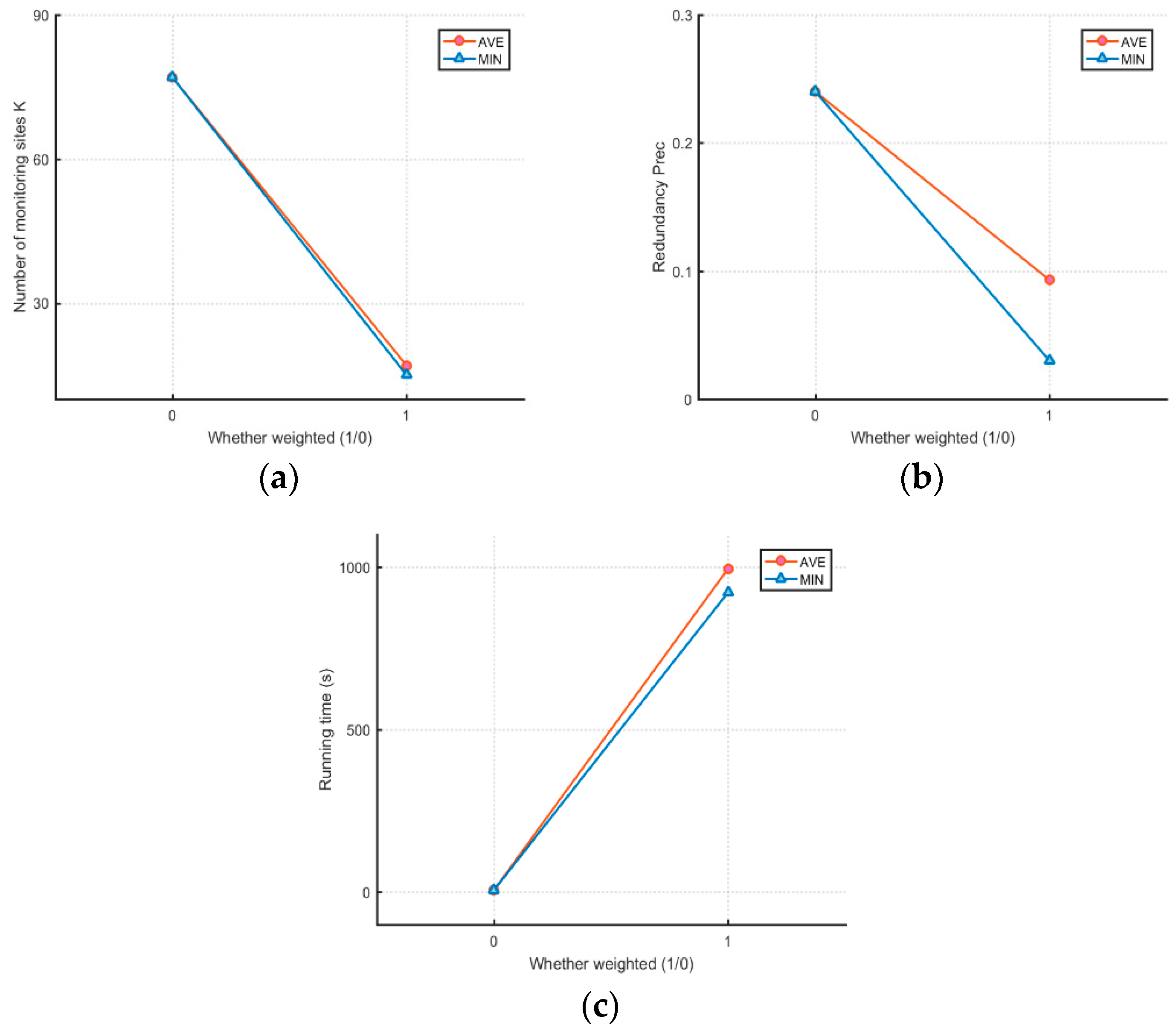
5.4. Effect of Weighted Coverage and Unweighted Coverage
6. Conclusions
- We can choose multiple heuristic algorithms to solve the model. In our research, we only rely on the fireworks algorithm to solve the model, and find a better algorithm to choose instead through the comparison and verification of multiple heuristic algorithms;
- We can improve the location optimization algorithm by combining it with other heuristics, such as simulated annealing, ant colony algorithm, and genetic algorithm;
- We can extend the research content to the optimization of the deployment of spatial monitoring points [55]. The location of sensors used to monitor the diffusion of chemically hazardous gases has only been studied in a two-dimensional planar area, and three-dimensional space with height has not been considered.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Amy, E.S.; Maureen, L. The destruction of weapons under the chemical weapons convention. Sci. Glob. Secur. 1996, 6, 79–100. [Google Scholar]
- OPCW by the Numbers. Available online: http://www.opcw.org/media-centre/opcw-numbers (accessed on 4 October 2019).
- Zhu, R.C. A Personalized and Practical Method for Analyzing the Risk of Chemical Terrorist Attacks. IEEE Access 2020, 8, 81711–81723. [Google Scholar] [CrossRef]
- Santos, C.; Zahran, T.E.; Weiland, J. Characterizing Chemical Terrorism Incidents Collected by the Global Terrorism Database, 1970–2015. Prehospital Disaster Med. 2019, 34, 385–392. [Google Scholar] [CrossRef] [PubMed]
- Pan, L.D. Characteristics of Chemical Accidents and Risk Assessment Method for Petrochemical Enterprises Based on Improved FBN. Sustainability 2022, 14, 12072. [Google Scholar] [CrossRef]
- Zhang, Y.P.; Niu, J.J.; Zhang, S.Q. Simulation Assessment of Hazardous Consequence of Poisonous Material Diffused into Atmosphere under Instantaneous Leakage and Windless Condition. Occup. Health Emerg. Rescue 2007, 25, 5–9. [Google Scholar]
- Johansson, L.; Karppinen, A.; Kurppa, A.; Kousa, A.; Niemi, J.-V.; Kukkonen, J. An operational urban air quality model ENFUSER, based on dispersion modelling and data assimilation. Environ. Model. Softw. 2022, 156, 105460. [Google Scholar] [CrossRef]
- Wang, S.; Lyu, F.; Wang, S.; Catlett, C.E.; Padmanabhan, A.; Soltani, K. Integrating CyberGIS and urban sensing for reproducible streaming analytics. In Urban Informatics; Springer: Singapore, 2021; pp. 663–681. [Google Scholar]
- Heitzler, M.; Lam, J.C.; Hackl, J.; Adey, B.T.; Hurni, L. GPU-accelerated rendering methods to visually analyze large-scale disaster simulation data. J. Geovis. Spat. Anal. 2017, 1, 1–18. [Google Scholar] [CrossRef]
- Huang, W. What were GIScience scholars interested in during the past decades? J. Geovis. Spat. Anal. 2022, 6, 1–21. [Google Scholar] [CrossRef]
- Wang, S.; Zhong, Y.; Wang, E. An integrated GIS platform architecture for spatiotemporal big data. Future Gener. Comput. Syst. 2019, 94, 160–172. [Google Scholar] [CrossRef]
- Chen, X.; Wang, S.; Li, H.; Lyu, F.; Liang, H.; Zhang, X.; Zhong, Y. Ndist2vec: Node with Landmark and New Distance to Vector Method for Predicting Shortest Path Distance along Road Networks. ISPRS Int. J. Geo-Inf. 2022, 11, 514. [Google Scholar] [CrossRef]
- Seo, J.K.; Kim, D.C.; Ha, Y.C.; Kim, B.J.; Paik, J.K. A methodology for determining efficient gas detector locations on offshore installations. Ships Offshore Struct. 2013, 8, 524–535. [Google Scholar] [CrossRef]
- Tassi, F.; Vaselli, O.; Cuccoli, F.; Buccianti, A.; Nisi, B.; Lognoli, E.; Montegrossi, G. A Geochemical Multi-Methodological Approach in Hazard Assessment of CO2-Rich Gas Emissions at Mt. Amiata Volcano (Tuscany, Central Italy). Water Air Soil Pollut. Focus 2009, 9, 117–127. [Google Scholar] [CrossRef]
- Prakhova, M.Y.; Khoroshavina, E.A.; Krasnov, A.N. Wireless Telemetry System for Gas Production. Lect. Notes Electr. Eng. 2020, 641, 9–16. [Google Scholar]
- Bernascolle, P.F.; Fervel, F.; Vallayer, B. CWA stand-off detection, a new figure-of-merit: The field surface scanning rate. In Chemical, Biological, Radiological, Nuclear, and Explosives (CBRNE) Sensing XIV; SPIE: Washington, DC, USA, 2013. [Google Scholar]
- Kim, J.; Nam, H.; Kim, H.J. Real-Time Measurement of Ammonia (NH3) in Artillery Smoke Using a Passive FT-IR Remote Sensor. ACS Omega 2019, 4, 16768–16773. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pacsial-Ong, E.J.; Aguilar, Z.P. Chemical warfare agent detection: A review of current trends and future perspective. Front. Biosci. 2013, 5, 516–543. [Google Scholar] [CrossRef] [PubMed]
- Majder-Lopatka, M.; Rogula-Kozlowska, W.; Wasik, W. The application of stand-off infrared detection to identify air pollutants. E3S Web Conf. 2018, 44, 104. [Google Scholar] [CrossRef] [Green Version]
- Jindal, M.K.; Mainuddin; Veerabuthiran, S. Laser-Based Systems for Standoff Detection of CWA: A Short Review. IEEE Sens. J. 2021, 21, 4085–4096. [Google Scholar] [CrossRef]
- Oldenborg, R.; Tiee, J.; Shimada, T. Heterodyne Lidar for Chemical Sensing. Chem. Biol. Sens. V 2004, 5416, 186–194. [Google Scholar]
- Liu, Q.-W.; Chen, Y.-F.; Yang, J.; Huang, H.; Hu, S.-X. Effect of temperature on inversion concentration of NO2 differential absorption lidar and optimized algorithm. J. Quant. Spectrosc. Radiat. Transf. 2021, 277, 107975. [Google Scholar] [CrossRef]
- Bogue, R. Remote chemical sensing: A review of techniques and recent developments. Sens. Rev. 2018, 38, 453–457. [Google Scholar] [CrossRef]
- Hakonen, A.; Andersson, P.O.; Schmidt, M.S. Explosive and chemical threat detection by surface-enhanced Raman scattering: A review (Review). Anal. Chim. Acta 2015, 893, 1–13. [Google Scholar] [CrossRef]
- Nureev, I.I.; Gubaidullin, R.R.; Kadushkin, V.V.; Kurbiev, I.Y.; Proskuriakov, A.D. Distributed Raman sensor system with point spots for downhole telemetry. IOP Conf. Ser. Mater. Sci. Eng. 2020, 734, 012142. [Google Scholar] [CrossRef]
- Gulati, K.K.; Gambhir, V.; Reddy, M.N. Detection of Nitro-aromatic Compound in Soil and Sand using Time Gated Raman Spectroscopy. Def. Sci. J. 2017, 67, 588–591. [Google Scholar] [CrossRef] [Green Version]
- Gulati, S.; Gulia, S.; Gambhir, T. Standoff Detection and Identification of Explosives and Hazardous Chemicals in Simulated Real Field Scenario using Time Gated Raman Spectroscopy. Def. Sci. J. 2019, 69, 342–347. [Google Scholar] [CrossRef] [Green Version]
- Gupta, S.; Ahmad, A.; Gambhir, V. Raman signal enhancement by multiple beam excitation and its application for the detection of chemicals. Appl. Phys. Lett. 2015, 107, 1–5. [Google Scholar] [CrossRef]
- ReVelle, C.S.; Eiselt, H.A. Location analysis: A synthesis and survey. Eur. J. Oper. Res. 2005, 165, 1–19. [Google Scholar] [CrossRef]
- Vianna, S.S.V. The set covering problem applied to optimisation of gas detectors in chemical process plants(Article). Comput. Chem. Eng. 2019, 121, 388–395. [Google Scholar] [CrossRef]
- Vieira, B.S.; Ferrari, T.; Ribeiro, G.M. A progressive hybrid set covering based algorithm for the traffic counting location problem. Expert Syst. Appl. 2020, 160, 113641. [Google Scholar] [CrossRef]
- Mokrini, A.E.; Boulaksil, Y.; Berrado, A. Modelling Facility Location Problems in Emerging Markets: The Case of The Public Healthcare Sector in Morocco. Oper. Supply Chain. Manag. 2019, 12, 1979–3561. [Google Scholar] [CrossRef] [Green Version]
- Cordeau, J.; Furini, F.; Ljubić, I. Benders decomposition for very large scale partial set covering and maximal covering location problems. Eur. J. Oper. Res. 2019, 275, 882–896. [Google Scholar] [CrossRef]
- Park, Y.; Nielsen, P.; Móon, I. Unmanned aerial vehicle set covering problem considering fixed-radius coverage constraint. Comput. Oper. Res. 2020, 119, 104936. [Google Scholar] [CrossRef]
- Alizadeh, R.; Nishi, T. Hybrid Set Covering and Dynamic Modular Covering Location Problem: Application to an Emergency Humanitarian Logistics Problem. Appl. Sci. 2020, 10, 7110. [Google Scholar] [CrossRef]
- Farahani, R.Z.; Asgari, N.; Heidari, N. Covering problems in facility location: A review. Comput. Ind. Eng. 2011, 62, 368–407. [Google Scholar] [CrossRef]
- Hashim, N.I.M.; Shariff, S.S.R.; Deni, S.M. Allocation of relief centre for flood victims using Location Set Covering Problem (LSCP). J. Phys. Conf. Ser. 2021, 2084, 12016. [Google Scholar] [CrossRef]
- Satawat, D. Analysis of Covering Problem Models for Setting the Location of a Ready-Mixed Concrete Plant: Case Study of the Rayong Province, Thailand. IOP Conf. Ser. Mater. Sci. Eng. 2020, 910, 12003. [Google Scholar]
- Rahman, M.; Chen, N.S.; Islam, M.M. Location-allocation modeling for emergency evacuation planning with GIS and remote sensing: A case study of Northeast Bangladesh. Geosci. Front. 2021, 12, 175–191. [Google Scholar] [CrossRef]
- Ermakov, S.M.; Semenchikov, D.N. Genetic global optimization algorithms. Commun. Stat. Simul. Comput. 2022, 51, 1503–1512. [Google Scholar] [CrossRef]
- Wu, J.; Fan, M.J.; Liu, Y.; Zhou, Y.P.; Yang, N.; Yin, M.H. A hybrid ant colony algorithm for the winner determination problem. Math. Biosci. Eng. 2022, 19, 3202–3222. [Google Scholar] [CrossRef]
- Wang, H.; Wang, W.J.; Sun, H.; Rahnamayan, S. Firefly algorithm with random attraction. Int. J. Bio-Inspired Comput. 2016, 8, 33–41. [Google Scholar] [CrossRef]
- Li, J.Z.; Tan, Y. A Comprehensive Review of the Fireworks Algorithm. ACM Comput. Surv. 2020, 52, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Ehsaeyan, E.; Zolghadrasli, A. FOA: Fireworks optimization algorithm. Multimed. Tools Appl. 2022, 81, 33151–33170. [Google Scholar] [CrossRef]
- Li, Y.F.; Tan, Y. Hierarchical Collaborated Fireworks Algorithm. Electronics 2022, 11, 948. [Google Scholar] [CrossRef]
- Baidoo, E. Fireworks Algorithm for Unconstrained Function Optimization Problems. Appl. Comput. Sci. 2017, 13, 61–74. [Google Scholar] [CrossRef]
- Cheng, R.; Bai, Y.P.; Zhao, Y.; Tan, X.H.; Xu, T. Improved fireworks algorithm with information exchange for function optimization. Knowl. Based Syst. 2019, 163, 82–90. [Google Scholar] [CrossRef]
- Ali, H.M.; Ejaz, W.; Lee, D.C.; Khater, I.M. Optimising the power using firework-based evolutionary algorithms for emerging IoT applications. IET Netw. 2019, 8, 15–31. [Google Scholar] [CrossRef]
- Tian, G.; Liu, C.; Gao, J.; Wu, S. Multi-sensor optimal disposition model based on fireworks algorithm(Article). Xi Tong Gong Cheng Yu Dian Zi Ji Shu 2019, 41, 1742–1748. [Google Scholar]
- Gui, W.X.; Lu, Q.; Su, M.L.; Pan, F.L. Wireless Sensor Network Fault Sensor Recognition Algorithm Based on MM* Diagnostic Model. IEEE Access 2020, 8, 127084–127093. [Google Scholar] [CrossRef]
- Amutha, J.; Sandeep, S.; Jaiprakash, N. WSN Strategies Based on Sensors, Deployment, Sensing Models, Coverage and Energy Efficiency: Review, Approaches and Open Issues. Wirel. Pers. Commun. 2020, 111, 1089–1115. [Google Scholar] [CrossRef]
- Liu, Y.H.; Suo, L.X.; Sun, D.Y.; Wang, A.M. A virtual square grid-based coverage algorithm of redundant node for wireless sensor network. J. Netw. Comput. Appl. 2013, 36, 811–817. [Google Scholar] [CrossRef]
- Liang, H.J.; Wang, S.H.; Li, H.L.; Ye, H.C.; Zhong, Y. A Trade-Off Algorithm for Solving p-Center Problems with a Graph Convolutional Network. ISPRS Int. J. Geo-Inf. 2022, 11, 270. [Google Scholar] [CrossRef]
- Tan, Y.; Yu, C.; Zheng, S.Q.; Ding, K. Introduction to Fireworks Algorithm. Int. J. Swarm Intell. Res. 2013, 4, 39–70. [Google Scholar] [CrossRef] [Green Version]
- Vahidnia, M.H.; Vahidi, H.; Hassanabad, M.G.; Shafiei, M. A Spatial Decision Support System Based on a Hybrid AHP and TOPSIS Method for Fire Station Site Selection. J. Geovis. Spat. Anal. 2020, 6, 1–20. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Y.; Zhang, H.; Chen, Z.; Sun, Y.; Liu, X.; Gu, J. A Study on the Deployment of Mesoscale Chemical Hazard Area Monitoring Points by Combining Weighting and Fireworks Algorithms. Sustainability 2023, 15, 5779. https://doi.org/10.3390/su15075779
Shi Y, Zhang H, Chen Z, Sun Y, Liu X, Gu J. A Study on the Deployment of Mesoscale Chemical Hazard Area Monitoring Points by Combining Weighting and Fireworks Algorithms. Sustainability. 2023; 15(7):5779. https://doi.org/10.3390/su15075779
Chicago/Turabian StyleShi, Yimeng, Hongyuan Zhang, Zheng Chen, Yueyue Sun, Xuecheng Liu, and Jin Gu. 2023. "A Study on the Deployment of Mesoscale Chemical Hazard Area Monitoring Points by Combining Weighting and Fireworks Algorithms" Sustainability 15, no. 7: 5779. https://doi.org/10.3390/su15075779