Bayesian Model Averaging: A Unique Model Enhancing Forecasting Accuracy for Daily Streamflow Based on Different Antecedent Time Series




Abstract
:1. Introduction
2. Methodology
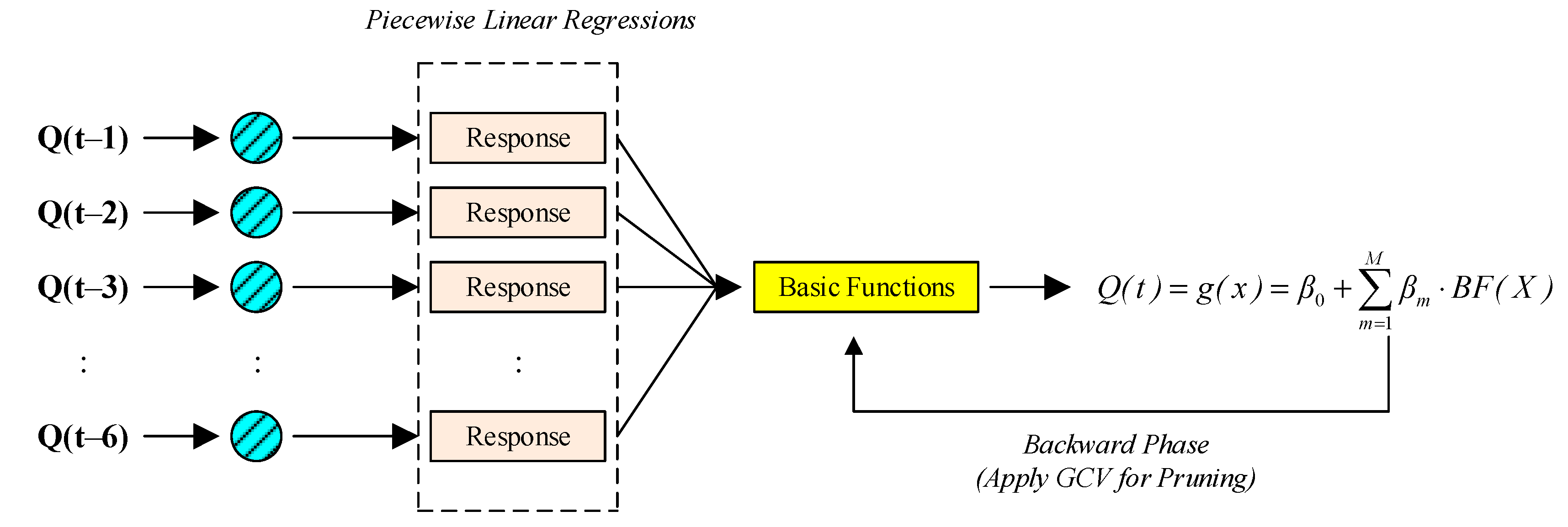
2.1. Multivariate Adaptive Regression Spline (MARS)
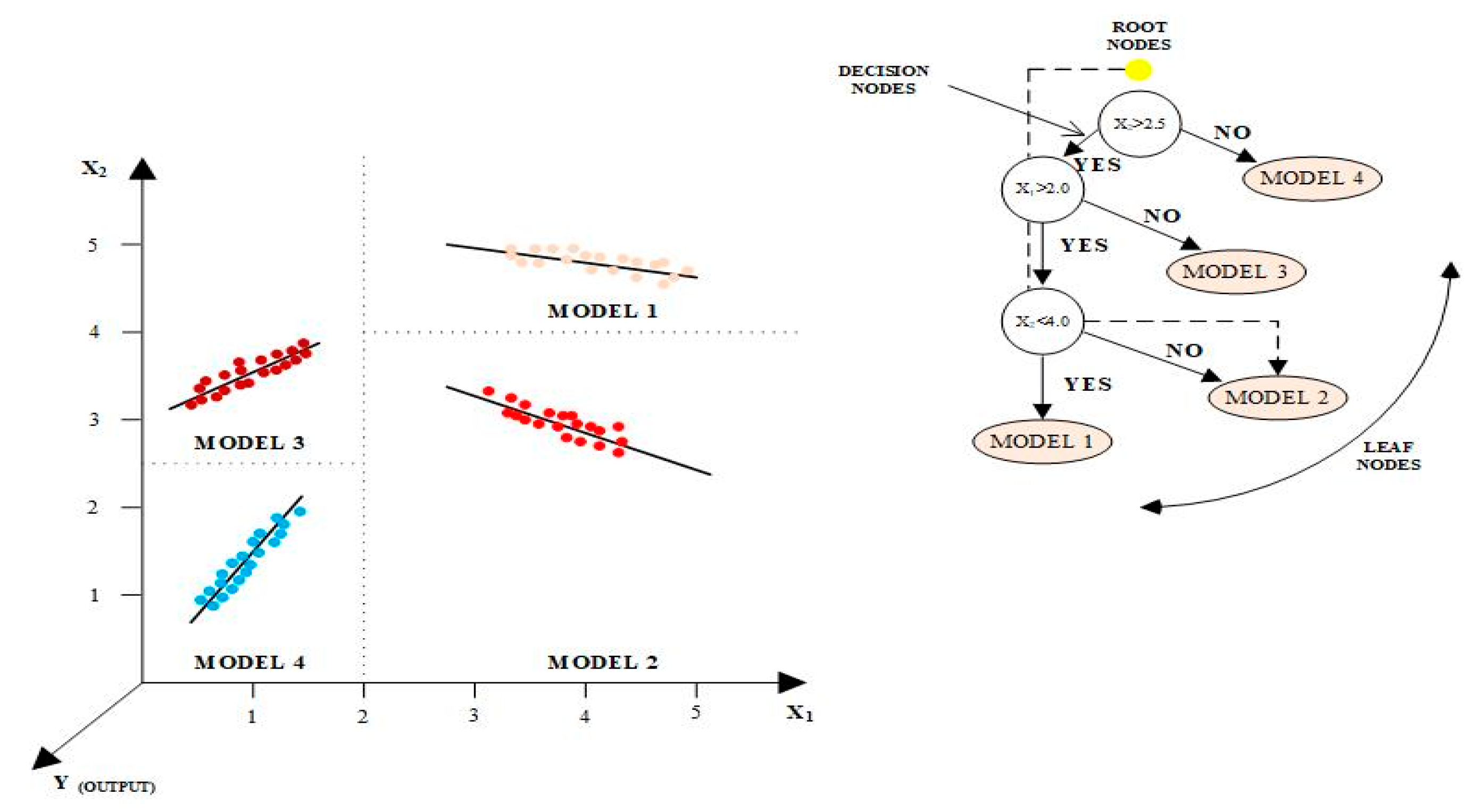
2.2. M5 Model Tree (M5Tree)
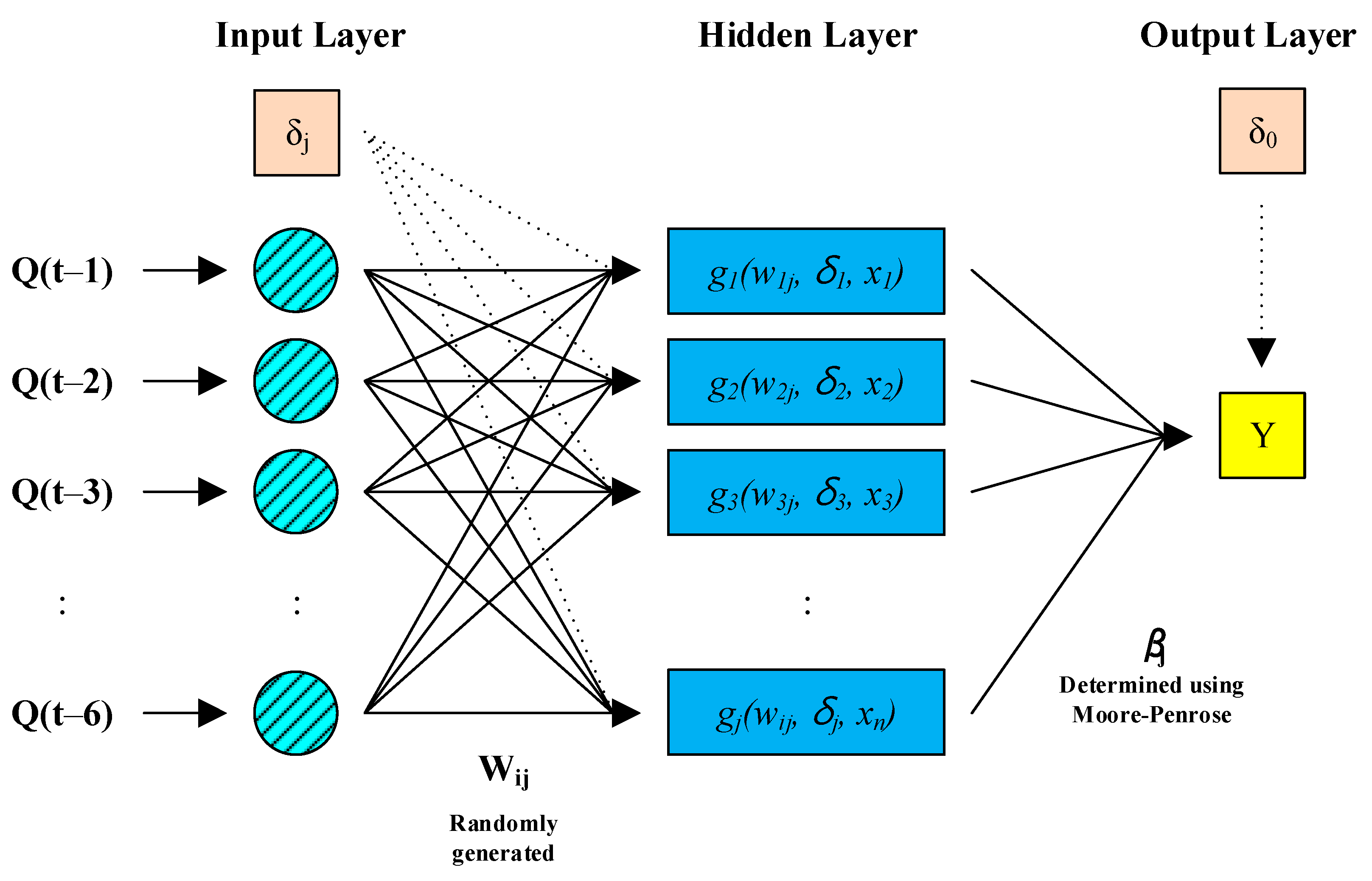
2.3. Kernel Extreme Learning Machines (KELM)
2.4. Bayesian Model Averaging (BMA)
2.5. Assessment of Models Performance
2.5.1. Root Mean Square Error (RMSE)
2.5.2. Nash-Sutcliffe Efficiency (NSE)
2.5.3. Correlation Coefficient (R)
2.5.4. Mean Absolute Error (MAE)
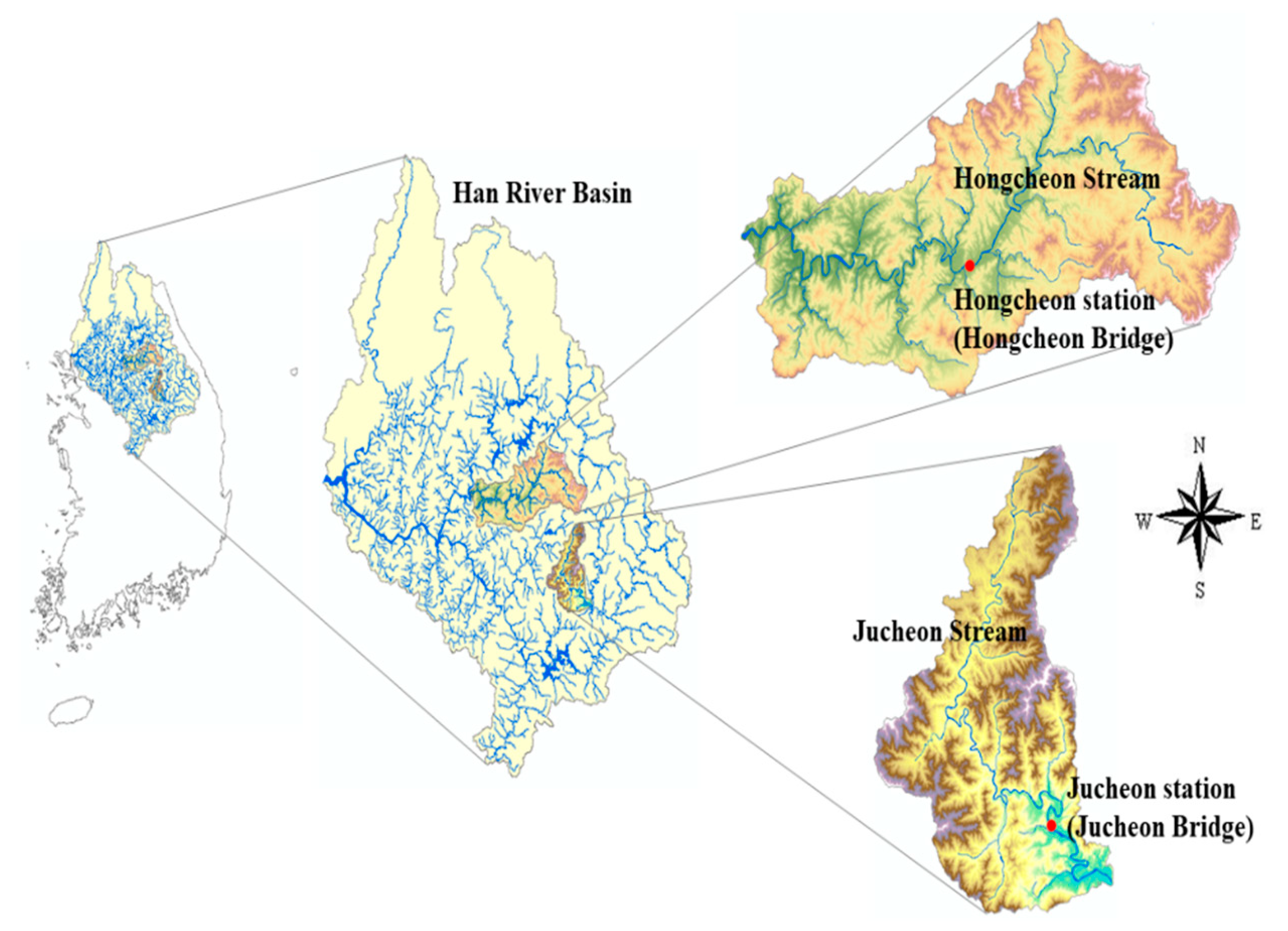
3. Study Area and Data
4. Application and Results
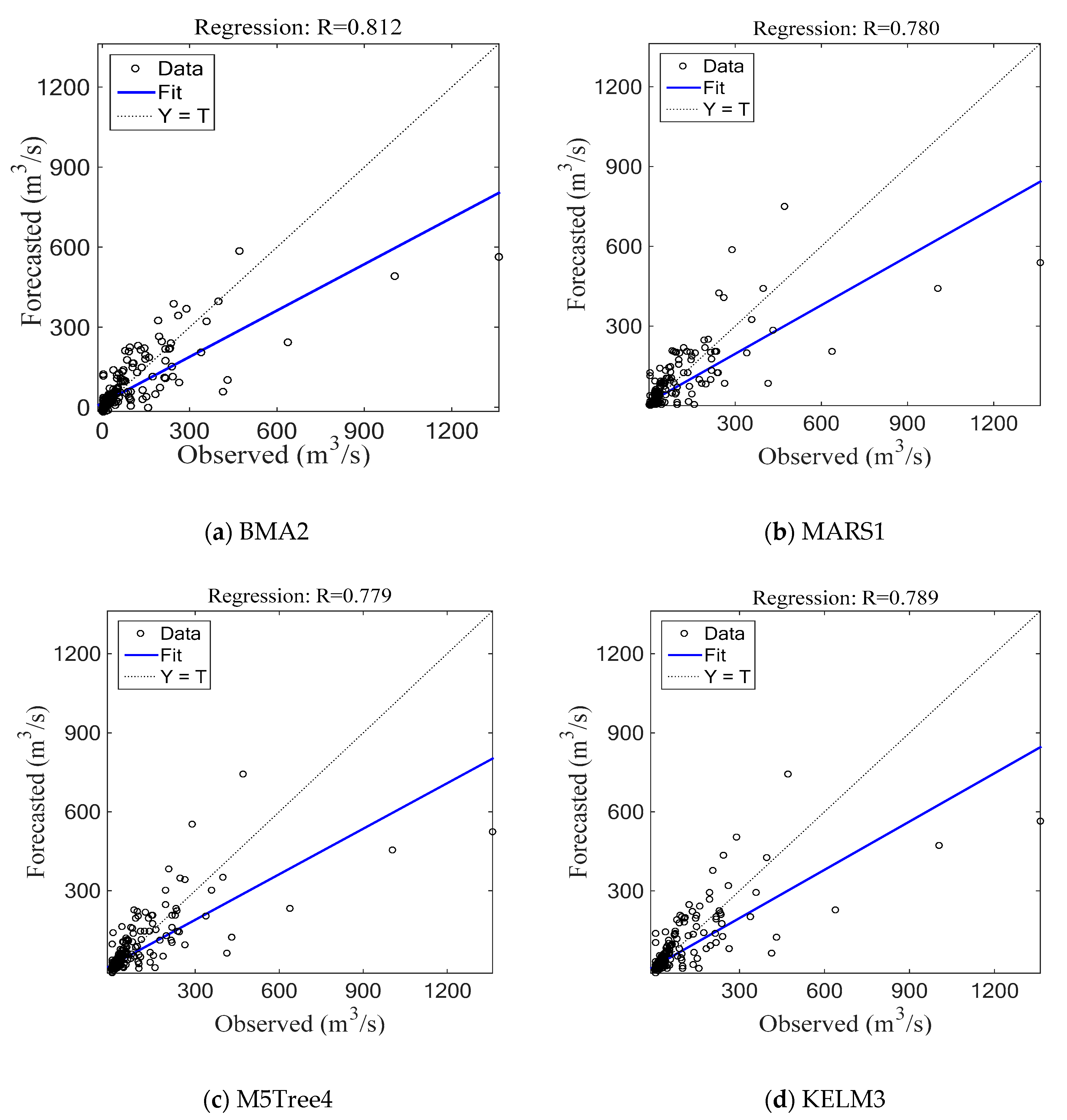
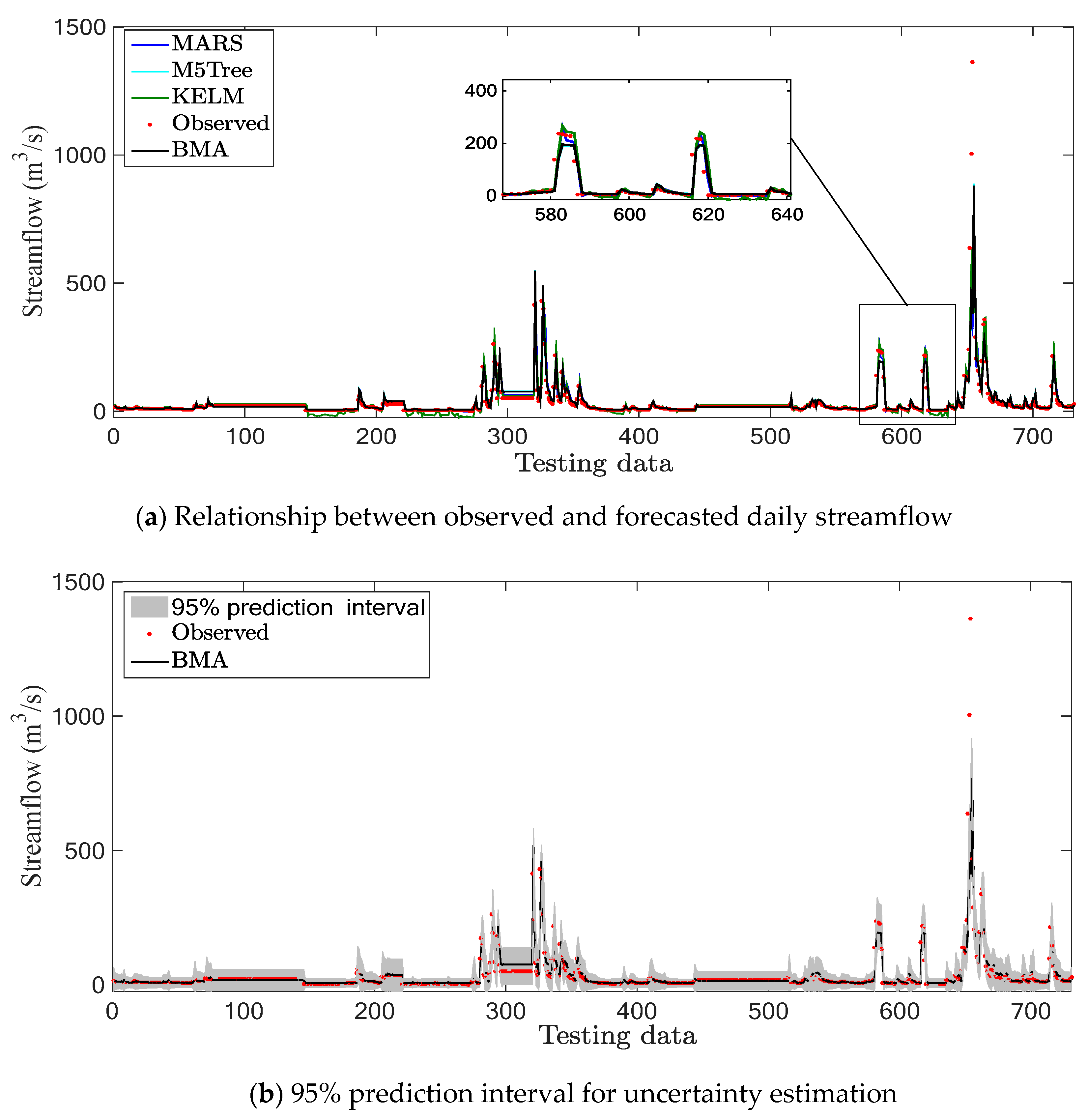
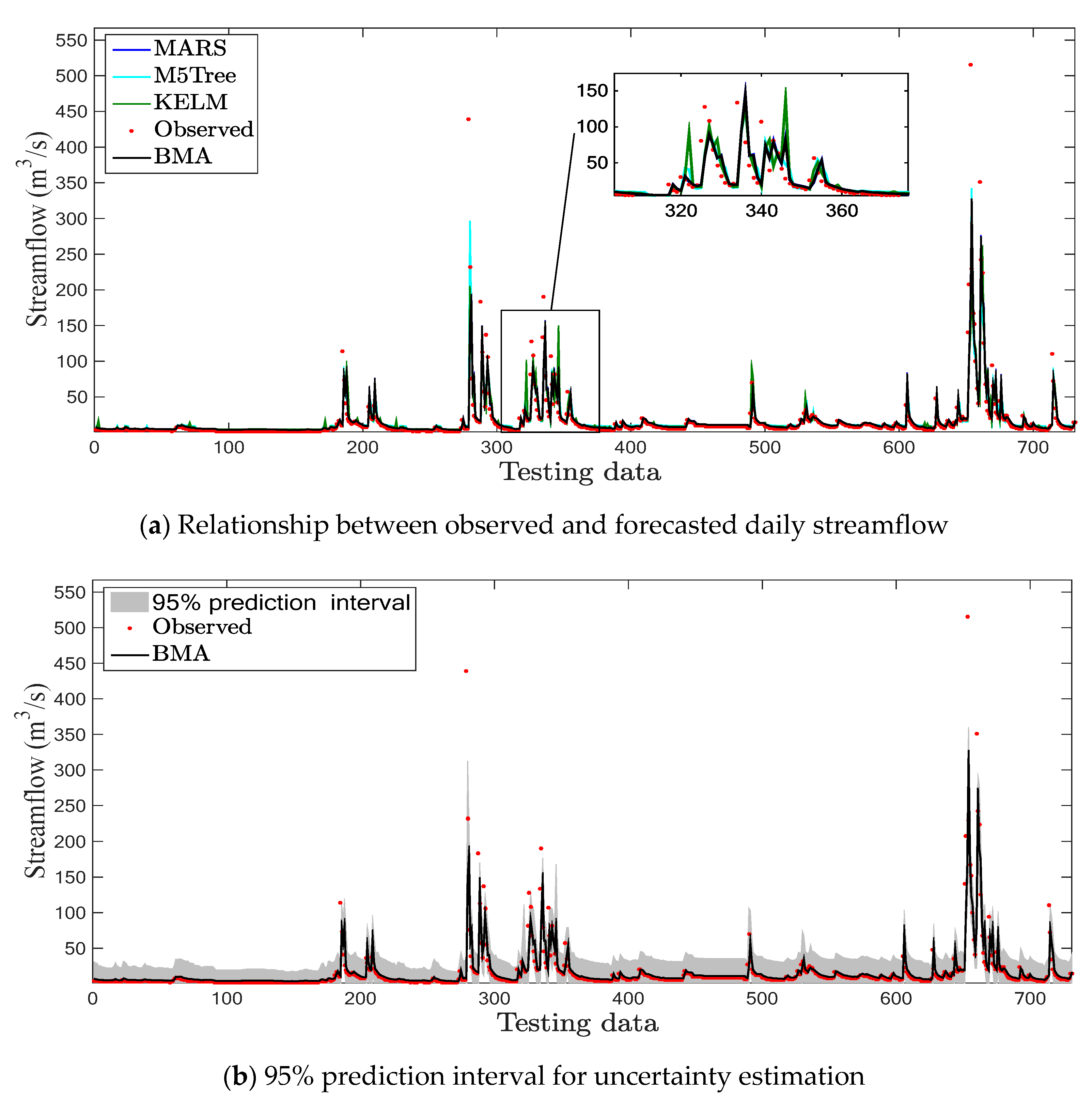
4.1. Hongcheon Station
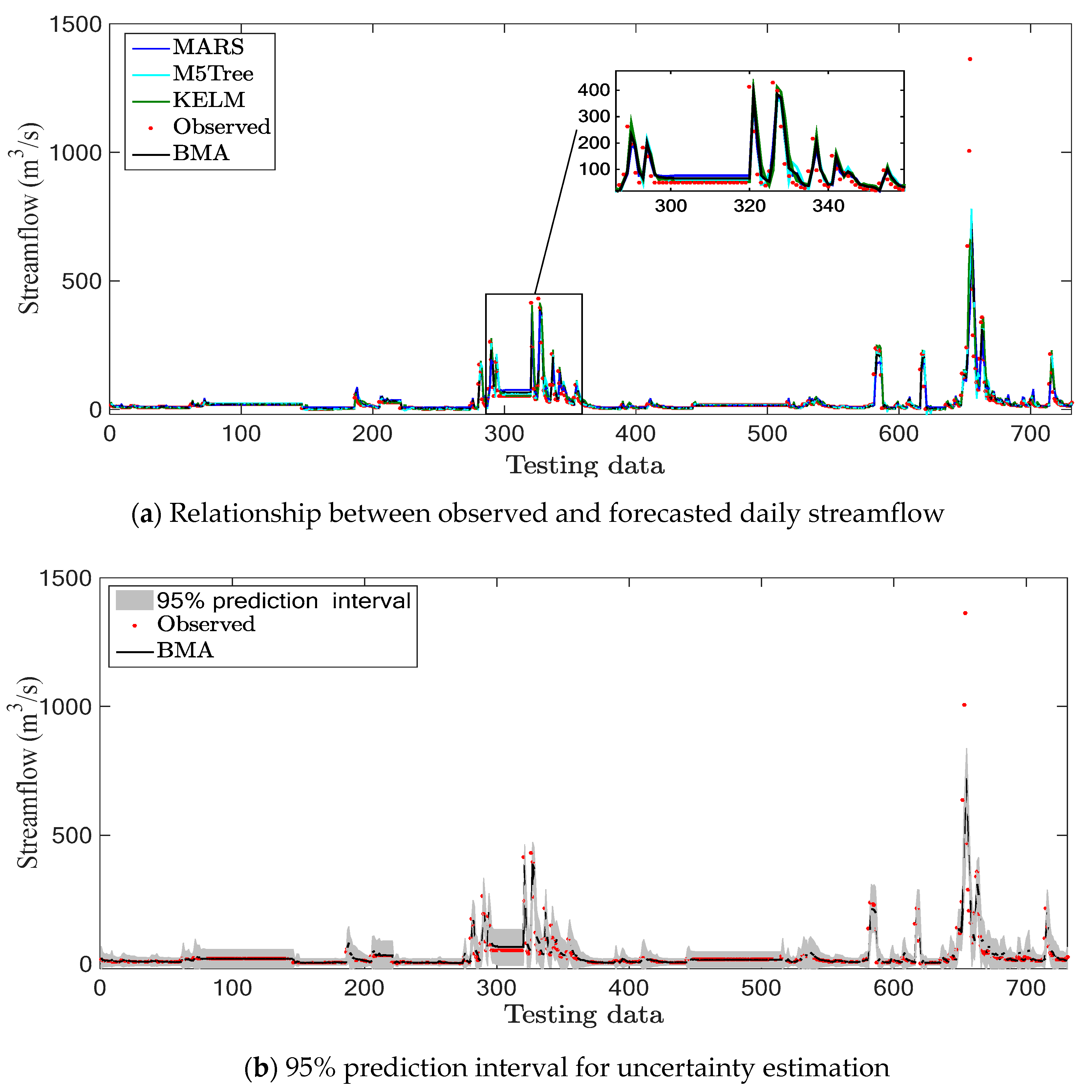
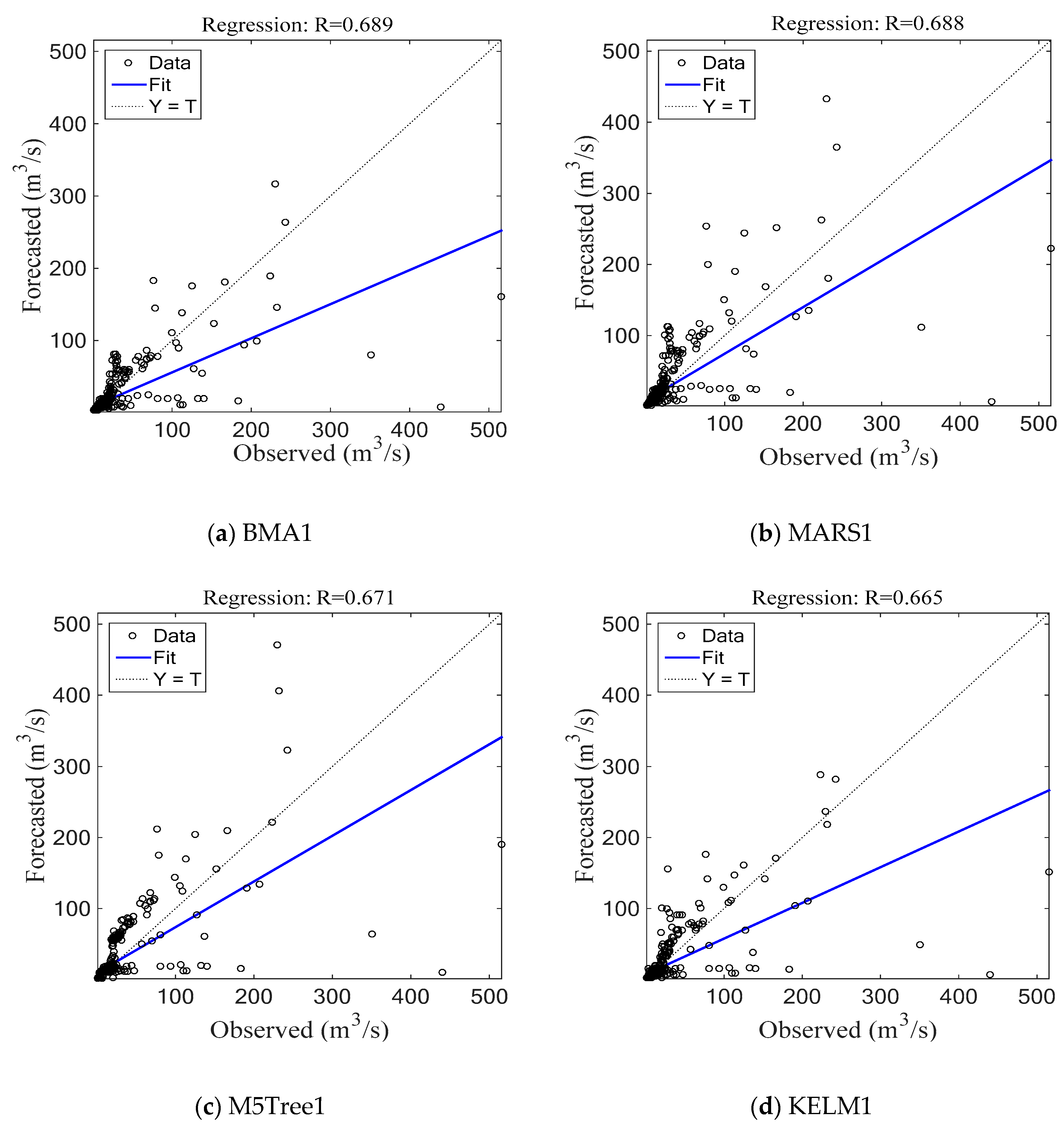
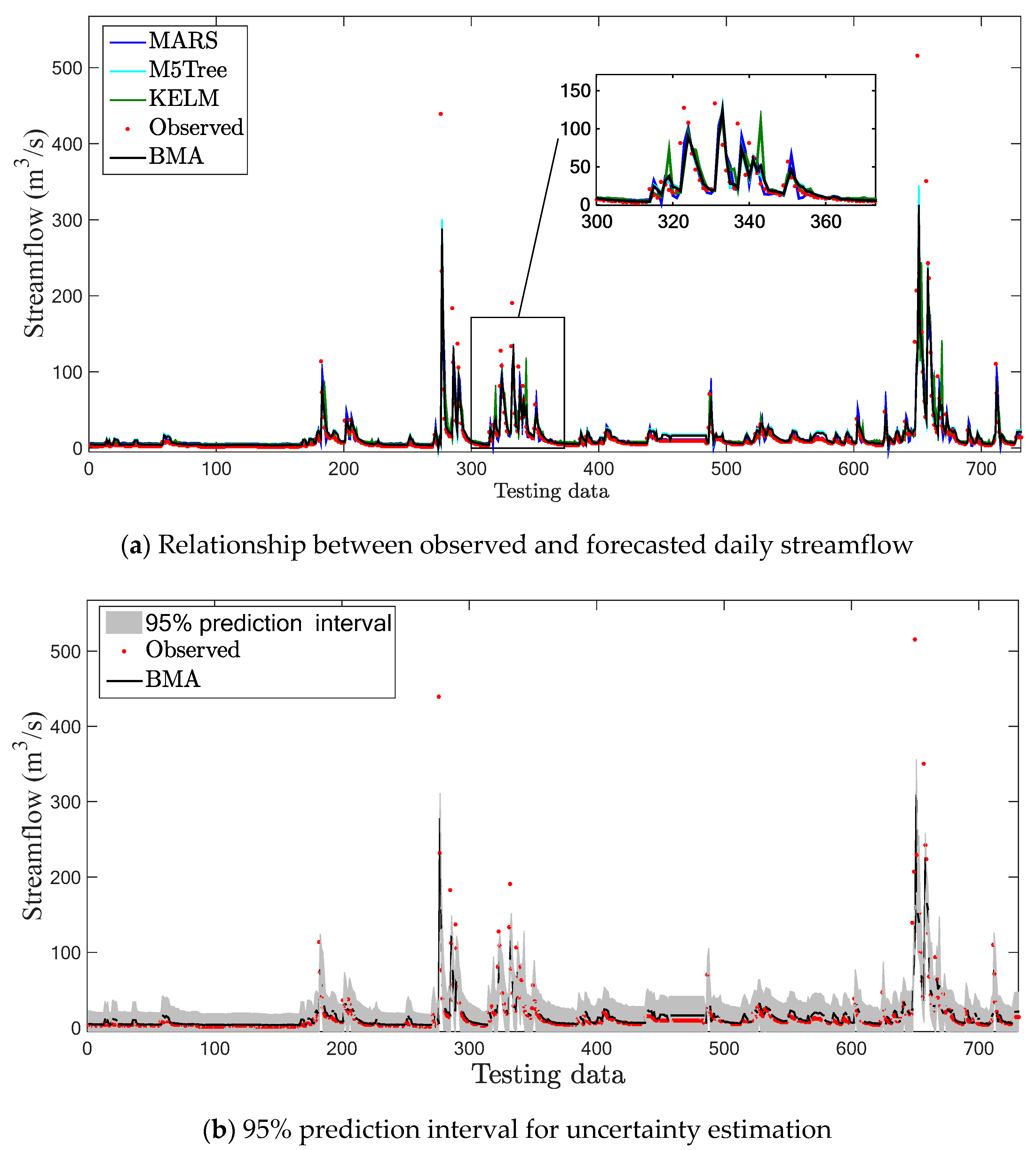
4.2. Jucheon Station
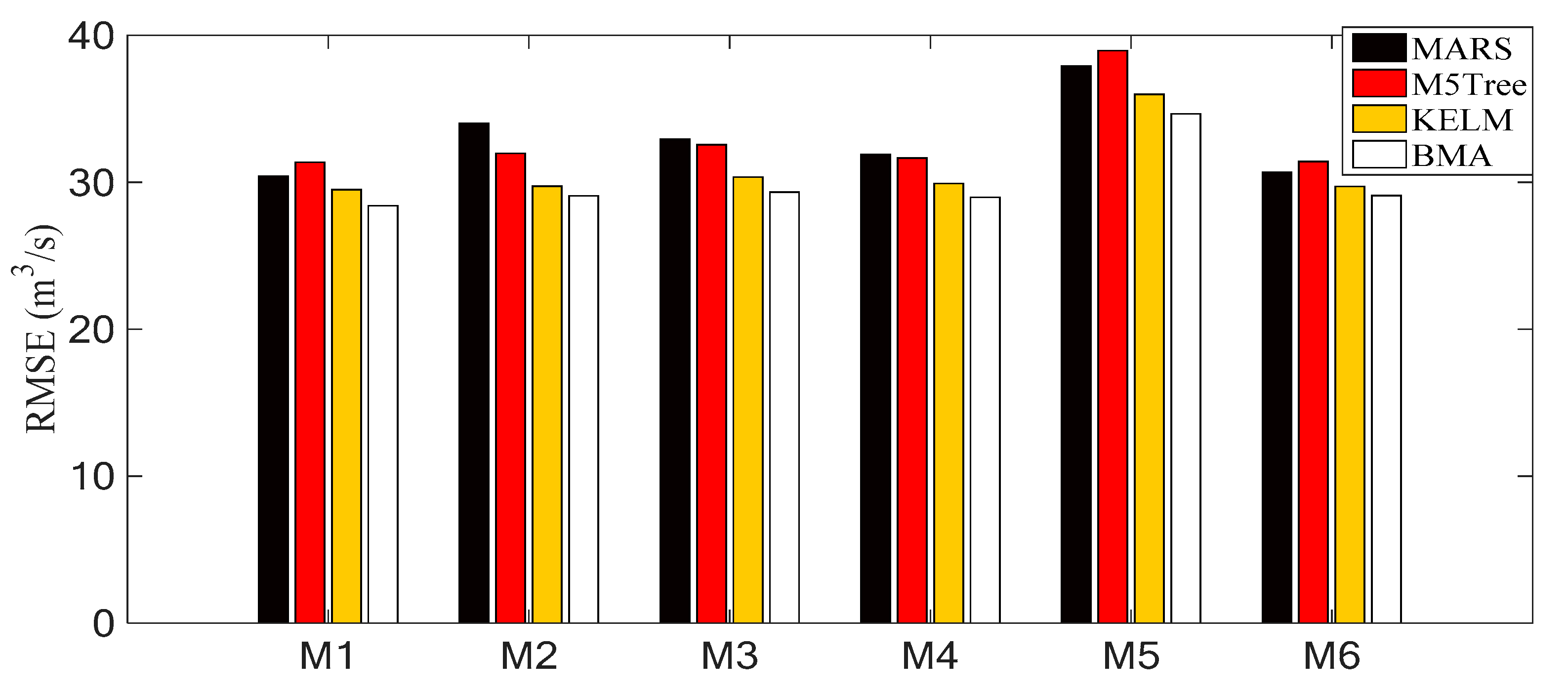
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Seo, Y.; Kim, S.; Kisi, O.; Singh, V.P. Daily water level forecasting using wavelet decomposition and artificial intelligence techniques. J. Hydrol. 2015, 520, 224–243. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Jaafar, O.; Deo, R.C.; Kisi, O.; Adamowski, J.; Quilty, J.; El-Shafie, A. Stream-flow forecasting using extreme learning machines: A case study in a semi-arid region in Iraq. J. Hydrol. 2016, 542, 603–614. [Google Scholar] [CrossRef]
- Zakhrouf, M.; Bouchelkia, H.; Stamboul, M.; Kim, S. Novel hybrid approaches based on evolutionary strategy for streamflow forecasting in the Chellif River, Algeria. Acta Geophys. 2020, 68, 167–180. [Google Scholar] [CrossRef]
- Zakhrouf, M.; Bouchelkia, H.; Stamboul, M.; Kim, S.; Singh, V.P. Implementation on the evolutionary machine learning approaches for streamflow forecasting: Case study in the Seybous River, Algeria. J. Korea Water Resour. Assoc. 2020, 53, 395–408. [Google Scholar]
- Badrzadeh, H.; Sarukkalige, R.; Jayawardena, A.W. Intermittent stream flow forecasting and modelling with hybrid wavelet neuro-fuzzy model. Hydrol. Res. 2018, 49, 27–40. [Google Scholar] [CrossRef]
- Zhou, J.; Peng, T.; Zhang, C.; Sun, N. Data pre-analysis and ensemble of various artificial neural networks for monthly streamflow forecasting. Water 2018, 10, 628. [Google Scholar] [CrossRef] [Green Version]
- Tikhamarine, Y.; Souag-Gamane, D.; Ahmed, A.N.; Kisi, O.; El-Shafie, A. Improving artificial intelligence models accuracy for monthly streamflow forecasting using grey Wolf optimization (GWO) algorithm. J. Hydrol. 2020, 582, 124435. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Allawi, M.F.; Yousif, A.A.; Jaafar, O.; Hamzah, F.M.; El-Shafie, A. Non-tuned machine learning approach for hydrological time series forecasting. Neural. Comput. Appl. 2018, 30, 1479–1491. [Google Scholar] [CrossRef]
- Luo, X.; Yuan, X.; Zhu, S.; Xu, Z.; Meng, L.; Peng, J. A hybrid support vector regression framework for streamflow forecast. J. Hydrol. 2019, 568, 184–193. [Google Scholar] [CrossRef]
- Cheng, M.; Fang, F.; Kinouchi, T.; Navon, I.M.; Pain, C.C. Long lead-time daily and monthly streamflow forecasting using machine learning methods. J. Hydrol. 2020, 590, 125376. [Google Scholar] [CrossRef]
- Yu, X.; Wang, Y.; Wu, L.; Chen, G.; Wang, L.; Qin, H. Comparison of support vector regression and extreme gradient boosting for decomposition-based data-driven 10-day streamflow forecasting. J. Hydrol. 2020, 582, 124293. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H. Evaluation of random forests and prophet for daily streamflow forecasting. Adv. Geosci. 2018, 45, 201–208. [Google Scholar] [CrossRef] [Green Version]
- Rezaie-Balf, M.; Kisi, O. New formulation for forecasting streamflow: Evolutionary polynomial regression vs. extreme learning machine. Hydrol. Res. 2018, 49, 939–953. [Google Scholar] [CrossRef] [Green Version]
- Zakhrouf, M.; Bouchelkia, H.; Stamboul, M.; Kim, S.; Heddam, S. Time series forecasting of river flow using an integrated approach of wavelet multi-resolution analysis and evolutionary data-driven models. A case study: Sebaou River (Algeria). Phys. Geogr. 2018, 39, 506–522. [Google Scholar] [CrossRef]
- Li, F.F.; Wang, Z.Y.; Qiu, J. Long-term streamflow forecasting using artificial neural network based on preprocessing technique. J. Forecast. 2019, 38, 192–206. [Google Scholar] [CrossRef]
- Fu, M.; Fan, T.; Ding, Z.A.; Salih, S.Q.; Al-Ansari, N.; Yaseen, Z.M. Deep learning data-intelligence model based on adjusted forecasting window scale: Application in daily streamflow simulation. IEEE Access 2020, 8, 32632–32651. [Google Scholar] [CrossRef]
- Al-Sudani, Z.A.; Salih, S.Q.; Yaseen, Z.M. Development of multivariate adaptive regression spline integrated with differential evolution model for streamflow simulation. J. Hydrol. 2019, 573, 1–12. [Google Scholar] [CrossRef]
- Adamowski, J.; Chan, H.F.; Prasher, S.O.; Sharda, V.N. Comparison of multivariate adaptive regression splines with coupled wavelet transform artificial neural networks for runoff forecasting in Himalayan micro-watersheds with limited data. J. Hydroinformatics 2012, 14, 731–744. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.; Langousis, A. Super ensemble learning for daily streamflow forecasting: Large-scale demonstration and comparison with multiple machine learning algorithms. Neural. Comput. Appl. 2020, 1–16. [Google Scholar] [CrossRef]
- Solomatine, D.P.; Xue, Y. M5 model trees and neural networks: Application to flood forecasting in the upper reach of the Huai River in China. J. Hydrol. Eng. 2004, 9, 491–501. [Google Scholar] [CrossRef]
- Štravs, L.; Brilly, M. Development of a low-flow forecasting model using the M5 machine learning method. Hydrol. Sci. J. 2007, 52, 466–477. [Google Scholar] [CrossRef]
- Sattari, M.T.; Pal, M.; Apaydin, H.; Ozturk, F. M5 model tree application in daily river flow forecasting in Sohu Stream, Turkey. Water Resour. 2013, 40, 233–242. [Google Scholar] [CrossRef]
- Adnan, R.M.; Yuan, X.; Kisi, O.; Adnan, M.; Mehmood, A. Stream flow forecasting of poorly gauged mountainous watershed by least square support vector machine, fuzzy genetic algorithm and M5 model tree using climatic data from nearby station. Water Resour. Manag. 2018, 32, 4469–4486. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Kisi, O.; Demir, V. Enhancing long-term streamflow forecasting and predicting using periodicity data component: Application of artificial intelligence. Water Resour. Manag. 2016, 30, 4125–4151. [Google Scholar] [CrossRef]
- Yin, Z.; Feng, Q.; Wen, X.; Deo, R.C.; Yang, L.; Si, J.; He, Z. Design and evaluation of SVR, MARS and M5Tree models for 1, 2 and 3-day lead time forecasting of river flow data in a semiarid mountainous catchment. Stoch. Environ. Res. Risk. Assess. 2018, 32, 2457–2476. [Google Scholar] [CrossRef]
- Kisi, O.; Choubin, B.; Deo, R.C.; Yaseen, Z.M. Incorporating synoptic-scale climate signals for streamflow modelling over the Mediterranean region using machine learning models. Hydrol. Sci. J. 2019, 64, 1240–1252. [Google Scholar] [CrossRef]
- Rezaie-Balf, M.; Kim, S.; Fallah, H.; Alaghmand, S. Daily river flow forecasting using ensemble empirical mode decomposition based heuristic regression models: Application on the perennial rivers in Iran and South Korea. J. Hydrol. 2019, 572, 470–485. [Google Scholar] [CrossRef]
- Rezaie-Balf, M.; Naganna, S.R.; Kisi, O.; El-Shafie, A. Enhancing streamflow forecasting using the augmenting ensemble procedure coupled machine learning models: Case study of Aswan High Dam. Hydrol. Sci. J. 2019, 64, 1629–1646. [Google Scholar] [CrossRef]
- Lima, A.R.; Cannon, A.J.; Hsieh, W.W. Forecasting daily streamflow using online sequential extreme learning machines. J. Hydrol. 2016, 537, 431–443. [Google Scholar] [CrossRef]
- Yadav, B.; Ch, S.; Mathur, S.; Adamowski, J. Discharge forecasting using an online sequential extreme learning machine (OS-ELM) model: A case study in Neckar River, Germany. Measurement 2016, 92, 433–445. [Google Scholar] [CrossRef]
- Niu, W.J.; Feng, Z.K.; Cheng, C.T.; Zhou, J.Z. Forecasting daily runoff by extreme learning machine based on quantum-behaved particle swarm optimization. J. Hydrol. Eng. 2018, 23, 04018002. [Google Scholar] [CrossRef]
- Vrugt, J.A.; Robinson, B.A. Treatment of uncertainty using ensemble methods: Comparison of sequential data assimilation and Bayesian model averaging. Water Resour. Res. 2007, 43, W01411. [Google Scholar] [CrossRef] [Green Version]
- Duan, Q.; Ajami, N.K.; Gao, X.; Sorooshian, S. Multi-model ensemble hydrologic prediction using Bayesian model averaging. Adv. Water Resour. 2007, 30, 1371–1386. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Ren, L.; Hong, Y.; Yong, B.; Yang, X.; Yuan, F.; Ma, M. Comprehensive evaluation of multi-satellite precipitation products with a dense rain gauge network and optimally merging their simulated hydrological flows using the Bayesian model averaging method. J. Hydrol. 2012, 452, 213–225. [Google Scholar] [CrossRef]
- Wang, Q.J.; Schepen, A.; Robertson, D.E. Merging seasonal rainfall forecasts from multiple statistical models through Bayesian model averaging. J. Clim. 2012, 25, 5524–5537. [Google Scholar] [CrossRef]
- Rathinasamy, M.; Adamowski, J.; Khosa, R. Multiscale streamflow forecasting using a new Bayesian Model Average based ensemble multi-wavelet Volterra nonlinear method. J. Hydrol. 2013, 507, 186–200. [Google Scholar] [CrossRef]
- Liu, Z.; Merwade, V. Accounting for model structure, parameter and input forcing uncertainty in flood inundation modeling using Bayesian model averaging. J. Hydrol. 2018, 565, 138–149. [Google Scholar] [CrossRef]
- Friedman, J. Multivariate adaptive regression splines. Ann. Stat. 1991, 19, 1–67. [Google Scholar] [CrossRef]
- Zhang, W.G.; Goh, A.T.C. Multivariate adaptive regression splines for analysis of geotechnical engineering systems. Comput. Geotech. 2013, 48, 82–95. [Google Scholar] [CrossRef]
- Solomatine, D.P.; Dulal, K.N. Model trees as an alternative to neural networks in rainfall—Runoff modelling. Hydrol. Sci. J. 2003, 48, 399–411. [Google Scholar] [CrossRef]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Alizamir, M.; Kim, S.; Kisi, O.; Zounemat-Kermani, M. Deep echo state network: A novel machine learning approach to model dew point temperature using meteorological variables. Hydrol. Sci. J. 2020, 65, 1173–1190. [Google Scholar] [CrossRef]
- Alizamir, M.; Kisi, O.; Ahmed, A.N.; Mert, C.; Fai, C.M.; Kim, S.; Kim, N.W.; El-Shafie, A. Advanced machine learning model for better prediction accuracy of soil temperature at different depths. PLoS ONE 2020, 15, e0231055. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Syst. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seo, Y.; Kim, S.; Singh, V.P. Comparison of different heuristic and decomposition techniques for river stage modeling. Environ. Monit. Assess 2018, 190, 392. [Google Scholar] [CrossRef] [PubMed]
- Raftery, A.E.; Madigan, D.; Hoeting, J.A. Bayesian model averaging for linear regression models. J. Am. Stat. Assoc. 1997, 92, 179–191. [Google Scholar] [CrossRef]
- Sloughter, J.M.L.; Raftery, A.E.; Gneiting, T.; Fraley, C. Probabilistic quantitative precipitation forecasting using Bayesian model averaging. Mon. Weather Rev. 2007, 135, 3209–3220. [Google Scholar] [CrossRef]
- Kisi, O.; Alizamir, M.; Gorgij, A.D. Dissolved oxygen prediction using a new ensemble method. Environ. Sci. Pollut. Res. 2020, 27, 9589–9603. [Google Scholar] [CrossRef]
- Kisi, O.; Alizamir, M.; Trajkovic, S.; Shiri, J.; Kim, S. Solar radiation estimation in Mediterranean climate by weather variables using a novel Bayesian model averaging and machine learning methods. Neural Process. Lett. 2020, 52, 2297–2318. [Google Scholar] [CrossRef]
- Baran, S. Probabilistic wind speed forecasting using Bayesian model averaging with truncated normal components. Comput. Stat. Data Anal. 2014, 75, 227–238. [Google Scholar] [CrossRef] [Green Version]
- Raftery, A.E.; Gneiting, T.; Balabdaoui, F.; Polakowski, M. Using Bayesian model averaging to calibrate forecast ensembles. Mon. Weather Rev. 2005, 133, 1155–1174. [Google Scholar] [CrossRef] [Green Version]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Dawson, C.W.; Abrahart, R.J.; See, L.M. HydroTest: A web-based toolbox of evaluation metrics for the standardised assessment of hydrological forecasts. Environ. Model. Softw. 2007, 22, 1034–1052. [Google Scholar] [CrossRef] [Green Version]
- Deo, R.C.; Şahin, M.; Adamowski, J.F.; Mi, J. Universally deployable extreme learning machines integrated with remotely sensed MODIS satellite predictors over Australia to forecast global solar radiation: A new approach. Renew. Sust. Energ. Rev. 2019, 104, 235–261. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models, Part 1 – A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Wilcox, B.P.; Rawls, W.J.; Brakensiek, D.L.; Wight, J.R. Predicting runoff from rangeland catchments: A comparison of two models. Water Resour. Res. 1990, 26, 2401–2410. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J. Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Salas, J.D.; Kim, H.S.; Eykholt, R.; Burlando, P.; Green, T.R. Aggregation and sampling in deterministic chaos: Implications for chaos identification in hydrological processes. Nonlinear Process. Geophys. 2005, 12, 557–567. [Google Scholar] [CrossRef] [Green Version]
- Yaseen, Z.M.; El-Shafie, A.; Jaafar, O.; Afan, H.A.; Sayl, K.N. Artificial intelligence based models for stream-flow forecasting: 2000–2015. J. Hydrol. 2015, 530, 829–844. [Google Scholar] [CrossRef]
- Rasouli, K.; Hsieh, W.W.; Cannon, A.J. Daily streamflow forecasting by machine learning methods with weather and climate inputs. J. Hydrol. 2012, 414, 284–293. [Google Scholar] [CrossRef]
- Tongal, H.; Booij, M.J. Simulation and forecasting of streamflows using machine learning models coupled with base flow separation. J. Hydrol. 2018, 564, 266–282. [Google Scholar] [CrossRef]
- McCuen, R.H. Microcomputer Applications in Statistical Hydrology, 1st ed.; Prentice Hall: Eaglewood Cliffs, NJ, USA, 1993; pp. 20–48. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Automat. Contr. 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Thiyagarajan, K.; Kodagoda, S.; Ranasinghe, R.; Vitanage, D.; Iori, G. Robust sensor suite combined with predictive analytics enabled anomaly detection model for smart monitoring of concrete sewer pipe surface moisture conditions. IEEE Sens. J. 2020, 20, 8232–8243. [Google Scholar] [CrossRef]
- Thiyagarajan, K.; Kodagoda, S.; Van Nguyen, L.; Ranasinghe, R. Sensor failure detection and faulty data accommodation approach for instrumented wastewater infrastructures. IEEE Access 2018, 6, 56562–56574. [Google Scholar] [CrossRef]
- Melesse, A.M.; Khosravi, K.; Tiefenbacher, J.P.; Heddam, S.; Kim, S.; Mosavi, A.; Pham, B.T. River water salinity prediction using hybrid machine learning models. Water 2020, 12, 2951. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hongcheon | Jucheon | |||
|---|---|---|---|---|
| Training | Testing | Training | Testing | |
| Number | 2922 | 731 | 2922 | 731 |
| Maximum | 1951.5 | 1362 | 2720.4 | 515.5 |
| Minimum | 2.92 | 0.92 | 0.01 | 1.12 |
| Average | 67.245 | 32.552 | 27.519 | 16.203 |
| Standard Deviation | 111.949 | 83.321 | 105.677 | 39.099 |
| Skewness | 4.844 | 9.310 | 11.966 | 7.207 |
| Types | Input Combinations | Functions |
|---|---|---|
| M1 | t − 1 | Q(t) = f (Q(t − 1)) |
| M2 | t − 1, t − 2 | Q(t) = f (Q(t − 1), Q(t − 2)) |
| M3 | t − 1, t − 2, t − 3 | Q(t) = f (Q(t − 1), Q(t − 2), Q(t − 3)) |
| M4 | t − 1, t − 3, t − 5 | Q(t) = f (Q(t − 1), Q(t − 3), Q(t − 5)) |
| M5 | t − 2, t − 4, t − 6 | Q(t) = f (Q(t − 2), Q(t − 4), Q(t − 6)) |
| M6 | t − 1, t − 2, t − 3, t − 4, t − 5, t − 6 | Q(t) = f (Q(t − 1), Q(t − 2), Q(t − 3), Q(t − 4), Q(t − 5), Q(t − 6)) |
| Category | Assessment Indexes | MARS1 | M5Tree1 | KELM1 | BMA1 |
|---|---|---|---|---|---|
| RMSE (m3/s) | 52.214 | 52.866 | 51.541 | 50.887 | |
| M1 | NSE | 0.609 | 0.600 | 0.619 | 0.629 |
| R | 0.780 | 0.780 | 0.789 | 0.798 | |
| MAE (m3/s) | 15.510 | 14.860 | 15.890 | 19.280 | |
| MARS2 | M5Tree2 | KELM2 | BMA2 | ||
| RMSE (m3/s) | 56.026 | 55.442 | 55.160 | 49.507 | |
| M2 | NSE | 0.550 | 0.560 | 0.564 | 0.649 |
| R | 0.743 | 0.749 | 0.751 | 0.812 | |
| MAE (m3/s) | 16.210 | 15.160 | 14.740 | 17.200 | |
| MARS3 | M5Tree3 | KELM3 | BMA3 | ||
| RMSE (m3/s) | 54.280 | 57.704 | 51.242 | 50.212 | |
| M3 | NSE | 0.578 | 0.523 | 0.624 | 0.639 |
| R | 0.760 | 0.732 | 0.789 | 0.805 | |
| MAE (m3/s) | 15.500 | 14.320 | 13.470 | 15.010 | |
| MARS4 | M5Tree4 | KELM4 | BMA4 | ||
| RMSE (m3/s) | 58.394 | 52.528 | 53.611 | 49.933 | |
| M4 | NSE | 0.511 | 0.605 | 0.588 | 0.643 |
| R | 0.715 | 0.779 | 0.767 | 0.808 | |
| MAE (m3/s) | 16.110 | 15.720 | 14.080 | 14.720 | |
| MARS5 | M5Tree5 | KELM5 | BMA5 | ||
| RMSE (m3/s) | 71.612 | 72.264 | 69.496 | 69.283 | |
| M5 | NSE | 0.266 | 0.252 | 0.308 | 0.313 |
| R | 0.524 | 0.505 | 0.555 | 0.562 | |
| MAE (m3/s) | 26.860 | 23.910 | 21.360 | 25.040 | |
| MARS6 | M5Tree6 | KELM6 | BMA6 | ||
| RMSE (m3/s) | 54.154 | 58.372 | 51.473 | 51.212 | |
| M6 | NSE | 0.580 | 0.512 | 0.620 | 0.624 |
| R | 0.762 | 0.715 | 0.794 | 0.790 | |
| MAE (m3/s) | 15.570 | 16.310 | 15.690 | 14.410 |
| Category | Assessment Indexes | MARS1 | M5Tree1 | KELM1 | BMA1 |
|---|---|---|---|---|---|
| RMSE (m3/s) | 30.429 | 31.367 | 29.498 | 28.396 | |
| M1 | NSE | 0.397 | 0.360 | 0.434 | 0.475 |
| R | 0.688 | 0.670 | 0.664 | 0.689 | |
| MAE (m3/s) | 9.910 | 10.390 | 7.380 | 7.850 | |
| MARS2 | M5Tree2 | KELM2 | BMA2 | ||
| RMSE (m3/s) | 34.026 | 31.972 | 29.730 | 29.083 | |
| M2 | NSE | 0.247 | 0.335 | 0.425 | 0.449 |
| R | 0.642 | 0.654 | 0.667 | 0.670 | |
| MAE (m3/s) | 10.760 | 9.900 | 7.600 | 7.840 | |
| MARS3 | M5Tree3 | KELM3 | BMA3 | ||
| RMSE (m3/s) | 32.925 | 32.554 | 30.346 | 29.321 | |
| M3 | NSE | 0.294 | 0.310 | 0.401 | 0.440 |
| R | 0.656 | 0.658 | 0.648 | 0.664 | |
| MAE (m3/s) | 10.490 | 13.180 | 7.700 | 7.940 | |
| MARS4 | M5Tree4 | KELM4 | BMA4 | ||
| RMSE (m3/s) | 31.896 | 31.648 | 29.923 | 28.972 | |
| M4 | NSE | 0.337 | 0.347 | 0.416 | 0.454 |
| R | 0.654 | 0.665 | 0.651 | 0.674 | |
| MAE (m3/s) | 10.540 | 11.720 | 7.550 | 7.990 | |
| MARS5 | M5Tree5 | KELM5 | BMA5 | ||
| RMSE (m3/s) | 37.917 | 38.960 | 35.990 | 34.657 | |
| M5 | NSE | 0.063 | 0.011 | 0.156 | 0.219 |
| R | 0.465 | 0.415 | 0.445 | 0.469 | |
| MAE (m3/s) | 15.410 | 19.110 | 11.960 | 11.870 | |
| MARS6 | M5Tree6 | KELM6 | BMA6 | ||
| RMSE (m3/s) | 30.690 | 31.417 | 29.723 | 29.092 | |
| M6 | NSE | 0.386 | 0.357 | 0.424 | 0.449 |
| R | 0.676 | 0.651 | 0.656 | 0.670 | |
| MAE (m3/s) | 9.730 | 11.800 | 7.610 | 8.190 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Alizamir, M.; Kim, N.W.; Kisi, O. Bayesian Model Averaging: A Unique Model Enhancing Forecasting Accuracy for Daily Streamflow Based on Different Antecedent Time Series. Sustainability 2020, 12, 9720. https://doi.org/10.3390/su12229720
Kim S, Alizamir M, Kim NW, Kisi O. Bayesian Model Averaging: A Unique Model Enhancing Forecasting Accuracy for Daily Streamflow Based on Different Antecedent Time Series. Sustainability. 2020; 12(22):9720. https://doi.org/10.3390/su12229720
Chicago/Turabian StyleKim, Sungwon, Meysam Alizamir, Nam Won Kim, and Ozgur Kisi. 2020. "Bayesian Model Averaging: A Unique Model Enhancing Forecasting Accuracy for Daily Streamflow Based on Different Antecedent Time Series" Sustainability 12, no. 22: 9720. https://doi.org/10.3390/su12229720