Artificial Intelligence Approach for Tomato Detection and Mass Estimation in Precision Agriculture



Abstract
:1. Introduction
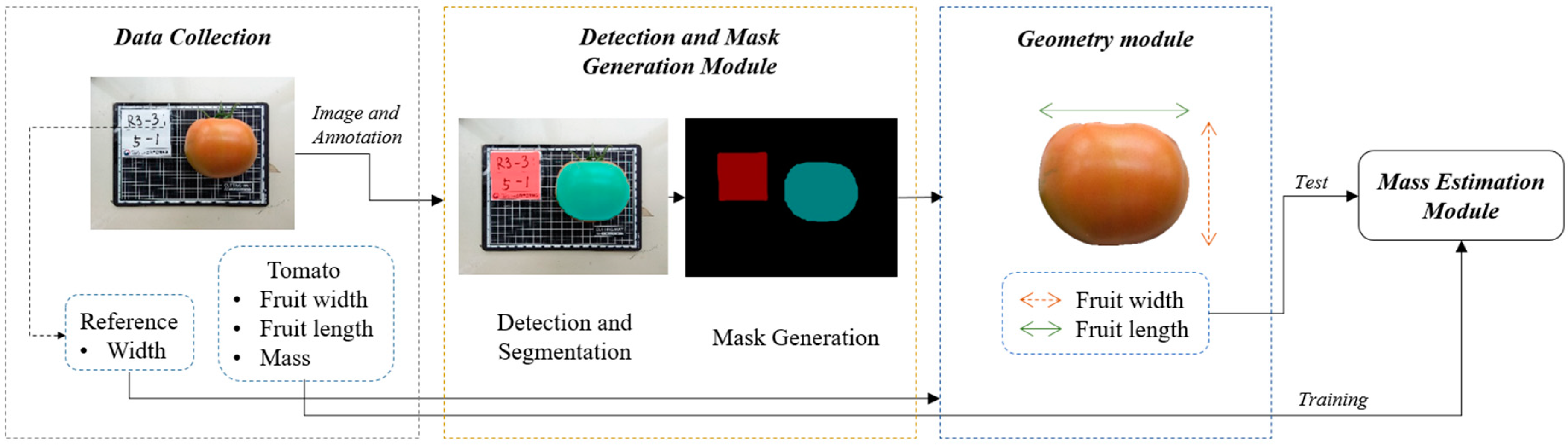
2. Materials and Methods
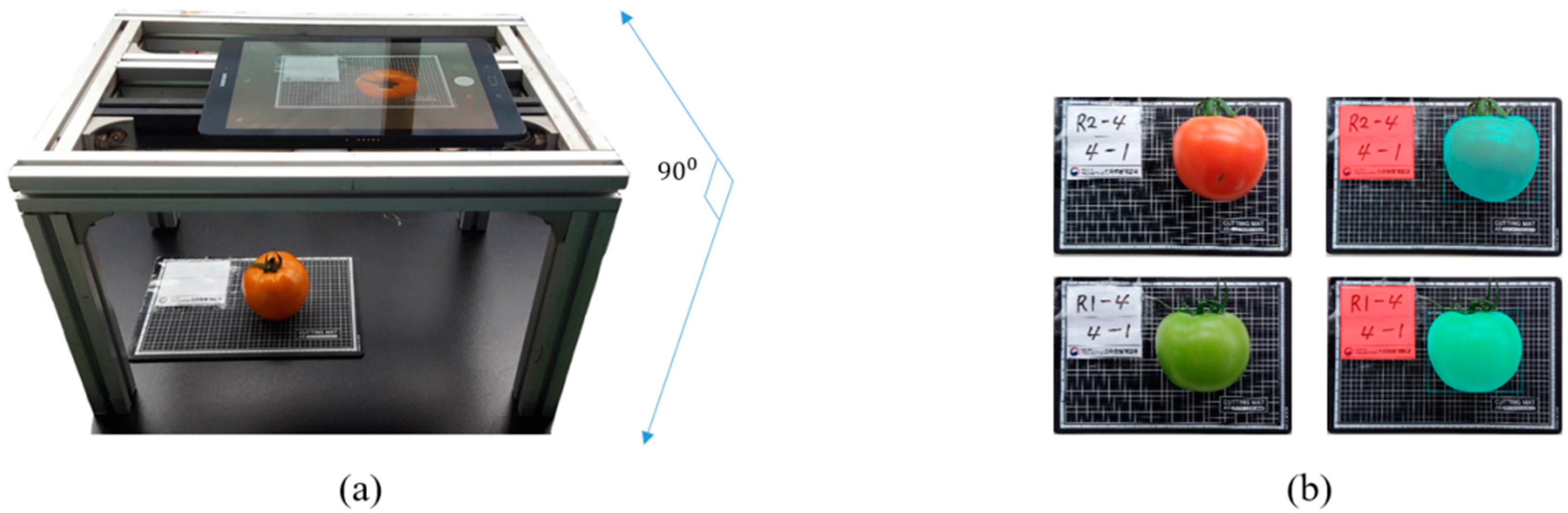
2.1. Data Collection and Annotation
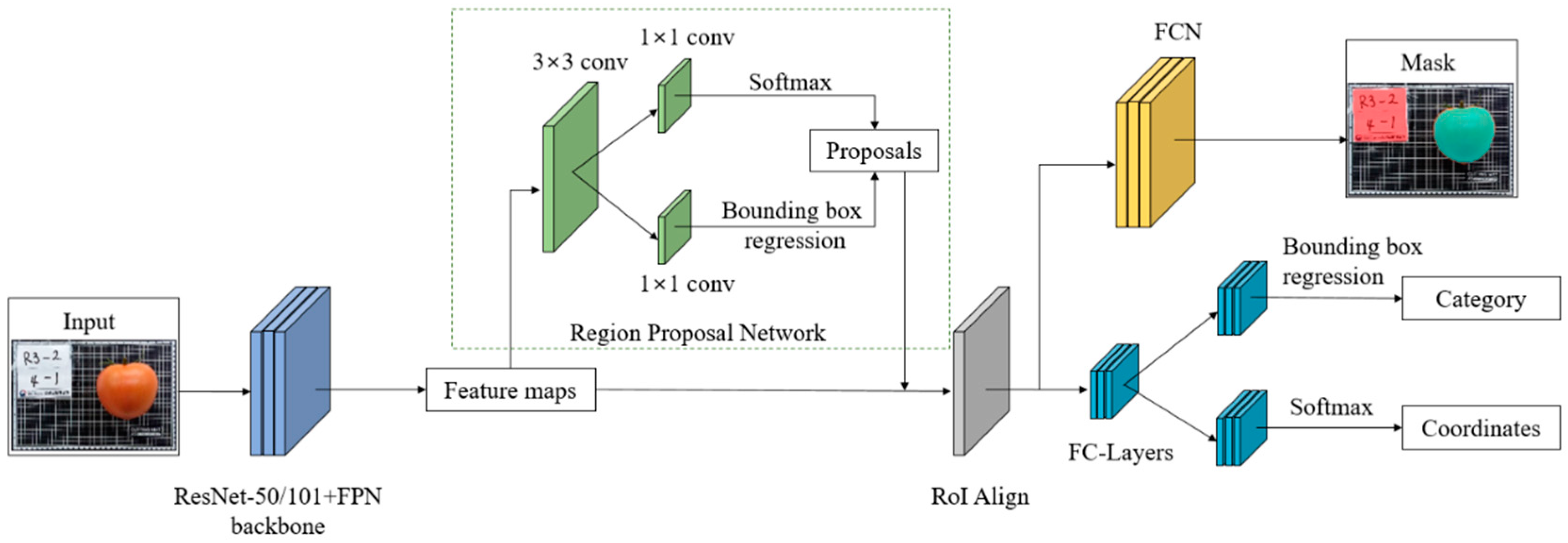
2.2. Detection and Mask Generation Module
2.3. Geometry Module
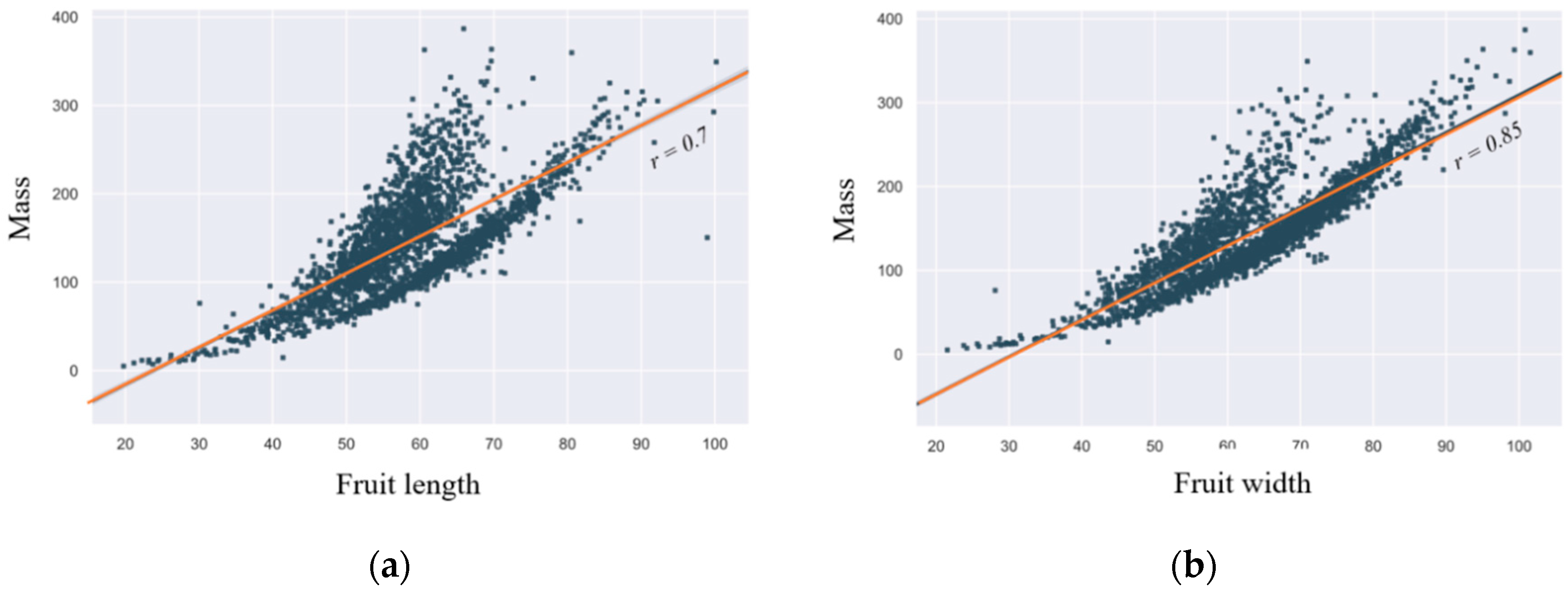
2.4. Mass Estimation Module
3. Results and Discussion
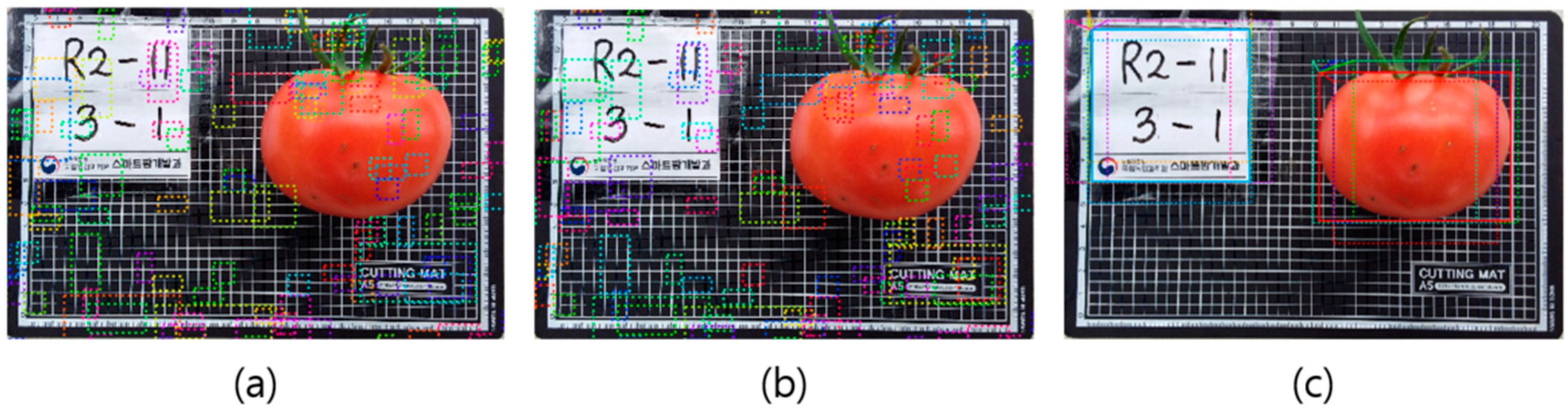
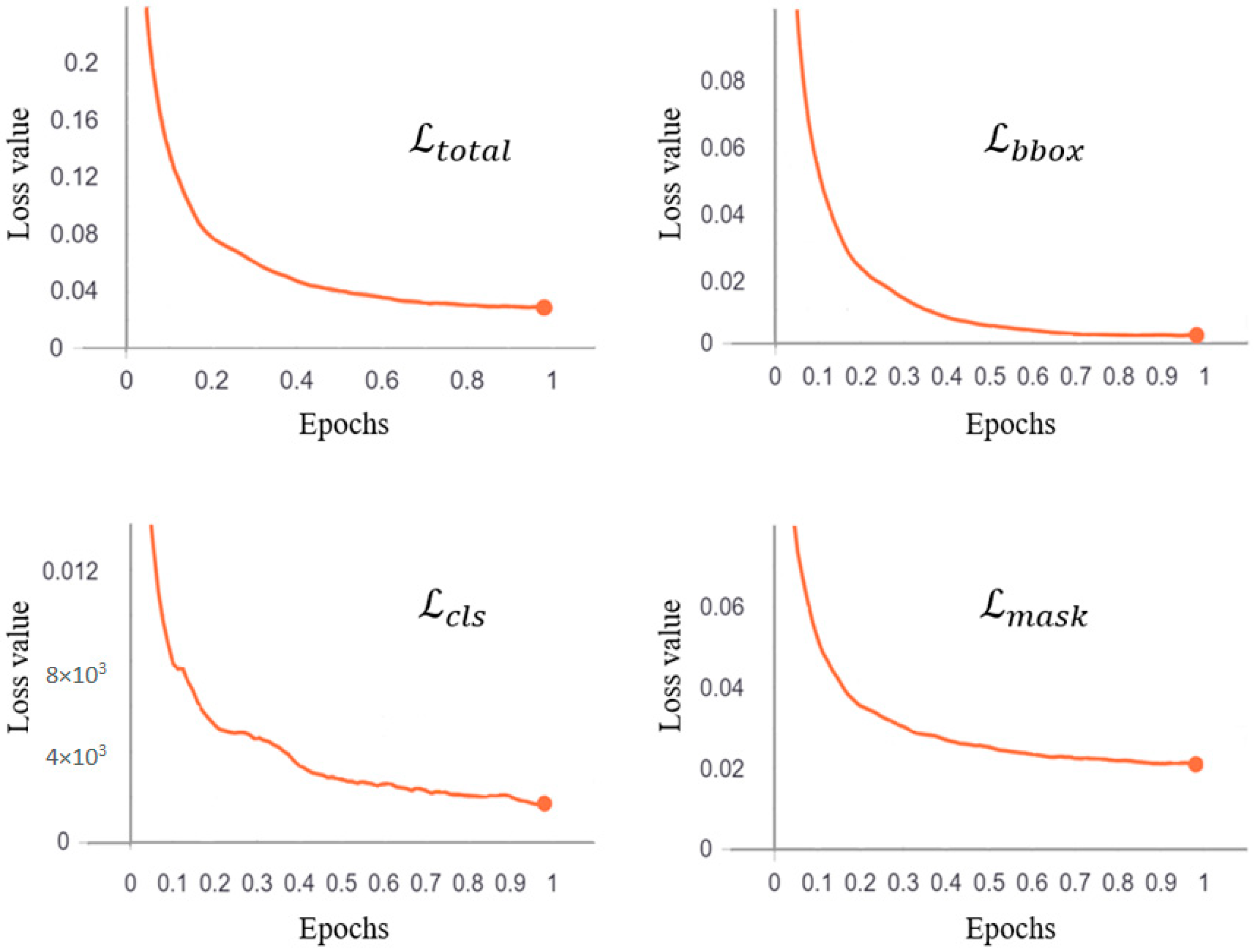
3.1. Evaluation of the Detection and Segmentation Module
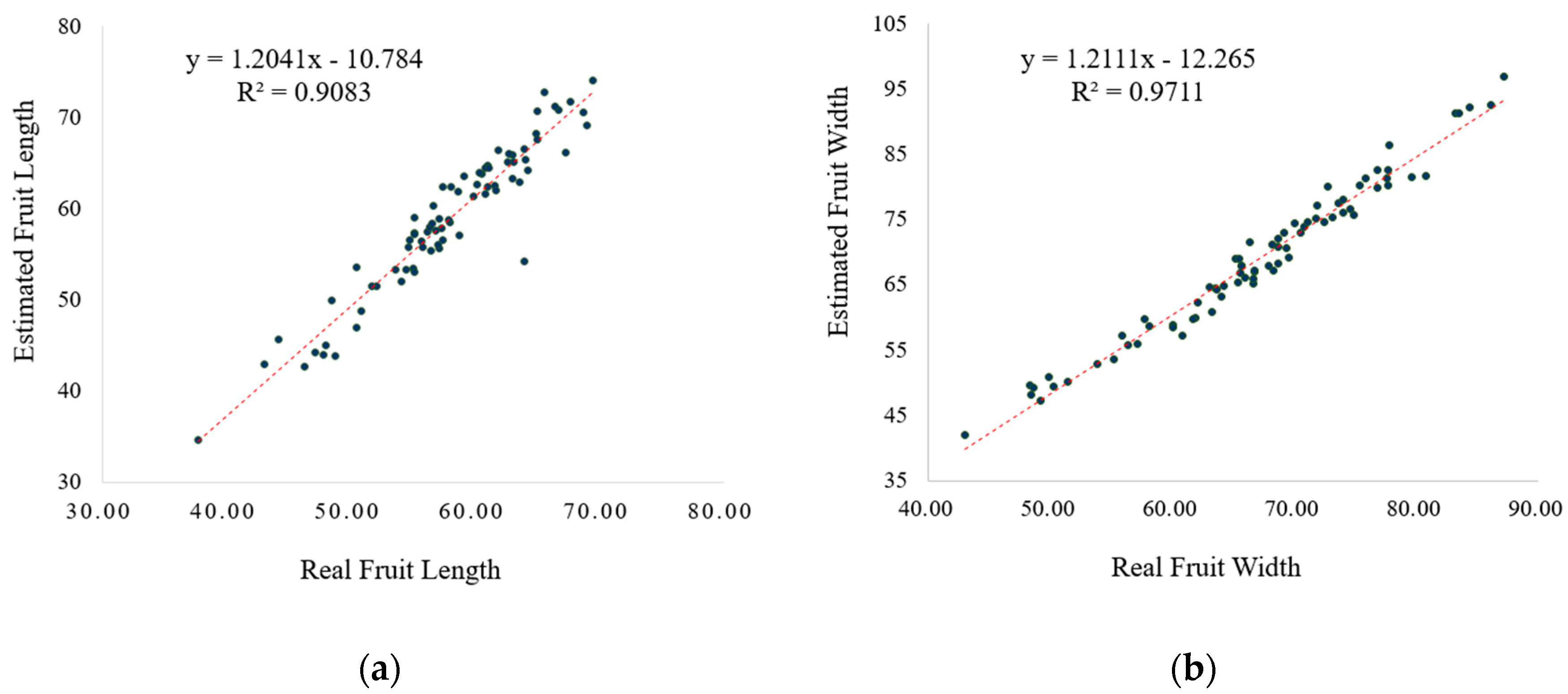
3.2. Evaluation of the Geometry Module
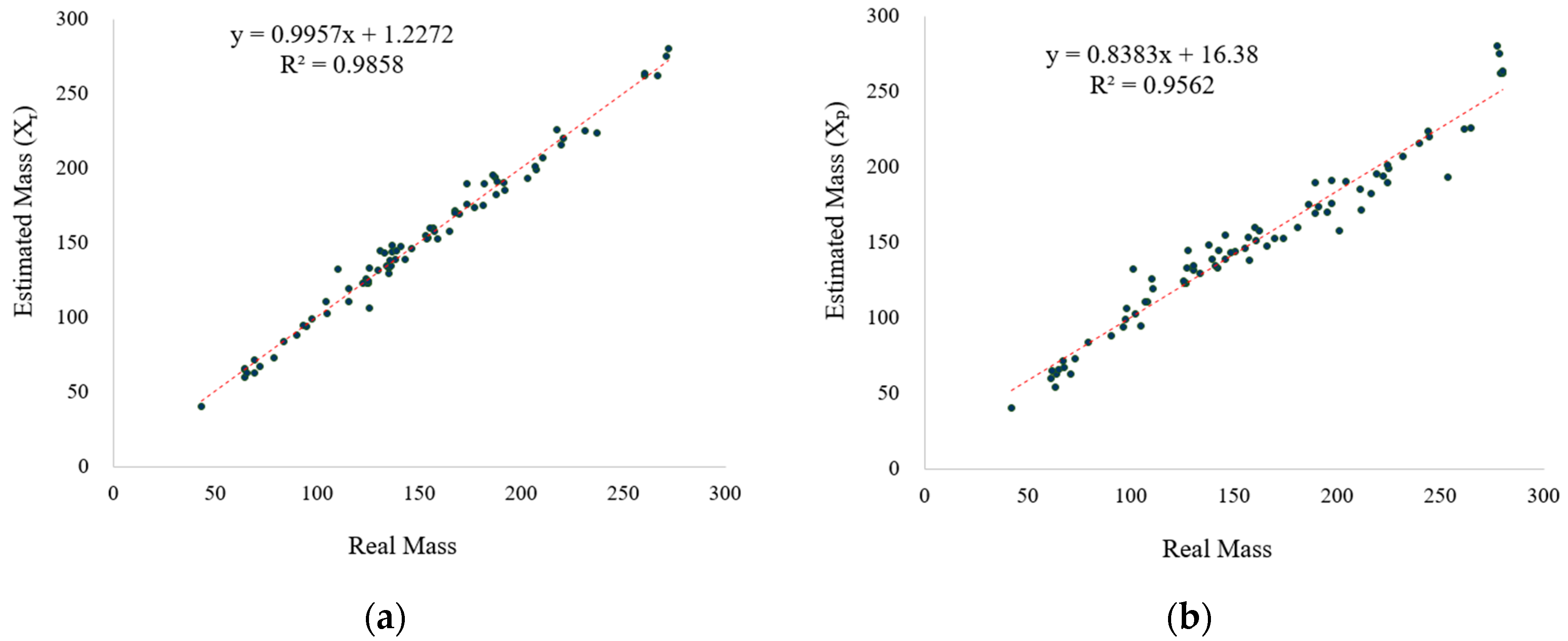
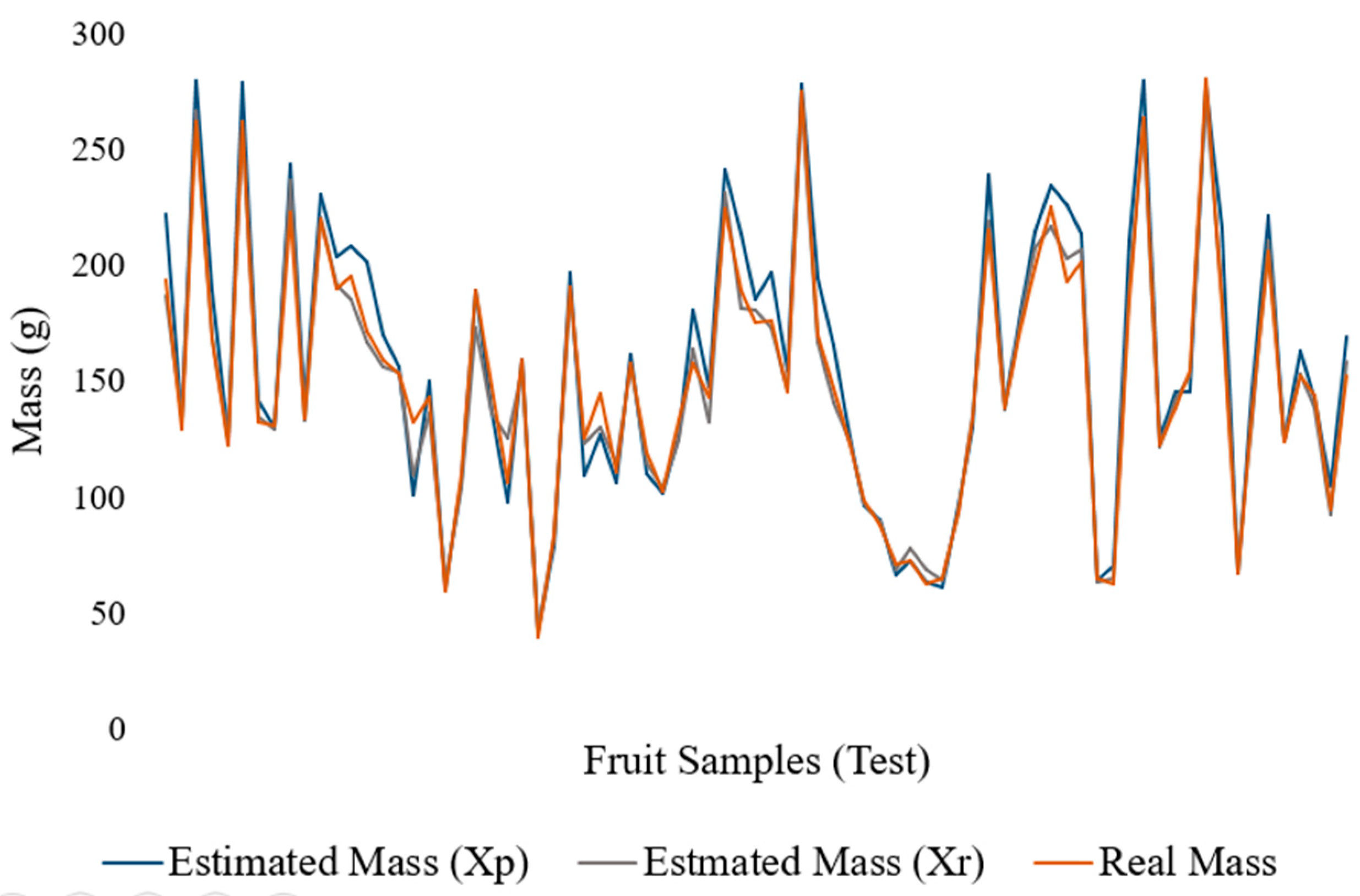
3.3. Evaluation of the Mass Estimation Module
4. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Sa’ad, F.S.A.; Ibrahim, M.F.; Shakaff, A.Y.; Zakaria, A.; Abdullah, M.Z. Shape and weight grading of mangoes using visible imaging. Comput. Electron. Agric. 2015, 115, 51–56. [Google Scholar] [CrossRef]
- Yamamoto, K.; Guo, W.; Yoshioka, Y.; Ninomiya, S. On plant detection of intact tomato fruits using image analysis and machine learning methods. Sensors 2014, 14, 12191–12206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kondo, N.; Ahmad, U.; Monta, M.; Murase, H. Machine vision based quality evaluation of Iyokan orange fruit using neural networks. Comput. Electron. Agric 2000, 29, 135–147. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J.P. Image segmentation for fruit detection and yield estimation in apple orchards. J. F. Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Lee, M.; Shin, C. IoT-based strawberry disease prediction system for smart farming. Sensors 2018, 18, 4051. [Google Scholar] [CrossRef] [Green Version]
- Choi, H.S.; Choi, H.S.; Du Mun, H. A Smart Fruits Quality Classification Hardware Design Using the Near-Infrared Spectroscopy and Image Processing Technologies. In Proceedings of the ICCC2018 International Conference on Convergence Content, Jeju, Korea, 17–19 December 2018. [Google Scholar]
- Vibhute, A.; Bodhe, K.S. Applications of image processing in agriculture: A survey. Int. J. Comput. Appl. 2012, 52, 34–40. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. Deepfruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [Green Version]
- FAOSTAT. Food and Agriculture Organization (FAO), Statistics. 2017. Available online: http://www.fao.org/faostat/en (accessed on 29 August 2019).
- Zhao, Y.; Gong, L.; Huang, Y.; Liu, C. A review of key techniques of vision-based control for harvesting robot. Comput. Electron. Agric. 2016, 127, 311–323. [Google Scholar] [CrossRef]
- Wachs, J.P.; Stern, H.I.; Burks, T.; Alchanatis, V. Low and high-level visual feature-based apple detection from multi-modal images. Precis. Agric. 2010, 11, 717–735. [Google Scholar] [CrossRef]
- Nuske, S.; Achar, S.; Bates, T.; Narasimhan, S.; Singh, S. Yield estimation in vineyards by visual grape detection. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011. [Google Scholar]
- Forbes, K.A.; Tattersfield, G.M. Estimating fruit volume from digital images. IEEE AFRICON Conf. 1999, 1, 107–112. [Google Scholar]
- Sabliov, C.M.; Boldor, D.; Keener, K.M.; Farkas, B.E. Image processing method to determine surface area and volume of axi-symmetric agricultural products. Int. J. Food Prop. 2002, 5, 641–653. [Google Scholar] [CrossRef]
- Wang, Q.; Nuske, S.; Bergerman, M.; Singh, S. Automated Crop Yield Estimation for Apple Orchards. In Experimental Robotics; Springer: Heidelberg, Germany, 2013; pp. 745–758. [Google Scholar]
- Hahn, F.; Sanchez, S. Carrot volume evaluation using imaging algorithms. J. Agric. Eng. Res. 2000, 75, 243–249. [Google Scholar] [CrossRef]
- Cheng, H.; Damerow, L.; Sun, Y.; Blanke, M. Early yield prediction using image analysis of apple fruit and tree canopy features with neural networks. J. Imaging 2017, 3, 6. [Google Scholar] [CrossRef]
- Mahesh, S.; Jayas, D.S.; Paliwal, J.; White, N.D.G. Hyperspectral imaging to classify and monitor quality of agricultural materials. J. Stored Prod. Res. 2015, 61, 17–26. [Google Scholar] [CrossRef]
- Nyalala, I.; Okinda, C.; Nyalala, L.; Makange, N.; Chao, Q.; Chao, L.; Yousaf, K.; Chen, K. Tomato volume and mass estimation using computer vision and machine learning algorithms: Cherry tomato model. J. Food Eng. 2019, 263, 288–298. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. IEEE Int. Conf. Robot. Autom. 2017, 3626–3633. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Haseeb, N.; Sook, Y.; Alvaro, F.; Park, D.S. Unsupervised image translation using adversarial networks for improved plant disease recognition. Comput. Electron. Agric. 2019, 168, 105117. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kainz, O.; Jakab, F.; Horecny, M.W.; Cymbalak, D. Estimating the object size from static 2D image. In Proceedings of the 2015 International Conference and Workshop on Computing and Communication (IEMCON), Vancouver, BC, Canada, 15–17 October 2015; pp. 1–5. [Google Scholar]
- Rosebrock, A. Measuring Size of Objects in an Image with OpenCV. Available online: https://www.pyimagesearch.com/2016/03/28/measuring-size-of-objects-in-animage-with-opencv (accessed on 1 November 2020).
- Mohsenin, N.N. Physical Properties of Plant and Animal Materials; Routledge: Abingdon-on-Thames, UK, 1986. [Google Scholar]
- Chaithanya, C.; Priya, S. Object weight estimation from 2D images. ARPN J. Eng. Appl. Sci. 2015, 10, 17. [Google Scholar]
- Wang, P.W.; Lin, C.J. Support vector machines. In Data Classification: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014; ISBN 9781466586758. [Google Scholar]
- Dutta, A.; Zisserman, A. The VGG Image Annotator (VIA). arXiv 2019, 10. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 3431–3440. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); DCFS: Tallahassee, FL, USA, 2014; pp. 740–755. [Google Scholar]
- Drucker, H.; Surges, C.J.C.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1997; pp. 155–161. [Google Scholar]
- Westreich, D.; Lessler, J.; Funk, M.J. Propensity score estimation: Neural networks, support vector machines, decision trees (CART), and meta-classifiers as alternatives to logistic regression. J. Clin. Epidemiol. 2010, 63, 826–833. [Google Scholar] [CrossRef] [Green Version]
- Seeger, M. Gaussian processes for machine learning. Int. J. Neural Syst. 2004, 14, 69–106. [Google Scholar] [CrossRef] [Green Version]
- Heckerman, D. A tutorial on learning with Bayesian networks. In Innovations in Bayesian Networks; Springer: Berlin, Germany, 2008. [Google Scholar]
- Williams, C.K.I. Prediction with Gaussian Processes: From Linear Regression to Linear Prediction and Beyond. In Learning in Graphical Models; Springer Science & Business Media: Berlin, Germany, 1998. [Google Scholar]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [Green Version]
- Bashiri, M.; Farshbaf Geranmayeh, A. Tuning the parameters of an artificial neural network using central composite design and genetic algorithm. Sci. Iran. 2011, 18, 1600–1608. [Google Scholar] [CrossRef] [Green Version]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- de Myttenaere, A.; Golden, B.; Le Grand, B.; Rossi, F. Mean absolute percentage error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mask-RCNN Backbone | Mask IoU | mAP |
|---|---|---|
| ResNet-50 + FPN | 95.32 | 90.13 |
| ResNet-101 + FPN | 96.05 | 93.30 |
| MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|
| Fruit width | 2.380 | 8.745 | 2.957 | 4.114 |
| Fruit length | 2.580 | 11.64 | 3.412 | 3.636 |
| MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|
| SVR (quadratic) 1 | 6.13 | 80.09 | 8.94 | 4.20 |
| SVR (RBF) 2 | 6.23 | 85.65 | 9.25 | 4.14 |
| Bagged ensemble tree | 4.76 | 41.51 | 6.44 | 3.39 |
| Exponential GPR | 4.71 | 42.72 | 6.53 | 3.21 |
| Neural network | 6.22 | 78.34 | 8.85 | 4.11 |
| MAE | MSE | RMSE | MAPE | |
|---|---|---|---|---|
| SVR (quadratic) 1 | 17.0159 | 572.8368 | 23.93401 | 10.03 |
| SVR(RBF) 2 | 15.98462 | 470.8138 | 21.69824 | 9.376872 |
| Bagged ensemble tree | 13.03521 | 325.7506 | 18.04856 | 7.900019 |
| Exponential GPR | 15.13498 | 421.6772 | 20.53478 | 9.095166 |
| Neural network | 15.11 | 417.12 | 20.42 | 9.06 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Nazki, H.; Baek, J.; Hong, Y.; Lee, M. Artificial Intelligence Approach for Tomato Detection and Mass Estimation in Precision Agriculture. Sustainability 2020, 12, 9138. https://doi.org/10.3390/su12219138
Lee J, Nazki H, Baek J, Hong Y, Lee M. Artificial Intelligence Approach for Tomato Detection and Mass Estimation in Precision Agriculture. Sustainability. 2020; 12(21):9138. https://doi.org/10.3390/su12219138
Chicago/Turabian StyleLee, Jaesu, Haseeb Nazki, Jeonghyun Baek, Youngsin Hong, and Meonghun Lee. 2020. "Artificial Intelligence Approach for Tomato Detection and Mass Estimation in Precision Agriculture" Sustainability 12, no. 21: 9138. https://doi.org/10.3390/su12219138