Review of Nitrogen Compounds Prediction in Water Bodies Using Artificial Neural Networks and Other Models


 , , , , and
, , , , and 
Abstract
:1. Introduction
2. Nitrogen Sources in Streams
3. Effects of Nitrogen
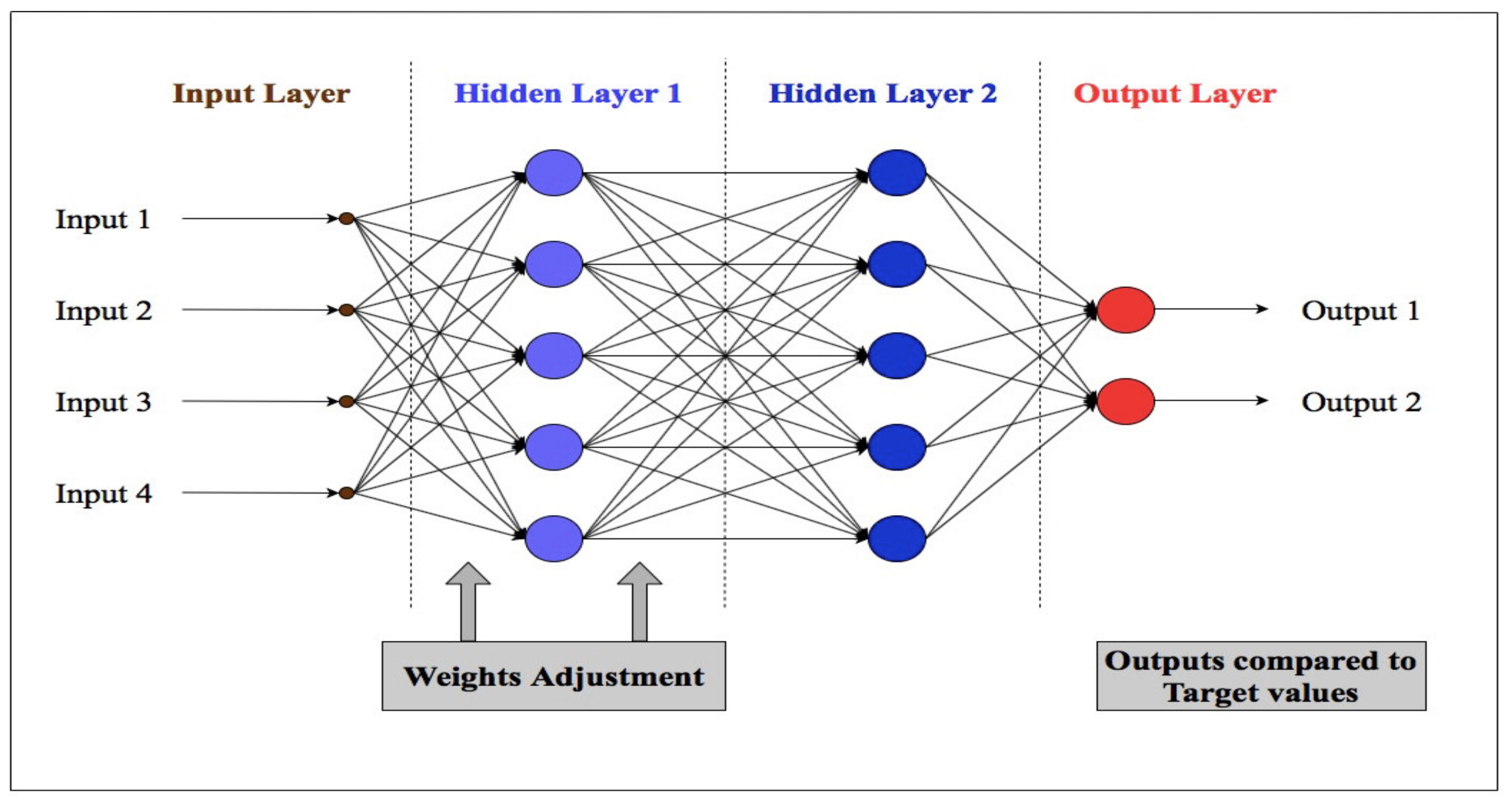
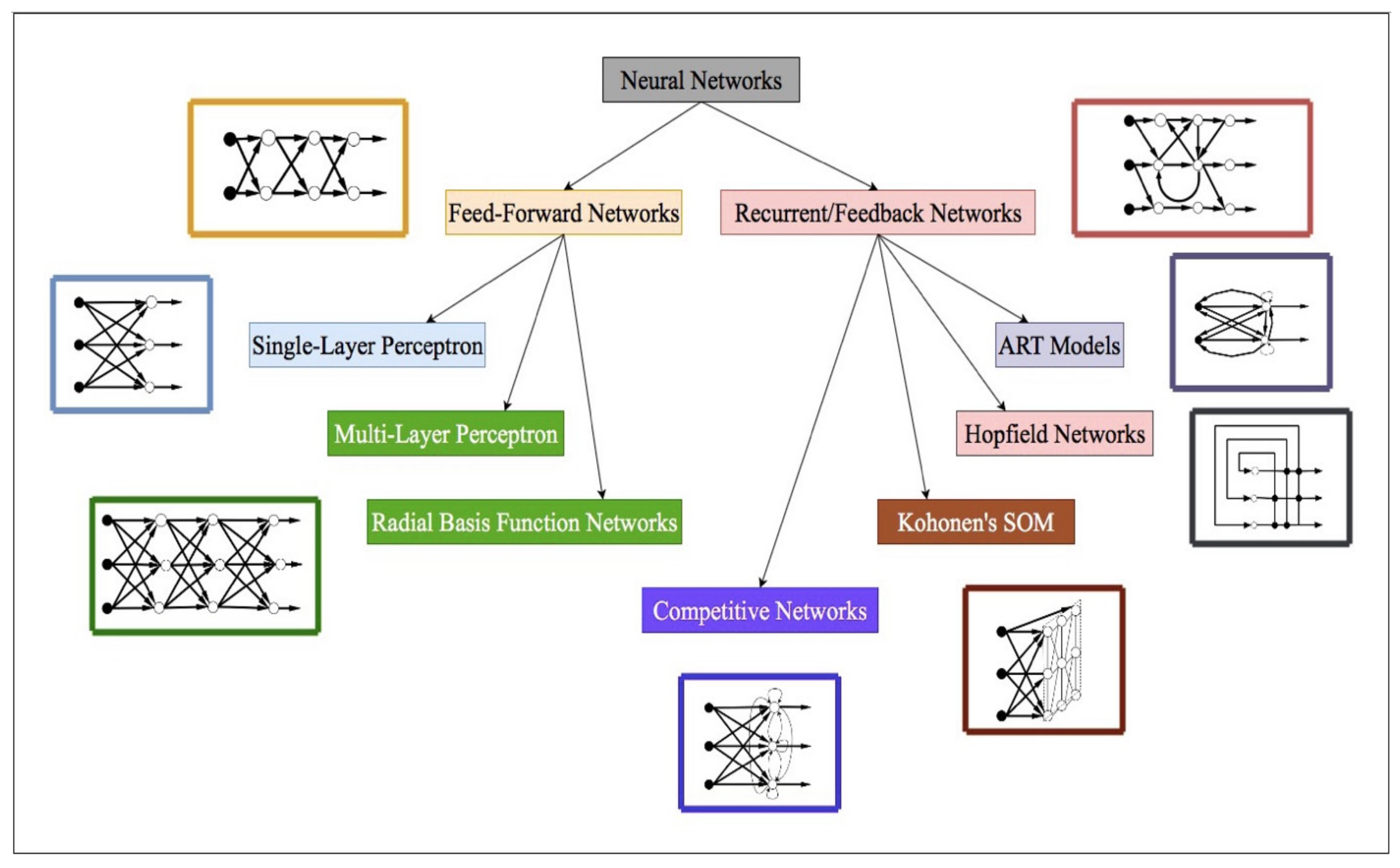
4. ANN
5. Hybrid Model
- ANN and genetic algorithm
- ANN and fruit fly optimization algorithm
- ANN and firefly algorithm
- ANN and artificial immune systems
- ANN and particle swarm-optimization algorithm
6. Methods and Evaluation
6.1. Nitrogen Monitoring
6.2. Application of ANN
7. Recommendation for Future Works
- a)
- Being the first step of modeling, the training is the most important part of the modeling procedure. Various kinds of important information are provided to the model during training. The model learns different patterns in the input data. Weights are updated during training [94]. Providing ample data for training can lead to better precision of the model. Input data is divided into three sets: training, testing and validation sets [95], and sometimes divided into two sets: training and testing set, depending on the model. Training set is used for updating the weights and biases of the model. Validation set is used for preventing the model from overfitting. While training, if the validation accuracy is decreasing, then the model seems to be overfitting and the training should be stopped. Testing set is used for testing the output of the model in order to confirm the accuracy of the model. These sets are divided on certain percentage of input data, either provided by user or divided, by default, by the model. By default, ANN modeling software uses 70% of the input data as the training data, which may be less for getting higher accuracy, 15% for validation and the remaining 15% for testing. In order to increase the accuracy of the model, we suggest using a higher percentage of data for training, i.e., about 80% to 90%. The remaining is to be divided equally for validation and testing. While dividing the input data into the training, validation and testing set, it should be ensured that these sets are statistically similar. In order to increase the learning capacity of the model, it should be ensured that the model is exposed to the maximum and minimum values of the inputs while training.
- b)
- The accuracy of the AI model also depends on the types of inputs provided to the model [96]. Since there are many input variables upon which the nitrogen in streams depends, we suggest considering all the relevant inputs and then performing a sensitivity analysis to select the highly sensitive input variables for the prediction. Some of the relevant inputs are daily average rainfall data, daily average river discharge, daily average water temperature, historical data of nitrogen in streams, land use pattern, Julian day, amount of fertilizer applied in the catchment area, and the amount of nitrogen per day added from point sources. Using many input variables leads to the increase in the complexity of the network, which often effects the results of the network. To avoid this complexity, the user should avoid selecting the inter-dependent variables, for example: if the runoff data is included in the input data then the precipitation data can be avoided because runoff is dependent on precipitation and has the same pattern as that of precipitation.
- c)
- ANN is divided into different types, which are utilized for modeling hydrological parameters having different complexity levels. For creating a model involving a huge set of input variables, we suggest creating a hybrid model, which has higher accuracy. The ANN model has to be clipped with other models to create a hybrid model, and hence, it improves the accuracy of the resultant model. Zhang, Zhang and Li [87] utilized a hybrid model (ARIMA and RBFNN) to predict the monthly total nitrogen, and the mean absolute percentage error was reduced to 7.017%. However, in this case, they used only historical monthly data as input to the hybrid model; hence, a hybrid model with a wide range of relevant stochastic input variables will attain increased accuracy.
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Maloney, K.O.; Weller, D.E. Anthropogenic disturbance and streams: Land use and land-use change affect stream ecosystems via multiple pathways. Freshw. Biol. 2011, 56, 611–626. [Google Scholar] [CrossRef]
- Kilonzo, F.; Masese, F.O.; Van Griensven, A.; Bauwens, W.; Obando, J.; Lens, P.N.L. Spatial–temporal variability in water quality and macro-invertebrate assemblages in the Upper Mara River basin, Kenya. Phys. Chem. EarthParts A/B/C 2014, 67–69, 93–104. [Google Scholar] [CrossRef]
- Jacobs, S.R.; Breuer, L.; Butterbach-Bahl, K.; Pelster, D.E.; Rufino, M.C. Land use affects total dissolved nitrogen and nitrate concentrations in tropical montane streams in Kenya. Sci. Total Env. 2017, 603–604, 519–532. [Google Scholar] [CrossRef] [PubMed]
- Hessong, A. The Composition of Fertilizers. Available online: http://homeguides.sfgate.com/composition-fertilizers-48898.html (accessed on 26 June 2019).
- Salehi, F.; Prasher, S.O.; Amin, S.; Madani, A.; Jebelli, S.J.; Ramaswamy, H.S.; Tan, C.; Drury, C.F. Prediction of annual nitrate-n losses in drain outflows with artificial neural networks. Am. Soc. Agric. Eng. 2000, 43, 1137–1143. [Google Scholar] [CrossRef]
- Sharma, V.; Negi, S.C.; Rudra, R.P.; Yang, S. Neural networks for predicting nitrate-nitrogen in drainage water. Agric. Water Manag. 2003, 63, 169–183. [Google Scholar] [CrossRef]
- Fewtrell, L. Drinking-water nitrate, methemoglobinemia, and global burden of disease: A discussion. Environ. Health Perspect 2004, 112, 1371–1374. [Google Scholar] [CrossRef] [Green Version]
- Gallo, E.L.; Meixner, T.; Aoubid, H.; Lohse, K.A.; Brooks, P.D. Combined impact of catchment size, land cover, and precipitation on streamflow and total dissolved nitrogen: A global comparative analysis. Glob. Biogeochem. Cycles 2015, 29, 1109–1121. [Google Scholar] [CrossRef]
- Ward, M.H.; deKok, T.M.; Levallois, P.; Brender, J.; Gulis, G.; Nolan, B.T.; VanDerslice, J.; International Society for Environmental. Workgroup report: Drinking-water nitrate and health--recent findings and research needs. Environ. Health Perspect 2005, 113, 1607–1614. [Google Scholar] [CrossRef] [Green Version]
- Reddy, A.G.S.; Niranjan Kumar, K.; Subba Rao, D.; Sambashiva Rao, S. Assessment of nitrate contamination due to groundwater pollution in north eastern part of Anantapur District, A.P. India. Environ. Monit. Assess. 2009, 148, 463–476. [Google Scholar] [CrossRef]
- Hamed, Y.; Awad, S.; Ben Sâad, A. Nitrate contamination in groundwater in the Sidi Aïch–Gafsa oases region, Southern Tunisia. Environ. Earth Sci. 2013, 70, 2335–2348. [Google Scholar] [CrossRef]
- Rahmati, O.; Samani, A.N.; Mahmoodi, N.; Mahdavi, M. Assessment of the Contribution of N-Fertilizers to Nitrate Pollution of Groundwater in Western Iran (Case Study: Ghorveh–Dehgelan Aquifer). Water Qual. Expo. Health 2015, 7, 143–151. [Google Scholar] [CrossRef]
- Räike, A.; Pietiläinen, O.P.; Rekolainen, S.; Kauppila, P.; Pitkänen, H.; Niemi, J.; Raateland, A.; Vuorenmaa, J. Trends of phosphorus, nitrogen and chlorophyll a concentrations in Finnish rivers and lakes in 1975–2000. Sci. Total Environ. 2003, 310, 47–59. [Google Scholar] [CrossRef]
- Qiu, Y.; Shi, H.-C.; He, M. Nitrogen and Phosphorous Removal in Municipal Wastewater Treatment Plants in China: A Review. Int. J. Chem. Eng. 2010, 2010, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.S.; Swaney, D.P.; Li, X.Y.; Hong, B.; Howarth, R.W.; Ding, S.H. Anthropogenic point-source and non-point-source nitrogen inputs into Huai River basin and their impacts on riverine ammonia–nitrogen flux. Biogeosciences 2015, 12, 4275–4289. [Google Scholar] [CrossRef] [Green Version]
- Indah Water, M. Ammonia. Available online: https://www.iwk.com.my/do-you-know/ammonia (accessed on 6 July 2019).
- Fogelman, S.; Blumenstein, M.; Zhao, H. Estimation of chemical oxygen demand by ultraviolet spectroscopic profiling and artificial neural networks. Neural Comput. Appl. 2005, 15, 197–203. [Google Scholar] [CrossRef]
- He, B.; Oki, T.; Sun, F.; Komori, D.; Kanae, S.; Wang, Y.; Kim, H.; Yamazaki, D. Estimating monthly total nitrogen concentration in streams by using artificial neural network. J. Env. Manag. 2011, 92, 172–177. [Google Scholar] [CrossRef]
- Holmberg, M.; Forsius, M.; Starr, M.; Huttunen, M. An application of artificial neural networks to carbon, nitrogen and phosphorus concentrations in three boreal streams and impacts of climate change. Ecol. Model. 2006, 195, 51–60. [Google Scholar] [CrossRef]
- Lek, S.; Guiresse, M.; Giraudel, J.-L. Predicting stream nitrogen concentration from watershed features using neural networks. Water Resour. Res. 1999, 33, 3469–3478. [Google Scholar] [CrossRef] [Green Version]
- Sarangi, A.; Bhattacharya, A.K. Comparison of Artificial Neural Network and regression models for sediment loss prediction from Banha watershed in India. Agric. Water Manag. 2005, 78, 195–208. [Google Scholar] [CrossRef]
- Ehtram, M.; Karami, H.; Mousavi, S.-F.; El-Shafie, A.; Amini, Z. Optimizing Dam and Reservoirs Operation Based Model Utilizing Shark Algorithm Approach. Knowl. -Based Syst. 2017. [Google Scholar] [CrossRef]
- Aguilera, P.A.; Frenich, A.G.; Torres, J.A.; Castro, H.; Vidal, J.L.M.; Canton, M. Application of the kohonen neural network in coastal water management: Methodological development for the assessment and prediction of water quality. Water Resources 2001, 35, 4053–4062. [Google Scholar] [CrossRef]
- Chang, L.-C.; Chang, F.-J. Intelligent control for modelling of real-time reservoir operation. Hydrol. Process. 2001, 15, 1621–1634. [Google Scholar] [CrossRef]
- Suen, J.-P.; Eheart, J.W. Evaluation of Neural Networks for Modeling Nitrate Concentrations in Rivers. J. Water Resour. Plan. Manag. ASCE 2003, 129, 505–510. [Google Scholar] [CrossRef]
- Zaheer, I.; Bai, C.-G. Application of artificial neural network for water quality management. Lowl. Technol. Int. 2003, 5, 10–15. [Google Scholar]
- Tayfur, G.; Swiatek, D.; Wita, A.; Singh, V.P. Case Study: Finite Element Method and Artificial Neural Network Models for Flow through Jeziorsko Earthfill Dam in Poland. J. Hydraul. Eng. 2005, 131, 431–440. [Google Scholar] [CrossRef]
- Mazvimavi, D.; Meijerink, A.M.J.; Savenije, H.H.G.; Stein, A. Prediction of flow characteristics using multiple regression and neural networks: A case study in Zimbabwe. Phys. Chem. EarthParts A/B/C 2005, 30, 639–647. [Google Scholar] [CrossRef]
- He, B.; Takase, K. Application of the Artificial Neural Network Method to Estimate the Missing Hydrologic Data. J. Jpn. Soc. Hydrol. Water Resour. 2006, 19, 249–257. [Google Scholar] [CrossRef] [Green Version]
- Cigizoglu, H.K.; Alp, M. Rainfall-Runoff Modelling Using Three Neural Network Methods. ICAISC 2004, 166–171. [Google Scholar]
- Riad, S.; Mania, J.; Bouchaou, L.; Najjar, Y. Rainfall-runoff model usingan artificial neural network approach. Math. Comput. Model. 2004, 40, 839–846. [Google Scholar] [CrossRef]
- Shamseldin, A.Y.; Nasr, A.E.; O’Connor, K.M. Comparison of different forms of the Multi-layer Feed-Forward Neural Network method used for river flow forecasting. Hydrol. Earth Syst. Sci. Discuss. 2002, 6, 671–684. [Google Scholar] [CrossRef]
- Teschl, R.; Randeu, W.L. A neural network model for short term river flow prediction. Nat. Hazards Earth Syst. Sci. 2006, 6, 629–635. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.L.; Chau, K.W. Rainfall–runoff modeling using artificial neural network coupled with singular spectrum analysis. J. Hydrol. 2011, 399, 394–409. [Google Scholar] [CrossRef] [Green Version]
- Gazzaz, N.M.; Yusoff, M.K.; Aris, A.Z.; Juahir, H.; Ramli, M.F. Artificial neural network modeling of the water quality index for Kinta River (Malaysia) using water quality variables as predictors. Mar. Pollut Bull. 2012, 64, 2409–2420. [Google Scholar] [CrossRef] [PubMed]
- Khalil, B.; Ouarda, T.B.M.J.; St-Hilaire, A. Estimation of water quality characteristics at ungauged sites using artificial neural networks and canonical correlation analysis. J. Hydrol. 2011, 405, 277–287. [Google Scholar] [CrossRef]
- Palani, S.; Liong, S.Y.; Tkalich, P. An ANN application for water quality forecasting. Mar. Pollut Bull. 2008, 56, 1586–1597. [Google Scholar] [CrossRef]
- Singh, K.P.; Basant, A.; Malik, A.; Jain, G. Artificial neural network modeling of the river water quality—A case study. Ecol. Model. 2009, 220, 888–895. [Google Scholar] [CrossRef]
- Suo, W.Q.; Dong-Bao, S.; Wei-Ping, H.; Yu-Zhong, L.; Xu-Rong, M.; Yan-Qing, Z. Human activities and nitrogen in waters. Acta Ecol. Sin. 2012, 32, 174–179. [Google Scholar] [CrossRef]
- USGS. Nitrogen and Water. Available online: https://www.usgs.gov/special-topic/water-science-school/science/nitrogen-and-water?qt-science_center_objects=0#qt-science_center_objects (accessed on 26 June 2019).
- Farid, A.M.; Lubna, A.; Choo, T.G.; Rahim, M.C.; Mazlin, M. A Review on the Chemical Pollution of Langat River, Malaysia. Asian J. Water Environ. Pollut. 2016, 13, 9–15. [Google Scholar] [CrossRef]
- Yi, Q.; Chen, Q.; Hu, L.; Shi, W. Tracking nitrogen sources, transformation and transport at a basin scale with complex plain river networks. Environ. Sci. Technol. 2017. [Google Scholar] [CrossRef]
- Nuruzzaman, M.; Mamun, A.A.; Salleh, M.N.B. Determining ammonia nitrogen decay rate of Malaysian river water in a laboratory flume. Int. J. Environ. Sci. Technol. 2017, 15, 1249–1256. [Google Scholar] [CrossRef] [Green Version]
- Rabalais, N.N.; Turner, R.E.; Scavia, D. Beyond Science into Policy: Gulf of Mexico Hypoxia and the Mississippi River. Bioscience 2002, 52, 129–142. [Google Scholar] [CrossRef] [Green Version]
- Rabalais, N.N.; Turner, R.E. Oxygen depletion in the gulf of mexico adjacent to the mississippi river. Past Present Water Column Anoxia 2006, 225–245. [Google Scholar]
- Hessen, D.O.; Hindar, A.; Holtan, G. The Significance of Nitrogen Runoff for Eutrophication of Freshwater and Marine Recipients. R. Swed. Acad. Sci. 1997, 26, 312–320. [Google Scholar]
- Dodds, W.; Smith, V. Nitrogen, phosphorus, and eutrophication in streams. Inland Waters 2016, 6, 155–164. [Google Scholar] [CrossRef]
- Dodds, W.K.K.; Welch, E.B. Establishing nutrient criteria in streams. J. N. Am. Benthol. Soc. 2000, 19, 186–196. [Google Scholar] [CrossRef]
- Murdoch, P.S.; Stoddard, J.L. The Role of Nitrate in the Acidification of Streams in the Catskill Mountains of New York. Water Resour. Res. 1992, 28, 2707–2720. [Google Scholar] [CrossRef]
- Gündüz, O. Water Quality Perspectives in a Changing World. Water Qual. Expo. Health 2015, 7, 1–3. [Google Scholar] [CrossRef] [Green Version]
- Su, X.; Wang, H.; Zhang, Y. Health Risk Assessment of Nitrate Contamination in Groundwater: A Case Study of an Agricultural Area in Northeast China. Water Resour. Manag. 2013, 27, 3025–3034. [Google Scholar] [CrossRef]
- He, S.; Wu, J. Hydrogeochemical Characteristics, Groundwater Quality, and Health Risks from Hexavalent Chromium and Nitrate in Groundwater of Huanhe Formation in Wuqi County, Northwest China. Expo. Health 2019, 11, 125–137. [Google Scholar] [CrossRef]
- Hossain, F.; Chang, N.-B.; Wanielista, M.; Xuan, Z.; Daranpob, A. Nitrification and Denitrification in a Passive On-site Wastewater Treatment System with a Recirculation Filtration Tank. Water Qual. Expo. Health 2010, 2, 31–46. [Google Scholar] [CrossRef]
- Gulis, G.; Czompolyova, M.; R Cerhan, J. An Ecologic Study of Nitrate in Municipal Drinking Water and Cancer Incidence in Trnava District, Slovakia. Environ. Res. 2002, 88, 182–187. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Wu, H.; Qian, H.; Gao, Y. Assessing Nitrate and Fluoride Contaminants in Drinking Water and Their Health Risk of Rural Residents Living in a Semiarid Region of Northwest China. Expo. Health 2017, 9, 183–195. [Google Scholar] [CrossRef]
- Sawyer, C.N.; McCarty, P.L.; Parkin, G.F. Chemistry for Environmental Engineering and Science, 5th ed.; McGraw Hill: New York, NY, USA, 2003; p. 667. [Google Scholar]
- Aslan, S.; Turkman, A. Biological denitrification of drinking water using various natural organic solid substrates. Water Sci. Technol. A J. Int. Assoc. Water Pollut. Res. 2003, 48, 489–495. [Google Scholar] [CrossRef]
- Della Rocca, C.; Belgiorno, V.; Meric, S. Cotton-supported heterotrophic denitrification of nitrate-rich drinking water with a sand filtration post-treatment. Water SA 2005, 31, 229–236. [Google Scholar] [CrossRef] [Green Version]
- Akrami, S.A.; El-Shafie, A.; Jaafar, O. Improving Rainfall Forecasting Efficiency Using Modified Adaptive Neuro-Fuzzy Inference System (MANFIS). Water Resour Manag. 2013. [Google Scholar] [CrossRef]
- Farzad, F.; El-Shafie, A.H. Performance Enhancement of Rainfall Pattern – Water Level Prediction Model Utilizing Self-Organizing-Map Clustering Method. Water Resour Manag. 2016. [Google Scholar] [CrossRef]
- Anctil, F.; Filion, M.; Tournebize, J. A neural network experiment on the simulation of daily nitrate-nitrogen and suspended sediment fluxes from a small agricultural catchment. Ecol. Model. 2009, 220, 879–887. [Google Scholar] [CrossRef] [Green Version]
- El-Shafie, A.H.; El-Shafie, A.; Mazoghi, H.G.E.; Shehata, A.; Taha, M.R. Artificial neural network technique for rainfall forecasting applied to Alexandria, Egypt. Int. J. Phys. Sci. 2011, 6, 1306–1316. [Google Scholar] [CrossRef]
- Raju, M.M.; Srivastava, R.K.; Bisht, D.C.S.; Sharma, H.C.; Kumar, A. Development of Artificial Neural-Network-Based Models for the Simulation of Spring Discharge. Adv. Artif. Intell. 2011, 2011, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Shafie, A.H.E.; El-Shafie, A.; Almukhtar, A.; Taha, M.R.; Mazoghi, H.G.E.; Shehata, A. Radial basis function neural networks for reliably forecasting rainfall. J. Water Clim. Chang. 2012. [Google Scholar] [CrossRef]
- Xie, Y. Values and Limitations of Statistical Models. Res. Soc. Strat. Mobil 2011, 29, 343–349. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial Neural Networks: A Tutorial. IEEE 1996, 31–44. [Google Scholar] [CrossRef] [Green Version]
- El-Shafie, A.; Noureldin, A.; Taha, M.; Hussain, A.; Mukhlisin, M. Dynamic versus static neural network model for rainfall forecasting at Klang River Basin, Malaysia. Hydrol. Earth Syst. Sci. 2012, 1151–1169. [Google Scholar] [CrossRef] [Green Version]
- Voyant, C.; Muselli, M.; Paoli, C.; Nivet, M.-L. Numerical weather prediction (NWP) and hybrid ARMA/ANN model to predict global radiation. Energy 2012, 341–355. [Google Scholar] [CrossRef] [Green Version]
- Grosan, C.; Abraham, A. Intelligent Systems A Modern Approach; Springer: Berlin/Heidelberg, Germany, 2011; Volume 17. [Google Scholar]
- Fallah, S.N.; Deo, R.C.; Shojafar, M.; Conti, M.; Shamshirband, S. Computational Intelligence Approaches for Energy Load Forecasting in Smart Energy Management Grids: State of the Art, Future Challenges, and Research Directions. Energies 2018, 11, 596. [Google Scholar] [CrossRef] [Green Version]
- Fiyadh, S.S.; AlSaadi, M.A.; Jaafar, W.Z.; AlOmar, M.K.; Fayaed, S.S.; Mohd, N.S.; Hin, L.S.; El-Shafie, A. Review on heavy metal adsorption processes by carbon nanotubes. J. Clean. Prod. 2019, 783–793. [Google Scholar] [CrossRef]
- Martín-Martín, A.; Thelwall, M.; Orduna-Malea, E.; López-Cózar, E.D. Google Scholar, Microsoft Academic, Scopus, Dimensions, Web of Science, and OpenCitations’ COCI: A multidisciplinary comparison of coverage via citations. 2020. [Google Scholar]
- Kannel, P.R.; Lee, S.; Lee, Y.S.; Kanel, S.R.; Pelletier, G.J. Application of automated QUAL2Kw for water quality modeling and management in the Bagmati River, Nepal. Ecol. Model. 2007, 202, 503–517. [Google Scholar] [CrossRef]
- The Star. Five Water Treatment Plants Shut down due to Ammonia Pollution Fully Operational. Available online: https://www.thestar.com.my/news/nation/2019/04/06/five-water-treatment-plants-shut-down-due-to-ammonia-pollution-fully-operational/ (accessed on 26 June 2019).
- New Straits Times. Another Johor Water Treatment Plant Shuts down over Ammonia Pollution. Available online: https://www.nst.com.my/news/nation/2017/11/304914/update-another-johor-water-treatment-plant-shuts-down-over-ammonia (accessed on 26 June 2019).
- Rekacewicz, P. Nitrate Levels: Concentrations at River Mouths. Available online: http://www.grida.no/resources/5650 (accessed on 26 June 2019).
- Canadian Council of Ministers of the Environment. Canadian Water Quality Guidelines for the Protection of Aquatic Life; Ammonia: Regina, SK, Canada, 2010. [Google Scholar]
- Basheer, A.O.; Hanafiah, M.M.; J. Abdulhasan, M. A Study on Water Quality from Langat River, Selangor. Acta Sci. Malays. 2017, 1, 01–04. [Google Scholar] [CrossRef]
- Juahir, H.; Zain, S.M.; Yusoff, M.K.; Hanidza, T.I.; Armi, A.S.; Toriman, M.E.; Mokhtar, M. Spatial water quality assessment of Langat River Basin (Malaysia) using environmetric techniques. Env. Monit Assess. 2011, 173, 625–641. [Google Scholar] [CrossRef] [Green Version]
- Yan, W.; Mayorga, E.; Li, X.; Seitzinger, S.P.; Bouwman, A.F. Increasing anthropogenic nitrogen inputs and riverine DIN exports from the Changjiang River basin under changing human pressures. Glob. Biogeochem. Cycles 2010, 24. [Google Scholar] [CrossRef]
- Singh, K.P.; Malik, A.; Sinha, S. Water quality assessment and apportionment of pollution sources of Gomti river (India) using multivariate statistical techniques—A case study. Anal. Chim. Acta 2005, 538, 355–374. [Google Scholar] [CrossRef]
- Li, S.; Cheng, X.; Xu, Z.; Han, H.; Zhang, Q. Spatial and temporal patterns of the water quality in the Danjiangkou Reservoir, China. Hydrol. Sci. J. 2009, 54, 124–134. [Google Scholar] [CrossRef]
- Pernet-Coudrier, B.; Qi, W.; Liu, H.; Muller, B.; Berg, M. Sources and pathways of nutrients in the semi-arid region of Beijing-Tianjin, China. Env. Sci Technol 2012, 46, 5294–5301. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Li, X.; Su, J.; Zhao, H. Sources and mass fluxes of the main contaminants in a heavily polluted and modified river of the North China Plain. Env. Sci. Pollut. Res. Int. 2014, 21, 5678–5688. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Song, X.; Xia, J.; Yuan, R.; Zhang, Y.; Liu, X.; Han, D. Major element chemistry of the Huai River basin, China. Appl. Geochem. 2011, 26, 293–300. [Google Scholar] [CrossRef]
- Wang, B.; Oldham, C.; Hipsey, M.R. Comparison of Machine Learning Techniques and Variables for Groundwater Dissolved Organic Nitrogen Prediction in an Urban Area. Procedia Eng. 2016, 154, 1176–1184. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, G.X.; Li, R.R. Water Quality Analysis and Prediction Using Hybrid Time Series and Neural Network Models. J. Agr. Sci. Tech. 2016, 18, 975–983. [Google Scholar]
- Markus, M.; Hejazi, M.I.; Bajcsy, P.; Giustolisi, O.; Savic, D.A. Prediction of weekly nitrate-N fluctuations in a small agricultural watershed in Illinois. J. Hydroinform. 2010, 12, 251–261. [Google Scholar] [CrossRef]
- Amiri, B.J.; Nakane, K. Comparative prediction of stream water total nitrogen from land cover using artificial neural network and multiple linear regression approaches. Pol. J. Environ. Stud. 2009, 18, 151–160. [Google Scholar]
- Zeleňáková, M.; Čarnogurská, M.; Šlezingr, M.; Słyś, D. Model based on dimensional analysis for prediction of nitrogen and phosphorus concentration in the River Laborec. Hydrol. Earth Syst. Sci. Discuss. 2012, 9, 5611–5634. [Google Scholar] [CrossRef] [Green Version]
- Akrami, S.A.; El-Shafie, A.; Naseri, M.; Santos, C.A.G. Rainfall data analyzing using moving average (MA) model and wavelet multi-resolution intelligent model for noise evaluation to improve the forecasting accuracy. Neural Comput Applic 2014, 25, 1853–1861. [Google Scholar] [CrossRef]
- May, D.B.; Sivakumar, M. Prediction of urban stormwater quality using artificial neural networks. Environ. Model. Softw. 2009, 24, 296–302. [Google Scholar] [CrossRef]
- Markus, M.; Tsai, C.W.-S.; Demissie, M. Uncertainty of Weekly Nitrate-Nitrogen Forecasts Using Artificial Neural Networks. J. Environ. Eng. 2003, 129, 267–274. [Google Scholar] [CrossRef] [Green Version]
- Najah, A.; El-Shafie, A.; Karim, O.A.; Jaafar, O. Integrated versus isolated scenario for prediction dissolved oxygen at progression of water quality monitoring stations. Hydrol. Earth Syst. Sci. 2011, 15, 2693–2708. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, A.N.; El-Shafie, A.; Karim, O.A.; El-Shafie, A. An augmented wavelet de-noising technique with neuro-fuzzy inference system for water quality prediction. Int. J. Innov. Comput. Inf. Control. 2012, 8. [Google Scholar]
- Maier, H.R.; Dandy, G.C. Neural networks for the prediction and forecasting of water resources variables: A review of modelling issues and applications. Environ. Model. Softw. 2000, 15, 101–124. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Main Type | Model Name | Advantages | Disadvantages |
|---|---|---|---|
| FFNN (Feed-Forward Neural Network) | Single Layer Perceptron |
Easy to setup |
|
| Multi-Layer Perceptron |
|
| |
| RBFNN |
|
| |
| Recurrent/Feedback Network | ART (Adaptive Resonance Theory) model |
|
|
| Hopfield Network |
|
| |
| Kohonen’s SOM |
|
| |
| Competitive Network |
|
|
| Authors | Specific Area | Location | Method | |
|---|---|---|---|---|
| 1 | Anctil, Filion and Tournebize [61] | Streams | Melarchez, France | Stacked multilayer perceptron |
| 2 | He, Oki, Sun, Komori, Kanae, Wang, Kim and Yamazaki [18] | Streams | Japan | Feed-forward model |
| 3 | Holmberg, Forsius, Starr and Huttunen [19] | Streams | Finland | Backpropagation algorithm |
| 4 | Lek, Guiresse and Giraudel [20] | Streams | The United States | Multilayer feed-forward |
| 5 | Suen and Eheart [25] | Streams | Illinois, The United States | Backpropagation and radial basis |
| 6 | Sharma, Negi, Rudra and Yang [6] | Drainage water | Canada | Fast backpropagation and self-organizing radial basis |
| 7 | Wang et al. [86] | Groundwater | Australia | 13 machine learning models |
| 8 | Zhang et al. [87] | Lake | China | ARIMA, radial basis, and hybrid |
| 9 | Markus et al. [88] | Streams | Illinois | Backpropagation, Evolutionary Polynomial Regression (EPR), and Naïve Bayes Model (NBM) |
| 10 | Amiri and Nakane [89] | Stream | Japan | Backpropagation and Multiple Linear Regression (MLR) |
| 11 | Zeleňáková et al. [90] | Streams | Slovakia | Dimensional analysis |
| No. | Authors | Duration of Data | Data Pre-Processing | Internal Parameters |
|---|---|---|---|---|
| 1 | Anctil, Filion and Tournebize [61] | 1975–1993 (Daily) | Standardization (linearly) | 2 Inputs, 12 hidden neurons |
| 2 | He, Oki, Sun, Komori, Kanae, Wang, Kim and Yamazaki [18] | 1995 (Monthly) | Sensitivity Analysis | 8 Inputs, 7 hidden neurons |
| 3 | Holmberg, Forsius, Starr and Huttunen [19] | 1990–2000 (Daily) | - | 13 Inputs, 1 hidden layer, 7 nodes |
| 4 | Lek, Guiresse and Giraudel [20] | One year | Sensitivity Analysis, Autoscaling | 8 Input, 10 hidden neurons |
| 5 | Suen and Eheart [25] | 1993–2000, (Daily) | - | - |
| 6 | Sharma, Negi, Rudra and Yang [6] | 1991–1994, (Daily) | Sensitivity Analysis | Fast Backpropagation: 8 Inputs, 20 hidden neurons, learning rate: 0.02 RBFNN: Tolerance 20, spread 15 |
| 7 | Wang, Oldham and Hipsey [86] | 2006–2014, (401 samples) | - | - |
| 8 | Zhang, Zhang and Li [87] | 2006–2011, (Monthly) | - | ARIMA:
|
| 9 | Markus, Hejazi, Bajcsy, Giustolisi and Savic [88] | 1994–1999, (Weekly) | - | ANN: 4 Input, 2 hidden nodes, epochs: 100,000; performance gradient: 1E-10; goal: zero EPR equations: NBM equations: |
| 10 | Amiri and Nakane [89] | 2001, (Monthly) | Statistical Analysis | 6 Input nodes, 2 hidden nodes, 1 output nodes, 11,600 epochs |
| 11 | Zeleňáková, Čarnogurská, Šlezingr and Słyś [90] | 2003–2010, (Monthly) | Sensitivity Analysis | Dimensional analysis equations: |
| No. | Authors | Input Variables | Prediction Variables | Accuracy |
|---|---|---|---|---|
| 1 | Anctil, Filion and Tournebize [61] |
| Nitrate-nitrogen flux | Efficiency index = 0.888 |
| 2 | He, Oki, Sun, Komori, Kanae, Wang, Kim and Yamazaki [18] |
| Monthly total nitrogen concentrations | = 0.96 = 0.84 = 0.9 |
| 3 | Holmberg, Forsius, Starr and Huttunen [19] |
|
| Flux efficiency:
|
| 4 | Lek, Guiresse and Giraudel [20] |
| Inorganic and total nitrogen concentration | Correlation coefficient: Total nitrogen = 0.82 Inorganic nitrogen = 0.8 |
| 5 | Suen and Eheart [25] |
| Nitrate concentration | Overall accuracy:
|
| ||||
| ||||
| 6 | Sharma, Negi, Rudra and Yang [6] |
| Nitrate concentration | Correlation coefficient
|
| 7 | Wang, Oldham and Hipsey [86] |
| DON | R2 of best models:
|
| ||||
| 8 | Zhang, Zhang and Li [87] | Monthly data for total nitrogen |
| Mean absolute percentage error:
|
| 9 | Markus, Hejazi, Bajcsy, Giustolisi and Savic [88] |
|
| Root mean square error (RMSE) for ANN:
RMSE for EPR:
Critical success index for NBM:
|
| 10 | Amiri and Nakane [89] |
| Total nitrogen | R2 Value:
|
| 11 | Zeleňáková, Čarnogurská, Šlezingr and Słyś [90] |
| Nitrogen and phosphorus concentration | Average Uncertainty:
|
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, P.; Lai, S.H.; Wong, J.K.; Mohd, N.S.; Kamal, M.R.; Afan, H.A.; Ahmed, A.N.; Sherif, M.; Sefelnasr, A.; El-Shafie, A. Review of Nitrogen Compounds Prediction in Water Bodies Using Artificial Neural Networks and Other Models. Sustainability 2020, 12, 4359. https://doi.org/10.3390/su12114359
Kumar P, Lai SH, Wong JK, Mohd NS, Kamal MR, Afan HA, Ahmed AN, Sherif M, Sefelnasr A, El-Shafie A. Review of Nitrogen Compounds Prediction in Water Bodies Using Artificial Neural Networks and Other Models. Sustainability. 2020; 12(11):4359. https://doi.org/10.3390/su12114359
Chicago/Turabian StyleKumar, Pavitra, Sai Hin Lai, Jee Khai Wong, Nuruol Syuhadaa Mohd, Md Rowshon Kamal, Haitham Abdulmohsin Afan, Ali Najah Ahmed, Mohsen Sherif, Ahmed Sefelnasr, and Ahmed El-Shafie. 2020. "Review of Nitrogen Compounds Prediction in Water Bodies Using Artificial Neural Networks and Other Models" Sustainability 12, no. 11: 4359. https://doi.org/10.3390/su12114359