1. Introduction
With the new four modernizations strategy of automobile industry (electricity, networking, intelligence, and sharing), the new energy vehicle (NEV) industry in China has developed rapidly in recent years. Statistics from the Ministry of Public Security show that, by the end of 2020, the number of NEVs in China reached 4.92 million [
1]. Different from traditional fuel vehicles, NEVs collect a large amount of operating data, which can reflect user habits and the product performance of NEVs to a certain extent. In order to improve the efficiency of NEV product R&D, optimize the product performance, and accelerate the product upgrade speed, NEV operation big data mining will become an important foundation for the development of the NEV industry.
At present, NEV technology is far less mature than traditional fuel vehicles. There are many issues that need to be researched in the R&D and operation of NEV. Among them, battery life and energy consumption are the most concerning issues of OEM and consumers, and are closely related to the driving style of the driver. Therefore, the driving style is an important factor that needs to be considered in the research of NEV products. As an interactive bridge between the driver and the NEV, the driving style is an important parameter that indicates the driver’s personal characteristics. The correct recognition of driving style, which can deepen our understanding of driving behavior, has a great reference value for the research and development of driving assistance systems. Research on the recognition of driving style is beneficial for improving the energy efficiency and safety of NEVs.
Many efforts concerning driving style recognition have been made in recent years. In past research works, researchers usually use driving data to calculate the maximum, minimum, average, and other conventional statistical parameters to represent the user’s driving characteristics. However, conventional statistical parameters can only reflect the overall status of the driving style, and the detailed information in the driving fragment is lost. In order to build a model that can accurately recognize the driving behavior of NEVs, improve NEV products based on different driving behavior characteristics, improve product intelligence and driving experience, and promote the positive development of the NEV industry, this paper collects NEV high-frequency big data by CAN bus, extracts joint distributed feature parameters that can reflect the characteristics of driving behavior in time and space, and builds a driving style recognition model using a BP neural network algorithm.
The remainder of this paper is organized as follows.
Section 2 describes the related works.
Section 3 introduces the methodology.
Section 4 presents the results and discussions. Lastly, conclusions are drawn in
Section 5.
3. Methodology
In this paper, the main steps of driving style recognition method is: (1) NEV high-frequency big data acquisition; (2) joint distribution feature parameters extraction; (3) feature parameters optimization; (4) driving style classification; (5) driving style recognition.
3.1. NEV High-Frequency Big Data Acquisition
At present, according to national requirements in GB/T32960 [
23] of China, companies need to acquire real-time data on NEVs and upload the data to the national big data platform. The data acquisition frequency is usually 10 s per frame. At the highest frequency, it can reach 1 s per frame, whereas the data uploaded to the national big data platform is 30 s per frame. This data frequency is far from enough to study the driving behavior of NEV users. Take the NIO ES6 as an example: its 100 km acceleration time is only 4.7 s. If the data acquisition frequency is 10 s, the data characteristics of the vehicle during acceleration cannot be captured. Even if the data frequency is 1 s per frame, up to 5 frames of data can be obtained, and it is difficult to accurately represent the user’s actual accelerator pedal operation characteristics at this stage. In order to cover the important characteristics of the user’s driving behavior, we used the CAN bus to collect high-frequency big data; the frequency can be up to 100 Hz, which is 0.01 s per frame. Similarly, taking the NIO ES6 100 km acceleration test as an example, the number of data frames we can collect reaches 470 frames, which is sufficiently detailed to describe the characteristics of the user’s driving behavior changes during this time period.
In this paper, a certain brand of BEV operating in Tianjin is used to collect NEV high-frequency big data. The five selected vehicles have close on-line dates and are operated in the same region, which can reduce the influence of factors, such as region, driving conditions, and battery life. The pure electric driving range of the selected vehicles is 320 km.
According to the collected data field requirements in GB/T32960 “Technical specifications of remote service and management system for electric vehicle”, we acquired NEV operation data using on-board OBD system and CAN bus, and transmitted the data to NEV data remote monitoring platform, as shown in
Figure 1. The acquired NEV high-frequency big data mainly includes driving behavior data, charging data, battery data, motor data, DCDC data, etc. In addition to the data fields required by GB/T32960, we also collected steering wheel angle and longitudinal acceleration. By using big data clusters as support, the NEV data remote monitoring platform is based on the ADC-DA efficient R&D architecture, and monitors the real-time data of NEVs through the high concurrency of the clusters. The real-time data are stored in Oracle database.
In this paper, the data fields we focus on are those that reflect characteristics of driving behaviors, including timestamp, vehicle speed, steering wheel angle, and longitudinal acceleration. We extracted the monitoring data of five selected vehicles from February 2019 to September 2019 from the database. To reduce storage and improve computational efficiency, we only extracted the required data fields and few data fields for auxiliary analysis, as shown in
Table 1. Among them, the voltage and current are used to confirm the vehicle status and the subsequent energy consumption analysis. The total data volume is 18 GB.
3.2. Driving Style Feature Parameter Extraction
Generally, the data used in evaluating driving behavior mainly include vehicle speed, steering wheel angle, longitudinal acceleration, braking deceleration, etc. The statistical parameters are extracted to reflect the driving characteristic, such as maximum, minimum, mean, median, mode, standard deviation, etc. The statistical parameters can represent the driving behavior characteristics in the time dimension, but the simultaneity between vehicle speed and longitudinal acceleration, braking deceleration, or steering wheel rotation speed is missed. In order to distinguish acceleration segments and deceleration segments, we redefine the segment data with positive longitudinal acceleration as longitudinal acceleration, and the data with negative longitudinal acceleration as braking deceleration.
In order to characterize the driving style of drivers precisely, especially vigorous driving behaviors, such as rapid acceleration, rapid deceleration, and sharp turning, we propose using the joint distribution of vehicle speed and other fields for evaluating driving style. The joint distribution characteristic parameters [
24] can reflect the spatial relationship between vehicle speed and longitudinal acceleration, braking deceleration or steering wheel speed, and evaluate the temporal and spatial characteristics of driving behavior comprehensively.
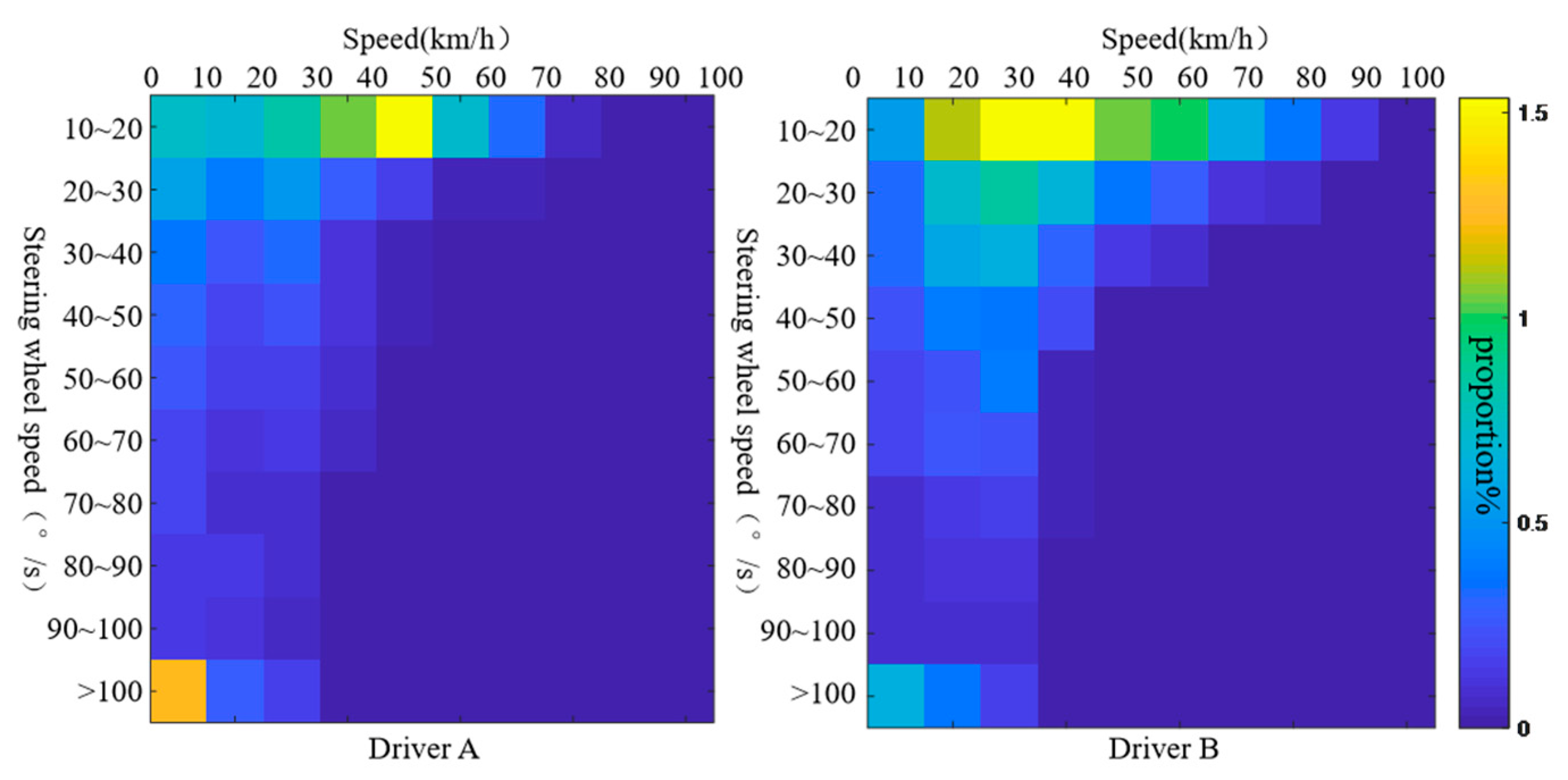
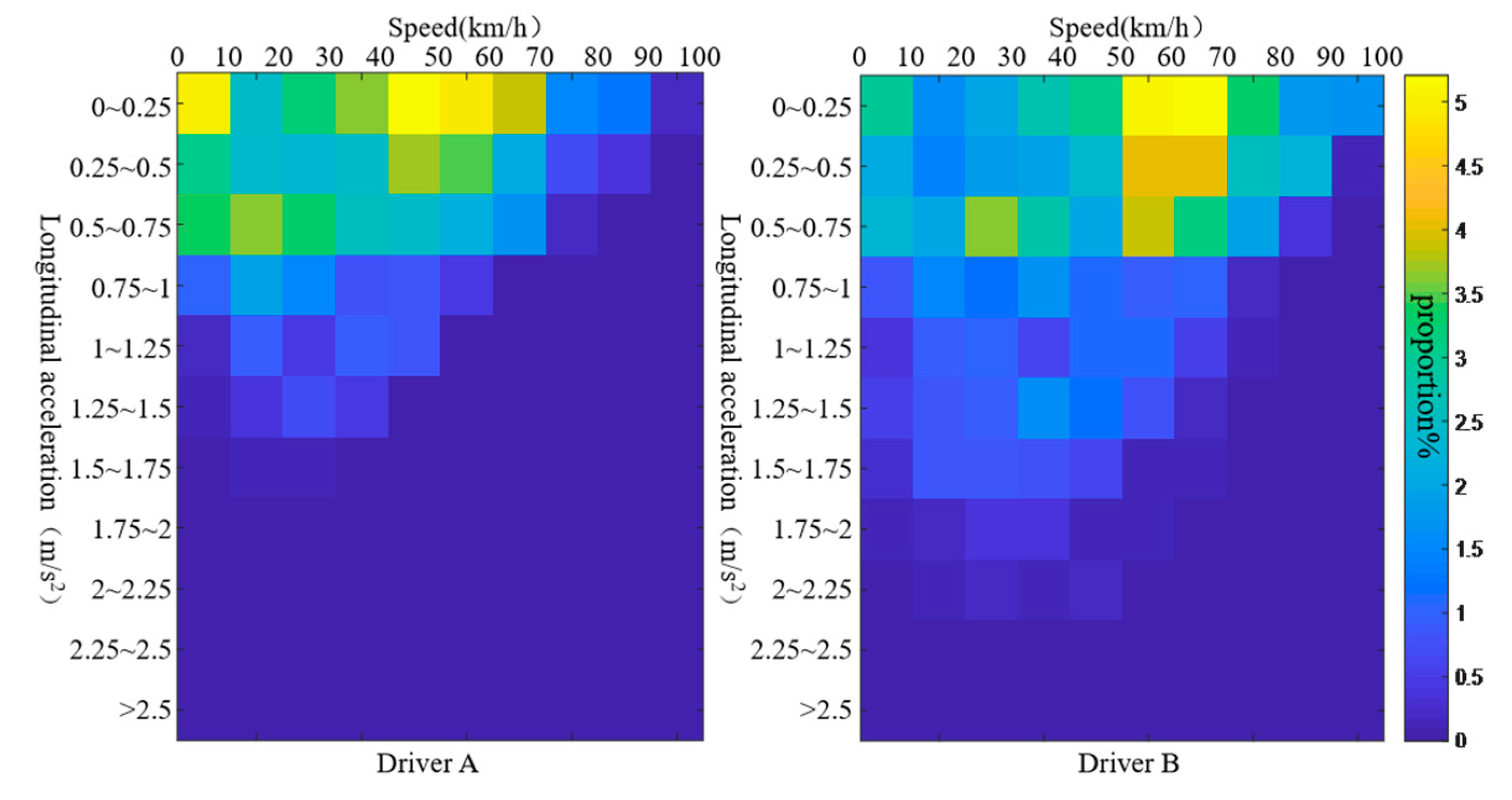
Taking a trip of driver A and a trip of driver B as examples, the joint distribution characteristic parameters of vehicle speed and longitudinal acceleration, braking deceleration, or steering wheel speed are extracted, respectively, as shown in
Figure 2,
Figure 3 and
Figure 4.
In
Figure 2, when the steering wheel speed is higher than 20°/s, the vehicle speed of driver A is concentrated below 30 km/h, whereas the vehicle speed of driver B is concentrated in the range of 10–50 km/h.
Figure 2 shows that the turning speed of driver B is higher than driver A. It can be seen from
Figure 3 and
Figure 4 that the joint distribution between vehicle speed–longitudinal acceleration and vehicle speed–brake deceleration of driver B is relatively scattered, and the vehicle speed, longitudinal acceleration, and braking deceleration are all higher than that of driver A.
Figure 3 and
Figure 4 show that the driving style of driver B is more intense than driver A.
3.3. Optimization of Driving Style Characteristic Parameters
The driving style characteristic parameters of this paper include a plurality of statistical parameters of NEV big data, the percentage of intervals, and three different joint distribution characteristics, totaling 383 dimensions. In order to minimize the resources required for calculation and maximize the retention of the information contained in the driving behavior characteristic parameters, the characteristic parameters need to be optimized for dimensionality reduction.
In this paper, we used principal component analysis algorithm to orthogonally transform the characteristic parameters of driving behavior. The characteristic parameters that may have a certain correlation with each other can be transformed into a linear and uncorrelated principal component. As shown in
Figure 5, the cumulative contribution rate of the first 35 principal components is over 85%. Therefore, the first 35 principal components can be used to represent the driving styles. The dimensionality reduction optimization processing reduces the complexity of the characteristic parameter matrix and can improve the calculation efficiency.
3.4. Automatic Classification of Driving Style
At present, the driving behaviors are usually divided into aggressive, normal, and mild driving behaviors based on the intensity of driving. Based on the characteristic parameters of driving behaviors in this paper, we use the clustering algorithm to realize the automatic classification of driving behavior intelligently and objectively.
The K-means algorithm randomly selects K points from the dataset as cluster center points, calculates the Euclidean distance between the data points of dataset and the cluster center points, and assigns them to the cluster center point with the smallest Euclidean distance. Then, it replaces original cluster center with the mean value of K-cluster, and iterates until the cluster center point remains unchanged or the sum of the squared errors reach local minimum. Among them, the formula for calculating Euclidean distance is
where
d is the Euclidean distance from the data point to the cluster center point,
n is the dimension of the data point,
xi is the characteristic parameter of the data point, and
ki is the characteristic parameter of the cluster center point.
The sum of the squared errors refers to the sum of clustering errors of all data points in the dataset, which can represent the clustering effect to a certain extent. The calculation formula is
where
SSE is the sum of squares of errors,
Ci represents the
i-type of data,
ki is the cluster center point of
Ci, and
x is any point in the
i-type of dataset.
3.5. Driving Style Recognition Model Construction
By K-means clustering algorithm, driving behavior is divided into five categories, and category labels are automatically generated. The classification results and data labels can be used as a training dataset for building a driving style recognition model. In this paper, BP neural network algorithm, which has strong inductive ability, is used to build a driving style model. BP neural network algorithm can obtain hidden data relationships from training data without prior assumptions, and deal with problems with unclear rules or complex internal relationships. The training optimization method of BP neural network is the gradient descent method. The input data of each neuron is
where
xi is the input feature and
wi is the connection weight.
If the Sigmoid function is used as the activation function, the hidden layer neuron output is
The training process of BP neural network includes forward propagation of information and back propagation of error. In the forward propagation process, the input of the previous layer is weighted, and becomes the input of the next layer, namely net. In the back propagation process, according to the difference between the actual output
y′ and the ideal output
y, the weight matrix is adjusted to minimize the error, and finally the error is controlled within a certain required range. The error of the sample data can be described as
The total error of the sample data set is . The algorithm will iterate until the parameters meet the requirements.
4. Results and Discussions
In this paper, the model was built and solved by Python. The output results are the driving behavior levels of all of the driving behavior fragments.
In theory, the larger the K value of the cluster number, the more accurate the classification. However, the larger K value is not conducive to the classification and analysis of real data. Therefore, it is necessary to first define the optimal cluster number K value. In this paper, we test the clustering effect of different clustering numbers K based on the driving behavior feature parameter set after the dimensionality reduction, as shown in
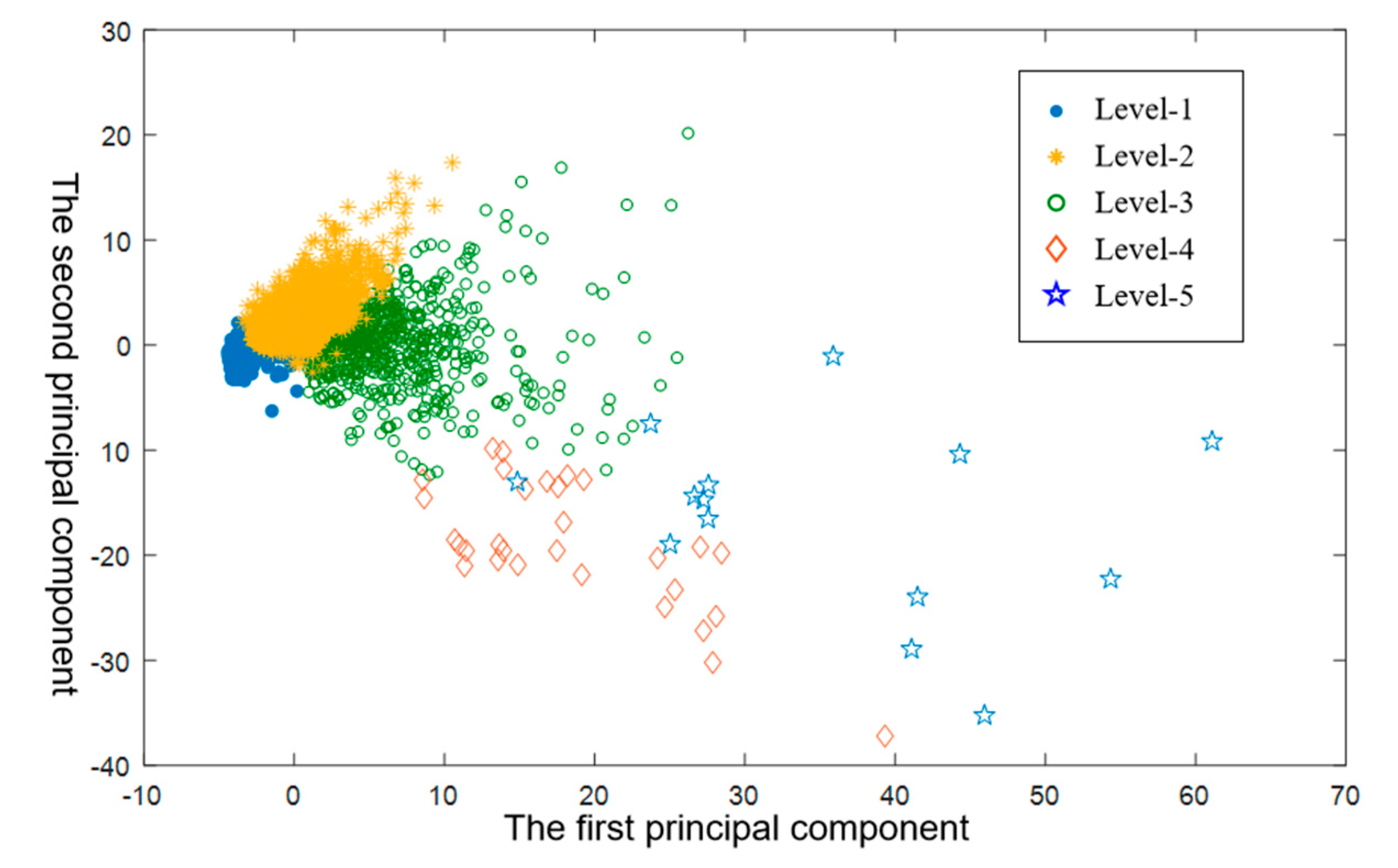
Figure 6. When K is less than 5, SSE drops sharply, indicating that, as K increases, the clustering effect is significantly improved. When K is greater than 5, the downward trend of SSE gradually weakens, indicating that the increase in K does not obviously improve the clustering effect. Therefore, we use 5 as the optimal number of clusters, and divide driving style into 5 levels, as shown in
Figure 7.
There are 4563 effective driving fragments in the high-frequency big data of this paper. Seventy percent of them are selected randomly as training samples, and the remaining 30% are selected as test samples. In order to speed up the learning process and avoid training non-convergence, the feature vector parameters are standardized and limited to the interval [0, 1].
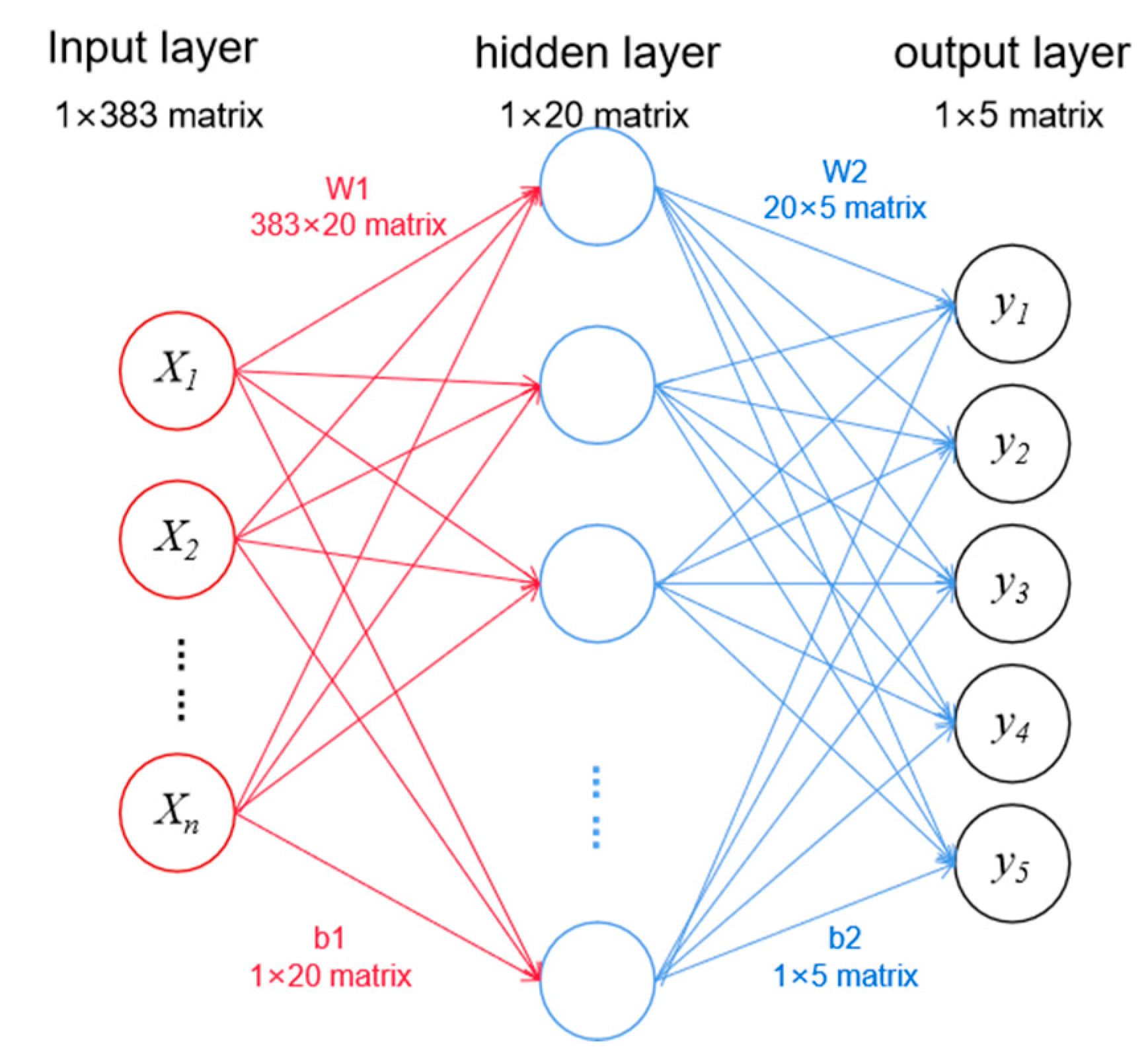
After experimental testing, a three-layer neural network driving style recognition model is established, as shown in
Figure 8. In
Figure 8,
Xi is a input layer node and represents a driving parameter, and
yi is an output layer node and represents the driving style level. The input layer has 383 driving style characteristic parameters, the output layer has 5 driving style levels, and the number of hidden layer nodes is 20. We select the BP algorithm training function tradingdx for network training, define the training parameters, and train the network combined with the number of hidden layer nodes in order to determine the driving style model parameters. The training parameters include a maximum network training times of 10,000, a learning rate of 0.02, and a target error of 1.0 × 10
−8.
We apply the driving behavior recognition model in
Figure 8 to the dataset of this paper, and recognize the driving styles of the 4563 effective driving fragments. In the results, 4417 driving styles are the same as in
Figure 7, and the recognition accuracy is 96.8%.
This paper uses joint distribution parameters and statistical parameter characteristic parameter sets. The characteristic parameter has 383 dimensions, among which, the joint distribution parameter has 320 dimensions, and the traditional statistical characteristic parameter has only 63 dimensions, as shown in
Table 2. Compared with the traditional driving behavior recognition method that only uses statistical feature parameters, this paper adds 320-dimension joint distribution feature parameters, which can describe the correlation between the vehicle speed and the steering wheel speed, acceleration, and deceleration during the driving stage. For example, in
Figure 2, when the steering wheel speed is in the range of 10–20°/s, the speed distributions of driver A and driver B are different, which expresses the difference in the driving style of the two drivers. Only statistical parameters extracted for the vehicle speed or steering wheel angle cannot express this information.
In order to discuss the influence of the feature parameter set on the driving style recognition result, we built a driving style recognition model using 63-dimension statistical feature parameters using the same method in
Figure 8. The number of input layer nodes is the same as the dimension of feature parameters, and the number of output layer nodes is the same as the number of driving style levels. Due to the reduction of input feature parameters, the number of nodes in the input layer of this model is reduced to 63. However, since the driving behavior is still divided into five levels according to
Figure 7, the number of nodes in the output layer remains unchanged. The number of nodes in the input layer is reduced, and the complexity of the model solution is reduced, so we redefine the number of nodes in the hidden layer to 10. Compared with the model in
Figure 8, the complexity of the new model is reduced, and the computing resources occupied are reduced. The parameters of the two driving behavior recognition models are shown in
Table 2.
Using the statistical parameters model and the 63-dimension statistical parameters of 4563 driving behavior fragments for driving style recognition, 4248 fragments can be correctly recognized, as shown in
Table 3. Compared with the joint analysis parameter sets model, the number of correct recognition fragments is reduced by 169. Most of the 169 driving behaviors with recognition errors are level 1, level 2, and level 3. In our opinion, the reason for the recognition error is that their statistical parameters are close to each other, and the subtle differences between driving behaviors in level 1 to level 3 cannot be distinguished.
The focus of this paper is to use new joint distribution feature parameters to represent driving behavior, instead of conventional statistical parameters, and to build a driving style recognition model based on these new parameters. We use the BP neural network algorithm because the BP algorithm has a strong generalization ability. Furthermore, the new joint distribution feature parameters can be applied to other modeling algorithms, such as SVM, random forest, Tri-CatBoost, ELM, etc.
It should be noted that we need to extract the joint distribution characteristic parameters from NEV high-frequency big data, so the method in this paper is not suitable for the low-frequency real-time big data currently being collected by the new energy vehicle industry in China. In addition, NEV high-frequency big data requires much higher storage equipment and computing resources than low-frequency data.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}