1. Introduction
Forest inventory is a systematic assessment and continuous monitoring of forest resources in a specific area, with the core objective of collecting and analyzing in-depth data on the structure, species diversity and ecological functions of forests, in order to gain a comprehensive understanding of the current state and future development potential of forests [
1]. In this process, in order to obtain exhaustive information about trees, such as number, height, diameter at breast height (DBH) and species, researchers usually choose ground measurement methods to take detailed measurements on predetermined sample plots. Among them, DBH measurement occupies a crucial position in the forest survey of sample plots. By measuring the DBH, researchers can accurately assess the growth trends and structural characteristics of the forest [
2]. These critical data are not only essential for the development of scientific forest management strategies, but also play an integral role in maintaining ecosystem integrity and monitoring the health of forests. Therefore, being able to accurately and efficiently measure DBH in sample plots is of far-reaching significance for improving the quality and efficiency of forest inventories [
3].
In the realm of forest inventory, the measurement of DBH has long relied on traditional manual methods. For instance, foresters often use contact measuring tools such as measuring tapes or calipers to measure directly around the trunk of a tree, and then use established formulas to convert the circumference data into a DBH value. A total station is an optical measurement tool that can estimate the DBH by evaluating the angle and distance between two points. In addition, the Haglof Electronic Diameter Meter provides a simplified method. Although it is primarily used to estimate tree height, it can also be used to measure DBH under certain conditions [
4,
5,
6]. Traditional methods of measuring DBH have proven their reliability in areas with flat terrain and a limited number of trees. However, when the demand extends to large-scale or real-time measurements, especially in complex terrain such as mountains, swamps, or dense forests, their efficiency and accuracy are seriously challenged. These challenges stem not only from the limitations of the methodology itself, but also from the complexity of operations, time constraints, and risks to personal safety in unknown environments [
7,
8,
9]. First, traditional methods usually require complex operational procedures, which can lead to significant time and labor cost increases in large-scale measurements [
10]. Second, due to time constraints, the measurement process may be compressed, which in turn affects its accuracy. Further, for trees with complex morphology or which are obscured by other vegetation and obstacles, the measurement accuracy of traditional methods may be significantly reduced [
7]. In summary, although the traditional methods are still applicable under specific conditions, their limitations in a wide range and complex application scenarios cannot be ignored [
10].
With the rapid development of modern technology, the emergence of advanced techniques such as LiDAR, Structure Restoration Motion (SFM) reconstruction techniques, and depth cameras have brought about unprecedented changes in the field of precision measurements. These technologies offer a rich source of information with high efficiency and accuracy of forest structure and tree parameters [
11,
12,
13,
14]. LiDAR technology, by emitting laser pulses and measuring the time of their reflection back to the ground, is capable of generating highly accurate 3D point cloud data [
11]. Meanwhile, SFM technology, by analyzing 2D images from multiple viewpoints, is also able to generate corresponding 3D point cloud data [
12]. Whether the point cloud data are obtained by LiDAR or SFM methods, a series of processing steps need to be followed in order to estimate the DBH of trees [
15]. First, for point cloud data on irregular ground, ground filtering is required to obtain a digital elevation model (DEM) [
16]. Subsequently, all point cloud data are normalized based on the DEM to obtain an approximately flat forest-like model. Next, by intercepting the point cloud at a fixed height, a subset of the point cloud with the “DBH height” of all trees in the sample plot can be obtained. Finally, the clustered subset of point clouds are fitted to circles or cylinders, respectively, and the DBH can be estimated [
16,
17,
18,
19,
20,
21].
Although these methods provide relatively accurate data, there are still some challenges in practical applications. For example, scanning times in some scenes via LiDAR can be as long as 40 min to 1.5 h [
17], while 3D reconstruction of a sample plot of 47 to 69 trees using SFM methods can take 7 to 11 h [
20]. In addition, LiDAR equipment, backpack LiDAR systems, and UAVs pose challenges for forestry surveyors to carry and maneuver in the forest due to their large size and weight (as shown in
Table 1). Offline forest inventory algorithms do not provide real-time operations, resulting in forestry surveyors not having instant access to measurement data. In addition to the limitations in operational performance, 3D unstructured point cloud data are highly variable in different scenarios. For example, in steep slope or ridge terrain point clouds, the error of ground filtering is still an unsolved problem [
22]. Ground filtering algorithms are usually not able to automatically adapt to different scenes [
23]. In the case of dense vegetation and complex terrain, the acquired point cloud data are not accurate, which can greatly limit the accuracy of the terrain surface, while heavily relying on empirical formulas for fitting the breast diameter for different tree species [
16,
20,
24]. The influence of factors makes point cloud-based ground object segmentation require developers to customize the algorithms for the characteristics of different forestry plots, which is one of the most important factors limiting its versatility. Meanwhile, its popularization in large-scale applications may be limited due to the high cost of high-precision LiDAR systems and high-performance computing equipment [
13].
In the current technological context, RGB-D (Red, Green, Blue-Depth) cameras represent a significant advancement over traditional imaging systems, particularly within agricultural and forestry applications [
25,
26]. These cameras not only capture the standard red, green, and blue (RGB) color data but also add depth information (D) by measuring the distance to objects using a sensor. This depth-sensing capability, often realized through techniques like Time-of-Flight or structured light, allows for the generation of a depth map, which, when fused with RGB data, results in a comprehensive 3D representation of the scene. The inclusion of depth data enables precise measurements of plant morphology and stand structure, offering detailed insights into canopy density and tree height. The relatively low cost and ease of operation further position RGB-D cameras as practical tools for high-resolution, large-scale data capture, providing valuable multidimensional information in real-time for various analytical and monitoring purposes [
14]. Fan et al. [
27] have pointed out the cost-effectiveness of RGB-D cameras compared to LiDAR systems in forest inventory and further developed an RGB-D-based SLAM system. Amelia et al. [
28] calculated the dominant depth values in a given area as the “trunk depth” and then filtered the pixels whose depths were much greater than the trunk depth, thus obtaining a mask of the main trunk of the tree. Based on traditional methods, the extraction of tree trunk ROI regions is always based on a large number of rules and assumptions of target states. For example, the center axis of the tree must almost overlap with the center line of the frame, and only one tree can appear in the image. Meanwhile the rough regularity algorithm will lead to a decrease in the accuracy of segmentation, resulting in insufficient accuracy of the measured data based on the masked region. Sun et al. [
29] constructed an apple tree trunk measurement system using the Azure Kinect V2 (Microsoft, Redmond, WA, USA) depth camera. They placed the depth camera on a tripod, which was connected to a computer via a data cable. Liu et al. [
30] chose a computer with a Nvidia GTX-1060 (NVIDIA Corporation, Santa Clara, CA, USA) as a way to improve the real-time performance of the system for fruit detection and picking point localization. Although RGB-D camera-based vision systems for real-time computing in forestry have been widely validated in academia and have been widely used, their practical application in complex forestry environments still faces challenges. For example, the difficulty of carrying large computing platforms makes it more difficult to measure in areas that are difficult for humans to access directly. These problems are similar to those faced when using conventional measuring equipment, where the equipment is not portable.
The great success of deep learning techniques in the field of image segmentation has led to the increasing use of deep cameras in the field of agriculture and forestry. For example, Sila et al. [
31] constructed an image-based tree trunk detection system for forestry mobile robots using five different neural networks. They used a detection frame to define tree trunks in the field of view, but since they did not segment the semantic information within the detection frame, the practical applications available are limited. Danilo et al. [
22] imporved the U-Net by adding a deep residual module for tree segmentation in urban environments and further fitting the skeleton model of trees. In addition, Vincent [
32] used Mask R-CNN and Cascade Mask R-CNN for segmenting tree images and predicting keypoint locations, in which they reported tree detection rates and segmentation accuracies of 90.4% and 87.2%, respectively. Although both studies successfully extracted the trunk masks of trees from 2D images, their algorithms still have limitations in terms of real-time performance. In order to achieve fast standing tree segmentation, Wang et al. [
33] optimized the DeepLabV3+ framework to enhance the performance of edge details in tree segmentation and introduced a lightweight network, MobileNet, to reduce the computational complexity, which resulted in a significant improvement in single-frame inference speed. Instance segmentation algorithms are usually categorized into one-stage and two-stage models. Two-stage models such as Region Convolution Neural Network (R-CNN) [
34], Fast-RCNN [
35], and Mask R-CNN [
36] show excellent performance in tasks such as forest detection, segmentation, maturity classification, and yield computation. However, networks such as Faster R-CNN suggest networks by generating regions, which improves segmentation accuracy but leads to an increase in model size and processing time, which is inconsistent with the demand for real-time and light weighting. Redmon et al. [
37] proposed YOLO, a single-stage target detection model, which integrates the tasks of detection, classification and localization into a single regression problem, thus simplifying the network structure and computational cost. Based on this, the Yolact [
38] model was developed, which simplifies the segmentation and localization tasks into two parallel tasks. First, it generates prototype masks that do not depend on any instances, using a similar approach to that of fully convolution networks [
39]; second, it adds a target detection branch that predicts “mask coefficients” for each anchor. The final mask is generated by combining these two parts after processing through non-maximal suppression [
40]. Cao et al. [
41] conducted a comprehensive evaluation of the performance of multiple segmentation algorithms on the tree segmentation task, and found that the YOLO series of models performed the best in terms of comprehensive performance. All these studies verified that deep learning-based segmentation algorithms are able to quickly and accurately acquire pixel-level coordinates of tree regions in 2D images, and these algorithms show significant advantages in data acquisition and recognition accuracy compared with traditional methods.
In order to accurately measure the tree’s diameter at breast height (DBH), the acquired trunk region montages need to be further processed. The diameter-at-breast points, usually located at a height of about 1.3 m above the ground in the trunk, are two points in the tree cross-section that intersect the line connecting the center of mass [
42]. The positioning accuracy of these points directly affects the accuracy of breast diameter measurements. Both traditional methods for locating breast diameter points and deep learning-based methods have their advantages and disadvantages. For example, Amelia et al. [
28] used principal component analysis to determine the main axis of the trunk and traversed the binary image to determine the breast diameter points. However, this method is sensitive to noise points and may not be applicable to morphologically irregular trees. Fan et al. [
27] combined the IMU sensor and SLAM method to record the spatial information of the root position of the tree so as to directly extract the cross section of the breast diameter position. However, due to the drift characteristics of the SLAM algorithm, long time measurements may lead to cumulative errors. Grondin [
32] optimized Mask R-CNN by adding a key point prediction module for predicting key points on the tree trunk, but this method requires a large amount of data annotation. They have a prediction error of 5.2 pixels for the diameter points of the thorax, and this error is further amplified during the mapping of the 2D image coordinate system to the 3D world coordinate system, resulting in a large deviation in the measured thorax values.
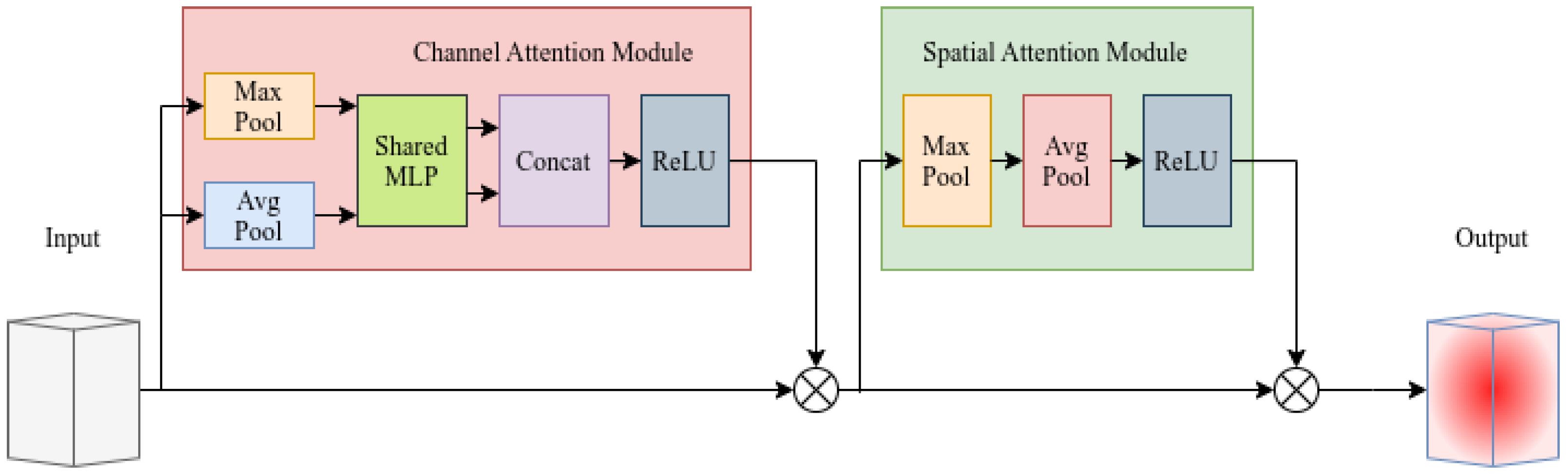
This system is not only portable, but also capable of calculating the breast diameter of trees in the field of view in real time. We have deeply optimized YOLOv5-seg, especially by introducing a Channel and Spatial Attention (CBAM)-based module, which enhances the model’s ability to identify and segment trees in complex forest environments. In addition, we propose a more robust, high real-time and multi-objective localization algorithm compared with the traditional tree breast diameter point localization method. In order to verify the effectiveness of the proposed system, we have performed the proposed system in seven different forest scenes by comparing the DBH computed by the system with the data obtained manually by the traditional method, whose average error is only 39.61 mm (, ). This result strongly suggests that the system has the potential to replace traditional chest diameter measurement tools. Considering our future research on the application of unmanned aircraft and unmanned ground vehicles to forest resource surveys and automated path planning in forests, we developed a wireless LAN-based server platform for the system, which allows users to visualize and monitor the system operation or guide the system operation remotely in real time.
5. Conclusions
To address the time-consuming, labor-intensive, and technical limitations encountered in the current forest resource inventory during DBH measurement, we have developed an automatic DBH measurement system based on W-LAN utilizing RGB-D cameras and deep learning technology. The effectiveness and accuracy of this system have been verified across various plots.
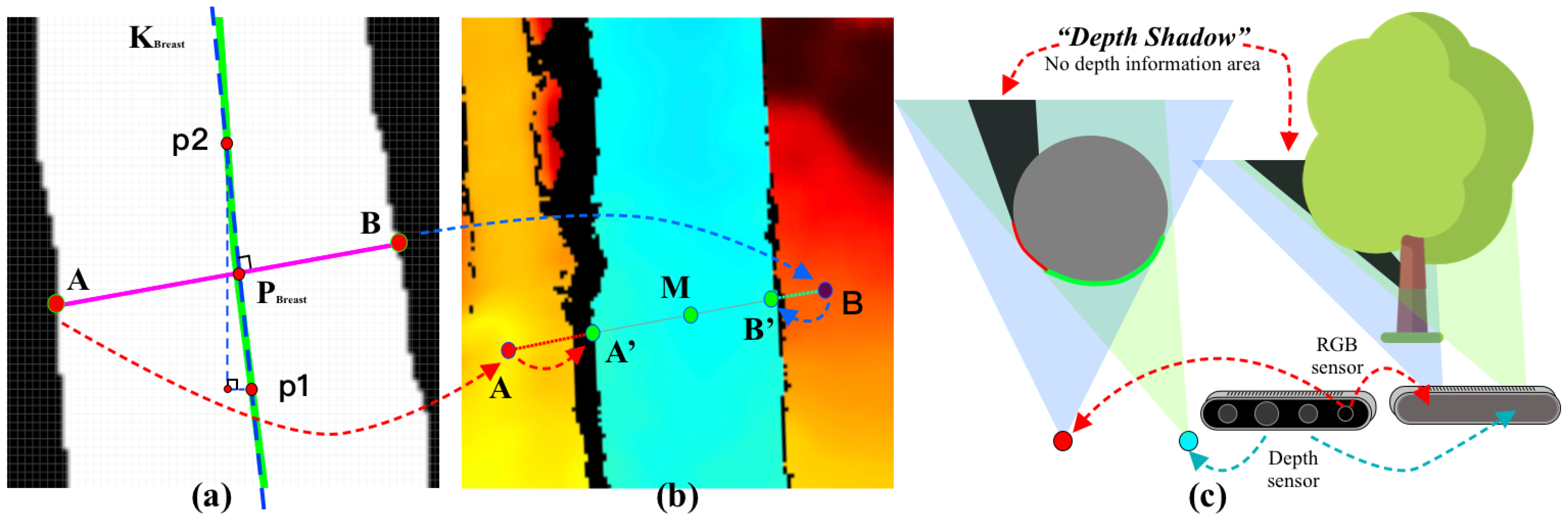
First, we enhanced the segmentation head of the YOLOv5-seg model, incorporating attention mechanisms to more comprehensively capture the global contextual information of tree features, thereby achieving higher segmentation accuracy in a shorter time. On this basis, we propose a novel image-based keypoint localization method for tree masks, which is able to accurately locate two mask edge points (DBH keypoints) whose connecting lines are perpendicular to the tree growth direction at any height of the tree mask. Subsequently, with the help of RGB-D camera, we map the DBH keypoints to the world coordinate system to obtain the DBH. In order to minimize the measurement errors, we discussed several situations that may lead to deviations in the positioning of the DBH keypoints, such as low-quality skeletons and the phenomenon of deep shadows, and then optimized each case accordingly.
In addition, we designed an optimization method based on target tracking that tracks multiple trees and improves the stability of the algorithm by reducing the probability of outliers during diameter measurements through repeated measurements. We also experimented with a WLAN-based edge computing strategy, and this separated architecture has two major advantages:
Shifting intensive computational tasks to a remote computing platform not only improves computational efficiency, but also reduces the burden on the low-power devices on the measurement side, allowing them to sample the environment more stably;
The cost of measurement-side equipment that simplifies the task is dramatically reduced, allowing deployment scales to be equitably increased. More measurement devices are monitored simultaneously at the remote end, improving inventory efficiency.
Accurate tree DBH measurements are important for both traditional forest inventory tasks and vision-based automated path planning for forestry robots. Once our system is activated, the entire process is fully automated, and we have provided a user-friendly graphical interface for operators, providing a solid foundation for future deployment on UAVs, UGVs or UMVs. We look forward to the system playing an even greater role in future unmanned equipment-based forest inventory missions. This will not only move our research forward, but will also revolutionize the entire field of forest resource management by providing more powerful tools to conserve and manage our valuable forest resources.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}