
Global Wildfire Susceptibility Mapping Based on Machine Learning Models


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
2.2. Methodology
3. Results
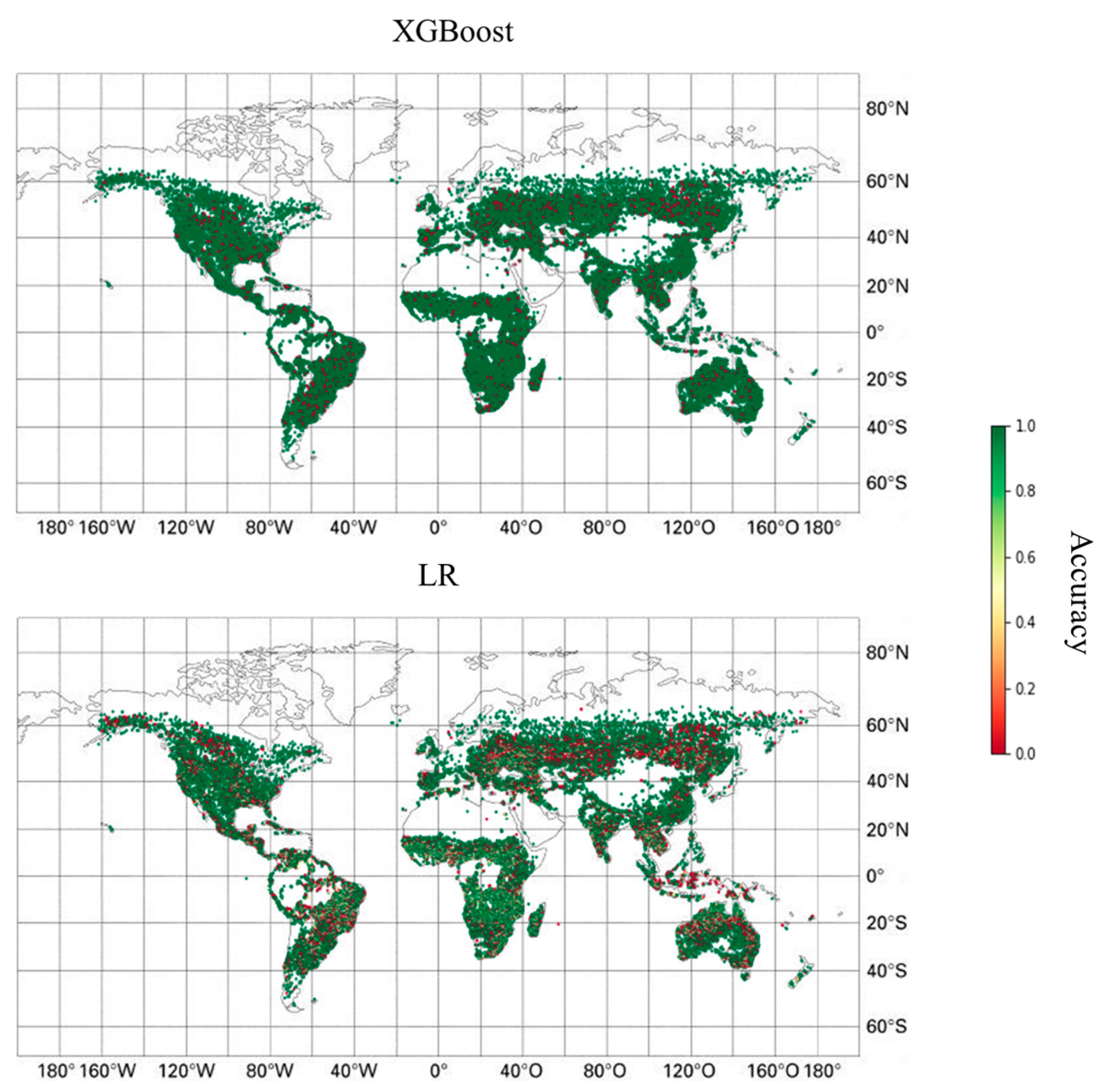
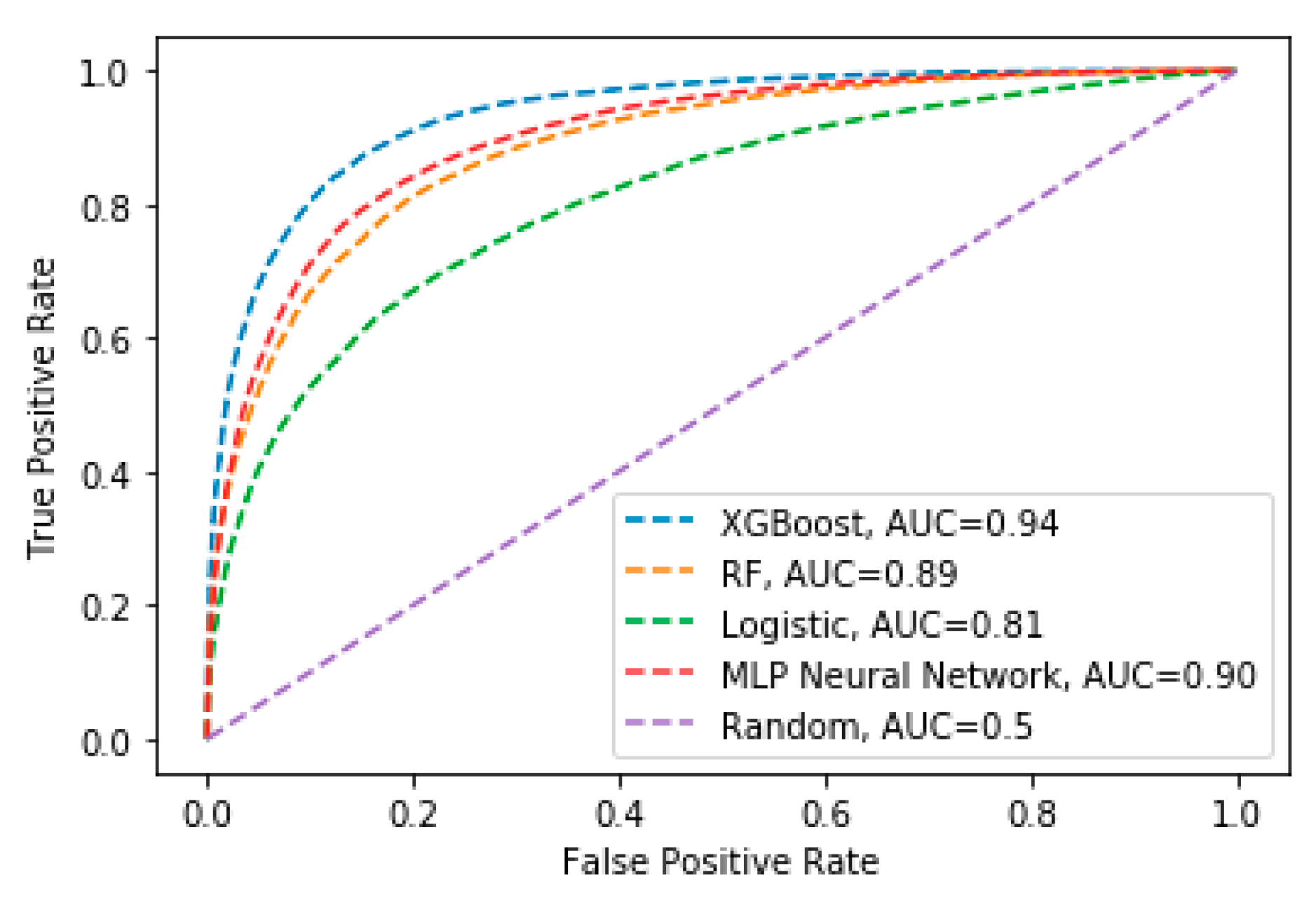
3.1. Wildfire Occurrence
3.2. Size of Burned Areas
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A




References
- Grad, S. Six of California’s largest fires in history ignited this year. Here’s what we know. Los Angeles Times 2020. Available online: https://www.latimes.com/california/story/2020-09-11/six-of-californias-largest-fires-in-history-are-burning-right-now (accessed on 26 May 2022).
- Burgess, T.; Burgmann, J.R.; Hall, S.; Holmes, D.; Turner, E. Black Summer: Australian Newspaper Reporting on the Nation’s Worst Bushfire Season. Monash Climate Change Communication Research Hub; Monash University: Clayton, Australia, 2020; p. 30. [Google Scholar]
- Westerling, A.L.; Bryant, B.P.; Preisler, H.K.; Holmes, T.P.; Hidalgo, H.; Das, T.; Shrestha, S. Climate change and growth scenarios for California wildfire. Clim. Chang. 2011, 109, 445–463. [Google Scholar] [CrossRef]
- Abatzoglou, J.T.; Williams, A.P. Impact of anthropogenic climate change on wildfire across western US forests. Proc. Natl. Acad. Sci. USA 2016, 113, 11770–11775. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Flannigan, M.; Harrington, J.B. A Study of the Relation of Meteorological Variables to Monthly Provincial Area Burned by Wildfire in Canada (1953–1980). J. Appl. Meteorol. 1988, 27, 441–452. [Google Scholar] [CrossRef]
- Slocum, M.G.; Beckage, B.; Platt, W.J.; Orzell, S.L.; Taylor, W. Effect of Climate on Wildfire Size: A Cross-Scale Analysis. Ecosystems 2010, 13, 828–840. [Google Scholar] [CrossRef]
- Vlassova, L.; Pérez-Cabello, F.; Mimbrero, M.R.; Llovería, R.M.; García-Martín, A. Analysis of the Relationship between Land Surface Temperature and Wildfire Severity in a Series of Landsat Images. Remote Sens. 2014, 6, 6136–6162. [Google Scholar] [CrossRef] [Green Version]
- Joseph, M.B.; Rossi, M.W.; Mietkiewicz, N.P.; Mahood, A.L.; Cattau, M.E.; St. Denis, L.A.; Nagy, R.C.; Iglesias, V.; Abatzoglou, J.T.; Balch, J.K. Spatiotemporal prediction of wildfire size extremes with Bayesian finite sample maxima. Ecol. Appl. 2019, 29, e01898. [Google Scholar] [CrossRef] [Green Version]
- US Army Signal Service. Report on the Michigan Forest Fires of 1881; Sig. Serv. Notes 1; Office of the Chief Signal Officer: Washington, DC, USA, 1881; p. 37. [Google Scholar]
- Chandler, C.C.; Storey, T.G.; Tangren, C.D. Prediction of Fire Spread Following Nuclear Explosions; Pacific Southwest Forest and Range Experiment Station: Berkley, CA, USA, 1963. [Google Scholar]
- Plucinski, M.P. A Review of Wildfire Occurrence Research. Bushfire Cooperative Research Centre; BCR Centre: Melbourne, VIC, Australia, 2012. [Google Scholar]
- Westerling, A.L.; Gershunov, A.; Cayan, D.R.; Barnett, T.P. Long lead statistical forecasts of area burned in western U.S. wildfires by ecosystem province. Int. J. Wildland Fire 2002, 11, 257–266. [Google Scholar] [CrossRef]
- Pineda, N.; Montanyà, J.; Van der Velde, O.A. Characteristics of lightning related to wildfire ignitions in Catalonia. Atmos. Res. 2014, 135, 380–387. [Google Scholar] [CrossRef]
- Westerling, A.L.; Bryant, B.P. Climate change and wildfire in California. Clim. Chang. 2008, 87, 231–249. [Google Scholar] [CrossRef]
- Jain, P.; Coogan, S.C.P.; Subramanian, S.G.; Crowley, M.; Taylor, S.W.; Flannigan, M.D. A review of machine learning applications in wildfire science and management. Environ. Rev. 2020, 28, 478–505. [Google Scholar] [CrossRef]
- Vega-Garcia, C.; Lee, B.S.; Woodard, P.M.; Titus, S.J. Applying neural network technology to human-caused wildfire occurrence prediction. AI Appl. 2012, 10, 9–18. [Google Scholar]
- Alonso-Betanzos, A.; Fontenla-Romero, O.; Guijarro-Berdiñas, B.; Hernández-Pereira, E.; Andrade, M.I.P.; Jiménez, E.; Soto, J.L.L.; Carballas, T. An intelligent system for forest fire risk prediction and fire fighting management in Galicia. Expert Syst. Appl. 2003, 25, 545–554. [Google Scholar] [CrossRef]
- Vasilakos, C.; Kalabokidis, K.; Hatzopoulos, J.; Kallos, G.; Matsinos, Y. Integrating new methods and tools in fire danger rating. Int. J. Wildland Fire 2007, 16, 306–316. [Google Scholar] [CrossRef]
- Sakr, G.E.; Elhajj, I.H.; Mitri, G. Efficient forest fire occurrence prediction for developing countries using two weather parameters. Eng. Appl. Artif. Intell. 2011, 24, 888–894. [Google Scholar] [CrossRef]
- zbayoğlu, A.M.; Bozer, R. Estimation of the burned area in forest fires using computational intelligence techniques. Procedia Comput. Sci. 2012, 12, 282–287. [Google Scholar] [CrossRef] [Green Version]
- Dutta, R.; Aryal, J.; Das, A.; Kirkpatrick, J.B. Deep cognitive imaging systems enable estimation of continental-scale fire incidence from climate data. Sci. Rep. 2013, 3, 3188. [Google Scholar] [CrossRef] [Green Version]
- Dutta, R.; Das, A.; Aryal, J. Big data integration shows Australian bushfire frequency is increasing significantly. R Soc. Open Sci. 2016, 3, 150241. [Google Scholar] [CrossRef] [Green Version]
- Stojanova, D.; Kobler, A.; Ogrinc, P.; Ženko, B.; Džeroski, S. Estimating the risk of fire outbreaks in the natural environment. Data Min. Knowl. Discov. 2012, 24, 411–442. [Google Scholar] [CrossRef]
- Vecín-Arias, D.; Castedo-Dorado, F.; Ordóñez, C.; Rodríguez-Pérez, J.R. Biophysical and lightning characteristics drive lightning-induced fire occurrence in the central plateau of the Iberian Peninsula. Agric. For. Meteorol. 2016, 225, 36–47. [Google Scholar] [CrossRef]
- Castelli, M.; Vanneschi, L.; Popovič, A. Predicting Burned Areas of Forest Fires: An Artificial Intelligence Approach. Fire Ecol. 2015, 11, 106–118. [Google Scholar] [CrossRef]
- Wood, D.A. Prediction and data mining of burned areas of forest fires: Optimized data matching and mining algorithm provides valuable insight. Artif. Intell. Agric. 2021, 5, 24–42. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, M.; Liu, K. Wildfire Susceptibility Assessment in Southern China: A Comparison of Multiple Methods. Int. J. Disaster Risk Sci. 2017, 8, 164–181. [Google Scholar] [CrossRef] [Green Version]
- Yu, B.; Chen, F.; Li, W.; Wang, L.; Wu, M.; Mingquan, W.; Bo, Y.; Fang, C.; Bin, L. Fire Risk Prediction Using Remote Sensed Products: A Case of Cambodia. Photogramm. Eng. Remote Sens. 2017, 83, 19–25. [Google Scholar] [CrossRef]
- Van Beusekom, A.E.; Gould, W.A.; Monmany-Garzia, A.C.; Khalyani, A.H.; Quiñones, M.; Fain, S.J.; Andrade-Núñez, M.J.; González, G. Fire weather and likelihood: Characterizing climate space for fire occurrence and extent in Puerto Rico. Clim. Chang. 2018, 146, 117–131. [Google Scholar] [CrossRef]
- De Angelis, A.; Ricotta, C.; Conedera, M.; Pezzatti, G.B. Modelling the meteorological forest fire niche in heterogeneous pyrologic conditions. PLoS ONE 2015, 10, e0116875. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.; Du, Y.; Niu, S.; Zhao, J. Modeling Forest Lightning Fire Occurrence in the Daxinganling Mountains of Northeastern China with MAXENT. Forests 2015, 6, 1422–1438. [Google Scholar] [CrossRef] [Green Version]
- Toujani, A.; Achour, H.; Faïz, S. Estimating Forest Fire Losses Using Stochastic Approach: Case Study of the Kroumiria Mountains (Northwestern Tunisia). Appl. Artif. Intell. 2018, 32, 882–906. [Google Scholar] [CrossRef]
- Wang, S.C.; Wang, Y. Predicting wildfire burned area in South Central US using integrated machine learning techniques. Atmos. Chem. Phys. Discuss. 2019, 20, 1–25. [Google Scholar]
- Bjånes, A.; De La Fuente, R.; Mena, P. A deep learning ensemble model for wildfire susceptibility mapping. Ecol. Inform. 2021, 65, 101397. [Google Scholar] [CrossRef]
- Chuvieco, E.; Pettinari, M.L.; Lizundia-Loiola, J.; Storm, T.; Padilla Parellada, M. ESA Fire Climate Change Initiative (Fire_cci): MODIS Fire_cci Burned Area Pixel product, version 5.1. Centre for Environmental Data. Data Anal 2018, 1. [Google Scholar] [CrossRef]
- Andela, N.; Morton, D.C.; Giglio, L.; Paugam, R.; Chen, Y.; Hantson, S.; van der Werf, G.R.; Randerson, J.T. The Global Fire Atlas of individual fire size, duration, speed and direction. Earth Syst. Sci. Data 2019, 11, 529–552. [Google Scholar] [CrossRef] [Green Version]
- Lizundia-Loiola, J.; Otón, G.; Ramo, R.; Chuvieco, E. A spatio-temporal active-fire clustering approach for global burned area mapping at 250 m from MODIS data. Remote Sens. Environ. 2020, 236, 111493. [Google Scholar] [CrossRef]
- Chuvieco, E.; Pettinari, M.L.; Koutsias, N.; Forkel, M.; Hantson, S.; Turco, M. Human and climate drivers of global biomass burning variability. Sci. Total Environ. 2021, 779, 146361. [Google Scholar] [CrossRef] [PubMed]
- Forkel, M.; Andela, N.; Harrison, S.P.; Lasslop, G.; van Marle, M.; Chuvieco, E.; Dorigo, W.; Forrest, M.; Hantson, S.; Heil, A.; et al. Emergent relationships with respect to burned area in global satellite observations and fire-enabled vegetation models. Biogeosciences 2019, 16, 57–76. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Wang, M.; Liu, K. Deep neural networks for global wildfire susceptibility modelling. Ecol. Indic. 2021, 127, 107735. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Armon, A. Tabular data: Deep learning is not all you need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Ahmad, A.; Ahmad, S.R.; Gilani, H.; Tariq, A.; Zhao, N.; Aslam, R.W.; Mumtaz, F. A Synthesis of Spatial Forest Assessment Studies Using Remote Sensing Data and Techniques in Pakistan. Forests 2021, 12, 1211. [Google Scholar] [CrossRef]
- ECMWF WEBSITE-European Centre for Medium-Range Weather Forecasts. Available online: https://cds.climate.copernicus.eu/#!/home (accessed on 9 June 2022).
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Rozum, I.; et al. ERA5 Monthly Averaged Data on Pressure Levels from 1979 to Present. Copernicus Climate Change Service (C3S) Climate Data Store (CDS). 2019. Available online: http://10.24381/cds.6860a573 (accessed on 23 April 2021).
- Troccoli, A. Solar Radiation—Variable Fact Sheet. Copernicus Climate Change Service. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels?tab=overview (accessed on 2 July 2022).
- Fire Danger Indices Historical Data from the Copernicus Emergency Management Service. Fire Danger Indices His-torical Data from the Copernicus Emergency Management Service—User Guide. 2021. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/cems-fire-historical?tab=overviewlast (accessed on 17 May 2021).
- Center for International Earth Science Information Network-CIESIN-Columbia University. Gridded Population of the World, Version 4 (GPWv4): Population Density, Revision 11. Palisades, NY: NASA Socioeconomic Data and Applications Center (SEDAC). 2018. Available online: https://sedac.ciesin.columbia.edu/data/set/gpw-v4-population-density-rev11 (accessed on 16 October 2021).
- Blessing, S.; Giering, R. Leaf Area Index and Fraction Absorbed of Photosynthetically Active Radiation 10-Daily Gridded Data from 1981 to Present. 2018. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/satellite-lai-fapar?tab=overviewlast (accessed on 10 May 2021).
- Didan, K.; Munoz, A.B.; Solano, R.; Huete, A. MODIS Vegetation index User’s Guide (MOD13 Series); University of Arizona, Vegetation Index and Phenology Lab.: Tucson, AZ, USA, 2015. [Google Scholar]
- De Jeu, R.; Van der Schalie, R. Algorithm Theoretical Basis Document Soil Moisture Products from active and passive microwave sensors. In Copernicus Climate Change Service; Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/satellite-soil-moisture?tab=overview (accessed on 27 May 2022).
- Pimont, F.; Dupuy, J.-L.; Linn, R.R. Coupled slope and wind effects on fire spread with influences of fire size: A numerical study using FIRETEC. Int. J. Wildland Fire 2012, 21, 828–842. [Google Scholar] [CrossRef]
- Amatulli, G.; Domisch, S.; Tuanmu, M.-N.; Parmentier, B.; Ranipeta, A.; Malczyk, J.; Jetz, W. A suite of global, cross-scale topographic variables for environmental and biodiversity modeling. Sci. Data 2018, 5, 180040. [Google Scholar] [CrossRef] [Green Version]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification; National Taiwan University: Taipei, Taiwan, 2003. [Google Scholar]
- Hasanin, T.; Khoshgoftaar, T. The effects of random undersampling with simulated class imbalance for big data. In Proceedings of the 2018 IEEE International Conference on Information Reuse and Integration (IRI), 6–9 July 2018, Salt Lake City, UT, USA; pp. 70–79.
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning deep representation for imbalanced classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5375–5384. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ling, C.X.; Huang, J.; Zhang, H. AUC: A better measure than accuracy in comparing learning algorithms. In Conference of the Canadian Society for Computational Studies of Intelligence; Springer: Berlin/Heidelberg, Germany, 2003; pp. 329–341. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.M.; Li, Q.; Saqib, Z.; Khan, N.; Habib, T.; Khalid, N.; Majeed, M.; Tariq, A. MaxEnt Modelling and Impact of Climate Change on Habitat Suitability Variations of Economically Important Chilgoza Pine (Pinus gerardiana Wall.) in South Asia. Forests 2022, 13, 715. [Google Scholar] [CrossRef]
- Al_Janabi, S.; Al_Shourbaji, I.; Salman, M.A. Assessing the suitability of soft computing approaches for forest fires prediction. Appl. Comput. Inform. 2018, 14, 214–224. [Google Scholar] [CrossRef]
- Xie, Y.; Peng, M. Forest fire forecasting using ensemble learning approaches. Neural Comput. Appl. 2019, 31, 4541–4550. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Biau, G.; Scornet, E. A random forest guided tour. TEST 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ramchoun, H.; Idrissi, M.A.J.; Ghanou, Y.; Ettaouil, M. Multilayer Perceptron: Architecture Optimization and Training. Int. J. Interact. Multimed. Artif. Intell. 2016, 4, 26. [Google Scholar] [CrossRef]
- Lever, J.; Krzywinski, M.; Altman, N. Logistic regression: Regression can be used on categorical responses to estimate probabilities and to classify. Nat. Methods 2016, 13, 541–543. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Mangalathu, S.; Hwang, S.H.; Jeon, J.S. Failure mode and effects analysis of RC members based on ma-chine-learning-based SHapley Additive exPlanations (SHAP) approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Verhoeven, E.M.; Murray, B.R.; Dickman, C.R.; Wardle, G.M.; Greenville, A.C. Fire and rain are one: Extreme rainfall events predict wildfire extent in an arid grassland. Int. J. Wildland Fire 2020, 29, 702. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Abbreviation | Source |
|---|---|---|
| monthly burned area (target variable) | BA | [37] |
| 2 m temperature | temp | [44] |
| relative humidity | RH | |
| 10 m wind velocity | wind_speed | |
| precipitation | prec | |
| mean relative humidity in previous month | RH_1_month | |
| mean precipitation in previous month | prec_1_month | |
| mean relative humidity in previous year | RH_12_months | |
| mean precipitation in previous year | prec_12_months | |
| percentage of burnable area | burnable | [37] |
| median burned area | median_burned | |
| mean burned area | mean_burned | |
| latitude | lat | - |
| longitude | lon | - |
| month (categorical) | month_1, month_2, etc. | - |
| leaf area index—low vegetation | LAI_low | [48] |
| leaf area index—high vegetation | LAI_high | |
| total leaf area index | LAI_tot | |
| normalized difference vegetation index | NDVI | [49] |
| incoming short-wave solar radiation | radiation | [45] |
| soil moisture | soil | [50] |
| mean slope | slope | [52] |
| population density | population | [47] |
| fire weather index—mean | FWI_mean | [46] |
| fire weather index—highest 7 in month | FWI_7 | |
| build up index—mean | BUI_mean | |
| build up index—highest 7 in month | BUI_7 | |
| danger index—mean | danger_mean | |
| danger index—highest 7 in month | danger_7 | |
| drought code—mean | drought_mean | |
| drought code—highest 7 in month | drought_7 | |
| duff moisture code—mean | DM_mean | |
| duff moisture code—highest 7 in month | DM_7 | |
| initial fire spread index—mean | ISI_mean | |
| initial fire spread index—highest 7 in month | ISI_7 | |
| fine fuel moisture code—mean | FFMC_mean | |
| fine fuel moisture code—highest 7 in month | FFMC_7 | |
| fire daily severity rating—mean | severity_mean | |
| fire daily severity rating—highest 7 in month | severity_7 | |
| Keetch–Byram drought index—mean | KBDI_mean | |
| Keetch–Byram drought index—highest 7 in month | KBDI_7 | |
| fire danger index—mean | FFDI_mean | |
| fire danger index—highest 7 in month | FFDI_7 | |
| spread component—mean | SC_mean | |
| spread component—highest 7 in month | SC_7 | |
| energy release component—mean | energy_mean | |
| energy release component—highest 7 in month | energy_7 | |
| burning index—mean | BI_mean | |
| burning index—highest 7 in month | BI_7 | |
| ignition component—mean | IC_mean | |
| ignition component—highest 7 in month | IC_7 |
| Including Regional Wildfire History | ||||||
| Model | AUC | Accuracy | TPR | TNR | Hyperparameters Tested | Best Parameters |
| RF | 0.92 | 0.83 | 0.81 | 0.86 | max depth: 8–10 | 10 |
| n_estimators: 100–550 | 550 | |||||
| XGBoost | 0.97 | 0.92 | 0.90 | 0.93 | max depth: 8–10 | 10 |
| n_estimators: 100–550 | 550 | |||||
| MLP | 0.69 | 0.67 | 0.45 | 0.83 | hidden layers: 1–3 | 1 |
| # neurons in layer: 50–150 | 100 | |||||
| LR | 0.73 | 0.69 | 0.52 | 0.79 | - | - |
| Excluding Regional Wildfire History | ||||||
| Model | AUC | Accuracy | TPR | TNR | Hyperparameters Tested | Best Parameters |
| RF | 0.89 | 0.80 | 0.77 | 0.83 | max depth: 8–10 | 10 |
| n_estimators: 100–550 | 550 | |||||
| XGBoost | 0.94 | 0.86 | 0.86 | 0.86 | max depth: 8–10 | 10 |
| n_estimators: 100–550 | 400 | |||||
| MLP | 0.90 | 0.80 | 0.81 | 0.84 | hidden layers: 1–3 | 2 |
| # neurons in layer: 50–150 | 150 | |||||
| LR | 0.81 | 0.73 | 0.71 | 0.76 | - | - |
| Including Regional Wildfire History | ||||
| Model | AUC | Accuracy | TPR | TNR |
| XGBoost (w = 1) | 0.94 | 0.93 | 0.59 | 0.98 |
| XGBoost (w = 5) | 0.94 | 0.89 | 0.81 | 0.91 |
| XGBoost (w = 7) | 0.94 | 0.88 | 0.85 | 0.88 |
| XGBoost (w = 9) | 0.94 | 0.86 | 0.87 | 0.86 |
| XGBoost (w = 20) | 0.94 | 0.80 | 0.92 | 0.78 |
| XGBoost (w = 50) | 0.93 | 0.72 | 0.95 | 0.69 |
| LR (w = 1) | 0.64 | 0.87 | 0.11 | 0.98 |
| LR (w = 5) | 0.77 | 0.75 | 0.71 | 0.75 |
| LR (w = 7) | 0.78 | 0.70 | 0.78 | 0.69 |
| LR (w = 9) | 0.79 | 0.66 | 0.83 | 0.63 |
| LR (w = 20) | 0.80 | 0.46 | 0.95 | 0.38 |
| LR (w = 50) | 0.69 | 0.14 | 0.99 | 0.01 |
| Excluding Regional Wildfire History | ||||
| Model | AUC | Accuracy | TPR | TNR |
| XGBoost (w = 1) | 0.92 | 0.92 | 0.52 | 0.98 |
| XGBoost (w = 5) | 0.92 | 0.88 | 0.78 | 0.89 |
| XGBoost (w = 7) | 0.92 | 0.85 | 0.82 | 0.86 |
| XGBoost (w = 9) | 0.92 | 0.84 | 0.85 | 0.84 |
| XGBoost (w = 20) | 0.92 | 0.76 | 0.91 | 0.74 |
| XGBoost (w = 50) | 0.92 | 0.67 | 0.95 | 0.62 |
| LR (w = 1) | 0.81 | 0.89 | 0.26 | 0.98 |
| LR (w = 5) | 0.81 | 0.80 | 0.64 | 0.83 |
| LR (w = 7) | 0.81 | 0.74 | 0.72 | 0.74 |
| LR (w = 9) | 0.81 | 0.67 | 0.78 | 0.66 |
| LR (w = 20) | 0.81 | 0.43 | 0.93 | 0.36 |
| LR (w = 50) | 0.81 | 0.22 | 0.99 | 0.10 |
| Including Regional Wildfire History | |||||
| Model | MAE | RMSE | MSE | Parameters Tested | Best Parameters |
| ) | ) | ) | |||
| RF | 3.44 | 16.21 | 262.87 | max depth: 8–10 | 10 |
| n_estimators: 100–550 | 550 | ||||
| XGBoost | 3.13 | 14.30 | 204.61 | max depth: 8–10 | 10 |
| n_estimators: 100–550 | 100 | ||||
| MLP | 4.78 | 21.34 | 455.63 | Hidden layers: 1–3 | 2 |
| # neurons in layer: 50–150 | 150 | ||||
| Linear Regression | 7.48 | 21.28 | 452.94 | - | - |
| Excluding Regional Wildfire History | |||||
| Model | MAE | RMSE | MSE | Parameters Tested | Best Parameters |
| ) | ) | ) | |||
| RF | 4.08 | 17.78 | 316.15 | max depth: 8–10 | 10 |
| n_estimators: 100–550 | 400 | ||||
| XGBoost | 3.75 | 15.67 | 245.50 | max depth: 8–10 | 10 |
| n_estimators: 100–550 | 100 | ||||
| MLP | 3.90 | 17.11 | 292.62 | Hidden layers: 1–3 | 3 |
| # neurons in layer: 50–150 | 150 | ||||
| Linear Regression | 7.51 | 22.03 | 485.52 | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shmuel, A.; Heifetz, E. Global Wildfire Susceptibility Mapping Based on Machine Learning Models. Forests 2022, 13, 1050. https://doi.org/10.3390/f13071050
Shmuel A, Heifetz E. Global Wildfire Susceptibility Mapping Based on Machine Learning Models. Forests. 2022; 13(7):1050. https://doi.org/10.3390/f13071050
Chicago/Turabian StyleShmuel, Assaf, and Eyal Heifetz. 2022. "Global Wildfire Susceptibility Mapping Based on Machine Learning Models" Forests 13, no. 7: 1050. https://doi.org/10.3390/f13071050