


Research on Tea Trees Germination Density Detection Based on Improved YOLOv5

 ,
,  , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Subject
2.2. Tea Trees Germination Images Acquisition
2.3. Image Processing
- Cut the original image into four pieces of one size;
- Label the buds in the image to obtain the ground truth box anchor coordinates;
- Check the database (delete the redundant image and empty xml file, and check whether the ground truth box is correct);
- Data enhancement.
2.4. YOLOv5 Network
2.5. Model Optimization Theory
2.6. Tea Trees Germination Density Calculation
2.7. Evaluation Indicator
3. Result
3.1. Improved YOLOv5
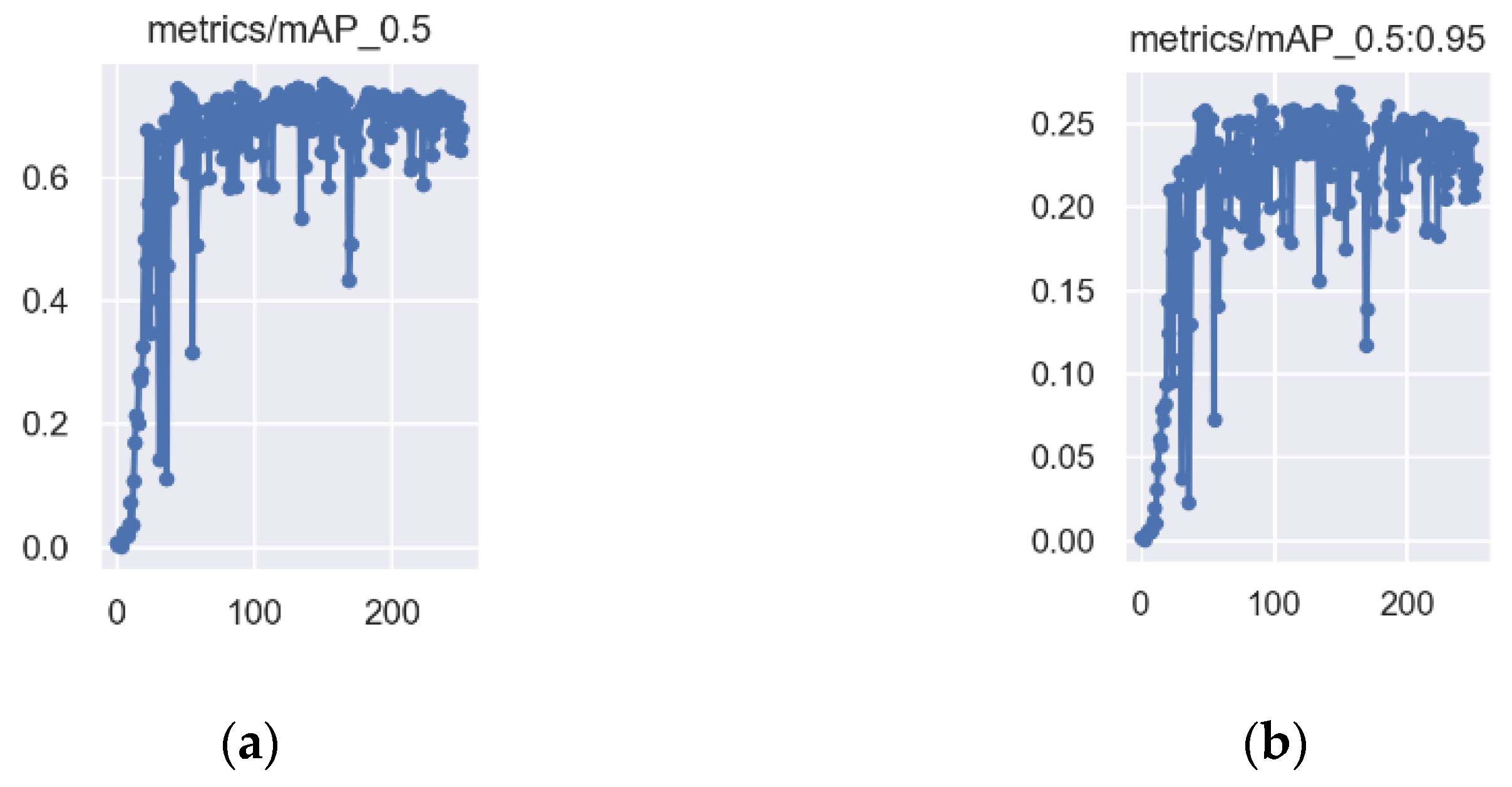
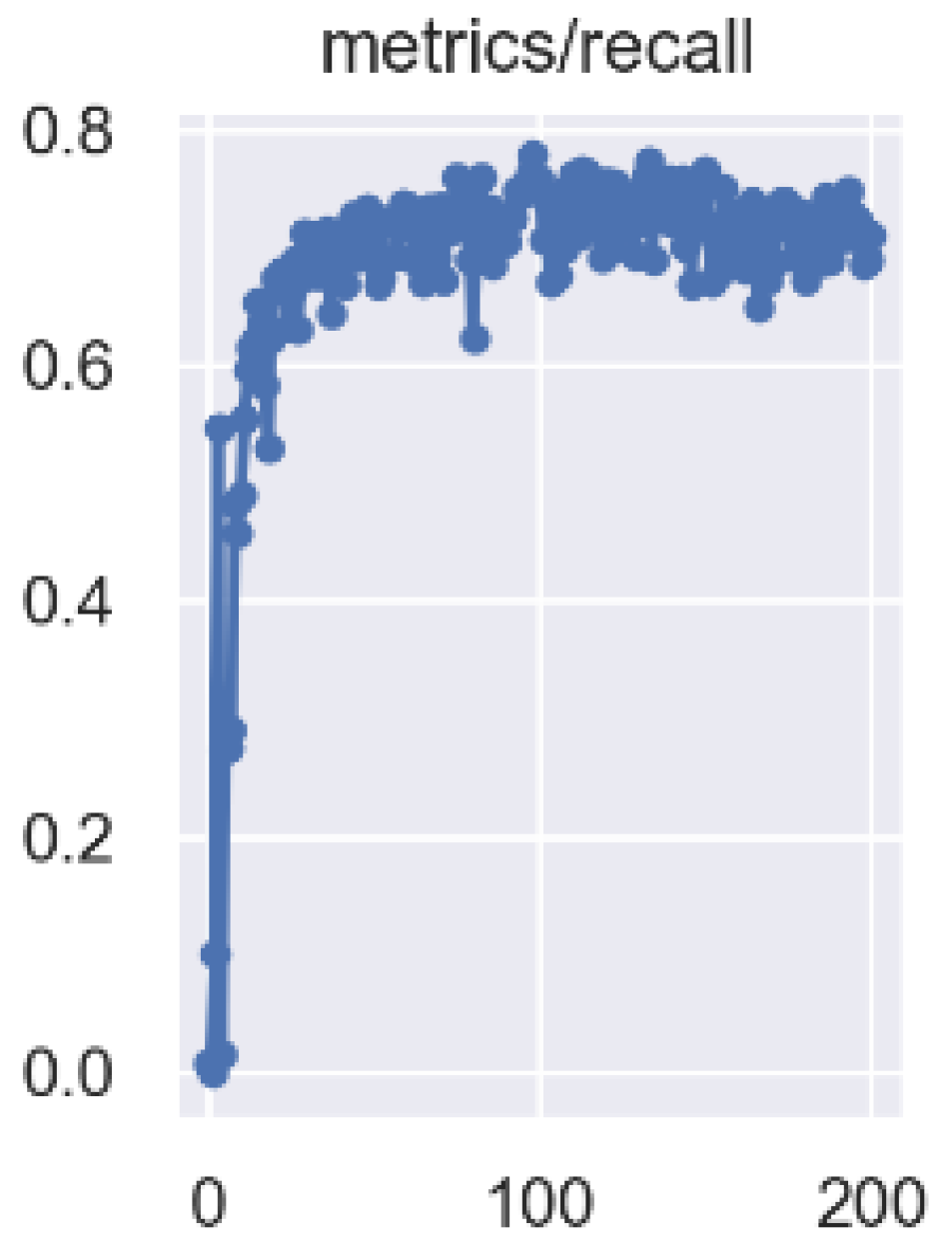
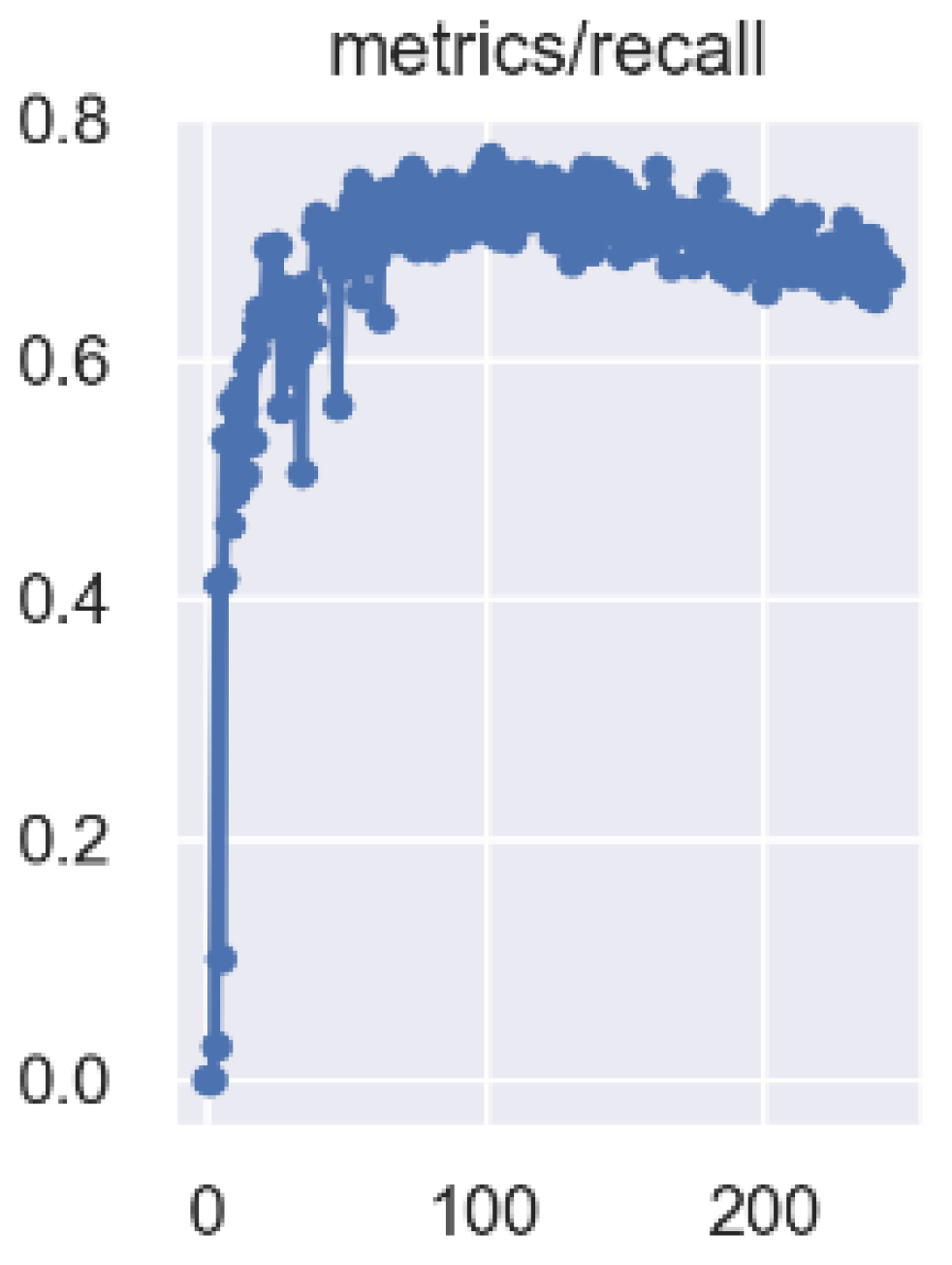
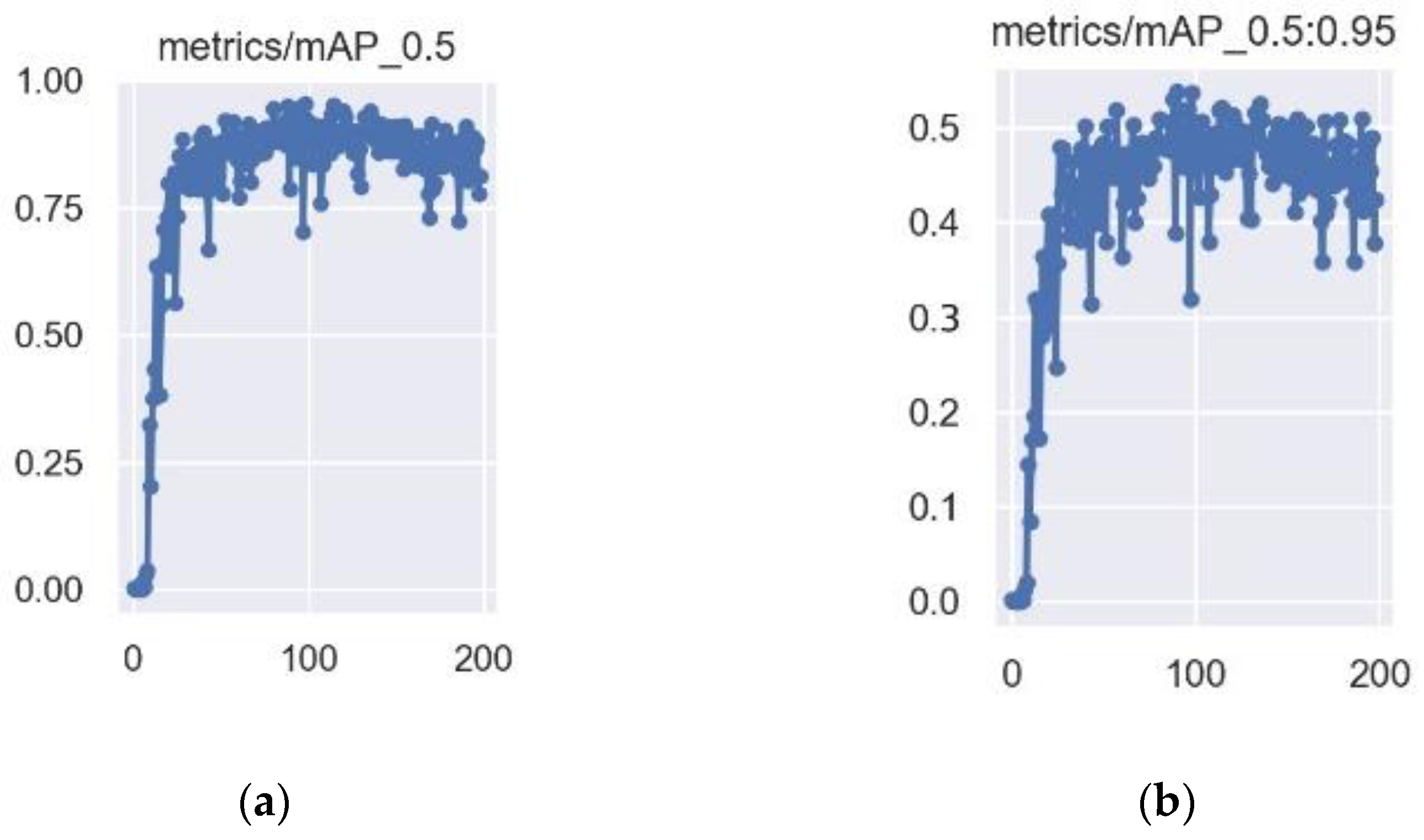
3.2. Model Training
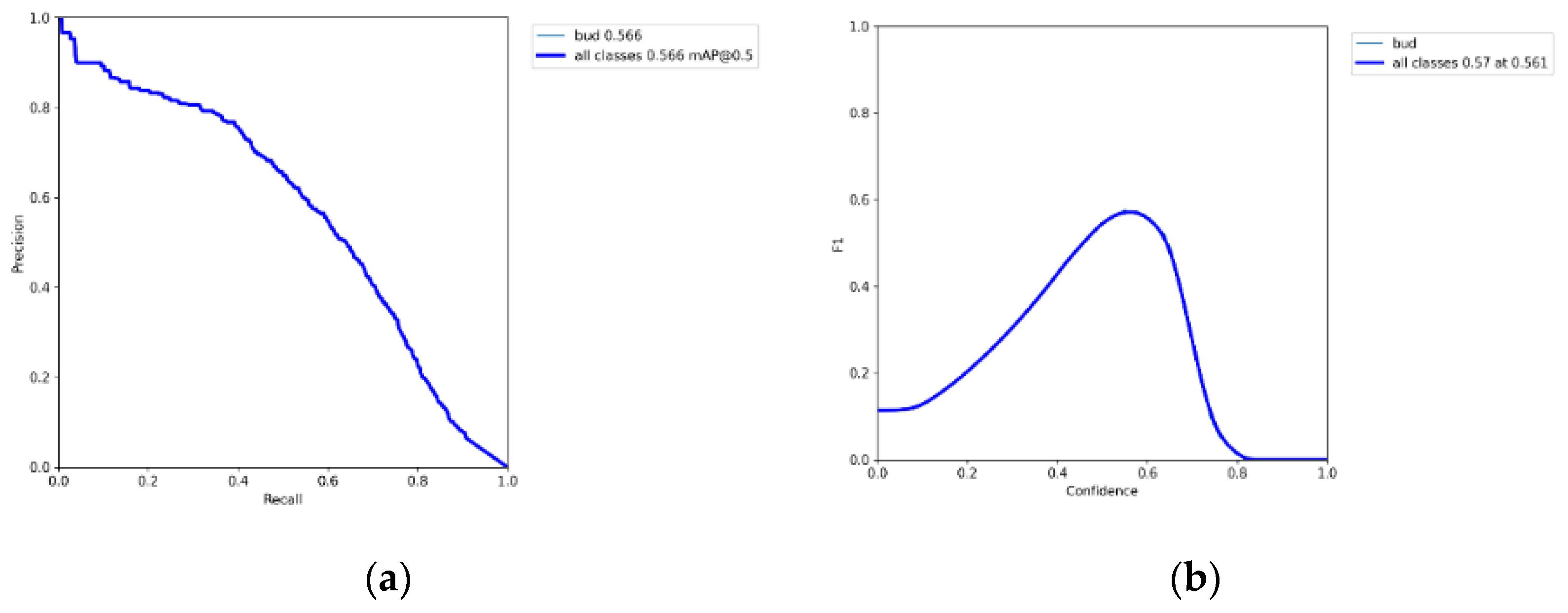
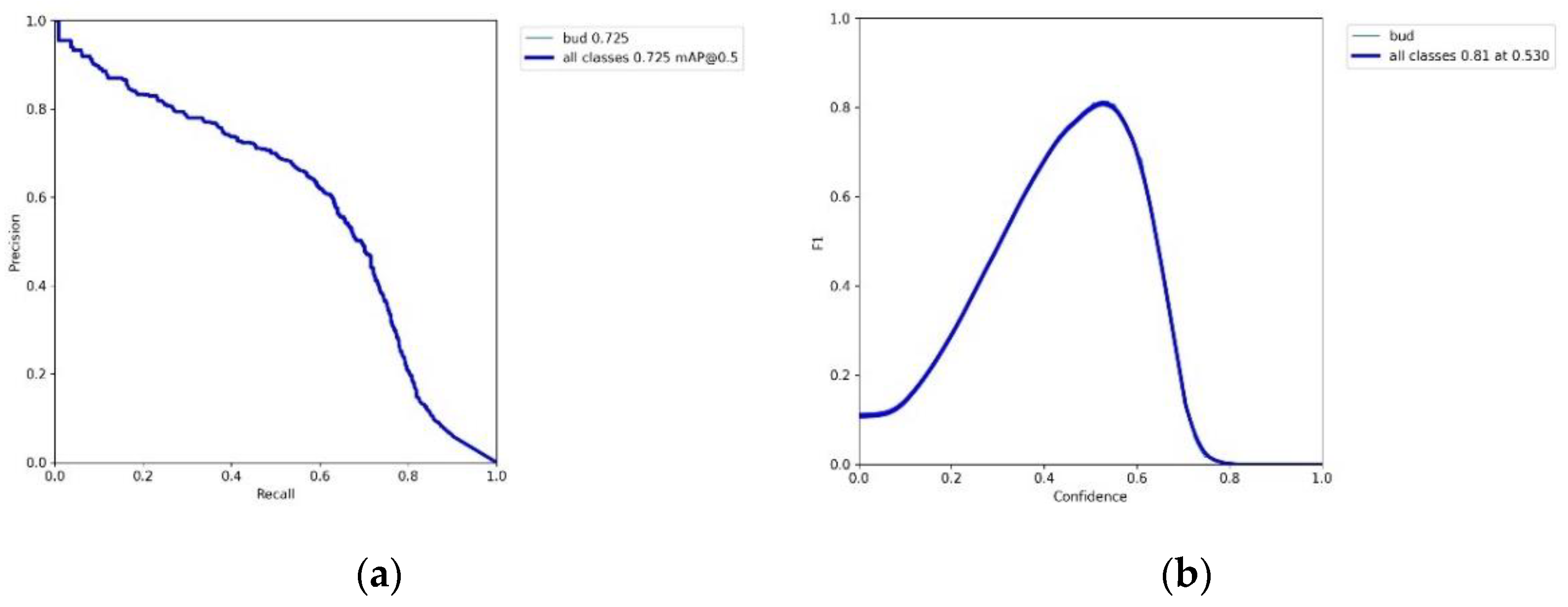
3.3. Tea Buds Recognition Accuracy
3.4. Tea Trees Germination Density Detection Accuracy
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A


















References
- FAO. Current Market Situation and Medium Term Outlook for Tea to 2027; CCP:TE18/CRS1; FAO: Rome, Italy, 2018. [Google Scholar]
- Zhang, X.; Fu, L.; Karkee, M.; Whiting, M.D.; Zhang, Q. Canopy Segmentation Using Res-Net for Mechanical Harvesting of Apples. IFAC-Pap. Online 2019, 52, 300–305. [Google Scholar] [CrossRef]
- Huang, H.; Huang, T.; Li, Z.; Lyu, S.; Hong, T. Design of Citrus Fruit Detection System Based on Mobile Platform and Edge Computer Device. Sensors 2022, 22, 59. [Google Scholar] [CrossRef] [PubMed]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Lyu, S.; Li, R.; Zhao, Y.; Li, Z.; Fan, R.; Liu, S. Green Citrus Detection and Counting in Orchards Based on YOLOv5-CS and AI Edge System. Sensors 2022, 22, 576. [Google Scholar] [CrossRef]
- Ye, Z.; Guo, Q.; Wei, J.; Zhang, J.; Zhang, H.; Bian, L.; Guo, S.; Zheng, X.; Cao, S. Recognition of terminal buds of densely-planted Chinese fir seedlings using improved YOLOv5 by integrating attention mechanism. Front. Plant Sci. 2022, 13, 991929. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Yan, J.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W. A Wheat Spike Detection Method in UA V Images Based on Improved YOLOv5. Remote Sens. 2021, 13, 3095. [Google Scholar] [CrossRef]
- Li, S.; Zhang, S.; Xue, J.; Sun, H. Lightweight target detection for the field flat jujube based on improved YOLOv5. Comput. Electron. Agric. 2022, 202, 107391. [Google Scholar] [CrossRef]
- Kamrul, M.H.; Rahman, M.; Robin, M.R.I.; Hossain, M.S.; Hasan, M.H.; Paul, P. A Deep Learning Based Approach on Categorization of Tea Leaf. In Proceedings of the International Conference on Computing Advancements (ICCA 2020), Dhaka, Bangladesh, 10–12 January 2020; Article No.: 72. pp. 1–8. [Google Scholar]
- Wei, K.; Chen, B.; Li, Z.; Chen, D.; Liu, G.; Lin, H.; Zhang, B. Classification of Tea Leaves Based on Fluorescence Imaging and Convolutional Neural Networks. Sensors 2022, 22, 7764. [Google Scholar] [CrossRef]
- Chen, Z.; He, L.; Ye, Y.; Chen, J.; Sun, L.; Wu, C.; Chen, L.; Wang, R. Automatic sorting of fresh tea leaves using vision-based recognition method. J. Food Process Eng. 2020, 43, e13474. [Google Scholar] [CrossRef]
- Cui, Q.; Yang, B.; Liu, B.; Li, Y.; Ning, J. Tea Category Identification Using Wavelet Signal Reconstruction of Hyperspectral Imagery and Machine Learning. Agriculture 2022, 12, 1085. [Google Scholar] [CrossRef]
- Yan, C.; Chen, Z.; Li, Z.; Liu, R.; Li, Y.; Xiao, H.; Lu, P.; Xie, B. Tea Sprout Picking Point Identification Based on Improved DeepLabV3+. Agriculture 2022, 12, 1594. [Google Scholar] [CrossRef]
- Chen, Y.T.; Chen, S.F. Localizing plucking points of tea leaves using deep convolutional neural networks. Comput. Electron. Agric. 2020, 171, 105298. [Google Scholar] [CrossRef]
- Tatsumi, K.; Igarashi, N.; Mengxue, X. Prediction of plant-Level tomato biomass and yield using machine learning with unmanned aerial vehicle imagery. Plant Methods 2021, 17, 77. [Google Scholar] [CrossRef] [PubMed]
- Lu, S.; Chen, W.; Zhang, X.; Karkee, M. Canopy-attention-YOLOv4-based immature/mature apple fruit detection on dense-foliage tree architectures for early crop load estimation. Comput. Electron. Agric. 2022, 193, 106696. [Google Scholar] [CrossRef]
- Lu, N.; Zhou, J.; Han, Z.; Li, D.; Cao, Q.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W.; Cheng, T. Improved estimation of aboveground biomass in wheat from RGB imagery and point cloud data acquired with a low-cost unmanned aerial vehicle system. Plant Methods 2019, 15, 17. [Google Scholar] [CrossRef] [Green Version]
- Yang, Q.; Shi, L.; Han, J.; Zha, Y.; Zhu, P. Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crop. Res. 2019, 235, 142–153. [Google Scholar] [CrossRef]
- Han, L.; Yang, G.; Dai, H.; Xu, B.; Yang, H.; Feng, H.; Li, Z.; Yang, X. Modeling maize aboveground biomass based on machine learning approaches using UAV remote-sensing data. Plant Methods 2019, 15, 10. [Google Scholar] [CrossRef] [Green Version]
- Escalante, H.J.; Rodríguez-Sánchez, S.; Jiménez-Lizárraga, M.; MoralesReyes, A.; De La Calleja, J.; Vazquez, R. Barley yield and fertilization analysis from UAV imagery: A deep learning approach. Int. J. Remote Sens. 2019, 40, 2493–2516. [Google Scholar] [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Qiu, Z.; Zhao, Z.; Chen, S.; Zeng, J.; Huang, Y.; Xiang, B. Application of an improved YOLOv5 algorithm in real-time detection of foreign objects by ground penetrating radar. Remote Sens. 2022, 14, 1895. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision; Springer: Munich, Germany, 2018; pp. 3–19. [Google Scholar]
- Bradley, A.P. The Use of the Area Under the ROC Curve in the Evaluation of Machine Learning Algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Chollet, F. Xception: Deep Learning with Depth wise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. arXiv 2018, arXiv:abs/1711.07767. [Google Scholar]
- Kubat, M.; Matwin, S. Addressing the Curse of Imbalanced Training Data Sets: One-sided Selection. In Proceedings of the 4th International Conference on Machine Learning, San Francisco, CA, USA, 8–12 July 1997. [Google Scholar]
- Huang, Q.; Xia, C.; Wu, C.; Li, S.; Wang, Y.; Song, Y.; Kuo, C.J. Semantic Segmentation with Reverse Attention. arXiv 2017, arXiv:abs/1707.06426. [Google Scholar]
- Ma, N.; Zhang, X.; Sun, J. Funnel Activation for Visual Recognition. arXiv 2020, arXiv:abs/2007.11824. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE++: Unified Content-Aware ReAssembly of Features. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4674–4687. [Google Scholar] [CrossRef]
- Rezatofighi, S.H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.D.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE Conference: Piscataway, NJ, USA, 2019; pp. 658–666. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T.S. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM international Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv preprint 2015, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. arXiv 2017, arXiv:abs/1711.05101. [Google Scholar]
- Mureşan, H.; Oltean, M. Fruit recognition from images using deep learning. arXiv preprint 2017, arXiv:1712.00580. [Google Scholar] [CrossRef] [Green Version]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Darwish, A.; Ezzat, D.; Hassanien, A.E. An optimized model based on convolutional neural networks and orthogonal learning particle swarm optimization algorithm for plant diseases diagnosis. Swarm Evol. Comput. 2020, 52, 100616. [Google Scholar] [CrossRef]
- Haase, D.; Amthor, M. Rethinking Depth wise Separable Convolutions: How In-tra-Kernel Correlations Lead to Improved MobileNets. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, Y.; Sun, L.; Zhang, Z.; He, H. Algorithm Research on Improving Activation Function of Convolutional Neural Networks. In Proceedings of the Chinese Control & Decision Conference, Nanchang, China, 3–5 June 2019; pp. 3582–3586. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Teng, Z.; Xing, J.; Gao, J.; Hu, W.; Maybank, S. Learning attentions: Residual at-tentional siamese network for high performance online visual tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 23 June 2018; pp. 4854–4863. [Google Scholar]
- Saxena, L.; Armstrong, L. A survey of image processing techniquesfor agriculture. In Proceedings of the Asian Federation for Information Technology in Agriculture, Hanoi, Vietnam, 24–26 November 2022; Australian Society of Information and Communication Technologies in Agriculture: Perth, Australia, 2022; pp. 401–413. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera Lens | ISO Speed | Resolution | Maximum Aperture |
|---|---|---|---|
| Zeiss Vario-Sonnar T | ISO-125 | 3648 × 2736 | F1.8(W)~2.8(T) |
| Positive Category | Negative Category | |
|---|---|---|
| Positive Prediction | True Positive (TP) | False Positive (FP) |
| Negative Prediction | False Negative (FN) | True Negative (TN) |
| System | CPU | GPU | Memory |
|---|---|---|---|
| Windows 10 21H2 | Intel(R) Core i7-7820x | NVIDIA GeForce GTX 1080 | 32 G |
| Model | Epochs | Convergence Time (h) | Layers | Parameters | Size (MB) |
|---|---|---|---|---|---|
| YOLOv5n | 253 | 2.773 | 213 | 1,760,518 | 4.2 |
| YOLOv5s | 196 | 2.433 | 213 | 7,012,822 | 14.8 |
| YOLOv5m | 201 | 4.294 | 290 | 20,852,934 | 42.6 |
| YOLOv5l | 246 | 15.467 | 367 | 46,108,278 | 93.2 |
| YOLOv5x | 237 | 13.422 | 444 | 86,173,414 | 173.5 |
| Improved YOLOv5 | 199 | 3.179 | 153 | 4,326,815 | 8.8 |
| Model | Train/ box_loss | Train/ obj_loss | Precision | Recall | mAP_0.5 | mAP_0.5:0.95 | Val/ box_loss | Val/ obj_loss |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 0.044635 | 0.066901 | 0.71316 | 0.71291 | 0.70232 | 0.2258 | 0.048975 | 0.059104 |
| YOLOv5s | 0.046034 | 0.074828 | 0.73444 | 0.74627 | 0.74697 | 0.26534 | 0.049554 | 0.055801 |
| YOLOv5m | 0.0459 | 0.067146 | 0.74894 | 0.7568 | 0.75755 | 0.26844 | 0.046898 | 0.055746 |
| YOLOv5l | 0.044313 | 0.066245 | 0.75449 | 0.7366 | 0.74373 | 0.26511 | 0.047924 | 0.057541 |
| YOLOv5x | 0.046262 | 0.070607 | 0.72062 | 0.75184 | 0.74489 | 0.2592 | 0.048473 | 0.057528 |
| Improved YOLOv5 | 0.030059 | 0.050968 | 0.94911 | 0.97642 | 0.91397 | 0.052312 | 0.24139 | 0.055131 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Li, X.; Yang, G.; Wang, F.; Men, S.; Xu, B.; Xu, Z.; Yang, H.; Yan, L. Research on Tea Trees Germination Density Detection Based on Improved YOLOv5. Forests 2022, 13, 2091. https://doi.org/10.3390/f13122091
Wang J, Li X, Yang G, Wang F, Men S, Xu B, Xu Z, Yang H, Yan L. Research on Tea Trees Germination Density Detection Based on Improved YOLOv5. Forests. 2022; 13(12):2091. https://doi.org/10.3390/f13122091
Chicago/Turabian StyleWang, Jinghua, Xiang Li, Guijun Yang, Fan Wang, Sen Men, Bo Xu, Ze Xu, Haibin Yang, and Lei Yan. 2022. "Research on Tea Trees Germination Density Detection Based on Improved YOLOv5" Forests 13, no. 12: 2091. https://doi.org/10.3390/f13122091