Large Area Forest Yield Estimation with Pushbroom Digital Aerial Photogrammetry


Abstract
:1. Introduction
2. Methods
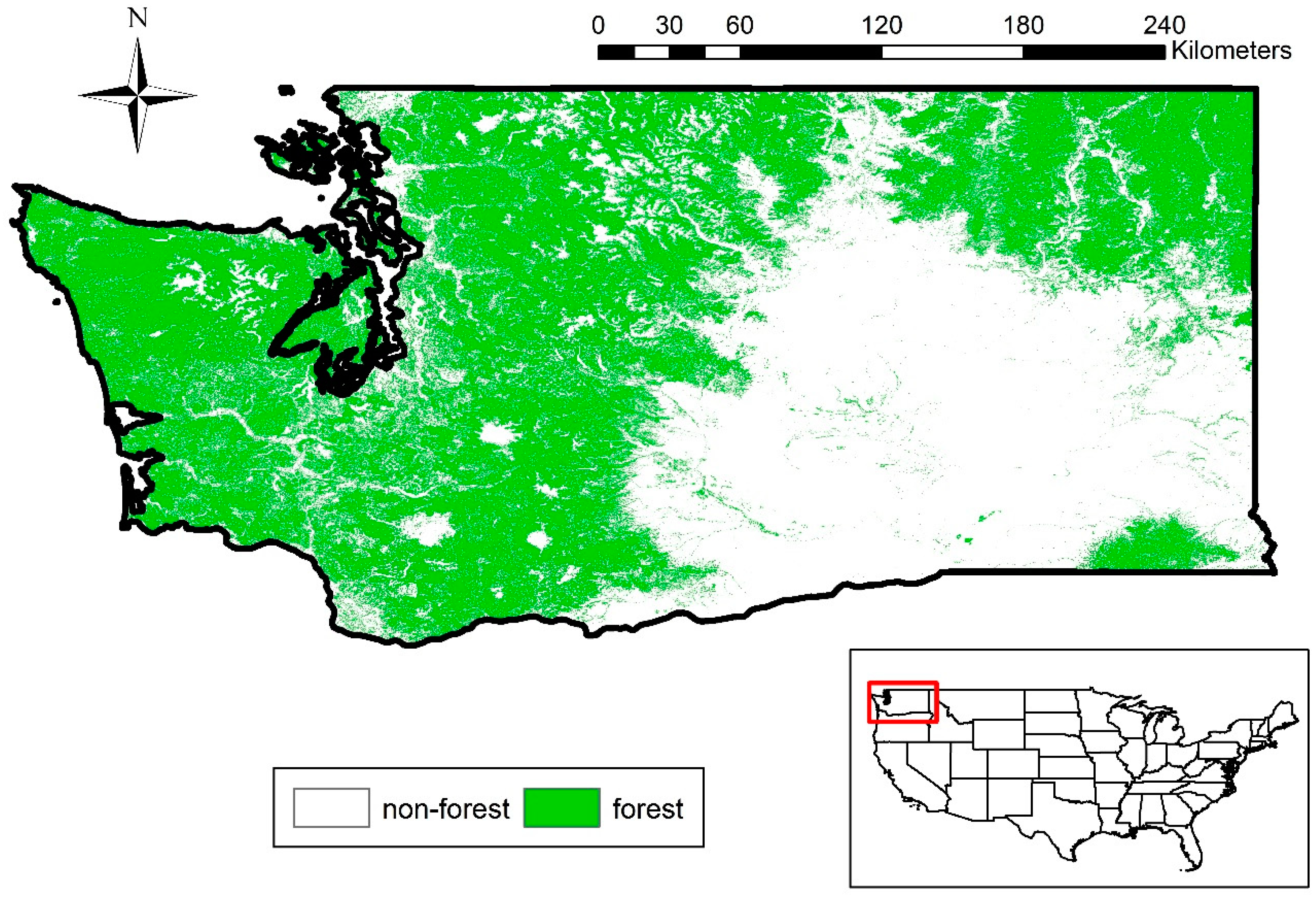
Study Site
3. Data
3.1. Field Measurements
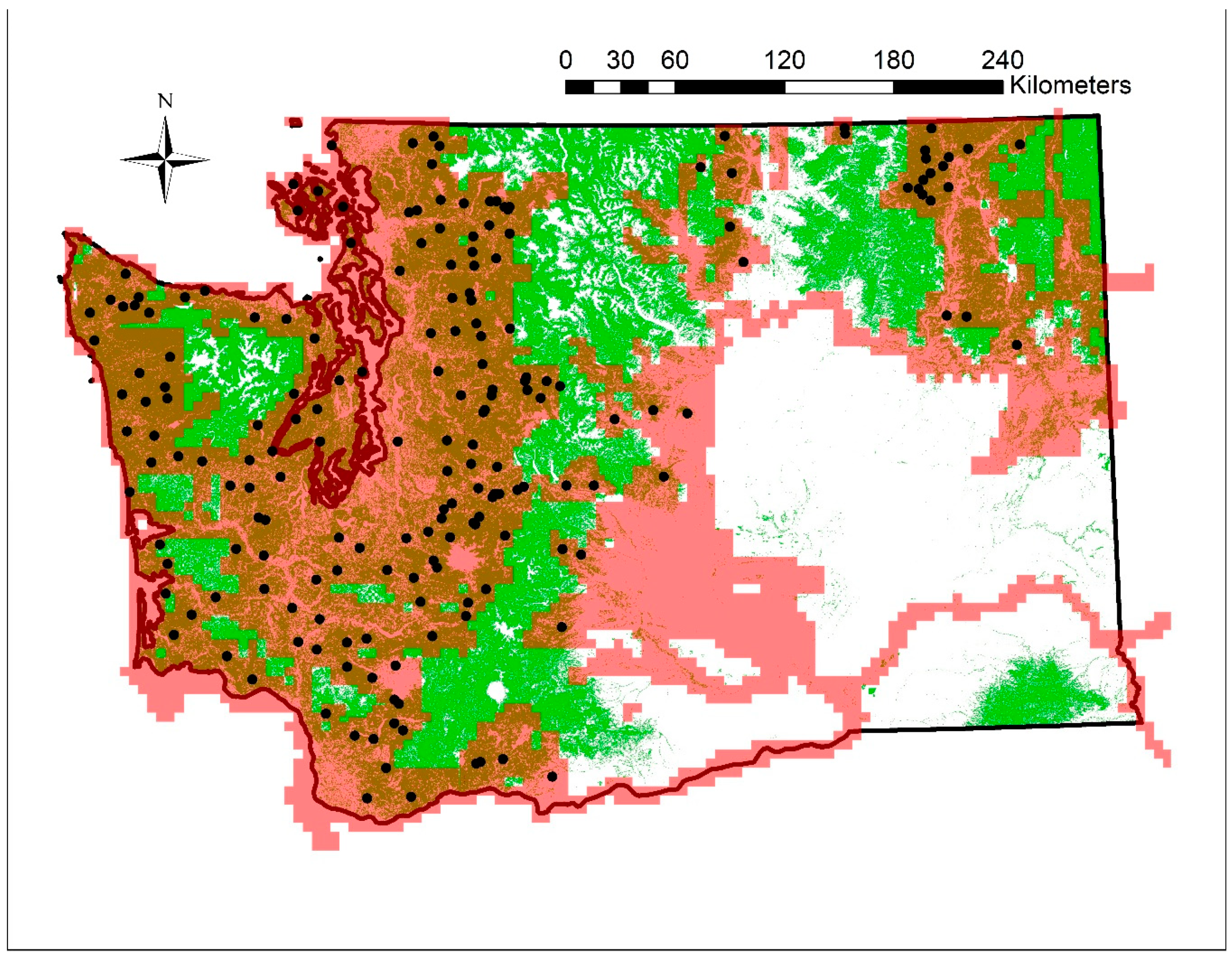
3.2. Plot Positioning
3.3. Photogrammetric Point Cloud (Photo Points)
3.4. Remotely-Sensed Structure Measurements
3.5. Forest Yield Estimation
3.6. Model Fitting and Post-Strata
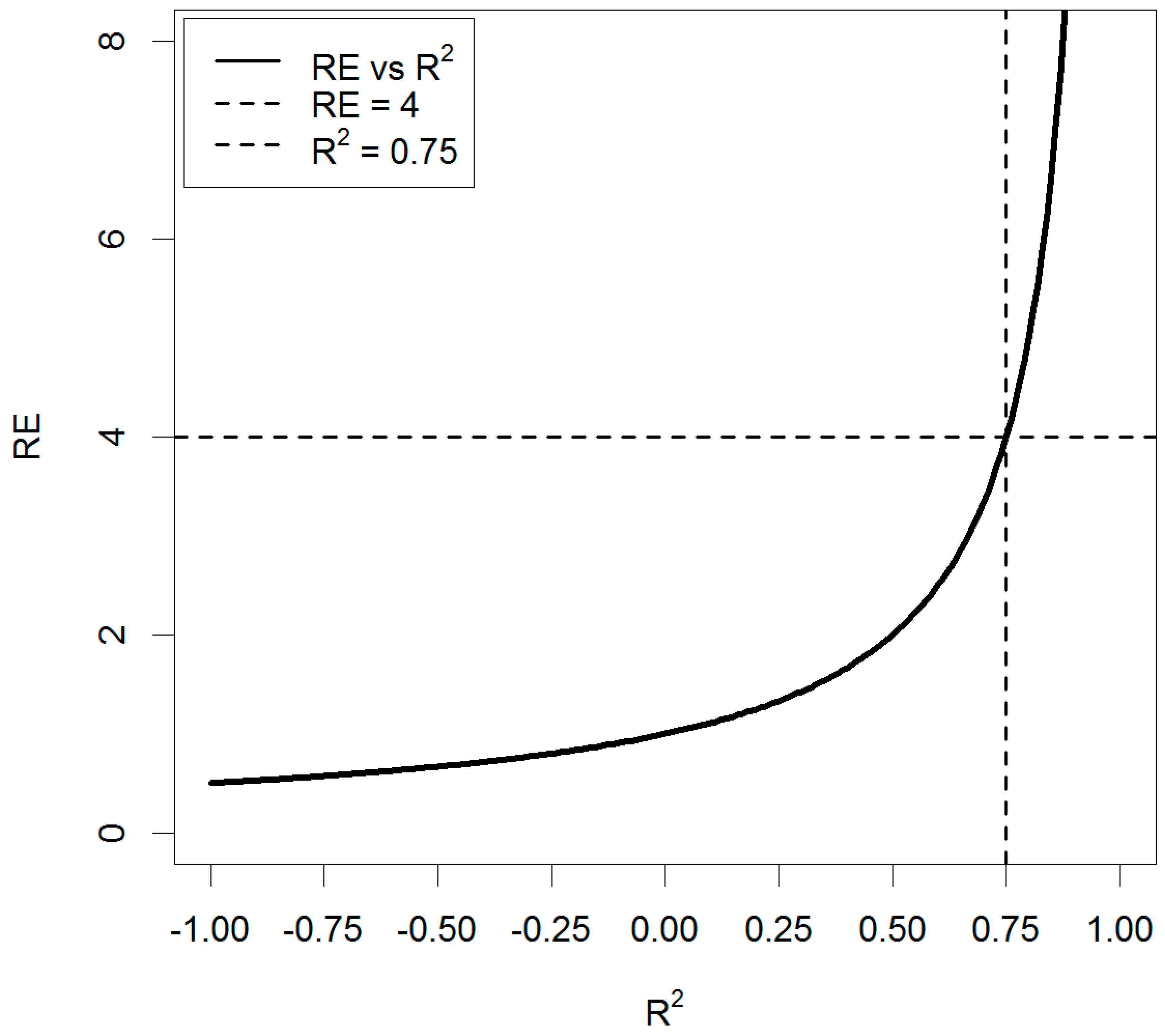
3.7. Efficiency Assessment
4. Results
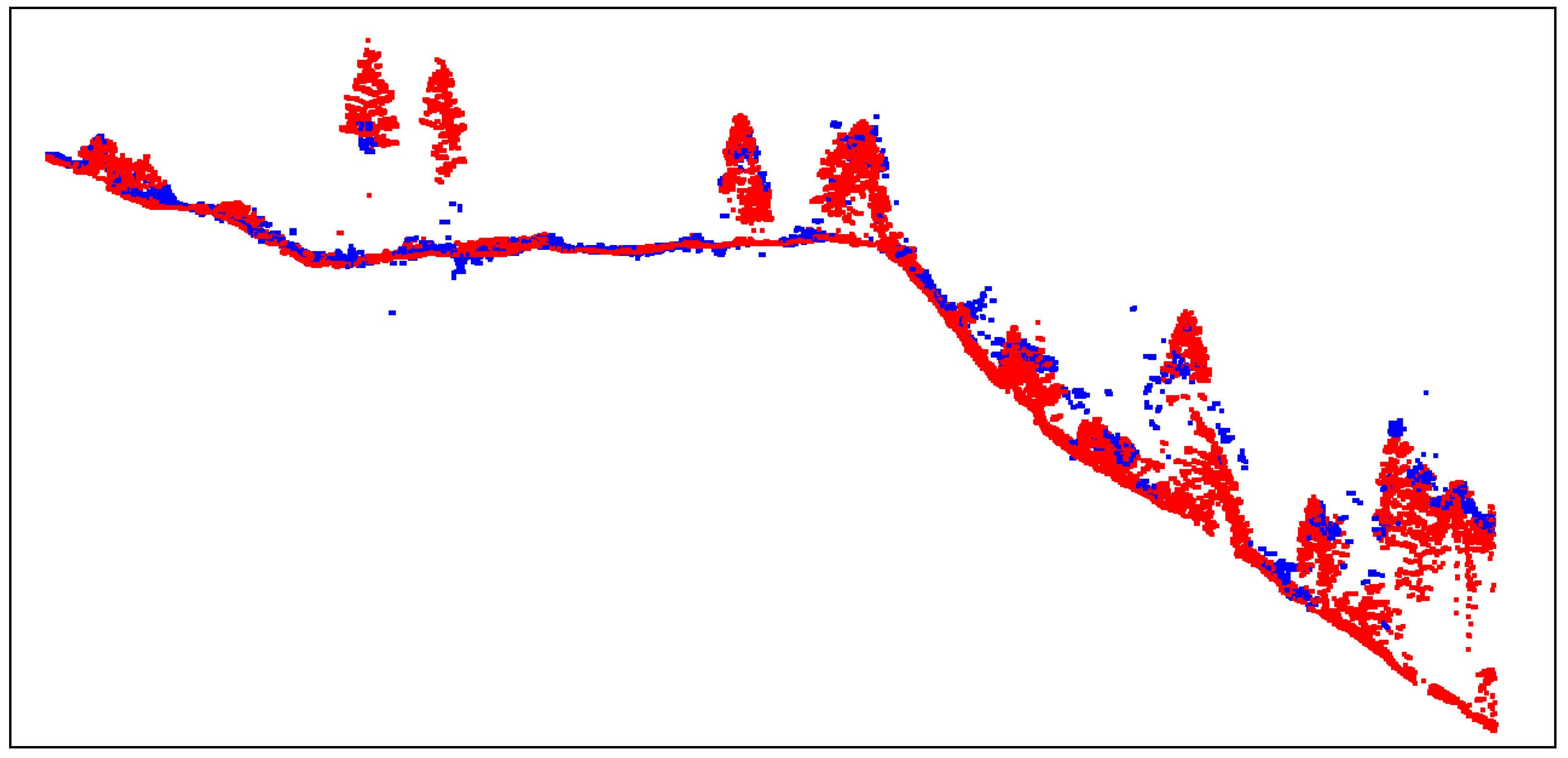
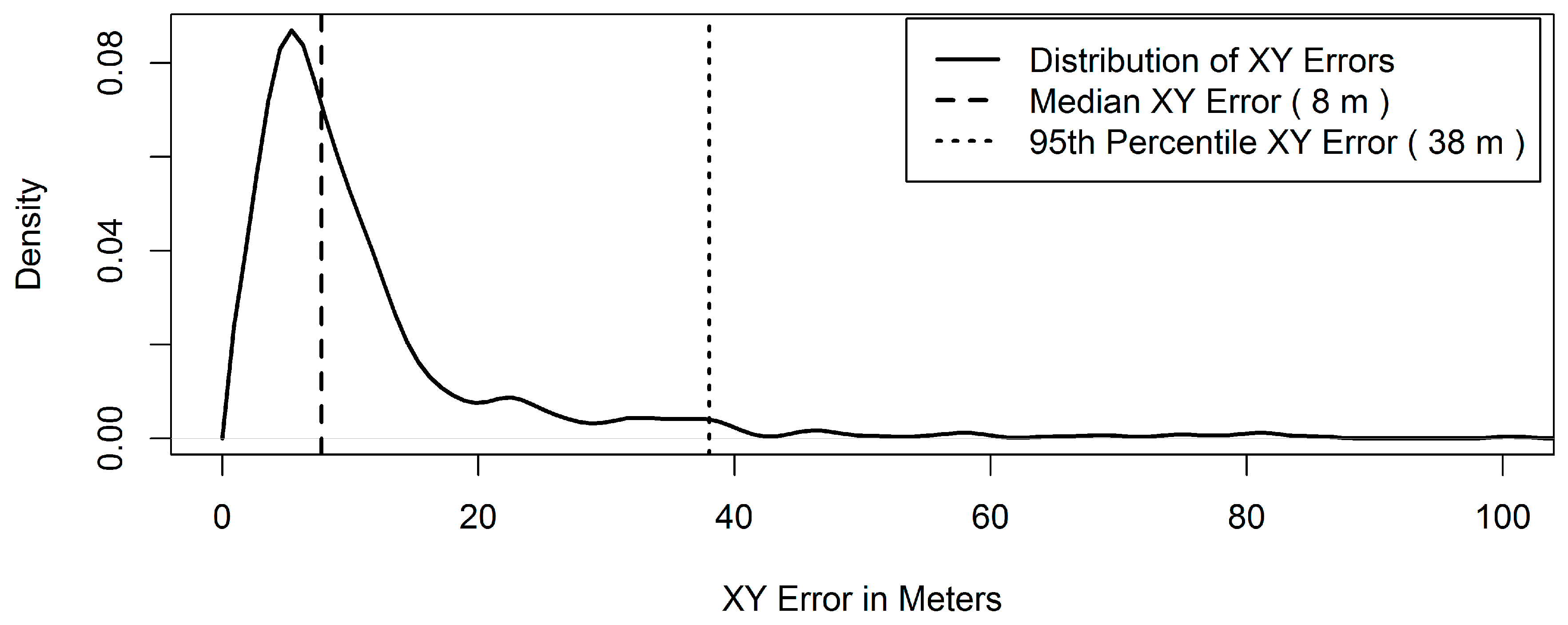
4.1. Coordinate Precision
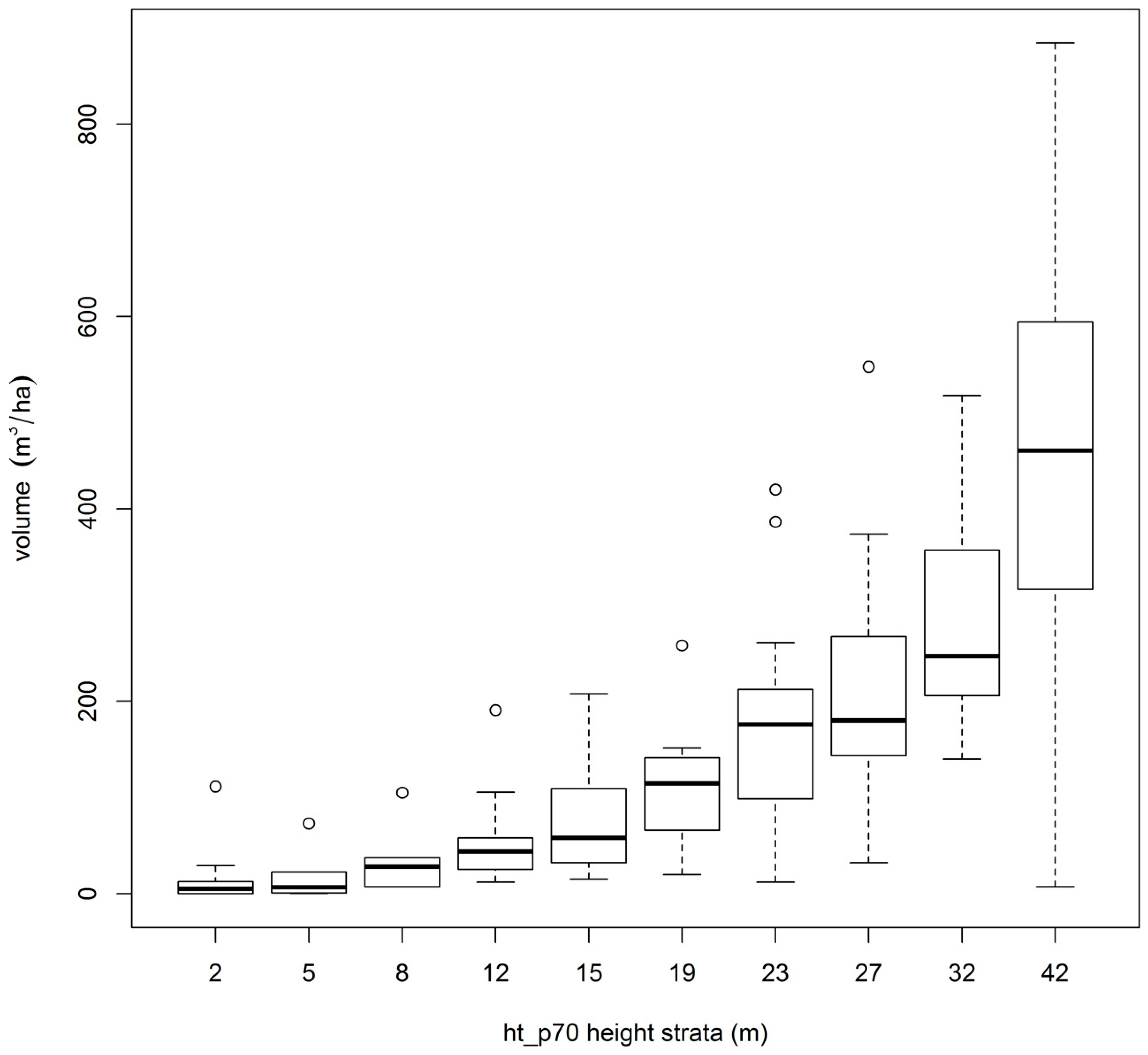
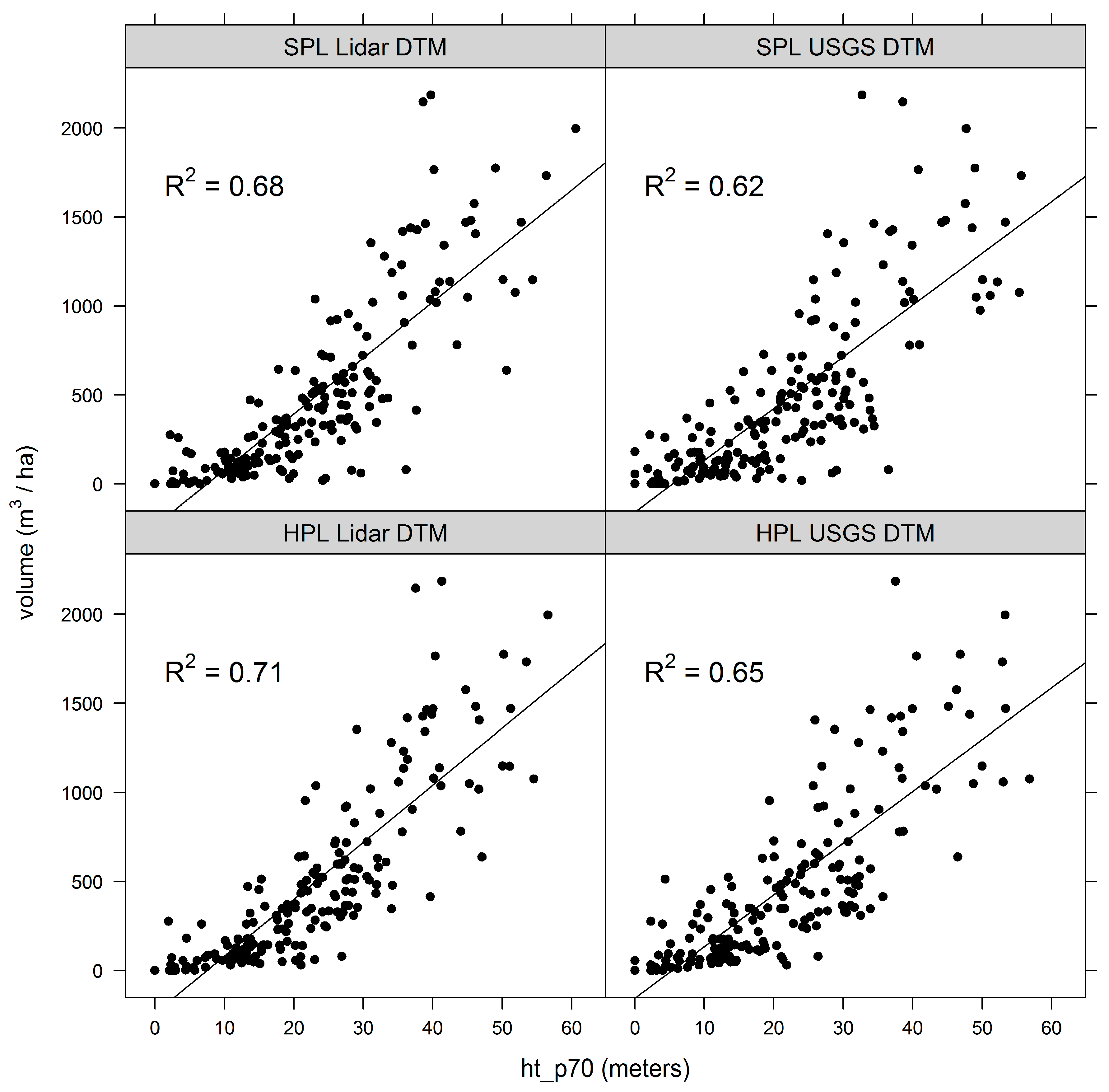
4.2. DAP Metrics versus Volume
4.3. Increased Map Resolution with DAP
4.4. Estimation Performance
5. Discussion
5.1. Terrain Models
5.2. Positional Accuracy
5.3. Estimators
5.4. Comparison with Other Studies
5.5. Feasibility
5.6. Monetary Value of Efficiency
5.7. Scope of Inference
5.8. Study Limitations and Future Direction
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Smith, W.B. Forest inventory and analysis: A national inventory and monitoring program. Environ. Pollut. 2002, 116, S233–S242. [Google Scholar] [CrossRef]
- The Enhanced Forest Inventory and Analysis Program: National Sampling Design and Estimation Procedures; Bechtold, W.A.; Patterson, P.L. (Eds.) US Department of Agriculture Forest Service, Southern Research Station: Asheville, NC, USA, 2005.
- Blackard, J.A.; Finco, M.V.; Helmer, E.H.; Holden, G.R.; Hoppus, M.L.; Jacobs, D.M.; Lister, A.J.; Moisen, G.G.; Nelson, M.D.; Riemann, R.; et al. Mapping U.S. forest biomass using nationwide forest inventory data and moderate resolution information. Remote Sens. Environ. 2008, 112, 1658–1677. [Google Scholar] [CrossRef]
- Waring, R.H.; Coops, N.C.; Fan, W.; Nightingale, J.M. MODIS enhanced vegetation index predicts tree species richness across forested ecoregions in the contiguous U.S.A. Remote Sens. Environ. 2006, 103, 218–226. [Google Scholar] [CrossRef]
- Næsset, E. Determination of mean tree height of forest stands using airborne laser scanner data. ISPRS J. Photogramm. Remote Sens. 1997, 52, 49–56. [Google Scholar] [CrossRef]
- Holmgren, J. Prediction of tree height, basal area and stem volume in forest stands using airborne laser scanning. Scand. J. For. Res. 2004, 19, 543–553. [Google Scholar] [CrossRef]
- Anderson, H.E.; Breidenbach, J. Statistical Properties of Mean Stand Biomass Estimators in a Lidar-Based Double Sampling Forest Survey Design; International Society for Photogrammetry and Remote Sensing: Istanbul, Turkey, 2007; p. 8. [Google Scholar]
- Patenaude, G.; Hill, R.A.; Milne, R.; Gaveau, D.L.A.; Briggs, B.B.J.; Dawson, T.P. Quantifying forest above ground carbon content using LiDAR remote sensing. Remote Sens. Environ. 2004, 93, 368–380. [Google Scholar] [CrossRef]
- Andersen, H.-E.; McGaughey, R.J.; Reutebuch, S.E. Estimating forest canopy fuel parameters using LIDAR data. Remote Sens. Environ. 2005, 94, 441–449. [Google Scholar] [CrossRef]
- Strunk, J.L.; Reutebuch, S.E.; Andersen, H.-E.; Gould, P.J.; McGaughey, R.J. Model-assisted forest yield estimation with light detection and ranging. West. J. Appl. For. 2012, 27, 53–59. [Google Scholar] [CrossRef]
- Sugarbaker, L.J.; Eldridge, D.F.; Jason, A.L.; Lukas, V.; Saghy, D.L.; Stoker, J.M.; Thunen, D.R. Status of the 3D Elevation Program, 2015; US Geological Survey: Reston, VA, USA, 2017.
- White, J.C.; Stepper, C.; Tompalski, P.; Coops, N.C.; Wulder, M.A. Comparing ALS and image-based point cloud metrics and modelled forest inventory attributes in a complex coastal forest environment. Forests 2015, 6, 3704–3732. [Google Scholar] [CrossRef]
- Bohlin, J.; Wallerman, J.; Fransson, J.E.S. Forest variable estimation using photogrammetric matching of digital aerial images in combination with a high-resolution DEM. Scand. J. For. Res. 2012, 27, 692–699. [Google Scholar] [CrossRef]
- Vastaranta, M.; Wulder, M.A.; White, J.C.; Pekkarinen, A.; Tuominen, S.; Ginzler, C.; Kankare, V.; Holopainen, M.; Hyyppä, J.; Hyyppä, H. Airborne laser scanning and digital stereo imagery measures of forest structure: comparative results and implications to forest mapping and inventory update. Can. J. Remote Sens. 2013, 39, 382–395. [Google Scholar] [CrossRef]
- National Elevation Dataset (NED) | The Long Term Archive. Available online: https://lta.cr.usgs.gov/NED (accessed on 7 August 2018).
- Gesch, D.B.; Oimoen, M.J.; Evans, G.A. Accuracy Assessment of the US Geological Survey National Elevation Dataset, and Comparison with Other Large-area Elevation Datasets: SRTM and ASTER; US Geological Survey: Reston, VA, USA, 2014.
- US Department of Commerce. National Geodetic Survey—CORS Homepage. Available online: https://www.ngs.noaa.gov/CORS/ (accessed on 2 October 2018).
- McGaughey, R.J.; Ahmed, K.; Andersen, H.-E.; Reutebuch, S.E. Effect of Occupation Time on the Horizontal Accuracy of a Mapping-Grade GNSS Receiver under Dense Forest Canopy. Photogramm. Eng. Remote Sens. 2017, 83, 861–868. [Google Scholar] [CrossRef]
- NAIP Imagery. Available online: https://www.fsa.usda.gov/programs-and-services/aerial-photography/imagery-programs/naip-imagery/ (accessed on 12 March 2019).
- Isenburg, M. LASzip: lossless compression of LiDAR data. Photogramm. Eng. Remote Sens. 2013, 79, 209–217. [Google Scholar] [CrossRef]
- Davis, D. NAIP Accuracy and Ground Control Point Collections 2016. Available online: https://www.fgdc.gov/groups/naip-accuracy-and-gcps-20160804.pptx (accessed on 5 February 2019).
- McGaughey, R.J. FUSION/LDV: Software for LIDAR Data Analysis and Visualization, Version 3.01; USFS: Seattle, WA, USA, 2016.
- Washington Lidar Portal. Available online: http://lidarportal.dnr.wa.gov/ (accessed on 6 March 2019).
- Särndal, C.E.; Swensson, B.; Wretman, J. Model Assisted Survey Sampling; Springer Verlag: New York, NY, USA, 2003. [Google Scholar]
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley & Sons: New York, NY, USA, 1977; ISBN 0-471-16240-X. [Google Scholar]
- Goerndt, M.E.; Monleon, V.J.; Temesgen, H. Small-Area Estimation of County-Level Forest Attributes Using Ground Data and Remote Sensed Auxiliary Information. For. Sci. 2013, 59, 536–548. [Google Scholar] [CrossRef]
- Furnival, G.M.; Wilson, R.W., Jr. Regressions by leaps and bounds. Technometrics 1974, 16, 499–511. [Google Scholar] [CrossRef]
- Myllymäki, M.; Gobakken, T.; Næsset, E.; Kangas, A. The efficiency of poststratification compared with model-assisted estimation. Can. J. For. Res. 2016, 47, 515–526. [Google Scholar] [CrossRef]
- Magnussen, S.; Andersen, H.-E.; Mundhenk, P. A Second Look at Endogenous Poststratification. For. Sci. 2015, 61, 624–634. [Google Scholar] [CrossRef]
- Breidt, F.J.; Opsomer, J.D. Endogenous post-stratification in surveys: Classifying with a sample-fitted model. Ann. Stat. 2008, 36, 403–427. [Google Scholar] [CrossRef]
- Pearse, G.D.; Dash, J.P.; Persson, H.J.; Watt, M.S. Comparison of high-density LiDAR and satellite photogrammetry for forest inventory. ISPRS J. Photogramm. Remote Sens. 2018, 142, 257–267. [Google Scholar] [CrossRef]
- D’Oliveira, M.V.; Reutebuch, S.E.; McGaughey, R.J.; Andersen, H.-E. Estimating forest biomass and identifying low-intensity logging areas using airborne scanning lidar in Antimary State Forest, Acre State, Western Brazilian Amazon. Remote Sens. Environ. 2012, 124, 479–491. [Google Scholar] [CrossRef]
- Kukkonen, M.; Maltamo, M.; Packalen, P. Image matching as a data source for forest inventory—Comparison of Semi-Global Matching and Next-Generation Automatic Terrain Extraction algorithms in a typical managed boreal forest environment. Int. J. Appl. Earth Obs. Geoinf. 2017, 60, 11–21. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Gobakken, T.; Næsset, E. Post-stratified estimation of forest area and growing stock volume using lidar-based stratifications. Remote Sens. Environ. 2012, 125, 157–166. [Google Scholar] [CrossRef]
- Särndal, C.E. The calibration approach in survey theory and practice. Surv. Methodol. 2007, 33, 99–119. [Google Scholar]
- Packalén, P.; Maltamo, M. Estimation of species-specific diameter distributions using airborne laser scanning and aerial photographs. Can. J. For. Res. 2008, 38, 1750–1760. [Google Scholar] [CrossRef]
- Means, J.E.; Acker, S.A.; Fitt, B.J.; Renslow, M.; Emerson, L.; Hendrix, C. Predicting Forest Stand Characteristics with Airborne Scanning Lidar. Photogramm. Eng. Remote Sens. 2000, 66, 1367–1371. [Google Scholar]
- Popescu, S.C.; Wynne, R.H.; Scrivani, J.A. Fusion of Small-Footprint Lidar and Multispectral Data to Estimate Plot- Level Volume and Biomass in Deciduous and Pine Forests in Virginia, USA. For. Sci. 2004, 50, 551–565. [Google Scholar]
- Frazer, G.W.; Magnussen, S.; Wulder, M.A.; Niemann, K.O. Simulated impact of sample plot size and co-registration error on the accuracy and uncertainty of LiDAR-derived estimates of forest stand biomass. Remote Sens. Environ. 2011, 115, 636–649. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Liknes, G.C.; Domke, G.M. Using a remote sensing-based, percent tree cover map to enhance forest inventory estimation. For. Ecol. Manag. 2014, 331, 12–18. [Google Scholar] [CrossRef]
- Yang, L.; Jin, S.; Danielson, P.; Homer, C.; Gass, L.; Bender, S.M.; Case, A.; Costello, C.; Dewitz, J.; Fry, J.; et al. A new generation of the United States National Land Cover Database: Requirements, research priorities, design, and implementation strategies. ISPRS J. Photogramm. Remote Sens. 2018, 146, 108–123. [Google Scholar] [CrossRef]
- St-Onge, B.; Hu, Y.; Vega, C. Mapping the height and above-ground biomass of a mixed forest using lidar and stereo Ikonos images. Int. J. Remote Sens. 2008, 29, 1277–1294. [Google Scholar] [CrossRef]
- Gobakken, T.; Næsset, E. Estimation of diameter and basal area distributions in coniferous forest by means of airborne laser scanner data. Scand. J. For. Res. 2004, 19, 529–542. [Google Scholar] [CrossRef]
- Hawryło, P.; Tompalski, P.; Wężyk, P. Area-based estimation of growing stock volume in Scots pine stands using ALS and airborne image-based point clouds. For. Int. J. For. Res. 2017, 90, 686–696. [Google Scholar] [CrossRef]
- Available online: http://www.asprs.org/a/society/about.html (accessed on 21 August 2018).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimator | Dataset | SE (m3/ha) | RE | R2 |
|---|---|---|---|---|
| post-stratified | HPL lidar | 22.60 | 4.16 | 0.76 |
| post-stratified | SPL lidar | 24.74 | 3.47 | 0.71 |
| post-stratified | HPL USGS | 24.38 | 3.57 | 0.72 |
| post-stratified | SPL USGS | 27.06 | 2.88 | 0.65 |
| regression | HPL lidar | 23.72 | 3.78 | 0.74 |
| regression | SPL lidar | 23.97 | 3.70 | 0.73 |
| regression | HPL USGS | 25.80 | 3.19 | 0.69 |
| regression | SPL USGS | 26.44 | 3.01 | 0.67 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Strunk, J.; Packalen, P.; Gould, P.; Gatziolis, D.; Maki, C.; Andersen, H.-E.; McGaughey, R.J. Large Area Forest Yield Estimation with Pushbroom Digital Aerial Photogrammetry. Forests 2019, 10, 397. https://doi.org/10.3390/f10050397
Strunk J, Packalen P, Gould P, Gatziolis D, Maki C, Andersen H-E, McGaughey RJ. Large Area Forest Yield Estimation with Pushbroom Digital Aerial Photogrammetry. Forests. 2019; 10(5):397. https://doi.org/10.3390/f10050397
Chicago/Turabian StyleStrunk, Jacob, Petteri Packalen, Peter Gould, Demetrios Gatziolis, Caleb Maki, Hans-Erik Andersen, and Robert J. McGaughey. 2019. "Large Area Forest Yield Estimation with Pushbroom Digital Aerial Photogrammetry" Forests 10, no. 5: 397. https://doi.org/10.3390/f10050397