

A Novel Intelligent Method for Fault Diagnosis of Steam Turbines Based on T-SNE and XGBoost


Abstract
:1. Introduction
2. Methods
2.1. Performance Indicator Extraction Based on t-SNE and K-Means
2.2. Imbalanced Data Recognition Model Based on SMOTE and XGBoost
2.3. Model Assessment Method
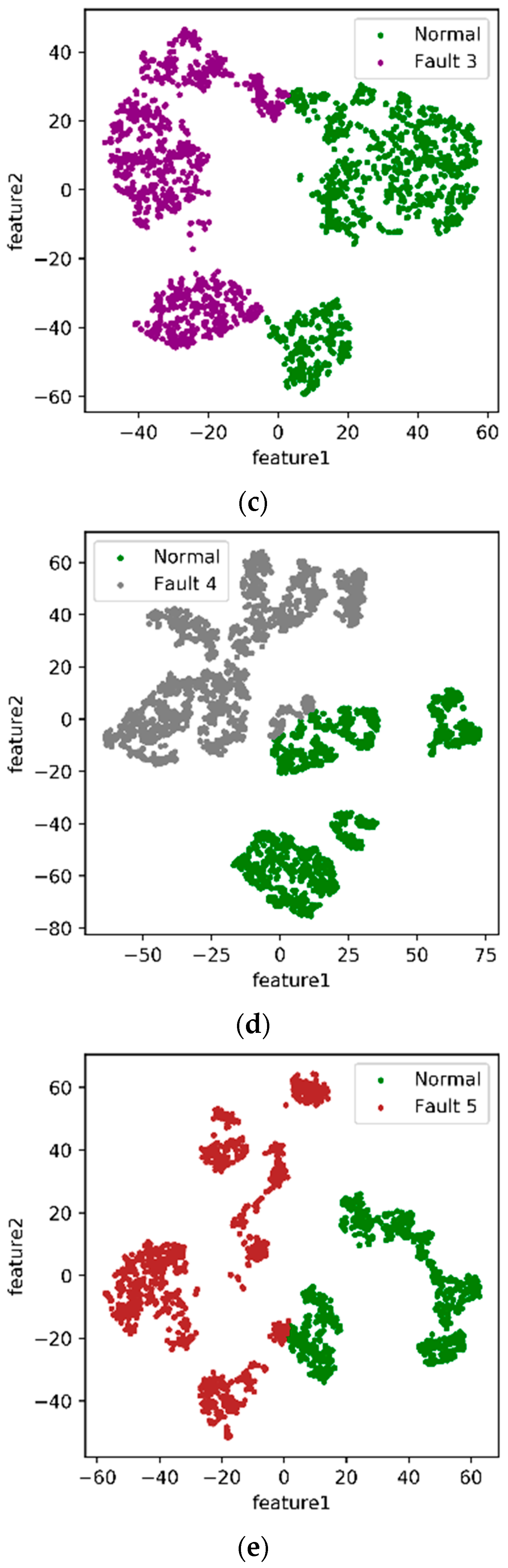
3. Experiments, Results and Discussion
3.1. Introduction of Data Set
3.2. Setting Labels for Different or Normal Faults
3.3. Dealing with Data Imbalance
3.4. Test Results
3.5. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Algorithm A1. T-SNE algorithm. |
| #!/usr/bin/env python # coding: utf-8 import os import sys os.chdir (os.path.split (os.path.realpath (sys.argv [0]))[0]) import numpy from numpy import * import numpy as np from sklearn.manifold import TSNE from sklearn.datasets import load_iris from sklearn.decomposition import PCA import matplotlib.pyplot as plt import pandas as pd df1 = pd.read_excel (‘D:/data/gz5.xlsx’) df1.label.value_counts () def get_data (data): X = data.drop (columns = [‘time’, ‘label’]).values y = data.label.values n_samples, n_features = X.shape return X, y, n_samples, n_features X1, y1, n_samples1, n_features1 = get_data (df1) X_tsne = TSNE (n_components = 2,init = ‘pca’, random_state = 0).fit_transform (X1) def plot_embedding (X, y, title = None): x_min, x_max = np.min(X, 0), np.max(X, 0) X = (X − x_min) / (x_max − x_min) plt.figure () ax = plt.subplot (111) for i in range (X.shape [0]): plt.text (X [i, 0], X [i, 1], ‘.’, color = plt.cm.Set1 (y[i] * 3/10.), fontdict = {‘weight’: ‘bold’, ‘size’: 9}) plt.xticks ([]), plt.yticks ([]) if title is not None: plt.title (title) plot_embedding (X_tsne, y1) from sklearn.cluster import KMeans from sklearn.externals import joblib from sklearn import cluster estimator = KMeans (n_clusters = 2) res = estimator.fit_predict (X_tsne) lable_pred = estimator.labels_ centroids = estimator.cluster_centers_ inertia = estimator.inertia_ from pandas import DataFrame XA = DataFrame (res) XA.to_csv (‘D:/data/gz5out.csv’) |
| Algorithm A2. XGBoost algorithm. |
| #!/usr/bin/env python # coding: utf-8 from xgboost import plot_importance from matplotlib import pyplot as plt import xgboost as xgb from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import numpy as np import pandas as pd from xgboost.sklearn import XGBClassifier # load data data = pd.read_csv (‘D:/data/suanfa/kyq.csv’) x, y = data.loc [:,data.columns.difference ([‘label’])].values, data [‘label’].values x_train, x_test, y_train, y_test = train_test_split (x, y, test_size = 0.3) data.label.value_counts () params ={‘learning_rate’: 0.1, ‘max_depth’: 2, ‘n_estimators’:50, ‘num_boost_round’:10, ‘objective’: ‘multi:softprob’, ‘random_state’: 0, ‘silent’:0, ‘num_class’:6, ‘eta’:0.9 } model = xgb.train (params, xgb.DMatrix (x_train, y_train)) y_pred = model.predict (xgb.DMatrix (x_test)) yprob = np.argmax (y_pred, axis = 1) # return the index of the biggest pro model.save_model (‘testXGboostClass.model’) yprob = np.argmax (y_pred, axis = 1) # return the index of the biggest pro predictions = [round (value) for value in yprob] # evaluate predictions accuracy = accuracy_score(y_test, predictions) print (“Accuracy: %.2f%%” % (accuracy * 100.0)) plot_importance (model) plt.show () xgb1 = XGBClassifier ( learning_rate = 0.1, n_estimators = 20, max_depth = 2, num_boost_round = 10, random_state = 0, silent = 0, objective = ‘multi:softprob’, num_class = 6, eta = 0.9 ) xgb1.fit (x_train, y_train) y_pred1 = xgb1.predict_proba (x_test) yprob1 = np.argmax (y_pred1, axis = 1) # return the index of the biggest pro from sklearn.metrics import confusion_matrix confusion_matrix (y_test.astype (‘int’), yprob1.astype (‘int’)) from sklearn.metrics import classification_report print (‘Accuracy of Classifier:’,xgb1.score (x_test, y_test.astype (‘int’))) print (classification_report (y_test.astype (‘int’), yprob1.astype (‘int’))) |
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Description |
|---|---|
| F0 | Time stamp |
| F1 | Turbine Speed |
| F2 | Main Steam Pressure |
| F3 | Reheat Steam Pressure |
| F4 | Main Steam Temp |
| F5 | Bearing Bushing 11 |
| F6 | Bearing Bushing 12 |
| F7 | Bearing Bushing 21 |
| F8 | Bearing Bushing 22 |
| F9 | Bearing Bushing 31 |
| F10 | Bearing Bushing 32 |
| F11 | Bearing Bushing 41 |
| F12 | Bearing Bushing 42 |
| F13 | Bearing Bushing 51 |
| F14 | Bearing Bushing 61 |
| F15 | Bearing Vibration 1X |
| F16 | Bearing Vibration 1Y |
| F17 | Bearing Vibration 1Z |
| F18 | Bearing Vibration 2X |
| F19 | Bearing Vibration 2Y |
| F20 | Bearing Vibration 2Z |
| F21 | Bearing Vibration 3X |
| F22 | Bearing Vibration 3Y |
| F23 | Bearing Vibration 3Z |
| F24 | Bearing Vibration 4X |
| F25 | Bearing Vibration 4Y |
| F26 | Bearing Vibration 4Z |
| F27 | Bearing Vibration 5X |
| F28 | Bearing Vibration 5Y |
| F29 | Bearing Vibration 5Z |
| F30 | Bearing Vibration 6X |
| F31 | Bearing Vibration 6Y |
| F32 | Bearing Vibration 6Z |
| F33 | Turbine Differential Expansion |
| F34 | Rotor Eccentricity |
References
- Yu, J.; Jang, J.; Yoo, J.; Park, J.H.; Kim, S. A fault isolation method via classification and regression tree-based variable ranking for drum-type steam boiler in thermal power plant. Energies 2018, 11, 1142. [Google Scholar] [CrossRef]
- Madrigal, G.; Astorga, C.M.; Vazquez, M.; Osorio, G.L.; Adam, M. Fault diagnosis in sensors of boiler following control of a thermal power plant. IEEE Lat. Am. Trans. 2018, 16, 1692–1699. [Google Scholar] [CrossRef]
- Wu, Y.; Li, W.; Sheng, D.; Chen, J.; Yu, Z. Fault diagnosis method of peak-load-regulation steam turbine based on improved PCA-HKNN artificial neural network. Proc. Inst. Mech. Eng. O J. Risk Reliab. 2021, 235, 1026–1040. [Google Scholar] [CrossRef]
- Cao, H.; Niu, L.; Xi, S.; Chen, X. Mechanical model development of rolling bearing-rotor systems: A review. Mech. Syst. Signal Process. 2018, 102, 37–58. [Google Scholar] [CrossRef]
- Xu, Y.; Zhen, D.; Gu, J.; Rabeyee, K.; Chu, F.; Gu, F.; Ball, A.D. Autocorrelated Envelopes for early fault detection of rolling bearings. Mech. Syst. Signal Process. 2021, 146, 106990. [Google Scholar] [CrossRef]
- Kazemi, P.; Ghisi, A.; Mariani, S. Classification of the Structural Behavior of Tall Buildings with a Diagrid Structure: A Machine Learning-Based Approach. Algorithms 2022, 15, 349. [Google Scholar] [CrossRef]
- Shi, Q.; Zhang, H. Fault Diagnosis of an Autonomous Vehicle With an Improved SVM Algorithm Subject to Unbalanced Datasets. IEEE Trans. Ind. Electron. 2021, 68, 6248–6256. [Google Scholar] [CrossRef]
- Zhang, P.; Gao, Z.; Cao, L.; Dong, F.; Zhou, Y.; Wang, K.; Zhang, Y.; Sun, P. Marine Systems and Equipment Prognostics and Health Management: A Systematic Review from Health Condition Monitoring to Maintenance Strategy. Machines 2022, 10, 72. [Google Scholar] [CrossRef]
- Li, X.; Wu, S.; Li, X.; Yuan, H.; Zhao, D. Particle swarm optimization-Support Vector Machine model for machinery fault diagnoses in high-voltage circuit breakers. Chin. J. Mech. Eng. 2020, 33, 6. [Google Scholar] [CrossRef]
- Zan, T.; Liu, Z.; Wang, H.; Wang, M.; Gao, X.; Pang, Z. Prediction of performance deterioration of rolling bearing based on JADE and PSO-SVM. Proc. Inst. Mech. Eng. C J. Mech. Eng. Sci. 2020, 235, 1684–1697. [Google Scholar] [CrossRef]
- Fink, O.; Wang, Q.; Svensen, M.; Dersin, P.; Lee, W.-J.; Ducoffe, M. Potential, challenges and future directions for deep learning in prognostics and health management applications. Eng. Appl. Artif. Intell. 2020, 92, 103678. [Google Scholar] [CrossRef]
- Deng, W.; Yao, R.; Zhao, H.; Yang, X.; Li, G. A novel intelligent diagnosis method using optimal LS-SVM with improved PSO algorithm. Soft Comput. 2019, 23, 2445–2462. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, L. Simulation study on fault diagnosis of power electronic circuits based on wavelet packet analysis and support vector machine. J. Electr. Syst. 2018, 14, 21–33. [Google Scholar]
- Wang, Z.; Xia, H.; Yin, W.; Yang, B. An improved generative adversarial network for fault diagnosis of rotating machine in nuclear power plant. Ann. Nucl. Energy 2023, 180, 109434. [Google Scholar] [CrossRef]
- Kang, C.; Wang, Y.; Xue, Y.; Mu, G.; Liao, R. Big Data Analytics in China’s Electric Power Industry. IEEE Power Energy Mag. 2018, 16, 54–65. [Google Scholar] [CrossRef]
- Ma, Y.; Huang, C.; Sun, Y.; Zhao, G.; Lei, Y. Review of Power Spatio-Temporal Big Data Technologies for Mobile Computing in Smart Grid. IEEE Access 2019, 7, 174612–174628. [Google Scholar] [CrossRef]
- Lai, C.S.; Locatelli, G.; Pimm, A.; Wu, X.; Lai, L.L. A review on long-term electrical power system modeling with energy storage. J. Clean. Prod. 2021, 280, 124298. [Google Scholar] [CrossRef]
- Dhanalakshmi, J.; Ayyanathan, N. A systematic review of big data in energy analytics using energy computing techniques. Concurr. Comput. Pract. Exp. 2021, 34, e6647. [Google Scholar] [CrossRef]
- Li, W.; Li, X.; Niu, Q.; Huang, T.; Zhang, D.; Dong, Y. Analysis and Treatment of Shutdown Due to Bearing Vibration Towards Ultra-supercritical 660MW Turbine. IOP Conf. Ser. Earth Environ. Sci. 2019, 300, 42006–42008. [Google Scholar] [CrossRef]
- Ashraf, W.M.; Rafique, Y.; Uddin, G.M.; Riaz, F.; Asin, M.; Farooq, M.; Hussain, A.; Salman, C.A. Artificial intelligence based operational strategy development and implementation for vibration reduction of a supercritical steam turbine shaft bearing. Alex. Eng. J. 2022, 61, 1864–1880. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Gisbrecht, A.; Schulz, A.; Hammer, B. Parametric nonlinear dimensionality reduction using kernel t-SNE. Neurocomputing 2015, 147, 71–82. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.-H.; Chen, C.-P. Applying t-SNE to Estimate Image Sharpness of Low-cost Nailfold Capillaroscopy. Intell. Autom. Soft Comput. 2022, 32, 237–254. [Google Scholar] [CrossRef]
- Xu, X.; Xie, Z.; Yang, Z.; Li, D.; Xu, X. A t-SNE Based Classification Approach to Compositional Microbiome Data. Front. Genet. 2020, 11, 620143. [Google Scholar] [CrossRef]
- Yi, C.; Tuo, S.; Tu, S.; Zhang, W. Improved fuzzy C-means clustering algorithm based on t-SNE for terahertz spectral recognition. Infrared Phys. Technol. 2021, 117, 103856. [Google Scholar] [CrossRef]
- Gutierrez-Lopez, A.; Gonzalez-Serrano, F.-J.; Figueiras-Vidal, A.R. Optimum Bayesian thresholds for rebalanced classification problems using class-switching ensembles. Pattern Recognit. 2023, 135, 109158. [Google Scholar] [CrossRef]
- Arora, J.; Tushir, M.; Sharma, K.; Mohan, L.; Singh, A.; Alharbi, A.; Alosaimi, W. MCBC-SMOTE: A Majority Clustering Model for Classification of Imbalanced Data. CMC-Comput. Mater. Contin. 2022, 73, 4801–4817. [Google Scholar] [CrossRef]
- Kumar, A.; Gopal, R.D.; Shankar, R.; Tan, K.H. Fraudulent review detection model focusing on emotional expressions and explicit aspects: Investigating the potential of feature engineering. Decis. Support Syst. 2022, 155, 113728. [Google Scholar] [CrossRef]
- Guo, S.; Chen, R.; Li, H.; Zhang, T.; Liu, Y. Identify Severity Bug Report with Distribution Imbalance by CR-SMOTE and ELM. Int. J. Softw. Eng. Knowl. Eng. 2019, 29, 139–175. [Google Scholar] [CrossRef]
- Duan, G.; Han, W. Heavy Overload Prediction Method of Distribution Transformer Based on GBDT. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2259014. [Google Scholar] [CrossRef]
- Liu, X.; Liu, W.; Huang, H.; Bo, L. An improved confusion matrix for fusing multiple K-SVD classifiers. Knowl. Inf. Syst. 2022, 64, 703–722. [Google Scholar] [CrossRef]
- Maldonado, S.; López, J.; Jimenez-Molina, A.; Lira, H. Simultaneous feature selection and heterogeneity control for SVM classification: An application to mental workload assessment. Expert Syst. Appl. 2020, 143, 112988. [Google Scholar] [CrossRef]
- Anowar, F.; Sadaoui, S.; Selim, B. Conceptual and empirical comparison of dimensionality reduction algorithms (PCA, KPCA, LDA, MDS, SVD, LLE, ISOMAP, LE, ICA, t-SNE). Comput. Sci. Rev. 2021, 40, 100378. [Google Scholar] [CrossRef]
- Khan, N.; Taqvi, S.A.A. Machine Learning an Intelligent Approach in Process Industries: A Perspective and Overview. ChemBioEng Rev. 2023. [Google Scholar] [CrossRef]




| Proposed Method | Other Literatures | |
|---|---|---|
| Data set source | Actual data from the actual plant | Experimental data or numerical simulation data |
| Data length | Larger (months or even years) | Smaller (hours or days) |
| Fault label | Partly missing or being blurred | Identified by the experiment |
| Fault verification | Based on real faults in the plant | Based on simulated faults |
| Iterative strategy for research | Determined by the actual operation of the plant | Unable to iterate |
| Significance of research | Solving practical problems | Continuous improvement of research algorithms |
| Data Set | Sample Size | Time Range |
|---|---|---|
| Steam turbine | 340,468 | January to August in 2018 |
| No. | Fault Discovery Time |
|---|---|
| 1 | 3 Feb 2018 2:07 |
| 2 | 11 Feb 2018 6:19 |
| 3 | 13 Mar 2018 7:28 |
| 4 | 10 Jun 2018 7:44 |
| 5 | 7 Aug 2018 23:17 |
| No. | Start Time | End Time | Advanced Time (min) |
|---|---|---|---|
| 1 | 3 Feb 2018 0:14 | 3 Feb 2018 6:45 | 113 |
| 2 | 10 Feb 2018 22:02 | 11 Feb 2018 16:16 | 497 |
| 3 | 12 Mar 2018 19:32 | 13 Mar 2018 11:10 | 716 |
| 4 | 9 Jun 2018 14:53 | 10 Jun 2018 17:25 | 1011 |
| 5 | 7 Aug 2018 12:07 | 8 Aug 2018 6:25 | 670 |
| Original Data | by SMOTE | |
|---|---|---|
| Normal | 78,513 | 78,513 |
| Fault 1 | 392 | 5832 |
| Fault 2 | 1095 | 16,823 |
| Fault 3 | 939 | 14,402 |
| Fault 4 | 1593 | 24,655 |
| Fault 5 | 1099 | 16,801 |
| Ratio | 15:1 | 1:1 |
| Confusion Matrix | Predicted Result (%) | |||||
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | |
| 0 | 97.06 | 0.08 | 1.09 | 0.67 | 0.37 | 0.73 |
| 1 | 0.06 | 99.94 | 0 | 0 | 0 | 0 |
| 2 | 1.24 | 0 | 98.76 | 0 | 0 | 0 |
| 3 | 2.36 | 0 | 0 | 97.64 | 0 | 0 |
| 4 | 0.41 | 0 | 0 | 0 | 99.59 | 0 |
| 5 | 0.27 | 0 | 0 | 0 | 0 | 99.72 |
| Fault Label | Precision | Recall Rate | F1-Score |
|---|---|---|---|
| 0 | 99.18% | 96.80% | 97.98% |
| 1 | 98.74% | 100.00% | 99.37% |
| 2 | 94.54% | 99.02% | 97.07% |
| 3 | 96.52% | 97.63% | 97.07% |
| 4 | 98.52% | 99.70% | 99.11% |
| 5 | 96.58% | 99.72% | 98.13% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, Z.; Zhang, L.; Wang, X. A Novel Intelligent Method for Fault Diagnosis of Steam Turbines Based on T-SNE and XGBoost. Algorithms 2023, 16, 98. https://doi.org/10.3390/a16020098
Liang Z, Zhang L, Wang X. A Novel Intelligent Method for Fault Diagnosis of Steam Turbines Based on T-SNE and XGBoost. Algorithms. 2023; 16(2):98. https://doi.org/10.3390/a16020098
Chicago/Turabian StyleLiang, Zhiguo, Lijun Zhang, and Xizhe Wang. 2023. "A Novel Intelligent Method for Fault Diagnosis of Steam Turbines Based on T-SNE and XGBoost" Algorithms 16, no. 2: 98. https://doi.org/10.3390/a16020098