1. Introduction
In many optimization problems arising in the decision science area, given a finite set
E of elements having a vector cost
c associated with them, the objective function is to find a feasible subset
, such that the difference in value between the most costly and the least costly selected elements is minimized. Such problems are denoted as balanced optimization problems (BOPs). One of the first approaches to solve a BOP is presented in [
1], where the authors consider the set
E as an
n ×
n assignment matrix, the cost
as the value contained in a generic cell
e of the assignment matrix, and the subset
F the selected cells of the defined assignment, thus obtaining the balanced assignment problem. Successively, Ref. [
2] introduced the minimum deviation problem, which minimizes the difference between the maximum and average weights in a solution. In the same paper, the authors proposed a general solution scheme also suitable for BOPs. Since then, numerous real-world applications have been defined and solved as BOPs, always with the goal of minimizing the deviation between the highest and lowest cost, or making the performance indices of interest as equal as possible. In the latter case, the most proposed applications in the literature as BOPs include, though are not limited to, production line operations in manufacturing systems (e.g., see [
3,
4,
5,
6] among others) and supply chain management [
7,
8]. Other BOPs were proposed in the class of flow and routing problems on networks, where the goal is to design either a single path or a subset of paths in which the arcs or nodes belonging to the solution have a homogeneous value of their relative weights, such as travel time, length, etc. (see [
9,
10,
11], among others).
This paper deals with a variant of the Shortest Path Problem (
) that fits into the class of BOPs. This problem, recently introduced in the literature [
12], is denoted Cost Balanced Path Problem (
).
The
is defined on a directed weighted graph
, where
N is the set of nodes and
A is the set of directed arcs. For each arc
there is a weight
; the weights represent either the increment (in case of positive weight) or the decrement (in case of negative weight) of the cost to balance along the path. The problem is to select in graph
G a path
p from an origin node
o to a destination node
d that minimizes the absolute value of the sum of the weights of path
p. More formally, the objective function of the
is given by:
In [
12] the authors demonstrate that the
, as many variants of the
[
13], is NP-hard in its general form. Moreover, they demonstrate that, in the following two particular cases, the
can be solved in polynomial time:
When all costs are non-negative or non-positive (i.e., or , ). In this case, the problem is equivalent to the ;
When the cost of the arc is a function of the elevation difference of the two nodes associated with the arc.
The reader may observe that the objective function (1) imposes minimization of an always positive value. For this reason, zero is a lower bound for the CBPP. This implies that any solution with zero objective function value, coincident with the lower bound, will always be optimal. The can be used for modelling various real problems that require the decision-maker to choose a path in a graph from an origin node to a destination one balancing some elements. Among others, the problems of route design for automated guided vehicles, the vehicles’ loading in pick-up and delivery, and storage and retrieval problems in warehouses and yards deserve attention. Another interesting application of the CBPP concerns electric vehicles with limited battery levels, considering, for example, that maintaining a lithium battery at a charge value of about helps to extend its life. In this case, given a graph, the positive or negative values associated with arcs represent, respectively, energy consumption or recharging obtained on downhill roads or through charging stations. Identifying a path in this graph so that the car arrives at its destination with a similar level of charge as at the start would extend the average life of a battery.
In [
12], the authors proposed a mixed-integer linear programming model for solving the
and tested it by using different sets of random instances. Experimental tests on the model showed that the computation time of instances that do not have zero as the optimal solution is significantly higher. For these more complex instances, it is, therefore, necessary to develop heuristic algorithms. Unfortunately, at least to the authors’ knowledge, no solution approaches for the
have been proposed in the literature. Instead, heuristic algorithms have been presented for some problems closely related to the
.
One of the most relevant and similar problem to the
is the cost-balanced Travelling Salesman Problem (
) introduced in [
14], in which the main objective is to find a Hamiltonian cycle in a graph with total travel cost as close to zero as possible. In [
15], the authors propose a variable neighborhood search algorithm, which is a local search with multiple neighborhood structures, to solve the cost-balanced
. The balanced
is widely described in [
16], where an equitable distribution of resources is the main objective. The authors cited many balanced combinatorial optimization problems studied in the literature, and proposed four different heuristics, derived by the double-threshold algorithm and the bottleneck one, to solve the balanced
. To solve the same problem, in [
17] an adaptive iterated local search is proposed with a perturbation and a random restart that can help in escaping local optimum. In [
18], a multiple balanced
TSP is analyzed to model and optimize the problems with multiple objectives (salesmen). The goal is to find
m Hamiltonian cycles in a graph
G by minimizing the difference between the highest edge cost and the smallest edge cost in the tours.
Another problem on graphs closely related to the
is the search for the balanced trees [
19], defined as the most appropriate structures (precisely the balanced tree structures) for managing networks with the aim of balancing two or more objectives. In [
20], the authors face the problem of finding two paths in a tree with positive and negative weights. They presented two polynomial algorithms with the goal of minimizing, respectively, the sum of the minimum weighted distances from every node of the tree to the two paths, and the sum of the weighted minimum distances from every node of the tree to the two paths.
To cover the above-mentioned lack of efficient solution methods for the
, the main aim of this paper is to propose a heuristic algorithm able to solve large instances of the problem. Since it is not possible to make comparisons with other heuristics proposed in the literature for the
, to validate the computational results, an iterative heuristic algorithm is presented. Thus, in the present paper, two heuristic approaches are described, tested, and compared. The first is a two-step heuristic algorithm that implements a constructive heuristic algorithm in the first step (
) followed by an improvement phase (
). The constructive step is a modified version of the well-known Dijkstra algorithm to solve
[
21], made necessary to deal with both positive and negative costs and the need to minimize the absolute value of the cost of the path. The second step of the algorithm
, starting from the feasible solution provided by
, tries to improve it using the information stored by
. In particular, starting from the destination node, algorithm
goes forward to evaluate new nodes that do not belong to the best-found path in
. A similar approach operating forward from the destination node is adopted in the definition of urban multimodal networks [
22]. Note that the Dijkstra algorithm has often been combined in solution approaches for solving some variants of the
, as, for example, in [
23,
24,
25]. The second heuristic algorithm is an iterative neighborhood search procedure [
26] based on an initial randomly generated solution, improved thanks to
previously cited. Among the hundred generated starting solutions, the best one obtained is given for comparison with the previous method.
The computation efficiency of proposed algorithms is tested with randomly generated instances of different sizes, densities, and arc weights. Since no other tests obtained with previously proposed heuristics to solve are available as validation of the proposed algorithms, we have compared them.
The remaining of this paper is organized as follows.
Section 2 presents the proposed algorithms for the
, while
Section 3 reports the computational experiments.
Section 4 gives some conclusions and perspectives.
3. Computational Experiments
In this section, we report the computational experimentation performed to validate the proposed algorithms. The computational tests were performed on a MacBook Pro (Apple Inc., Cupertino, CA, USA), with a 2.9 GHz Intel i9 (Intel Inc., Santa Clara, CA, USA) processor and 32 GB of RAM. In all tests, we used as input the two sets of instances reported in [
12] and some new large random instances also generated, as described in [
12].
The first set of instances, named
, is characterized by complete square grids, where each node is connected to its four neighbors. The second set of instances, named
, is characterized by randomly generated connected graphs with the average degree ranging from 2 to 20. All instances used in this section can be found at the link [
28]. In the following, we will refer to these instances as
, where
represents the number of nodes and
represents the percentage of arcs incident on each vertex. The third set of instances is an extension of the
instances generated with the same criteria but with a number of nodes equal to
and 5000.
The costs associated with the arcs of each instance were generated following 3 different schemes, based on a homogeneous distribution of randomly generated costs with different ranges, respectively, , and .
Each row in the following tables reports the average of the results of five instances.
In the following different experimental campaigns are reported.
3.1. First Experimental Campaign: Small Instances
Small instances have been optimally solved by the mathematical model presented in [
12], thus we are able to compare the results obtained by the proposed
algorithm with the optimal solutions. Thanks to the following results, it is possible to understand the behaviour of the proposed algorithm, in particular the effectiveness of
, and to compare
and
instances.
Table 1 shows the number of optimal solutions obtained, respectively, using
and
. Looking at
Table 1, we can observe that
always improves the solutions obtained by
. This improvement is more evident for instances with costs
, while the number of optimal solutions remains almost the same for
instances. The two sets of instances (
and
) have the same behavior.
All instances can be solved in less than one millisecond.
Actually, in
Table 2 are reported the absolute objective function values obtained at the end of
and
for instances with randomly generated costs in
,
and
. Note that, the optimal value for all instances is zero (as shown in [
12]). From
Table 2, it is evident that it is always possible to improve the objective function values using
after
. In particular, for the largest instances (i.e., last row of each group), both Grid and Rand, with costs in
,
is able to provide optimal solutions. On average, for grid instances, the improvements are 92.3%, 92.2% and 87.8%, respectively, for instances with costs
,
, and
. The improvements are about 70% for instances of type Rand_100, and about 82% for Rand_100. In all cases, the improvement is lower when costs are in
.
Finally, by comparing the results shown in
Table 2 with the optimal values, that is for all these instances equal to zero, we can note that the optimality gap is larger for instances with costs in
.
In further computational experimentation, we solved instances whose optimal value of the objective function is not zero. In particular, the costs associated with the arcs of the corresponding graph are obtained as follows: a random cost is associated with each node in the range [0, 10,000]. Then, the cost of an arc is obtained by a random perturbation of the displacement of the costs. We will refer to this cost structure as .
For this type of instance, we noted that the proposed algorithm did not provide good solutions, even if it performs very quickly. The best case corresponds to the Rand _100 _03 set of instances, for which the optimal value is 6005, while the solutions obtained at the end of and , respectively, are 6557 and 5431, thus corresponding to an optimality gap of 7%. Unfortunately, in the worst case, we have a set of instances (Rand_200_20) with the average optimal function value equal to 74, while our algorithm is not able to go down 2605. Note that, also in these cases, the computational time is negligible.
The above computational results suggest that the proposed algorithm can produce effective solutions in case of very large instances and when the cost of the arcs is generated uniformly. Instead, it appears that the algorithm cannot be used for instances with cost-structure . It also seems that as the size of the instances increases, the quality of the solution produced improves, as does the number of optimal solutions identified.
3.2. Second Experimental Campaign: Large Instances
This experimental campaign is based on the third set of generated instances, a set of random, larger-sized instances, for which it is not possible to obtain the optimal solution by the mathematical model used to solve small instances.
These tests permit a better investigation of the behavior of the proposed algorithm. The obtained results are compared with those of the iterated neighborhood search procedure. In these new sets of instances, the number of nodes ranges from 500 to 5000. For completeness, the following tables report also the results related to small instances. Note that tests have been executed with costs generated uniformly ([−10, 10], [−100, 100] and [1K, 1K]) and with cost structure .
Table 3 shows the behavior of
as the size of the instances increases. The number of solutions with objective function values equal to zero is shown. Although we do not know the optimal solution for the generated large instances, obviously we can certify the optimality of the heuristic solution in case a solution with an objective function value equal to zero is identified. We can see that, as the size of the instance increases, the number of zero-solutions improves. The table shows that the proposed algorithm is able to identify 92% of optimal solutions for the solved instances (i.e., 167 on 180) in case of uniform cost distribution in
. In all instances with a number of nodes greater than or equal to 500, we can obtain the optimal solution. Moreover, with the increase in
also for the distribution of costs
we are able to identify numerous optimal solutions, with
we identify at least 25 optimal solutions (i.e., 83%).
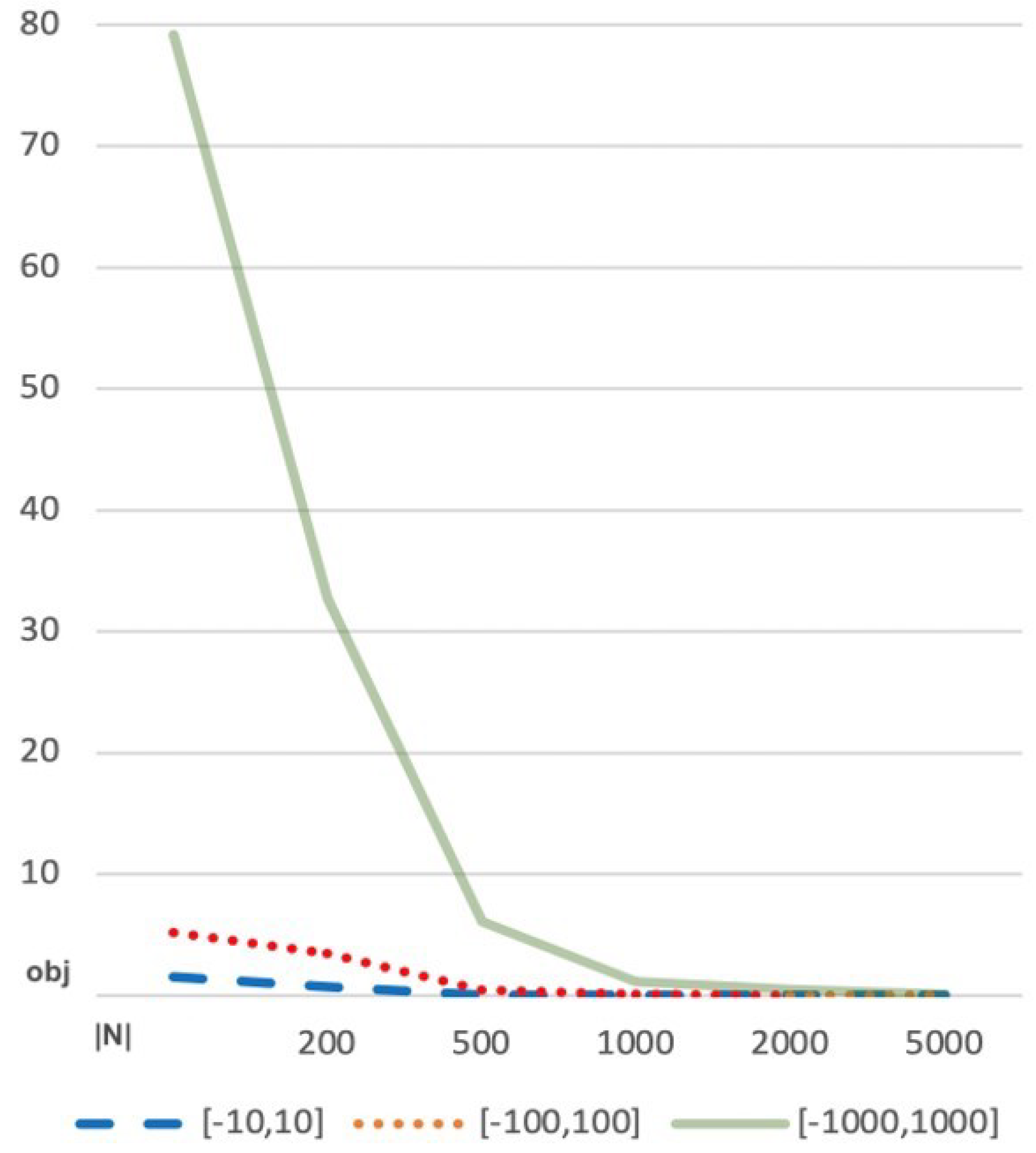
Table 4 shows the average value of the objective function for the same scenario as
Table 3. The data contained in this table are used in
Figure 4 to highlight how the solution produced improves as the size increases.
Table 5 reports the CPU time in milliseconds. The computational time required to produce a solution using the
is less than half a second even for instances with 5000 nodes. These computational times suggest that the average number of iterations of the algorithm is significantly less than the number of iterations associated with the computational complexity of the worst case
.
Table 6 shows the average number of iterations performed by
. The
column is useful to understand how many iterations, on average, are performed for every million theoretical iterations associated with the worst case
.
Figure 5 shows the relationship between the number of iterations and the number of nodes in the graph. For the set of instances used, the trend as
increases appears linear.
In the following tables, the results obtained by
are compared with those obtained by using the iterated neighborhood search procedure described in
Section 2.2. In each Table, both the best among the first random paths (
) and the best path after the improvement phase (
) are reported.
Table 7 and
Table 8 show, respectively, the number of optimal solutions and the computational times in milliseconds, identified by
,
and
.
It can be seen from these tables that produces the maximum number of optimal solutions in about of the computational time required by the and iterative techniques.
In particular, is able to find more 30% optimal solutions than for costs [−100, 100] and , and about 180% for cost [−1K, 1K].
These results also show that applied to the significantly increases the number of optimal solutions identified by the , passing from 181 to 319 optimal solutions identified; the greatest effect is on instances with cost and [−1K, 1K].








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}