Feature Papers in Combinatorial Optimization, Graph, and Network Algorithms
Share This Topical Collection
Editor
 Prof. Dr. Roberto Montemanni
Prof. Dr. Roberto Montemanni
Prof. Dr. Roberto Montemanni
E-Mail
Website
Collection Editor
Department of Sciences and Methods for Engineering, University of Modena and Reggio Emilia, 42100 Reggio Emilia, Italy
Interests: combinatorial optimization; operations research; machine learning; artificial intelligence; logistics; heuristic algorithms; exact algorithms
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
This Topical Collection “Feature Paper in Combinatorial Optimization, Graph, and Network Algorithms” aims to collect high-quality research articles and review articles in the wide fields of combinatorial optimization, graph theory, operations research and industrial engineering. The topics are of great interest both in academia and industry, spanning from theoretical results to applied contributions. Artificial Intelligence is becoming a popular tool in the field, therefore contributions incorporating such an aspect are encouraged. Survey papers are also welcome.
Prof. Dr. Roberto Montemanni
Collection Editor
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Algorithms is an international peer-reviewed open access monthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 1600 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- artificial intelligence
- big data analytics and optimization
- business analytics
- control theory and system dynamics
- covering and location
- cutting and packing
- disaster management
- discrete and combinatorial optimization
- emergency and humanitarian logistics
- financial modeling and risk management
- game theory
- graph theory and network optimization
- heuristics and metaheuristics
- industrial production
- linear and nonlinear programming
- logistics
- machine learning
- mathematical programming
- multiple-criteria decision making
- network analytics
- network medicine
- optimization software
- planning and project management
- railway and air traffic problems
- routing
- scheduling and timetabling
- simulation and queuing theory
- social networks
- soft OR
- stochastic and robust optimization
- supply chain management
- traffic and transportation
Published Papers (26 papers)
Open AccessArticle
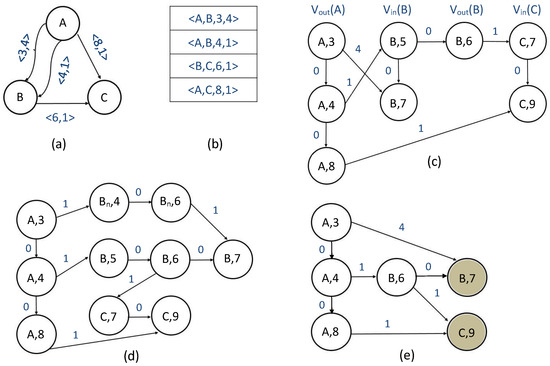
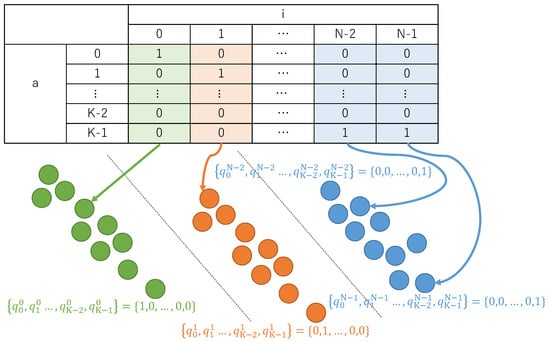
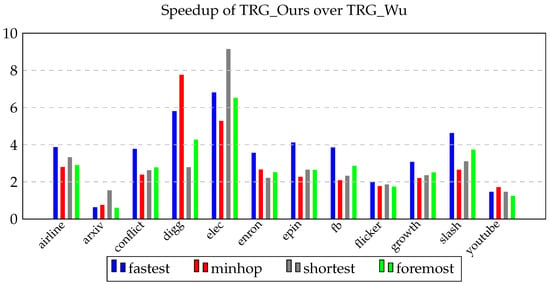
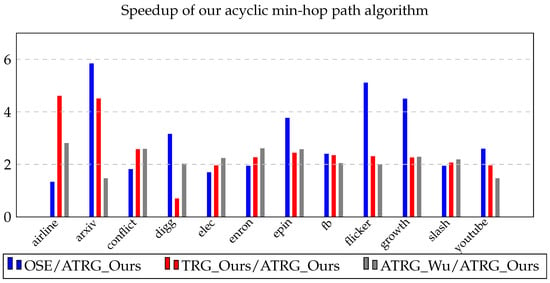
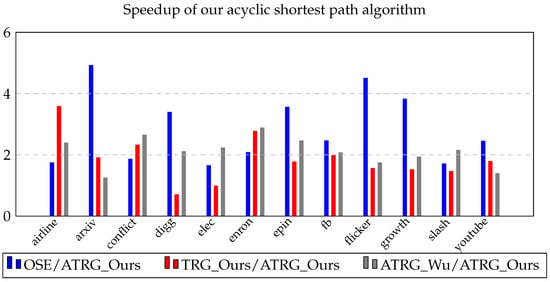
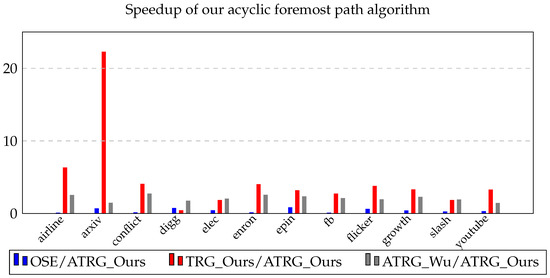
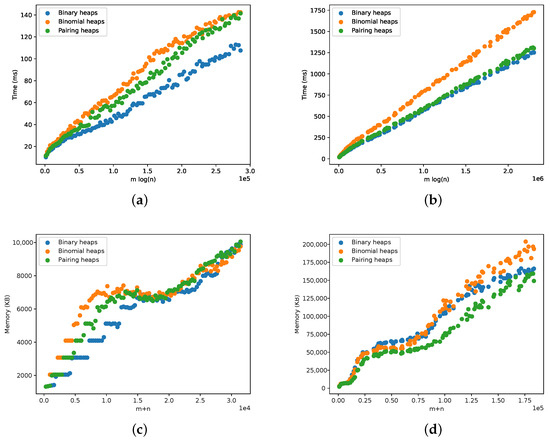
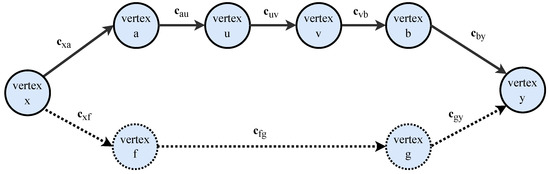
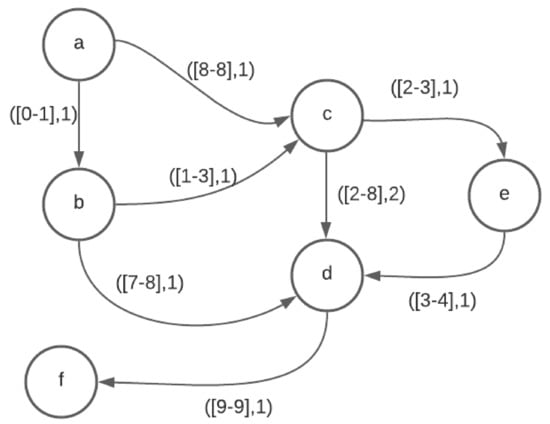
Path Algorithms for Contact Sequence Temporal Graphs
by
Sanaz Gheibi, Tania Banerjee, Sanjay Ranka and Sartaj Sahni
Viewed by 584
Abstract
This paper proposes a new time-respecting graph (TRG) representation for contact sequence temporal graphs. Our representation is more memory-efficient than previously proposed representations and has run-time advantages over the ordered sequence of edges (OSE) representation, which is faster than other known representations. While
[...] Read more.
This paper proposes a new time-respecting graph (TRG) representation for contact sequence temporal graphs. Our representation is more memory-efficient than previously proposed representations and has run-time advantages over the ordered sequence of edges (OSE) representation, which is faster than other known representations. While our proposed representation clearly outperforms the OSE representation for shallow neighborhood search problems, it is not evident that it does so for different problems. We demonstrate the competitiveness of our TRG representation for the single-source all-destinations fastest, min-hop, shortest, and foremost paths problems.
Full article
►▼
Show Figures
Open AccessArticle
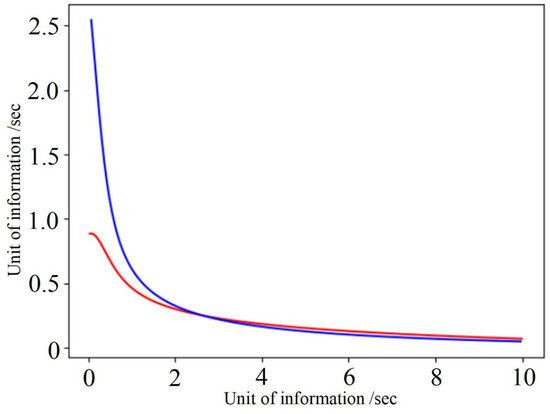
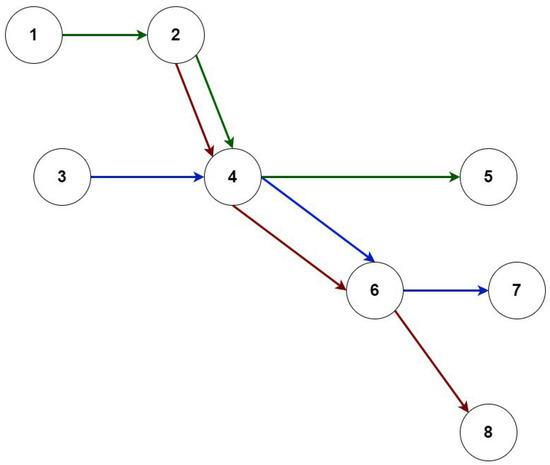
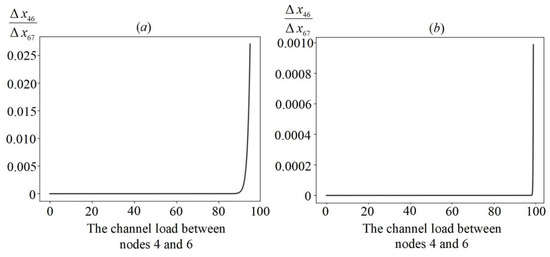
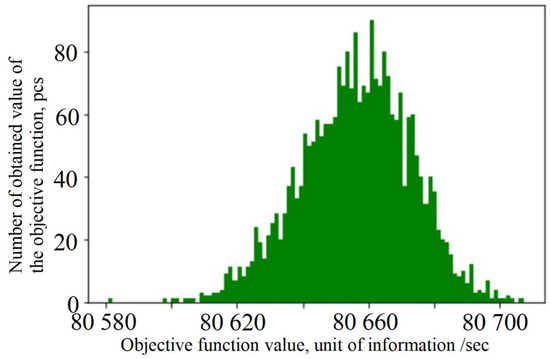
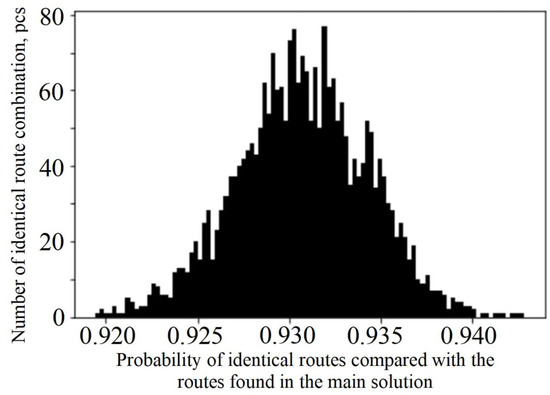
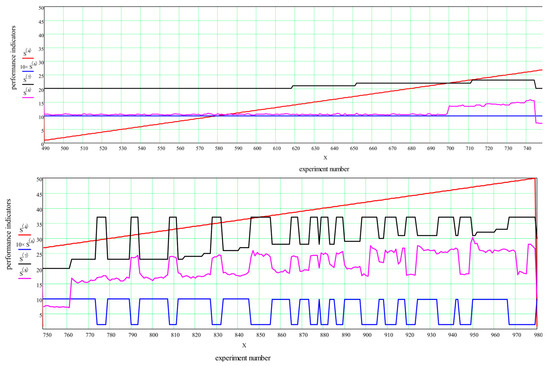
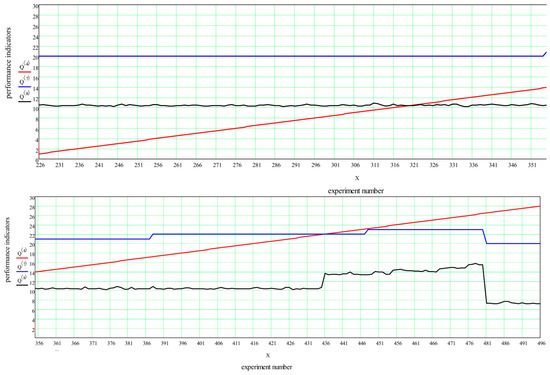
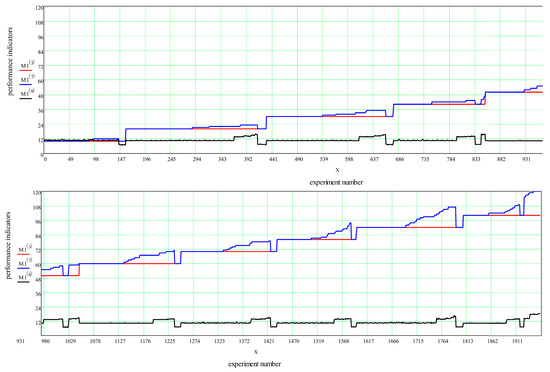
Heuristic Greedy-Gradient Route Search Method for Finding an Optimal Traffic Distribution in Telecommunication Networks
by
Konstantin Gaipov, Daniil Tausnev, Sergey Khodenkov, Natalya Shepeta, Dmitry Malyshev, Aleksey Popov and Lev Kazakovtsev
Viewed by 1261
Abstract
Rapid growth in the volume of transmitted information has lead to the emergence of new wireless networking technologies with variable heterogeneous topologies. With limited radio frequency resources, optimal routing problems arise, both at the network design stage and during its operation. We propose
[...] Read more.
Rapid growth in the volume of transmitted information has lead to the emergence of new wireless networking technologies with variable heterogeneous topologies. With limited radio frequency resources, optimal routing problems arise, both at the network design stage and during its operation. We propose an algorithm based on a minimum loss intensity (greedy-gradient algorithm) to search for optimal routes of information transmission in telecommunication networks. The relevance of the developed algorithm is determined by its practical use in data-transmitting modeling systems. The proposed algorithm satisfies several requirements, such as the speed of the calculations performed, the fulfillment of the conditions for its convergence, and its independence on the selected loss probability function, as well as on the network topology. The idea of the algorithm is a step-by-step recalculation of metrics based on derivatives of the loss intensity function with simultaneous redistribution of information flows along the routes determined by the Floyd algorithm. The comparative efficiency of the proposed algorithm is demonstrated by computational experiments on various network topologies (up to 100 nodes) with various traffic intensities.
Full article
►▼
Show Figures
Open AccessArticle
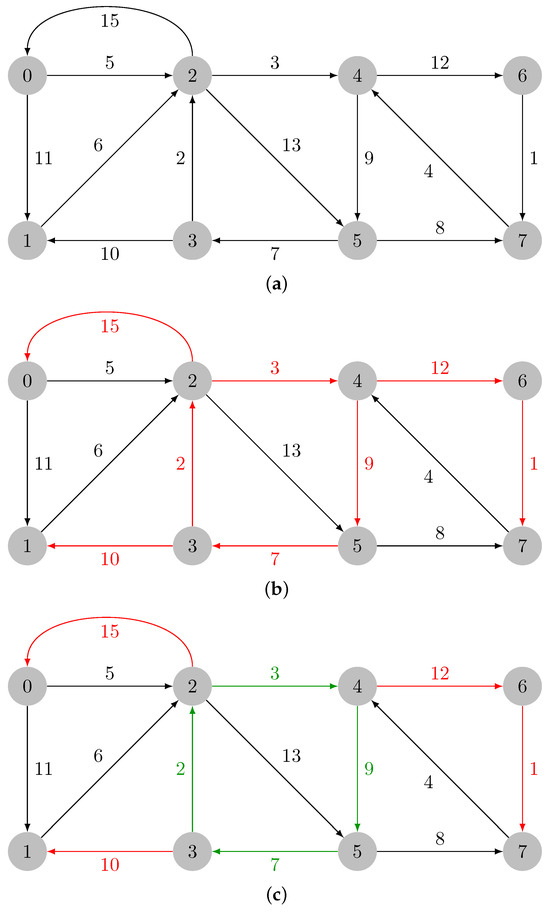
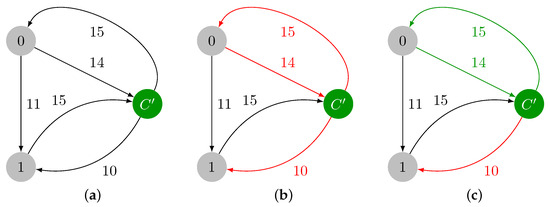
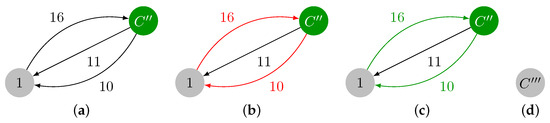
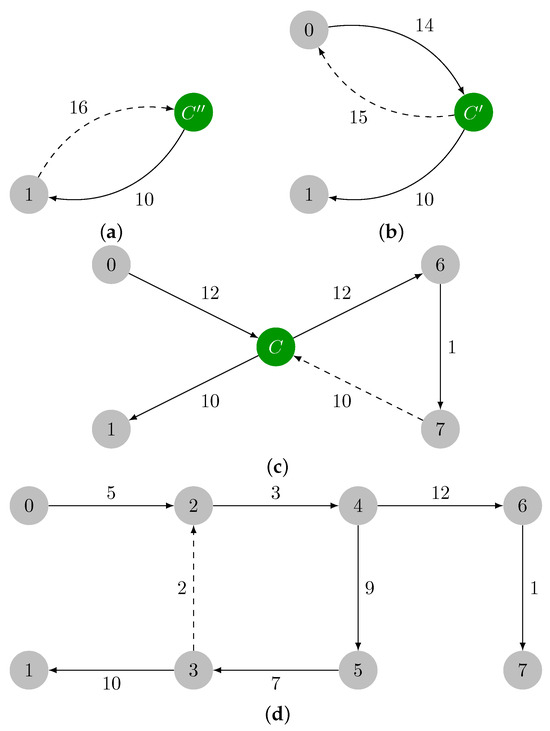
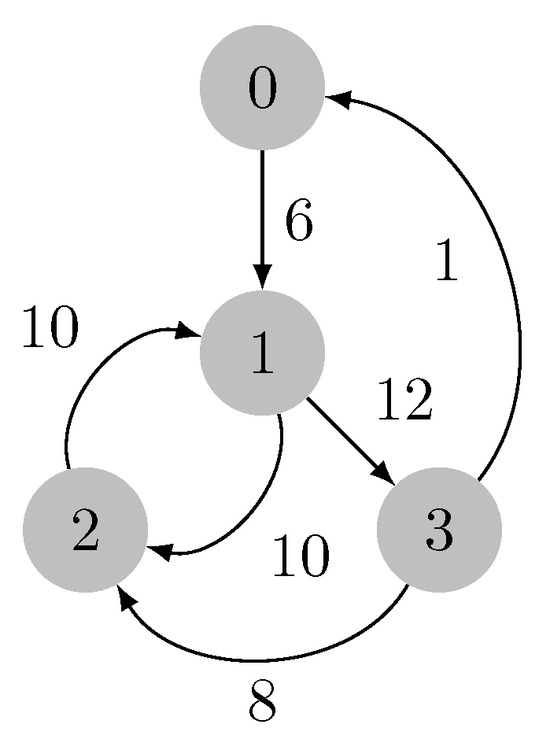
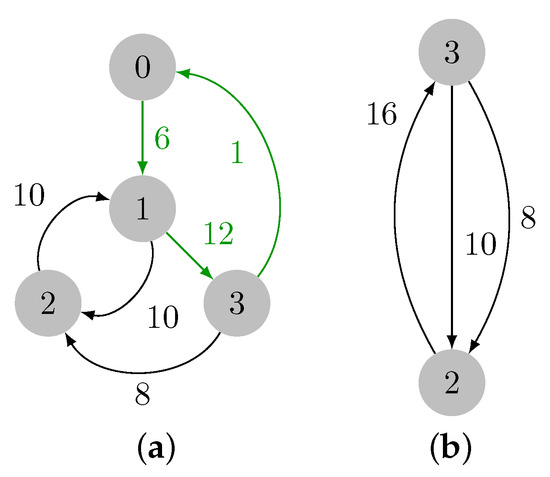
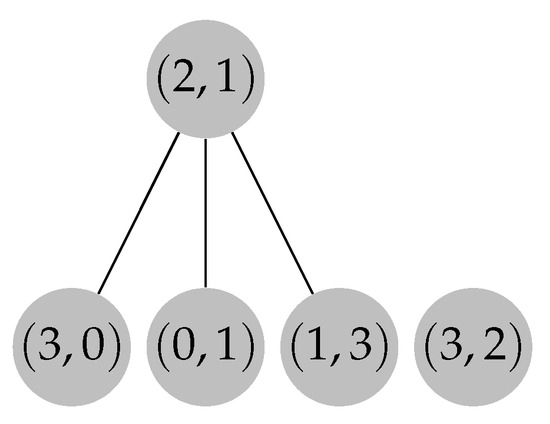
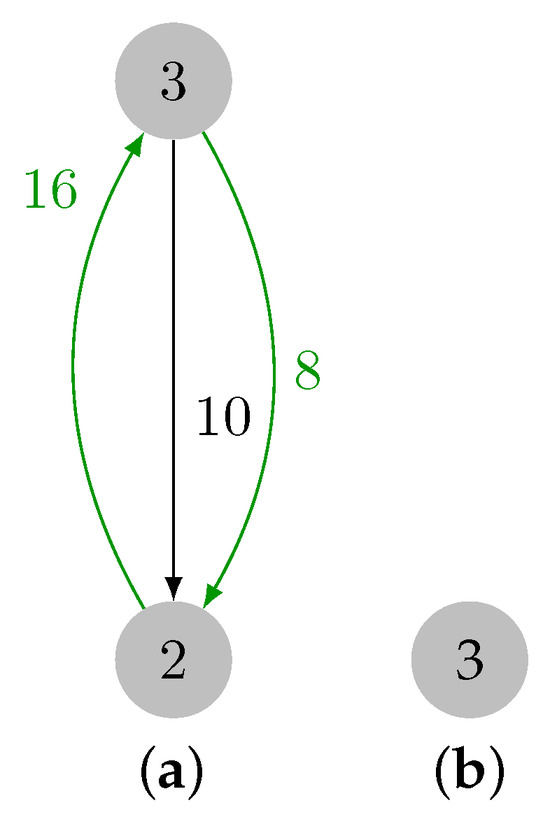
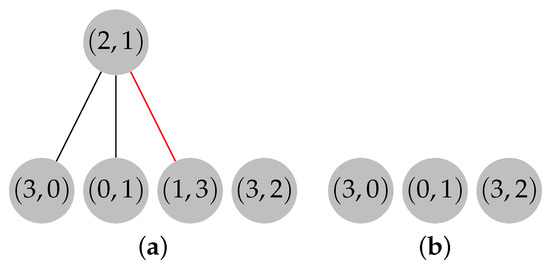
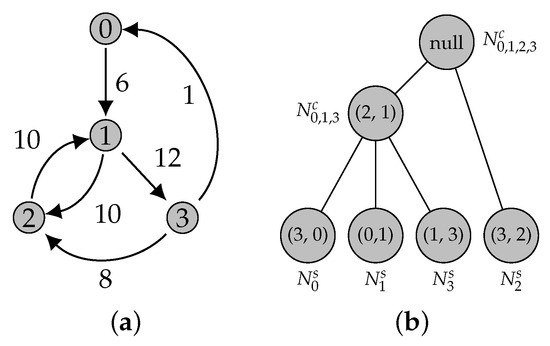
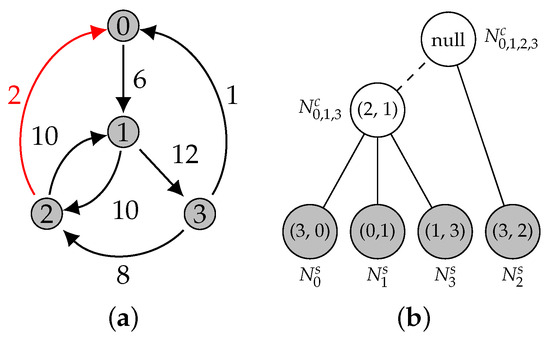
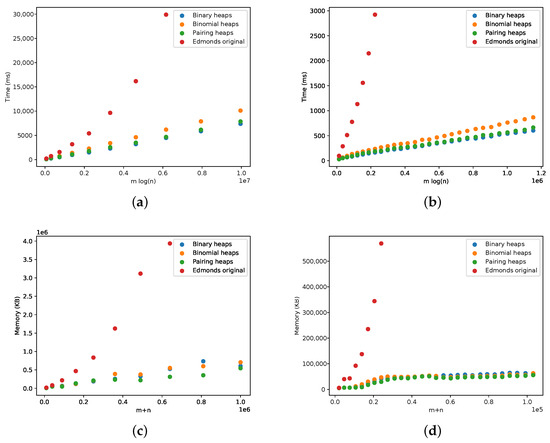
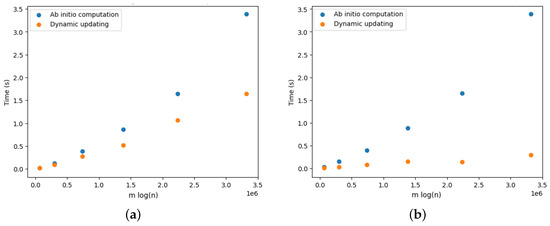
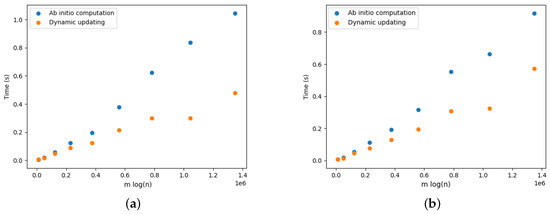
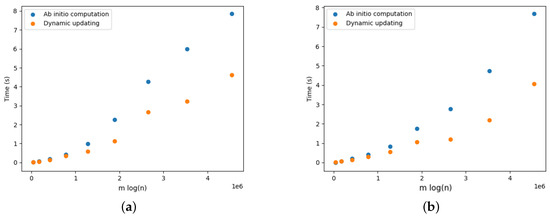
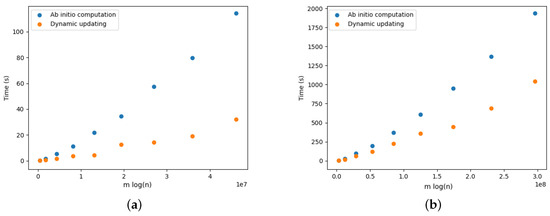
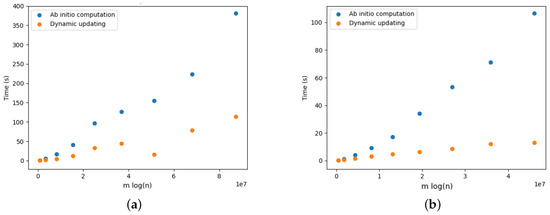
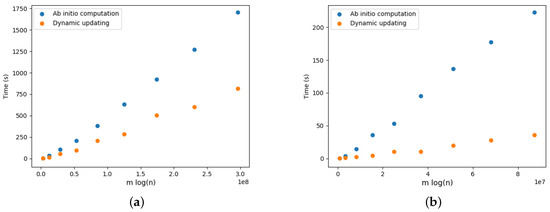
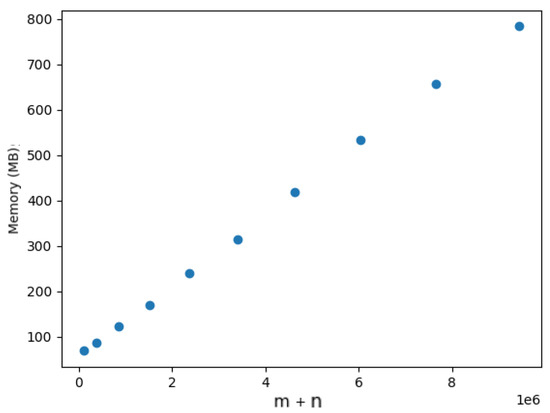
On Finding Optimal (Dynamic) Arborescences
by
Joaquim Espada, Alexandre P. Francisco, Tatiana Rocher, Luís M. S. Russo and Cátia Vaz
Viewed by 1467
Abstract
Let
be a directed and weighted graph with a vertex set
V of size
n and an edge set
E of size
m such that each edge
has a
[...] Read more.
Let
be a directed and weighted graph with a vertex set
V of size
n and an edge set
E of size
m such that each edge
has a real-valued weight
. An arborescence in
G is a subgraph
such that, for a vertex
, which is the root, there is a unique path in
T from
u to any other vertex
. The weight of
T is the sum of the weights of its edges. In this paper, given
G, we are interested in finding an arborescence in
G with a minimum weight, i.e., an optimal arborescence. Furthermore, when
G is subject to changes, namely, edge insertions and deletions, we are interested in efficiently maintaining a dynamic arborescence in
G. This is a well-known problem with applications in several domains such as network design optimization and phylogenetic inference. In this paper, we revisit the algorithmic ideas proposed by several authors for this problem. We provide detailed pseudocode, as well as implementation details, and we present experimental results regarding large scale-free networks and phylogenetic inference. Our implementation is publicly available.
Full article
►▼
Show Figures
Open AccessArticle
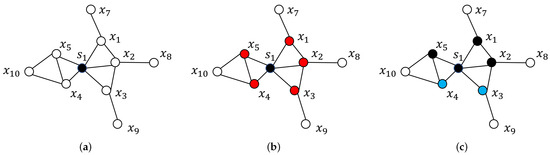
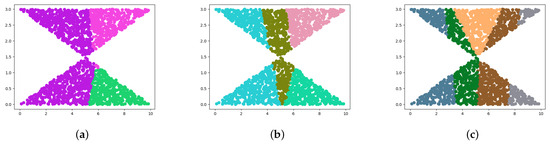
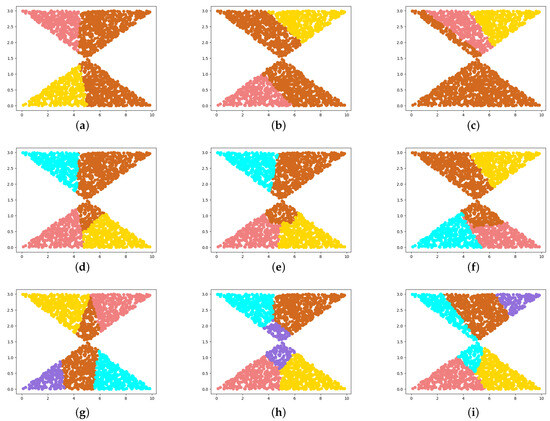
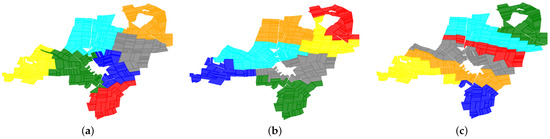
Shelved–Retrieved Method for Weakly Balanced Constrained Clustering Problems
by
Xinxiang Hou, Andong Qiu, Lu Yang and Zhouwang Yang
Viewed by 1502
Abstract
Clustering problems are prevalent in areas such as transport and partitioning. Owing to the demand for centralized storage and limited resources, a complex variant of this problem has emerged, also referred to as the weakly balanced constrained clustering (WBCC) problem. Clusters must satisfy
[...] Read more.
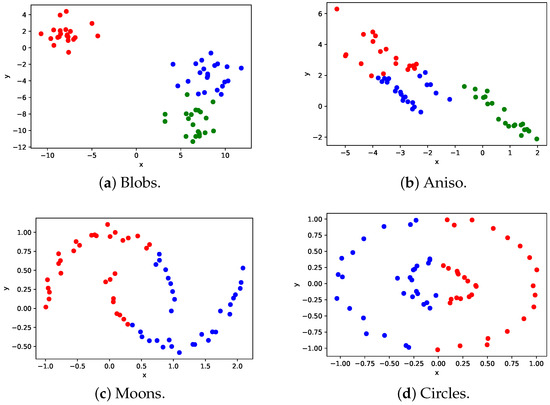
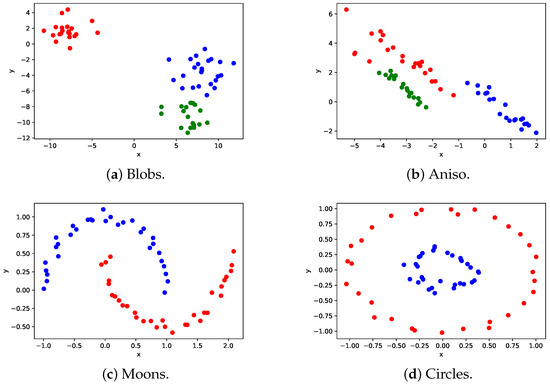
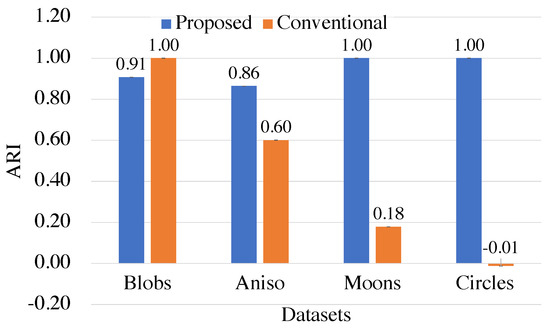
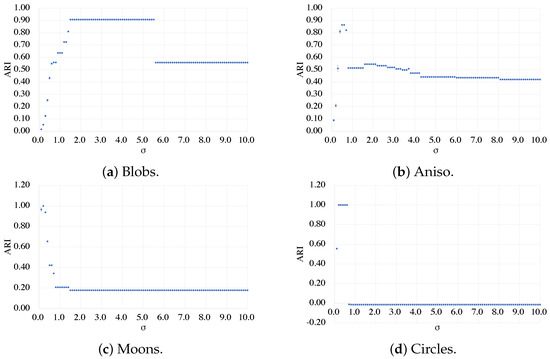
Clustering problems are prevalent in areas such as transport and partitioning. Owing to the demand for centralized storage and limited resources, a complex variant of this problem has emerged, also referred to as the weakly balanced constrained clustering (WBCC) problem. Clusters must satisfy constraints regarding cluster weights and connectivity. However, existing methods fail to guarantee cluster connectivity in diverse scenarios, thereby resulting in additional transportation costs. In response to the aforementioned limitations, this study introduces a shelved–retrieved method. This method embeds adjacent relationships during power diagram construction to ensure cluster connectivity. Using the shelved–retrieved method, connected clusters are generated and iteratively adjusted to determine the optimal solutions. Further, experiments are conducted on three synthetic datasets, each with three objective functions, and the results are compared to those obtained using other techniques. Our method successfully generates clusters that satisfy the constraints imposed by the WBCC problem and consistently outperforms other techniques in terms of the evaluation measures.
Full article
►▼
Show Figures
Open AccessArticle
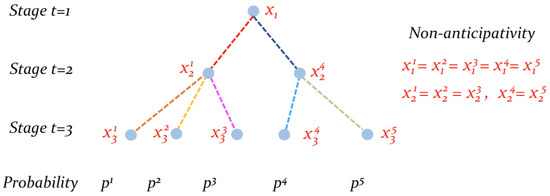
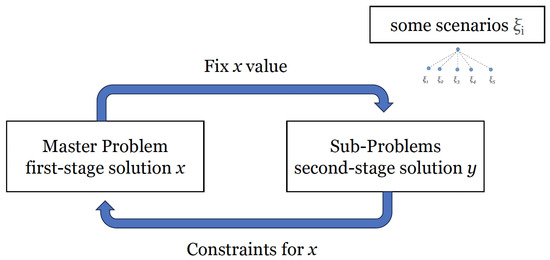
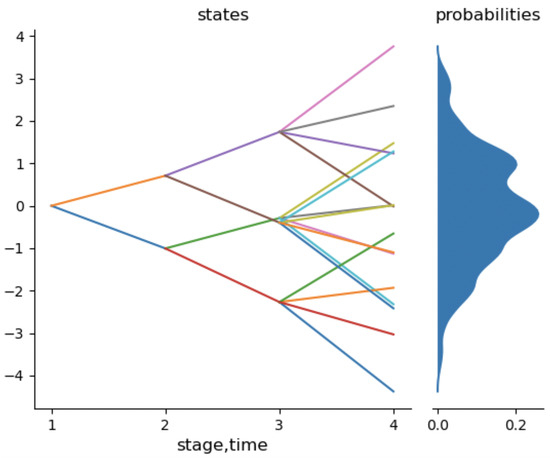
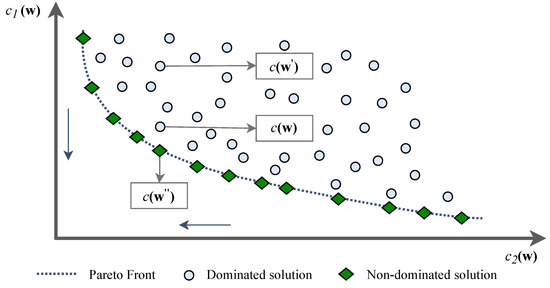
Problem-Driven Scenario Generation for Stochastic Programming Problems: A Survey
by
Xiaochen Chou and Enza Messina
Viewed by 1655
Abstract
Stochastic Programming is a powerful framework that addresses decision-making under uncertainties, which is a frequent occurrence in real-world problems. To effectively solve Stochastic Programming problems, scenario generation is one of the common practices that organizes realizations of stochastic processes with finite discrete distributions,
[...] Read more.
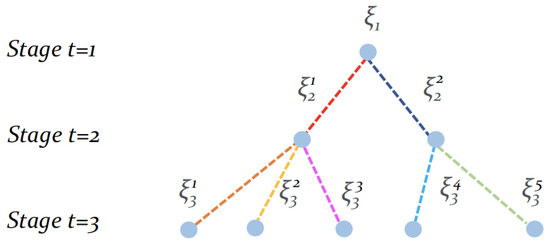
Stochastic Programming is a powerful framework that addresses decision-making under uncertainties, which is a frequent occurrence in real-world problems. To effectively solve Stochastic Programming problems, scenario generation is one of the common practices that organizes realizations of stochastic processes with finite discrete distributions, which enables the use of mathematical programming models of the original problem. The quality of solutions is significantly influenced by the scenarios employed, necessitating a delicate balance between incorporating informative scenarios and preventing overfitting. Distributions-based scenario generation methodologies have been extensively studied over time, while a relatively recent concept of problem-driven scenario generation has emerged, aiming to incorporate the underlying problem’s structure during the scenario generation process. This survey explores recent literature on problem-driven scenario generation algorithms and methodologies. The investigation aims to identify circumstances under which this approach is effective and efficient. The work provides a comprehensive categorization of existing literature, supplemented by illustrative examples. Additionally, the survey examines potential applications and discusses avenues for its integration with machine learning technologies. By shedding light on the effectiveness of problem-driven scenario generation and its potential for synergistic integration with machine learning, this survey contributes to enhanced decision-making strategies in the context of uncertainties.
Full article
►▼
Show Figures
Open AccessArticle
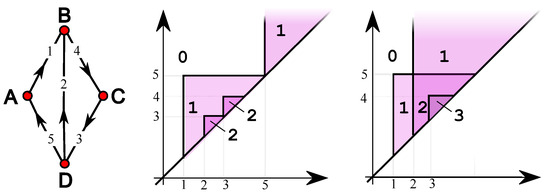
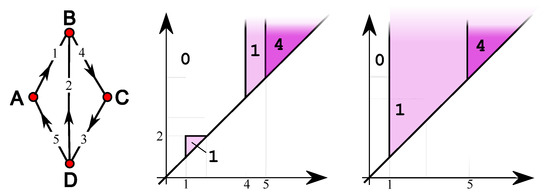
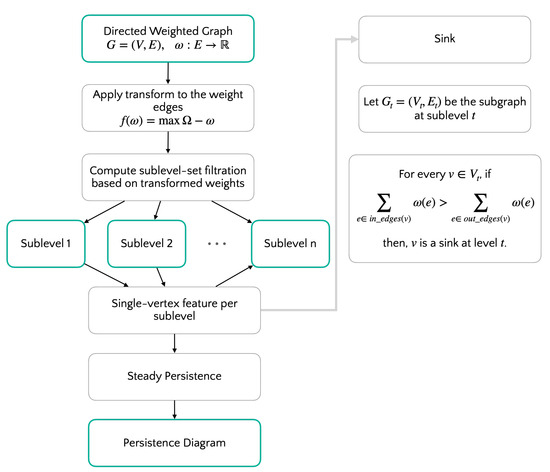
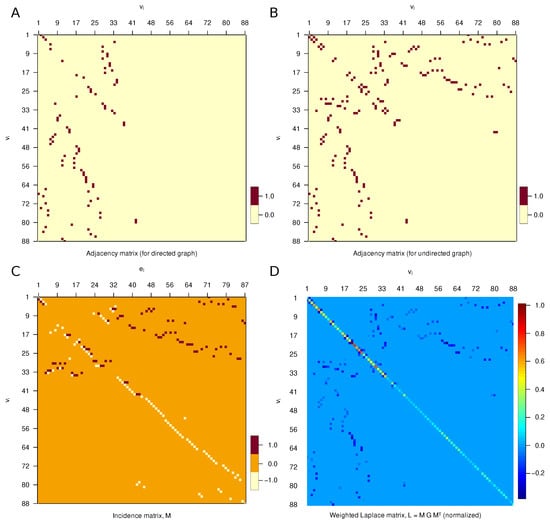
Exploring Graph and Digraph Persistence
by
Mattia G. Bergomi and Massimo Ferri
Viewed by 1132
Abstract
Among the various generalizations of persistent topology, that based on rank functions and leading to indexing-aware functions appears to be particularly suited to catching graph-theoretical properties without the need for a simplicial construction and a homology computation. This paper defines and studies “simple”
[...] Read more.
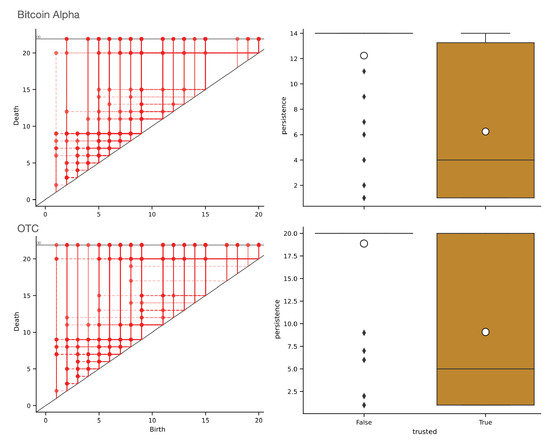
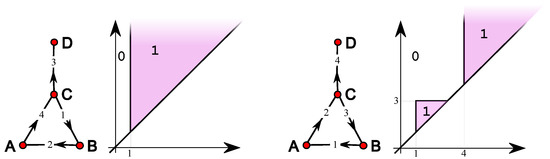
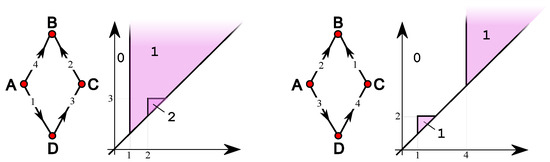
Among the various generalizations of persistent topology, that based on rank functions and leading to indexing-aware functions appears to be particularly suited to catching graph-theoretical properties without the need for a simplicial construction and a homology computation. This paper defines and studies “simple” and “single-vertex” features in directed and undirected graphs, through which several indexing-aware persistence functions are produced, within the scheme of steady and ranging sets. The implementation of the “sink” feature and its application to trust networks provide an example of the ease of use and meaningfulness of the method.
Full article
►▼
Show Figures
Open AccessArticle
A Surprisal-Based Greedy Heuristic for the Set Covering Problem
by
Tommaso Adamo, Gianpaolo Ghiani, Emanuela Guerriero and Deborah Pareo
Cited by 1 | Viewed by 994
Abstract
In this paper we exploit concepts from Information Theory to improve the classical Chvatal greedy algorithm for the set covering problem. In particular, we develop a new greedy procedure, called Surprisal-Based Greedy Heuristic (SBH), incorporating the computation of a “surprisal” measure when selecting
[...] Read more.
In this paper we exploit concepts from Information Theory to improve the classical Chvatal greedy algorithm for the set covering problem. In particular, we develop a new greedy procedure, called Surprisal-Based Greedy Heuristic (SBH), incorporating the computation of a “surprisal” measure when selecting the solution columns. Computational experiments, performed on instances from the OR-Library, showed that SBH yields a 2.5% improvement in terms of the objective function value over the Chvatal’s algorithm while retaining similar execution times, making it suitable for real-time applications. The new heuristic was also compared with Kordalewski’s greedy algorithm, obtaining similar solutions in much shorter times on large instances, and Grossmann and Wool’s algorithm for unicost instances, where SBH obtained better solutions.
Full article
Open AccessArticle
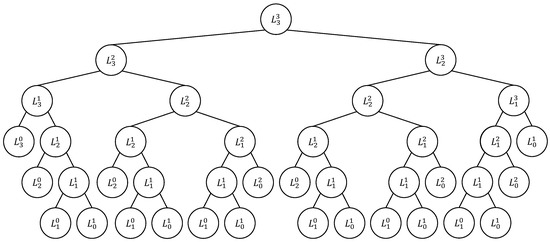
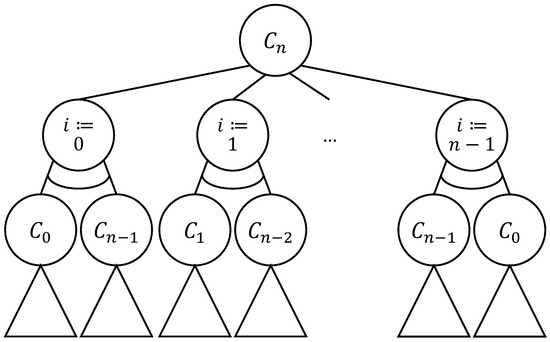
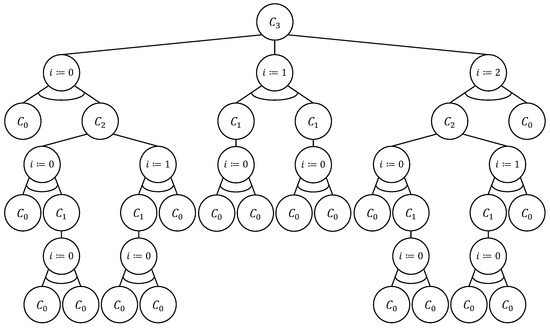
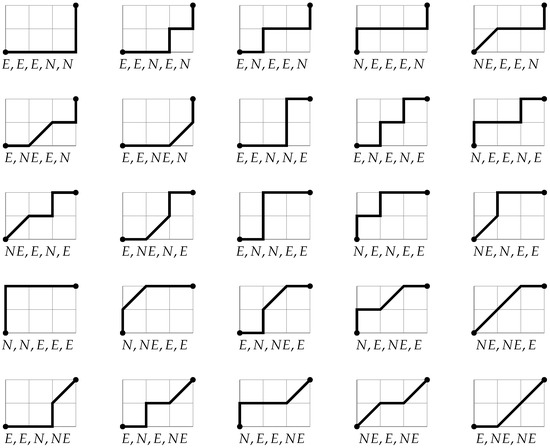
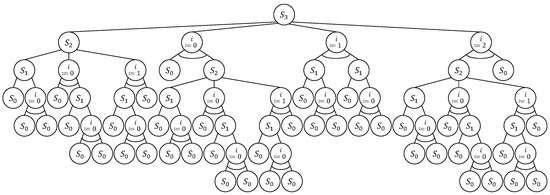
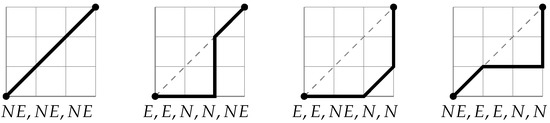
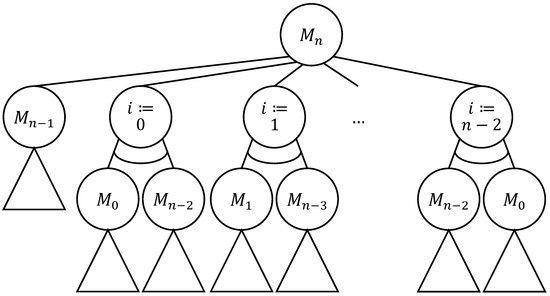
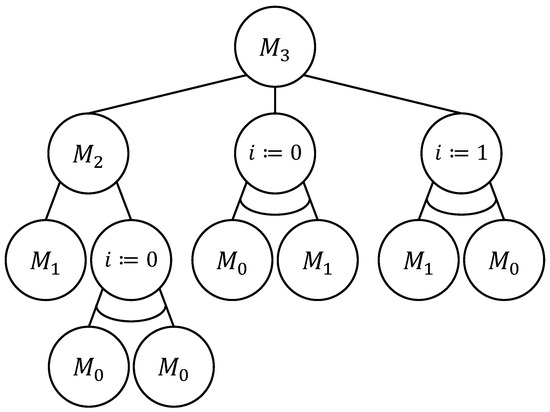
Combinatorial Generation Algorithms for Some Lattice Paths Using the Method Based on AND/OR Trees
by
Yuriy Shablya
Viewed by 1158
Abstract
Methods of combinatorial generation make it possible to develop algorithms for generating objects from a set of discrete structures with given parameters and properties. In this article, we demonstrate the possibilities of using the method based on AND/OR trees to obtain combinatorial generation
[...] Read more.
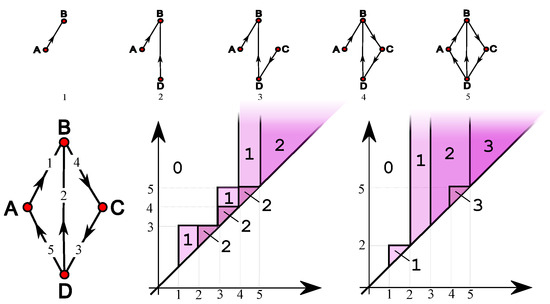
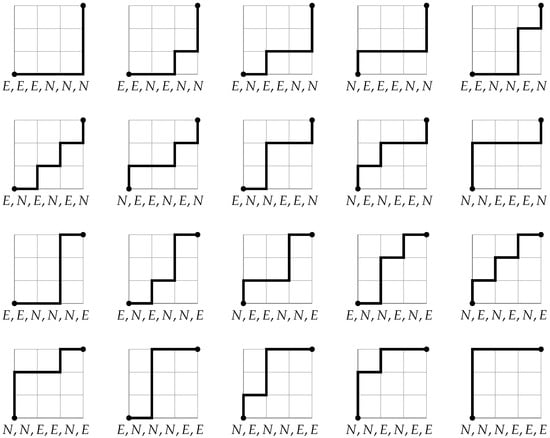
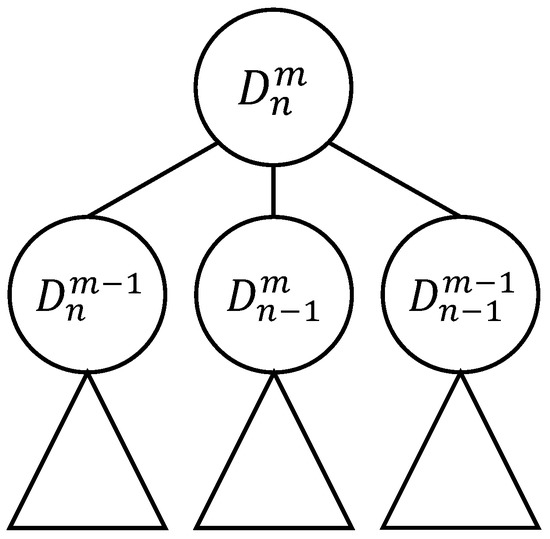
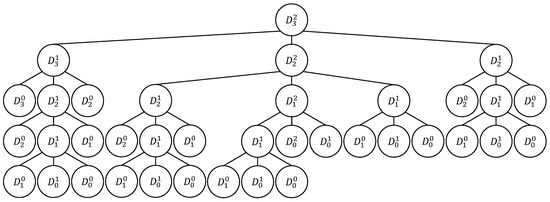
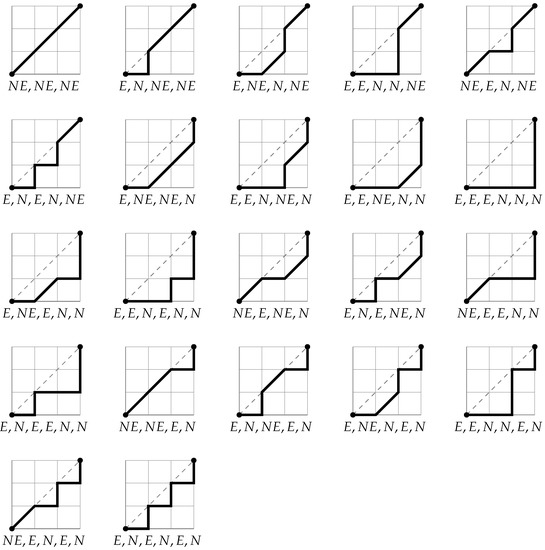
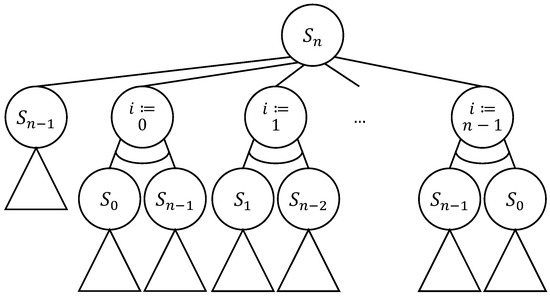
Methods of combinatorial generation make it possible to develop algorithms for generating objects from a set of discrete structures with given parameters and properties. In this article, we demonstrate the possibilities of using the method based on AND/OR trees to obtain combinatorial generation algorithms for combinatorial sets of several well-known lattice paths (North-East lattice paths, Dyck paths, Delannoy paths, Schroder paths, and Motzkin paths). For each considered combinatorial set of lattice paths, we construct the corresponding AND/OR tree structure where the number of its variants is equal to the number of objects in the combinatorial set. Applying the constructed AND/OR tree structures, we have developed new algorithms for ranking and unranking their variants. The performed computational experiments have confirmed the obtained theoretical estimation of asymptotic computational complexity for the developed ranking and unranking algorithms.
Full article
►▼
Show Figures
Open AccessArticle
Subgroup Discovery in Machine Learning Problems with Formal Concepts Analysis and Test Theory Algorithms
by
Igor Masich, Natalya Rezova, Guzel Shkaberina, Sergei Mironov, Mariya Bartosh and Lev Kazakovtsev
Viewed by 2264
Abstract
A number of real-world problems of automatic grouping of objects or clustering require a reasonable solution and the possibility of interpreting the result. More specific is the problem of identifying homogeneous subgroups of objects. The number of groups in such a dataset is
[...] Read more.
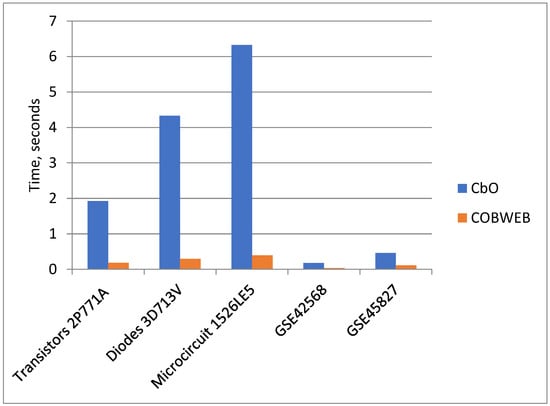
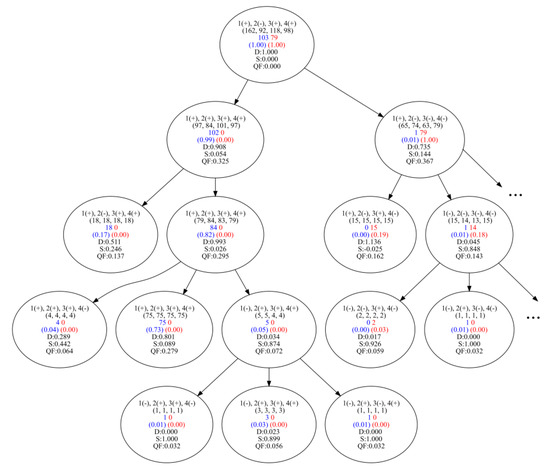
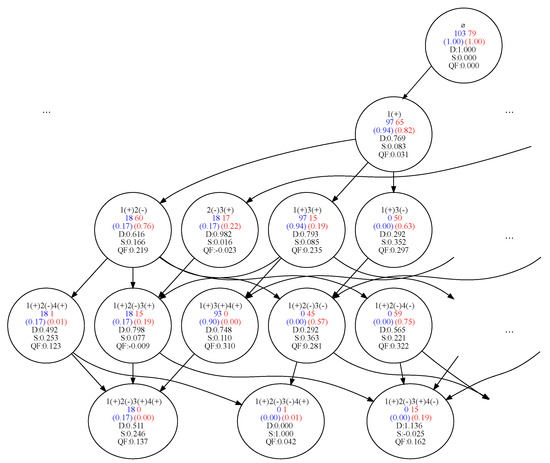
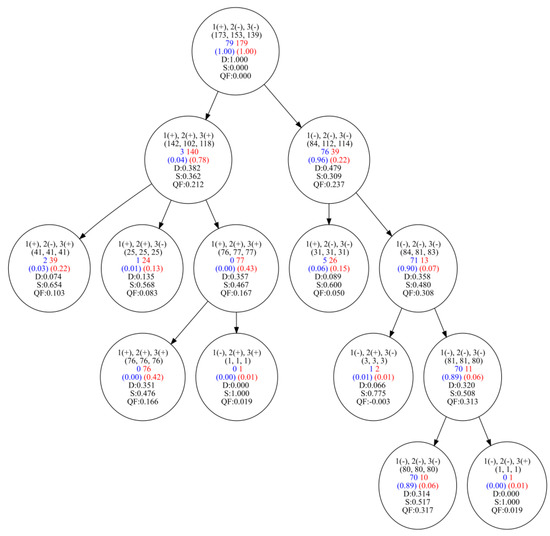
A number of real-world problems of automatic grouping of objects or clustering require a reasonable solution and the possibility of interpreting the result. More specific is the problem of identifying homogeneous subgroups of objects. The number of groups in such a dataset is not specified, and it is required to justify and describe the proposed grouping model. As a tool for interpretable machine learning, we consider formal concept analysis (FCA). To reduce the problem with real attributes to a problem that allows the use of FCA, we use the search for the optimal number and location of cut points and the optimization of the support set of attributes. The approach to identifying homogeneous subgroups was tested on tasks for which interpretability is important: the problem of clustering industrial products according to primary tests (for example, transistors, diodes, and microcircuits) as well as gene expression data (collected to solve the problem of predicting cancerous tumors). For the data under consideration, logical concepts are identified, formed in the form of a lattice of formal concepts. Revealed concepts are evaluated according to indicators of informativeness and can be considered as homogeneous subgroups of elements and their indicative descriptions. The proposed approach makes it possible to single out homogeneous subgroups of elements and provides a description of their characteristics, which can be considered as tougher norms that the elements of the subgroup satisfy. A comparison is made with the COBWEB algorithm designed for conceptual clustering of objects. This algorithm is aimed at discovering probabilistic concepts. The resulting lattices of logical concepts and probabilistic concepts for the considered datasets are simple and easy to interpret.
Full article
►▼
Show Figures
Open AccessArticle
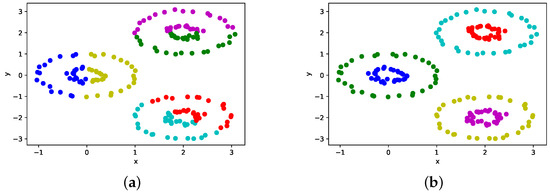
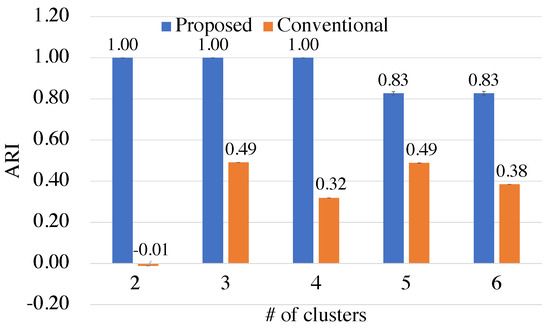
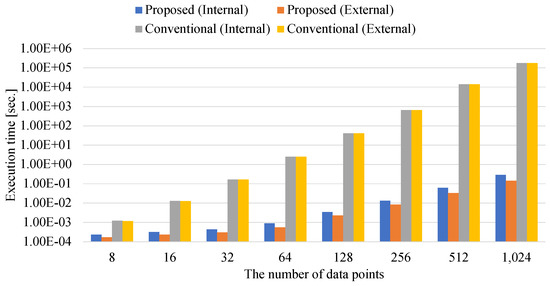
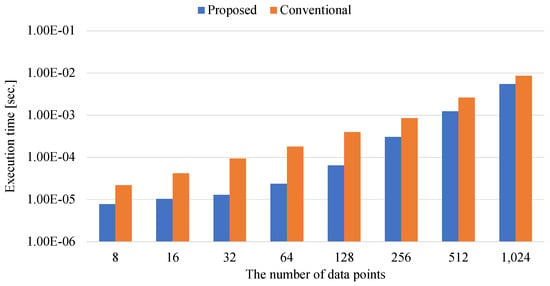
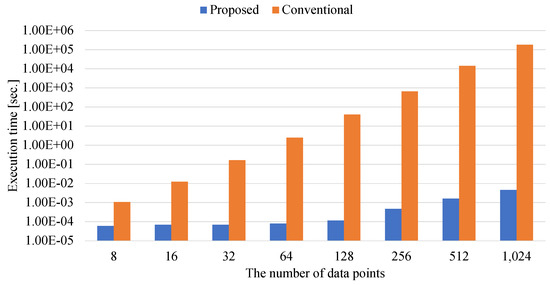
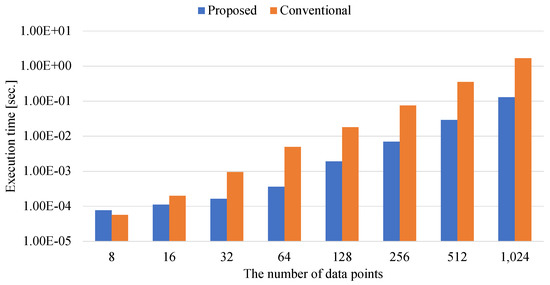
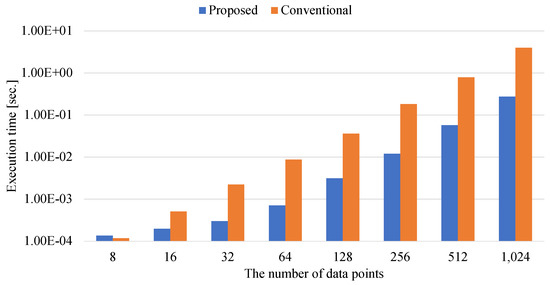
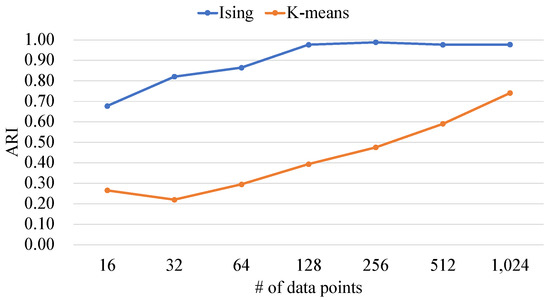
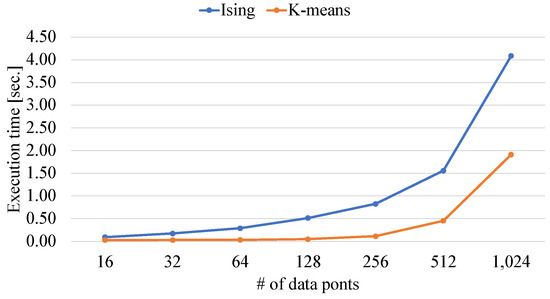
Ising-Based Kernel Clustering
by
Masahito Kumagai, Kazuhiko Komatsu, Masayuki Sato and Hiroaki Kobayashi
Cited by 2 | Viewed by 1376
Abstract
Combinatorial clustering based on the Ising model is drawing attention as a high-quality clustering method. However, conventional Ising-based clustering methods using the Euclidean distance cannot handle irregular data. To overcome this problem, this paper proposes an Ising-based kernel clustering method. The kernel clustering method is
[...] Read more.
Combinatorial clustering based on the Ising model is drawing attention as a high-quality clustering method. However, conventional Ising-based clustering methods using the Euclidean distance cannot handle irregular data. To overcome this problem, this paper proposes an Ising-based kernel clustering method. The kernel clustering method is designed based on two critical ideas. One is to perform clustering of irregular data by mapping the data onto a high-dimensional feature space by using a kernel trick. The other is the utilization of matrix–matrix calculations in the numerical libraries to accelerate preprocess for annealing. While the conventional Ising-based clustering is not designed to accept the transformed data by the kernel trick, this paper extends the availability of Ising-based clustering to process a distance matrix defined in high-dimensional data space. The proposed method can handle the Gram matrix determined by the kernel method as a high-dimensional distance matrix to handle irregular data. By comparing the proposed Ising-based kernel clustering method with the conventional Euclidean distance-based combinatorial clustering, it is clarified that the quality of the clustering results of the proposed method for irregular data is significantly better than that of the conventional method. Furthermore, the preprocess for annealing by the proposed method using numerical libraries is by a factor of up to
million × from the conventional naive python’s implementation. Comparisons between Ising-based kernel clustering and kernel K-means reveal that the proposed method has the potential to obtain higher-quality clustering results than the kernel K-means as a representative of the state-of-the-art kernel clustering methods.
Full article
►▼
Show Figures
Open AccessArticle
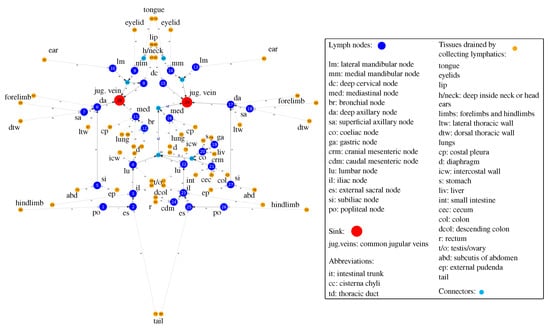
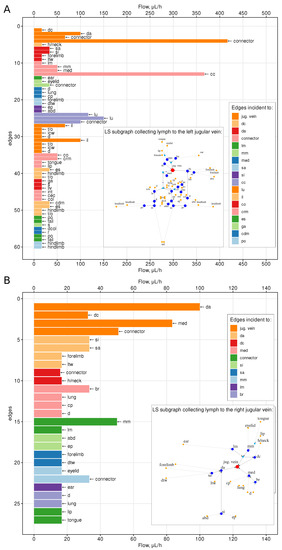
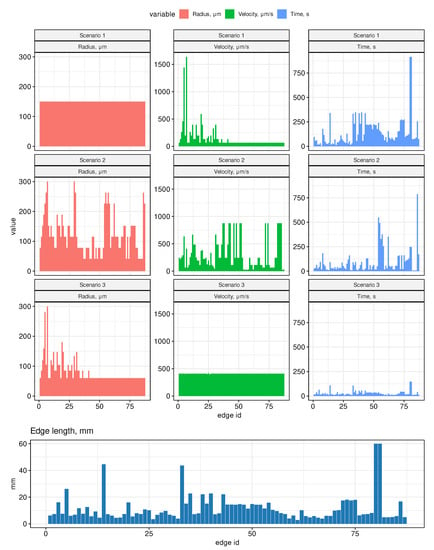
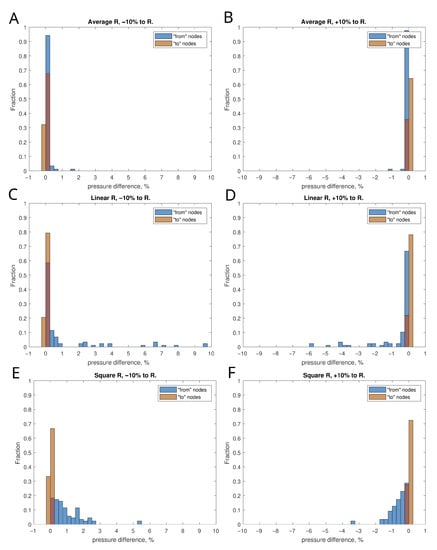
Network Modeling of Murine Lymphatic System
by
Dmitry Grebennikov, Rostislav Savinkov, Ekaterina Zelenova, Gennady Lobov and Gennady Bocharov
Viewed by 1343
Abstract
Animal models of diseases, particularly mice, are considered to be the cornerstone for translational research in immunology. The aim of the present study is to model the geometry and analyze the network structure of the murine lymphatic system (LS). The algorithm for building
[...] Read more.
Animal models of diseases, particularly mice, are considered to be the cornerstone for translational research in immunology. The aim of the present study is to model the geometry and analyze the network structure of the murine lymphatic system (LS). The algorithm for building the graph model of the LS makes use of anatomical data. To identify the edge directions of the graph model, a mass balance approach to lymph dynamics based on the Hagen–Poiseuille equation is applied. It is the first study in which a geometric model of the murine LS has been developed and characterized in terms of its structural organization and the lymph transfer function. Our study meets the demand for quantitative mechanistic approaches in the growing field of immunoengineering to utilize or exploit the lymphatic system for immunotherapy.
Full article
►▼
Show Figures
Open AccessArticle
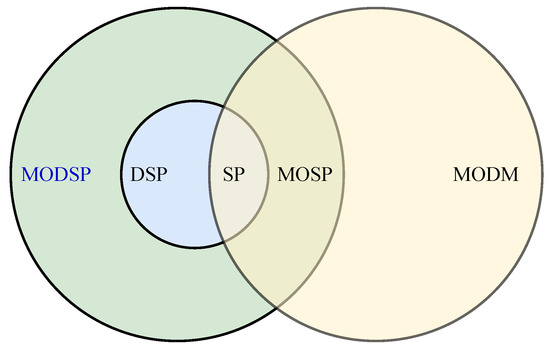
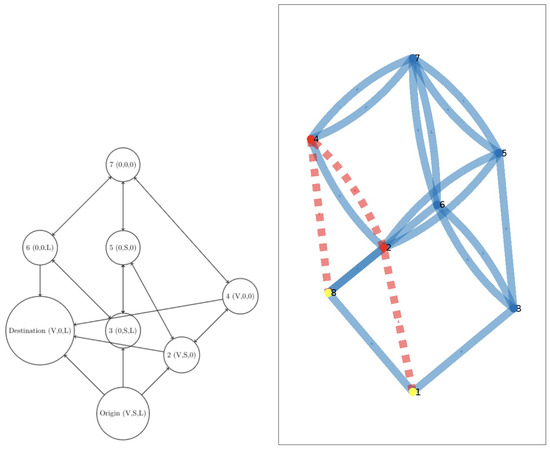
Multi-Objective Decision-Making Meets Dynamic Shortest Path: Challenges and Prospects
by
Juarez Machado da Silva, Gabriel de Oliveira Ramos and Jorge Luis Victória Barbosa
Cited by 1 | Viewed by 1778
Abstract
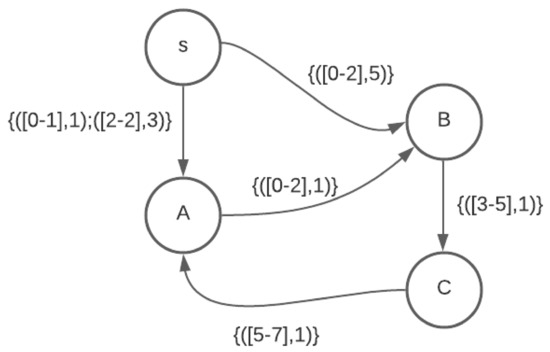
The Shortest Path (SP) problem resembles a variety of real-world situations where one needs to find paths between origins and destinations. A generalization of the SP is the Dynamic Shortest Path (DSP) problem, which also models changes in the graph at any time.
[...] Read more.
The Shortest Path (SP) problem resembles a variety of real-world situations where one needs to find paths between origins and destinations. A generalization of the SP is the Dynamic Shortest Path (DSP) problem, which also models changes in the graph at any time. When a graph changes, DSP algorithms partially recompute the paths while taking advantage of the previous computations. Although the DSP problem represents many real situations, it leaves out some fundamental aspects of decision-making. One of these aspects is the existence of multiple, potentially conflicting objectives that must be optimized simultaneously. Recently, we performed a first incursion on the so-called Multi-Objective Dynamic Shortest Path (MODSP), presenting the first algorithm able to take the MODM perspective into account when solving a DSP problem. In this paper, we go beyond and formally define the MODSP problem, thus establishing and clarifying it with respect to its simpler counterparts. In particular, we start with a brief overview of the related literature and then present a complete formalization of the MODSP problem class, highlighting its distinguishing features as compared to similar problems and representing their relationship through a novel taxonomy. This work also motivates the relevance of the MODSP problem by enumerating real-world scenarios that involve all its ingredients, such as multiple objectives and dynamically updated graph topologies. Finally, we discuss the challenges and open questions for this new class of shortest path problems, aiming at future work directions. We hope this work sheds light on the theme and contributes to leveraging relevant research on the topic.
Full article
►▼
Show Figures
Open AccessArticle
A Dynamic Programming Approach to Ecosystem Management
by
Alessandra Rosso and Ezio Venturino
Cited by 1 | Viewed by 1211
Abstract
We propose a way of dealing with invasive species or pest control in agriculture. Ecosystems can be modeled via dynamical systems. For their study, it is necessary to establish their possible equilibria. Even a moderately complex system exhibits, in general, multiple steady states.
[...] Read more.
We propose a way of dealing with invasive species or pest control in agriculture. Ecosystems can be modeled via dynamical systems. For their study, it is necessary to establish their possible equilibria. Even a moderately complex system exhibits, in general, multiple steady states. Usually, they are related to each other through transcritical bifurcations, i.e., the system settles to a different equilibrium when some bifurcation parameter crosses a critical threshold. From a situation in which the pest is endemic, it is desirable to move to a pest-free point. The map of the system’s equilibria and their connections via transcritical bifurcations may indicate a path to attain the desired state. However, to force the parameters to cross the critical threshold, some human action is required, and this effort has a cost. The tools of dynamic programming allow the detection of the cheapest path to reach the desired goal. In this paper, an algorithm for the solution to this problem is illustrated.
Full article
►▼
Show Figures
Open AccessArticle
Union Models for Model Families: Efficient Reasoning over Space and Time
by
Sanaa Alwidian, Daniel Amyot and Yngve Lamo
Cited by 1 | Viewed by 1501
Abstract
A model family is a set of related models in a given language, with commonalities and variabilities that result from evolution of models over time and/or variation over intended usage (the spatial dimension). As the family size increases, it becomes cumbersome to analyze
[...] Read more.
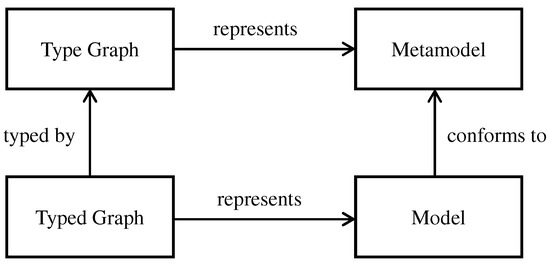
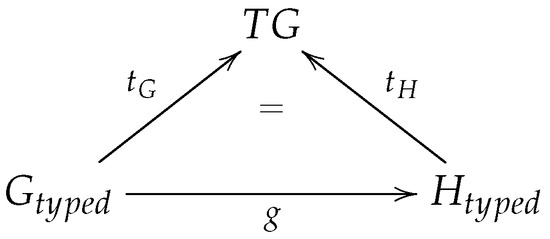
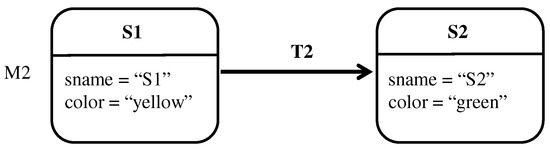
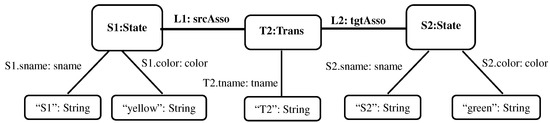
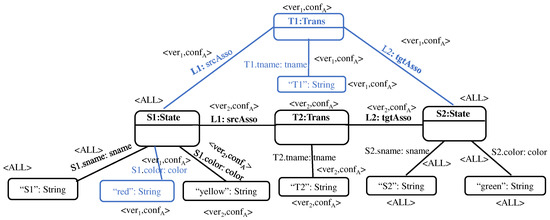
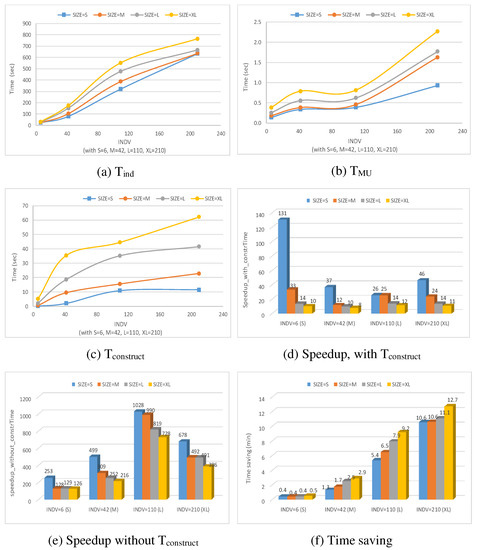
A model family is a set of related models in a given language, with commonalities and variabilities that result from evolution of models over time and/or variation over intended usage (the spatial dimension). As the family size increases, it becomes cumbersome to analyze models individually. One solution is to represent a family using one global model that supports analysis. In this paper, we propose the concept of union model as a complete and concise representation of all members of a model family. We use graph theory to formalize a model family as a set of attributed typed graphs in which all models are typed over the same metamodel. The union model is formalized as the union of all graph elements in the family. These graph elements are annotated with their corresponding model versions and configurations. This formalization is independent from the modeling language used. We also demonstrate how union models can be used to perform reasoning tasks on model families, e.g., trend analysis and property checking. Empirical results suggest potential time-saving benefits when using union models for analysis and reasoning over a set of models all at once as opposed to separately analyzing single models one at a time.
Full article
►▼
Show Figures
Open AccessArticle
Solving the Parallel Drone Scheduling Traveling Salesman Problem via Constraint Programming
by
Roberto Montemanni and Mauro Dell’Amico
Cited by 8 | Viewed by 2102
Abstract
Drones are currently seen as a viable way of improving the distribution of parcels in urban and rural environments, while working in coordination with traditional vehicles, such as trucks. In this paper, we consider the parallel drone scheduling traveling salesman problem, where a
[...] Read more.
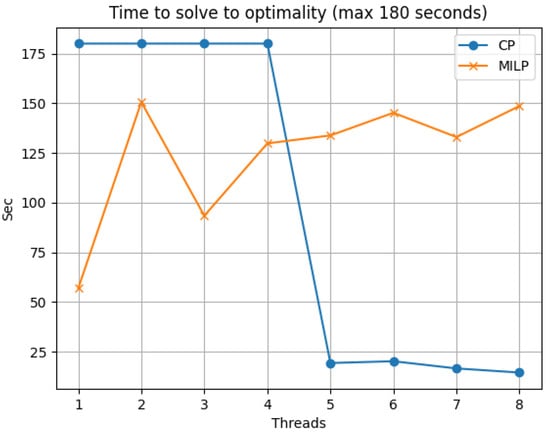
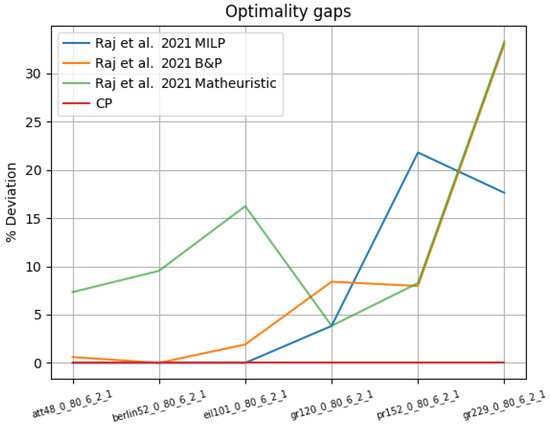
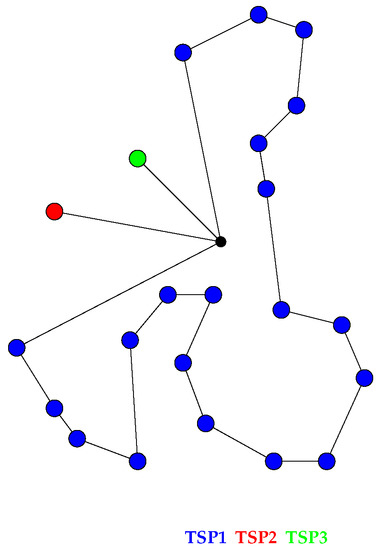
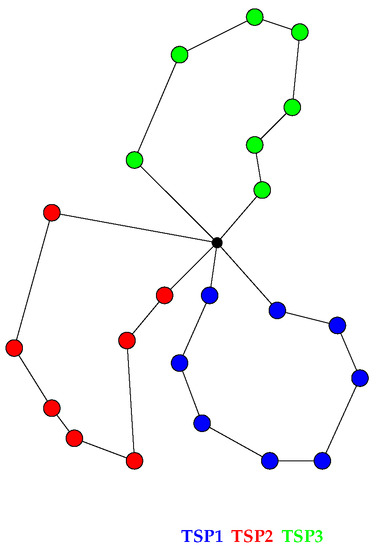
Drones are currently seen as a viable way of improving the distribution of parcels in urban and rural environments, while working in coordination with traditional vehicles, such as trucks. In this paper, we consider the parallel drone scheduling traveling salesman problem, where a set of customers requiring a delivery is split between a truck and a fleet of drones, with the aim of minimizing the total time required to serve all the customers. We propose a constraint programming model for the problem, discuss its implementation and present the results of an experimental program on the instances previously cited in the literature to validate exact and heuristic algorithms. We were able to decrease the cost (the time required to serve customers) for some of the instances and, for the first time, to provide a demonstrated optimal solution for all the instances considered. These results show that constraint programming can be a very effective tool for attacking optimization problems with traveling salesman components, such as the one discussed.
Full article
►▼
Show Figures
Open AccessArticle
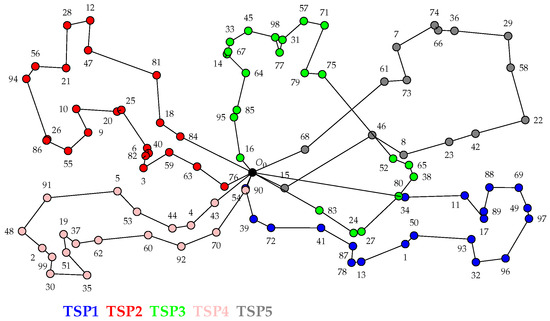
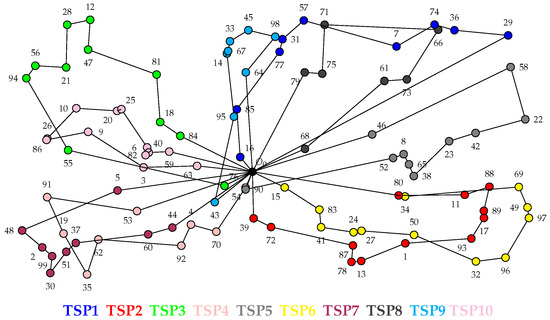
Ant-Balanced Multiple Traveling Salesmen: ACO-BmTSP
by
Sílvia de Castro Pereira, Eduardo J. Solteiro Pires and Paulo B. de Moura Oliveira
Cited by 1 | Viewed by 1922
Abstract
A new algorithm based on the ant colony optimization (ACO) method for the multiple traveling salesman problem (mTSP) is presented and defined as ACO-BmTSP. This paper addresses the problem of solving the mTSP while considering several salesmen and keeping both the total travel
[...] Read more.
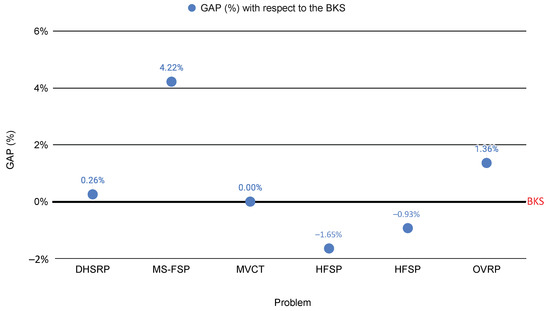
A new algorithm based on the ant colony optimization (ACO) method for the multiple traveling salesman problem (mTSP) is presented and defined as ACO-BmTSP. This paper addresses the problem of solving the mTSP while considering several salesmen and keeping both the total travel cost at the minimum and the tours balanced. Eleven different problems with several variants were analyzed to validate the method. The 20 variants considered three to twenty salesmen regarding 11 to 783 cities. The results were compared with best-known solutions (BKSs) in the literature. Computational experiments showed that a total of eight final results were better than those of the BKSs, and the others were quite promising, showing that with few adaptations, it will be possible to obtain better results than those of the BKSs. Although the ACO metaheuristic does not guarantee that the best solution will be found, it is essential in problems with non-deterministic polynomial time complexity resolution or when used as an initial bound solution in an integer programming formulation. Computational experiments on a wide range of benchmark problems within an acceptable time limit showed that compared with four existing algorithms, the proposed algorithm presented better results for several problems than the other algorithms did.
Full article
►▼
Show Figures
Open AccessArticle
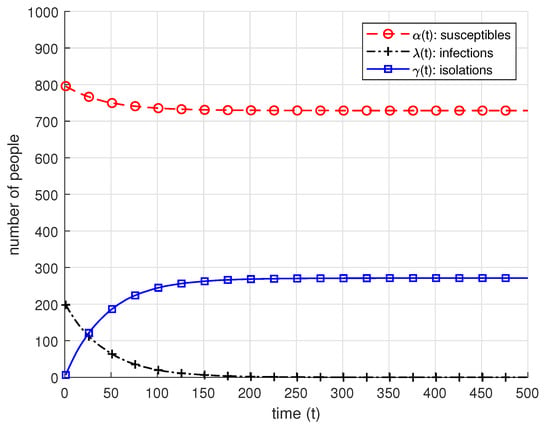
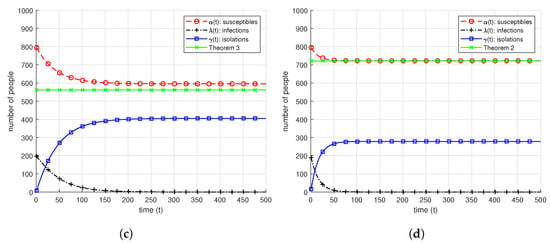
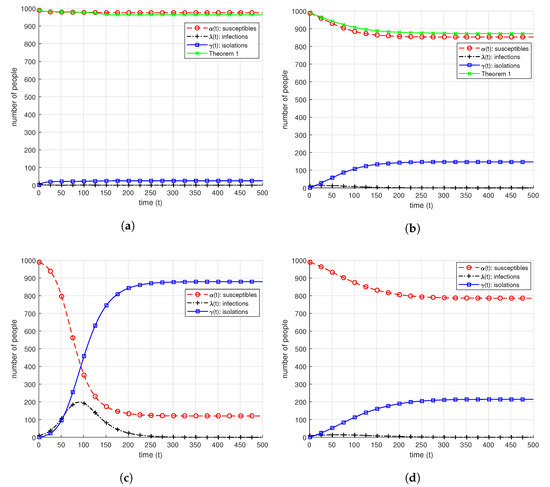
Dynamic Infection Spread Model Based Group Testing
by
Batuhan Arasli and Sennur Ulukus
Cited by 1 | Viewed by 1165
Abstract
Group testing idea is an efficient approach to detect prevalence of an infection in the test samples taken from a group of individuals. It is based on the idea of pooling the test samples and performing tests to the mixed samples. This approach
[...] Read more.
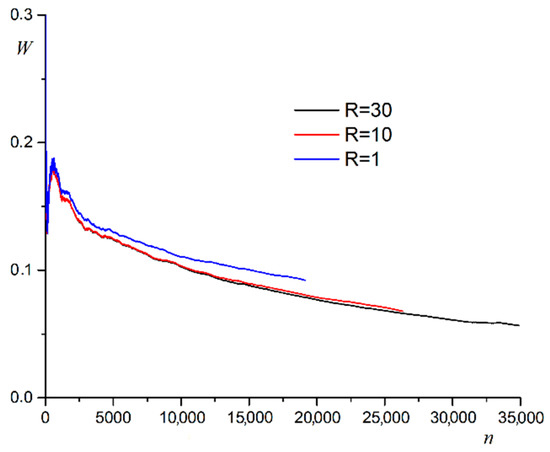
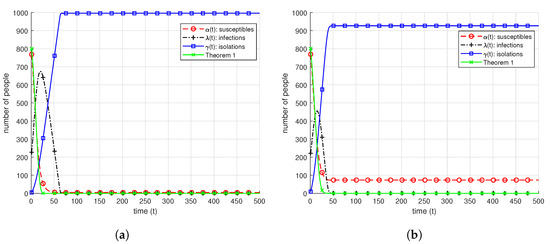
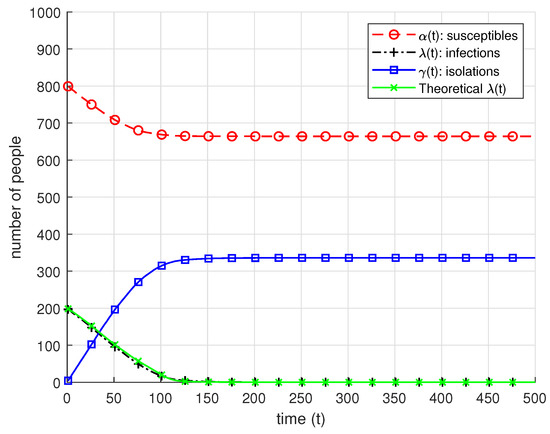
Group testing idea is an efficient approach to detect prevalence of an infection in the test samples taken from a group of individuals. It is based on the idea of pooling the test samples and performing tests to the mixed samples. This approach results in possible reduction in the required number of tests to identify infections. Classical group testing works consider static settings where the infection statuses of the individuals do not change throughout the testing process. In our paper, we study a dynamic infection spread model, inspired by the discrete time SIR model, where infections are spread via non-isolated infected individuals, while infection keeps spreading over time, a limited capacity testing is performed at each time instance as well. In contrast to the classical, static group testing problem, the objective in our setup is not to find the minimum number of required tests to identify the infection status of every individual in the population, but to control the infection spread by detecting and isolating the infections over time by using the given, limited number of tests. In order to analyze the performance of the proposed algorithms, we focus on the average-case analysis of the number of individuals that remain non-infected throughout the process of controlling the infection. We propose two dynamic algorithms that both use given limited number of tests to identify and isolate the infections over time, while the infection spreads, while the first algorithm is a dynamic randomized individual testing algorithm, in the second algorithm we employ the group testing approach similar to the original work of Dorfman. By considering weak versions of our algorithms, we obtain lower bounds for the performance of our algorithms. Finally, we implement our algorithms and run simulations to gather numerical results and compare our algorithms and theoretical approximation results under different sets of system parameters.
Full article
►▼
Show Figures
Open AccessArticle
Dynamic SAFFRON: Disease Control Over Time via Group Testing
by
Batuhan Arasli and Sennur Ulukus
Viewed by 1398
Abstract
Group testing is an efficient algorithmic approach to the infection identification problem, based on mixing the test samples and testing the mixed samples instead of individually testing each sample. In this paper, we consider the dynamic infection spread model that is based on
[...] Read more.
Group testing is an efficient algorithmic approach to the infection identification problem, based on mixing the test samples and testing the mixed samples instead of individually testing each sample. In this paper, we consider the dynamic infection spread model that is based on the discrete SIR model, which assumes the disease to be spread over time via infected and non-isolated individuals. In our system, the main objective is not to minimize the number of required tests to identify every infection, but instead, to utilize the available, given testing capacity
T at each time instance to efficiently control the infection spread. We introduce and study a novel performance metric, which we coin as
-disease control time. This metric can be used to measure how fast a given algorithm can control the spread of a disease. We characterize the performance of the dynamic individual testing algorithm and introduce a novel dynamic SAFFRON-based group testing algorithm. We present theoretical results and implement the proposed algorithms to compare their performances.
Full article
►▼
Show Figures
Open AccessArticle
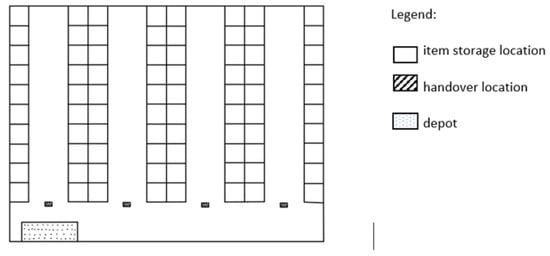
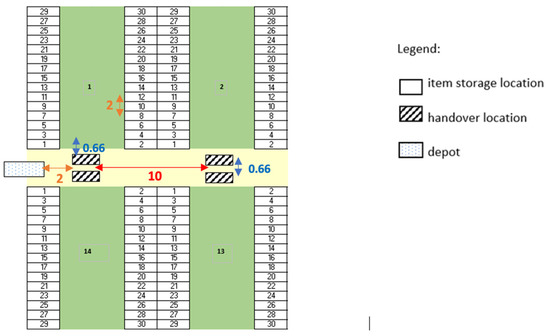
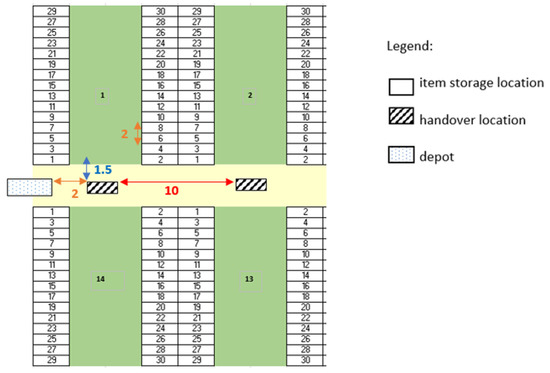
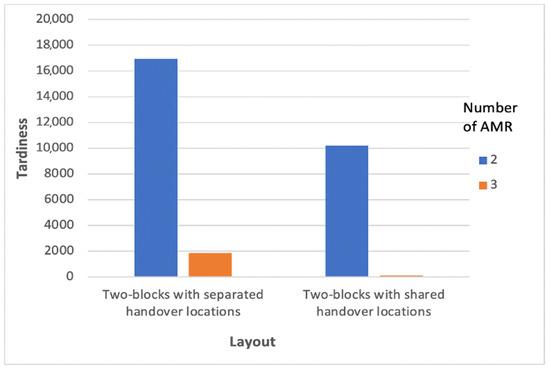
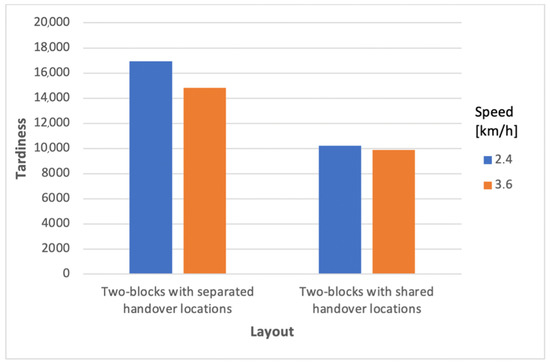
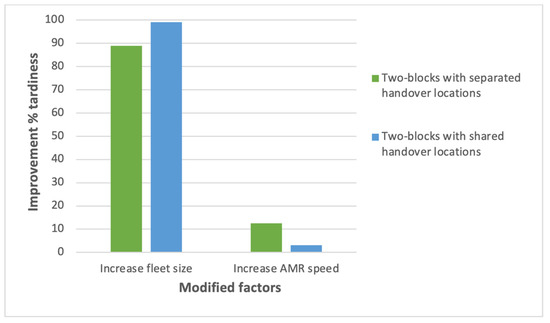
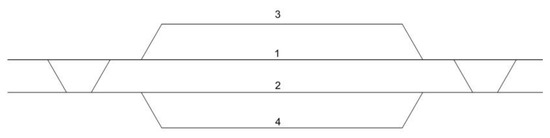
AMR-Assisted Order Picking: Models for Picker-to-Parts Systems in a Two-Blocks Warehouse
by
Giulia Pugliese, Xiaochen Chou, Dominic Loske, Matthias Klumpp and Roberto Montemanni
Cited by 3 | Viewed by 2539
Abstract
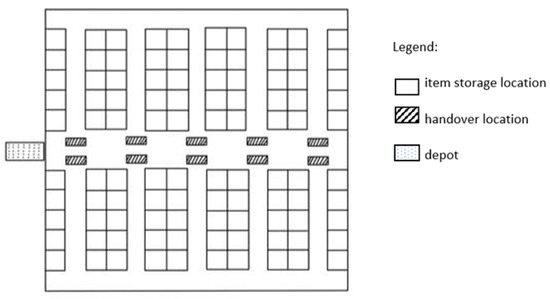
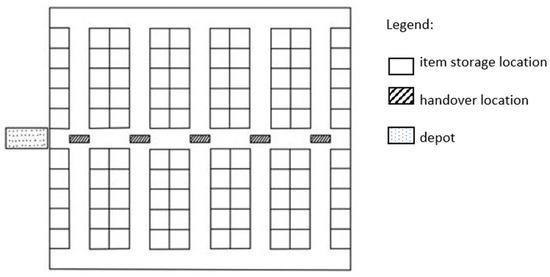
Manual order picking, the process of retrieving stock keeping units from their storage location to fulfil customer orders, is one of the most labour-intensive and costly activity in modern supply chains. To improve the outcome of order picking systems, automated and robotized components
[...] Read more.
Manual order picking, the process of retrieving stock keeping units from their storage location to fulfil customer orders, is one of the most labour-intensive and costly activity in modern supply chains. To improve the outcome of order picking systems, automated and robotized components are increasingly introduced creating hybrid order picking systems where humans and machines jointly work together. This study focuses on the application of a hybrid picker-to-parts order picking system, in which human operators collaborate with Automated Mobile Robots (AMRs). In this paper a warehouse with a two-blocks layout is investigated. The main contributions are new mathematical models for the optimization of picking operations and synchronizations. Two alternative implementations for an AMR system are considered. In the first one handover locations, where pickers load AMRs are shared between pairs of opposite sub-aisles, while in the second they are not. It is shown that solving the mathematical models proposed by the meaning of black-box solvers provides a viable algorithmic optimization approach that can be used in practice to derive efficient operational plannings. The experimental study presented, based on a real warehouse and real orders, finally allows to evaluate and strategically compare the two alternative implementations considered for the AMR system.
Full article
►▼
Show Figures
Open AccessArticle
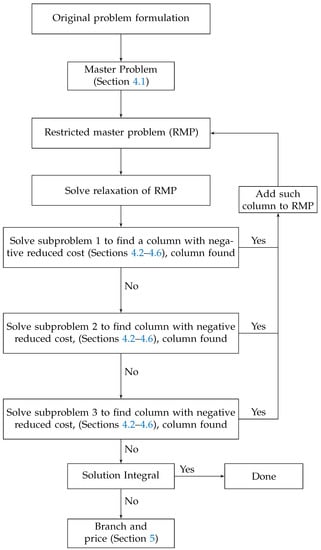
Branch and Price Algorithm for Multi-Trip Vehicle Routing with a Variable Number of Wagons and Time Windows
by
Leila Karimi and Chowdhury Nawrin Ferdous
Cited by 2 | Viewed by 1793
Abstract
Motivated by the transportation needs of modern-day retailers, we consider a variant of the vehicle routing problem with time windows in which each truck has a variable capacity. In our model, each vehicle can bring one or more wagons. The clients are visited
[...] Read more.
Motivated by the transportation needs of modern-day retailers, we consider a variant of the vehicle routing problem with time windows in which each truck has a variable capacity. In our model, each vehicle can bring one or more wagons. The clients are visited within specified time windows, and the vehicles can also make multiple trips. We give a mathematical programming formulation for the problem, and a branch and price algorithm is developed to solve the model. In each iteration of branch and price, column generation is used. Different subproblems are created based on the different capacities to find the best column. We use CPLEX to solve the problem computationally and extend Solomon’s instances to evaluate our approach. To our knowledge, ours is the first such study in this field.
Full article
►▼
Show Figures
Open AccessArticle
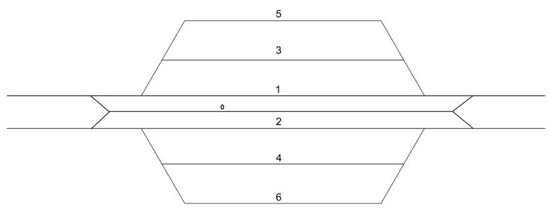
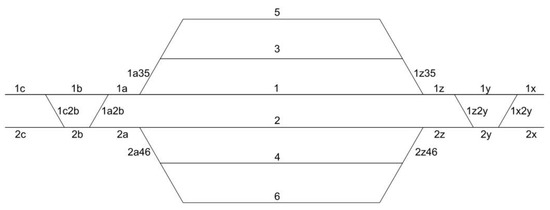
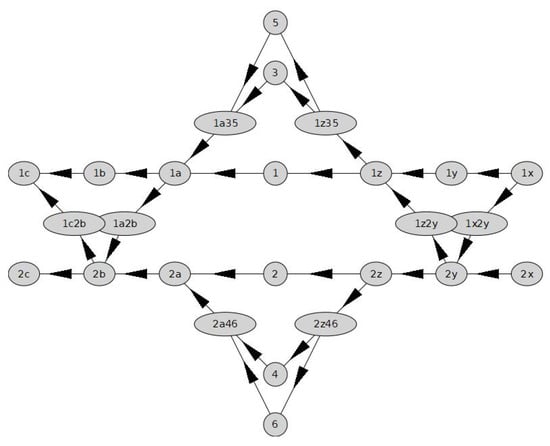
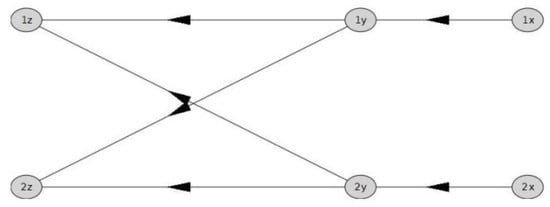
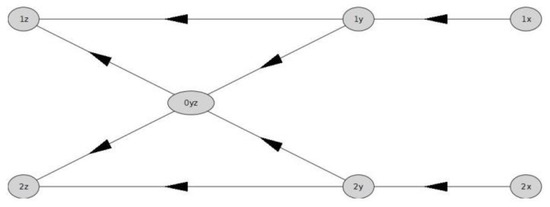
A Computational Approach to Overtaking Station Track Layout Design Using Graphs: An Extension That Supports Special Turnouts—An Improved Alternative Track Layout Proposal
by
Eugenio Roanes-Lozano
Viewed by 1668
Abstract
The author recently designed, developed and implemented in
Maple a package based on the use of digraphs that analyses the connectivity of an overtaking station on a double-track line. It was used to propose an alternative track layout for this kind of station,
[...] Read more.
The author recently designed, developed and implemented in
Maple a package based on the use of digraphs that analyses the connectivity of an overtaking station on a double-track line. It was used to propose an alternative track layout for this kind of station, with advantages over the track layouts usually adopted. However, that package could only deal with “standard” turnouts (but neither with crossings nor with “special” turnouts, such as “single slip turnouts” or “scissors crossings”). This new article presents an improved version of the package. It uses a trick consisting in including virtual vertices in the associated digraph that are dead ends. This way it is possible to include the “special” turnouts in the track layout. It makes it possible to evaluate different alternative track layouts, including “special” turnouts; and to finally find one track layout that has advantages over the standard one and over the one proposed in the previous article. Let us observe that the design of the track layout is key for the exploitation of the infrastructure. In fact, the Spanish infrastructure administrator is nowadays remodelling the track layout of some of its main railway stations, as well as other smaller facilities.
Full article
►▼
Show Figures
Open AccessArticle
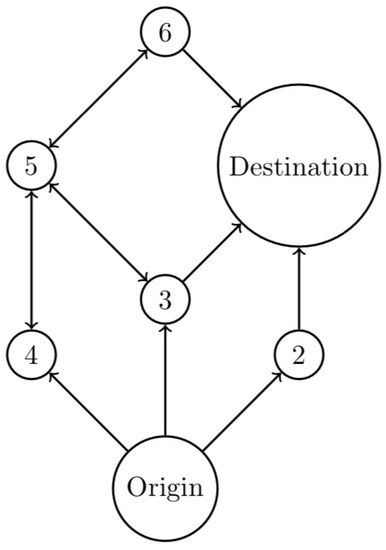
A Constructive Heuristics and an Iterated Neighborhood Search Procedure to Solve the Cost-Balanced Path Problem
by
Daniela Ambrosino, Carmine Cerrone and Anna Sciomachen
Cited by 1 | Viewed by 1416
Abstract
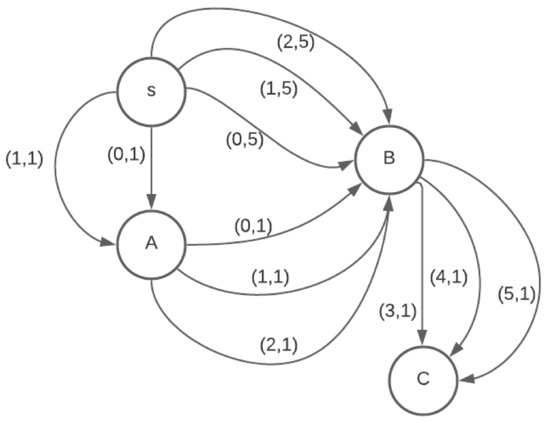
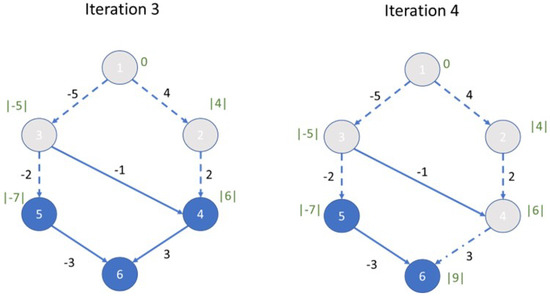
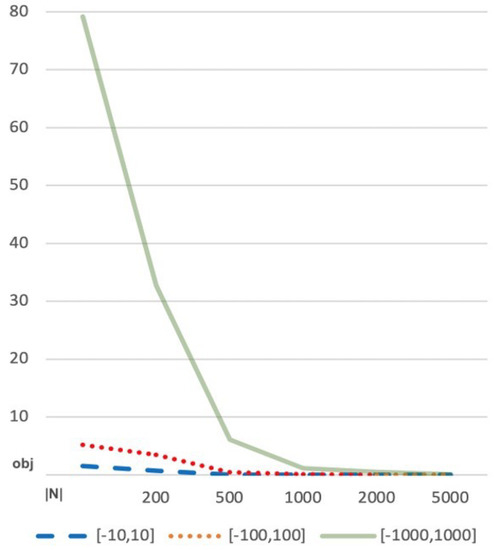
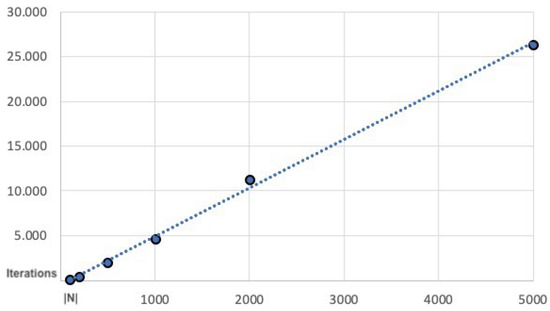
This paper presents a new heuristic algorithm tailored to solve large instances of an NP-hard variant of the shortest path problem, denoted the cost-balanced path problem, recently proposed in the literature. The problem consists in finding the origin–destination path in a direct graph,
[...] Read more.
This paper presents a new heuristic algorithm tailored to solve large instances of an NP-hard variant of the shortest path problem, denoted the cost-balanced path problem, recently proposed in the literature. The problem consists in finding the origin–destination path in a direct graph, having both negative and positive weights associated with the arcs, such that the total sum of the weights of the selected arcs is as close to zero as possible. At least to the authors’ knowledge, there are no solution algorithms for facing this problem. The proposed algorithm integrates a constructive procedure and an improvement procedure, and it is validated thanks to the implementation of an iterated neighborhood search procedure. The reported numerical experimentation shows that the proposed algorithm is computationally very efficient. In particular, the proposed algorithm is most suitable in the case of large instances where it is possible to prove the existence of a perfectly balanced path and thus the optimality of the solution by finding a good percentage of optimal solutions in negligible computational time.
Full article
►▼
Show Figures
Open AccessArticle
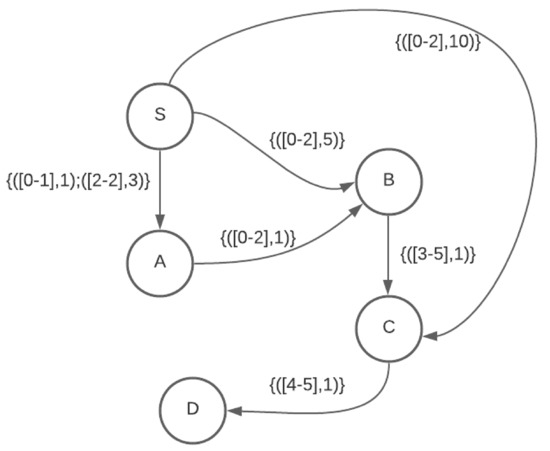
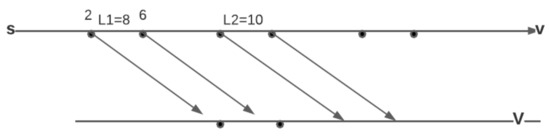
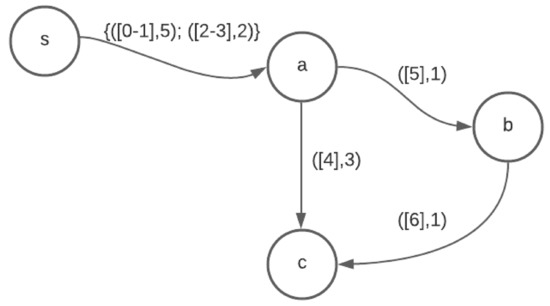
Foremost Walks and Paths in Interval Temporal Graphs
by
Anuj Jain and Sartaj Sahni
Cited by 1 | Viewed by 1457
Abstract
The min-wait foremost, min-hop foremost and min-cost foremost paths and walks problems in interval temporal graphs are considered. We prove that finding min-wait foremost and min-cost foremost walks and paths in interval temporal graphs is NP-hard. We develop a polynomial time algorithm for
[...] Read more.
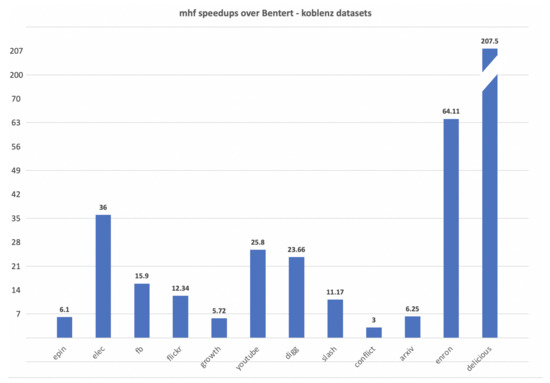
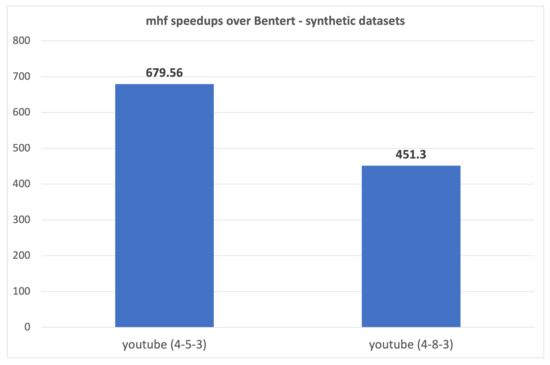
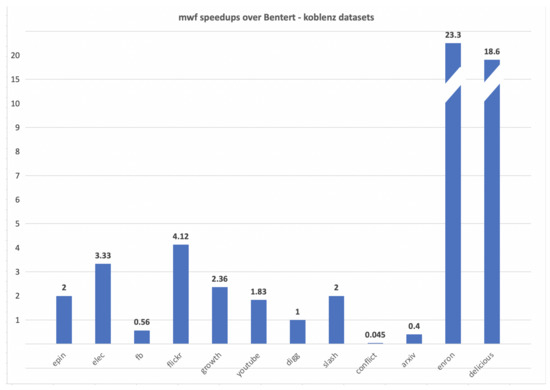
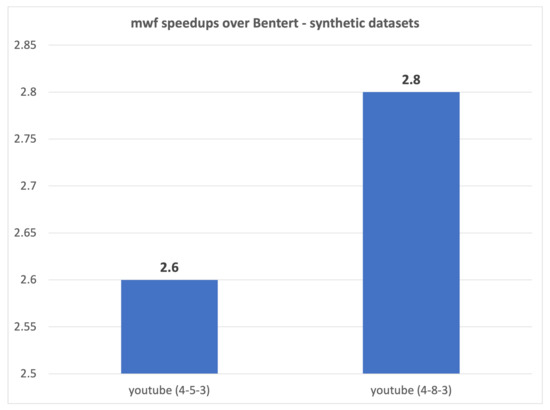
The min-wait foremost, min-hop foremost and min-cost foremost paths and walks problems in interval temporal graphs are considered. We prove that finding min-wait foremost and min-cost foremost walks and paths in interval temporal graphs is NP-hard. We develop a polynomial time algorithm for the single-source all-destinations min-hop foremost paths problem and a pseudopolynomial time algorithm for the single-source all-destinations min-wait foremost walks problem in interval temporal graphs. We benchmark our algorithms against algorithms presented by Bentert et al. for contact sequence graphs and show, experimentally, that our algorithms perform up to 207.5 times faster for finding min-hop foremost paths and up to 23.3 times faster for finding min-wait foremost walks.
Full article
►▼
Show Figures
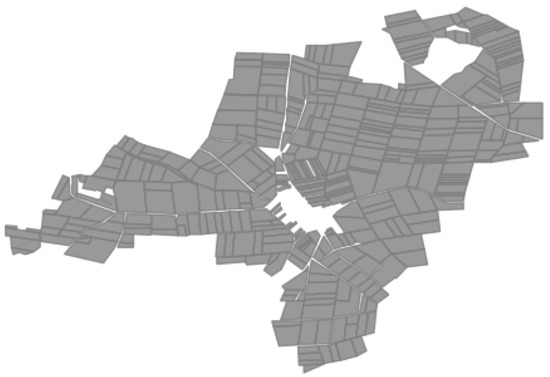
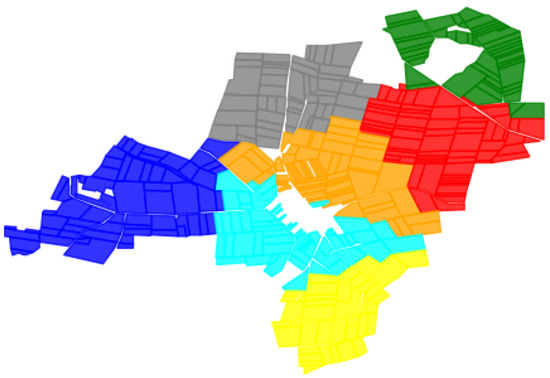
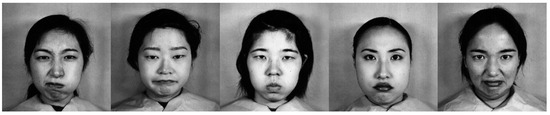
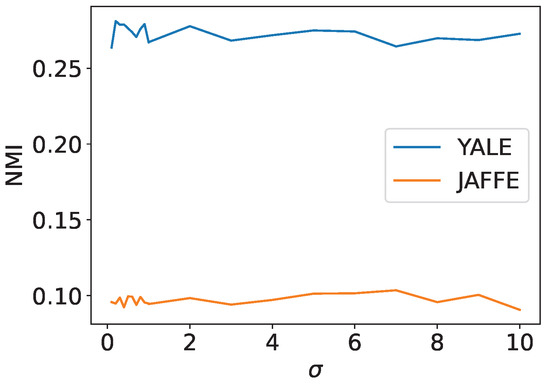
Open AccessArticle
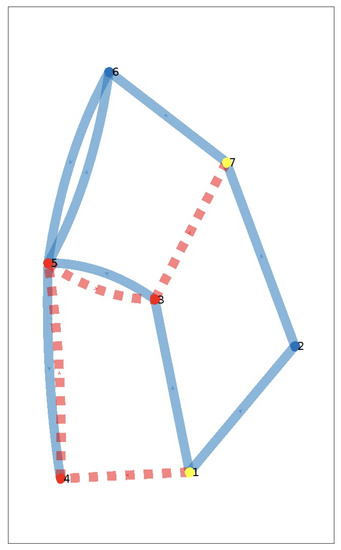
Images Segmentation Based on Cutting the Graph into Communities
by
Sergey V. Belim and Svetlana Yu. Belim
Cited by 1 | Viewed by 1703
Abstract
This article considers the problem of image segmentation based on its representation as an undirected weighted graph. Image segmentation is equivalent to partitioning a graph into communities. The image segment corresponds to each community. The growing area algorithm search communities on the graph.
[...] Read more.
This article considers the problem of image segmentation based on its representation as an undirected weighted graph. Image segmentation is equivalent to partitioning a graph into communities. The image segment corresponds to each community. The growing area algorithm search communities on the graph. The average edge weight in the community is a measure of the separation quality. The correlation radius determines the number of next nearest neighbors connected by edges. Edge weight is a function of the difference between color and geometric coordinates of pixels. The exponential law calculates the weights of an edge in a graph. The computer experiment determines the parameters of the algorithm.
Full article
►▼
Show Figures
Open AccessArticle
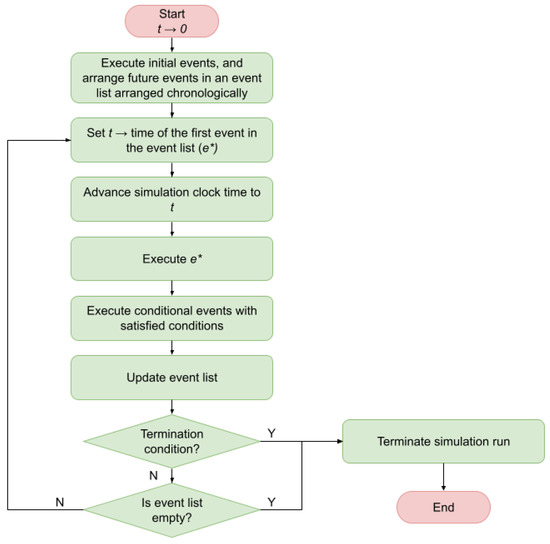
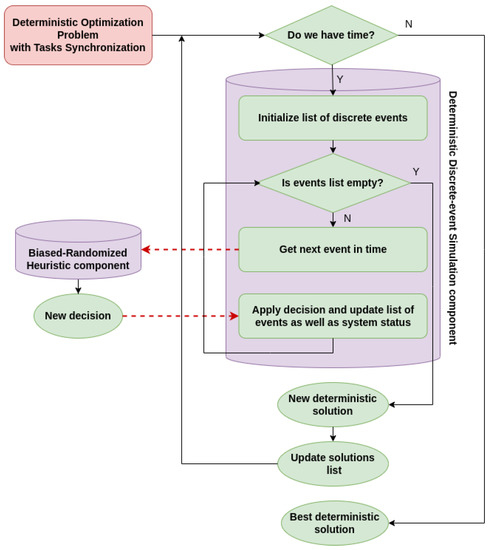
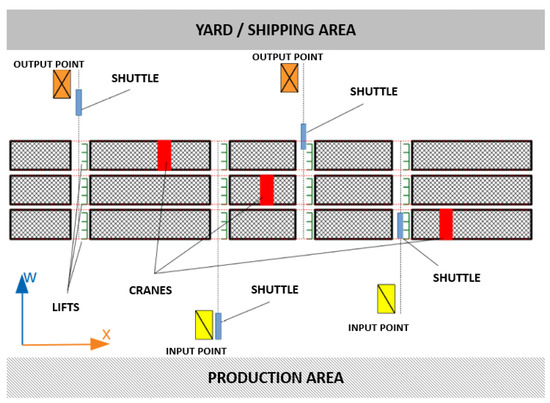
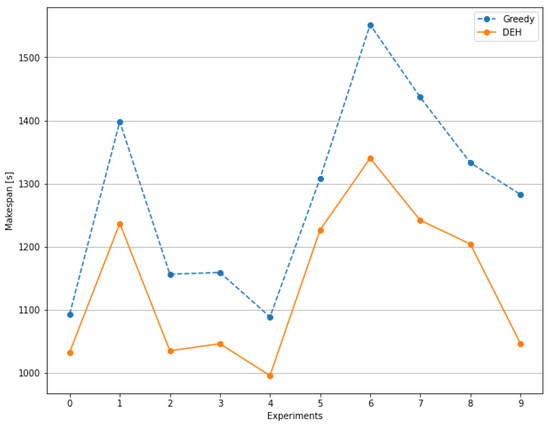
Biased-Randomized Discrete-Event Heuristics for Dynamic Optimization with Time Dependencies and Synchronization
by
Juliana Castaneda, Mattia Neroni, Majsa Ammouriova, Javier Panadero and Angel A. Juan
Cited by 3 | Viewed by 1593
Abstract
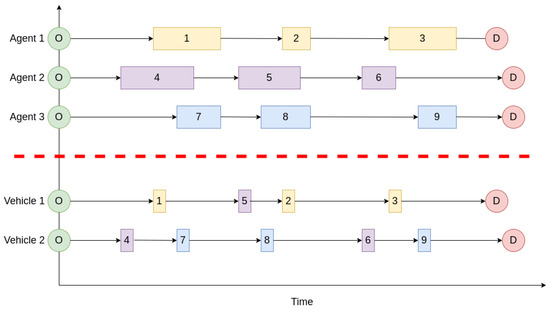
Many real-life combinatorial optimization problems are subject to a high degree of dynamism, while, simultaneously, a certain level of synchronization among agents and events is required. Thus, for instance, in ride-sharing operations, the arrival of vehicles at pick-up points needs to be synchronized
[...] Read more.
Many real-life combinatorial optimization problems are subject to a high degree of dynamism, while, simultaneously, a certain level of synchronization among agents and events is required. Thus, for instance, in ride-sharing operations, the arrival of vehicles at pick-up points needs to be synchronized with the times at which users reach these locations so that waiting times do not represent an issue. Likewise, in warehouse logistics, the availability of automated guided vehicles at an entry point needs to be synchronized with the arrival of new items to be stored. In many cases, as operational decisions are made, a series of interdependent events are scheduled for the future, thus making the synchronization task one that traditional optimization methods cannot handle easily. On the contrary, discrete-event simulation allows for processing a complex list of scheduled events in a natural way, although the optimization component is missing here. This paper discusses a hybrid approach in which a heuristic is driven by a list of discrete events and then extended into a biased-randomized algorithm. As the paper discusses in detail, the proposed hybrid approach allows us to efficiently tackle optimization problems with complex synchronization issues.
Full article
►▼
Show Figures
Open AccessArticle
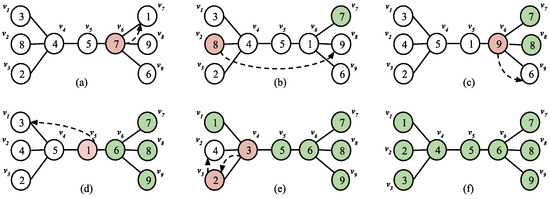
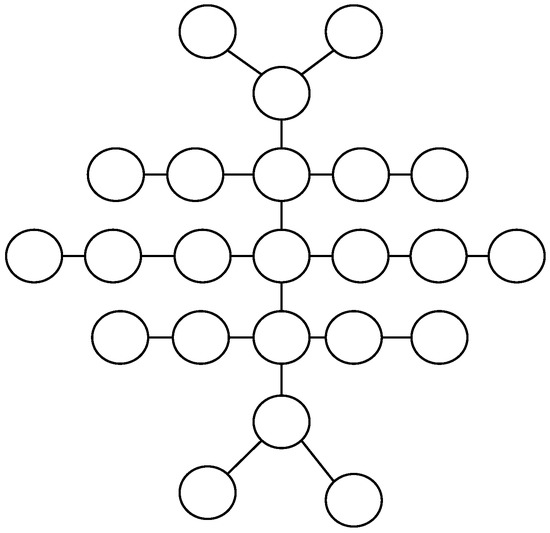
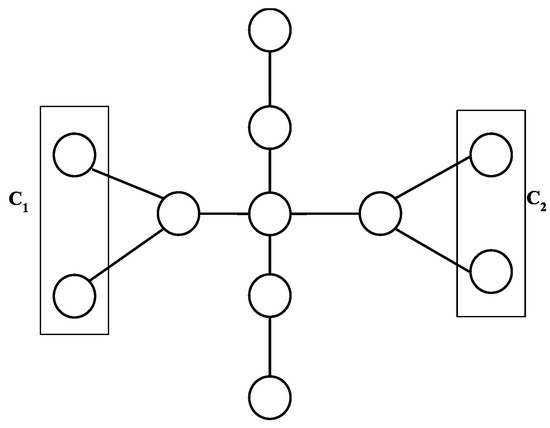
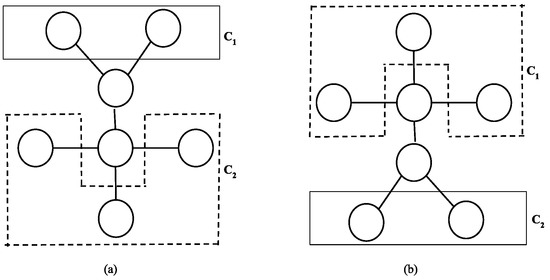
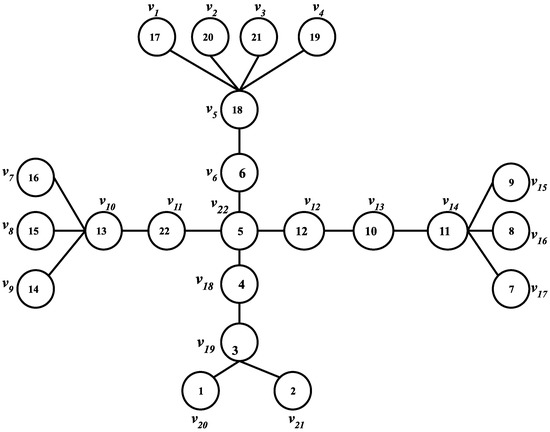
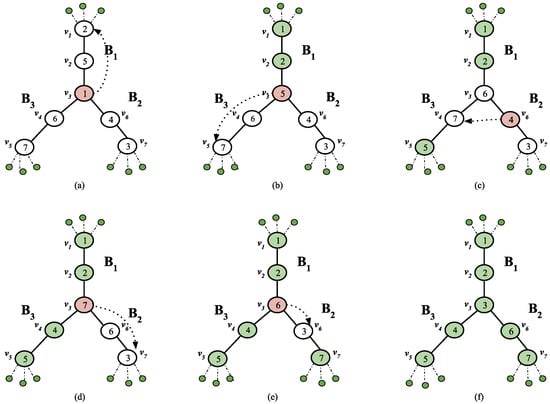
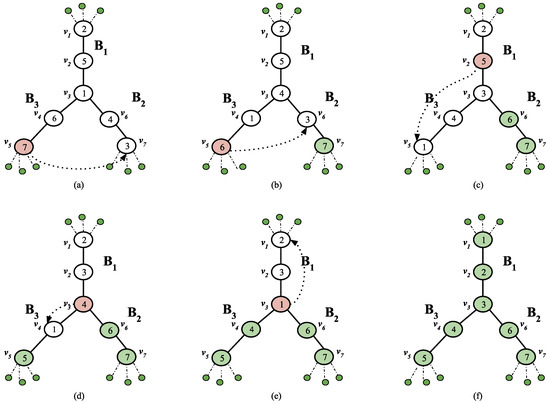
Optimal Algorithms for Sorting Permutations with Brooms
by
Indulekha Thekkethuruthel Sadanandan and Bhadrachalam Chitturi
Cited by 5 | Viewed by 2554
Abstract
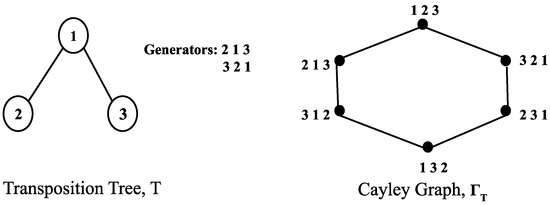
Sorting permutations with various operations has applications in genetics and computer interconnection networks where an operation is specified by its generator set. A transposition tree
is a spanning tree over
n vertices
[...] Read more.
Sorting permutations with various operations has applications in genetics and computer interconnection networks where an operation is specified by its generator set. A transposition tree
is a spanning tree over
n vertices
.
T denotes an operation in which each edge is a generator. A value assigned to a vertex is called a
token or a
marker. The markers on vertices
u and
v can be swapped only if the pair
. The initial configuration consists of a bijection from the set of vertices
to the set of markers
. The goal is to
sort the initial configuration of
T, i.e., an input permutation, by applying the minimum number of swaps or
moves in
T. Computationally tractable optimal algorithms to sort permutations are known only for a few classes of transposition trees. We study a class of transposition trees called a
broom and its variation a
double broom. A
single broom is a tree obtained by joining the centre vertex of a star with one of the two leaf vertices of a path graph. A
double broom is an extension of a single broom where the centre vertex of a second star is connected to the terminal vertex of the path in a single broom. We propose a simple and efficient algorithm to obtain an optimal swap sequence to sort permutations with the transposition tree broom and a novel optimal algorithm to sort permutations with a double broom. We also introduce a new class of trees named
millipede tree and prove that
yields a tighter upper bound for sorting permutations with a balanced millipede tree compared to
. Algorithms
and
are designed previously.
Full article
►▼
Show Figures



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
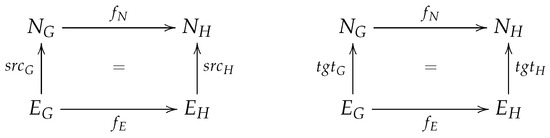{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}