
Assessment of Convolutional Neural Network Pre-Trained Models for Detection and Orientation of Cracks

 ,
,  ,
,  , ,
, , 
Abstract
:1. Introduction
2. Literature Review
3. Experimental Study
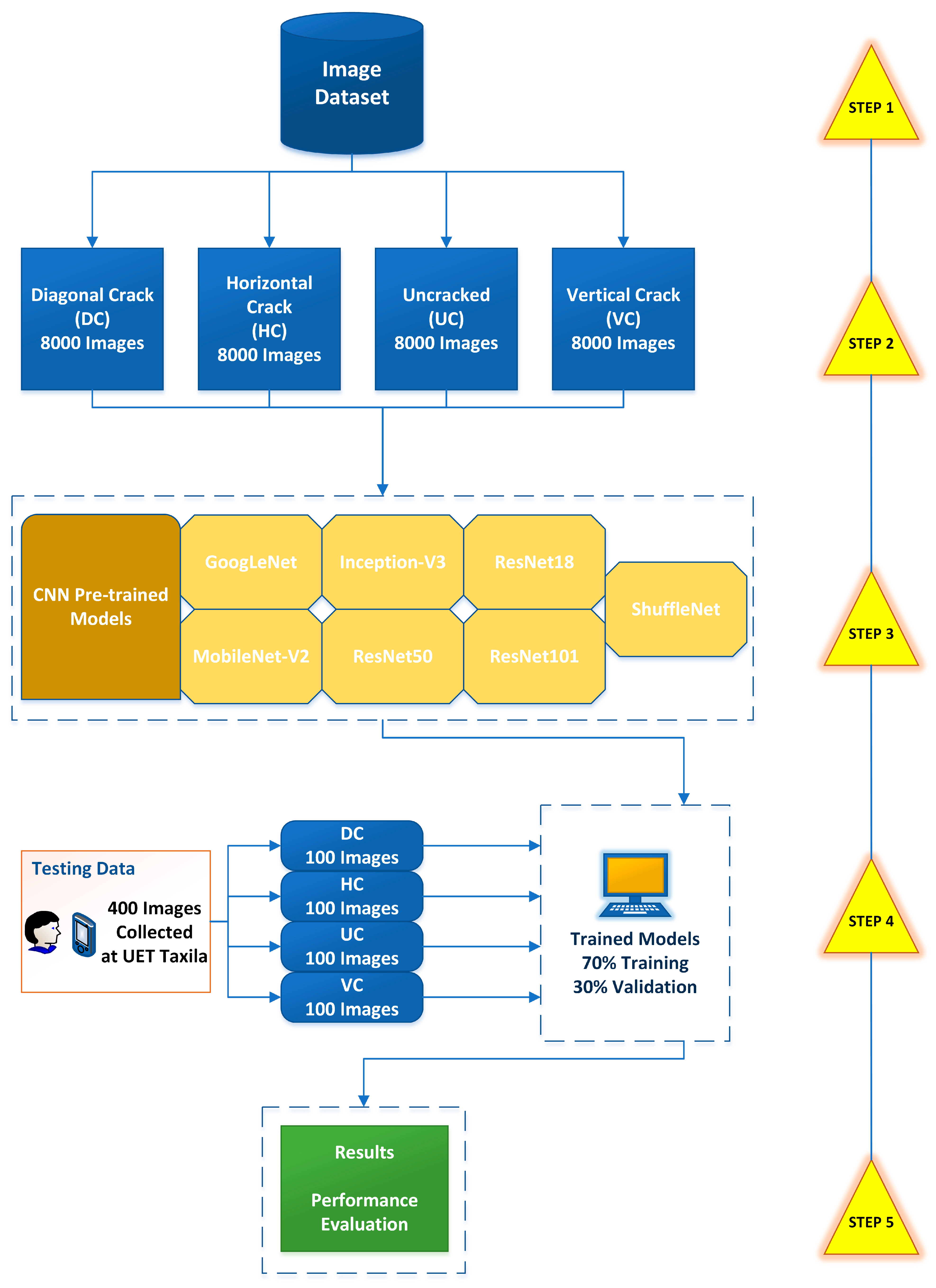
3.1. Overview of Methodology
3.2. Dataset Acquisition
3.3. Training, Validation, and Testing Dataset
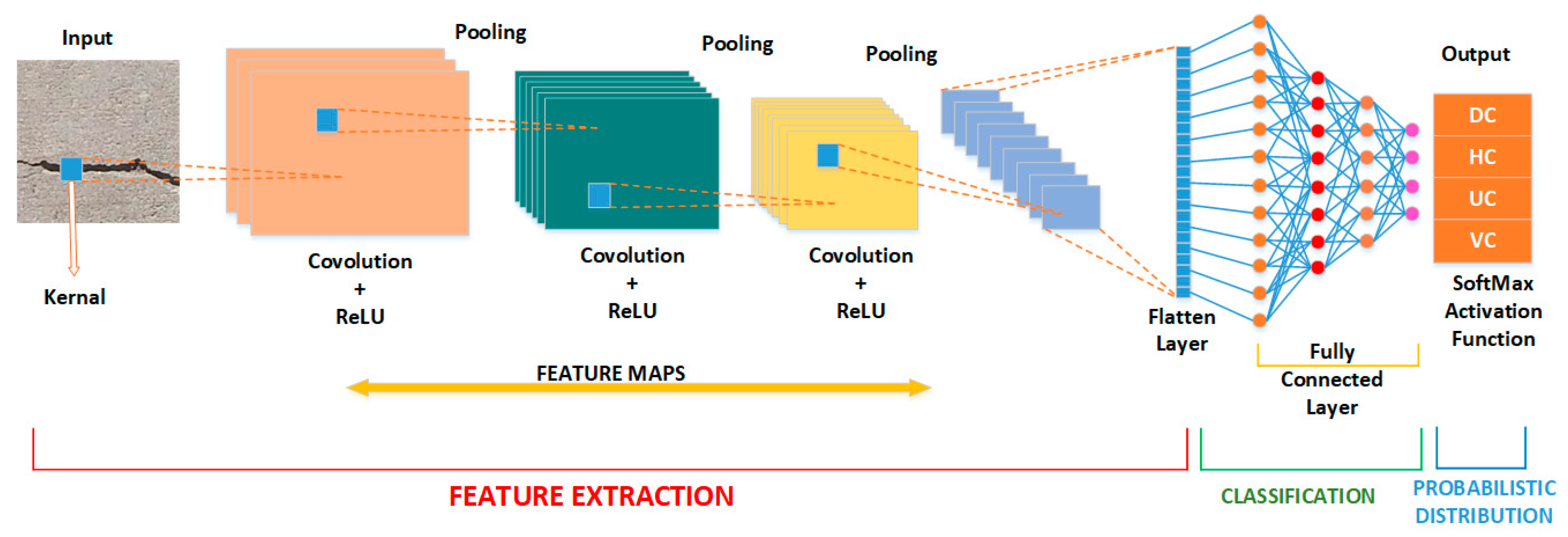
3.4. Pre-Trained Models
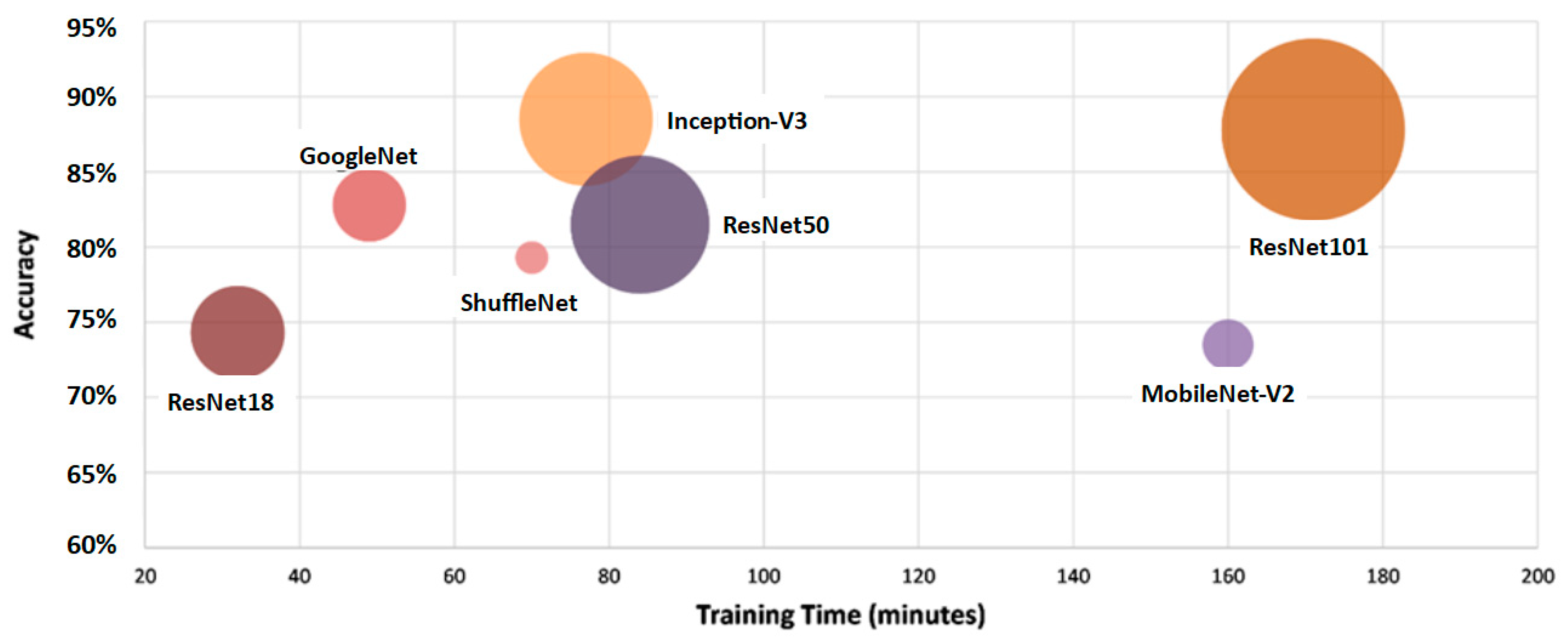
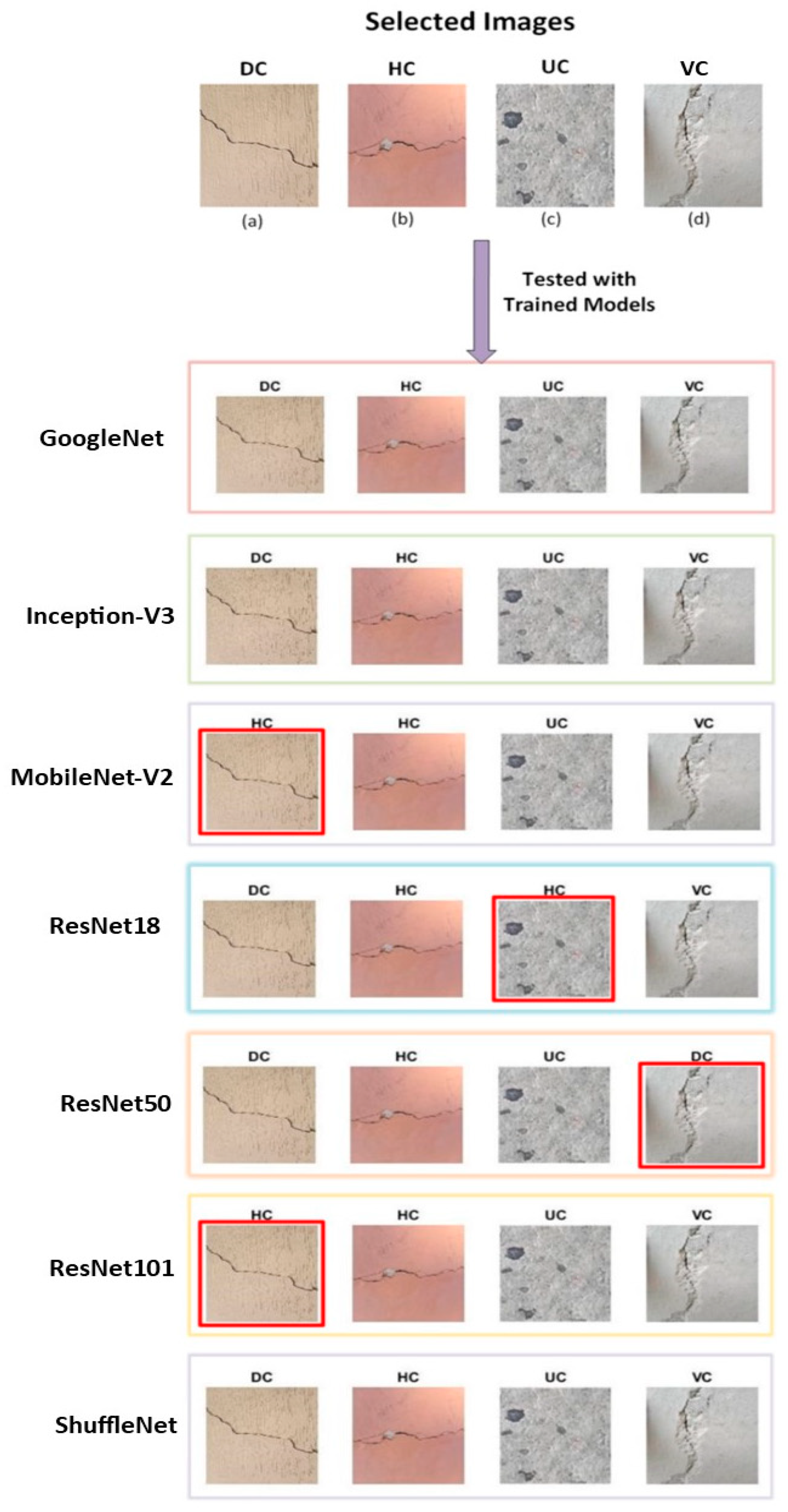
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Munawar, H.S.; Hammad, A.W.A.; Haddad, A.; Soares, C.A.P.; Waller, S.T. Image-based crack detection methods: A review. Infrastructures 2021, 6, 115. [Google Scholar] [CrossRef]
- Ni, F.T.; Zhang, J.; Chen, Z.Q. Pixel-level crack delineation in images with convolutional feature fusion. Struct. Control Health Monit. 2019, 26, e2286. [Google Scholar] [CrossRef] [Green Version]
- Liong, S.; Gan, Y.S.; Huang, Y.; Yuan, C.; Chang, H. Automatic defect segmentation on leather with deep learning. arXiv 2019, arXiv:1903.12139. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road Crack Detection Using Deep Convolutional Neural Network; IEEE Xplore: New York, NY, USA, 2016. [Google Scholar]
- Deng, L.; Way, O.M.; Yu, D.; Way, O.M. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Teuwen, J.; Moriakov, N. Convolutional neural networks. In Handbook of Medical Image Computing and Computer Assisted Intervention; Academic Press: Cambridge, MA, USA, 2020; pp. 481–501. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. arXiv 2015. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Chollet, F. Xception: Deep learning with depth wise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Tan, M.; Le, Q. Efficient net: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Nishikawa, T. Concrete crack detection by multiple sequential image filtering. Comput. Aided Civ. Infrastruct. Eng. 2012, 27, 29–47. [Google Scholar] [CrossRef]
- Brownjohn, J.M.W. Structural health monitoring of civil infrastructure. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2007, 365, 589–622. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ullah, F.; Sepasgozar, S.M.E.; Thaheem, M.J.; Al-turjman, F. Barriers to the digitalisation and innovation of Australian Smart Real Estate: A managerial perspective on the technology non-adoption. Environ. Technol. Innov. 2021, 22, 101527. [Google Scholar] [CrossRef]
- Ullah, F.; Qayyum, S.; Jamaluddin, M.; Al-Turjman, F.; Sepasgozar, S.M.E. Risk management in sustainable smart cities governance: A TOE framework. Technol. Forecast. Soc. Chang. 2021, 167, 120743. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 2003, 174, 255–263. [Google Scholar] [CrossRef] [Green Version]
- Prasanna, P.; Dana, K.; Gucunski, N.; Basily, B. Computer-vision based crack detection and analysis. In Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems; SPIE: Bellingham, WA, USA, 2012; Volume 8345, pp. 1143–1148. [Google Scholar]
- Maniat, M.; Camp, C.; Kashani, A. Deep learning-based visual crack detection using Google Street View images. Neural Comput. Appl. 2021, 33, 14565–14582. [Google Scholar] [CrossRef]
- Vu, C.; Duc, L. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput. Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Chaiyasarn, K.; Khan, W.; Ali, L.; Sharma, M.; Brackenbury, D.; DeJong, M. Crack detection in masonry structures using convolutional neural networks and support vector machines. In Proceedings of the ISARC the International Symposium on Automation and Robotics in Construction, Berlin, Germany, 20–25 July 2018. [Google Scholar] [CrossRef] [Green Version]
- Abdel-Qader, I.; Pashaie-Rad, S.; Abudayyeh, O.; Yehia, S. PCA-Based algorithm for unsupervised bridge crack detection. Adv. Eng. Softw. 2006, 37, 771–778. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, G.; Ding, Y.; Wu, B.; Lu, G. A vision-based active learning convolutional neural network model for concrete surface crack detection. Adv. Struct. Eng. 2020, 23, 2952–2964. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W. Vision-based concrete crack detection using a convolutional neural network. Conf. Proc. Soc. Exp. Mech. Ser. 2017, 2 Pt F2, 71–73. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Ehtisham, R.; Mir, J.; Chairman, N.; Ahmad, A. Evaluation of pre-trained ResNet and MobileNetV2 CNN models for the concrete crack detection and crack orientation classification. In Proceedings of the 1st International Conference on Advances in Civil and Environmental Engineering, Taxila Pakistan, 22–23 February 2022. [Google Scholar]
- Ahmed, C.F.; Cheema, A.; Qayyum, W.; Ehtisham, R. Detection of pavement cracks of UET Taxila using pre-trained model Resnet50 of CNN. IEEE Access 2022, 7, 176065–176086. [Google Scholar]
- Munawar, H.S.; Ullah, F.; Heravi, A.; Thaheem, M.J.; Maqsoom, A. Inspecting buildings using drones and computer vision: A machine learning approach to detect cracks and damages. Drones 2022, 6, 5. [Google Scholar] [CrossRef]
- Özgenel, F.; Sorguç, A.G. Performance comparison of pretrained convolutional neural networks on crack detection in buildings. In Proceedings of the ISARC the International Symposium on Automation and Robotics in Construction, Berlin, Germany, 20–25 July 2018. [Google Scholar] [CrossRef]
- Guzmán-Torres, J.A.; Naser, M.Z.; Domínguez-Mota, F.J. Effective medium crack classification on laboratory concrete specimens via competitive machine learning. Structures 2022, 37, 858–870. [Google Scholar] [CrossRef]
- Qayyum, W.; Ahmad, A.; Chairman, N. Evaluation of GoogLenet, Mobilenetv2, and Inceptionv3, pre-trained convolutional neural networks for detection and classification of concrete crack images. In Proceedings of the 1st International Conference on Advances in Civil and Environmental Engineering, Taxila Pakistan, 22–23 February 2022. [Google Scholar]
- Thai, H.T. Machine learning for structural engineering: A state-of-the-art review. Structures 2022, 38, 448–491. [Google Scholar] [CrossRef]
- Mishra, M.; Lourenço, P.B.; Ramana, G.V. Structural health monitoring of civil engineering structures by using the internet of things: A review. J. Build. Eng. 2022, 48, 103954. [Google Scholar] [CrossRef]
- Nunez, I.; Marani, A.; Flah, M.; Nehdi, M.L. Estimating compressive strength of modern concrete mixtures using computational intelligence: A systematic review. Constr. Build. Mater. 2021, 310, 125279. [Google Scholar] [CrossRef]
- Jiang, Y.; Pang, D.; Li, C. A deep learning approach for fast detection and classification of concrete damage. Autom. Constr. 2021, 128, 103785. [Google Scholar] [CrossRef]
- Dung, C.V.; Sekiya, H.; Hirano, S.; Okatani, T.; Miki, C. A vision-based method for crack detection in gusset plate welded joints of steel bridges using deep convolutional neural networks. Autom. Constr. 2019, 102, 217–229. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Talip, M.S.A.; Mokhtar, N.; Shoaib, M.A. Structural crack detection using deep convolutional neural networks. Autom. Constr. 2022, 133, 103989. [Google Scholar] [CrossRef]
- Asadi Shamsabadi, E.; Xu, C.; Rao, A.S.; Nguyen, T.; Ngo, T.; Dias-da-Costa, D. Vision transformer-based autonomous crack detection on asphalt and concrete surfaces. Autom. Constr. 2022, 140, 104316. [Google Scholar] [CrossRef]
- Yin, X.; Chen, Y.; Bouferguene, A.; Zaman, H.; Al-Hussein, M.; Kurach, L. A deep learning-based framework for an automated defect detection system for sewer pipes. Autom. Constr. 2020, 109, 102967. [Google Scholar] [CrossRef]
- Hassan, S.I.; Dang, L.M.; Mehmood, I.; Im, S.; Choi, C.; Kang, J.; Park, Y.-S.; Moon, H. Underground sewer pipe condition assessment based on convolutional neural networks. Autom. Constr. 2019, 106, 102849. [Google Scholar] [CrossRef]
- Wang, C.; Antos, S.E.; Triveno, L.M. Automatic detection of unreinforced masonry buildings from street view images using deep learning-based image segmentation. Autom. Constr. 2021, 132, 103968. [Google Scholar] [CrossRef]
- Kim, B.; Yuvaraj, N.; Preethaa, K.R.S.; Pandian, R.A. Surface crack detection using deep learning with shallow CNN architecture for enhanced computation. Neural Comput. Appl. 2021, 33, 9289–9305. [Google Scholar] [CrossRef]
- Nguyen, N.H.T.; Perry, S.; Bone, D.; Le, H.T.; Nguyen, T.T. Two-stage convolutional neural network for road crack detection and segmentation. Expert Syst. Appl. 2021, 186, 115718. [Google Scholar] [CrossRef]
- Ali, L.; Alnajjar, F.; Al Jassmi, H.; Gocho, M.; Khan, W.; Serhani, M.A. Performance evaluation of deep CNN-based crack detection and localization techniques for concrete structures. Sensors 2021, 21, 1688. [Google Scholar] [CrossRef]
- Wang, P.; Huang, H. Comparison analysis on present image-based crack detection methods in concrete structures. In Proceedings of the 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010; Volume 5, pp. 2530–2533. [Google Scholar] [CrossRef]
- Mohan, A.; Poobal, S. Crack detection using image processing: A critical review and analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Shan, Q.; Dewhurst, R.J. Surface-breaking fatigue crack detection using laser ultrasound. Appl. Phys. Lett. 1993, 62, 2649–2651. [Google Scholar] [CrossRef]
- Feng, C.; Liu, M.Y.; Kao, C.C.; Lee, T.Y. Deep active learning for civil infrastructure defect detection and classification. Proceedings of ASCE International Workshop on Computing in Civil Engineering 2017, Seattle, WA, USA, 25–27 June 2017; 2017; pp. 298–306. [Google Scholar] [CrossRef] [Green Version]
- Maguire, M.; Dorafshan, S.; Thomas, R. SDNET2018: A Concrete Crack Image Dataset for Machine Learning Applications. Ph.D. Thesis, Utah State University, Logan, UT, USA, 17 May 2018. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- MathWorks. Pretrained Deep Neural Networks. Available online: https://www.mathworks.com/help/deeplearning/ug/pretrained-convolutional-neural-networks.html (accessed on 21 June 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Domain | Dataset | Image Features | Results | Reference |
|---|---|---|---|---|---|
| FFT, FHT, Sobel, and Canny edge detector | Concrete Bridge | 50 | 640 × 480 | FHT more reliable Accuracy = 86% | [26] |
| SVM | Bridge deck | 118 | - | Accuracy = 76% | [27] |
| VGG16 | Street Images | 48,000 | 200 × 200 | Accuracy = 98.6% | [28] |
| Fully Convolutional Network VGG16, Inception-V3, and ResNet | Concrete Cracks | 40,000 | 227 × 227 | VGG16 Accuracy = 99.9% | [29] |
| Canny and Sobel Edge detection | Concrete Cracks | 40,000 | 256 × 256 | Accuracy = 98.2% | [30] |
| CNN and SVM | Masonry Structure | 6002 | 96 × 96 | Accuracy = 86% | [31] |
| AlexNet and ChaNet | Concrete Cracks | 125 | 256 × 256 | ChaNet Accuracy = 7.91% | [33] |
| Deep CNN with eight layers Convolution, Pooling, Relu, and SoftMax | Concrete Cracks | 40,000 | 256 × 256 × 3 | Accuracy = 98% | [34] |
| VGG16 | Pavement Cracks | 1056 | 3072 × 2048 | Accuracy = 87% | [35] |
| ResNet18, ResNet50, ResNet101, and MobileNet-V2 | Concrete and Pavement Cracks | 32,000 | 256 × 256 × 3 | ResNet50 Accuracy = 86.2% | [36] |
| ResNet50 | Pavement Cracks | 48,000 | 256 × 256 × 3 | Accuracy = 99.8% | [37] |
| AlexNet, VGG16, VGG19, GoogLeNet, ResNet50, ResNet101, and ResNet152 | Masonry walls and Concrete Floors | 40,000 | 224 × 224 | VGG16 Average Accuracy = 96% | [39] |
| SVM and MDNMS | Road Cracks | 7250 | 4000 × 1000 | Precision = 98.29% | [56] |
| GoogLeNet, CNN, and FPN | Concrete Cracks | 128,000 | 6000 × 4000 | Precision = 80.13% | [57] |
| STRUM, SVM, AdaBoost, and Random Forest | Concrete Bridge | 100 | 1920 × 1280 | Accuracy = 95% | [58] |
| SVM and CNN | Pavement Cracks | 500 | 3264 × 2448 | Accuracy = 91.3% | [59] |
| GoogLeNet, MobileNet-V2, and Inception-V3 | Concrete and Pavement Cracks | 48,000 | 256 × 256 × 3 | Inception-V3 Accuracy = 97.2% | [41] |
| Network | Image Input Size | Parameters (Millions) | Size (MB) | Depth (Layers) |
|---|---|---|---|---|
| GoogLeNet | 224 × 224 | 7.0 | 27 | 22 |
| Inception-V3 | 299 × 299 | 23.9 | 89 | 48 |
| MobileNet-V2 | 224 × 224 | 3.5 | 13 | 53 |
| ResNet18 | 224 × 224 | 11.7 | 44 | 18 |
| ResNet50 | 224 × 224 | 25.6 | 96 | 50 |
| ResNet101 | 224 × 224 | 44.6 | 167 | 101 |
| ShuffleNet | 224 × 224 | 1.4 | 1.4 | 50 |
| Sr. No. | CNN Architecture | Class | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| 1 | GoogLeNet | DC | 92% | 94% | 79% | 86% |
| HC | 93% | 89% | 84% | 86% | ||
| UC | 88% | 53% | 100% | 69% | ||
| VC | 92% | 95% | 78% | 86% | ||
| 2 | MobileNet-V2 | DC | 86% | 92% | 65% | 76% |
| HC | 91% | 88% | 77% | 82% | ||
| UC | 87% | 47% | 100% | 64% | ||
| VC | 84% | 67% | 68% | 68% | ||
| 3 | Inception-V3 | DC | 96% | 98% | 88% | 93% |
| HC | 94% | 96% | 81% | 88% | ||
| UC | 92% | 67% | 100% | 80% | ||
| VC | 96% | 93% | 89% | 91% | ||
| 4 | ResNet18 | DC | 84% | 98% | 62% | 76% |
| HC | 90% | 74% | 85% | 79% | ||
| UC | 85% | 40% | 100% | 57% | ||
| VC | 89% | 85% | 75% | 79% | ||
| 5 | ResNet50 | DC | 88% | 98% | 67% | 80% |
| HC | 97% | 91% | 97% | 94% | ||
| UC | 92% | 69% | 100% | 82% | ||
| VC | 86% | 68% | 75% | 71% | ||
| 6 | ResNet101 | DC | 95% | 86% | 93% | 90% |
| HC | 95% | 99% | 83% | 90% | ||
| UC | 92% | 71% | 96% | 82% | ||
| VC | 94% | 95% | 83% | 88% | ||
| 7 | ShuffleNet | DC | 82% | 97% | 58% | 73% |
| HC | 91% | 65% | 97% | 78% | ||
| UC | 90% | 60% | 100% | 75% | ||
| VC | 96% | 95% | 90% | 92% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qayyum, W.; Ehtisham, R.; Bahrami, A.; Camp, C.; Mir, J.; Ahmad, A. Assessment of Convolutional Neural Network Pre-Trained Models for Detection and Orientation of Cracks. Materials 2023, 16, 826. https://doi.org/10.3390/ma16020826
Qayyum W, Ehtisham R, Bahrami A, Camp C, Mir J, Ahmad A. Assessment of Convolutional Neural Network Pre-Trained Models for Detection and Orientation of Cracks. Materials. 2023; 16(2):826. https://doi.org/10.3390/ma16020826
Chicago/Turabian StyleQayyum, Waqas, Rana Ehtisham, Alireza Bahrami, Charles Camp, Junaid Mir, and Afaq Ahmad. 2023. "Assessment of Convolutional Neural Network Pre-Trained Models for Detection and Orientation of Cracks" Materials 16, no. 2: 826. https://doi.org/10.3390/ma16020826