
Research on Data-Driven Optimal Scheduling of Power System
Abstract
:1. Introduction
- A random variable model is established based on the history or forecast data of renewable energy generation to improve the applicability of scheduling scheme in actual system operation;
- To explore the statistical information represented by data, data-driven distributionally robust optimization (DRO) has been studied to solve the problem of the inaccurate modeling of uncertainty factors in traditional stochastic optimization and to reduce the conservatism of traditional robust optimization [11,12].
2. The Power System Scheduling Model with Renewable Energy
2.1. Objective Function
- Unit operating cost function:where N is the total number of units; is the active power output of the unit i in the scheduling period t; , , is the power generation cost coefficient of unit i; is the unit start-stop cost. The unit start-stop cost is determined according to whether the unit’s active power output is zero.
- Renewable energy consumption function:where is the total number of renewable energy units, is the active power output of the I-th renewable energy unit in the scheduling period t, and is the maximum active power output of the I-th renewable energy unit in the scheduling period t.
- Line overlimit function:where is the number of branches of the power network; is the current through the i branch at time t; is the maximum current allowed through the line i; and ∈ is a constant of 0.001 to prevent the denominator from being 0.
2.2. Constraint Condition
- Power balance constraints:At any given time, the total active power of thermal power units, renewable energy units and balancing units shall be equal to the total active power of the load:where , , and refer to the number of renewable energy units, thermal power units and load, respectively. is the active power output of the i renewable energy unit at time t; is the active power output of the i thermal power unit at time t; is the active power output of the balancing unit at time t; and is the active power consumed by the i load at time t.
- Unit output upper and lower limits constraints:At any given time, the active power output of any unit shall not be greater than the upper limit of the active power output, nor less than the lower limit of the active power output:where and are the minimum and maximum active output of the i thermal power unit, respectively:where is the maximum active output of the i renewable energy unit.The balance unit is used to share the system power imbalance caused by unreasonable scheduling policies and power flow calculation; the maximum output of the balance unit cannot exceed the upper limit of 110%, and the minimum cannot be lower than the lower limit of 90%:where and are the minimum and maximum active output of the balancing unit, respectively.
- Climbing constraint of thermal power unit:The output adjustment values of any thermal power unit should meet the climbing constraint:where rate is the climbing rate of the thermal power unit; is the maximum value that the thermal power unit can actually adjust downwards at time t + 1; and is the maximum downclimb constraint value. The maximum value of the two values is the maximum downclimb value allowed to be adjusted by the unit i. is the maximum value that the thermal power unit can actually adjust upwards at time t + 1, and is the maximum upward-climb constraint value. The minimum value of the two values is the maximum climbing value allowed to be adjusted by the unit i.
3. Data-Driven Reinforcement Learning Scheduling Algorithm
3.1. Deep Reinforcement Learning Framework
3.2. Proximal Policy Optimization Algorithm
3.2.1. Importance Sampling Principle
3.2.2. KL Divergence Penalty Factor
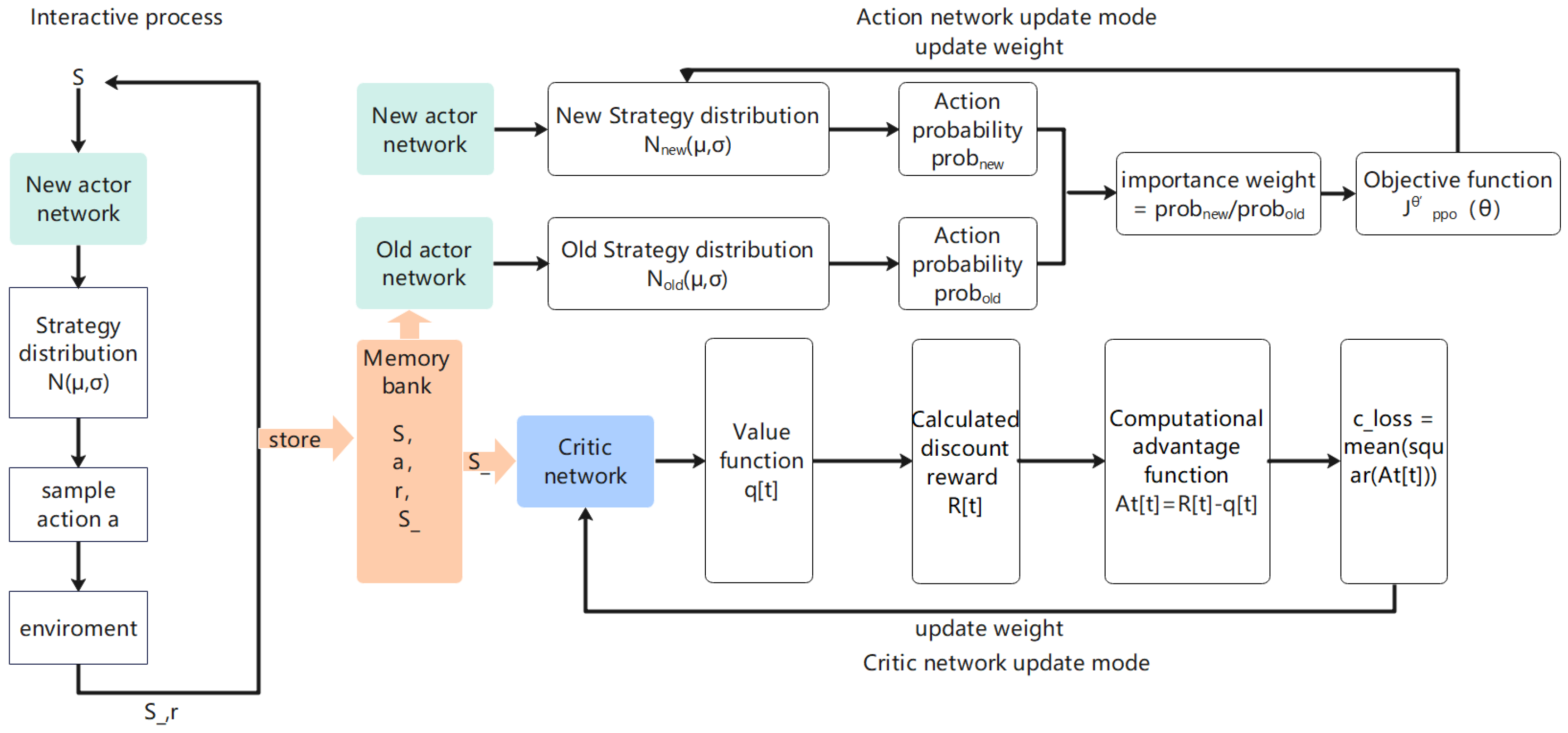
3.2.3. Algorithm Training Process
- Environmental information S is fed into the actor-new network and two values are obtained, one mu and one sigma. These two values are then taken as mean and variance, respectively, to construct a normal distribution, and an action is sampled through this normal distribution.The action is entered into the environment to obtain a reward r and the next state S_, and (S,a,r,S_) is stored as a scheduling experience. Then S_ is entered into the actor-new network, and the previous step is cycled until a certain amount of scheduling experience is stored [26].
- The S_ obtained in the previous step is fed into the critic network, the q_ value of the state is obtained, and the discount reward is calculated. We will get R = [R[0], R[1], …, R[T]].
- All S stored in step 1 are fed into the critic network to obtain all q_ state values, and At = R − q_ is calculated.c_loss = mean (square (At)) is calculated and the critical network parameters are updated by backpropagation.
- All combinations of stored S are entered into the actor-old network and actor-new network to obtain Normal1 and Normal2, respectively. Enter all combinations of stored actions into the normal distributions Normal1 and Normal2 to obtain prob1 and prob2 for each action. Then, the weights of importance are obtained by dividing prob2 by prob1.
- According to Formulas (19) and (20) of the paper, the loss function of the action network is calculated, and then backpropagation is carried out to update the actor-new network.
- Repeat 4–5 steps. After a certain step, the cycle ends. Update the actor-old network with actor-new network weights.
- Repeat 1–6 steps for training until convergence.

4. Example Simulation Analysis
4.1. Model Training Parameter Setting
4.2. Data Pre-Processing
4.3. Economic Security Scheduling Decision Model
- The reward of renewable energy consumption:
- The reward of line overlimit:
- The punishment of unit operating cost:
- The punishment of power unbalance:
- The punishment of unit output exceeding the limit:Unlike other constraints, there is no need to set a penalty for this constraint, and the unit output adjustment value was limited within the upper and lower limits at the time of setting.
- The punishment of output climbing over the limit of thermal power unit:
- Real-time reward function:Real-time reward function in reinforcement learning plays an important guiding role in agent exploration. Therefore, it is necessary to consider punishment and cost as a whole, define a reasonable reward function, and guide the agent’s strategy in the right direction to update. Combining the above rewards and punishments, set a real-time reward r for scheduling policies:where represents each reward item after normalization, the field values of the reward items r1 and r2 are [0,1], and the field values of the reward items r3, r4 and r5 are [−1,0]. represents the coefficient of each reward item, according to the research emphasis of this paper, a2 = a4 = a5 = 1, a1 = a3 = 2.
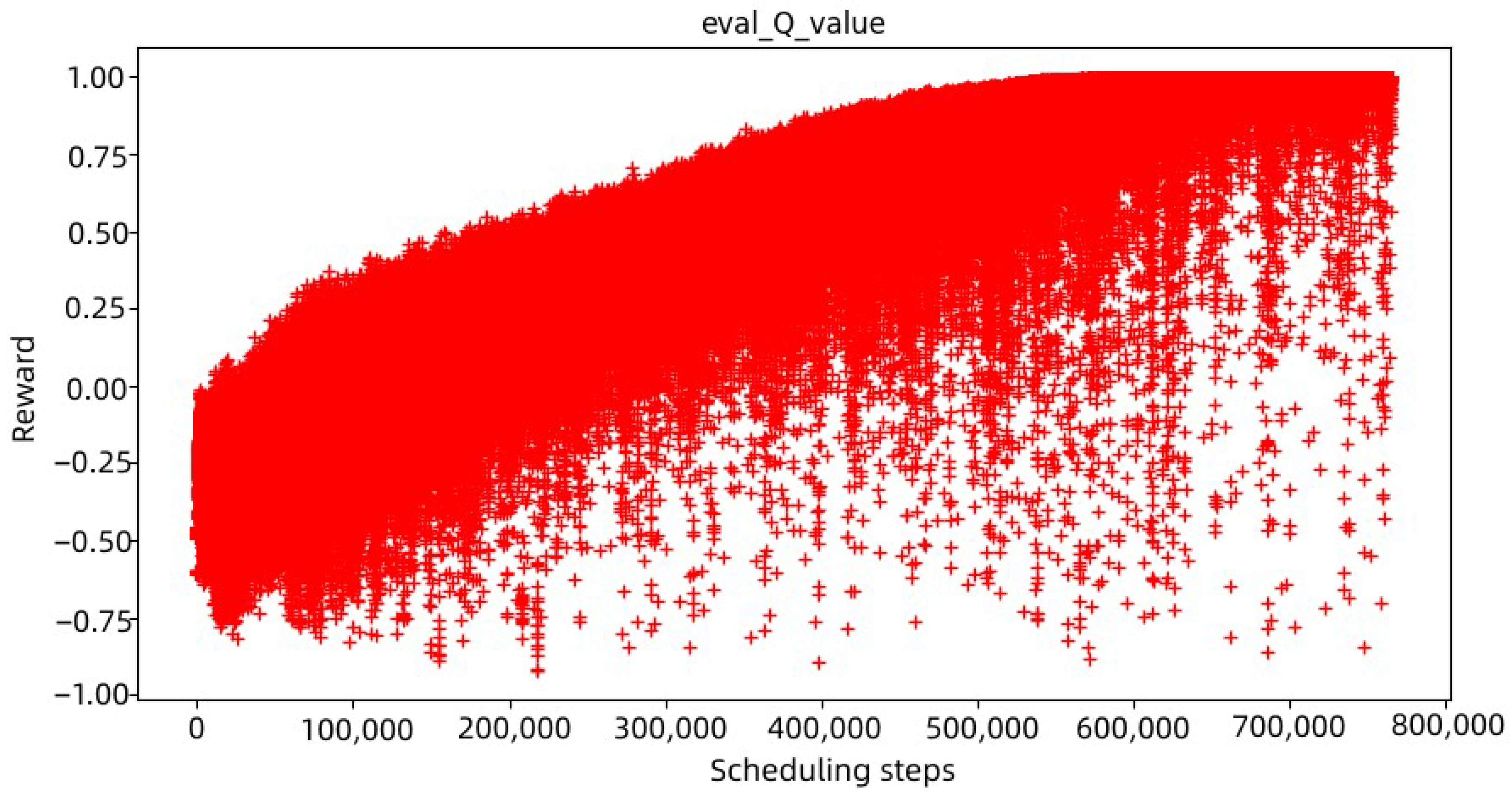
4.4. Analysis of Training Results of the Model
4.5. Analysis of Scheduling Results of the Model
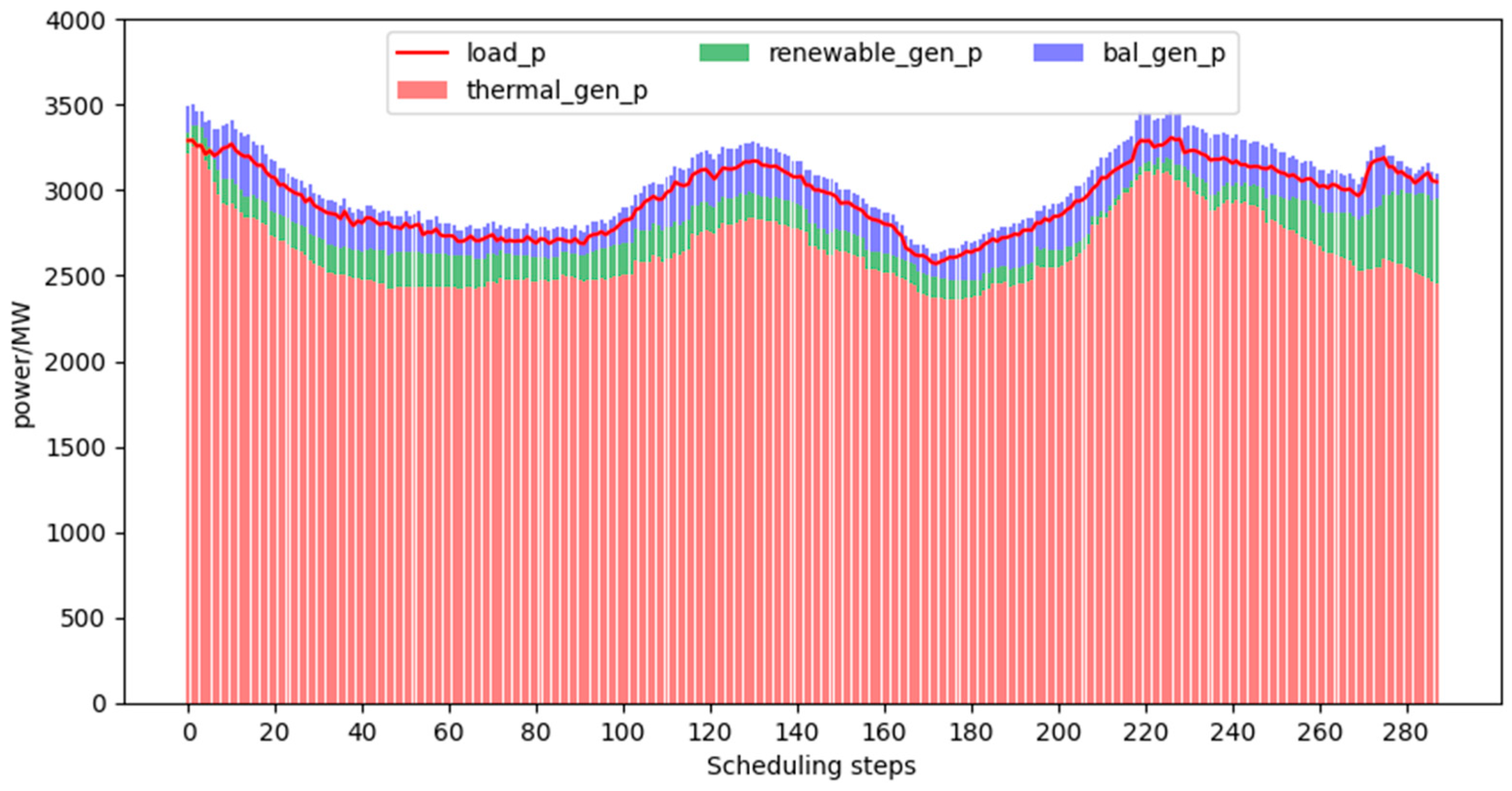
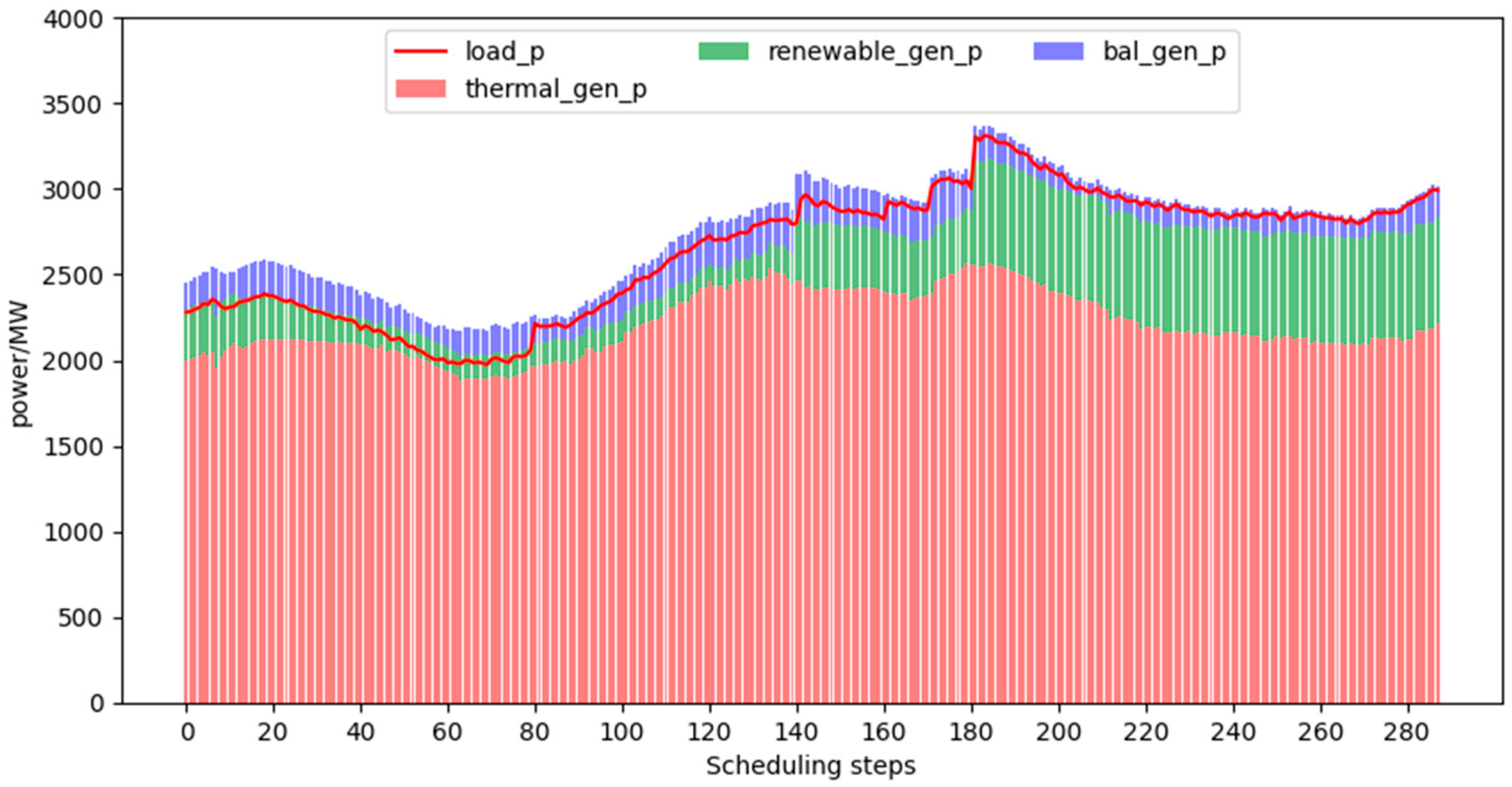
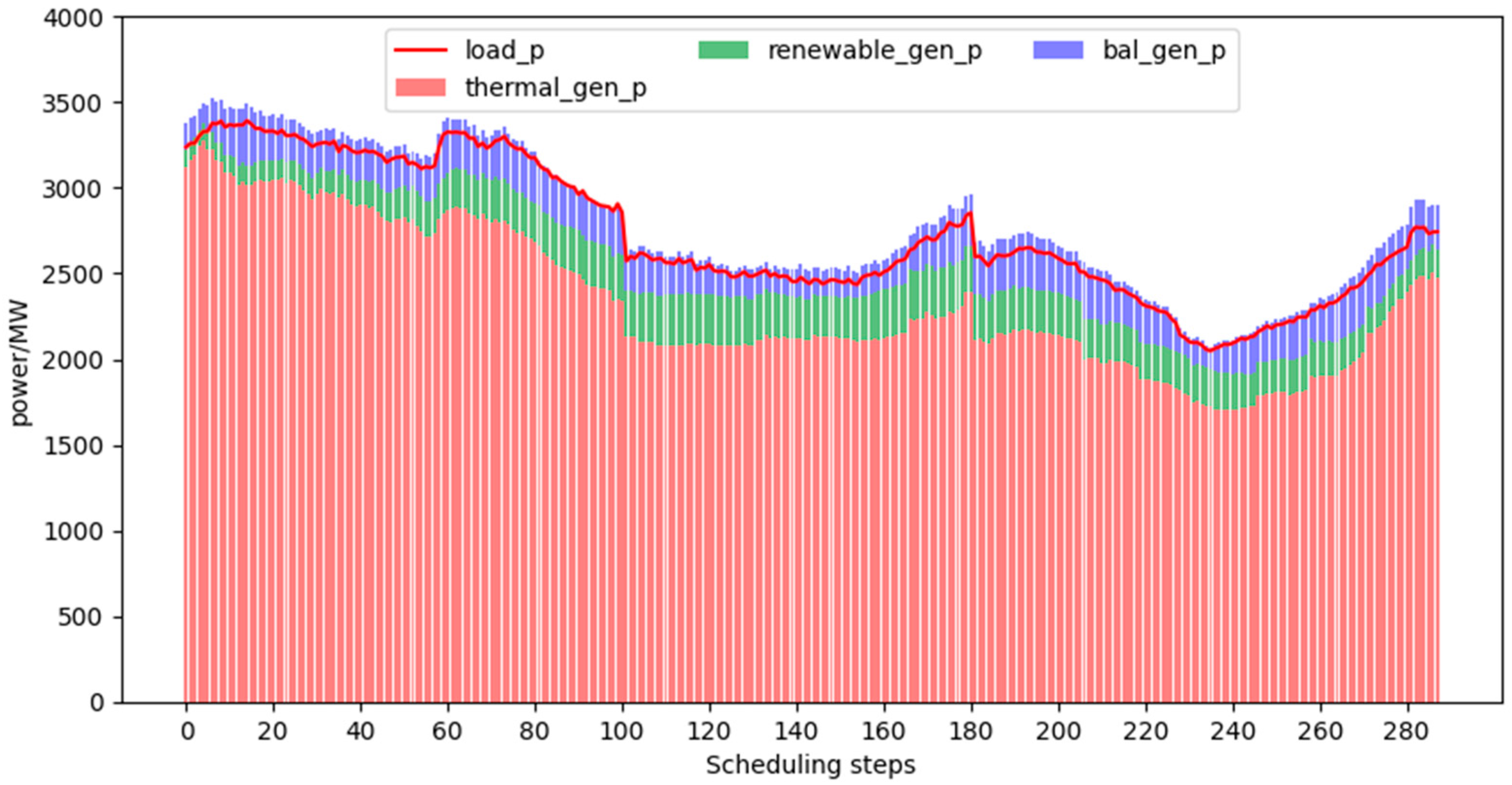
- Analysis of daily scheduling results:In the simulation analysis of this paper, a day is set as a scheduling cycle, with a scheduling policy every 5 min. A scheduling cycle provides 288 scheduling policies. The output of each unit in a scheduling cycle with different trends in total loads is shown in Figure 3, Figure 4 and Figure 5.Figure 3, Figure 4 and Figure 5 are obtained by the interaction between the scheduling strategy trained by the proximal policy optimization algorithm and the grid environment. As can be seen from the figure, under three different total load scenarios, the output of the balance unit meets the constraints and does not exceed the limit, thus ensuring the smooth operation of the power grid. The unit’s active power output and total load meet the power balance constraints. The variable output range of renewable units is large and the uncertainty is high, which increases the difficulty of scheduling the power system.
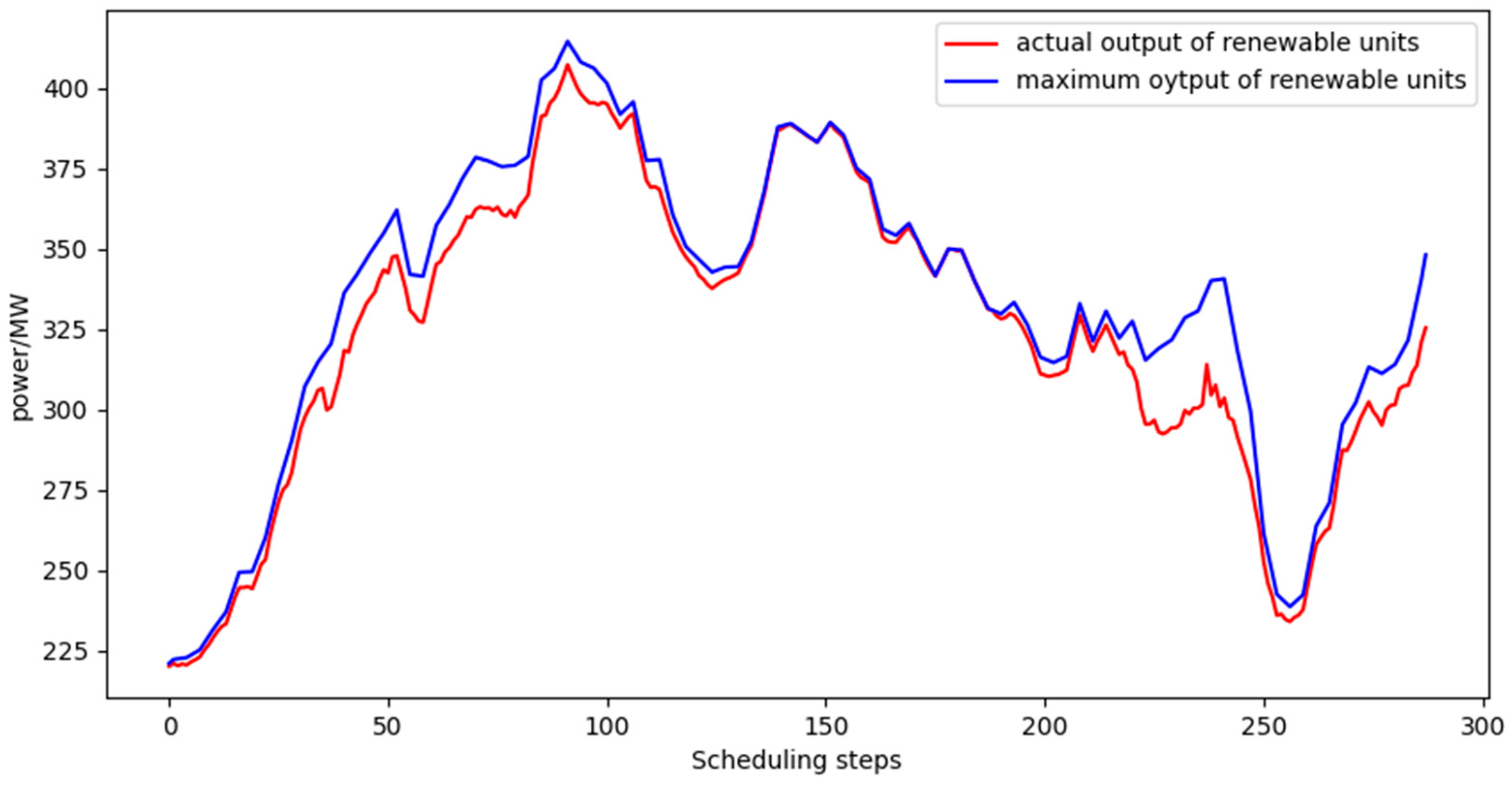
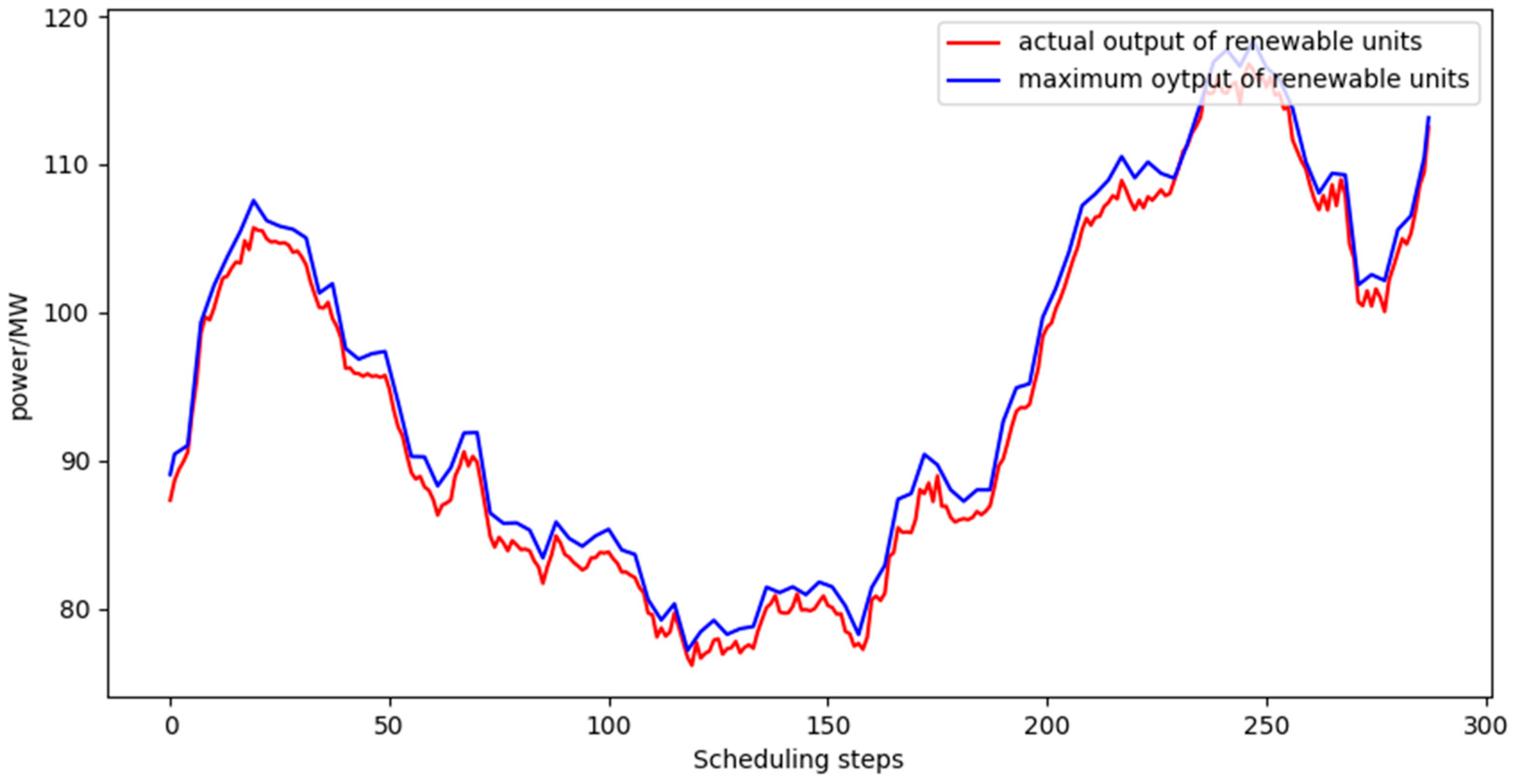
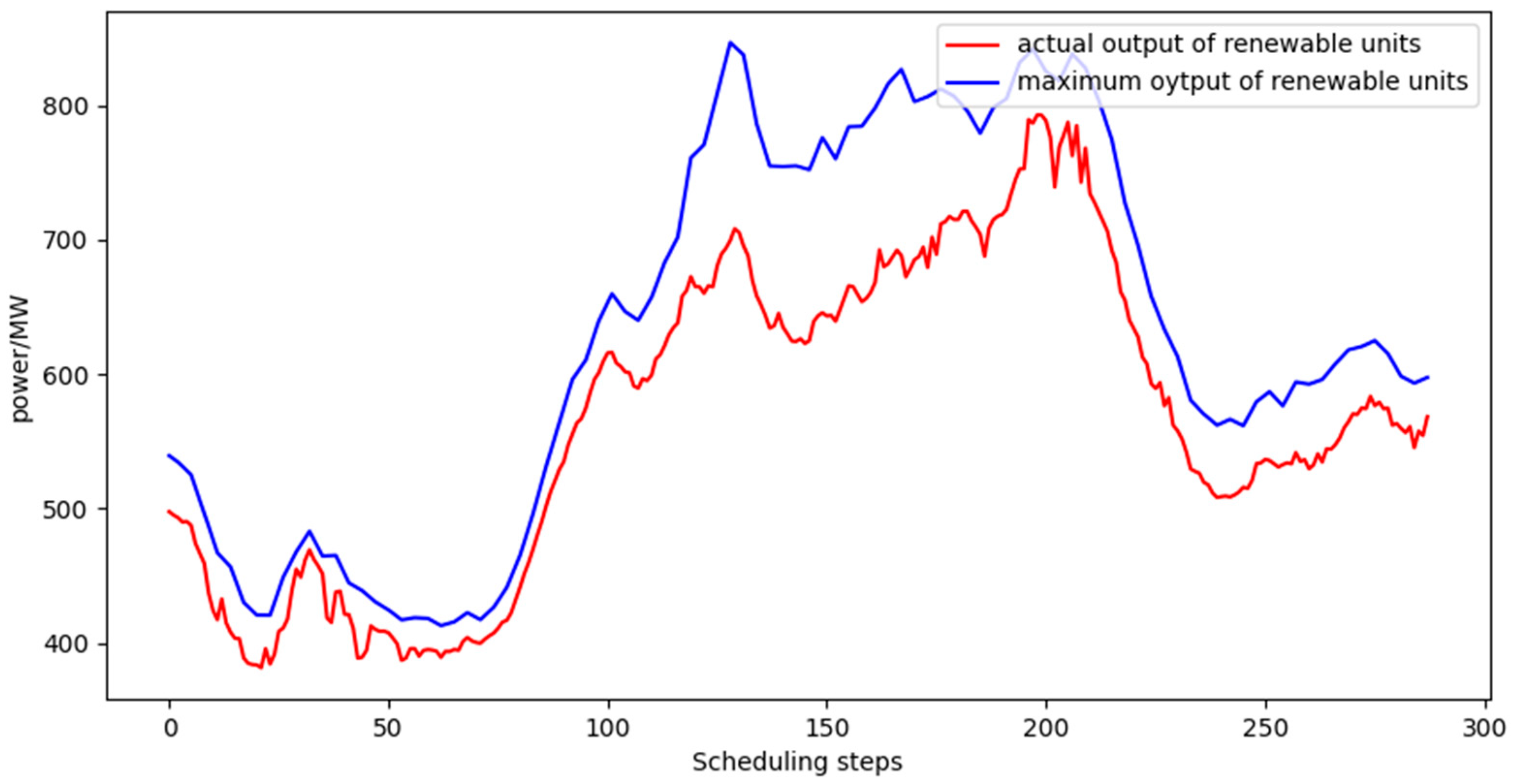
- Analysis of renewable energy consumption.The renewable energy consumption rate refers to the ratio of the actual electricity consumed by the generating unit in a dispatch cycle to the electricity generated in the current dispatch cycle. The renewable energy generation rate refers to the ratio of the current renewable energy generation electricity to the maximum generation electricity of the unit. Figure 6, Figure 7 and Figure 8 show the consumption of renewable energy in the three dispatch cycles with different renewable energy generation rates available. Table 2 shows the specific renewable energy generation rate and corresponding consumption rates. It can be seen that when the proportion of renewable energy generation is 19.8%, the consumption rate is high and can be effectively absorbed. When the proportion of renewable energy generation is 94.52%, the consumption rate is relatively low. Renewable energy must therefore be used carefully to reduce the impact of uncertainty on grid operation. The dispatch strategy can effectively absorb renewable energy on the premise of ensuring the safe operation of the power grid.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DRO | Distributionally Robust Optimization |
| DQN | Deep Q-Network |
| MDP | Markov Decision Process |
| PPO | Proximal Policy Optimization |
| KL | Kullback–Leibler |
References
- Bussar, C.; Stöcker, P.; Cai, Z.; Moraes, L., Jr.; Magnor, D.; Wiernes, P.; van Bracht, N.; Moser, A.; Sauer, D.U. Large-scale integration of renewable energies and impact on storage demand in a European renewable power system of 2050—Sensitivity study. J. Energy Storage 2016, 6, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Liu, S.; Bie, Z.; Wang, J. Renewable energy accommodation capability evaluation of power system with wind power and photovoltaic integration. IFAC-PapersOnLine 2018, 51, 55–60. [Google Scholar] [CrossRef]
- Albadi, M.H.; El-Saadany, E. Overview of wind power intermittency impacts on power systems. Electr. Power Syst. Res. 2010, 80, 627–632. [Google Scholar] [CrossRef]
- Roald, L.A.; Pozo, D.; Papavasiliou, A.; Molzahn, D.K.; Kazempour, J.; Conejo, A. Power systems optimization under uncertainty: A review of methods and applications. Electr. Power Syst. Res. 2023, 214, 108725. [Google Scholar] [CrossRef]
- Aien, M.; Hajebrahimi, A.; Fotuhi-Firuzabad, M. A comprehensive review on uncertainty modeling techniques in power system studies. Renew. Sustain. Energy Rev. 2016, 57, 1077–1089. [Google Scholar] [CrossRef]
- Alqurashi, A.; Etemadi, A.H.; Khodaei, A. Treatment of uncertainty for next generation power systems: State-of-the-art in stochastic optimization. Electr. Power Syst. Res. 2016, 141, 233–245. [Google Scholar] [CrossRef]
- Tang, C.; Xu, J.; Sun, Y.; Liu, J.; Li, X.; Ke, D.; Yang, J.; Peng, X. Look-ahead economic dispatch with adjustable confidence interval based on a truncated versatile distribution model for wind power. IEEE Trans. Power Syst. 2017, 33, 1755–1767. [Google Scholar] [CrossRef]
- Ma, M.; He, B.; Shen, R.; Wang, Y.; Wang, N. An adaptive interval power forecasting method for photovoltaic plant and its optimization. Sustain. Energy Technol. Assessments 2022, 52, 102360. [Google Scholar] [CrossRef]
- Nazari-Heris, M.; Mohammadi-Ivatloo, B. Application of robust optimization method to power system problems. In Classical and Recent Aspects of Power System Optimization; Elsevier: Amsterdam, The Netherlands, 2018; pp. 19–32. [Google Scholar]
- Xie, W.; Yi, Y.; Zhou, Z.; Wang, K. Data-driven stochastic optimization for power grids scheduling under high wind penetration. Energy Syst. 2020, 14, 41–65. [Google Scholar] [CrossRef]
- Mieth, R.; Dvorkin, Y. Data-driven distributionally robust optimal power flow for distribution systems. IEEE Control. Syst. Lett. 2018, 2, 363–368. [Google Scholar] [CrossRef] [Green Version]
- Cherukuri, A.; Cortés, J. Cooperative data-driven distributionally robust optimization. IEEE Trans. Autom. Control. 2019, 65, 4400–4407. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zhang, D.; Qiu, R.C. Deep reinforcement learning for power system applications: An overview. CSEE J. Power Energy Syst. 2019, 6, 213–225. [Google Scholar]
- Perera, A.; Kamalaruban, P. Applications of reinforcement learning in energy systems. Renew. Sustain. Energy Rev. 2021, 137, 110618. [Google Scholar] [CrossRef]
- Navin, N.K.; Sharma, R.; Malik, H. Solving nonconvex economic thermal power dispatch problem with multiple fuel system and valve point loading effect using fuzzy reinforcement learning. J. Intell. Fuzzy Syst. 2018, 35, 4921–4931. [Google Scholar] [CrossRef]
- Li, F.; Qin, J.; Kang, Y. Multi-agent system based distributed pattern search algorithm for non-convex economic load dispatch in smart grid. IEEE Trans. Power Syst. 2018, 34, 2093–2102. [Google Scholar] [CrossRef]
- Lu, Y.; Xiang, Y.; Huang, Y.; Yu, B.; Weng, L.; Liu, J. Deep reinforcement learning based optimal scheduling of active distribution system considering distributed generation, energy storage and flexible load. Energy 2023, 271, 127087. [Google Scholar] [CrossRef]
- Dong, J.; Wang, H.; Yang, J.; Lu, X.; Gao, L.; Zhou, X. Optimal scheduling framework of electricity-gas-heat integrated energy system based on asynchronous advantage actor-critic algorithm. IEEE Access 2021, 9, 139685–139696. [Google Scholar] [CrossRef]
- White, C.C., III; White, D.J. Markov decision processes. Eur. J. Oper. Res. 1989, 39, 1–16. [Google Scholar] [CrossRef]
- Hausknecht, M.; Stone, P. On-policy vs. off-policy updates for deep reinforcement learning. In Proceedings of the Deep Reinforcement Learning: Frontiers and Challenges, IJCAI 2016 Workshop, New York, NY, USA, 9–15 July 2016; AAAI Press: New York, NY, USA, 2016. [Google Scholar]
- Cao, D.; Hu, W.; Zhao, J.; Zhang, G.; Zhang, B.; Liu, Z.; Chen, Z.; Blaabjerg, F. Reinforcement learning and its applications in modern power and energy systems: A review. J. Mod. Power Syst. Clean Energy 2020, 8, 1029–1042. [Google Scholar] [CrossRef]
- Metelli, A.M.; Papini, M.; Faccio, F.; Restelli, M. Policy optimization via importance sampling. arXiv 2018, arXiv:1809.06098. [Google Scholar]
- Metelli, A.M.; Papini, M.; Montali, N.; Restelli, M. Importance sampling techniques for policy optimization. J. Mach. Learn. Res. 2020, 21, 5552–5626. [Google Scholar]
- Engstrom, L.; Ilyas, A.; Santurkar, S.; Tsipras, D.; Janoos, F.; Rudolph, L.; Madry, A. Implementation matters in deep policy gradients: A case study on ppo and trpo. arXiv 2020, arXiv:2005.12729. [Google Scholar]
- Liu, B.; Cai, Q.; Yang, Z.; Wang, Z. Neural trust region/proximal policy optimization attains globally optimal policy. arXiv 2019, arXiv:1906.10306. [Google Scholar]
- Wang, K.; Peng, H.; Zhao, M.; Guan, W. Collaborative exploration of multiple unmanned surface vessels in complex areas based on PPO algorithm. Journal of Physics: Conference Series. In Proceedings of the 2021 International Conference on Artificial Intelligence, Automation and Algorithms (AI2A 2021), Guilin, China, 23–25 July 2021; IOP Publishing: Bristol, UK, 2021; Volume 2003, p. 012017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Parameter Setting | Input Layer | First Hidden Layer | Second Hidden Layer | Third Hidden Layer | Output Layer | Learning Rate |
|---|---|---|---|---|---|---|
| Actor network | 348 | 512 | 512 | 256 | 54 | 0.0001 |
| Critic network | 402 | 512 | 512 | 256 | 1 | 0.00001 |
| Proportion of Renewable Energy Output | 19.8% | 50.09% | 94.52% |
| Renewable energy consumption | 98.5% | 96.3% | 90.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, J.; Zhang, W.; Wang, H.; Wei, W.; He, J. Research on Data-Driven Optimal Scheduling of Power System. Energies 2023, 16, 2926. https://doi.org/10.3390/en16062926
Luo J, Zhang W, Wang H, Wei W, He J. Research on Data-Driven Optimal Scheduling of Power System. Energies. 2023; 16(6):2926. https://doi.org/10.3390/en16062926
Chicago/Turabian StyleLuo, Jianxun, Wei Zhang, Hui Wang, Wenmiao Wei, and Jinpeng He. 2023. "Research on Data-Driven Optimal Scheduling of Power System" Energies 16, no. 6: 2926. https://doi.org/10.3390/en16062926