1. Introduction
Since the European Union (EU) created the Emission Trading System (EU ETS) in 2005 to combat climate change, it has become one of the cornerstones of the European environmental policy, with strong implications for industrial activities and repercussions that reach all economic and social sectors. Its main goal is to reduce greenhouse gas emission. It is supposed that companies producing carbon emissions must effectively manage associated costs by buying or selling rights to emit CO2, the so-called European Union Allowances (EUAs). The EU ETS is a cap-and-trade system, which includes only large stationary sources of emissions belonging to the most pollutant industrial sectors of the European economy (power plants, oil refineries, ferrous metallurgy, cement clinker or lime, glass—including glass fiber—ceramic products by firing, and pulp, paper and board).
Companies involved can either use EUAs to compensate their emissions or sell them to others that need them [
1]; they are allowed to trade emission allowances freely within the EU, so the system seeks to ensure that overall emissions are reduced, but also that cuts are made by those companies that can achieve the most efficient abatement costs [
2,
3].
Although the main EUA market goal was to give firms an incentive to move towards a less fossil fuel-intensive production, it also provides a new asset and new business development opportunities for financial intermediaries. Thus, current allowance prices, as well as the predicted EUA prices, are critical for companies, brokers, traders, and investors, and they can also affect decarbonization investment decisions [
4,
5,
6,
7]. Therefore, it may be stated that, although the market is designed to encourage decarbonization investments in the industrial sectors subject to the system, the consideration of emission allowances as financial assets introduces a new component that may complicate the market’s effectiveness in environmental terms.
Regarding the consideration of EUA as financial assets, it would be helpful to obtain short-term reliable forecasts, since agents involved in this market need to make quick buying and selling decisions in order to obtain maximum profitability [
8].
However, in terms of the environmental component underlying the market, agents involved in the decisions need to use a longer time horizon. For the system to work properly, the EUA market must provide information that incentivizes decarbonization decisions, even though investments in technological improvements or fuel substitution can take long payback periods. Therefore, incentives for decarbonization decisions must be credible and long-lasting, so that, rather than the information contained in the day-to-day fluctuation of prices, it is the trend of EUA prices that is of interest. In order to favor market stability and fulfillment of the objective of incentivizing decarbonization decisions by maintaining EUA prices, in 2019 the EU created a mechanism—the Market Stability Reserve (MSR)—with the aim of removing the excess of emission allowances that had generated the crisis since 2008. The MSR was designed to absorb excess EUAs in the short-term and to match the supply of EUAs in case of severe shortages in the long-term. However, EUA prices have risen sharply in the last years and this increase can hardly be explained by the purchasing needs of the companies included in the system, but rather by the arrival of other investors in the market, outside the polluting sectors, which are governed by objectives other than those initially set out in the EU ETS. In this case, we are talking about the behavior of EUAs as financial assets, whose price has shown not only rapid growth but also high volatility in the short-term.
The evolution of EUA prices has complicated the current economic situation, as their sharp rise has affected the costs of various sectors, causing significant increases in electricity prices. For example, the wholesale electricity market prices in Spain in September 2021 are three times higher than the year before. Although the cost of EUAs is not the only factor responsible for this price increase, according to some estimates [
9], in the case of Spain, around 20% of this increase would be related to the rise of CO
2 prices in the EU ETS. Other European markets have experienced an evolution of wholesale electricity prices very similar to the Spanish one. In this way, the energy price increase in Europe has become macroeconomically significant [
10]. Several factors, in addition to the CO
2 rising trend, are responsible for the rise of electricity prices: an increase of natural gas demand forced by higher demand of electric energy along with a decrease in renewable electricity production and a significant increase in coal prices. The pricing system in European (and other) electricity markets assumes that the price of electricity reflects the marginal production cost of the most expensive technology involved in generation. Therefore, fossil fuel power producers incorporate the price of EUAs into the marginal cost, passing on CO
2 prices into electricity prices and, where appropriate, incentivizing investment in renewable sources. The maintenance of high EUAs prices, although may be compatible with the environmental objective of the system and reinforce the incentives for decarbonization, can also lead to problems derived from the increase in costs in all sectors, including the loss of commercial competitiveness in Europe. In addition, the effects of higher electricity prices on consumers can be very significant, affecting different social classes in different ways. Therefore, prediction of the time evolution of EUA prices has become a fundamental tool for enterprises dealing with them, both for the short-term, to manage their day-to-day evolution—linked to its behavior as a financial asset—and the long-term, related to investments and decisions aimed at reducing the emission of greenhouse gases.
Prediction of EAU prices can be carried out by organizing them as times series so that tools usually used to carry out predictions in this field could be applied to obtain those future price predictions. It is generally accepted that economic variables follow nonlinear processes [
11]; non-linearity represents a major difficulty when modeling the dynamics of time series describing those economic (and financial) variables’ evolution [
12,
13]. To deal with those kinds of complex problems, classical linear forecasting tools such as ARIMA are used along with other forecasting tools in [
14] a Fourier Series Expansion optimized with Particle Swarm Optimization (PSO) was used to refine the predictions provided by a seasonal ARIMA to forecast electricity consumption, while in [
15] ARIMA was combined with Autoregressive Conditional Heteroscedasticity (ARCH) to forecast CO
2 emissions in Europe. The hybrid models clearly outperformed the basic ARIMA. Nevertheless, other forecasting tools which could provide more accurate predictions when dealing with a nonlinear behavior have been also used. The ARCH and Generalized ARCH (GARCH) models have proved very useful for financial time series analysis. Thus, they have been also used to forecast CO
2 allowance prices, sometimes without any other tool [
16], where a modification of its basic structure (fractionally integrated asymmetric power GARCH) is used, integrated into another forecasting model such as Markov chains [
4,
13] or by forming a hybrid model with other forecasting tool such as ARIMA [
15].
Despite the good results obtained by those models with some time series, the development of new forecasting tools based on artificial intelligence have driven many researchers to use them to forecast time series, as they are especially well suited to deal with the nonlinear behavior of complex series [
17]. In this work several forecasting tools were tested and Artificial Intelligence models clearly outperformed statistical ones such as ARIMA or GARCH in electricity price forecasting. Between them, Neural Networks (NN) have been widely used to forecast variables related to economy or energy, as they have been able to provide very accurate predictions. One of the most popular ones is the Multilayer Perceptron (MLP); it is one of the first neural models developed, and despite its simplicity, it has been widely used, as it is able to provide very accurate predictions of complex nonlinear time series. There are several fields where it has been used, such as forecasting of electric power transactions [
18], natural gas demand [
19], electric energy consumption [
20], stock market variables [
21,
22] or electricity prices [
23]. Despite its simplicity, MLP has been able to provide accurate and reliable predictions of different variables such as those mentioned above. In fact, it is able to provide predictions that are as good as those obtained with other more elaborated neural models and, indeed, to outperform some of them [
18]. They have been also used to forecast CO
2 emission allowance prices [
24,
25]. In [
24] it provided direct predictions of EUA prices while in [
25] it was combined with a mixed data sampling regression (MIDAS) to forecast carbon prices in a Chinese market with the help of several energy, weather and environmental variables. Nevertheless, MLP is not the only neural model usually used for time series forecasting. The development of new complex neural structures known as deep learning neural networks, so-called because of the high number of processing elements, has driven many researchers to use some of those structures to forecast time series [
17]. Long Short-Term Memory (LSTM) is one of such structures, as it has provided very accurate and reliable results when applied to carry out very complex data processing such as speech or text recognition, and they are able to analyze the time and contextual dependencies present in those problems. This is why they are supposed to be able to provide accurate predictions in time series forecasting; indeed, they have been used to predict electric energy load [
26,
27,
28] or electricity prices [
29]. In [
29] LSTM clearly outperformed ARIMA. In [
27] LSTM made up a hybrid model with VMD and a Genetic Algorithm, while in [
28] LSTM combined with Empirical Mode Decomposition (EMD) and information related to day similarity was able to provided better predictions than ARIMA, MLP and Support Vector Regression (SVR). Other Artificial Intelligence tools have been also used for time series forecasting such as Random Forest (RF), Gradient Boosting (GB) and Extreme Gradient Boosting (XGBoost) [
30] or SVR [
31], although neural networks are nowadays the preferred option because they are better suited for the time series forecasting problem. In fact, when comparing performances, neural networks usually outperform other forecasting tools, especially those known as statistical methods such as ARIMA [
20,
25,
27,
28,
29].
Although the forecasting tools described are able to provide accurate and reliable predictions when forecasting time series, a lot of work has been carried out in order to improve their performance by preprocessing available data. The aim is to modify the time series to provide several ones which could be more efficiently predicted or to extract information about the series time evolution that could help the forecasting tools to improve performance. The Empirical Mode Decomposition (EMD) decomposes a time series into a set of subseries, each one with a proper oscillatory behavior which is easier to predict; they are separately forecasted and then added to obtain the original series forecasting. This is a heuristic algorithm that suffers from a lack of mathematical theory supporting it, and to overcome this problem, the Variational Mode Decomposition has been developed. They both have been used with different forecasting tools such as LSTM [
27,
28], SVR [
31] or spiking neurons [
32]. A simplified version of those decomposition processes could be obtained by splitting the time series only into its trend and fluctuations. In this way two series are obtained: one describing the global trend of data and the other their seasonal and cyclic oscillations. It has provided good results when applied to electric consumption forecasting [
20] and also to EUA prices prediction [
33]. Another approximation to this decomposition is a regression algorithm that samples a dataset at different frequencies (MIDAS), which have been developed to deal with econometric series, and have been also applied to carbon prices forecasting [
25]. All these algorithms have provided good results, and it is not possible to select one as the best option, since they all have their pros and cons and selecting one or another depends on the problem at hand and the researcher’s own experience. In any case, preprocessing has become a fundamental step in the forecasting process, as many works have proved that it has improved the performance of forecasting tools when properly selected and applied to the time series to be predicted.
There are not many works devoted to forecast CO
2 prices [
24,
25,
32,
33]. Nevertheless, the increasing interest in environmental preservation and the influence that free auctioning of EUA has on the final price of electric energy have increased the interest of researchers in this field. Several works have appeared in which CO
2 allowance prices are predicted not only in Europe but also in other countries [
25,
31]. Most of them use neural networks tools along with some kind of preprocessing to carry out this task.
The aim of this work is to test several forecasting tools along with a proper preprocessing of data to provide accurate and robust predictions of 20 days ahead of carbon prices; usually, a one-day-ahead prediction is provided in most works. Nevertheless, multistep predictions could be potentially more interesting than those of one only data ahead because a more complete time evolution of the forecasted variable is provided. Despite this, there are few works that provide multistep predictions [
25,
33,
34]. So, in this work 20 future prices are provided each time a prediction is carried out. In this way, both short and long-term predictions are provided at once, so that this information could be valuable for both traders considering EUA as financial assets (who carry out shot-term buying and selling operations) and agents involved in decision-making related to decarbonization polices (who would prefer a long-term prediction of the price evolution).Two neural networks (MLP and LSTM) that have proved to be very accurate forecasting tools have been used. Another machine learning tool (XGBoost) has also been tested because, although it has been little used in time series forecasting, it has provided very good results in classification problems. Two preprocessing strategies have been tested to improve the prediction accuracy: the decomposition of the original time series into its trend and fluctuations components and the Empirical Mode Decomposition. The results obtained were analyzed to find out the structure providing the best performance. They showed that a proper preprocessing of data before being predicted by the forecasting tools clearly improves the prediction accuracy.
The paper is organized as follows:
Section 2 describes the models used to forecast future CO
2 prices along with the preprocessing algorithms, while
Section 3 describes the figures of merit used to measure the forecasting performance and the data preprocessing applied to the original time series to improve the forecasting models accuracy. Then, the simulation results obtained with the three models tested and the two preprocessing algorithms are described. In
Section 4, those results are compared, and the best performance identified. Finally,
Section 5 presents the conclusions.
3. Results
The time series used in this work is the daily spot price of a ton of CO
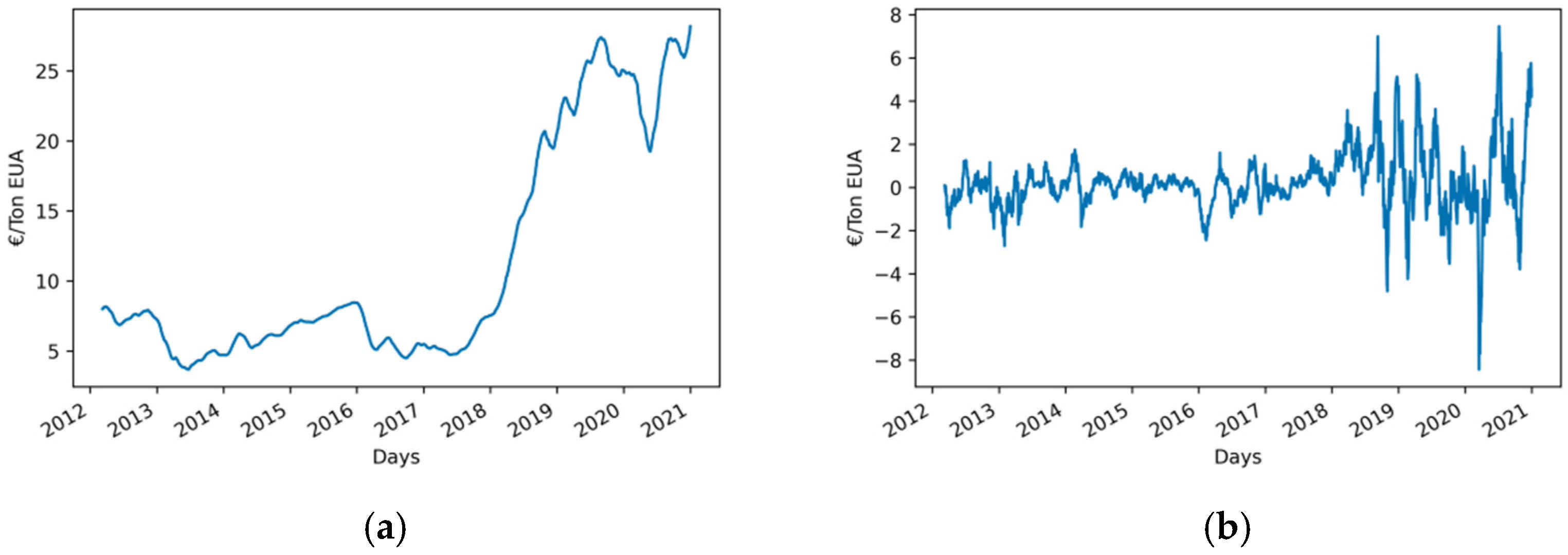
2 quoted on the European Energy Exchange (EEX) in Leipzig, Germany. It ranges from 14 October 2009 to 1 January 2021 with a total of 2890 data, as seen in
Figure 1. This plot shows two different behaviors of prices: a more or less soft evolution with medium and low values until 2018, and a clear rising trend with high values and steep variations after this year. They have been arranged into a time series to train and then validate the performance of the forecasting tools proposed in this work. Only past data of prices have been used to forecast future values.
It is usual in time series forecasting to use the first data (60–80% of them) to train the model and the remaining (40–20%) to validate its performance. Two of such possible divisions have been tested in this work: 60–40% (training-validation) and 80–20%. Training data will be used to learn the times series behavior by adjusting the model’s inner parameters. Once the forecasting tool (neural networks or XGBoost) is trained, the model so obtained is used to forecast with data from the validation dataset (the predictions obtained in this manner will be compared with the actual values of this dataset to obtain a measurement of the forecasting model accuracy).
Conversely, it should be taken into account that validation data with values significantly higher than those used for training and with steep variations (as those at the end of the time series) could jeopardize the accuracy of the forecasting models, as they have a behavior different from those used form training. To find out whether or not this behavior of the data worsens the performance of the forecasting models they will be also tested with a simpler dataset with a less steep evolution: the time series made up with data from 2009 to 2016, where validation data are similar to those used for training. In other words, the last data of the time series, those with higher values and steep variations, have been removed. The different forecasting structures defined in this work will be tested with both datasets and their corresponding performances compared.
The different behavior of both datasets may be better understood when statistical information describing their data distribution is provided. They may be seen in
Table 1 and
Table 2. The total number of data along their mean values, standard deviation, minimum and maximum values and the values defining each quartile are presented. From these data it may be concluded that the time series from 2009 to 2016 presents a more bonded behavior with lower fluctuations. Information regarding the scaled versions of both datasets (see below) is also provided.
The performance of predictions will be measured with two figures of merit: the Mean Absolute Percentage Error (MAPE) and the Root Mean Squared Error (RMSE):
where
Ai is an actual datum,
Fi a forecasted one and
N the total number of data predicted.
3.1. Data Scaling
The structure of the data shown in
Figure 1 suggests that it may be difficult for the forecasting tool to provide accurate predictions because a lot of extreme values appear. To overcome this problem, very common in both regression and classification problems, data were scaled before using them, that is to say, they were transformed into a new bounded dataset. In the programming environment used in this work, Python, there are two algorithms which are mainly used to carry out this task: normalization and standardization. The first one transforms the original dataset into another in which values are included in interval [
1]. There are several ways to do this, although in this work, the Min-Max one has been selected because of its simplicity:
where
represents the normalized datum,
the original one and
and
the maximum and minimum data in the original data set.
The second algorithm transforms the dataset into another one with zero mean and variations normalized to the standard deviation of data. This process is carried out with:
where
is the standardized datum,
the mean of the whole data set and
their standard deviation.
Both algorithms will be used with all the forecasting tools used in this work to find out which one provides the best performance. It is worth noting that a process opposite to that of scaling must be applied to the forecasted data. The corresponding expressions will be obtained by reversing Equations (21) and (22).
3.2. Model Simulation
In this work, three artificial intelligence forecasting models have been tested: two Neural Networks (MLP and LSTM) and a popular machine learning tool widely used to solve data science problems, XGBoost. Each model will be simulated with three different preprocessing scenarios: no preprocessing, trend-fluctuations, decomposition, and EMD.
The first preprocessing method consists of splitting the CO
2 emission allowance price series into two subseries (
Figure 2): its trend and fluctuations around it. They both will be independently forecasted, and their predictions added to obtain the predicted price.
In the second preprocessing model, the times series is split into eight stationary subseries (
Figure 3), IMFs, which are independently forecasted and then added.
Before preprocessing the dataset, it has been scaled with both Min-Max normalization and standardization. The whole sequence of the different actions carried out to perform forecasting is described in the flowchart presented in
Figure 4. As it may be seen, the process starts by scaling data and then splitting them into trend-fluctuations or IMF subseries, which are independently forecasted by each model. The predictions obtained are added to obtain the price predictions after rescaling the values provided by those summations. When data are not split, they are directly processed after scaled. This process is the same for both training and validation.
As pointed out above two datasets have been used: a simpler one, in which the data to be forecasted (validation subset) have a more or less stationary behavior, and the whole dataset, in which the data to be forecasted have values higher than those used for training with steep oscillations. The first defines a “simpler” problem without too extreme values and a “smooth” evolution. The second represents a harder problem with data with a different behavior from those used for training. The aim of defining two different scenarios is to check whether or not the forecasting models are able to provide good performances with both “easier” and “more difficult” problems of the same nature.
Regarding the two neural models, different numbers of layers and neurons in each one were tested. Nevertheless, structures with several hidden layers did not provide better performances than those with one only hidden layer. In fact, this last structure outperformed those with several ones. This is a hardly surprising fact for a MLP because, as pointed out above, an MLP with one hidden layer with enough neurons behaves as a universal approximator. The case of LSTM is different, as it is usually used with a high number of layers and neurons, making up what is known as a “deep learning” neural network. However, this structure is applied to very complex problems, such as text or speech processing. Forecasting time series, no matter how nonlinear it is, is a much simpler problem to deal with. Thus, it looks reasonable to accept that a LSTM with one only layer will be enough to obtain accurate predictions. Therefore, only the results obtained with one hidden layer are presented in this work. The best performance was obtained with 100 neurons in the hidden layer for MLP and 100 memory blocks with one only cell in each one for LSTM. In this last network, the depth of the time delays in feedback was 3. Higher values were also tested, but the effect of gradient explosion appeared.
As these neural networks (and XGBoost) carry out a process of time series forecasting, past data of prices are used to forecast future ones. Those past values (several data preceding those to be forecasted) are the inputs to the neural networks (and XGBoost). The number of past data which provides the most accurate predictions should be determined by trial and error; therefore, several numbers of inputs between 1 and 100 were tested with the three models for the two datasets used. For MLP, the best performances were obtained with 60 inputs for the reduced dataset and 3 for the whole one. For LSTM, the best results were obtained with 3 inputs for the 2 datasets.
Several structures were also tested for the XGBoost algorithm. The best results were obtained with 1000 trees with a tree depth of 3 and 3 inputs for the two datasets.
The three forecasting models predicted 20 data at once, that is to say, they provided forecasted values of the daily spot price of CO2 for the next 20 working days. So, the output layer of both MLP and LSTM has 20 neurons. This value was selected because it represents predictions for almost one month, four weeks, as the European Energy Exchange does not work at weekend days. The aim of providing 20 future values is to obtain both short-term and long-term predictions at once with one only forecasting model. The accuracy of the predictions (errors) will refer to that of 1 day ahead, 2 days ahead, and so on for the 20 predicted data.
All simulations have been programmed in Python with Tensor Flow and Keras packages. The XGBoost library for Python has been also used. The programs have been run in a personal computer with an Intel core i7-9700, 3.6 GHz with 32 Gbytes of RAM memory. Simulations have intensively used the GPU included in a RTX 2070 SUPER graphic card from Nvidia.
3.3. Prediction with MLP
The prediction errors (RMSE and MAPE) obtained with MLP are presented for both the simplified dataset and the whole one in
Table 3 and
Table 4. Several divisions of data for training and validation were tested and the best results were obtained with 60–40% for the first dataset and 80–20% for the second. This is hardly surprising, because the first one takes into account data with values similar to those to be forecasted in the training subset, nevertheless for the whole dataset a division of 60–40% does not consider data with a steep rising trend for training, while in that of 80–20% a lot of data with that behavior are used.
The results in
Table 3 show that the best performance was obtained when EMD was used to preprocess the reduced dataset. Nevertheless, although the best results were obtained with 60 inputs, a noticeable result was also obtained with a lower number of inputs (3): while the short-term horizon predictions are clearly improved those of the long-term ones got worse, providing a wider range of errors (as the higher standard deviation obtained shows). So, they both have been included in
Table 3 as structures providing the best performance. It is difficult to decide which of them is the most accurate; in fact, it becomes a matter of preference; it depends on which prediction horizon the user is interested in.
The results obtained when the whole dataset was used (
Table 4) show that, again, the best predictions were obtained when EMD was used to preprocess the input data. It is worth noting that these results were obtained, in all cases, with only 3 inputs.
When comparing the results obtained with the two datasets, it may be seen that those obtained with the whole dataset are worse than those obtained with the reduced one. Nevertheless, these worse results are not too high, and it may be stated that reliable predictions were obtained. This fact shows the robustness of MLP as a forecasting tool, as its performance has suffered only a slight worsening when dealing with more complex data. In addition, it only needed three inputs to provide those results with the whole dataset, a structure much simpler than that with 60 inputs for the reduced one.
3.4. Prediction with LSTM
Table 5 and
Table 6 show the results obtained with the two datasets used. The best results were obtained with a distribution training-validation 60–40% for the reduced data set and 80–20% for the whole one, a distribution equal to that obtained with MLP. Results in
Table 5 shows that now the best performance was obtained when no preprocessing was applied to the reduced dataset. The accuracy obtained when data were preprocessed by splitting them into trend and fluctuation was slightly better for the first two forecasted data than those without preprocessing, although they are clearly worse for the remaining ones. Data preprocessed with EMD provide clearly worse predictions than the option without preprocessing for short-term forecasting, although similar results were obtained for the long-term ones. When compared with the trend-fluctuations decomposition, it provides significantly worse results for short-term predictions, while providing better results for long-term ones.
Performances when the whole dataset was used are shown in
Table 6. Now the best accuracy was obtained with the trend-fluctuations preprocessing, although it was only slightly better than that obtained without preprocessing. It provides an accuracy only slightly worse than that obtained without preprocessing when the reduced dataset was used (the best option for that case), and clearly better for the last forecasted data when the same preprocessing process was applied to the reduced dataset. Nevertheless, the results obtained when the data were preprocessed with EMD are surprisingly poor, and what is more, long-term predictions are slightly better than short-term ones. They are much worse than those obtained with the reduced dataset. So, it may be stated that LSTM when EMD preprocessing was used has not been able to deal with the steep changes that appear at the end of the whole time series, while the structures without preprocessing and with trend-fluctuations decomposition were able to provide predictions that are only slightly worse that those obtained with the reduced dataset. This fact shows the robustness of LSTM with those two preprocessing models, as their performance suffers only a slightly worsen when a more complex time series is forecasted.
3.5. Prediction with XGBoost
The results obtained with XGBoost are shown in
Table 7 and
Table 8. The first one presents the results obtained with the reduced dataset with a 60–40% division for training and validation and the second those with the whole one and an 80–20% division. The best performance obtained with the reduced dataset (
Table 7) may be assumed as that provided by the model without preprocessing. Nevertheless, this statement demands a detailed explanation. The mean error of the twenty predictions is 8.54% for this model although that obtained with the EMD decomposition is 8.27%. However, the errors provided by this last model are almost constant for all predictions (as their very low standard deviation shows), while those obtained with the model without preprocessing are lower for the short-term predictions and higher for the long-term ones (higher standard deviation). This represents a more logical behavior of the forecasting tool, which provides a balanced evolution, since predictions get worse as the time horizon increases. But if the user considers-long-term predictions as more valuable than short-term ones, the best model should be that with EMD decomposition.
The predictions obtained with the whole dataset (
Table 8) are clearly worse that those obtained with the reduced one. The best performances were obtained with both the trend-fluctuation decomposition and without it, and it is surprising that the performance obtained with the EMD decomposition is especially bad. The errors are almost constant but with a so high value that it must be discarded as a forecasting model. When comparing the results obtained by the two datasets (only for no preprocessing and the trend-fluctuation decomposition) it may be seen that predictions get worse for the short-term remaining similar for the long-term. This means that XGBoost have problems to deal with a more complex dataset, at least in the short-term.
4. Discussion
When comparing the performance of the models simulated, it is clear that both MLP and LSTM outperform XGBoost in all cases. Only short-term predictions errors when no preprocessing and trend-fluctuations were used with the reduced dataset were similar to those of MLP or LSTM. For the whole dataset, errors are so high, especially in the case of EMD, that it may be stated that XGBoost is not a useful tool for forecasting this time series. This is not surprising if one bears in mind that XGBoots was designed to carry out classification tasks, so that it is not well suited for time series prediction. As it is proved in this work, XGBoost is not able to provide better results than other machine learning tools usually used in time series forecasting, such as the neural models used here.
Both MLP and LSTM were able to provide good predictions with the simplified dataset. In fact, very similar results were obtained when forecasting without preprocessing and when the trend-fluctuations were used: mean errors of 5.66% for MLP and 5.75% for LSTM without preprocessing and 6.39 and 6.70% for the trend-fluctuation preprocessing were obtained. This data also show that the accuracy of both models gets worse for the trend-fluctuations decomposition. Nevertheless, the performance of MLP is clearly improved when EMD is applied to the dataset (mean errors of 3.44 and 3.54%) while that of LSTM remains unchanged (mean error of 6.75%). As pointed out before, two structures have been tested with the MLP-EMD model because, although they provided almost equal mean errors, the time evolution of the prediction accuracies clearly differ: the structure with 3 inputs provides lower errors for short-term predictions, while that with 60 ones is better for long-term. From these results, it may be stated that the performance of MLP is clearly improved when EMD is applied, so that this structure provides the best performance of all the models tested with this dataset.
When the whole dataset is used, both MLP and LSTM provide similar results when no preprocessing was used (mean error of 6.25% for MLP and 6.64% for LSTM) and with the trend-fluctuations preprocessing (6.08 and 6.03%, respectively). However, their behavior clearly differs when preprocessed with EMD: while the mean error provided by MLP clearly decreases, providing a mean error of 4.44%, that obtained with LSTM undergoes a strong increase to 16.61%.
When comparing the results provided by MLP and LSTM with the two datasets, it may be seen that they are very similar, with a slight increase when no preprocessing was used (they pass from 5.66 and 5.75% for MLP and LSTM, respectively, with the reduced dataset to 6.25 and 6.64% with the whole one) and a slight decrease when trend-fluctuation was applied (6.39 and 6.70% to 6.08 and 6.03%).
These facts prove the robustness of MLP and LSTM when forecasting time series, as they are able to provide accurate prediction with both simpler and more complex time series providing that the training dataset is properly selected (the whole dataset was split into an 80–20% decomposition for the training-validation division instead of the 60–40% used for the reduced one).
Both MLP and LSTM are able to provide equally accurate predictions when they carry out forecasting directly, without preprocessing, achieving very similar errors. This common behavior changes when preprocessing is included. They both provide similar mean results when trend-fluctuations are included, although MLP behaves better for long-term predictions while LSTM does for short-term ones; but, for the reduced dataset, when EMD is included, MLP is able to improve its performance by decreasing its mean error to 3.44 and 3.54%, whereas LSTM is only able to provide a mean error almost equal to that obtained with trend-fluctuations (although now with worse errors for short-time predictions). This behavior is more striking for the whole data set, since while MLP clearly improves accuracy when EMD was applied (its mean error falls to 4.44%) LSTM undergoes a strong increase to 16.16% and, what is more striking, with all values very close to that mean.
Therefore, it may be stated that both MLP and LSTM are able to provide accurate and robust prediction when no preprocessing is included in the forecasting model, but when it is included MLP clearly improves its performance when EMD is used, whereas LSTM provides much worse results, in fact the worst ones achieved with the three options tested.
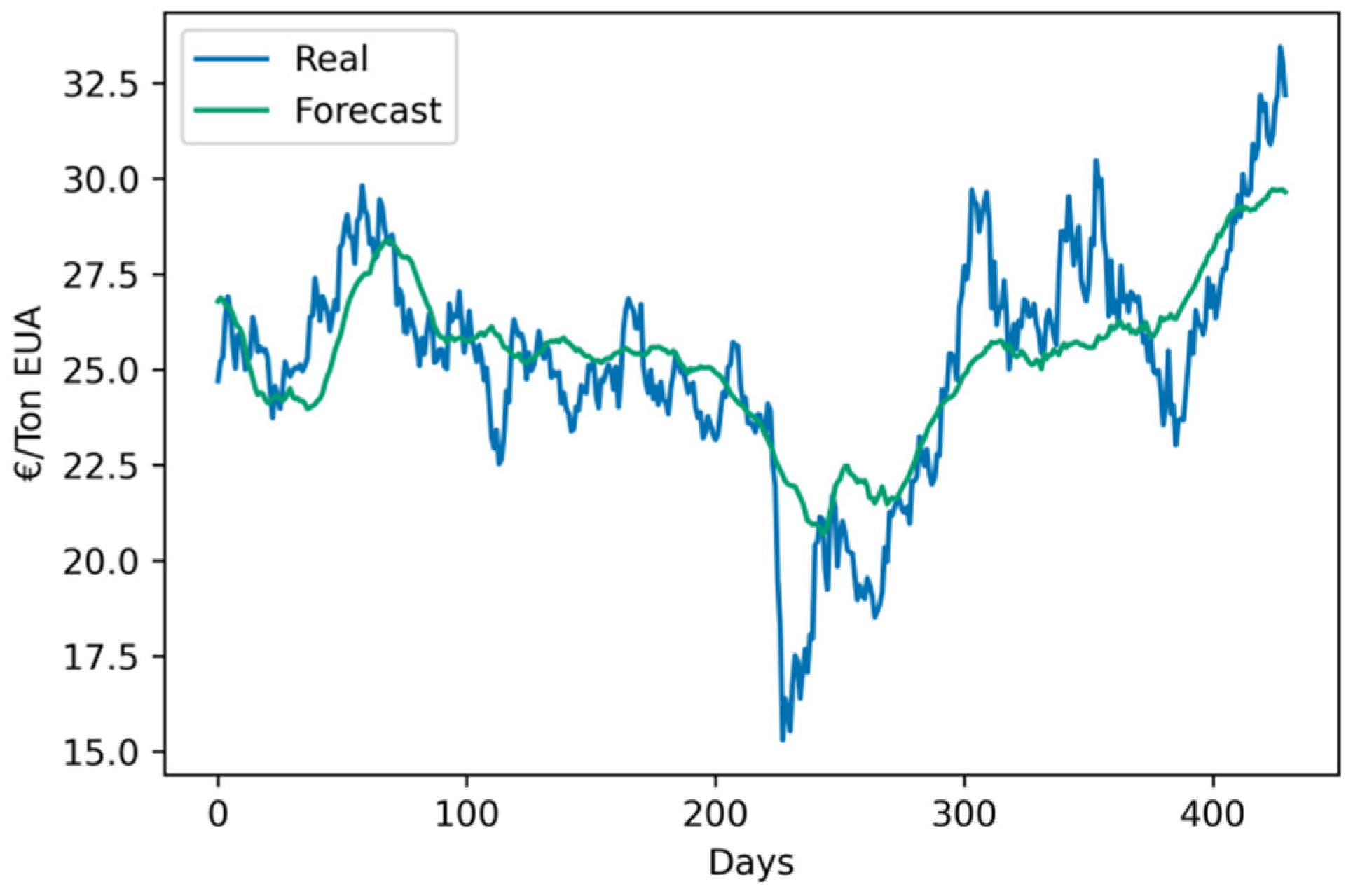
On the other hand, it may be very interesting to analyze the evolution of predictions regarding their time horizon in order to identify how they behave, and their accuracies evolve. To do that, the one-day-ahead and the twenty-days-ahead predictions obtained in the validation set of the whole dataset provided by MLP-EMD are presented in
Figure 5 and
Figure 6. It may be seen in
Figure 5 that one-day-ahead predictions are able to follow fluctuations of CO
2 price, providing a reliable estimation of its daily evolution. Nevertheless, predictions with a time horizon of 20 days, as seen in
Figure 6, are not able to follow daily fluctuations but, instead, they represent a sort of mean value of fluctuating prices, in other words, they provide a sort of trend of the time evolution of CO
2 prices. So, it could be stated that the model provides a prediction of the trend of the price evolution for the long-term instead of an estimation of actual prices on that time horizon. This behavior may be very useful for traders interested in the long-term evolution of prices because those predictions describe a sort of trend of how they will evolve.
This twofold behavior of the predicted data may be very useful, because it provides valuable information to agents involved in purchasing and selling EUAs. They can serve as a reference for managers of companies included in the EU ETS, as they can manage their allowances portfolio with reliable information to help them make decisions about their costs in the short-term. In addition, long-term forecasts may be very useful for managers of polluting companies, as they provide fairly tight predictions of the price evolution trend. The proposed model gives reliable trend information, with a time horizon that is more suitable for making decisions on decarbonization in production processes.
5. Conclusions
Forecasting daily spot prices of CO2 has become a key issue in recent years due to its upward trend that is affecting the final price of electricity. Several tools may be used to carry out this task, although Neural Networks seem to be the most reliable option, since they have proved to be one of the most accurate tools for time series forecasting. Nevertheless, not all models are able to provide accurate and reliable predictions and the best option for each particular time series should be identified by testing several ones. In this work, two popular neural models (MLP and LSTM) have been used to forecast the time series of daily spot prices of CO2. Another popular artificial intelligence tool (XGBoost) has been also used for the sake of comparison. It provided poor performance compared with those obtained with the neural models. Several works have proved that the prediction accuracy of the forecasting models may be significantly improved when a suitable data preprocessing is applied prior to carry out the forecasting process. Thus, in this work, two techniques have been tested, trend-fluctuation decomposition and EMD, to provide data preprocessing. The best results were obtained with a hybrid MLP-EMD model, which provided a significant decrease in the forecasting errors. However, several of the combinations tested were not able to overcome the corresponding single forecasting tool, providing, in some cases, significantly higher errors. The robustness of the proposed models has been tested by using two datasets: a simplified one with a soft evolution and an enlarged one that included updated data with a rising trend with steep variations. The combination of MLP-EMD was able to provide accurate and reliable predictions with them both. Only a small increase of forecasting errors with the enlarged dataset was obtained, a fact that proves the model to be a robust forecasting tool. It is worth noting that MLP clearly outperforms LSTM as a forecasting tool despite the fact that this last seems, at first glance, to be better fitted for time series forecasting because of its recurrent behavior and inner “memory”. In fact, MLP has proved to be a more accurate and robust forecasting tool. In addition, it has been able to take advantage of preprocessing techniques to improve accuracy while LSTM was not.
Therefore, an accurate and robust forecasting tool has been proposed to predict the time evolution of the daily spot price of CO2. Predictions for 20 working days (four weeks) are provided at once with good accuracy, as means error of 2.91 % for the nearest prediction (1 day ahead) and 5.65% for the furthest one (20 days ahead) were provided. Thus, it may be a very useful tool for enterprises selling and purchasing emission allowances as well as for electric energy trading companies, as the forecasting model presented in this work is able to provide reliable predictions of the time evolution of daily spot prices of CO2, what may help them to make decisions concerning their selling or purchasing activities.
On other hand, obtaining reliable allowance price predictions is important to market participants (such as affected companies, traders or brokers) who need accuracy price predictions to better manage their portfolios. Moreover, it is also crucial for the design of environmental policies, since CO2 emission allowance prices provide information on the marginal abatement costs in the industry. Thus, based on the evolution of prices, the effectiveness of the environmental policies can be evaluated and the emission cap adjusted. Therefore, a more accurate carbon price forecasting is essential to establish a stronger and more efficient emission market.
Based on the results presented in this work, we aim at carrying out further research to test the efficiency of preprocessing strategies different from those used here. Refinements of EMD such as Ensemble Empirical Mode Decomposition (EEMD) or Variational Mode Decomposition (VMD) could be applied and their performances compared with those obtained in this work. In addition, a study of different strategies to split data into training and validation sets based on cross-validation should also be carried out to try to define a model independent of the training-validation division dependence of accuracy pointed out in this work.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}