1. Introduction
With the aging of the population and the increasing awareness of public health care, people’s demands for medical and health services are becoming more and more frequent. With the increase in workload, the amount of information that doctors receive and need to call as the leader of medical services also increases exponentially, so it is very easy to cause medical deviations, such as missed diagnosis and misdiagnosis. Predicting the disease of a patient through an automatic diagnosis model can not only help the hospital to carry out the initial triage and guidance of patients, but also reduce errors in the process of clinical diagnosis, improve medical quality and work efficiency, and reduce medical costs [
1]. Meanwhile, In the vast majority of developing countries, due to the imbalance of urban development and the distribution of medical resources, there are great differences in the diagnosis level between doctors. Computer-aided or automatic diagnosis can effectively help patients with the disease early warning and chronic disease screening and reduce the difference in the diagnosis level of doctors [
2,
3].
Clinical electronic health records (EHR) are a document used by medical institutions to record patients’ condition, clinical treatment, guiding intervention process and final diagnosis and treatment results by means of informatization [
4]. In recent years, with the vigorous development of computer related technology, the use of data mining related technology for electronic medical record analysis has become a new direction. An important application of data mining in healthcare is disease prediction where the task is commonly formulated as learning a classifier that infers the prediction results from EHR [
5].
According to the number of diseases covered by disease prediction, it can be divided into single disease prediction and multi-disease prediction, corresponding to single label classification (SLC) and multi-label classification (MLC) in machine learning. SLC refers to the data to be classified as having only one category. According to the number of categories, it can be divided into single label two categories and single label multi categories. MLC refers to that each data to be classified belongs to multiple different category labels [
6]. In the medical field, a patient often suffers from multiple diseases (especially multiple chronic diseases) at the same time. Therefore, multi-disease prediction is of greater significance for patients’ early intervention and treatment, but there is no doubt that multi-disease prediction has higher requirements for data extraction ability and greater complexity of classification.
Existing multi-label learning algorithms can be divided into problem transformation (PT) and algorithm adaptation (AA) strategies [
7]. The PT strategy entails transforming MLC into a series of SLC problems, which can be solved using the existing single-label learning algorithm. PT strategy can be categorized into two schemes: binary relevance (BR) and label powerset (LP). The core of the BR scheme is to transform an MLC problem into multiple binary classification problems in which each binary classifier corresponds to a label to be classified [
8,
9]. As a conventional multi-label learning strategy, BR is relatively simple and easy to understand, but it completely ignores the correlation between labels, which makes it difficult to achieve the optimal performance of the model. To solve this problem, some scholars have proposed a classifier chain method, which connected constructed classifiers in series and considered the interaction between all tags [
10,
11]. However, as the number of tags to be classified increases, the number of classifiers constructed by such methods also increases. The LP scheme classifies any number of different label combinations as a new label to treat a problem as a single-label problem [
12]. During the classification, this scheme cannot consider the combination of tags that do not appear in the training set [
13]. In addition, because the new tags formed by the combination method are associated with only a limited number of instances, the data are very sparse or there is a serious imbalance phenomenon. Therefore, the LP scheme often has a poor application effect when the dataset is large or there are many tags.
The AA strategy entails optimizing and improving the existing single-label learning algorithm to form an improved algorithm or a new algorithm, which can be divided into probability model-based methods (e.g., the MFOM model based on a Bayesian algorithm [
14]), support vector machine (SVM)-based methods (e.g., Rank-SVM [
15]), decision tree (DT)-based methods (e.g., ML-DT [
16]), K-nearest neighbor (KNN)-based methods (e.g., ML-KNN [
10]), and ensemble learning-based methods (e.g., BoosTexer [
17]). With the further development of computer technology, some deep learning (DL) models have been applied to MLC to achieve certain results. For example, Nam J et al. [
18] regarded the MLC problem as the prediction of the target label sequence of the given original text and used a recurrent neural network (RNN) to generate label sequences in turn to obtain the correlation between labels; Yang P et al. [
19] improved the sequence generation model (SGM) through the disorder of set decoder to reduce the impact of error tags; Gong J et al. [
20] proposed a classification model based on a transformer, which captures text features through multilayer transformer structure and solved the MLC problem using the hierarchical relationship of labels. Some scholars employed a convolutional neural network (CNN) for text feature extraction and exploited cyclic neural networks in sequence data to generate label sequences [
21,
22]. Nowadays, deep learning has gradually become the mainstream method of text classification because of its strong text extraction ability [
23]. However, these algorithms still lack the ability to obtain the semantics of texts in a specialized domain, and it is difficult to capture the high-order correlation between tags only through the tags themselves [
6], which limits the performance of classifiers.
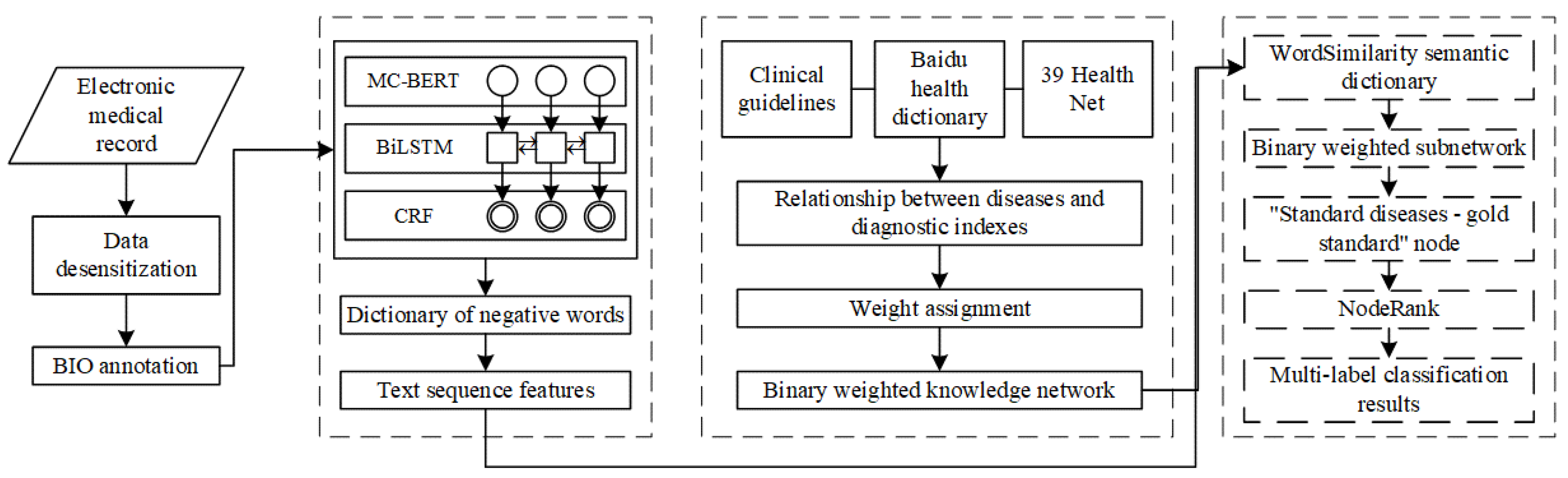
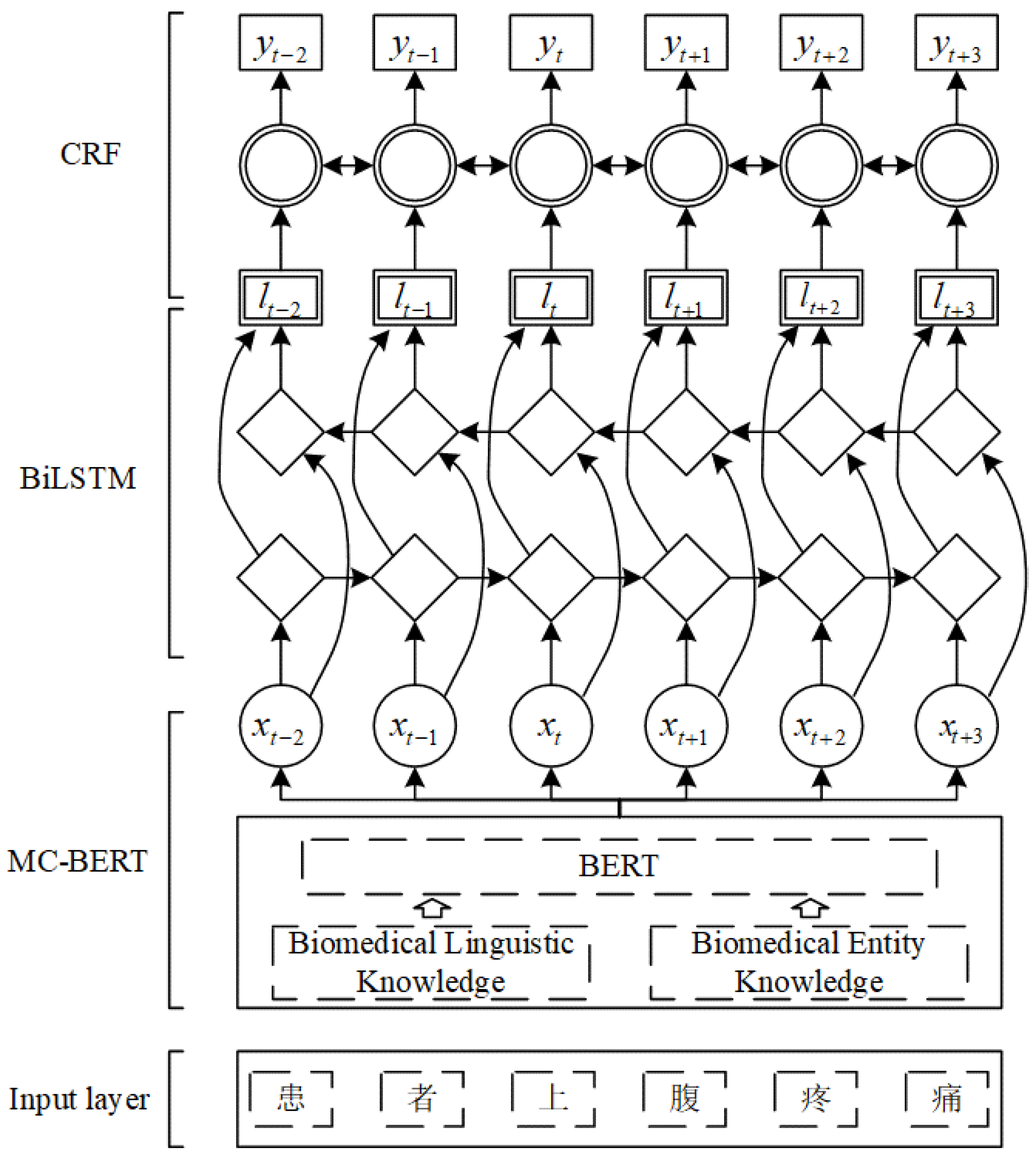
In summary, the existing research still has the following limitations: (1) the semantic extraction ability of professional text needs to be further strengthened; (2) in the process of classification, the correlation between tags is not fully considered. Based on this, we propose a novel disease prediction model DLKN-MLC. The contributions of this paper include the following: (1) The model extracts the information in EHR through deep learning combined with a disease knowledge network, quantifies the correlation between diseases through NodeRank, and completes multi-disease prediction; (2) we distinguished the importance of common disease symptoms, occasional disease symptoms and auxiliary examination results in the process of disease diagnosis.
The rest of the paper is organized as follows.
Section 2 describes the research datasets and the DLKN-MLC model. Experiments results and evaluation are presented in
Section 3.
Section 4 discusses the results of the model data experiment and comparative experiment.
Section 5 concludes the paper and recommends future works.
5. Conclusions
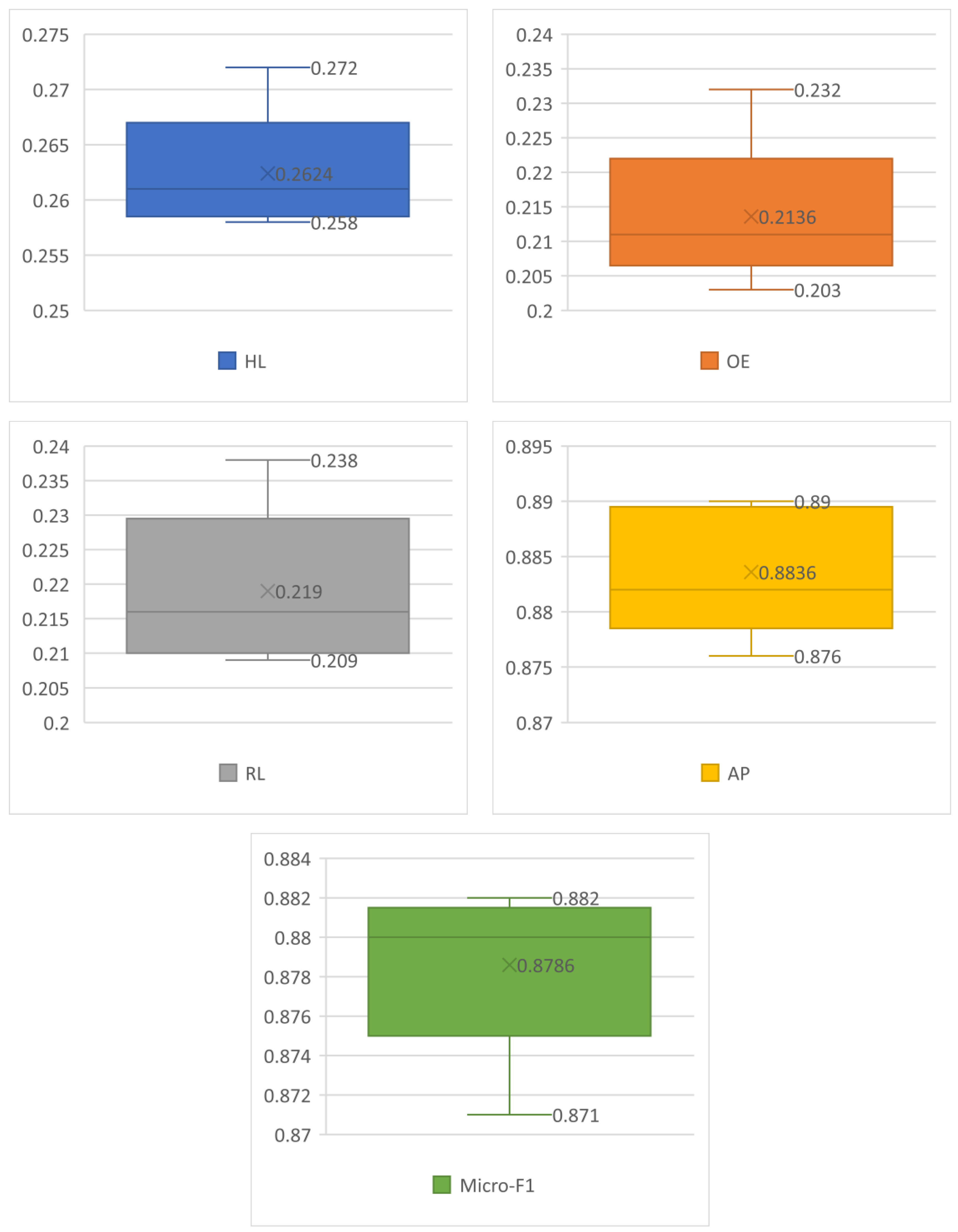
In conclusion, we proposed a novel disease prediction model based on a Chinese EHR named DLKN-MLC. The model extracts the features of EHR through the DL module, uses the binary-weighted KN to obtain the correlation between diseases, and then uses NodeRank to complete the final sorting classification. The results showed that the model could further improve the performance of disease prediction. We also verified the effectiveness and superiority of DLKN-MLC, which had certain methodological significance.
However, there are still some limitations in this paper: the DLKN-MLC model is discussed from the influence of different weighting values and the quality of model prediction, and the running cost and time efficiency of the model are not discussed. In future research, we will compare and analyze the complexity and running time of relevant models and consider using the public disease knowledge graph for auxiliary classification, so as to further enhance the correlation between diseases.








{kind=link}
{kind=link}
{kind=link}
{kind=link}