1. Introduction
Remote desktops, which are essential in various sectors such as cloud computing and wireless sensor networks [
1], face challenges with the growth of display resolutions. For instance, a 4K resolution desktop image, uncompressed, demands about 23.73 MB per frame. At 60 Hz, this equates to a bandwidth of roughly 1.39 GB/s. Such high bandwidth consumption can degrade user experience. VNC (Virtual Network Console), a popular remote desktop tool, uses the RFB (Remote Frame Buffer) protocol with its tight encoding mode employing JPEG for image compression. This approach conserves bandwidth. However, JPEG’s fixed parameters in its discrete cosine transform may not always suit the image’s features. Moreover, its block processing can introduce block effects and artifacts.
Some researchers have proposed different solutions for desktop image processing methods in remote desktop application scenarios. Lin et al. proposed a composite image compression algorithm specifically for remote desktop image transmission [
2]. This algorithm uses a method similar to the block partitioning of desktop images in the JPEG compression algorithm. On this basis, the algorithm divides the text and graphics in the blocks and uses different compression methods for them than for images. For text and graphics, the color values can be indexed and compressed based on the index for text and graphics areas, while for areas with complex color information such as images, the JPEG compression algorithm is used for compression. However, this method still does not solve the shadow and blur problems caused by the JPEG compression algorithm for desktop images under low-quality parameters. Wang et al. proposed a composite image compression method and joint coding (UC) based on several effective text/graphics and natural image compression algorithms [
3,
4]. This method mainly uses lossy intra-frame hybrid coding tools or their variants to compress natural images, while for text/graphics, it mainly uses dictionary entropy coding, run-length coding (RLE) in the RFB protocol, Hextile in the RFB protocol, and PNG and other encoding tools as candidates for text/graphics compression. By appropriately combining these lossless tools with intra-frame hybrid coding, high compression performance is achieved for the text/graphics part of the composite image. This method uses an optimizer based on rate–distortion cost to separate natural images and text/graphics, and finally selects lossy and lossless coding tools for encoding, respectively. However, this desktop image coding scheme still has some drawbacks. Firstly, the image to be encoded needs to be divided into small pixel blocks. Secondly, iterative selection is required for different block coding, which may affect the real-time performance of image coding. Lastly, the support for high-resolution images is not good enough, which cannot adapt well to the current era of high-resolution desktop images.
Several researchers have optimized desktop image coding methods for specific remote desktop usage scenarios. Sazawa et al. proposed a desktop image coding scheme for engineering applications such as 2D-CAD and CAE: Remote Virtual Environment Computing (RVEC) [
5]. RVEC combines movie compression and compression algorithms with small static image loss, which greatly reduces the bandwidth of image transmission without compromising the acceptable engineering standards. In addition, RVEC uses a new lossless compression algorithm, the graphic compression algorithm, to compress static images applied to graphics. The graphic compression algorithm uses vector features in the displayed image to obtain better compression ratios without affecting the compression speed. Shimada et al. later proposed a high-compression method for graphic images in 3D-CAD, CAE software, and other engineering applications based on Sazawa’s research [
6]. This method uses the characteristic that the pixel values in artificial images do not change locally and extracts constant gradients through frequency transformation, fully utilizing the characteristics of graphic images. It provides reasonable actual compression time, compression size, and image quality for engineering applications in cloud environments. However, although the image coding scheme proposed by Sazawa, Shimada, and others performs well in the field of engineering applications, it is not universal and therefore difficult to apply to general remote desktop usage scenarios.
Deep learning’s advancements [
7] offer promising applications in image processing. Its ability to discern image features can reduce data redundancy, optimizing bandwidth for remote desktop transmission. Given that users focus on specific desktop areas, deep learning can enhance the reconstruction of text and graphics, improving visual experience.
Deep learning-based image compression methods have been proposed, showing performance approaching or surpassing traditional methods [
8]. This potential paves the way for its application in remote desktop image transmission. This paper focuses on constructing an algorithm that is more suitable for remote desktops, replicating the method proposed by Ballé et al. [
9], with Mean Squared Error (MSE) as the optimization target. Despite optimizing Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity (SSIM) of images [
10], this method presents some limitations [
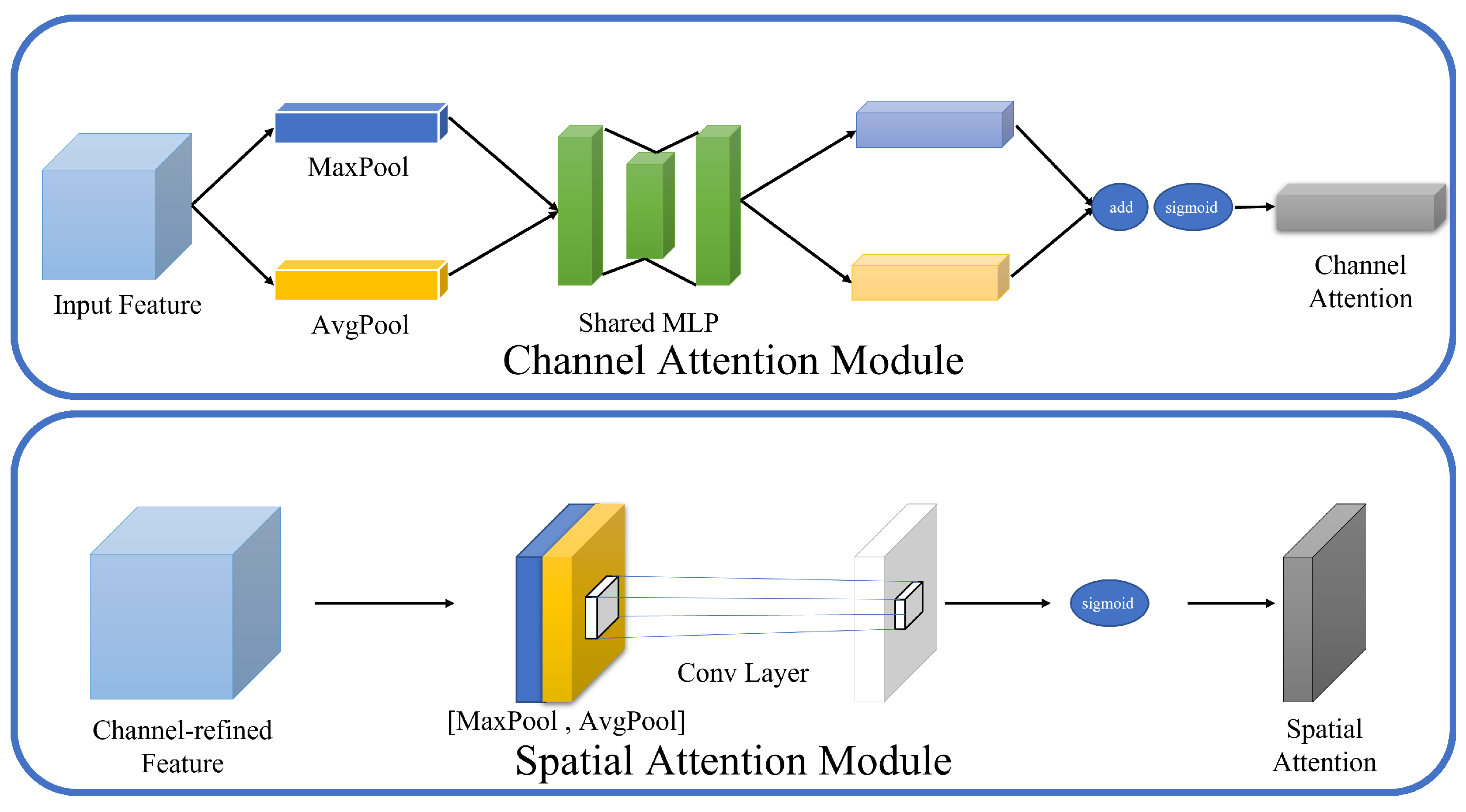
11]. Considering the importance of users’ subjective perception of desktop image quality in performance evaluation, this paper introduces Multi-Scale Structural Similarity (MS-SSIM) as an additional optimization target. Moreover, an adaptive attention mechanism module is introduced, combining spatial and channel attention, which serves as an image encoder enhancement module, applying attention weights to the latent representations of images [
12,
13,
14,
15]. Subsequently, this paper improves the existing RFB protocol based on this image compression algorithm, introducing a novel encoding method. This approach employs a convolutional neural network-based image compression technique as its core method for encoding images. Experimental results indicate that the enhanced RFB protocol proposed in this paper can reduce the bandwidth consumption for remote desktop usage by 30–80% without compromising the adequacy of remote desktop image transmission.
Compared to the preliminary conference version of the paper [
16], this work has expanded on it by designing protocols based on the input–output characteristics of the CNN model to enable its application in remote desktops. In this work, several different processing approaches are introduced to maximize the improvement in image transmission efficiency of the optimized RFB protocol, while ensuring a balance between bandwidth consumption and hardware performance. Ultimately, this paper demonstrates the effectiveness of our proposed optimized RFB protocol—significantly reducing bandwidth consumption in remote desktops while enhancing the quality of transmitted desktop images.
The remainder of this paper is organized as follows:
Section 2 reviews related work, while
Section 3 analyzes the differences between various image quality assessment methods.
Section 4 introduces the image compression techniques employed in the improved RFB protocol proposed in this paper.
Section 5 details the proposed improved RFB protocol.
Section 6 presents the experimental results and analysis, and
Section 7 offers conclusions.
2. Related Works
In the domain of remote desktop technologies, significant progress has been made in optimizing the performance and efficiency of transmission protocols, particularly focusing on encoding strategies and virtualization enhancements. A notable contribution in this field is the work by Halim [
17], which presents a detailed framework for evaluating the encoding performance in remote desktop systems, with a specific focus on the TigerVNC protocol. This analysis is crucial as it provides insights into the optimization of image transmission, which is a key factor in remote desktop interactions. Complementing this, the study by Li et al. [
18] investigates the enhancement of service transportation in cloud-based virtual desktop infrastructures. Their research sheds light on the integral role of video encoding and compression algorithms in improving the overall efficiency and performance of virtual desktop systems. Both studies collectively offer a comprehensive understanding of the current advancements and challenges in remote desktop protocol technologies, underlining the importance of continuous innovation in this rapidly evolving field.
Most image compression methods based on deep learning are lossy image compression methods [
19]. Due to the robust modeling capabilities of deep learning, these algorithms have gradually approached or even surpassed the performance of traditional image compression methods. Currently, the primary deep learning-based image compression techniques involve the integration of convolutional neural networks (CNNs), recurrent neural networks (RNNs), and generative adversarial networks (GANs). CNNs, in particular, have seen rapid development in image processing, excelling in tasks such as object detection, image classification, and semantic segmentation. The sparse connectivity and parameter sharing properties of CNN convolution operations have demonstrated advantages in image compression.
In 2016, Ballé et al. [
20] introduced a parametric nonlinear model for Gaussianizing data derived from natural images. Their primary contribution was the development of a normalization layer—the Generalized Divisive Normalization (GDN) layer—optimized for image compression and reconstruction tasks. This layer effectively reduces random noise introduced by traditional Batch Normalization (BN) layers. Later, Ballé et al. [
21] proposed an image compression technique based on nonlinear transformation and uniform quantization. This approach leverages a CNN to extract latent feature representations from images and implements local gain via the previously proposed GDN layer to reduce additive noise. This marked the first integration of CNNs with image compression techniques, establishing a foundation for the development of end-to-end CNN-based image compression methods. Subsequently, Ballé et al. [
9] introduced an end-to-end image compression model that integrates hyperprior encoders with decoders. This model effectively captures spatial dependencies within latent feature representations and eliminates redundancy via Gaussian distribution modeling, resulting in lower bit-rate image compression. Jiang et al. [
22] introduced an end-to-end CNN-based image compression encoder–decoder. This approach utilizes a neural network in conjunction with traditional image processing techniques to process images. Initially, a CNN-based image encoder is employed to extract a compact representation of the image, effectively shrinking the original image along its height and width dimensions. Subsequently, traditional image compression methods (e.g., JPEG or BPG) are utilized to encode this compact representation of the image. At the decoding stage, traditional image compression encoding is first applied to restore the compact representation of the image. Then, a CNN-based image decoder is used to scale up this compact representation and restore it back into its original form as an image. Zhao et al. [
23] argued that integrating traditional forms of image compression may not be optimal for deep learning-based approaches to this task. As such, they proposed a method that employs a virtual encoder to connect the encoding and decoding stages during training. This virtual encoder—also based on CNNs—can directly map compact representations onto image code streams transmitted to the decoding stage via nonlinear mapping. This approach effectively links neural network-based encoding and decoding stages and can be integrated with traditional encoders to produce high-quality reconstructed images. It can also be extended to other end-to-end CNN-based image compression architectures. To enhance the quality of reconstructed images, Liu et al. [
22] introduced a decoding stage enhancement module capable of learning residual information between reconstructed and original images via neural networks. By leveraging this residual information to improve decoding performance, the module further enhances the quality of images reconstructed by decoders.
3. Algorithm for Remote Desktop Image and Compression Quality Evaluation
Image compression algorithms are typically evaluated by applying image quality standards to measure the extent of quality degradation after compression. These evaluation techniques can be categorized into subjective and objective assessments. Subjective assessment involves viewer-based scoring, wherein several evaluators grade the reconstructed image against the original one, with the mean score serving as the final evaluation. In contrast, objective assessment calculates the differences between images using mathematical models. Although subjective assessments are time-consuming and affected by numerous factors, objective assessments offer automated scoring that is not influenced by viewer bias.
Common objective image quality metrics include Peak Signal-to-Noise Ratio (PSNR), which is widely used in the field of image and video processing. PSNR, calculated conveniently through Mean Squared Error (MSE), quantifies image distortion. The computation equation for MSE is presented in Equation (
1), and substituting it into Equation (
2) gives the PSNR value for an image, where n represents the number of pixels in the image.
In optimizing the quality of reconstructed desktop images, the Mean Squared Error (MSE) method presents certain limitations. MSE, offering equal weight to all pixels, may not aptly assess reconstructed desktop images. Even with identical MSEs, perceptual differences between images can be significant, indicating that the Peak Signal-to-Noise Ratio (PSNR) derived from MSE may not accurately represent human perception. When viewing desktop images, the human eye often concentrates on specific work areas and is more sensitive to noise in these sections than in other areas. Furthermore, the human eye has greater sensitivity to luminance than color, a facet overlooked when merely calculating MSE between the reconstructed image and the original. In contrast, the Structural Similarity Index (SSIM) estimates luminance similarity, contrast, and structure similarity between two images by calculating their means, variance, and covariance. Equations (
3), (
4) and (
5), respectively, represent the calculations for luminance similarity, contrast, and structure similarity.
Here,
,
,
with
,
, and
, where
B denotes the pixel depth of the image. The structural similarity between the distorted and original images can be calculated by substituting Equations (
3)–(
5) into Equation (
6), with
. Optimal performance of structural similarity requires specific configuration. In contrast, Multi-Scale Structural Similarity (MS-SSIM) calculates the degree of structural similarity at different scales between the distorted and original images through multiple low-pass filtering and downsampling processes, maintaining good performance across different image resolutions. Equation (
7) describes the calculation of structural similarity at multiple scales, where
and
.
This study aims to optimize the performance of end-to-end image compression models using Mean Squared Error (MSE) combined with Multi-Scale Structural Similarity (MS-SSIM) as the loss function. By disregarding the quality of monotonic or non-working areas that are less relevant to human perception, we ensure a more complete preservation of image information in the working area of the reconstructed desktop image, thereby enhancing the comprehensive performance of the proposed method in the field of desktop image compression.
6. Experiments and Analysis
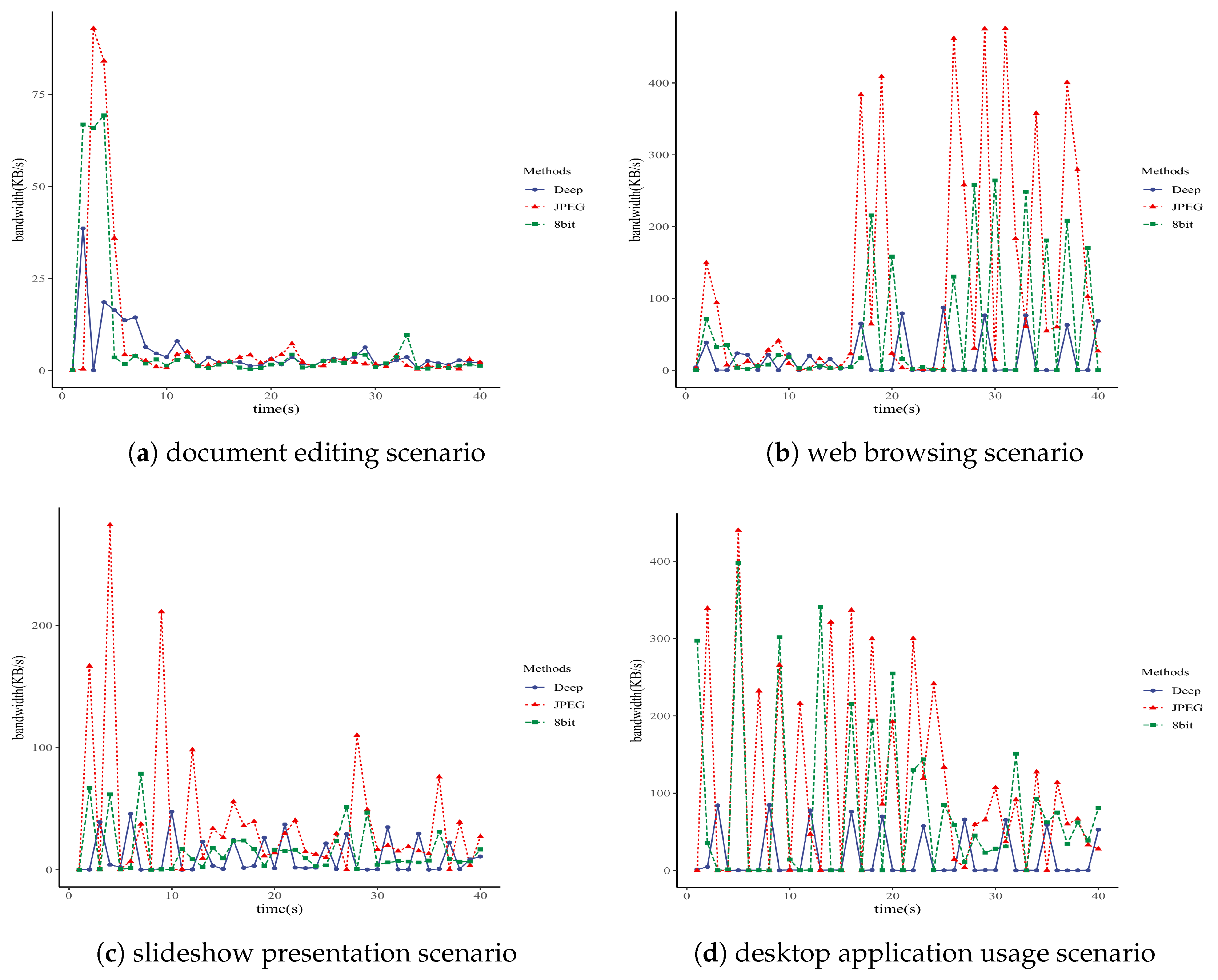
In this paper, the remote desktop clients used in the experiments were deployed on two Windows 10 computers with x86 architecture, equipped with Intel i9-10900 CPUs and 64GB of memory. This experiment analyzed bandwidth-time curves for three RFB protocol encoding methods: DeepTight encoding based on deep image compression, Tight encoding using the JPEG image compression algorithm, and the 8-bit mode provided by VNC. The
Figure 4 show that, in the same scenarios, the DeepTight encoding proposed in this paper consumed less network bandwidth than the other two low-bandwidth encoding methods available in VNC for most of the time.
Table 5 lists detailed bandwidth data for these three encoding methods in scenarios such as document editing, web browsing, slideshow presentation, and desktop application usage. The data reveals that, across all four scenarios, DeepTight encoding uses less average and peak bandwidth compared to the other two methods. Specifically, compared to Tight encoding with JPEG compression, DeepTight encoding saved 34.08%, 84.60%, 72.96%, and 83.89% of average bandwidth and 58.42%, 81.68%, 83.19%, and 80.78% of peak bandwidth in the four scenarios, respectively. In comparison to the 8-bit color depth method, DeepTight encoding saved 29.80%, 66.67%, 32.18%, and 77.99% of average bandwidth and 44.27%, 67.03%, 39.64%, and 78.73% of peak bandwidth in each respective scenario. Average bandwidth represents the network traffic consumption of a remote desktop protocol. Generally, the lower the average bandwidth required by a remote desktop protocol over a period of time, the less the total network traffic consumption. Peak bandwidth determines the maximum network bandwidth demand of the remote desktop protocol. The lower the peak bandwidth required by the remote desktop protocol, the lower the network bandwidth needed for smooth operation. The data shows that, in terms of both network traffic and bandwidth, DeepTight requires the least, making it more adaptable to low-bandwidth environments compared to the other two methods.
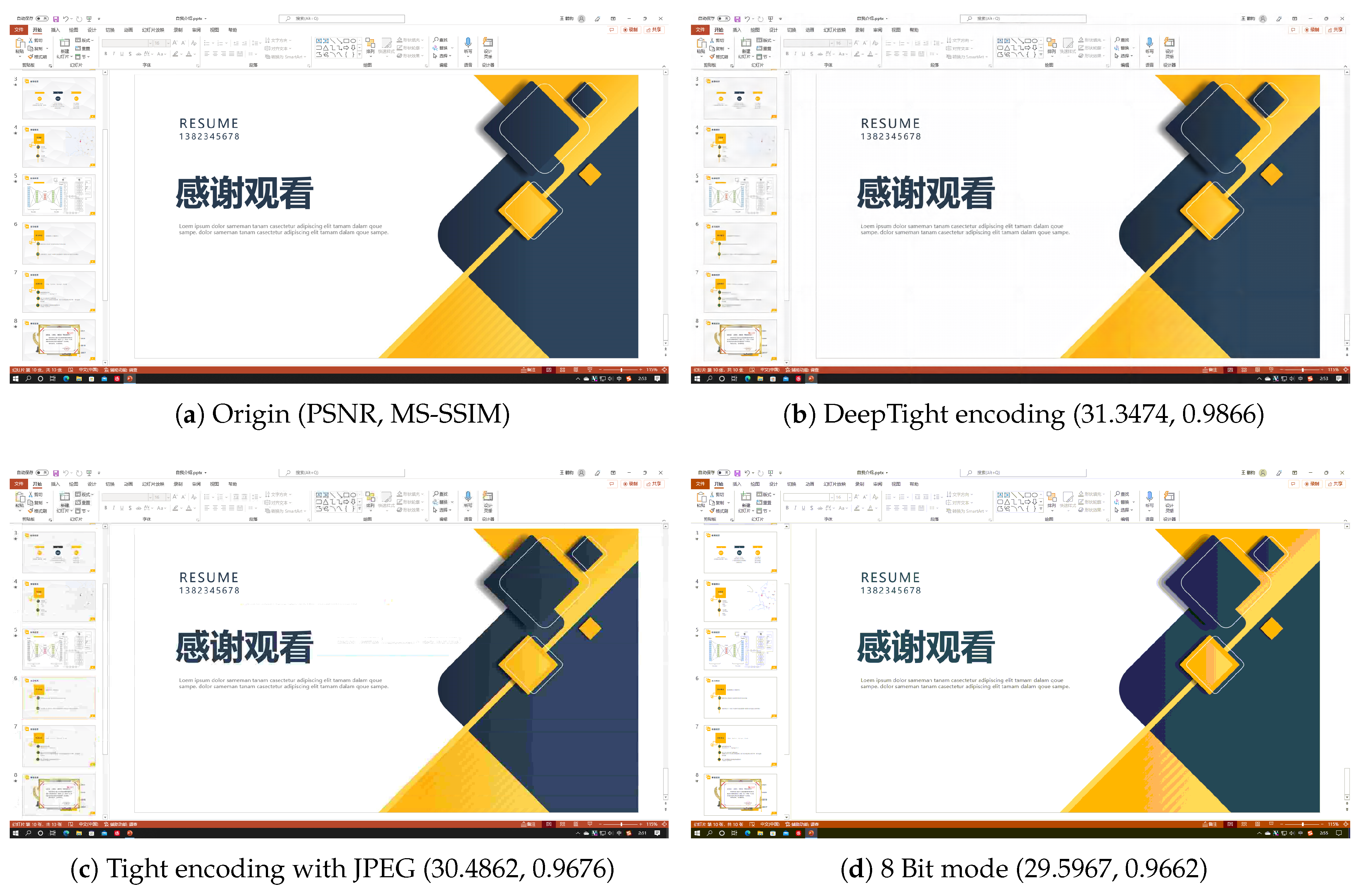
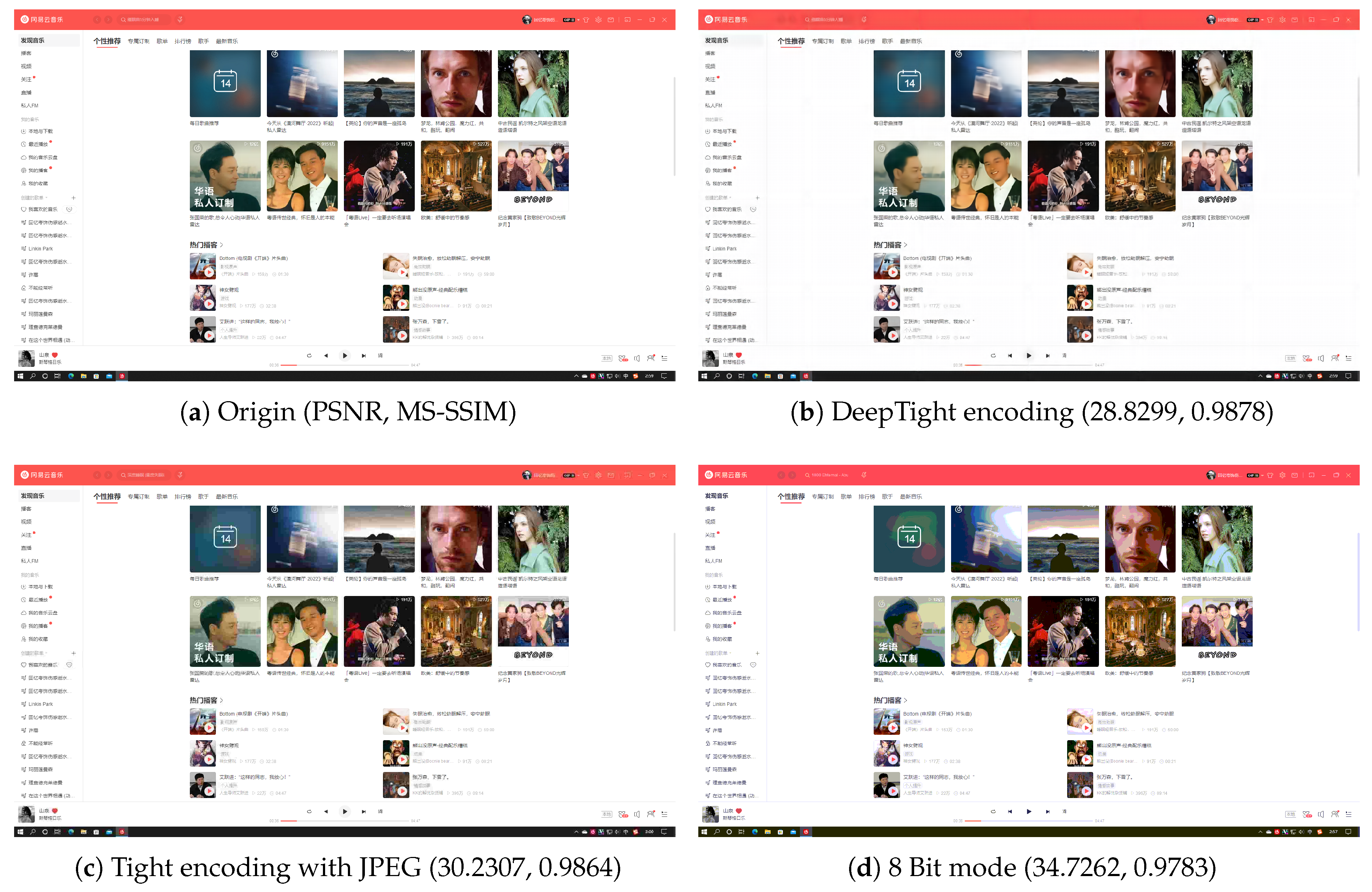
Figure 5,
Figure 6,
Figure 7 and
Figure 8 each demonstrate the reconstructed desktop images and their level of distortion relative to the original server-side desktop images under different encoding schemes in four scenarios: document editing, web browsing, slideshow presentation, and desktop application usage.
Table 6 provides a detailed display of the PSNR and MS-SSIM scores for different encodings in four scenarios. The data reveal that in all these scenarios, DeepTight encoding surpasses the other two encoding methods in terms of MS-SSIM scores for reconstructed desktop images. In PSNR comparison, however, DeepTight encoding outperforms the others only in the slideshow presentation scenario, while in the remaining scenarios, the scores for DeepTight encoding’s reconstructed images are comparable to or slightly lower than those of the other two encoding methods. PSNR represents the average difference between the reconstructed image and the original image. In the other three scenarios, there is a significant amount of whitespace in the desktop images. DeepTight encoding’s restoration of these whitespace areas is not as effective as the other two methods. However, these whitespace areas are non-working zones that users generally do not focus on. Minor distortions in these areas are unlikely to impact the users’ actual visual experience. From the graphical analysis, it can be observed that compared to Tight encoding, DeepTight encoding restores desktop images with greater color continuity and smoothness. In contrast to the 8 Bit mode, DeepTight encoding achieves more accurate color reproduction. Moreover, among all encoding methods, DeepTight encoding consumes the least bandwidth, both in terms of average and peak usage.
Additionally, in all four scenarios, compared to Tight encoding using the JPEG compression algorithm, DeepTight encoding effectively reduces block artifacts and shadow effects in the reconstructed desktop images. In contrast to encoding methods using 8-bit color depth, DeepTight encoding more accurately restores the colors of the original server-side desktop images and also reduces block artifacts resulting from lower pixel color depth.
7. Conclusions
This study advances convolutional neural networks, introducing an end-to-end model for image compression and decompression with corresponding computational equations. It also enhances the RFB protocol, a key component in VNC’s remote transmission, by integrating a novel scheme, Deep encoding, which is tailored for deep image compression and decompression codecs. This innovation led to the development of a remote desktop prototype using open-source VNC code based on the Deep encoding approach.
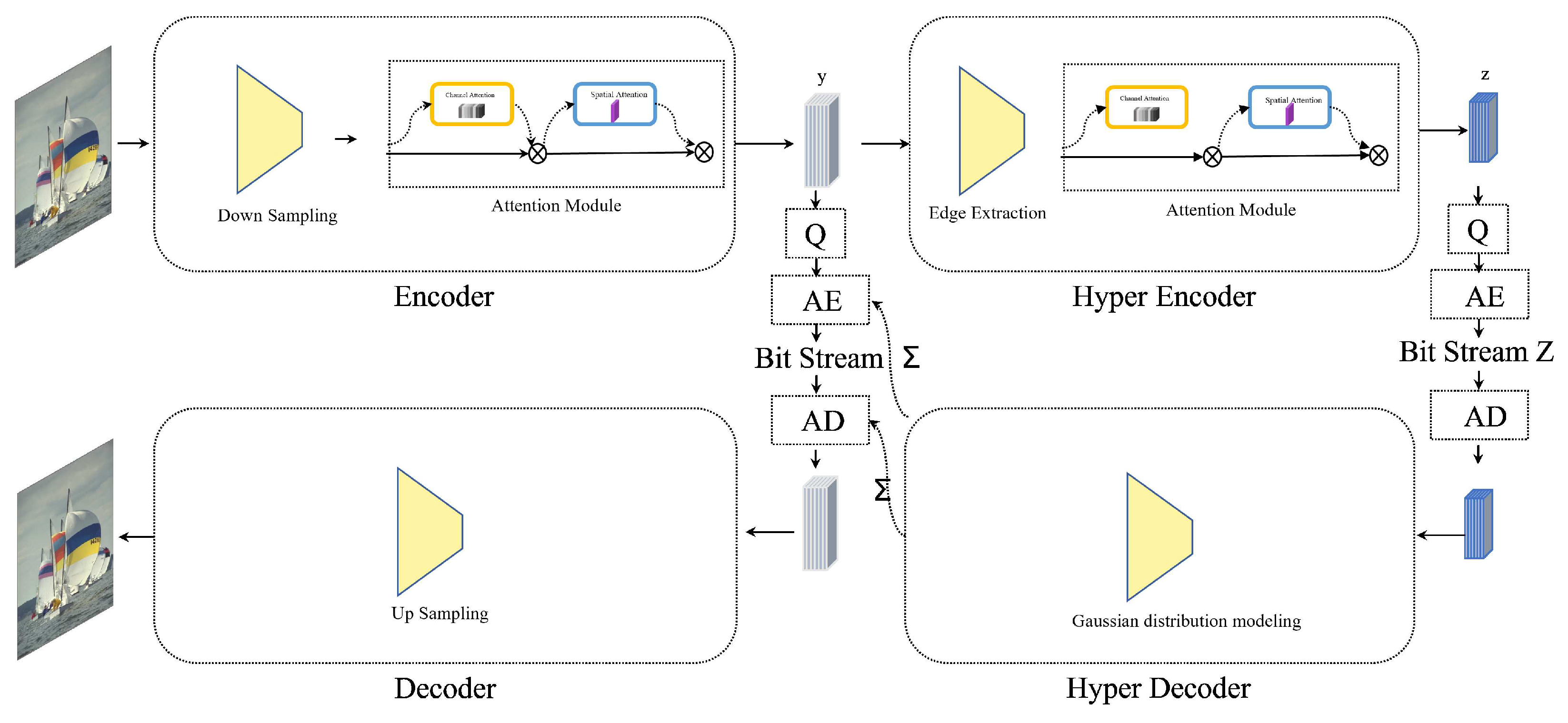
This paper details an image compression and decompression model fine-tuned for optimal human perception of reconstructed image quality. It seamlessly integrates adaptive spatial and channel attention mechanisms, comprising an encoder, a decoder, and a hyperprior codec. The encoder extracts latent image features, the decoder reconstructs images from these features, and the hyperprior codec converts these features into Gaussian form, aiding in achieving an improved rate–distortion equilibrium.
For optimization, the study employs Mean Squared Error (MSE) and Multi-Scale Structural Similarity (MS-SSIM) as combined metrics to assess image reconstruction distortion. The findings reveal that this dual-metric approach not only boosts MS-SSIM performance in desktop image reconstruction but also retains greater structural and textural fidelity compared to MSE-only optimizations, which can smooth out important textural nuances. This paper further introduces an attention mechanism within the model, targeting latent feature representations across both channel and spatial dimensions, thereby enhancing rate–distortion effectiveness. Testing shows that this addition elevates Peak Signal-to-Noise Ratio (PSNR) performance while preserving MS-SSIM quality.
To adapt this model for the open-source VNC remote desktop, this paper introduces Deep encoding—a fresh approach to remote desktop transmission encoding. This method, focused on segmenting, identifying, and encoding diverse image feature-based update areas, marks a significant refinement of the RFB protocol. The prototype, built on Deep encoding and VNC code, was evaluated against two low-bandwidth VNC encoding schemes, demonstrating up to 84.60% average and 83.19% peak bandwidth savings. Its MS-SSIM performance surpasses all existing low-bandwidth image encoding methods in VNC. Moreover, images reconstructed with Deep encoding show markedly fewer block effects and artifacts in low-bandwidth scenarios, substantially improving the user experience.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}