
Hubble Meets Webb: Image-to-Image Translation in Astronomy
 ,
,  , , , , and
, , , , and 
Abstract
:1. Introduction
2. Related Work
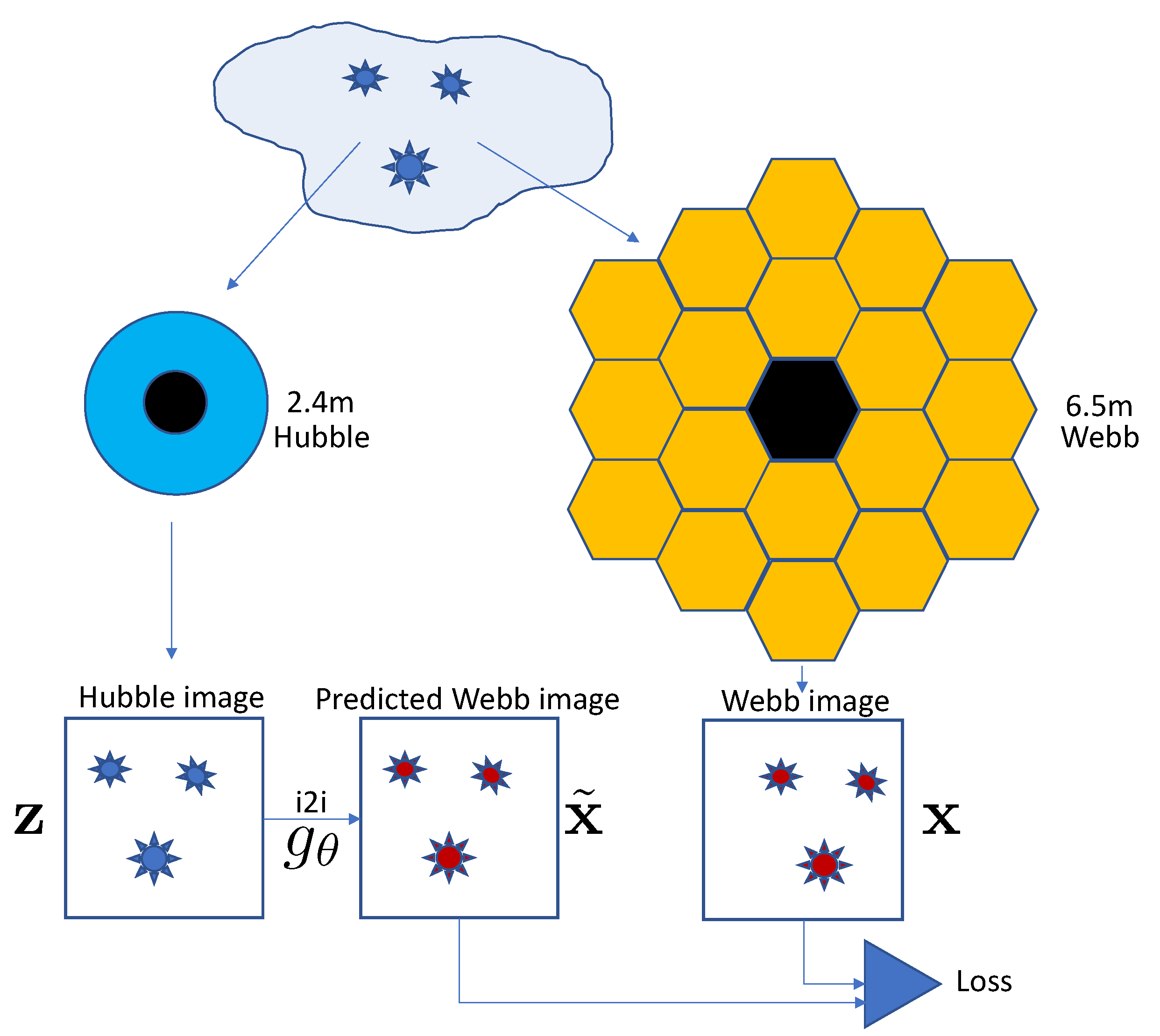
2.1. Comparison between Webb and Hubble Telescopes


2.2. Image-to-Image Translation
2.3. Image-to-Image Translation in Astrophysics
2.4. Metrics
- Mean square error (MSE) between the original and the generated Webb images;
- To address an issue that the MSE is not highly indicative of the perceived similarity of images, we calculate the Structural Similarity Index (SSIM) [12] between the original and generated Webb images;
- Fréchet Inception Distance (FID): proposed in [14]. Instead of a simple pixel-by-pixel comparison of images, FID estimates the mean and standard deviation of one of the deep layers in the pretrained convolutional neural network. It has become one of the most widely used metrics for the image-to-image translation task;
- Peak Signal-to-Noise Ratio (PSNR): This metric evaluates the quality of the generated images by comparing the maximum possible power of a signal (original images) to the power of the same images after distortion (generated images). PSNR is often used as a measure of reconstruction quality in image compression and restoration tasks;
- Learned Perceptual Image Patch Similarity (LPIPS): proposed in [13]. LPIPS measures the perceptual similarity between images by using deep features extracted from a pretrained neural network. It is designed to better reflect human perception of image similarity compared to traditional metrics like MSE or PSNR.
3. Proposed Approach
3.1. Dataset
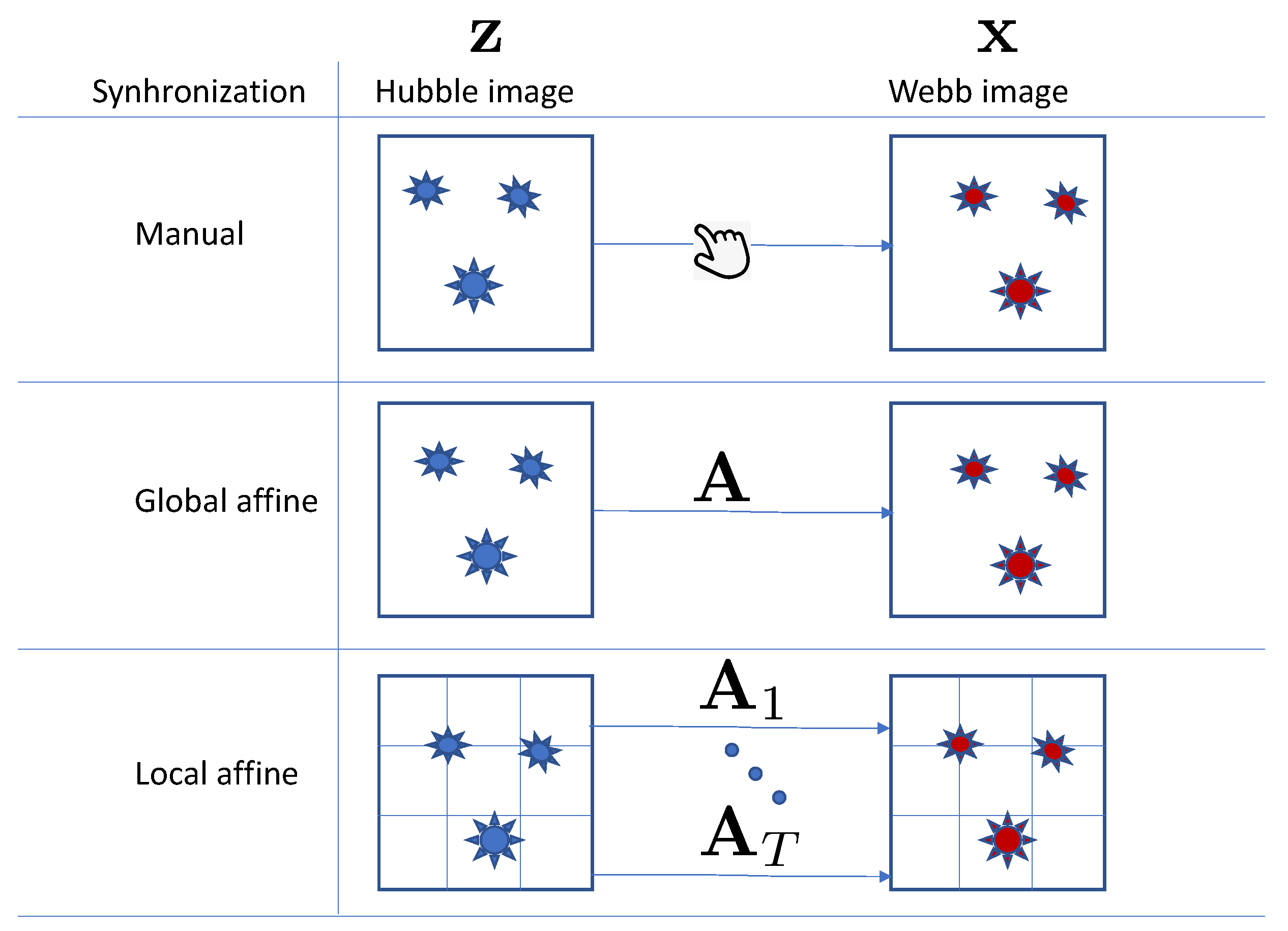
3.2. Image Registration
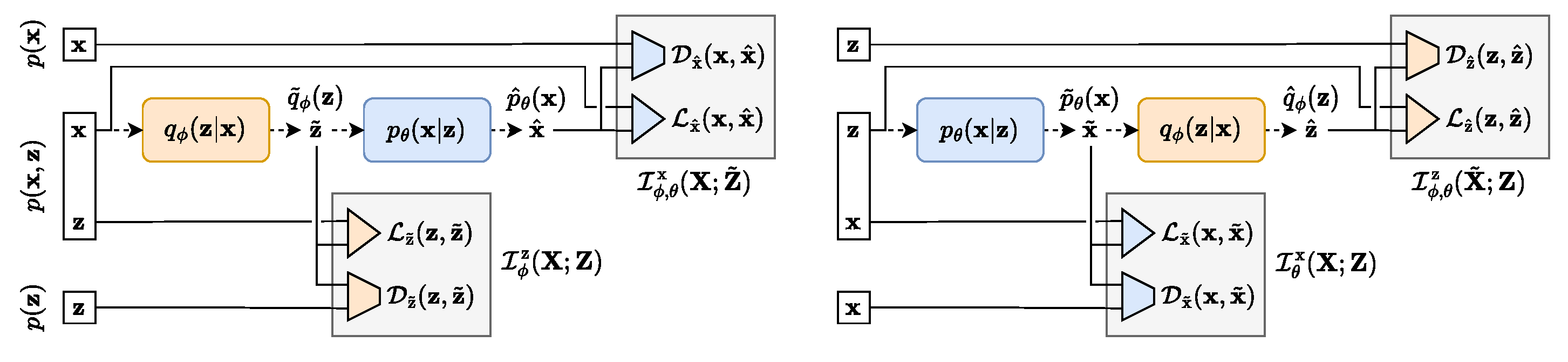
3.3. TURBO
3.3.1. Mathematical Interpretation
3.3.2. Paired Setup: Pix2Pix as Particular Case of TURBO
3.3.3. Unpaired Setup: CycleGAN as Particular Case of TURBO
3.4. Denoising Diffusion Based Image-to-Image Translation
| Algorithm 1 Training a denoising model |
|
| Algorithm 2 Inference in T iterative refinement steps |
|
4. Uncertainty Estimation
5. Implementation Details
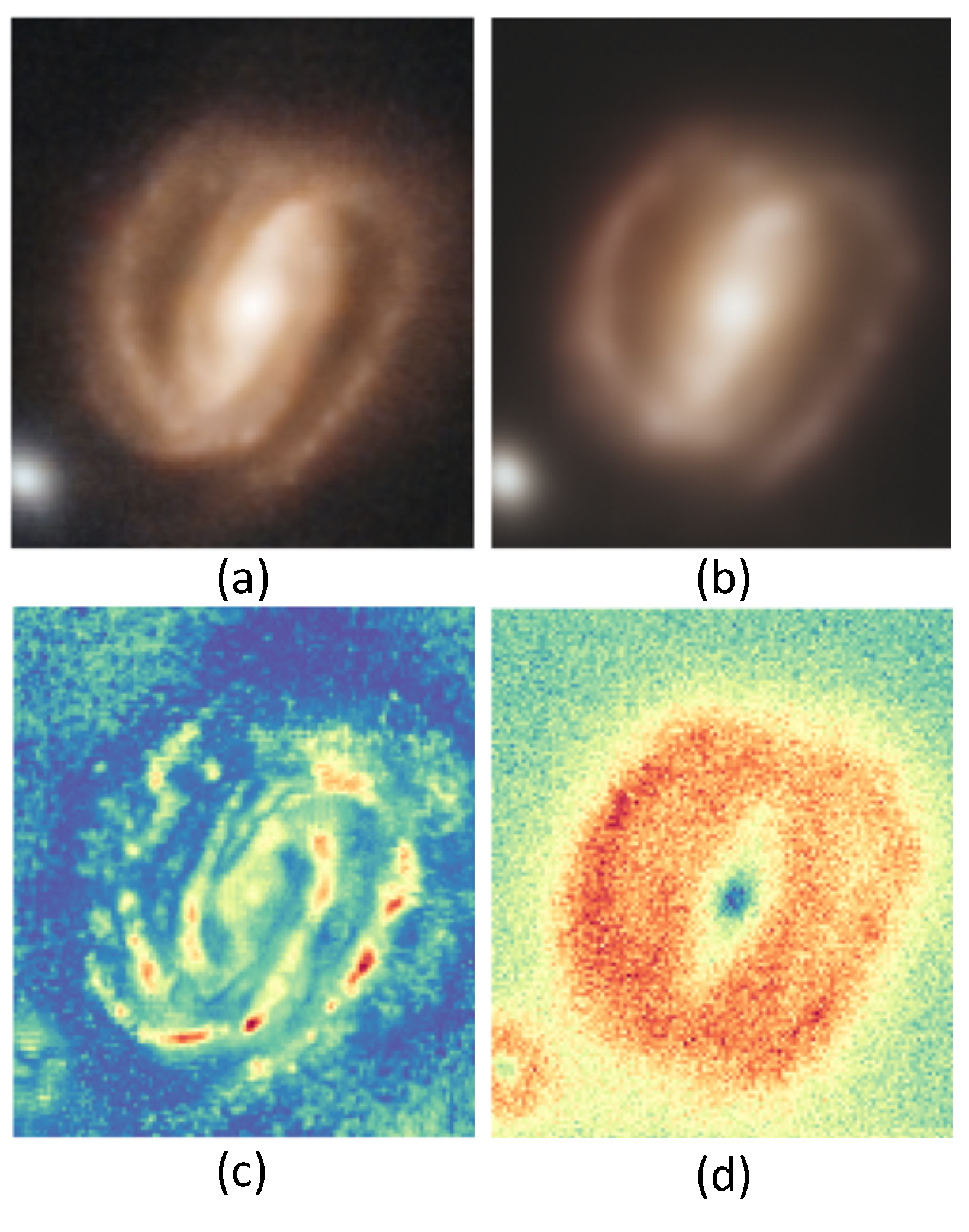
6. Results
7. Conclusions
8. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| GAN | Generative adversarial network |
| DDPM | Denoising diffusion probabilistic model |
| MSE | Mean squared error |
| PSNR | Peak signal to noise ratio |
| LPIPS | Learned perceptual image patch similarity |
| FID | Fréchet inception distance |
| RGB | Red, green, blue |
| AE | Auto-encoder |
| SSIM | Structural similarity index measure |
| TURBO | Two-way Uni-directional Representations by Bounded Optimisation |
| HST | Hubble Space Telescope |
| JWST | James Webb Space Telescope |
| LSGAN | Least Squares Generative Adversarial Network |
| SIFT | Scale-Invariant Feature Transform |
| RANSAC | Random Sample Consensus |
| ESA | European Space Agency |
| NASA | National Aeronautics and Space Administration |
| STScI | Space Telescope Science Institute |
References
- Garner, J.P.; Mather, J.C.; Clampin, M.; Doyon, R.; Greenhouse, M.A.; Hammel, H.B.; Hutchings, J.B.; Jakobsen, P.; Lilly, S.J.; Long, K.S.; et al. The James Webb space telescope. Space Sci. Rev. 2006, 123, 485–606. [Google Scholar] [CrossRef]
- Lallo, M.D. Experience with the Hubble Space Telescope: 20 years of an archetype. Opt. Eng. 2012, 51, 011011. [Google Scholar] [CrossRef]
- Lin, Q.; Fouchez, D.; Pasquet, J. Galaxy Image Translation with Semi-supervised Noise-reconstructed Generative Adversarial Networks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5634–5641. [Google Scholar]
- Schaurecker, D.; Li, Y.; Tinker, J.; Ho, S.; Refregier, A. Super-resolving Dark Matter Halos using Generative Deep Learning. arXiv 2021, arXiv:2111.06393. [Google Scholar]
- Racca, G.D.; Laureijs, R.; Stagnaro, L.; Salvignol, J.C.; Alvarez, J.L.; Criado, G.S.; Venancio, L.G.; Short, A.; Strada, P.; Bönke, T.; et al. The Euclid mission design. In Proceedings of the Space Telescopes and Instrumentation 2016: Optical, Infrared, and Millimeter Wave, Edinburgh, UK, 19 July 2016; Volume 9904, pp. 235–257. [Google Scholar]
- Hall, P.; Schillizzi, R.; Dewdney, P.; Lazio, J. The square kilometer array (SKA) radio telescope: Progress and technical directions. Int. Union Radio Sci. URSI 2008, 236, 4–19. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Quétant, G.; Belousov, Y.; Kinakh, V.; Voloshynovskiy, S. TURBO: The Swiss Knife of Auto-Encoders. Entropy 2023, 25, 1471. [Google Scholar] [CrossRef] [PubMed]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/8a1d694707eb0fefe65871369074926d-Paper.pdf (accessed on 3 January 2024).
- NASA. Webb vs Hubble Telescope. Available online: https://www.jwst.nasa.gov/content/about/comparisonWebbVsHubble.html (accessed on 6 January 2024).
- Science, N. Hubble vs. Webb. Available online: https://science.nasa.gov/science-red/s3fs-public/atoms/files/HSF-Hubble-vs-Webb-v3.pdf (accessed on 6 January 2024).
- Space Telescope Science Institute. Webb Space Telescope. Available online: https://webbtelescope.org (accessed on 6 January 2024).
- European Space Agency. Hubble Space Telescope. Available online: https://esahubble.org (accessed on 6 January 2024).
- Pang, Y.; Lin, J.; Qin, T.; Chen, Z. Image-to-image translation: Methods and applications. IEEE Trans. Multimed. 2021, 24, 3859–3881. [Google Scholar] [CrossRef]
- Liu, M.Y.; Huang, X.; Mallya, A.; Karras, T.; Aila, T.; Lehtinen, J.; Kautz, J. Few-shot unsupervised image-to-image translation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10551–10560. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 649–666. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Patel, D.; Patel, S.; Patel, M. Application of Image-To-Image Translation in Improving Pedestrian Detection. In Artificial Intelligence and Sustainable Computing; Pandit, M., Gaur, M.K., Kumar, S., Eds.; Springer Nature: Singapore, 2023; pp. 471–482. [Google Scholar]
- Kaji, S.; Kida, S. Overview of image-to-image translation by use of deep neural networks: Denoising, super-resolution, modality conversion, and reconstruction in medical imaging. Radiol. Phys. Technol. 2019, 12, 235–248. [Google Scholar] [CrossRef]
- Liu, M.-Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/dc6a6489640ca02b0d42dabeb8e46bb7-Paper.pdf (accessed on 3 February 2024).
- Tripathy, S.; Kannala, J.; Rahtu, E. Learning image-to-image translation using paired and unpaired training samples. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 51–66. [Google Scholar]
- Vojtekova, A.; Lieu, M.; Valtchanov, I.; Altieri, B.; Old, L.; Chen, Q.; Hroch, F. Learning to denoise astronomical images with U-nets. Mon. Not. R. Astron. Soc. 2021, 503, 3204–3215. [Google Scholar] [CrossRef]
- Liu, T.; Quan, Y.; Su, Y.; Guo, Y.; Liu, S.; Ji, H.; Hao, Q.; Gao, Y. Denoising Astronomical Images with an Unsupervised Deep Learning Based Method. arXiv 2023. [Google Scholar] [CrossRef]
- NASA/IPAC. Galaxy Cluster SMACS J0723.3-7327. Available online: http://ned.ipac.caltech.edu/cgi-bin/objsearch?search_type=Obj_id&objid=189224010 (accessed on 6 January 2024).
- Bohn, T.; Inami, H.; Diaz-Santos, T.; Armus, L.; Linden, S.T.; Surace, J.; Larson, K.L.; Evans, A.S.; Hoshioka, S.; Lai, T.; et al. GOALS-JWST: NIRCam and MIRI Imaging of the Circumnuclear Starburst Ring in NGC 7469. arXiv 2022, arXiv:2209.04466. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Redhook, NY, USA, 2019; Volume 32, Available online: https://proceedings.neurips.cc/paper_files/paper/2019/file/bdbca288fee7f92f2bfa9f7012727740-Paper.pdf (accessed on 3 February 2024).
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Redhook, NY, USA, 2017; Volume 30, Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 3 February 2024).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MSE ↓ | SSIM ↑ | PSNR ↑ | LPIPS ↓ | FID↓ |
|---|---|---|---|---|---|
| 0.002 | 0.93 | 26.94 | 0.47 | 83.32 | |
| 0.002 | 0.93 | 26.98 | 0.47 | 76.03 | |
| 0.002 | 0.93 | 26.93 | 0.47 | 82.71 | |
| LPIPS | 0.002 | 0.93 | 26.68 | 0.44 | 72.84 |
| Pix2Pix | 0.002 | 0.93 | 26.78 | 0.44 | 54.58 |
| Pix2Pix + LPIPS | 0.003 | 0.93 | 27.02 | 0.44 | 58.86 |
| TURBO | 0.003 | 0.92 | 25.88 | 0.41 | 43.36 |
| TURBO + LPIPS | 0.003 | 0.92 | 25.91 | 0.39 | 50.83 |
| 0.002 | 0.93 | 26.15 | 0.45 | 70.51 | |
| + LPIPS | 0.002 | 0.93 | 26.13 | 0.46 | 67.52 |
| TURBO same D | 0.002 | 0.92 | 26.04 | 0.4 | 55.29 |
| TURBO same D + LPIPS | 0.002 | 0.92 | 26.13 | 0.39 | 55.88 |
| Method | MSE ↓ | SSIM ↑ | PSNR ↑ | LPIPS ↓ | FID ↓ |
|---|---|---|---|---|---|
| unpaired | |||||
| CycleGAN | 0.010 | 0.83 | 20.11 | 0.48 | 128.12 |
| paired: synchronization with respect to celestial coordinates | |||||
| Pix2Pix | 0.007 | 0.87 | 21.37 | 0.5 | 102.61 |
| TURBO | 0.008 | 0.85 | 20.87 | 0.49 | 98.41 |
| DDPM (Palette) | 0.003 | 0.88 | 25.36 | 0.43 | 51.2 |
| paired: global synchronization | |||||
| Pix2Pix | 0.003 | 0.92 | 25.85 | 0.46 | 55.69 |
| TURBO | 0.003 | 0.91 | 25.08 | 0.45 | 48.57 |
| DDPM (Palette) | 0.002 | 0.94 | 28.12 | 0.45 | 43.97 |
| paired: local synchronization | |||||
| Pix2Pix | 0.002 | 0.93 | 26.78 | 0.44 | 54.58 |
| TURBO | 0.003 | 0.92 | 25.88 | 0.41 | 43.36 |
| DDPM (Palette) | 0.001 | 0.95 | 29.12 | 0.44 | 30.08 |
| Model | Trainable Params | Inference Paras | Inference Time |
|---|---|---|---|
| DDPM (1000 steps) | 62.641 Mio | 62.641 Mio | 42.77 ± 0.18 s |
| Pix2Pix | 14.143 Mio | 11.378 Mio | 0.07 ± 0.004 s |
| CycleGAN | 28.286 Mio | 11.378 Mio | 0.07 ± 0.004 s |
| TURBO | 33.816 Mio | 11.378 Mio | 0.07 ± 0.004 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kinakh, V.; Belousov, Y.; Quétant, G.; Drozdova, M.; Holotyak, T.; Schaerer, D.; Voloshynovskiy, S. Hubble Meets Webb: Image-to-Image Translation in Astronomy. Sensors 2024, 24, 1151. https://doi.org/10.3390/s24041151
Kinakh V, Belousov Y, Quétant G, Drozdova M, Holotyak T, Schaerer D, Voloshynovskiy S. Hubble Meets Webb: Image-to-Image Translation in Astronomy. Sensors. 2024; 24(4):1151. https://doi.org/10.3390/s24041151
Chicago/Turabian StyleKinakh, Vitaliy, Yury Belousov, Guillaume Quétant, Mariia Drozdova, Taras Holotyak, Daniel Schaerer, and Slava Voloshynovskiy. 2024. "Hubble Meets Webb: Image-to-Image Translation in Astronomy" Sensors 24, no. 4: 1151. https://doi.org/10.3390/s24041151