
Study on the Influence of Label Image Accuracy on the Performance of Concrete Crack Segmentation Network Models
 ,
,
Abstract
:1. Introduction
2. Image Semantic Segmentation (ISS)
2.1. Method Based on Encoder–Decoder Structure
2.2. Method Based on Feature Fusion
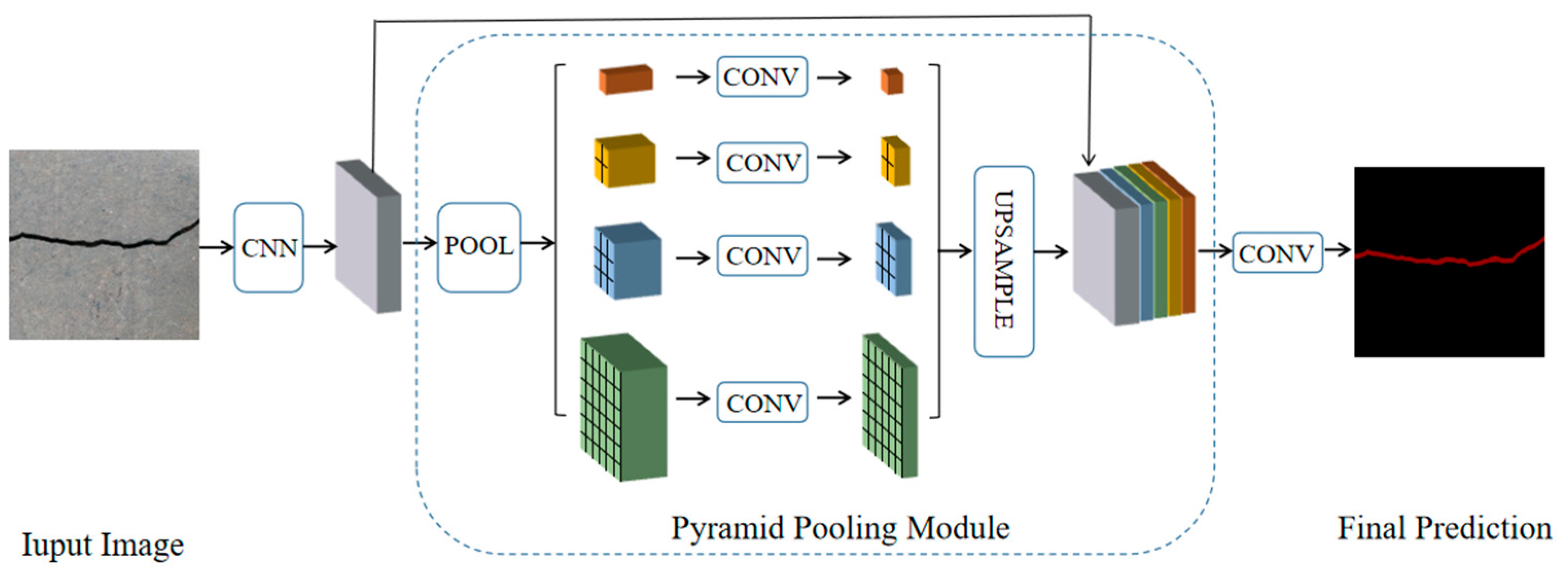
2.3. Method Based on Void Convolution
3. Dataset Construction
3.1. Transfer Learning
3.2. Construction of Datasets with Different Labelling Accuracy
4. Evaluation Methods of Network Model Performance
4.1. Network Model Accuracy Evaluation Methods
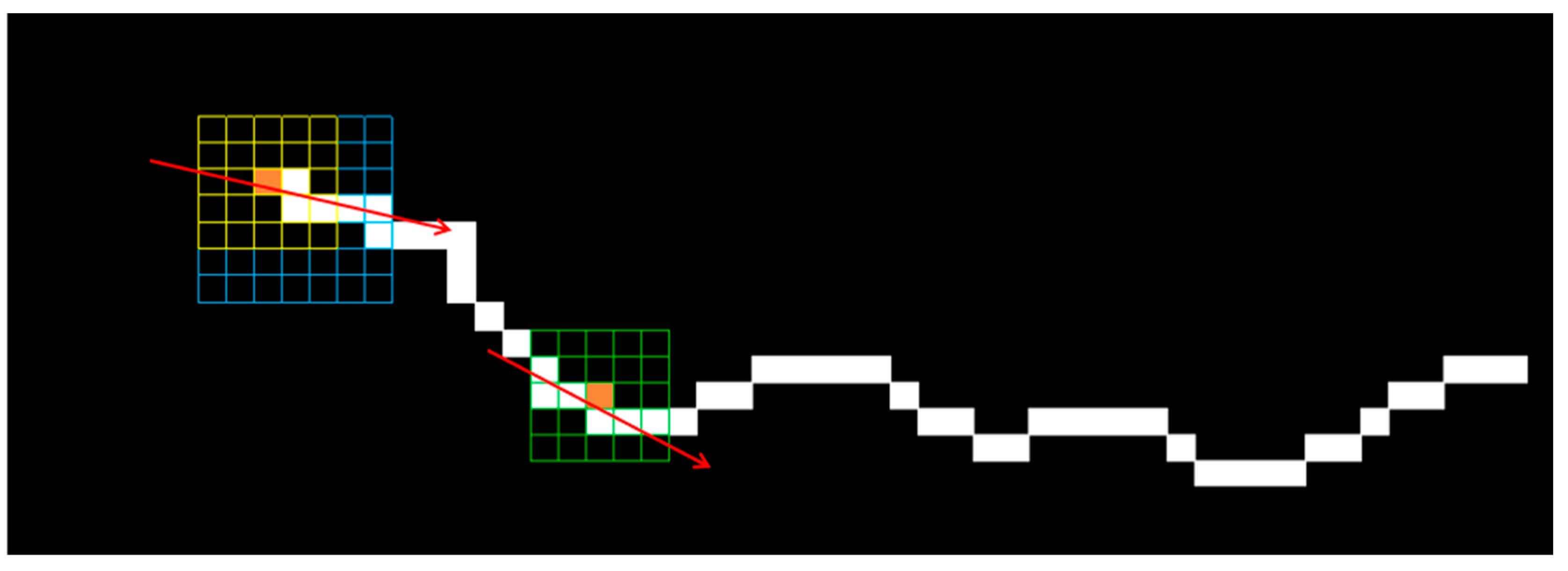
4.2. Quantization Method of Crack Parameters
- (1)
- The crack contour is extracted using an edge detection algorithm, and then the skeleton of the crack image is extracted using an axis transformation or an image-thinning algorithm.
- (2)
- The skeleton points are extracted sequentially on the crack skeleton line, and a 5 × 5 regional core is constructed with the skeleton points as the centre. The second-order moment of the connected domain composed of all the skeleton points in the regional core is used to calculate the crack extension direction θ, as shown in Equation (1) [52], and then the orthogonal vector of the crack extension direction is calculated using the orthogonal property.where , , ; where is the total number of skeleton points in the region nucleus; and are the image coordinates of skeleton points in the region nucleus; and are the average value of the image coordinates of skeleton points.
- (1)
- With the skeleton point as the centre of the circle and a certain threshold as the radius, the search domain is set to obtain the local crack contour points for the skeleton point, and the projection coefficient of each local contour point onto the orthogonal vector is calculated. Due to the directivity of the vector, the projection coefficients of the contour points on both sides of the skeleton on the orthogonal vector are positive and negative. According to the positive and negative projection coefficients, the local contour points can be divided into two groups.
- (2)
- The contribution coefficient α (0–1) is introduced to adjust the degree of contribution of the two quantization ideas to the crack width calculation results. The closer α is to 1, the greater the contribution of the orthogonal ideas.
- (3)
- For a group with a positive projection coefficient, if the ratio of the local contour point’s projection coefficient to the maximum projection coefficient exceeds the contribution coefficient α, the contour point is considered as an alternative point and stored in set A. For a group with a negative projection coefficient, if the ratio of the local contour point’s projection coefficient to the minimum projection coefficient exceeds the contribution coefficient α, the contour point is considered as a candidate point and stored in set B. Finally, the combination with the shortest Euclidean distance between the two groups of candidate points is selected as the width of the crack at the skeleton point, and the width is calculated as shown in Equation (2).
5. Experiments and Results
5.1. Experimental Environment and Parameter Settings
5.2. Experimental Process
5.3. Comparative Experiment
5.3.1. Accuracy Evaluation of Network Models
5.3.2. Network Model Segmentation Accuracy Evaluation
6. Discussion
7. Conclusions
- (1)
- The comparison results of the network model training accuracy show that due to the specificity of the crack object, the labelling accuracy of the crack label image has a different influence on the performance of the SSNMs, and different SSNMs have different sensitivity to crack label images with different accuracy. The Accuracy values of the four SSNMs trained using the pixel-level fine label image are all the highest, among which the Accuracy values of the U-Net are the highest, while the MIoU and MPA values are the lowest. The Accuracy values of the four SSNMs trained using the image data labelled with outer contour widening are all the lowest, among which DeepLabV3+ has the lowest Accuracy value. For the Accuracy values of the four SSNMs trained on the image data labelled with topological structure widening, the MIoU value of the three SSNMs except the PSPNetV2 is the highest, and the U-Net has the highest MPA value. It can be seen that the labelling accuracy of the crack label images strongly affects the learning efficiency and training accuracy of the SSNMs.
- (2)
- According to the comparison results of the segmentation effect of the network model, among the four SSNMs trained with pixel-level finely labelled image data, U-Net achieves accurate segmentation results for crack images with different segmentation difficulties, such as fine crack, strong crack and reticulated crack, and the segmentation contour is the most detailed. HRNetV2, PSPNet and DeepLabV3+ have good segmentation performance only for strong cracks. Four kinds of SSNMs were obtained using image data labelled with outer contour widening, and the segmentation results of fine cracks and strong cracks are more accurate. For the reticulated crack, U-Net obtained the same features as the labelled images, HRNetV2 obtained the same features as the reticulated crack topology and PSPNet and DeepLabV3+ obtained the same features as the labelled images, but the internal filling was incomplete. The four SSNMs trained on the image data labelled with the topological structure widening obtain complete segmentation results for the three types of crack images, but the segmentation contours are all wider than the real crack contours. It can be seen that the characteristics of the image labels have a profound effect on the learning efficiency of the network models and the segmentation effect of the crack images. In addition, the U-Net has a stronger learning ability than PSPNet, HRNetV2 and DeepLabV3+ and can better learn the crack characteristics for crack label images with different label accuracy. The model has high accuracy and strong stability, which is more suitable for crack detection.
- (3)
- Compared with the segmentation accuracy of the network model, it can be seen that the finely labelled crack label images have a higher demand on the learning ability of the SSNM, but the trained network model has a crack segmentation contour that is closer to the real crack contour for the segmentation results of the crack image. However, the widened labelled crack image has a slightly lower learning requirement for the SSNM. The network model trained with the label image data of such accuracy has an increased width of the crack segmentation contour compared to the real crack contour. The U-Net is obtained using the image data of the outer contour widening label; for the segmentation results of the crack image, the quantified value of the contour width is very different from the real width value of the crack, but the segmented contour has better integrity and intuitionism, which is conducive to the location and identification of the crack. It can be seen that in order to improve the efficiency of crack detection and obtain accurate crack segmentation results, excellent network models and pixel-level fine labelling data are indispensable.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Y.H.; Li, P.F.; Lv, M. Surface crack detection of concrete structures based on deep learning. Concrete 2022, 394, 187–192. [Google Scholar]
- Ding, W.; Yu, K.; Shu, J.P. Method for detecting cracks in concrete strucyures based on deep learning and UAV. China Civ. Eng. J. 2021, 54, 1–12. [Google Scholar]
- Amhaz, R.; Chambon, S.; Idier, J.; Baltazart, V. Automatic crack detection on two-dimensional pavement images: An algorithm based on minimal path selection. IEEE Trans. Intell. Transp. 2016, 17, 2718–2729. [Google Scholar] [CrossRef]
- Qiu, Y.J.; Wang, G.L.; Yang, E.H.; Yu, X.L.; Wang, C.P. Crack detection of 3D asphalt pavement based on multi-feature test. J. Southwest Jiaotong Univ. 2020, 55, 518–524. [Google Scholar]
- Li, P.; Li, Q.; Ma, W.M.; Jiang, W. Pavement crack segmentation algorithm based on k-means clustering. Comput. Eng. Design 2020, 41, 3143–3147. [Google Scholar]
- Wei, C.T.; Zhu, X.Y.; Zhang, D.M. Lightweight grid bridge crack detection technology based on depth classification. Comput. Eng. Design 2022, 43, 2334–2341. [Google Scholar]
- Yu, J.Y.; Liu, B.L.; Yin, D.; Gao, W.Y.; Xie, Y.L. Intelligent identification and measurement of bridge cracks based on YOLOv5 and U-Net3+. J. Hunan. Univ. 2023, 50, 65–73. [Google Scholar]
- Deng, L.; Chu, H.H.; Long, L.Z.; Wang, W.; Kong, X.; Cao, R. Review of deep learning-based crack detection for civil infrastructures. China J. Highw. Transp. 2023, 36, 1–21. [Google Scholar]
- Li, L.F.; Ma, W.F.; Li, L.; Lu, C. Research on detection algorithm for bridge cracks based on deep learning. Acta Autom. Sin. 2019, 45, 1727–1742. [Google Scholar]
- Ma, K.F.; Meng, X.; Hao, M.S.; Huang, G.P.; Hu, Q.F.; He, P.P. Research on the efficiency of bridge crack detection by coupling deep learning frameworks with convolutional neural networks. Sensors 2023, 23, 7272. [Google Scholar] [CrossRef]
- Zhu, Y.F.; Wang, H.T.; Li, K.; Wu, H.J. Crack U-Net: Towards high quality pavement crack detection. Comput. Sci. 2022, 49, 204–211. [Google Scholar]
- Liu, F.; Wang, J.F.; Chen, Z.Y.; Xu, F. Parallel attention based UNet for crack detection. Comput. Res. Dev. 2021, 58, 1718–1726. [Google Scholar]
- Tan, G.J.; Ou, J.; Ai, Y.M.; Yang, R.C. Bridge crack image segmentation method based on improved DeepLabv3+ model. J. Jilin. Univ. 2022, 52, 1–7. [Google Scholar]
- Huang, R.X.; Liu, D.E. Improved Deeplabv3+ pavement crack detection based on maximum connection region collaboration. Comput. Simul. 2023, 40, 182–186. [Google Scholar]
- Li, L.F.; Wang, N.; Wu, B.; Zhang, X. Segmentation algorithm of bridge crack image based on modified PSPNet. Laser Optoelectron. Prog. 2021, 58, 101–109. [Google Scholar]
- Zhang, J.; Qian, S.R.; Tan, C. Automated bridge surface crack detection and segmentation using computer vision-based deep learning model. Eng. Appl. Artif. Intell. 2022, 115, 105225. [Google Scholar] [CrossRef]
- Zhong, J.T.; Zhu, J.Q.; Huyan, J.; Ma, T.; Zhang, W.G. Multi-scale feature fusion network for pixel-level pavement distress detection. Automat. Constr. 2022, 141, 104436. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, S.L.; Li, X.; Li, G.; Li, X.Y. Lightweight bridge crack detection method based on SegNet and Bottleneck depth-separable convolution with residuals. Autom. Constr. 2021, 9, 161649–161668. [Google Scholar] [CrossRef]
- Chen, H.S.; Su, Y.S.; He, W. Automatic crack segmentation using deep high-resolution representation learning. Appl. Opt. 2021, 60, 6080–6090. [Google Scholar] [CrossRef]
- He, A.Z.; Dong, Z.S.; Zhang, H.; Zhang, A.A.; Qiu, S.; Liu, Y.; Wang, K.C.P.; Lin, Z.H. Automated pixel- level detection of expansion joints on asphalt pavement using a deep-learning-based approach. Struct. Control. Health 2023, 2023, 7552337. [Google Scholar] [CrossRef]
- Zhu, S.Y.; Du, J.C.; Li, Y.S.; Wang, X.P. Method for bridge crack detection based on the U-Net convolutional networks. J. Xidian Univ. 2019, 46, 35–42. [Google Scholar]
- Wu, X.D.; Zhao, J.K.; Liu, C.Q. Bridge crack detection algorithm based on CNN and CRF. Comput. Eng. Des. 2021, 42, 51–56. [Google Scholar]
- Liao, Y.N.; Li, W. Bridge crack detection method based on convolution neural network. Comput. Eng. Des. 2021, 42, 2366–2372. [Google Scholar]
- Xiang, J.H.; Xu, H. Research on image semantic segmentation algorithm based on deep learning. Appl. Res. Comput. 2020, 37, 316–317+320. [Google Scholar]
- Wang, Y.R.; Chen, Q.L.; Wu, J.J. Research on image semantic segmentation for complex environments. Comput. Sci. 2019, 46, 36–46. [Google Scholar]
- Yang, C.X.; Weng, G.R.; Chen, Y.Y. Active contour model based on local Kulback-Leibler divergence for fast image segmentation. Eng. Appl. Artif. Intell. 2023, 123, 106472. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Jing, Z.W.; Guan, H.Y.; Peng, D.F.; Yu, Y.T. Survey of research in image semantic segmentation based on deep neural network. Comput. Eng. 2020, 46, 1–17. [Google Scholar]
- Lu, X.; Liu, Z. A review of image semantic segmentation based on deep learning. Softw. Guide 2021, 20, 242–244. [Google Scholar]
- Xu, H.; Zhu, Y.H.; Zhen, T.; Li, Z.H. Survey of image semantic segmentation methods based on deep neural network. J. Front. Comput. Sci. Technol. 2021, 15, 47–59. [Google Scholar]
- Kuang, H.Y.; Wu, J.J. Survey of image semantic segmentation based on deep learning. Comput. Eng. Appl. 2019, 55, 12–21+42. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhang, L.X.; Shen, J.K.; Zhu, B.J. A research on an improved Unet-based concrete crack detection algorithm. Struct. Health Monit. 2020, 20, 1864–1879. [Google Scholar] [CrossRef]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J.Y. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Wang, J.D.; Sun, K.; Cheng, T.H.; Jiang, B.R.; Deng, C.R.; Zhao, Y.; Liu, D.; Mu, Y.D.; Tan, M.K.; Wang, X.G.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.K.; Zhu, C.J.; Zhang, Y. Research on improved lightweight high resolution human keypoint detection. Comput. Eng. Appl. 2021, 57, 143–149. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. Comput. Sci. 2014, 41, 357–361. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fuly connected CRFs. IEEE Trans. Pattern Anal. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Zhao, X.B.; Wang, J.J. Bridge crack detection based on improved DeeplabV3+ and migration learning. Comput. Eng. Appl. 2023, 59, 262–269. [Google Scholar]
- Wang, J.F.; Liu, F.; Yang, S.; Lv, T.Y.; Chen, Z.Y.; Xu, F. Dam crack detection based on multi-source transfer learning. Comput. Sci. 2022, 49, 319–324. [Google Scholar]
- Jia, D.; Wei, D.; Socher, R.; Li-Jia, L.; Kai, L.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Eric, B.; Matthew, H. Concrete Crack Conglomerate Dataset; Dataset; University Libraries, Virginia Tech: Blacksburg, VA, USA, 2021. [Google Scholar]
- Eric, B.; Matthew, H. Labeled Cracks in the Wild (LCW) Dataset; Dataset; University Libraries, Virginia Tech: Blacksburg, VA, USA, 2021. [Google Scholar]
- Shi, Y.; Cui, L.M.; Qi, Z.Q.; Meng, F.; Chen, Z.S. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Liu, Y.H.; Yao, J.; Lu, X.H.; Xie, R.P.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing. 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Ruiz, R.D.B.; Lordsleem Junior, A.C.; de Sousa Neto, A.F.; Fernandes, B.J.T. Digital image processing for automatic detection of cracks in buildings coatings. Ambiente Construído 2021, 21, 139–147. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.Q.; Mao, Q.Z.; Wang, S. Crack tree: Automatic crack detection from pavement images. Pattern. Recogn. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.Q.; Qi, X.B.; Wang, Q.; Wang, S. DeepCrack: Learning hierarchical convolutional features for crack detection. IEEE Trans. Image Process. 2019, 28, 1498–1512. [Google Scholar] [CrossRef]
- Li, L.F.; Wu, B.; Wang, N. Method for bridge crack detection based on multiresolution network. Laser Optoelectron. Prog. 2021, 58, 103–112. [Google Scholar]
- Yang, J.W.; Zhang, G.; Chen, X.J.; Ban, Y. Research on bridge crack detection based on deep learning under complex background. J. Railw. Sci. Eng. 2020, 17, 2722–2728. [Google Scholar]
- Ong, J.C.H.; Ismadi, M.-Z.P.; Wang, X. A hybrid method for pavement crack width measurement. Measurement 2022, 197, 111260. [Google Scholar] [CrossRef]
- Qiu, S.; Wang, W.; Wang, S.; Wang, K.C.P. Methodology for accurate AASHTO PP67-10-based cracking quantification using 1-mm 3D pavement images. J. Comput. Civil. Eng. 2017, 31, 04016056. [Google Scholar] [CrossRef]
- Hou, X.Z.; Chen, B. Weakly supervised semantic segmentation algorithm based on self-supervised image pair. J. Comput. Appl. 2022, 42, 53–59. [Google Scholar]
- Bai, X.F.; Li, W.J.; Wang, W.J. Saliency background guided network for weakly-supervised semantic segmentation. Pattern Recognit. Artif. Intell. 2021, 34, 824–835. [Google Scholar]
- Luan, X.M.; Liu, E.H.; Wu, P.F.; Zhang, J. Weakly-supervised semantic segmentation method of remote rensing images based on edge enhancement. Comput. Eng. Appl. 2022, 58, 188–196. [Google Scholar]
- Tian, X.; Wang, L.; Ding, Q. Review of image semantic segmentation based on deep learning. J. Softw. 2019, 30, 440–468. [Google Scholar]
- Xie, X.L.; Yin, D.X.; Xu, X.Y.; Liu, X.F.; Luo, C.Y.; Xie, G. A survey of weakly-supervised image semantic segmentation based on image -level labels. J. Taiyuan Univ. 2021, 52, 894–906. [Google Scholar]
- Gong, Y.D.; Liu, G.Z.; Xue, Y.Z.; Li, R.; Meng, L.Z. A survey on dataset quality in machine learning. Inf. Softw. Technol. 2013, 162, 107268. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Labelling Strategy Crack Type | Original Crack Image | Pixel-Level Fine Labelling | Outer Contour Widening Labelling | Topological Structure Widening Labelling |
|---|---|---|---|---|
| Fine crack |  |  |  |  |
| Strong crack |  |  |  |  |
| Cross crack |  |  |  |  |
| Reticulated crack |  |  |  |  |
| Name | Definition | Instructions |
|---|---|---|
| TP | True Positive | The sample is predicted to be positive and the true label is positive. |
| FP | False Positive | The sample is predicted to be positive, but the true label is negative. |
| TN | True Negative | The sample is predicted to be negative and the true label is negative. |
| FN | False Negative | The sample is predicted to be negative, but the true label is positive. |
| MIou | Mean Intersection over Union | where represents the number of categories. |
| MPA | Mean Pixel Accuracy | where represents the number of categories. |
| Accuracy | Pixel Accuracy |
| Network Models | Training Datasets | Experimental Results | ||
|---|---|---|---|---|
| MioU (%) | MPA (%) | Accuracy (%) | ||
| U-Net | dataset 1 | 80.58 | 86.64 | 98.88 |
| dataset 2 | 83.52 | 89.41 | 98.17 | |
| dataset 3 | 85.47 | 90.86 | 98.66 | |
| HRNetV2 | dataset 1 | 71.59 | 75.33 | 98.42 |
| dataset 2 | 77.88 | 82.85 | 97.57 | |
| dataset 3 | 78.06 | 82.94 | 97.97 | |
| PSPNet | dataset 1 | 70.45 | 73.53 | 98.40 |
| dataset 2 | 78.17 | 85.25 | 97.46 | |
| dataset 3 | 77.33 | 82.71 | 97.87 | |
| DeepLabV3+ | dataset 1 | 71.37 | 75.10 | 98.41 |
| dataset 2 | 76.36 | 82.39 | 97.31 | |
| dataset 3 | 76.66 | 81.38 | 97.84 | |
| Training Datasets | Network Models | |||
|---|---|---|---|---|
| U-Net | HRNetV2 | PSPNet | DeepLabV3+ | |
| dataset 1 |  |  |  |  |
| dataset 2 |  |  |  |  |
| dataset 3 |  |  |  |  |
| Training Datasets | Network Models | |||
|---|---|---|---|---|
| U-Net | HRNetV2 | PSPNet | DeepLabV3+ | |
| dataset 1 |  |  |  |  |
| dataset 2 |  |  |  |  |
| dataset 3 |  |  |  |  |
| Training Datasets | Network Models | |||
|---|---|---|---|---|
| U-Net | HRNetV2 | PSPNet | DeepLabV3+ | |
| dataset 1 |  |  |  |  |
| dataset 2 |  |  |  |  |
| dataset 3 |  |  |  |  |
| Original Crack Image | Crack True Contour | Network Model Segmentation Contour | ||
|---|---|---|---|---|
| Dataset 1 | Dataset 2 | Dataset 3 | ||
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
| Original Crack Image | Quantized Value | Dataset 1 | Dataset 2 | Dataset 3 |
|---|---|---|---|---|
 | MW | +0.672 | +10.738 | +9.606 |
| AW | +0.648 | +9.931 | +8.400 | |
 | MW | +0.141 | +11.537 | +10.302 |
| AW | +0.414 | +7.518 | +7.872 | |
 | MW | +1.997 | +5.941 | +5.260 |
| AW | +0.532 | +7.496 | +6.900 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, K.; Hao, M.; Shang, W.; Liu, J.; Meng, J.; Hu, Q.; He, P.; Li, S. Study on the Influence of Label Image Accuracy on the Performance of Concrete Crack Segmentation Network Models. Sensors 2024, 24, 1068. https://doi.org/10.3390/s24041068
Ma K, Hao M, Shang W, Liu J, Meng J, Hu Q, He P, Li S. Study on the Influence of Label Image Accuracy on the Performance of Concrete Crack Segmentation Network Models. Sensors. 2024; 24(4):1068. https://doi.org/10.3390/s24041068
Chicago/Turabian StyleMa, Kaifeng, Mengshu Hao, Wenlong Shang, Jinping Liu, Junzhen Meng, Qingfeng Hu, Peipei He, and Shiming Li. 2024. "Study on the Influence of Label Image Accuracy on the Performance of Concrete Crack Segmentation Network Models" Sensors 24, no. 4: 1068. https://doi.org/10.3390/s24041068