

CM-YOLOv8: Lightweight YOLO for Coal Mine Fully Mechanized Mining Face


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Predefined Anchor Box
3.2. Pruning Based on L1 Norm
| Algorithm 1. Channel L1 norm-based pruning algorithm |
| Input: Training data: X, pre-trained weights: W, hyperparameter group, |
| pruning strategy: |
| neural network training parameters (such as learning rate, batch size, etc.), |
| Output: Compressed weights |
| 1: for pruning strategy do |
| 2: Obtain θn based on W and hyperparameter group |
| 3: if Wn < θn do |
| 4: Channel L1 norm-based pruning on Wn |
| 5: else do |
| 6: Retrain the network |
| 7: end for |
3.3. Network Structure
4. Results
4.1. Experiment Introduction
4.1.1. Dataset
4.1.2. Experimental Environment and Training Strategies
4.1.3. Evaluation Indicators
4.2. Experiment Results
4.2.1. Quantitative Comparison of Different Models
4.2.2. Comparison of Loss Function Changes during Training for Different Kinds of Targets
4.2.3. Comparison of Computational and Model Parametric Quantities after Lightweight Pruning
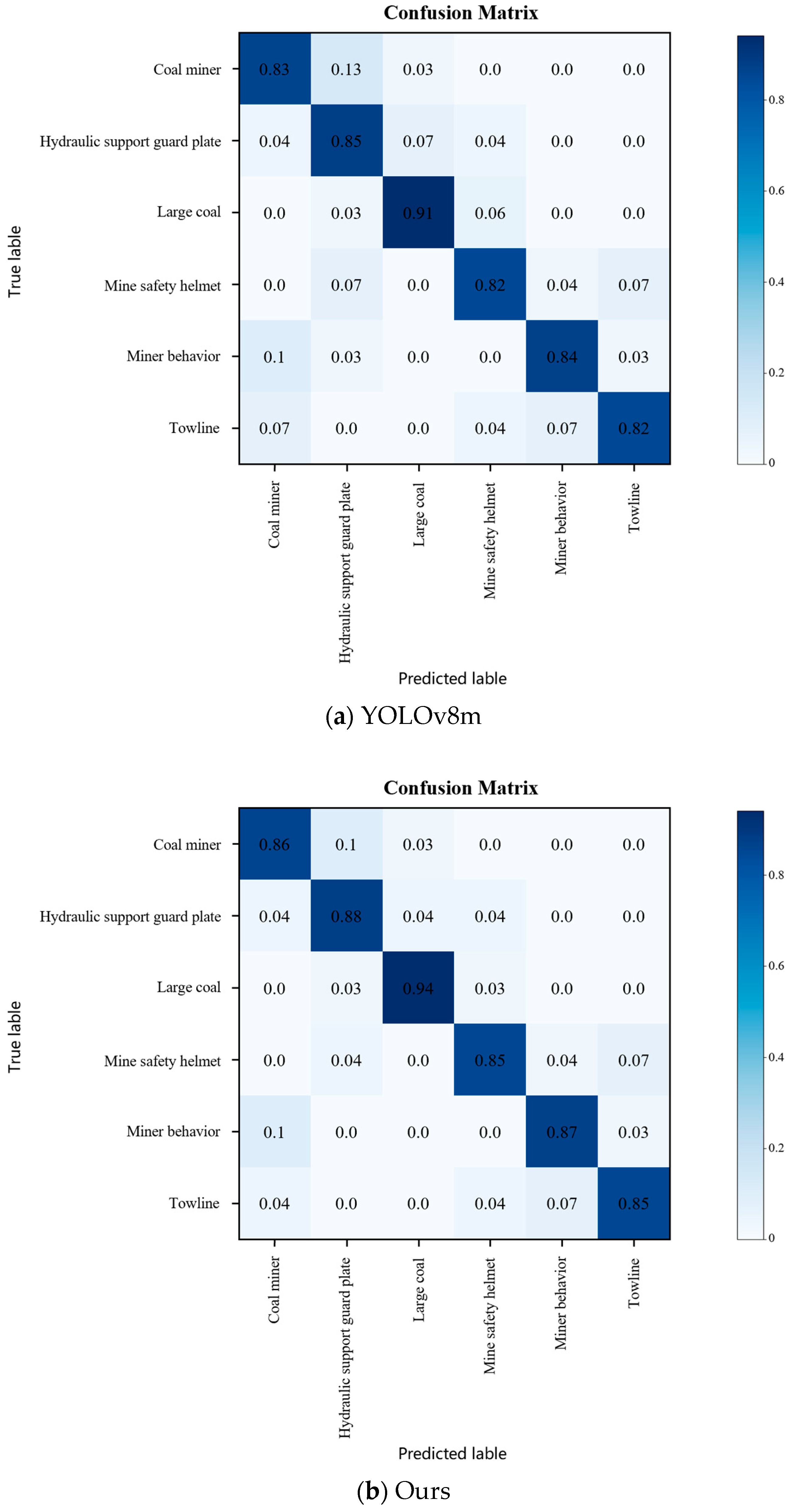
4.2.4. Comparison of Recognition Results for Visualization of Different Kinds of Targets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, C.H.; Bai, H.T.; Lu, Y.Y.; Bian, J.H.; Dong, Y.; Xu, H. Life-cycle assessment for coal-based methanol production in China. J. Clean. Prod. 2018, 188, 1004–1017. [Google Scholar] [CrossRef]
- Gao, Z.X.; Guo, H.Y.; Liu, X.L.; Wang, Q.; Lv, J.H.; Liu, S.; Yu, H.F.; Yin, X.J. Controlling mechanism of coal chemical structure on biological gas production characteristics. Int. J. Energy Res. 2020, 44, 5008–5016. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, X.W.; Patouillard, L.; Margni, M.; Bulle, C.; Hua, H.; Yuan, Z.W. Remarkable Spatial Disparity of Life Cycle Inventory for Coal Production in China. Environ. Sci. Technol. 2023, 57, 15443–15453. [Google Scholar] [CrossRef]
- Ma, T.J.; Chi, C.J. Spatial configuration and technology strategy of China’s green coal-electricity system. J. Renew. Sustain. Energy 2012, 4, 031806. [Google Scholar] [CrossRef]
- Zhao, X.L.; Lyon, T.P.; Wang, F.; Song, C. Why do electricity utilities cooperate with coal suppliers? A theoretical and empirical analysis from China. Energy Policy 2012, 46, 520–529. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, C.; Liu, W.Y. Impact of Coal-Electricity Integration on China’s Power Grid Development Strategy. In Proceedings of the 3rd International Conference on Energy, Environment and Sustainable Development (EESD 2013), Shanghai, China, 12–13 November 2013; pp. 2600–2605. [Google Scholar]
- Wei, J.; Chen, H.; Qi, H. Who reports low safety commitment levels? An investigation based on Chinese coal miners. Saf. Sci. 2015, 80, 178–188. [Google Scholar] [CrossRef]
- Wu, B.; Wang, J.X.; Qu, B.L.; Qi, P.Y.; Meng, Y. Development, effectiveness, and deficiency of China’s Coal Mine Safety Supervision System. Resour. Policy 2023, 82, 103524. [Google Scholar] [CrossRef]
- Li, X.C.; Tao, X.Y. Study on decision-making system of coal mines environment management base on integrated artificial intelligence method. In Proceedings of the 5th China-Japan International Symposium on Industrial Management, Beijing, China, 16–18 October 2000; pp. 430–433. [Google Scholar]
- Qin, Z.; Chen, S.Y.; Xu, X.L.; Zhao, M.H. Research on Key Technologies and System Construction of Smart Mine. In Proceedings of the 5th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Electr Network, Singapore, 17–19 July 2020; pp. 116–121. [Google Scholar]
- Yu, X.C.; Li, X.W. Sound Recognition Method of Coal Mine Gas and Coal Dust Explosion Based on GoogLeNet. Entropy 2023, 25, 412. [Google Scholar] [CrossRef]
- Zhang, Y.X.; Tao, Y.R.; Li, S.H. An efficient method for recognition of coal/gangue with thermal imaging technique. Int. J. Coal Prep. Util. 2023, 43, 1665–1678. [Google Scholar] [CrossRef]
- Yang, J.J.; Luo, W.J.; Zhang, Y.C.; Chang, B.S.; Zheng, R.L.; Wu, M. Establishment of a Coal Mine Roadway Model Based on Point Cloud Feature Matching. Math. Probl. Eng. 2022, 2022, 8809521. [Google Scholar] [CrossRef]
- Ding, S.F.; An, Y.X.; Zhang, X.K.; Wu, F.L.; Xue, Y. Wavelet twin support vector machines based on glowworm swarm optimization. Neurocomputing 2017, 225, 157–163. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.Y.; Gao, L.; Zhang, Y.Y. A New Convolutional Neural Network-Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron. 2018, 65, 5990–5998. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Dai, Y.M.; Wu, Y.Q.; Zhou, F.; Barnard, K. Attentional Local Contrast Networks for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Chen, H.; Qi, H.; Feng, Q. Characteristics of direct causes and human factors in major gas explosion accidents in Chinese coal mines: Case study spanning the years 1980–2010. J. Loss Prev. Process Ind. 2013, 26, 38–44. [Google Scholar] [CrossRef]
- Wang, K.; Wang, L.; Ju, Y.; Dong, H.Z.; Zhao, W.; Du, C.G.; Guo, Y.Y.; Lou, Z.; Gao, H. Numerical study on the mechanism of air leakage in drainage boreholes: A fully coupled gas-air flow model considering elastic-plastic deformation of coal and its validation. Process Saf. Environ. Prot. 2022, 158, 134–145. [Google Scholar] [CrossRef]
- Agioutantis, Z.; Luxbacher, K.; Karmis, M.; Schafrik, S. Development of an atmospheric data-management system for underground coal mines. J. South. Afr. Inst. Min. Metall. 2014, 114, 1059–1063. [Google Scholar]
- Zhang, L.Y.; Yang, W.; Hao, B.A.; Yang, Z.F.; Zhao, Q. Edge Computing Resource Allocation Method for Mining 5G Communication System. IEEE Access 2023, 11, 49730–49737. [Google Scholar] [CrossRef]
- Li, Y.T.; Fan, Q.S.; Huang, H.S.; Han, Z.G.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]
- Jang, J.G.; Quan, C.; Lee, H.D.; Kang, U. Falcon: Lightweight and accurate convolution based on depthwise separable convolution. Knowl. Inf. Syst. 2023, 65, 2225–2249. [Google Scholar] [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Sharma, V.K.; Mir, R.N. A comprehensive and systematic look up into deep learning based object detection techniques: A review. Comput. Sci. Rev. 2020, 38, 100301. [Google Scholar] [CrossRef]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef]
- Wang, X.Y.; Han, T.X.; Yan, S.C. An HOG-LBP Human Detector with Partial Occlusion Handling. In Proceedings of the 12th IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 32–39. [Google Scholar]
- Davarzani, R.; Mozaffari, S.; Yaghmaie, K. Perceptual image hashing using center-symmetric local binary patterns. Multimed. Tools Appl. 2016, 75, 4639–4667. [Google Scholar] [CrossRef]
- Yang, J.C.; Yu, K.; Gong, Y.H.; Huang, T. Linear Spatial Pyramid Matching Using Sparse Coding for Image Classification. In Proceedings of the IEEE-Computer-Society Conference on Computer Vision and Pattern Recognition Workshops, Miami Beach, FL, USA, 20–25 June 2009; pp. 1794–1801. [Google Scholar]
- Chatfield, K.; Lempitsky, V.; Vedaldi, A.; Zisserman, A. The devil is in the details: An evaluation of recent feature encoding methods. In Proceedings of the 22nd British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Tong, K.; Wu, Y.Q. Deep learning-based detection from the perspective of small or tiny objects: A survey. Image Vis. Comput. 2022, 123, 104471. [Google Scholar] [CrossRef]
- Zhang, T.W.; Zhang, X.L.; Ke, X. Quad-FPN: A Novel Quad Feature Pyramid Network for SAR Ship Detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- Shi, J.; Zhou, Y.L.; Xia, W.J.; Zhang, Q.Z. Target Detection Based on Improved Mask Rcnn in Service Robot. In Proceedings of the 38th Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8519–8524. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Li, P.; Han, T.Y.; Ren, Y.F.; Xu, P.; Yu, H.L. Improved YOLOv4-tiny based on attention mechanism for skin detection. Peerj Comput. Sci. 2023, 9, e1288. [Google Scholar] [CrossRef]
- Liao, S.D.; Huang, C.Y.; Liang, Y.; Zhang, H.Q.; Liu, S.F. Solder Joint Defect Inspection Method Based on ConvNeXt-YOLOX. IEEE Trans. Compon. Packag. Manuf. Technol. 2022, 12, 1890–1898. [Google Scholar] [CrossRef]
- Saydirasulovich, S.N.; Abdusalomov, A.; Jamil, M.K.; Nasimov, R.; Kozhamzharova, D.; Cho, Y.I. A YOLOv6-Based Improved Fire Detection Approach for Smart City Environments. Sensors 2023, 23, 3161. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.L.; Jiang, S.; Zhao, E.L.; Liu, Y.L.; Zhu, H.C.; Wang, W.W.; Wang, R.Y. Detection of Camellia oleifera Fruit in Complex Scenes by Using YOLOv7 and Data Augmentation. Appl. Sci. 2022, 12, 11318. [Google Scholar] [CrossRef]
- Liu, B.; Bai, X.Y.; Su, X.Y.; Song, C.X.; Yao, Z.H.; Wei, X.; Zhang, H.X. DAC-PPYOLOE plus: A Lightweight Real-time Detection Model for Early Apple Leaf Pests and Diseases under Complex Background. In Proceedings of the 47th IEEE-Computer-Society Annual International Conference on Computers, Software, and Applications (COMPSAC), Torino, Italy, 27–29 June 2023; pp. 174–182. [Google Scholar]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single Image Super-Resolution via a Holistic Attention Network. In Proceedings of the InComputer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Cheng, D.Q.; Chen, L.L.; Lv, C.; Guo, L.; Kou, Q.Q. Light-Guided and Cross-Fusion U-Net for Anti-Illumination Image Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8436–8449. [Google Scholar] [CrossRef]
- Wu, Q.; Zeng, H.F.; Zhang, J.; Xia, H.J. Multi-image hybrid super-resolution reconstruction via interpolation and multi-scale residual networks. Meas. Sci. Technol. 2023, 34, 075403. [Google Scholar] [CrossRef]
- Yang, X.; Lin, X.H.; Yao, W.Q.; Ma, H.W.; Zheng, J.L.; Ma, B.L. A Robust LiDAR SLAM Method for Underground Coal Mine Robot with Degenerated Scene Compensation. Remote Sens. 2023, 15, 186. [Google Scholar] [CrossRef]
- Kirkwood, L.; Shehab, E.; Baguley, P.; Amorim-Melo, P.; Durazo-Cardenas, I. Challenges in cost analysis of innovative maintenance of distributed high-value assets. In Proceedings of the 3rd International Conference on Through-life Engineering Services (TESConf), Cranfield, UK, 4–5 November 2014; pp. 148–151. [Google Scholar]
- Pan, H.G.; Shi, Y.H.; Lei, X.Y.; Wang, Z.; Xin, F.F. Fast identification model for coal and gangue based on the improved tiny YOLO v3. J. Real-Time Image Process 2022, 19, 687–701. [Google Scholar] [CrossRef]
- Zhang, Y.C.; Wang, J.S.; Yu, Z.W.; Zhao, S.; Bei, G.X. Research on intelligent detection of coal gangue based on deep learning. Measurement 2022, 198, 111415. [Google Scholar] [CrossRef]
- Fan, J.W.; Du, M.L.; Liu, L.; Li, G.; Wang, D.C.; Liu, S. Macerals particle characteristics analysis of tar-rich coal in northern Shaanxi based on image segmentation models via the U-Net variants and image feature extraction. Fuel 2023, 341, 127757. [Google Scholar] [CrossRef]
- Liang, B.; Wang, Z.B.; Si, L.; Wei, D.; Gu, J.H.; Dai, J.B. A Novel Pressure Relief Hole Recognition Method of Drilling Robot Based on SinGAN and Improved Faster R-CNN. Appl. Sci. 2023, 13, 513. [Google Scholar] [CrossRef]
- Lou, H.T.; Duan, X.H.; Guo, J.M.; Liu, H.Y.; Gu, J.S.; Bi, L.Y.; Chen, H.A. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.J.; Zhang, X.H.; Ma, B.; Wang, Y.Q.; Wu, Y.J.; Yan, J.X.; Liu, Y.W.; Zhang, C.; Wan, J.C.; Wang, Y.; et al. An open dataset for intelligent recognition and classification of abnormal condition in longwall mining. Sci. Data 2023, 10, 416. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.S.; Zhou, J.; Zhang, B.; Dai, S.Y.; Shen, M.X. Visual detection on posture transformation characteristics of sows in late gestation based on Libra R-CNN. Biosyst. Eng. 2022, 223, 219–231. [Google Scholar] [CrossRef]
- Wang, D.S.; Li, Z.L.; Du, X.Q.; Ma, Z.H.; Liu, X.G. Farmland Obstacle Detection from the Perspective of UAVs Based on Non-local Deformable DETR. Agriculture 2022, 12, 983. [Google Scholar] [CrossRef]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision Transformer Adapter for Dense Predictions. arXiv 2022, arXiv:2205.08534. [Google Scholar]
- Tian, Y.N.; Yang, G.D.; Wang, Z.; Wang, H.; Li, E.; Liang, Z.Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Chen, K.; Pang, J.M.; Wang, J.Q.; Xiong, Y.; Li, X.X.; Sun, S.Y.; Feng, W.S.; Liu, Z.W.; Shi, J.P.; Ouyang, W.L.; et al. Hybrid Task Cascade for Instance Segmentation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4969–4978. [Google Scholar]
- Yang, R.J.; Li, W.F.; Shang, X.N.; Zhu, D.P.; Man, X.Y. KPE-YOLOv5: An Improved Small Target Detection Algorithm Based on YOLOv5. Electronics 2023, 12, 817. [Google Scholar] [CrossRef]
- Yang, Z.J.; Feng, H.L.; Ruan, Y.P.; Weng, X. Tea Tree Pest Detection Algorithm Based on Improved Yolov7-Tiny. Agriculture 2023, 13, 1031. [Google Scholar] [CrossRef]
- Sun, H.Y.; Zhang, S.L.; Tian, X.; Zou, Y.Y. Pruning DETR: Efficient end-to-end object detection with sparse structured pruning. Signal Image Video Process 2023, 18, 125–139. [Google Scholar] [CrossRef]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. DAB-DETR: Dynamic Anchor Boxes are Better Queries for DET. arXiv 2022, arXiv:2201.12329. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Configuration |
|---|---|
| CPU | Intel Core i9-13900HX (Intel Corporation, Shanghai, China) (2.2 GHz, 6 cores, 12 threads) |
| RAM | 16 GB DDR4 2400 MHz |
| GPU | NVIDIA GeForce GTX 4070 Ti × 2 (NVIDIA Corporation, Beijing, China) |
| GPU memory size | 16 GB |
| cuDNN | 8.9.6 |
| CUDA | 12.1 |
| Deep learning framework | python 3.8.18 + pytorch 2.1.2 |
| Parameters | Value |
|---|---|
| Epochs | 300 |
| Initial learning rate | 1 × 10−2 |
| Final learning rate | 1 × 10−4 |
| Momentum | 0.937 |
| Weight-Decay | 5 × 10−4 |
| Batch size | 4 |
| Mosaic | 1.0 |
| (Wise-IoU) | 1.9 |
| (Wise-IoU) | 3 |
| Input image size | 640 × 640 |
| Number of images | 138,004 |
| Optimizer | SGD |
| Close Mosaic | Last 10 epochs |
| Method | YOLOv7 | DETA | ViT-Adapter-L | YOLOv8m | Ours | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | Precision | Recall | mAP 0.5 | mAP 0.5:0.95 | Precision | Recall | mAP 0.5 | mAP 0.5:0.95 | Precision | Recall | mAP 0.5 | mAP 0.5:0.95 | Precision | Recall | mAP 0.5 | mAP 0.5:0.95 | Precision | Recall | mAP 0.5 | mAP 0.5:0.95 |
| Coal miners | 0.965 | 0.968 | 0.986 | 0.773 | 0.967 | 0.970 | 0.976 | 0.684 | 0.961 | 0.965 | 0.966 | 0.702 | 0.968 | 0.971 | 0.988 | 0.775 | 0.968 | 0.970 | 0.986 | 0.774 |
| Mine safety helmet | 0.942 | 0.958 | 0.976 | 0.679 | 0.948 | 0.965 | 0.960 | 0.601 | 0.945 | 0.951 | 0.961 | 0.624 | 0.946 | 0.962 | 0.980 | 0.680 | 0.943 | 0.959 | 0.979 | 0.680 |
| Hydraulic support guard plate | 0.972 | 0.927 | 0.978 | 0.813 | 0.971 | 0.932 | 0.958 | 0.762 | 0.963 | 0.928 | 0.963 | 0.753 | 0.978 | 0.927 | 0.974 | 0.817 | 0.972 | 0.925 | 0.971 | 0.812 |
| Large Coal | 0.814 | 0.776 | 0.868 | 0.572 | 0.820 | 0.771 | 0.815 | 0.549 | 0.811 | 0.776 | 0.854 | 0.532 | 0.815 | 0.780 | 0.873 | 0.580 | 0.814 | 0.786 | 0.871 | 0.574 |
| Miners’ behaviors | 0.880 | 0.880 | 0.913 | 0.752 | 0.884 | 0.886 | 0.914 | 0.718 | 0.879 | 0.874 | 0.928 | 0.714 | 0.882 | 0.882 | 0.926 | 0.754 | 0.883 | 0.879 | 0.924 | 0.754 |
| Towline | 0.995 | 0.997 | 0.997 | 0.916 | 0.996 | 0.998 | 0.989 | 0.915 | 0.995 | 0.992 | 0.989 | 0.871 | 0.997 | 0.997 | 0.996 | 0.920 | 0.997 | 0.996 | 0.996 | 0.919 |
| Average | 0.928 | 0.918 | 0.953 | 0.751 | 0.931 | 0.920 | 0.935 | 0.705 | 0.926 | 0.914 | 0.944 | 0.699 | 0.931 | 0.920 | 0.956 | 0.754 | 0.930 | 0.920 | 0.955 | 0.752 |
| Method | mAP:0.5(%) | Params(M) | GFLOPs |
|---|---|---|---|
| YOLOv3 [62] | 85.9 | 61.5 | 193.9 |
| YOLOv5m [64] | 87.7 | 21.8 | 39.4 |
| YOLOv7 [44] | 95.3 | 36.5 | 103.5 |
| YOLOv7-tiny [65] | 78.4 | 6.0 | 13.1 |
| YOLOv8m [27] | 95.6 | 25.9 | 78.9 |
| Faster-RCNN [20] | 86.2 | 40.2 | 207.3 |
| DETR [66] | 79.4 | 41.9 | 225.7 |
| DAB-DETR [67] | 90.3 | 44.8 | 256.1 |
| HTC [63] | 82.3 | 80.5 | 441.3 |
| Ours (group = 2) | 95.5 | 15.6 | 43.7 |
| Ours (group = 4) | 94.1 | 9.7 | 23.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Y.; Mao, S.; Li, M.; Wu, Z.; Kang, J. CM-YOLOv8: Lightweight YOLO for Coal Mine Fully Mechanized Mining Face. Sensors 2024, 24, 1866. https://doi.org/10.3390/s24061866
Fan Y, Mao S, Li M, Wu Z, Kang J. CM-YOLOv8: Lightweight YOLO for Coal Mine Fully Mechanized Mining Face. Sensors. 2024; 24(6):1866. https://doi.org/10.3390/s24061866
Chicago/Turabian StyleFan, Yingbo, Shanjun Mao, Mei Li, Zheng Wu, and Jitong Kang. 2024. "CM-YOLOv8: Lightweight YOLO for Coal Mine Fully Mechanized Mining Face" Sensors 24, no. 6: 1866. https://doi.org/10.3390/s24061866