4.1. 2D Case
In the simplest, two-dimensional scenario, differences in the height of base stations’ antennas and mobile nodes are omitted. Distance-difference values were calculated on an X–Y plane. Both the Gauss–Newton and the Levenberg–Marquardt iterative algorithms failed to provide correct position estimation results when the starting point for the first iteration was located in the origin of the local coordinate system, which means
,
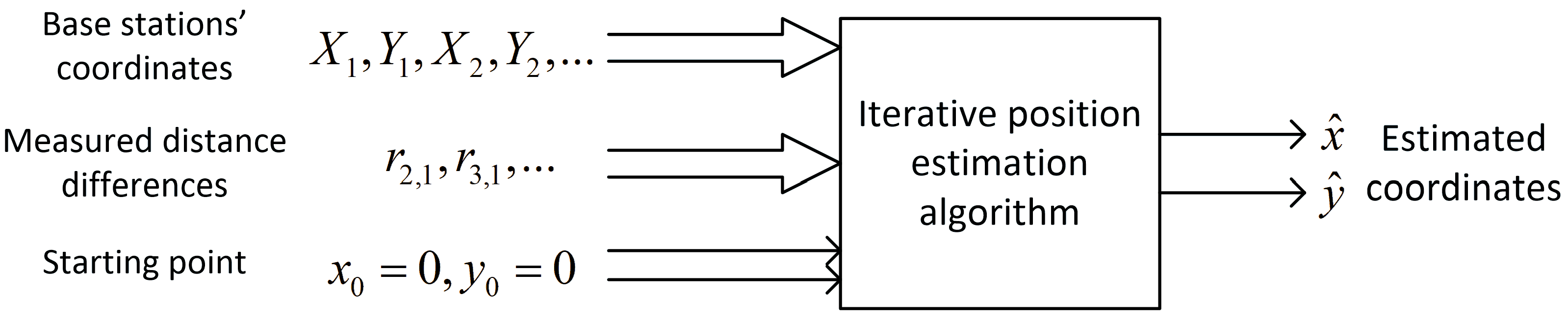
. In such cases, a set of input data for a position estimation algorithm consists of base stations’ coordinates
and the results of distance-difference measurements
as presented in the block diagram in
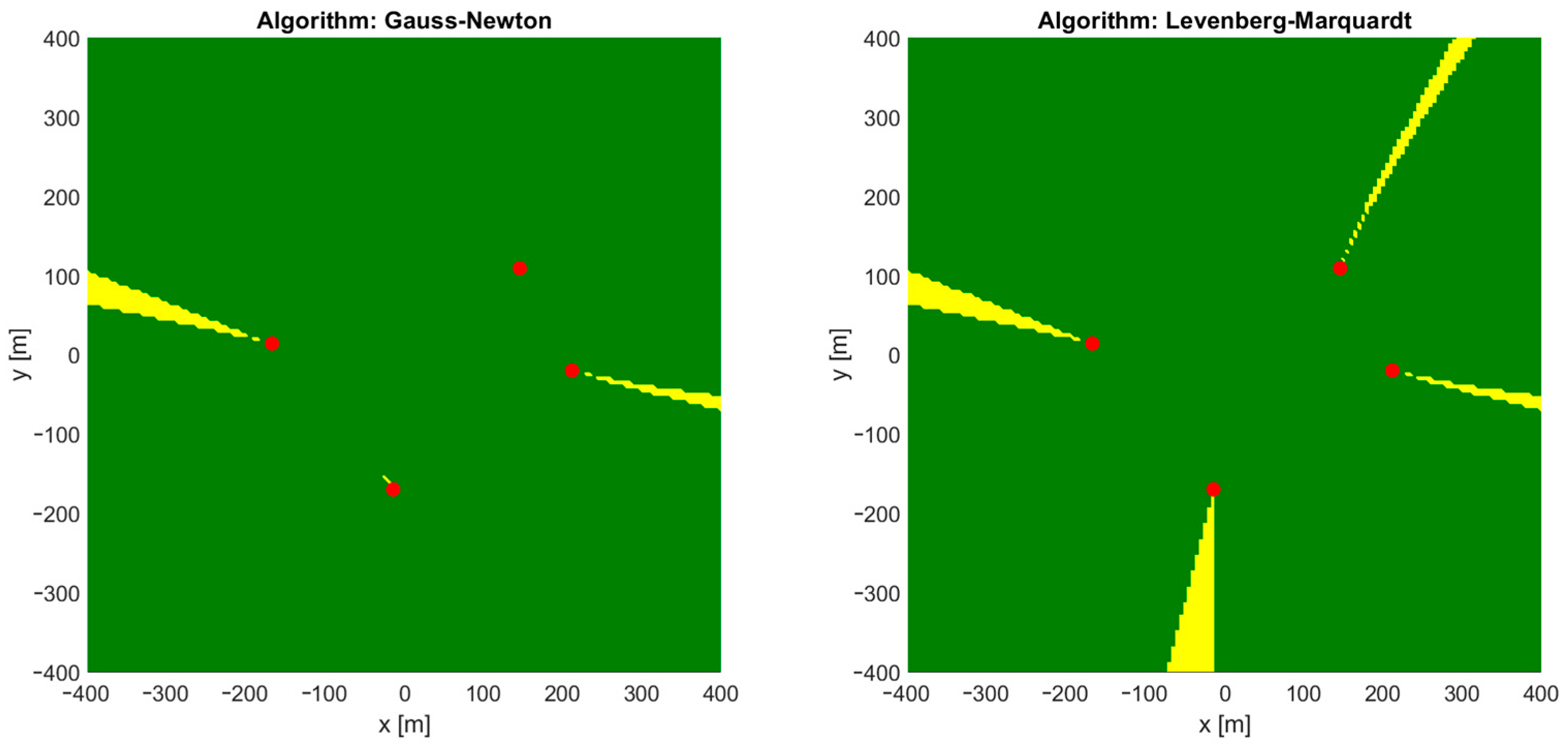
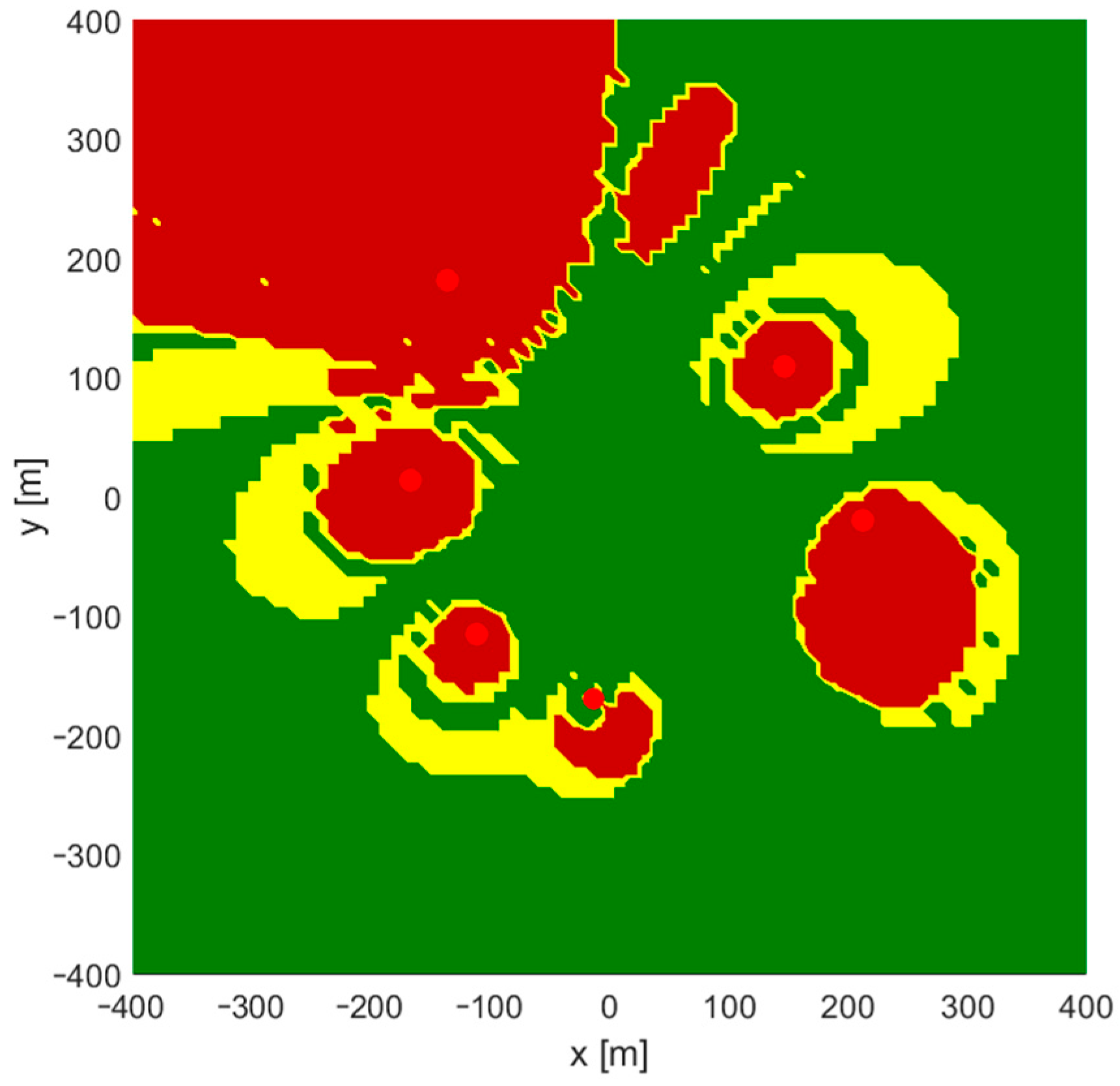
Figure 2. Regions in which these iterative algorithms returned incorrect coordinates or were even divergent are marked yellow on charts in
Figure 3. It should be noted that some impact on the convergence may be seen when a different number of distance-difference equations are used in iterative algorithms. In the case of
base stations, only
distance-difference values (4) are independent, while others are simply linear combinations that do not provide additional data. In the simulator used in our investigation, a full set of
positioning equations was used, and therefore all the results presented later in the paper were obtained for an overdetermined system of equations. However, it has been checked that conclusions on the usability of FNN to indicate initial coordinates for iterative position estimation are also valid when the numbers of position equations are reduced.
The results of a convergence check for the 2D TDoA positioning system are summarized in
Table 3. The average and maximum number of iterations were counted only for cases which converged to the correct coordinates of the mobile terminal.
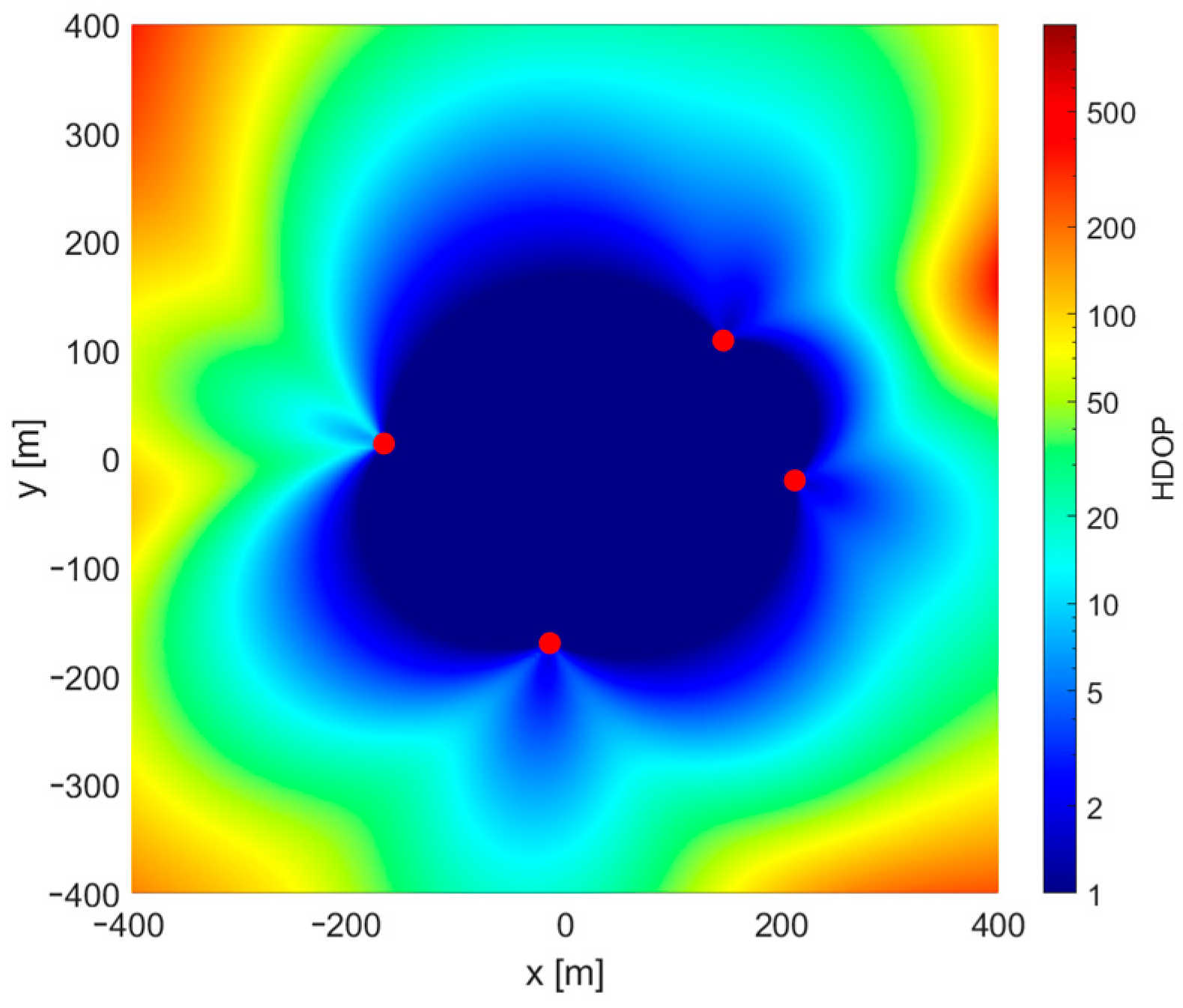
It is somehow surprising that there is no obvious coincidence of regions of incorrect convergence and regions with high values of a horizontal dilution of precision (HDOP), which is a good measure of relation between system geometry and possible position estimation accuracy. Comparing
Figure 3 and
Figure 4, it may be said that convergence problems occur mostly in regions located on the opposite side of one of the base stations from the starting point.
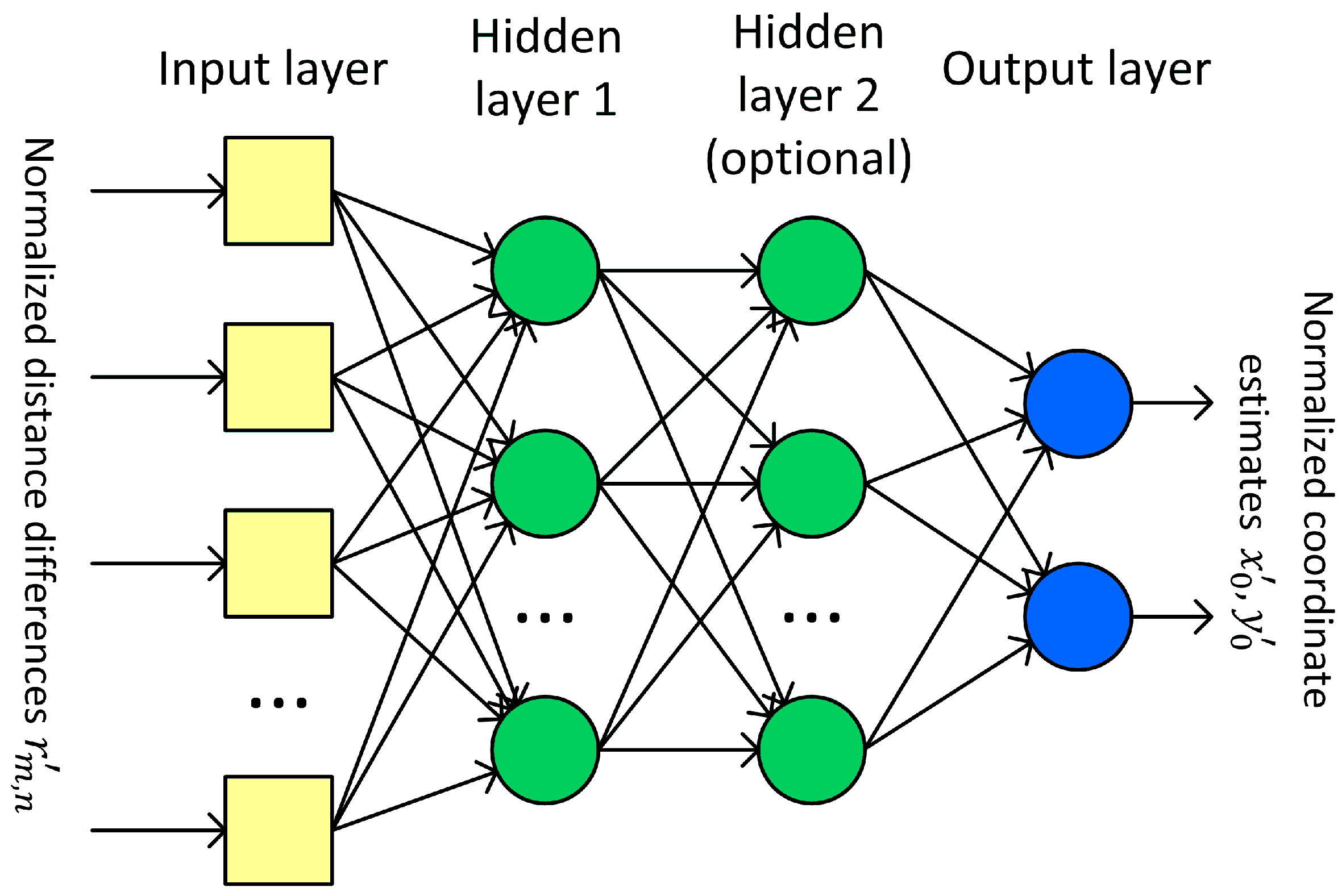
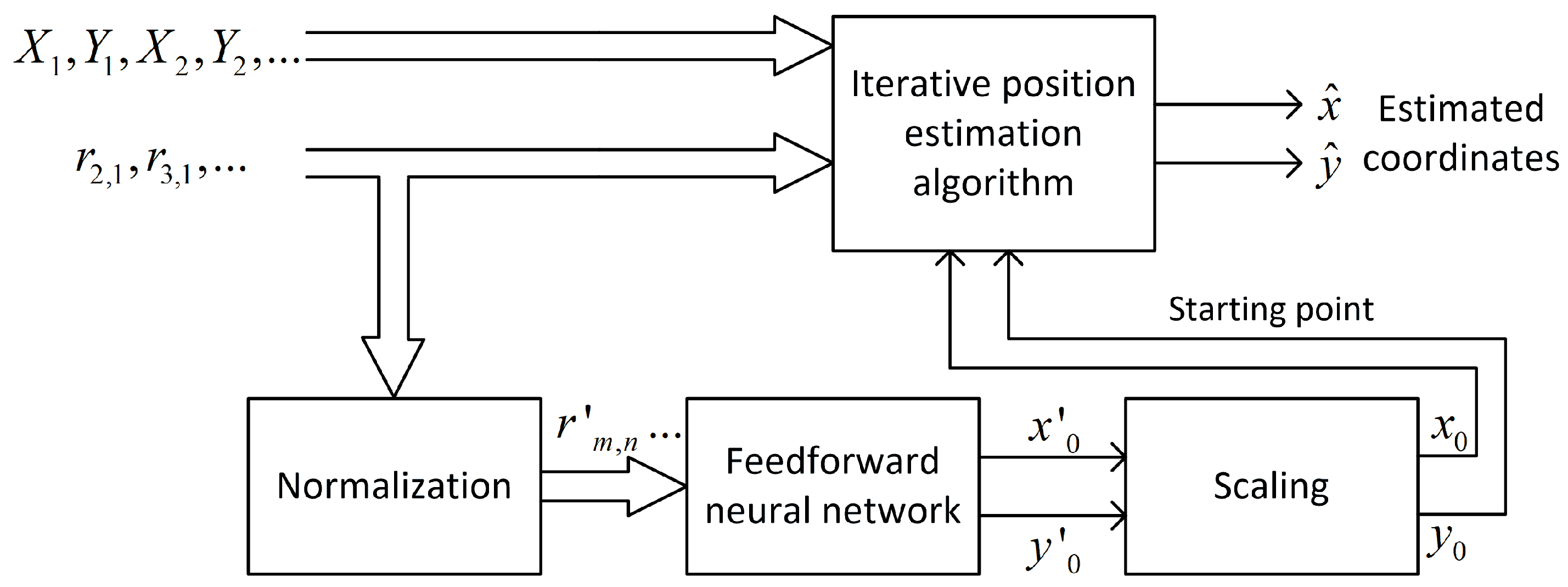
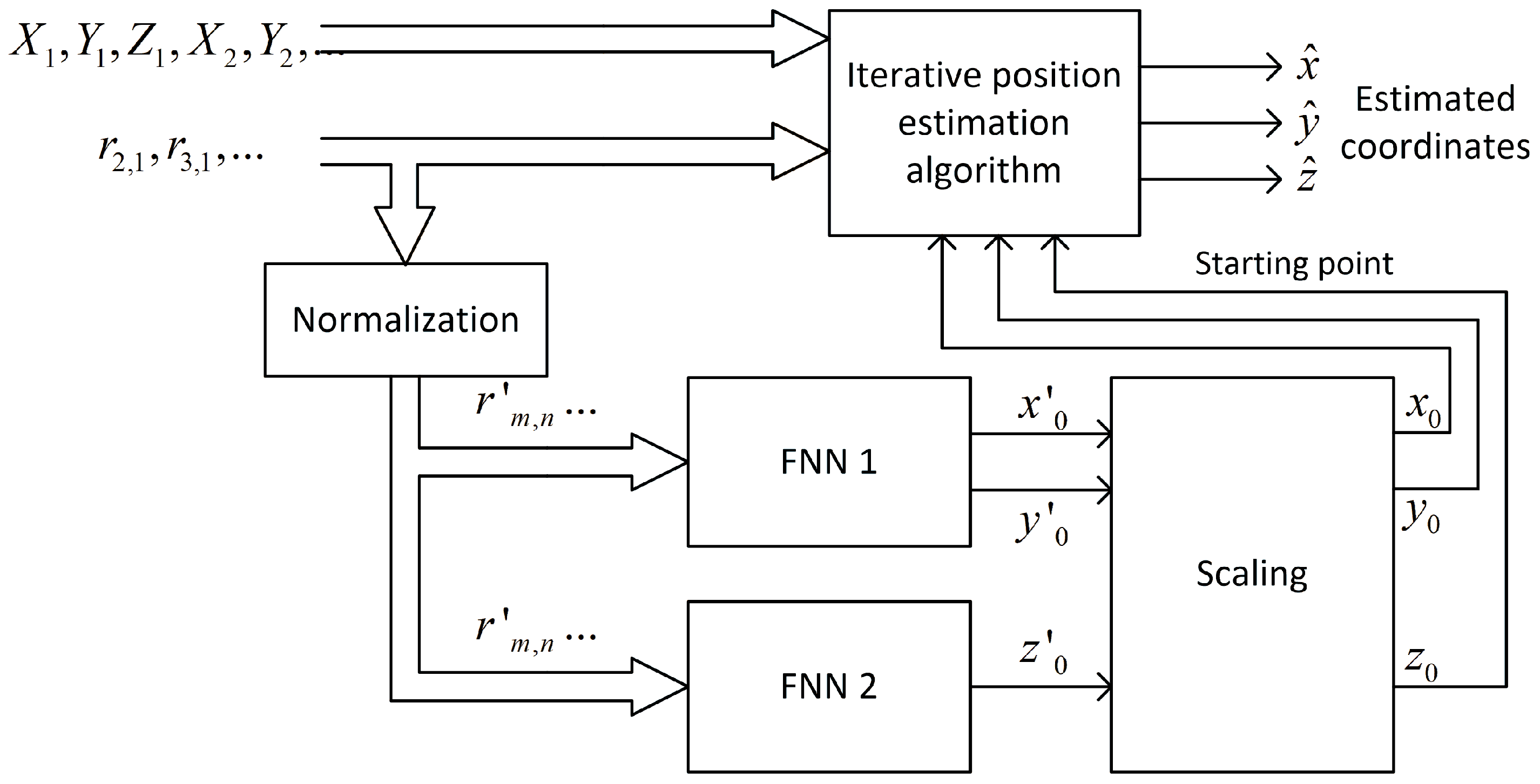
A feedforward neural network uses normalized distance-difference values (13) to estimate the scaled initial position of a mobile terminal
as it is presented in the block diagram in
Figure 5. It was assumed that the learned network would only be used in one scenario, i.e., with an unchanging distribution of base stations. For this reason, the coordinates of the reference stations are not an input to the neural network.
To carry out the neural network learning process, it is necessary to prepare reference data. If the neural network is used as the sole tool to estimate position of a mobile object, the training dataset typically consists of reference data from points deployed uniformly over whole area of system operation and the goal of learning is to achieve the best quality of position estimation in terms of RMS or maximal position estimation error. But in our investigation, rough estimates of mobile terminal positions are used as starting points for fine position estimation using iterative algorithms. Therefore, although selecting the closest coordinates should usually result in a fast convergence with a low number of required iterations, correct convergence can be obtained also for an unlimited number of other possible candidates for starting points, even located far away from true terminal position. So, for the specified set of distance-difference data (1), there is more than one possible set of output data that allows us to achieve a convergence of iterative position estimation algorithms. It is also important that the closest approximation of the mobile terminal position may not be the best method of evaluation of the neural network effectiveness, because in the search for the simplest network structure, networks giving higher errors of position estimation may turn out to be better candidates. However, the definition of network training goals and the cost function for our investigation is not trivial, and finding the simplest FNN structure may require adaptive changes in training datasets during the training process, which is not already implemented in the tool used for FNN experiments. Therefore, our search for FNN structure was conducted by training the FNN using datasets with the true coordinates of the mobile terminal, selected uniformly and non-uniformly in a predefined area of system operation. It may of course raise question of whether the obtained results are really the simplest structures of FNN capable of solving the convergence problem, but, as it will be shown later, in all tested scenarios, the obtained network structures are really promising.
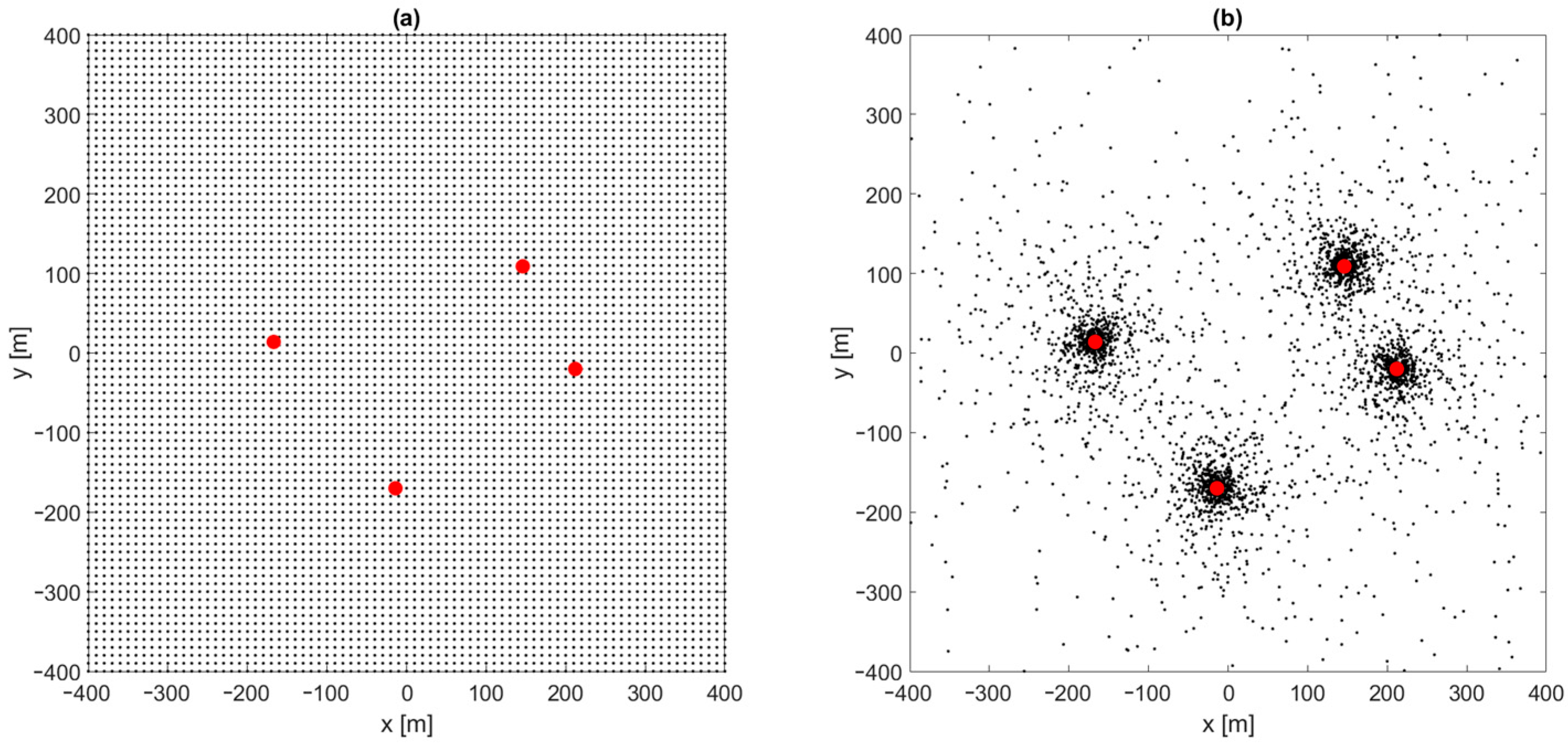
The investigation of position estimation convergence improvement by FNN was started with a learning dataset consisting of reference distance-difference values for mobile terminal positions generated uniformly in the whole area of system operation in a grid with
and
coordinate step equal 10 m (
Figure 6a). Therefore, for an area of 800 × 800 m, the reference dataset size was 6561. All simulations were made using Matlab (version R2022b) with a Deep Learning toolbox (version 14.5), using built-in network training procedures. Unless otherwise stated, the Levenberg–Marquardt algorithm with an RMS error function was used to train the network, with a random division of the reference dataset into three groups: 70% training data, 15% validation data and 15% test data. Please note that the Levenberg–Marquardt algorithm occurs twice in this article: as an iterative position estimation algorithm and as an FNN training algorithm. The initialization of neuron weights and biases in FNN was made using the Nguyen-Widrow algorithm, which contains some degree of randomness; therefore, repetitions of network training may result in different network parameters and performances. Thus, the presented data corresponds to the best results obtained in 10 to 30 repetitions of FNN training process. The performed simulations can be summarized in the following steps:
Generate test points uniformly distributed in the whole system area with an and step equal to 5 m (25,921 point in total), and calculate TDoA data for all test points;
Run the iterative position estimation algorithm (Gauss–Newton or Levenberg–Marquardt) with TDoA data corresponding to all test points, with the starting point in origin (, ), and check convergence to correct coordinates;
Generate reference points for the neural network training: uniformly with an and step equal to 10 m (6561 points in total), or non-uniformly using the rules described later in the article; calculate TDoA data for all reference points;
Normalize TDoA data and reference points’ coordinates and train the feedforward neural network to predict normalized coordinates using normalized TDoA input data;
Verify the convergence of the iterative position estimation algorithm (G–N or L–M) using a larger set of test points from step 1 with initial coordinates calculated using the output of a neural network trained using a smaller set of training points from step 3.
Training the network using a smaller set of training points compared to the set of test points used to verify the convergence of iterative position estimation algorithms allows us to check its ability to generalize the solution by FNN. In this way, in step no. 5, the trained network is used to predict the coordinates of the mobile object using data that was not previously used to train the network.
Table 4 and
Table 5 show the selected numerical results of the convergence analysis of the iterative algorithms with the starting points indicated by the neural networks, obtained using Gauss–Newton and Levenberg–Marquardt algorithms. The size of the input layer, which is 12, is determined by the number of distance-difference values
for any
. The input layer is always linear. The transfer function of the output layer is by default linear, but a non-linear case has also been checked. The size of the output layer equals the number of estimated coordinates. Various combinations of transfer functions have been checked in networks with one and two hidden layers. The symbol “lin” denotes the linear transfer function, “tanh” is the hyperbolic tangent function, “log” is the logistic sigmoid function, “ell” is the Elliot activation function and “rad” is the radial basis transfer function. For the selected neural network configuration: the number of layers, activation functions in all layers and for the two-layer case, the number of neurons in the second layer and the size of the first hidden layer was reduced by one starting from several dozen, until it was not possible to obtain a 100% convergence of position estimation. Then, another network configuration was selected (e.g., a different activation function) and the simulation process was repeated.
Data in both
Table 4 and
Table 5 are arranged in some subcategories that differ, e.g., by the number of hidden layers or activation functions in the first, the second or both hidden layers. Data in the rows printed in bold indicates the smallest network size (optimal configuration in terms of computational complexity) that achieved a 100% convergence of position estimation in these subcategories. In addition, some examples of neural networks much larger than required are also presented (e.g., the first three rows in
Table 4) to show that an increasing accuracy of position estimation using FNN results in a slightly lower average number of iterations using both iterative algorithms (G–N and L–M). In turn, some examples of networks slightly smaller than the minimum network configurations marked in bold are also included to show that the degradation in the convergence ratio caused by reducing the FNN size below a critical value is not rapid and only causes convergence problems in a few test points out of over twenty-five thousand.
From the results presented in
Table 4, even for networks with linear inputs and output layers and only one hidden layer with a hyperbolic tangent activation function, only eight neurons in hidden layers were necessary to obtain the convergence of the Gauss–Newton position estimation algorithm. A higher number of neurons in hidden layers obviously increased the quality of rough position estimation for the first iteration, but it had only a marginal impact on the average number of iterations needed to reach a final position estimation. On the other side, networks with seven or less neurons in hidden layers were not able to provide correct starting point coordinates in at least one of the tested points. It must be pointed out that a required hidden layer size of only eight neurons is already surprisingly small; however, it cannot be precluded that networks with even lower numbers of neurons but trained in different ways or with different structures are also able to estimate correct initial coordinates, reaching convergence in all test points. Thus, more tests were needed.
A change in the activation function in the output layer from a linear to hyperbolic tangent worsened the results, probably because the region of high variability of the tanh function values in output layers corresponds to the center of the area of the positioning system operation. Therefore, the output layer activation function was kept linear. The logistic sigmoid function in hidden layers gave almost exactly the same results as the hyperbolic tangent, which is not surprising as the logistic sigmoid function can be obtained by the proper scaling of tanh. From other activation functions that are differentiable in the entire domain, the Elliot sigmoid function and the radial basis function have been checked as potential candidates for hidden layers, but obtained results were significantly worse compared to hyperbolic tangent. Also, different network training algorithms and different error functions (mean error, sum of squared errors) could not outperform the results obtained using the Levenberg–Marquardt training algorithm with mean squared error as the error function.
Further, tests were conducted with networks consisting of two hidden layers, both using a hyperbolic tangent activation function. The smallest configurations of hidden layers in terms of the total number of neurons with non-linear processing, which allows for obtaining a convergence of position estimations in all tested points, included the following: two layers with four neurons, a first layer with six neurons, followed by a second hidden layer with three neurons and first layer with twelve neurons, followed by a second layer with two neurons only. Any of these configurations could not outperform the network with one hidden layer working with eight neurons, so the minimal network configuration seems to be eight non-linear neurons, no matter if they are in one or two hidden layers.
The results of the convergence test for the Levenberg–Marquardt iterative position estimation algorithm, presented in
Table 5, are a little better than those obtained using the Gauss–Newton algorithm in the case of FNN with two hidden layers, which is unexpected as the L–M algorithm with fixed starting points had a lower probability of convergence than G–N (see
Table 3). For example, for the G–N algorithm, a minimal FNN configuration with four tanh neurons in the second layer required also four tanh neurons in the first hidden layer (a total of eight non-linear neurons, the smallest configuration of a two-layer network in this scenario) and three neurons in the second layer required six neurons in the first layer (nine in total). But, in the case of the L–M algorithm, four tanh neurons in the first hidden layer required only three neurons in the second layer (a total of seven non-linear neurons, the smallest configuration for the L–M algorithm) and the same number of neurons also worked correctly in a network with five neurons in the first layer and two in the second one (also seven in total). Therefore, in the case of the L–M algorithm, slightly smaller two-layer neural network configurations were found compared to the G–N case. However, when only one hidden layer was used, G–N slightly outperformed L–M in terms of convergence. Thus, no significant differences between G–N and L–M algorithms are visible.
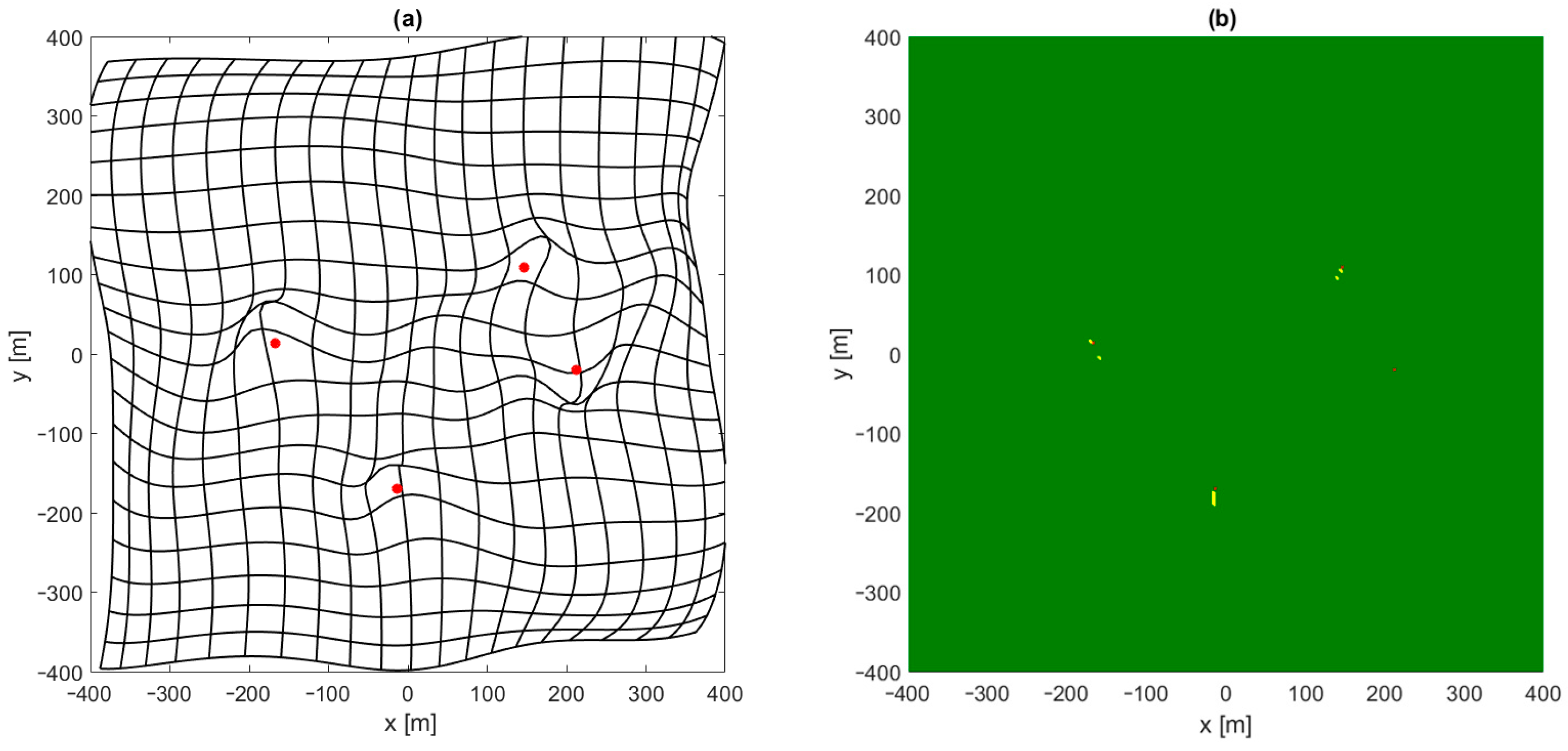
Interesting conclusions can be drawn by analyzing the distribution of places in which the convergence of position estimation algorithms was not achieved, even though a starting point selection by the neural network was used. In
Figure 7a a kind of map is shown which presents the distortion of a mobile terminal coordinate grid estimated using a feedforward network. In the case of a perfect estimation, this figure should contain a grid of perpendicular straight lines with a 40 m raster. The deformation and displacement of lines clearly shows that the quality of position estimation using FNN is not the same in whole area of system operation. Comparing this map with
Figure 7b, which presents the results of the convergence test, reveals that a lack of convergence is observed only in proximity to one or more base stations, and it coincides with some deformation in the grid in
Figure 7a in these regions. Therefore, greater emphasis must be placed on the quality of position estimation using FNN close to all base stations. It may be achieved by changing the error function used during network training in such a way that in regions close to base stations, a lower position estimation error is required, but the simplest method would be to change the distribution of points used to generate reference data for network training while keeping the MSE error function unchanged.
The uneven deployment of reference points with a higher density close to base stations should increase the position estimation in these regions; therefore, the following procedure was proposed to generate a training dataset. The coordinates of candidate points were generated randomly with a uniform distribution in the whole area of system operation. Next, the distances
from this candidate to all
base stations were calculated. The candidate is added to training dataset with a probability defined by equation:
Candidate generation is repeated until the predefined size of the training dataset is achieved. In order to obtain results comparable with those for a uniform distribution of training points, a dataset size of 6000 points was chosen. One of the obtained non-uniform distribution training points is presented in
Figure 6b.
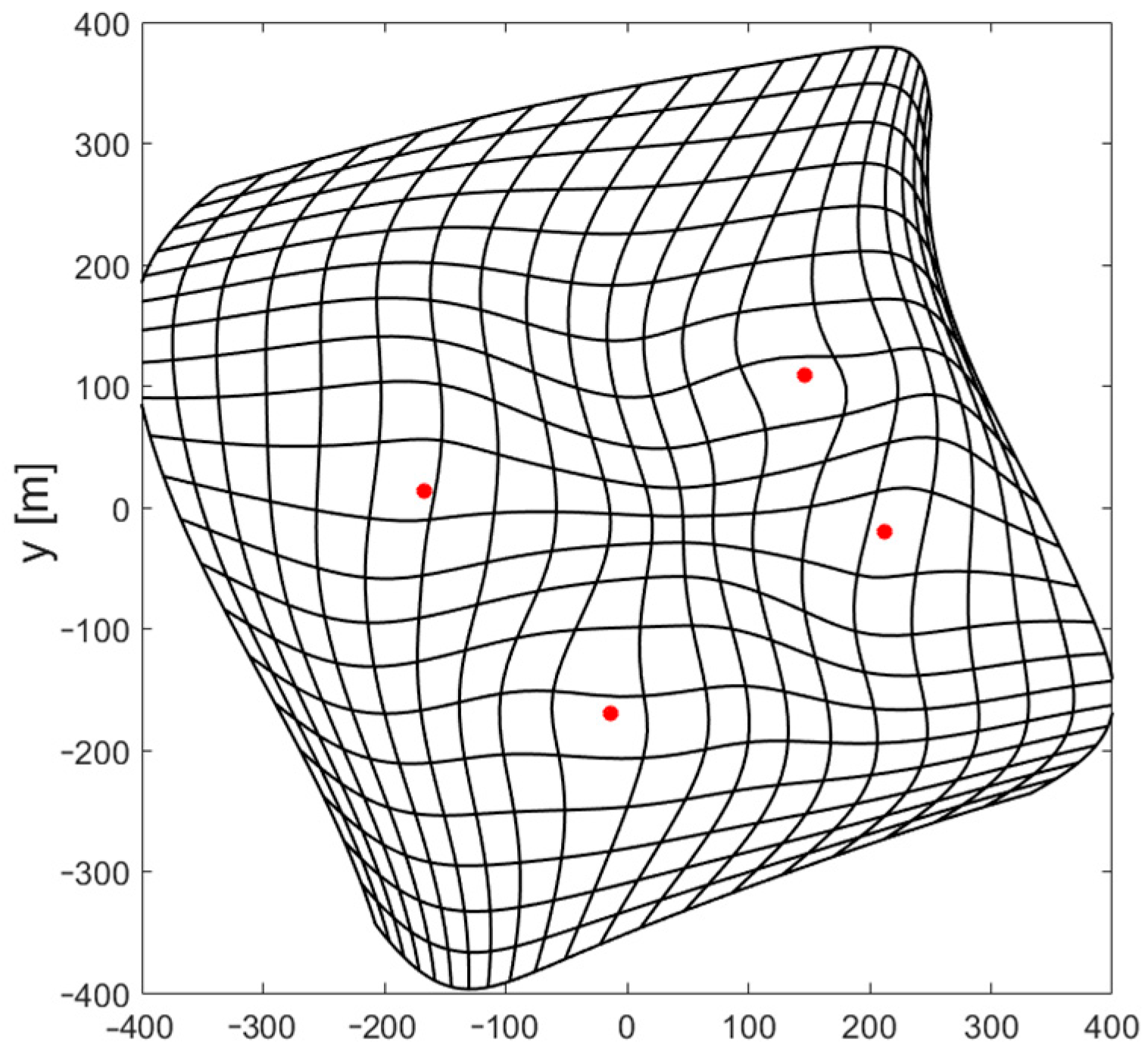
The results of using FNN with a non-uniform distribution of reference data used for training are very promising. Both the Gauss–Newton and Levenberg–Marquardt iterative position estimation algorithms were convergent in all tested points when the starting point for the first iteration was estimated using a neural network with only four neurons with a hyperbolic tangent activation function in the only hidden layer. Although, the numerical values of the position estimation for such a network were quite high, with an RMS error of 53.5 m and a maximum error exceeding 200 m, and though the deformation of the coordinate grid shown in
Figure 8 is very large, especially near edges of the area of system operation, such a rough estimation of the position was sufficient to achieve the full convergence of both tested algorithms.
It is hard to imagine the possibility of solving the problem of estimating two coordinates of a mobile terminal with network consisting of less than four neurons with a non-linear activation function; therefore, the obtained network structure may be treated as the minimal FNN configuration. By extracting weights and biases from a trained network and reducing the number of input data to a minimal set of independent distance-difference values, it is possible to write equations that fully describe the operation of the minimal network structure found during the investigation:
Comparing the data from
Table 3 and
Table 6, it is also obvious that the pre-calculation of starting points significantly reduces the average and maximal number of iterations needed to reach the assumed stop condition in iterative position calculation, typically defined as the maximal norm of the position update vector, which was 10
−4. The gain in the reduced number of iterations fully compensates the additional computational effort that is caused by the need to calculate starting points using (15) and (16).
4.2. 3D Case
In 3D hyperbolic positioning, at least five reference points are needed to obtain an unambiguous position indication. However, when these reference points have coordinates of stations no. 1 to 5 from
Table 2, the maximum value of 3D dilution of precision parameter (DOP) exceeds 2.5 million in the area to the north of station no. 5 and to the south of station no. 4. A positioning system with such a high value of DOP is practically unusable, as a 1 mm error in distance-difference measurements could cause a 2.5 km position estimation error. It has been checked that even with such an unfavorable geometry of base stations, it is possible to train FNN to indicate starting points for the G–N algorithm using, e.g., two separate networks from
Section 4.2.2; the first network: one layer tanh, 40 neurons and the second one: one layer tanh, 400 neurons. However, in order to make the results more usable, another base station has been added and all the 3D simulation results presented in next subsections were obtained using six base stations. In such a case, the maximum DOP was 845, which is still not low enough to reach a high position estimation quality in whole area of system operation, but can be accepted in some regions in practical solutions.
Test points for the 3D scenario were distributed uniformly with
and
in a range from −400 to 400 m and an step equal to 10 m. The
range was set from 0 to 20 m with a step equal to 2 m. After removing points located too close to base stations, a total number of 72,164 points were checked for the convergence of the Gauss-Newton iterative position calculation algorithm. The results obtained for the fixed starting point
are depicted in
Figure 9, where a yellow color indicates that at least for one value of
coordinate the G–N algorithm was divergent or converged to an incorrect result, while the dark red color indicates regions where convergence was not possible for any value of
. In this scenario, convergence was achieved in 49,365 points, which is 68.4% of test points.
The results presented in
Section 4.1 for 2D positioning showed that the G–N algorithm supported by a feedforward neural network with only one hidden layer and hyperbolic tangent activation function allowed us to obtain representative results, compared to other network structures. Thus, in this section, only the results obtained for the G–N algorithm and one-layer networks with a tanh function will be presented, although different network structures and functions were also tested. It should be noted that the hyperbolic tangent activation function is also frequently used by other authors, e.g., in direction of arrival estimation presented in [
28].
4.2.1. One Network
Compared to the 2D case presented in
Figure 5, the indication of starting points in 3D positioning system requires only adding one more neuron in the output layer of the feedforward neural network. However, in this straightforward approach, there is no way to control what part of a neural network resource is used to estimate horizontal and vertical coordinates.
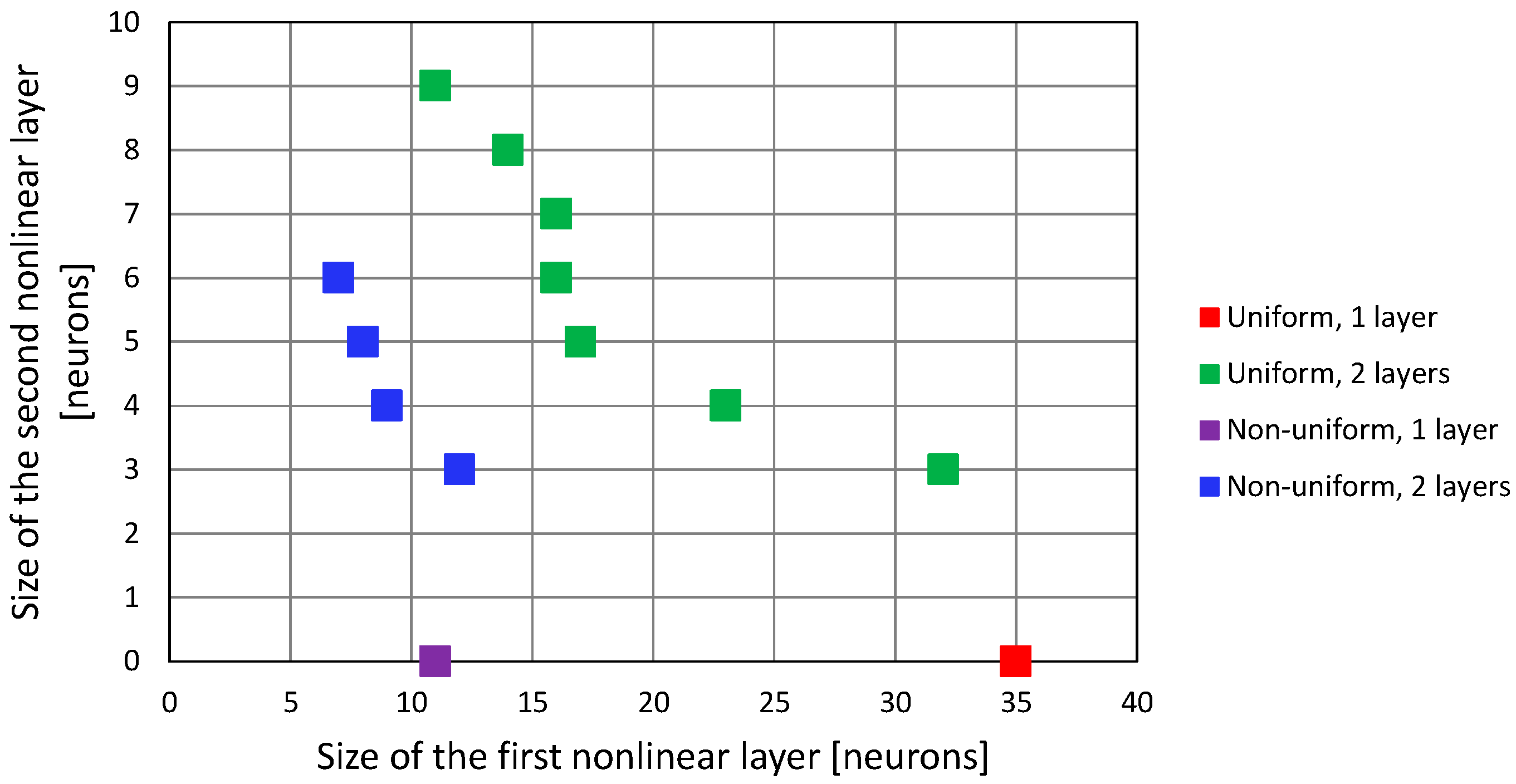
The minimal configurations of neural networks with one and two hidden layers with a hyperbolic tangent activation function, that allowed us to achieve convergence in all test points in the 3D case, are presented in
Figure 10 for both the linear and non-linear deployment of reference points in the network training dataset. Assuming that the computation of a non-linear activation function value is the most resource-consuming part of FNN work, the closer the points are to the origin in
Figure 10, the less complicated the network structure is.
When the feedforward neural network was trained using a uniform distribution of the training dataset, networks with only one hidden layer required 35 tanh neurons, while two-layered networks required 11 neurons in the first hidden layer and 9 in the second one, amounting to 20 non-linear neurons in total. However, the non-uniform distribution of training data allowed us to obtain the same result (convergence of G–N algorithm in all test points) using 11 tanh neurons in only one hidden layer. Adding the second layer did not improve the results, as the minimum configurations of a two-layer FNN trained using a non-uniform dataset required 13 tanh neurons in total (configuration: 7 + 6, 8 + 5 and 9 + 4 neurons).
4.2.2. Two Separate Networks
The range of
and
coordinates in the scenario presented in
Section 4.2 differs significantly from range of
. Thus, the required accuracy of the initial values of
and
may also be different. Two separate neural networks were implemented to check if a separate estimation of horizontal and vertical coordinates allows us to reduce the computational complexity understood as the total number of non-linear neurons. The block diagram of position estimation in this experiment is depicted in
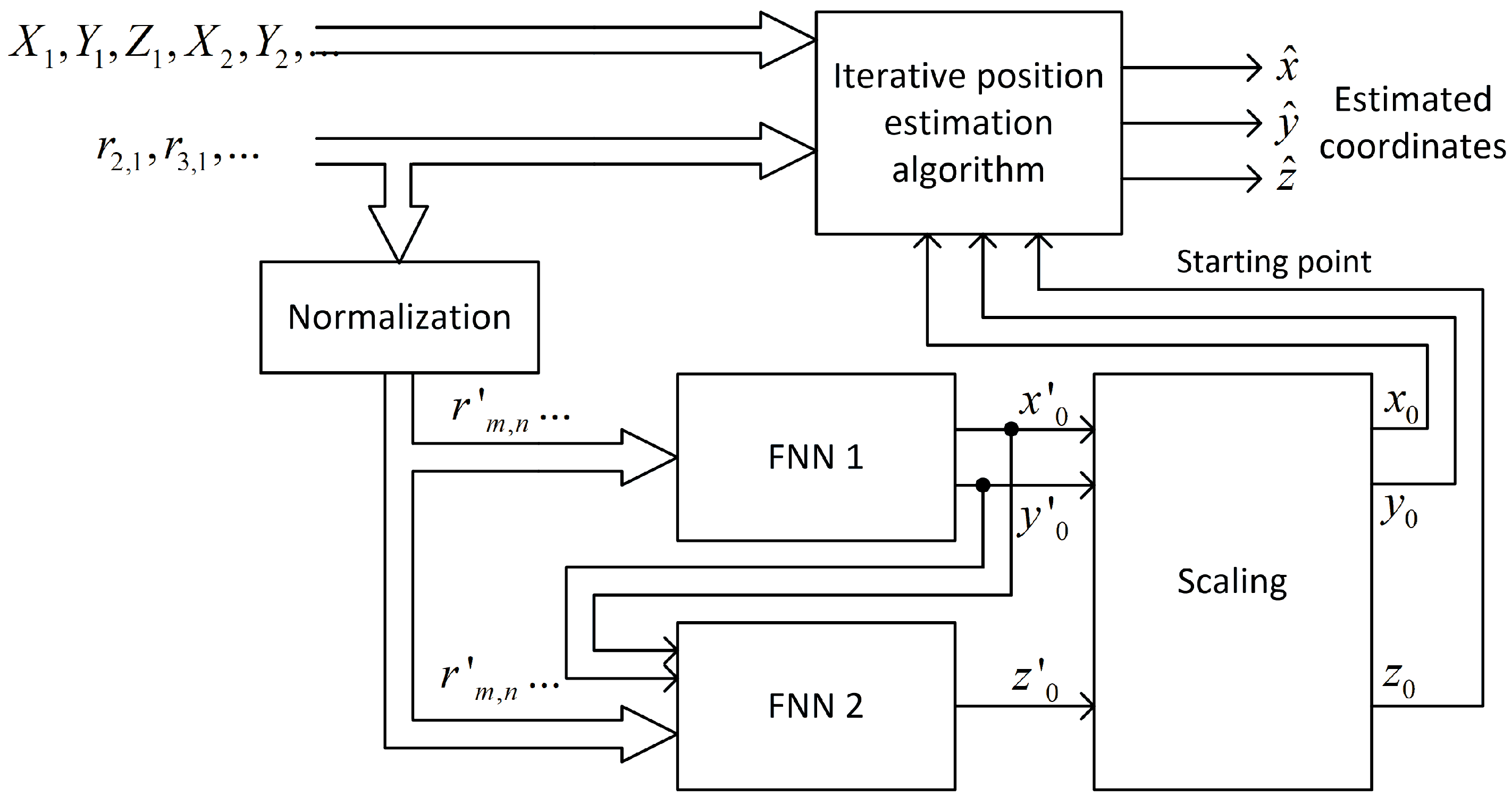
Figure 11.
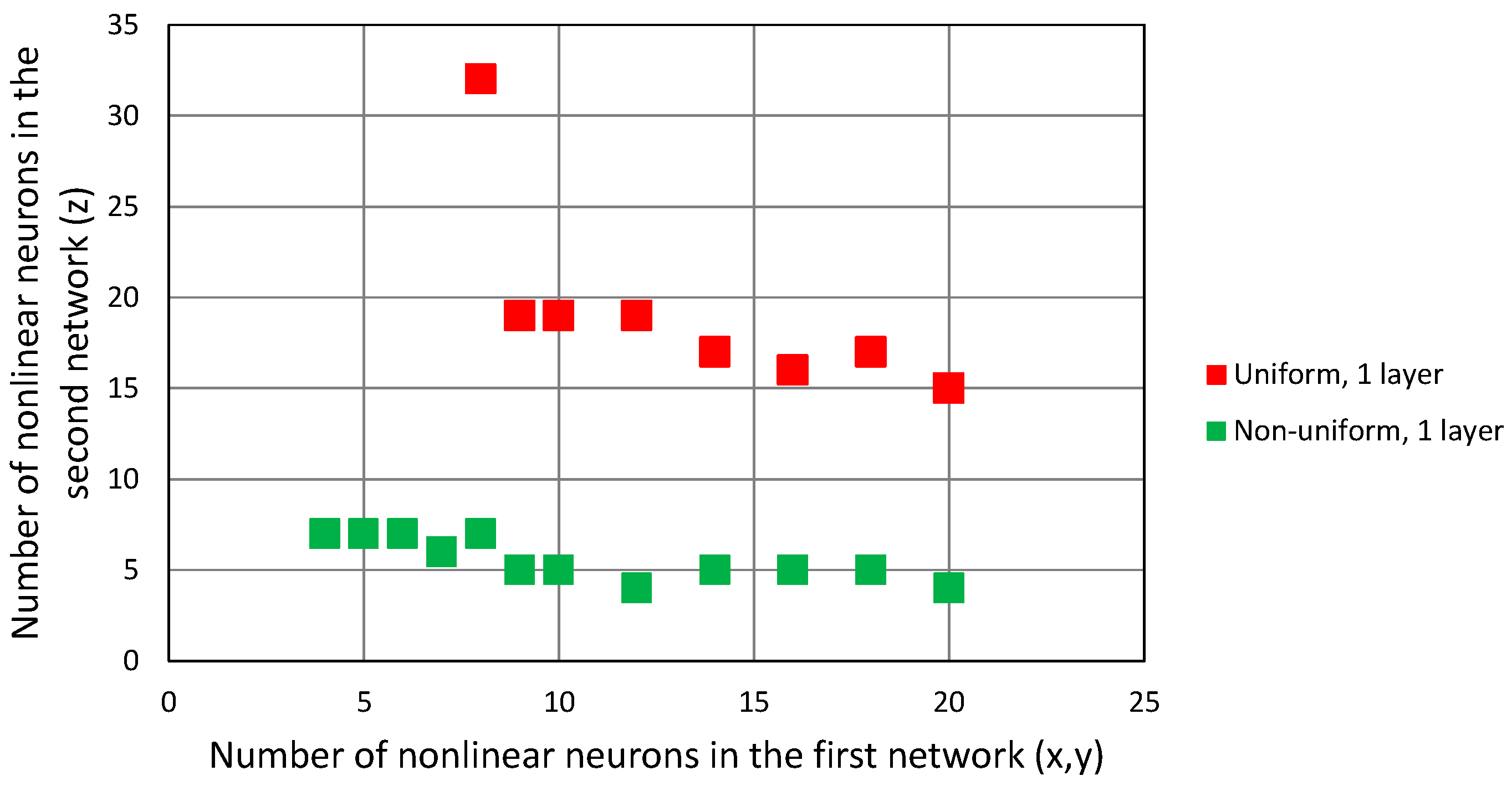
The results of the simulations are presented in
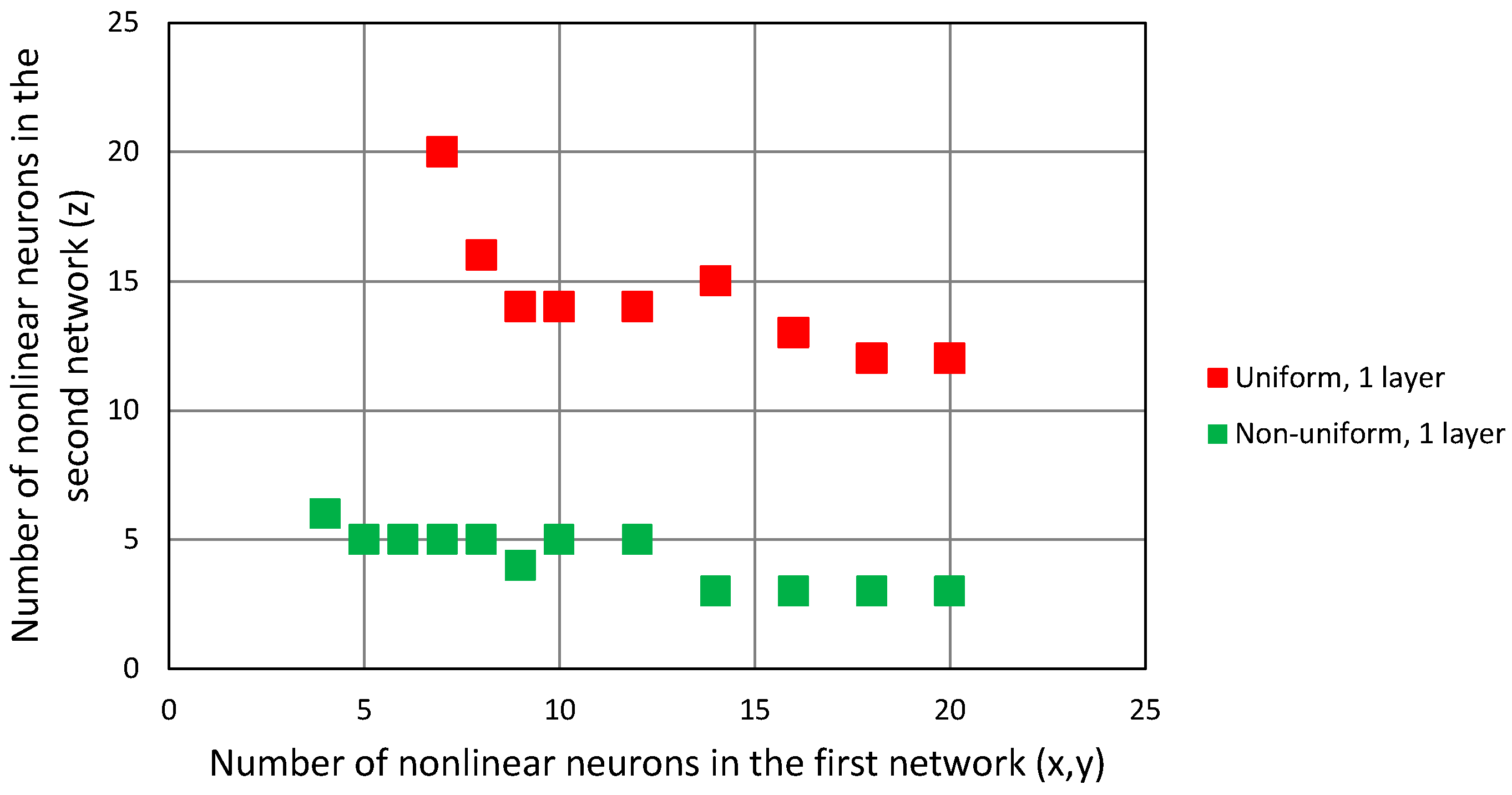
Figure 12 in form of points indicating the number of non-linear neurons in the first network, responsible for the horizontal coordinate estimation and the number of non-linear neurons in the second network, which was only for estimating vertical coordinates. Both networks had only one hidden layer.
In the case of the uniform distribution of data in training dataset, the minimal size of both FNN, in terms of the total number of non-linear neurons, was 28, but the majority of them (19) had to be in the second network, responsible for coordinate estimation. This clearly indicates a greater importance of this coordinate in the convergence of the G–N algorithm. The same trend is visible in the data from the networks trained using a non-uniform dataset: the minimal configuration of networks was four neurons in the x-y network and seven neurons in network, amounting to 11 in total. However, comparing these results to the case with one network only, no reduction in the number of neurons in the smallest network configuration was observed.
4.2.3. Two Networks Cascaded
Another neural network configuration that has been tested in simulations is presented in
Figure 13. Also, this time, two feedforward neural networks have been used, but the second network, responsible for vertical coordinate estimation, was able to use output data from the first network as additional inputs, so these networks are connected in a cascade.
In the cascaded configuration, the second FNN takes advantage of the output from the first network, and therefore is able to provide a comparable quality of prediction using the lower number of non-linear neurons. Comparing the results from
Figure 14 with
Figure 12, it can be seen that almost in all cases for the same size of the first network, the number of non-linear neurons in the second FNN required for the convergence of G–N algorithm is reduced. The minimal configuration of two cascaded networks in the case of the uniform training dataset is 9 + 14 neurons, and in the case of the non-uniform distribution of training points, it is 5 + 5 neurons. It should be noted that it still indicates a higher computational complexity of vertical coordinate estimation, as the first FNN with five neurons in the hidden layer estimates two coordinates, while the second FNN needs five neurons for one coordinate.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}