1. Introduction
The development of Industry 4.0, also known as the fourth industrial revolution, has significantly impacted the manufacturing sector in recent times. In the context of tool condition monitoring, Industry 4.0 has a significant role in improving monitoring systems’ accuracy and efficiency. One key aspect of Industry 4.0 in tool condition monitoring (TCM) is the use of advanced sensors and monitoring systems that are capable of collecting large amounts of data in real-time. These systems can be integrated with artificial intelligence (AI) and machine learning (ML) algorithms to analyze the data and provide insights into the condition of the tool [
1]. For example, machine learning algorithms can be used to analyze the vibration patterns generated by the tool to identify any abnormal patterns that may indicate tool wear or breakage. Similarly, AI can be used to analyze temperature and pressure data to detect anomalies related to the tool’s condition [
2]. This can result in significant improvements in efficiency and productivity, as well as reduce the risk of downtime due to unexpected tool failures or other issues. There are two main categories of tool condition monitoring techniques: direct and indirect. The measurement of physical characteristics that are directly connected to the tool or machine that is being monitored is involved in direct procedures. Indirect techniques of condition monitoring involve monitoring parameters that are indirectly related to the health of the machine or the component being monitored. These parameters can include temperature, pressure, voltage, current, and other physical or operational data that can provide insights into the machine’s condition. The indirect techniques of condition monitoring can also be combined with direct techniques to provide a more complete picture of the machine’s condition. For example, vibration analysis can be used in conjunction with temperature monitoring to detect abnormal vibration patterns that are related to temperature changes. Direct techniques are generally more accurate and reliable than indirect techniques, but they can be more complex and require specialized equipment to implement. On the other hand, indirect techniques are often more straightforward and easier to implement but may not provide as much detail about the tool or machine’s performance.
Vibration analysis is a powerful technique used in tool condition monitoring to detect any abnormalities or faults in a machine tool. By analyzing the vibration patterns generated by the tool, it is possible to identify various conditions such as tool wear, tool breakage, or poor tool performance [
3,
4]. Machine vision can monitor tool wear in real time using cameras and image processing algorithms. The authors [
5,
6] devised a method for detecting tool wear by analyzing the images of specimens manufactured through the machining process. Their approach identified surface roughness changes which could be further explored to estimate the remaining usable life of a tool. Moldovan et al. [
7] provided an alternative technique. In the end milling process, they proposed a tool-flank-wear monitoring system that used the Euler number to distinguish between worn and unworn tool flanks under variable cutting periods. For a ball end milling operation, Zhang and Zhang [
8] used an enhanced wear edge detecting method that achieved subpixel precision. Overall, the research indicates that machine vision is a viable technique for monitoring tool wear, with the potential to enhance the productivity and quality of industrial operations. However, there are obstacles to overcome, such as the inaccessibility of the cutting region during the machining process. In addition, certain direct TCM techniques need the cutting tool to be removed from the tool post, which may result in the misalignment of the tool during the subsequent operation [
9]. There has been a plethora of attempts to establish a causal link between machining parameters and tool wear, and hence, support the use of indirect methods for monitoring tool condition [
10]. In recent years, ML algorithms have grown in favor of a robust tool for predicting and monitoring the status of cutting tools. These algorithms have demonstrated significant results in a variety of aspects of tool condition monitoring (TCM), such as tool wear [
11], surface quality [
12], and material removal rate [
13]. Real-time tool wears prediction using machine learning techniques enables the early identification and replacement of worn-out tools. These algorithms examine sensor inputs such as acoustic emission, vibration, and temperature to anticipate tool wear. The most often used methods for tool wear prediction are artificial neural networks (ANNs), support vector machines (SVMs), and random forest (RF) algorithms. ML algorithms may be used to evaluate the surface finish, which is a crucial quality parameter in machining operations. These algorithms then determine the surface finish based on process characteristics such as cutting speed, feed rate, and tool shape. The material removal rate is another parameter that determines the productivity of the machining process. ML algorithms can be used to enhance MRR by highlighting the required process parameters that yield the maximum MRR.
Studies have shown that machine learning algorithms can effectively predict tool wear rates in various machining operations, such as milling [
14], turning [
15], and grinding [
16]. Hybrid models combining ML algorithms with optimization techniques have also been proposed and shown to have high accuracy in predictions [
17]. SVM has also been used for TCM and has been shown to have good performance in detecting tool wear and predicting tool life [
18]. Deep learning (DL) models have become a popular tool for TCM in recent years due to their ability to handle large amounts of data and to detect patterns and anomalies in data that are difficult to detect using traditional methods [
19]. DL models such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), and deep belief networks (DBNs) have been applied to TCM and trained on large datasets of machining processes to learn the patterns and relationships between tool conditions and tool wear. In addition, transfer learning techniques have been proposed for TCM, allowing for the transfer of knowledge from one machining process to another and improving the efficiency of the prediction process [
20]. Despite these advantages, there are also limitations to the use of ML models for TCM. ML and DL models require large amounts of experimental data to be trained effectively. In the case of TCM, these data need to include detailed information about the machining process, tool conditions, and wear patterns. Recently generative adversarial networks (GAN) were developed by Goodfellow [
21] and are capable of generating synthetic data that can supplement the real data used in training machine learning models. Compared to traditional techniques, GAN can be useful for tool condition monitoring in various ways. To begin, GANs can be used to generate synthetic data that can be used to supplement the real tool wear data used in training machine learning models. This is especially useful when there is a scarcity of real-world data for training. Secondly, GANs can be used to reduce the time and effort required for feature extraction while also improving prediction accuracy. Finally, with the availability of additional spectrograms (generated by GAN), deep learning models such as RNN can be developed, which was previously very tedious due to a lack of experimental data.
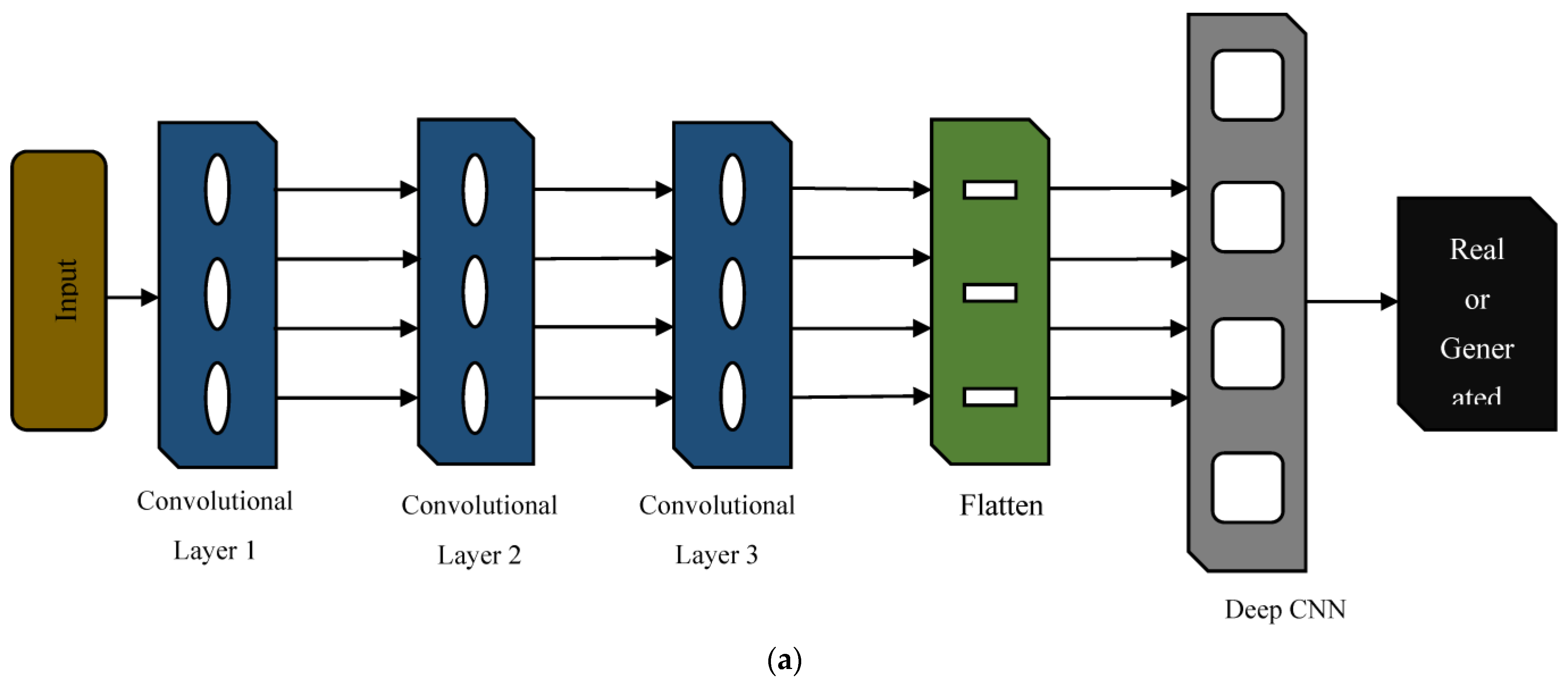
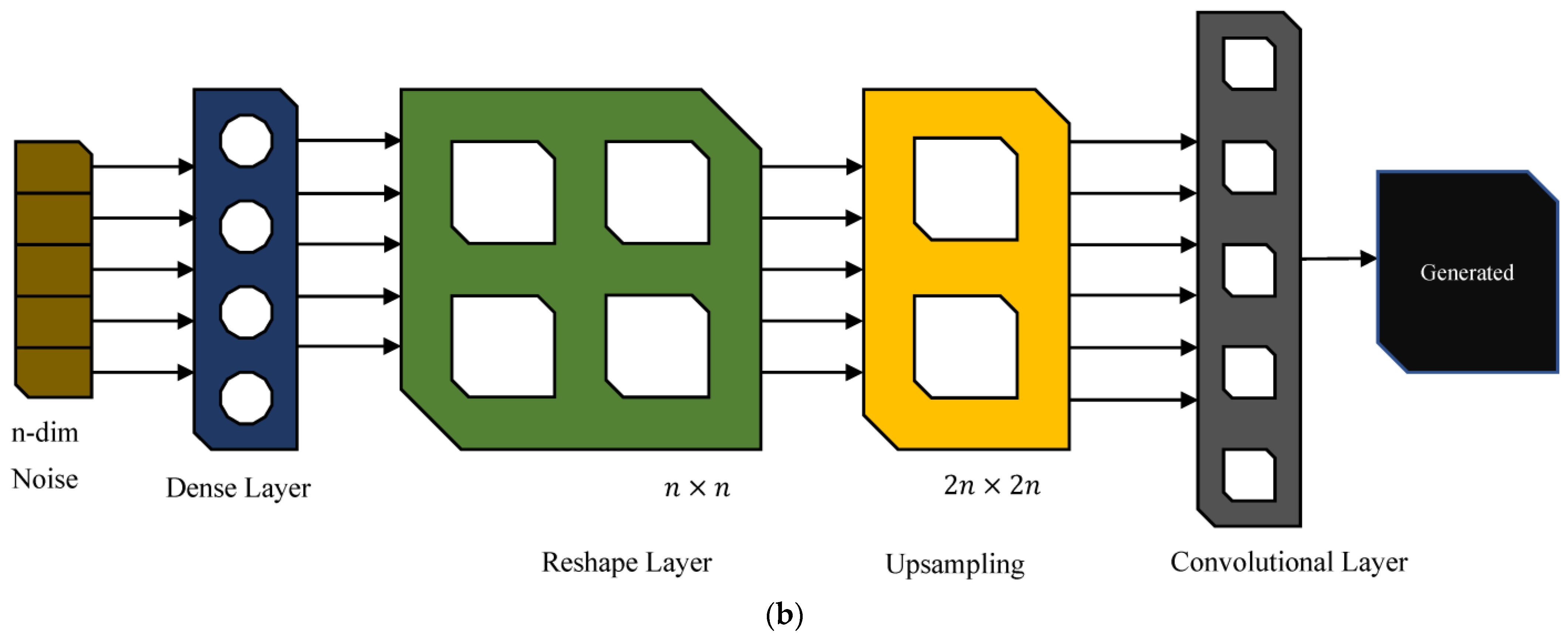
As per the available literature, the utility of GAN in the area of TCM has not been explored effectively. Therefore, to circumvent the issue of a limited dataset, the authors developed deep convolutional generative adversarial networks (DCGAN) to generate additional data on publicly accessible milling datasets from NASA’s Prognostics Centre of Excellence-Data Repository [
22], which helped to train the ML models to predict the tool wear rate effectively. DCGAN is a type of GAN that uses convolutional neural networks (CNNs) to generate high-quality images. While GANs are a class of neural networks used for generating new data that resemble a given dataset, DCGAN specifically uses convolutional layers to improve the quality of generated images. The following is the author’s specific contributions:
To investigate the use of the Walsh–Hadamard transform and DCGAN for signal processing and spectrogram generation, respectively, and to assess their effectiveness in predicting tool wear.
To investigate and compare the performance of three different metaheuristic optimization feature selection algorithms through the selection of relevant features for tool wear prediction and evaluate their impact on prediction accuracy.
To compare the performance of three different machine learning models for tool wear prediction in conjunction with the Walsh–Hadamard transform, DCGAN, and the use of the selected features.
To develop a more accurate and efficient TCM system for tool wear prediction by integrating novel approaches using the Walsh–Hadamard transform and DCGAN, exploring metaheuristic optimization feature selection algorithms, and evaluating the performance of different machine learning models.
The remaining sections of the article are structured as follows:
Section 2 describes the methods and experiments,
Section 3 analyzes the results, and
Section 4 provides the conclusion.
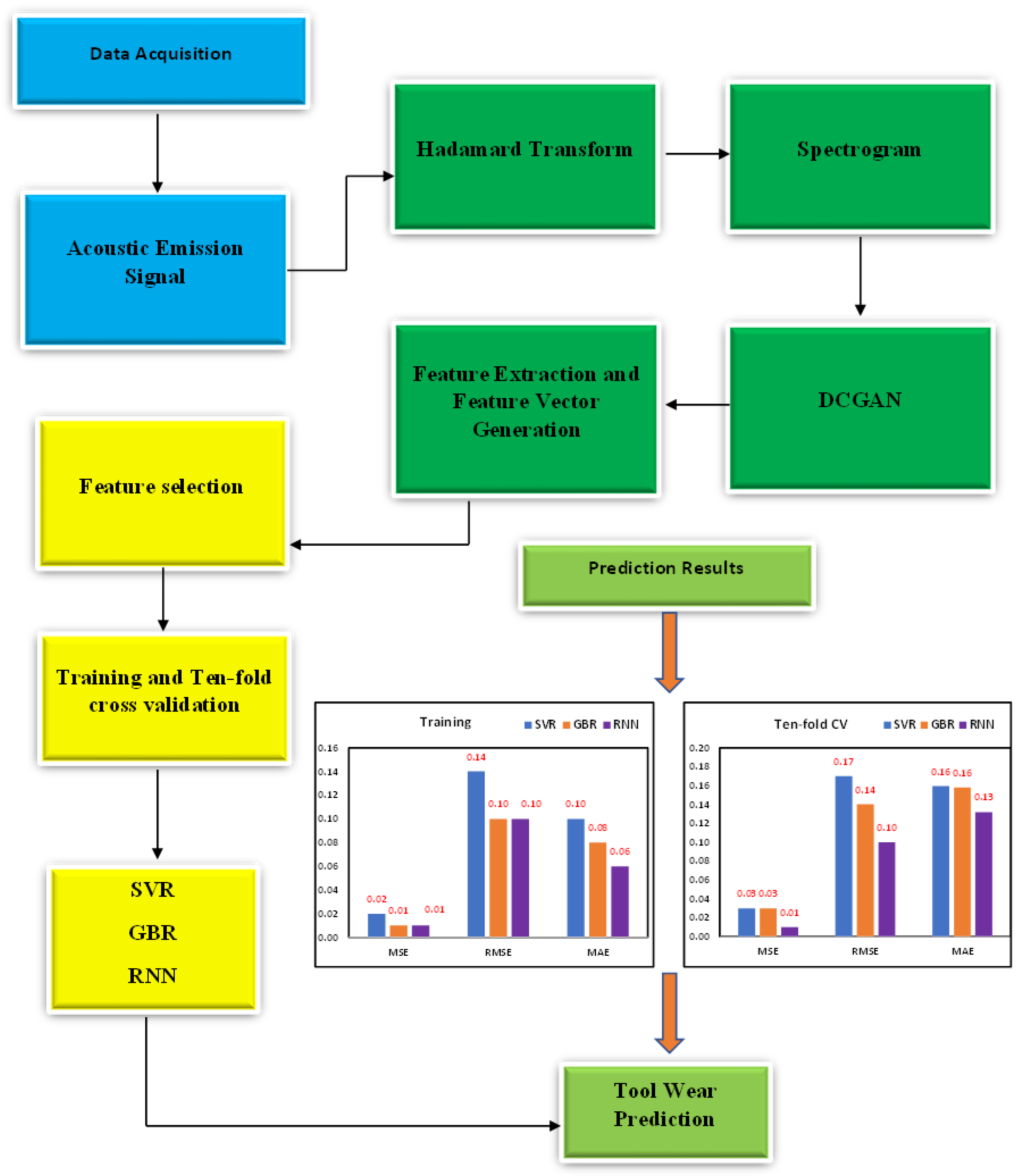
Figure 1 shows a flowchart of the proposed methodology.
3. Results
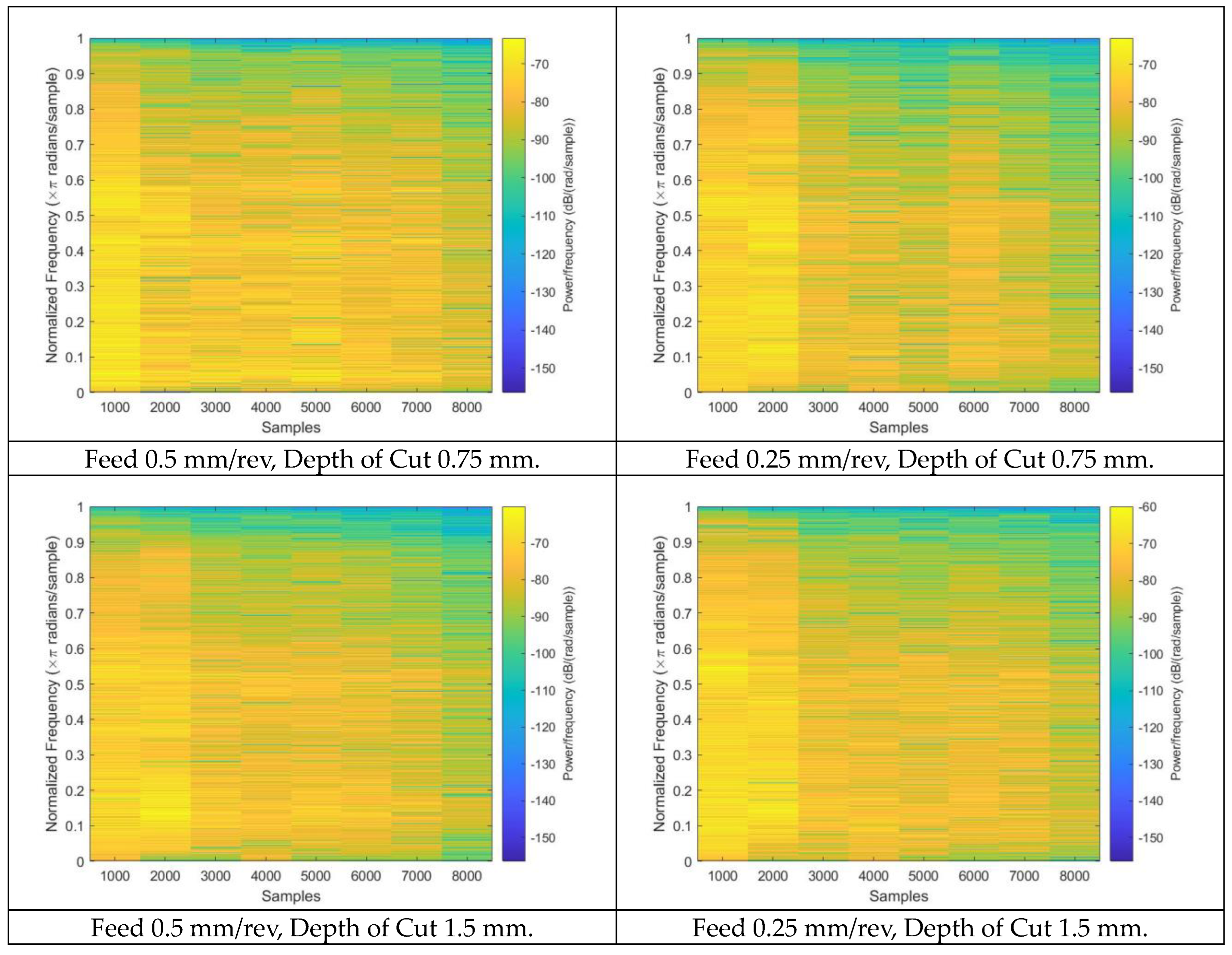
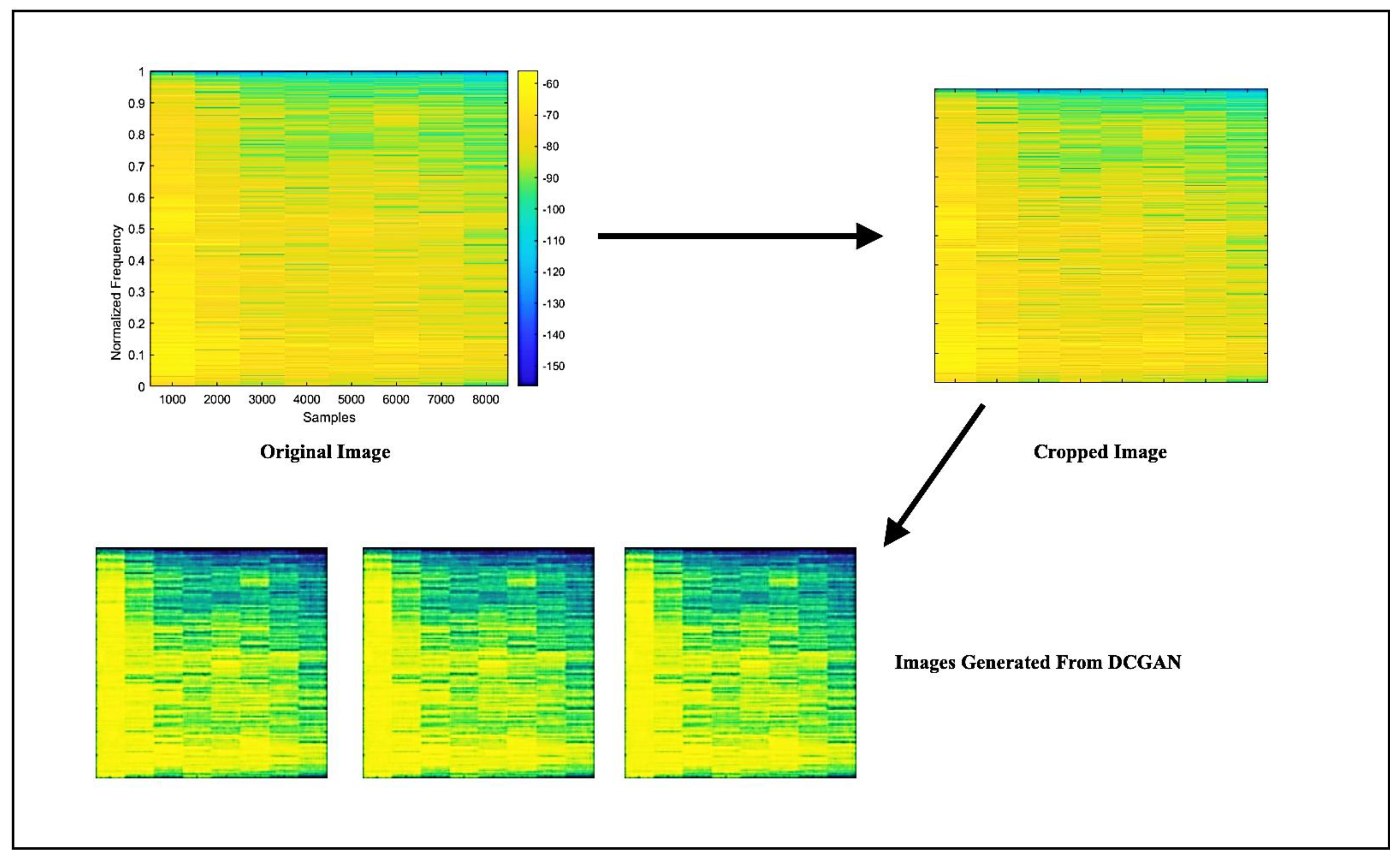
In order to predict the tool wear of a specimen produced via the face milling process, 109 spectrograms were generated by employing the Walsh–Hadamard transforms on the AE signals. The spectrograms corresponding to distinct operating conditions are illustrated in
Figure 3. Spectrograms are useful in predicting tool wear as they extract the meaningful and relevant properties of the signal generated during the machining process. The spectrogram displays the signal’s frequency content as a function of time, which allows the identification of specific patterns that correspond to tool wear. By analyzing the features extracted from the spectrograms, a machine-learning model can be trained to predict the level of tool wear for a given set of operating conditions. The features extracted through spectrograms are listed in
Table 2 and were derived from the additional generated images obtained after applying DCGAN. From each original spectrogram, 100 images were generated, and the relevant features were extracted. A feature vector of size 10,900 × 7 was constructed, which can be used to train RNN, GBR, and SVR models to predict tool wear. The spectrogram generated after applying DCGAN is shown in
Figure 5.
Table 3 and
Table 4 exhibit sample feature vectors extracted from the generated spectrograms. As seen from both tables, the extracted features exhibit considerable variation with respect to various operating conditions performed on a milling machine. A standardized transformation of the feature vector was required to decrease bias and successfully train the models. During the standardized feature vector transformation process, the features were rescaled to ensure that the mean and the standard deviation would be equal to 0 and 1, respectively.
Table 4 shows the sample feature vectors that were standardized. The Dragonfly, Harris hawk, and genetic optimization algorithms were used to identify the relevant features. These updated feature vectors were fed into SVR, GBR, and RNN models for flank wear prediction. To evaluate the tool wear prediction capabilities, three performance parameters, namely, the mean squared error (MSE), root mean squared error (RMSE), and mean absolute error (MAE), were computed.
where
P is the predicted value,
A is the actual value and
L is the number of observations.
Ten-fold cross-validation is a common technique that is used in machine learning to assess the performance of predictive models, such as those used for tool wear prediction. The utility of ten-fold cross-validation in tool wear prediction lies in its ability to provide a more accurate assessment of the model’s performance than simple holdout validation. Holdout validation involves splitting the data into a training set and a test set, with the model being trained on the former and tested on the latter. However, holdout validation can be sensitive to how the data are split, leading to variability in the performance estimates. Ten-fold cross-validation helps address this issue by repeatedly evaluating the model on different subsets of the data, thereby reducing the impact of the particular data split on the performance estimates.
Table 5 displays the hyperparameter settings of the DCGAN and ML models used in the present study.
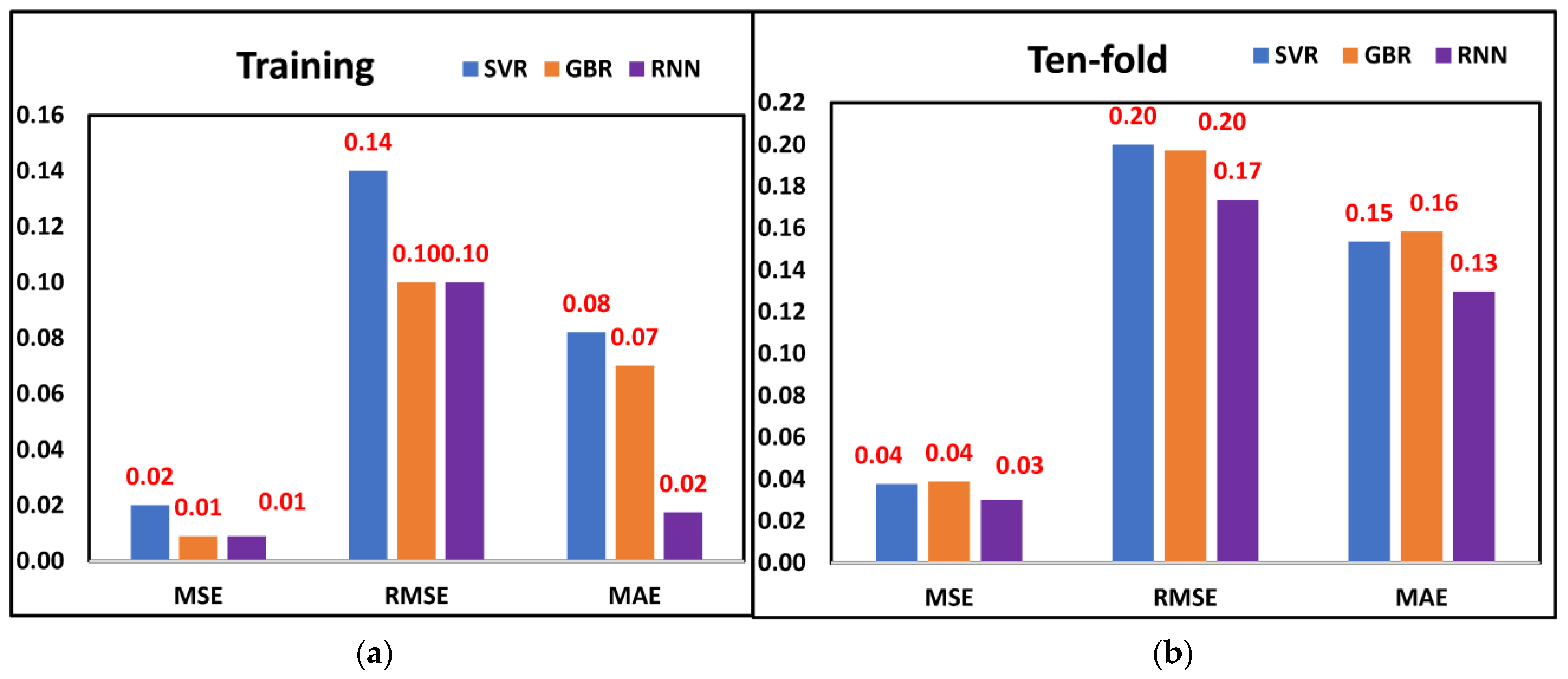
The aim of this study was to investigate the efficacy of the proposed methodology for tool wear prediction. As discussed earlier, the features selected through metaheuristic optimization models were fed into three ML models. The MSE, RMSE, and MAE values are displayed in
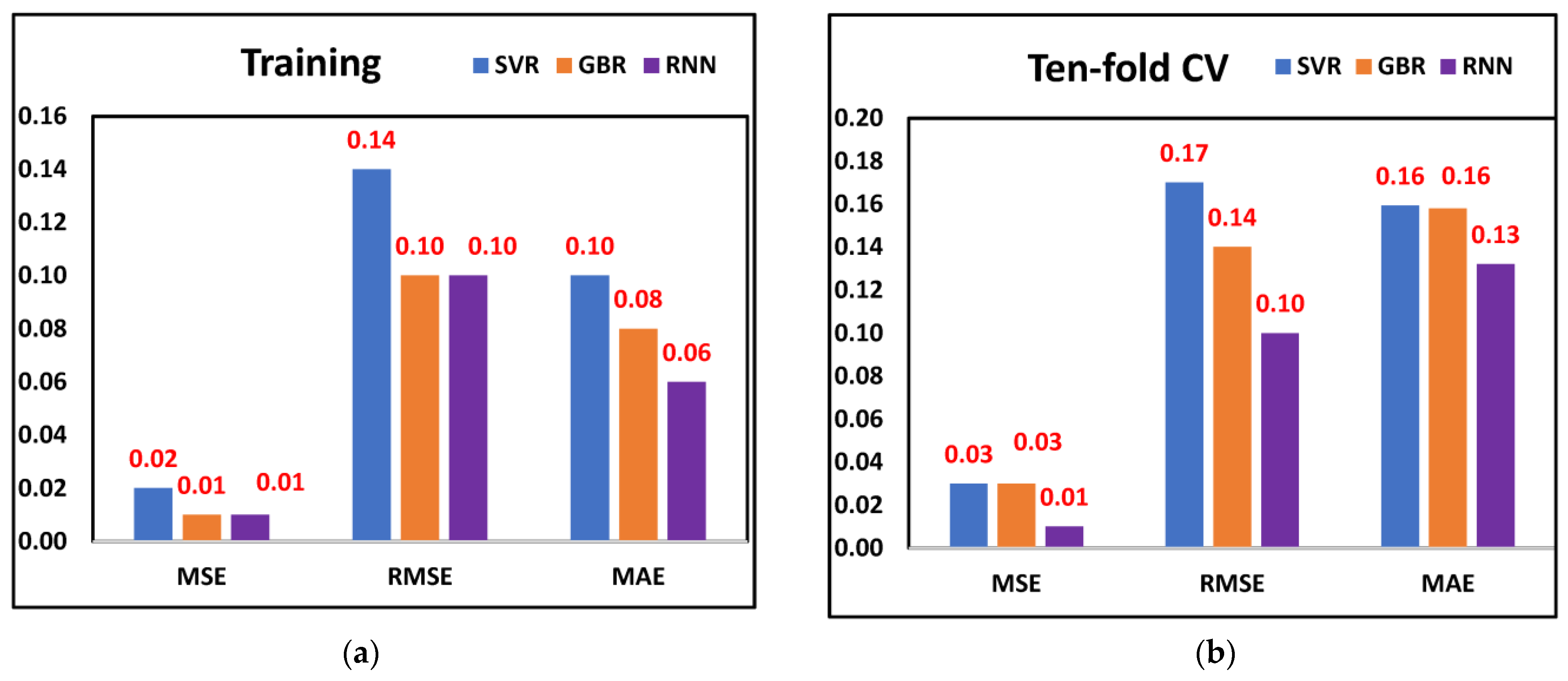
Figure 6a,b when training and ten-fold cross-validation was performed on all three ML models and considering the features selected through the Dragonfly algorithm. The least MSE (0.01), RMSE (0.10), and MAE (0.06) were observed from the RNN model, followed by GBR and SVR, respectively, when training was performed. A similar trend was observed when all three models were cross-validated. The least MSE (0.01), RMSE (0.10), and MAE (0.13) were observed from the RNN model. The results indicate that the RNN model was better for predicting tool wear since it provided significantly fewer prediction errors.
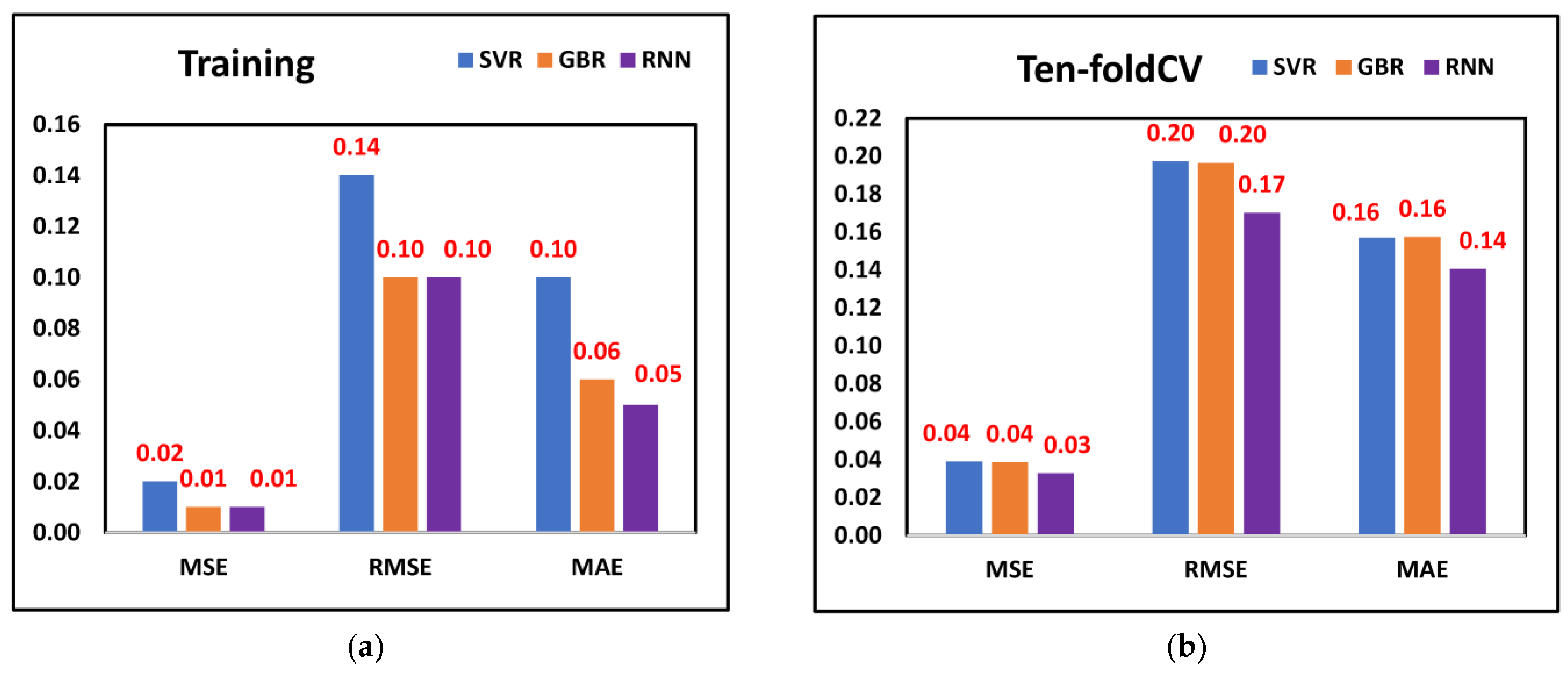
Figure 7a,b displays the tool wear prediction errors when the features selected through Harris Hawk were fed into ML models. From the RNN model, the least MSE (0.01), RMSE (0.10), and MAE (0.05) were observed when training was performed, whereas when ten-fold cross-validation was considered, the least MSE (0.03), RMSE (0.17) and MAE (0.14) was observed from the RNN model. This finding suggests that the RNN model was better for predicting tool wear compared to SVR and GBR models when Harris Hawk features were considered. Finally,
Figure 8a,b shows the tool wear prediction errors when features selected through the genetic algorithm were fed into ML models. The prediction results indicate that RNN was better compared to SVR and GBR as it provided the least MSE, RMSE, and MAE values after performing training and ten-fold cross-validation. By comparing the prediction errors of various machine learning models, the authors found that our proposed methodology integrating DCGAN, the Walsh–Hadamard Transform, and Dragonfly algorithm demonstrated reliable and promising results for tool wear prediction. Notably, RNN exhibited the lowest prediction errors when trained on the selected features from Dragonfly, Harris Hawk, and genetic algorithms, while the other two ML models also performed acceptably, whether trained on the selected features or using the ten-fold procedure. Overall, these findings suggest that our methodology can improve the accuracy of tool wear prediction and provides a valuable tool for industry practitioners.
The authors demonstrated that the performance of SVR, GBR, and RNN could identify prediction capabilities based on a proposed methodology. By evaluating the performance of multiple algorithms based on a proposed methodology, the authors were able to observe that deep learning, specifically RNN, was a viable approach for tool wear prediction as it produces the least prediction errors with all metaheuristic feature selection algorithms. To effectively demonstrate the utility of their proposed methodology, the authors prepared a comparison table (
Table 5) that highlighted the significant differences and similarities among various research studies related to the same TCM dataset. This comparison table allowed readers to easily assess the performance of different machine learning algorithms for tool wear prediction and provided insights into the effectiveness of the proposed methodology. Overall, the authors’ approach thoroughly evaluated various machine learning algorithms and highlighted the potential of deep learning for tool wear prediction. There are certain reasons to choose SVR, GBR, and RNN as ML algorithms for tool wear prediction. The authors wanted to compare the performance of different machine learning algorithms for tool wear prediction. By applying multiple algorithms, the strengths and weaknesses of each algorithm were evaluated based on the proposed methodology. By comparing the performance of RNN with traditional machine learning algorithms, such as SVR and GBR, it was observed that deep learning could be a viable approach for tool wear prediction as it gives the least prediction errors with all metaheuristic feature selection algorithms. Further, a comparison table has been prepared (
Table 6), which effectively demonstrates the utility of the methodology proposed by highlighting the significant differences and similarities among various research studies related to the same TCM dataset.
4. Conclusions
This investigation aimed to establish a precise method for predicting tool wear by analyzing the signals from AE sensors. To do so, the authors used Walsh–Hadamard Transform to remove noise from the measured signals before generating spectrograms from the filtered signals. However, obtaining sufficient training data was challenging due to limited experimental data availability. To address this issue, the DCGAN technique was used to generate additional spectrograms from the dataset. Following that, standard statistical features were extracted, and a feature vector was created. The authors utilized metaheuristic feature selection algorithms such as Dragonfly, Harris Hawk, and genetic algorithms to identify relevant statistical features. Finally, researchers assessed the effectiveness of our models with support vector regression (SVR), gradient-boosting regression (GBR), and recurrent neural network (RNN) models using training and ten-fold cross-validation techniques. The outcomes of this study are as follows:
- (a)
The RNN model with a Dragonfly algorithm feature has the lowest MSE (0.01), RMSE (0.10), and MAE (0.06) to predict tool wear when the training of ML models is carried out.
- (b)
When ten-fold cross-validation is performed, the tool wear rate prediction from the RNN model with features selected from the Dragonfly algorithm has the lowest MSE (0.01), RMSE (0.10), and MAE (0.13).
- (c)
Compared to the GBR and SVR models, the RNN model was found to have significantly fewer incorrect predictions regarding tool wear.
- (d)
The features chosen by the Dragonfly algorithm were superior to those selected by the Harris hawk algorithm and the genetic algorithm. This conclusion was reached after comparing the three algorithms.
The authors investigated three machine learning models, but other models may better predict tool wear. In the future, we need to explore different models, such as convolutional neural networks or transformer-based models, to improve the system’s accuracy. To enhance the performance of machine learning models, the authors could further optimize their hyperparameters. This could be accomplished through the use of techniques such as grid search or Bayesian optimization. The proposed TCM system could be improved by creating a real-time monitoring system capable of detecting tool wear in real-time and alerting operators to perform maintenance before significant damage occurs. In the manufacturing industry, this could lead to increased productivity and decreased downtime.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}