1. Introduction
The convergence of information technology and economic society has led to the rapid growth of data. In turn, big data has also changed the traditional production mode and economic operation mechanism [
1]. While the big data industry has become a new economic growth point, it has also brought a brand-new challenge: how to effectively and rapidly process large-scale data so as to efficiently mine the value of big data. The development of high-performance networked systems has brought a significant data processing problem [
2]. However, how to reasonably allocate workloads on multiple servers directly determines both the resource utilization of networked systems and the processing efficiency of big data. Hence, finding an optimal task-scheduling strategy is the main focus and difficulty of studying networked systems and big data.
The Divisible-Load Theory (DLT) [
3] is one of the task-scheduling theories developed under this background. The DLT assumes that a big data workload can be divided into load partitions of arbitrary sizes, without any data dependency or execution order between these load partitions, that is, each load partition can be independently transmitted and processed [
4]. These divisions are distributed to multiple servers on the networked system through a reasonable task-scheduling strategy to complete parallel computing, thus shortening the makespan of the entire workload. The DLT has been successfully applied in various big data-related fields, such as image processing [
5], dynamic voltage and frequency regulation [
6], signature searching [
7], data flow optimization [
8], real-time video encoding [
9], and other typical big data application problems.
It has been proved that divisible-load scheduling problems in networked systems are NP-hard [
10]. If the scheduling model is too idealistic, the obtained solution of the model (i.e., load-partitioning scheme) may be difficult to apply to the actual networked systems. On the contrary, if the scheduling model is too detailed with all possible factors that affect the makespan, it will sharply increase the complexity of the problem to be solved, resulting in an inability to obtain an optimal solution to the model within a tolerable time. Therefore, when establishing a task-scheduling model for networked systems, it is necessary to balance the complexity of the model and the performance of the system.
To better adapt to different network topologies of networked systems, various task-scheduling models based on the DLT have been studied. For example, divisible-load scheduling models have been applied on the bus network [
11], multi-level tree network [
12], Gaussian, mesh, torus network [
13], complete b-Ary tree network [
14], Cloud platform [
15], time-sensitive network [
16], wireless sensor networks [
17], Edge platform [
18], Fog platform [
19], and so on.
In order to make task-scheduling models closer to the real distributed platform environment, researchers proposed considerable divisible-load scheduling models with all sorts of constraints. For example, the authors in [
20] introduced the concept of startup overheads in the scheduling model, and studied the unneglectable impact of startup overheads on the makespan of workloads. The work in [
21] took limited memory buffers into consideration. It assumed that the amount of memory available on the remote servers is too small to hold the whole workload at once. Hence, the workload must be distributed into multi-installments. The authors in [
22] studied divisible-load scheduling among multi-task servers whose processing speeds and channel speeds are time-varying. Two recursive algorithms were provided to solve this problem when the arrival and departure times of the background workloads are known a priori and an iterative algorithm was provided to solve the case where such times are not known. The work in [
23] focused on heterogeneous networked systems with hierarchical memory. It found that different levels of memory hierarchy have different time and energy efficiencies. Core memory may be too small to hold the whole workload to be processed, while computations using external storage are expensive in terms of time and energy. In order to avoid the costs of processing the workload in the external memory, it allows the workload to be distributed into multi-installments. The authors in [
24] studied the communication and computation rate-cheating problems as in a real distributed environment, wherein servers may cheat users by not reporting their true computation or communication rates. The work in [
25] addressed failures on servers and takes checkout start-up overhead and checkout time consumption into account. The authors in [
26] proposed a novel architecture of a multi-cloud system that can satisfy the complex requirements of users on computing resources and network topology, as well as guarantee a quality of services. Based on this architecture, they designed a dynamic scheduling strategy that integrates the DLT and node ready-time prediction techniques to achieve high performance. The work in [
27] studied a scheduling problem with divisible loads and subcontracting options with three linear subcontracting prices. The objective is to minimize the sum of the total weighted tardiness and subcontracting costs. The article in [
28] is concerned with the investigation of adapting a user’s preference policies for scheduling real-time divisible loads in a cloud computing environment.
However, the above scheduling models all assume that servers in the system remain idle at the beginning of workload division and assignment and that servers involved in workload computation are able to stay online forever. That is to say, existing studies do not consider the available time of each server. In the actual parallel and networked systems, on the one hand, servers may still be busy computing their previous workload assignment when a new workload arrives. On the other hand, the platform cannot ensure that all servers remain online during workload computation. Servers may become offline or even be shut down before completing their assignment due to network attacks or communication interruptions. In addition, the servers’ continuous operation may cause their temperature to rise due to electric heating, which may endanger the service life of server components; therefore, servers require to be offline periodically to cool down. Meanwhile, servers may also generate available-time fragments due to the user’s advance reservation. If these time fragments are not utilized properly, the overall resource utilization of the servers will be reduced to some extent. On the contrary, if one prefers to make full use of these fragments, then the constraints of server online times and offline times must be considered when allocating load partitions on servers.
From the above analysis, we can see that servers may have heterogeneous available and unavailable time periods for various reasons. Here, available time corresponds to the time period between the server’s release time and the server’s offline time. If we inadvertently assign tasks to servers without considering their availability constraints, all the unfinished workload partitions need to be reassigned to other available servers, resulting in an inefficient time schedule. Hence, limited server available times must be considered when scheduling workloads on a networked system. However, it has been proved that even without server availability constraints, the divisible-load scheduling problem under networked systems is also an NP-hard problem [
29].
As regards the server release times alone, several load-scheduling strategies were proposed. For example, the work in [
30] addressed the problem of scheduling a computationally intensive divisible load with server release times and finite size buffer capacity constraints in bus networks. The work in [
31] addressed divisible-load scheduling with server startup overheads and release times, while a new divisible-load scheduling model was proposed in [
32], considering server distribution sequence and release times. The authors in [
33] investigated the problem of scheduling multiple divisible loads in networked systems with arbitrary server release times and heterogeneous processing requirements of different workloads. In order to obtain a global optimal load scheduling strategy on tree networks, an exhaustive search algorithm was proposed in [
34], but as expected, exhaustive algorithms are time-consuming, especially when networks become large. To make it more time-efficient, the work in [
35] proposed a genetic algorithm. In addition to the research based on server release times, the authors in [
36] studied the impact of both server online times and offline times, that is, server available times, on the process of divisible-load scheduling.
However, the above studies are all based on single-installment scheduling, which has been proven to be not as efficient as multi-installment scheduling in minimizing the makespan of workloads [
10]. In single-installment scheduling models, the master divides large-scale workloads into load partitions with the same number as the slave servers and it only assigns load partitions to each slave server once. By contrast, in multi-installment scheduling models, the master divides workloads into load partitions that are several times the number of slave servers and assigns load partitions to each server in multiple rounds. It is thus clear that, compared with single-installment scheduling, multi-installment scheduling can reduce the waiting time of servers, so it can achieve a shorter makespan and higher utilization of platform resources.
In summary, on the one hand, it is known that multi-installment scheduling is superior to single-installment scheduling in terms of time efficiency; on the other hand, limited server available times should be considered when scheduling workloads on a networked system, but in the existing research, available time constraints have only been studied in single-installment scheduling models. Based on this background, in this paper, firstly, we explicitly consider server available times in our scheduling model, which brings the work closer to reality. Secondly, we design a multi-installment scheduling strategy for this scheduling problem at hand.
The remainder of this paper is organized as follows.
Section 2 firstly gives a mathematical description of the divisible-load scheduling problem on networked systems with arbitrary sever available times, followed by the proposed multi-installment scheduling model. With this model, we accordingly design a heuristic algorithm in
Section 3 to obtain an optimal load-partitioning scheme, which will be evaluated through experiments in
Section 4. In the last section, the conclusions are shared.
2. Multi-Installment Scheduling Model with Server Available Times
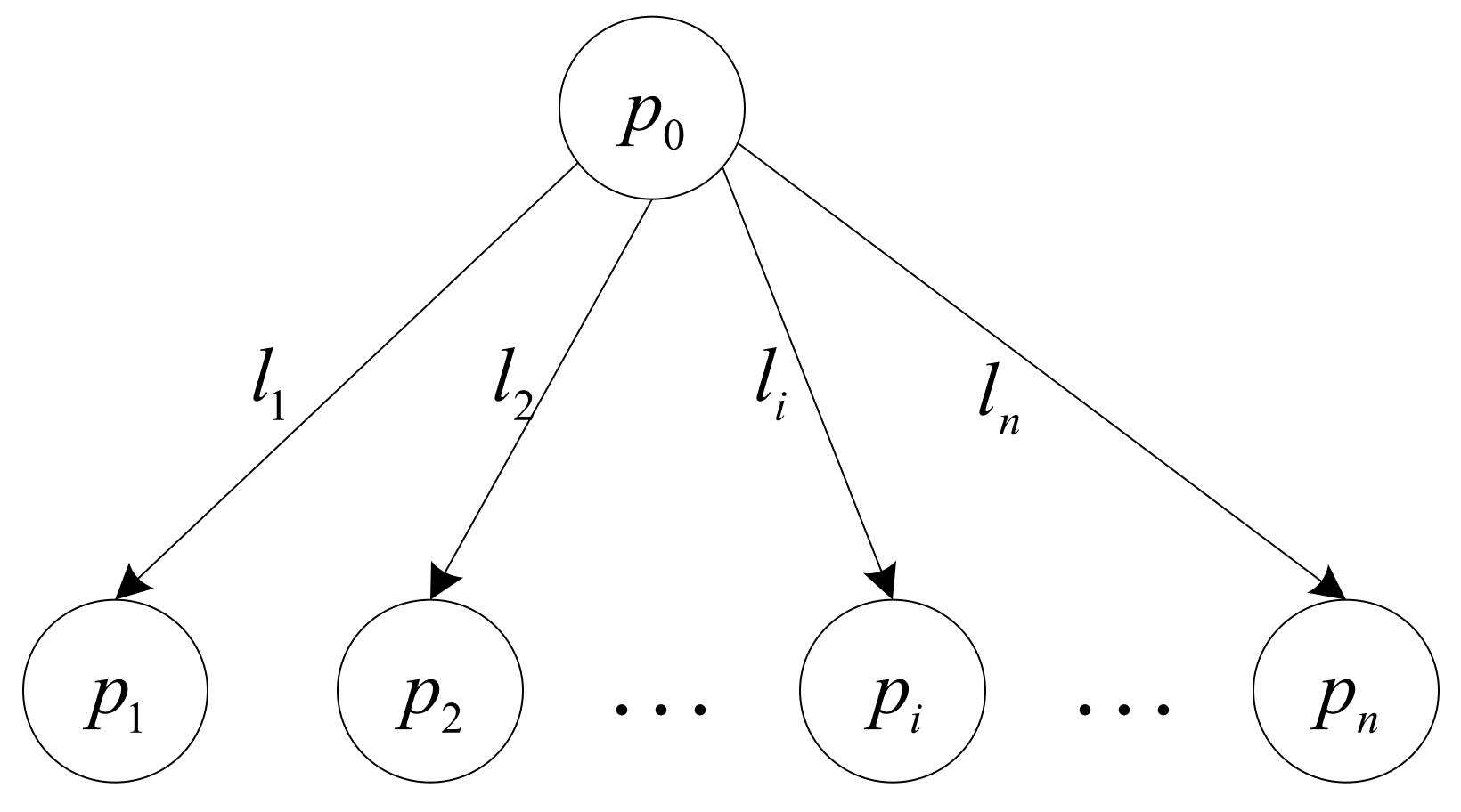
Let us consider
servers connected in a single-level tree topology, as illustrated in
Figure 1, where
represents the master and
denotes slave servers. The master
is different from the master of the entire distributed system, but represents a server that stores the workload waiting to be processed and it does not participate in the workload computation but is only responsible for splitting the workload and distributing load partitions to slave servers in multiple installments, while slave servers are responsible for workload computation. The master is connected to each slave server through communication links, denoted as
. When all servers have completed their assigned load partitions, the entire workload is considered to have been completed. The time required from the first server accepting its assignment to the last server finishing load computation is called the makespan of the entire workload. Evidently, the shorter the makespan is, the better. That is, the goal of optimization is to pursue the shortest makespan for the entire workload. For ease of reading, the most commonly used notations in this paper are listed in
Table 1.
The entire workload to be processed arrives at the master at time . First of all, before load transmission, it is necessary to establish a communication link between the master and each server, and experience a series of communication connections such as three handshakes. Due to the fact this period of time is relatively fixed, it can be regarded as a constant, which is called communication startup overhead, denoted as for link . Let be the time required for link to transmit unit size of workload. Hence, it takes time for link to transmit a workload with size . After receiving load partitions from the master, each server needs to start specific components or programs needed for load computation. This startup time can be regarded as a constant, called the computation startup overhead, denoted as for server . Let be the time required for server to finish computing the unit size of the workload. Hence, it takes time for server to complete a workload with size . The communication mode considered in this paper is a non-blocking mode. Hence, each server starts computing the moment it receives its assignment.
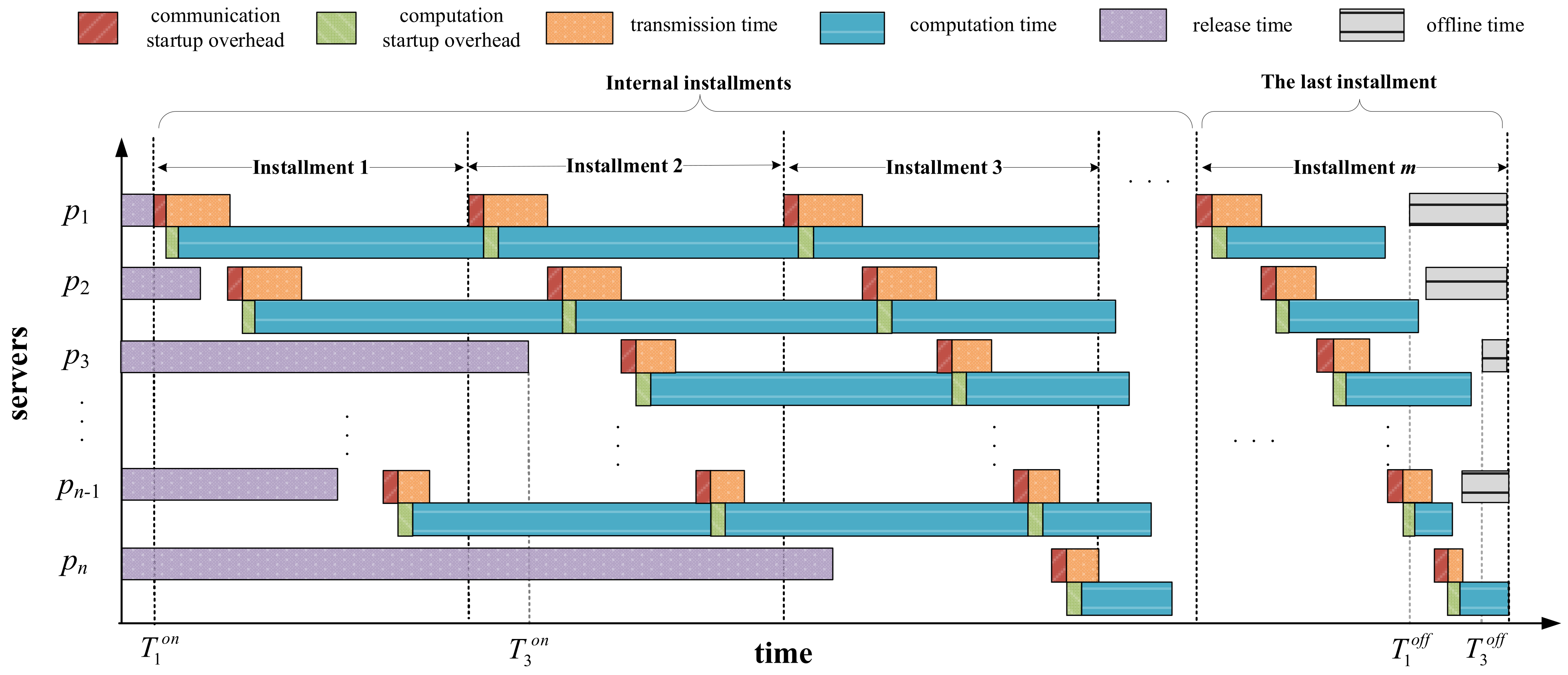
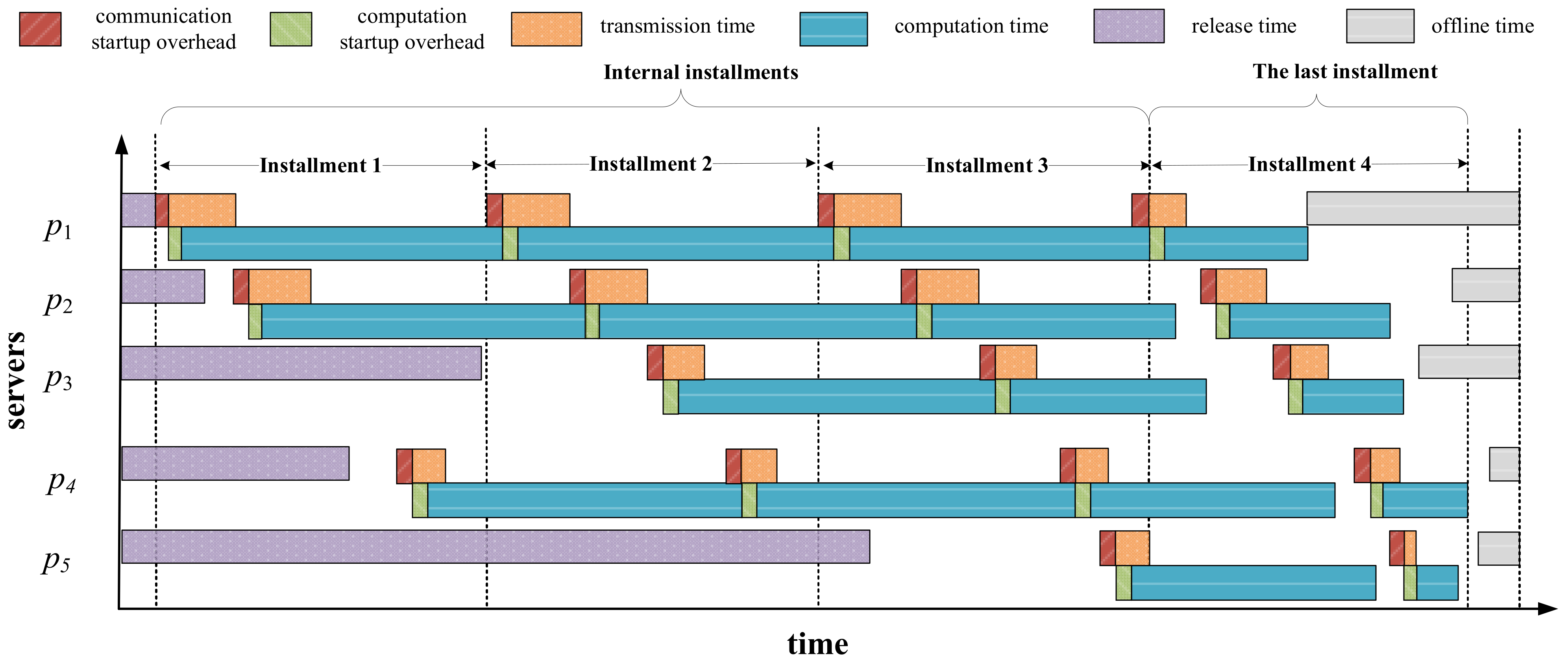
Figure 2 shows one possible Gantt chart for task-scheduling process on networked systems with arbitrary server available times. As can be seen, each server has different release and offline times, denoted as
and
, respectively. The scheduling process consists of
installments, in which the first
installments are denoted as internal installments. The last installment differs from the others since it ensures that all servers complete workload computation before their offline times and finish computing simultaneously as much as possible. If we do not consider server available times, to achieve the goal of minimizing the makespan, all servers are required to finish load computation at the same time. Otherwise, we can redistribute the partial load assigned to the server that finishes computing later to the server that completes first, thus reducing the makespan of the entire workload. This is referred to as the optimality principle in the DLT [
14]. However, under the constraint that servers have heterogeneous offline times, the optimality principle is no longer applicable. In the last installment, the redundant part of the load assigned on the servers that do not meet the offline time constraint should be rescheduled to other servers that meet the time constraint. Moreover, for those servers that meet the offline time constraint, their load completion times should be as identical as possible to minimize the makespan.
The total size of the workload that all servers are expected to complete in each installment is . The master assigns to server the loads and in every internal installment and the last installment. The master transmits load partitions to one server at a time, that is, each server starts to receive its load partition after the master has finished sending divisions to its previous server. It is worth noting that each server must wait until its online time arrives to start receiving and computing its assigned load partitions, that is, the start time of each server is equal to the greater part of its online time and the time its previous server finished receiving its assignment. Similarly, each server must complete load computation in the last installment before its offline time arrives. Therefore, the makespan of the entire workload depends on the server that completes load computation the latest.
The goal of this paper is to find an optimal, if not a sub-optimal, load partitioning scheme that minimizes the makespan of the entire workload under the constraints of server available times.
2.1. Internal Installments
In order to ensure that each server has no time interval between any two adjacent internal installments, all servers must take the exact same time to process their assigned load fractions. Thus, we have
By Equation (1),
can be expressed by
as
Substituting Equation (3) into (2) yields
Substituting Equation (4) into
, we have
Let
and
, we can simplify Equation (5) as
Then, we obtain an optimal load partition for the internal installments as follows:
Although the entire workload arrives at the master at time
, the scheduling process starts when the first server
releases from its previous load computation at time
. If we neglect the online time constraint, the theoretical start time
of server
is as follows:
Due to the online time constraint, servers may not be able to participate through the whole scheduling process. Hence, we need to identify which number of installments
server
can participate in the earliest as long as it meets the online time constraint.
In theory, the total amount of workload that should be completed by all internal installments is . However, if there exists with , then server will miss several internal installments, resulting in the amount of workload not being completed entirely. The unfinished part of workload should be scheduled and completed in the last installment.
2.2. The Last Installment
The size of the workload waiting to be processed in the last installment can be written as
Here, we shall first derive an optimal load partition for the last installment without considering the offline time constraint. According to the optimal principle in the DLT, all servers should finish computing at the same time, so we have
From Equation (11),
can be expressed by
Let us define two new variables below for convenience.
Simplifying Equation (12) by Equation (13), we have
By recursively calculating Equation (14) by the iterative method, one can obtain the expression of
by
where
From the previous analysis, we know that the total amount of workload that all servers need to complete in the last scheduling is
, that is,
Substituting Equation (15) into Equation (17), one can obtain an optimal load partition for the last installment without taking the offline time constraint into consideration.
Likewise, let
and
. Then, Equation (18) can be simplified as
So far, without considering the offline time constraint, we have derived an optimal load partition for the last installment. However, since servers have heterogeneous offline times, it is necessary to adjust the value of , so that the makespan of the entire workload could be the shortest under available time constraints.
2.3. Scheduling Model
Based on the actual load partitions for the last installment, the completion time
of server
can be written as follows:
Therefore, the makespan the entire workload is
where
,
and
.
Here, we establish a new scheduling model aiming at a minimum makespan
T under the available time constraints on networked systems.
subject to
- (a)
- (b)
where
- (1)
- (2)
- (3)
- (4)
- (5)
The optimization goal of the above model is to minimize the makespan of the entire workload. Although makespan
is a function of
,
, and
according to Equation (22), we can obtain an optimal solution to
and
in
Section 2.1, so only one set of variables, that is
, is involved in the proposed model. Moreover, this model contains two constraints. Constraint (a) means that every load partition assigned to severs in the last installment cannot be negative and that the total amount of workload completed by all servers in the last installment must be equal to
. Constraint (b) indicates that all servers must meet their corresponding offline time constraint. The reason for which the online time constraint is not reflected in the proposed model is that in
Section 2.1 we have already taken online times into full consideration when obtaining an optimal to
and
.
3. Heuristic Scheduling Algorithm
In this section, a heuristic algorithm is designed to solve our proposed optimization model. It includes two strategies: a repair strategy and a local search strategy. The repair strategy is responsible for ensuring that all servers finish their load computation before their offline times, while the local search strategy ensures that servers can finish computing at the same time as much as possible (on the premise of satisfying available time constraints), so as to minimize the makespan of the entire workload.
3.1. Repair Strategy
The idea of the repair strategy is searching from to in turn to find the server that does not meet time constraints. If the completion time of server is greater than its offline time , this means that the master has allocated too great an amount of assignment to this server. The extra amount of load will be assigned to the next server, that is, . In this way, we only need to verify all servers once from beginning to end, and the time constraints of the proposed model will be satisfied after one round of repairment. In the worst case, all servers need to be fixed once.
Let us suppose there exists server
that
. Let
be the amount of load that needs to be assigned to server
. We have
We need to reschedule
from server
to server
. Let
and
, respectively, be the updated amounts of load that is scheduled on servers
and
after repairing.
Since load partitions assigned on servers
and
have been adjusted, their completion times are altered correspondingly, as follows.
It is worth noting that since the master allocates less amount of load to server
in the last installment, its transmission time becomes shorter. Conversely, as server
has to undertake more load, its transmission takes a longer time. Due to the heterogeneity of the networked systems, the reduced transmission time of server
is not necessarily equal to the increased transmission time of server
. This will cause the completion time
of server
with
that schedules after
changes as follows.
So far, the repair operation of server is completed. The repairment will continue to the next server . If cannot complete its assignment before it reaches its offline time, we need to reschedule its overloaded partition to server and recalculate the completion time of all the servers behind . Repeat this process until all servers have gone through the repair operation once.
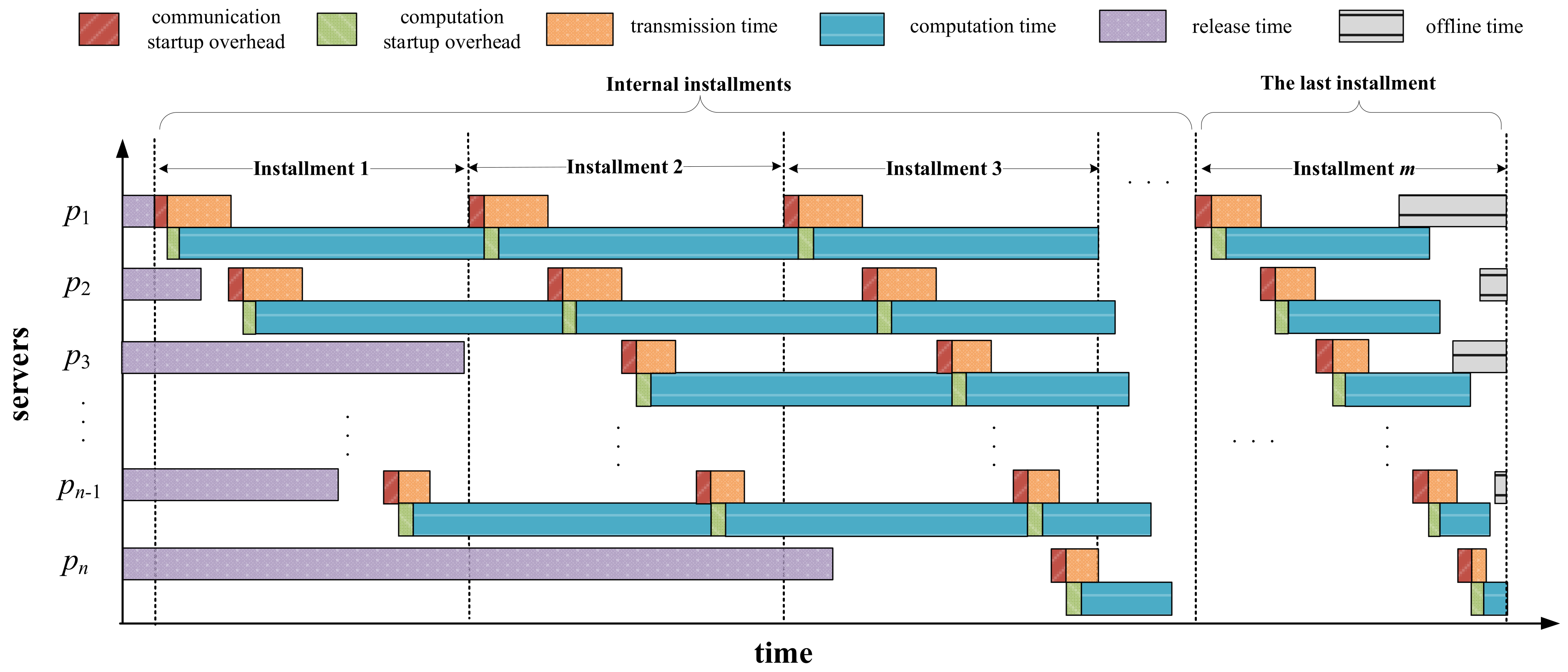
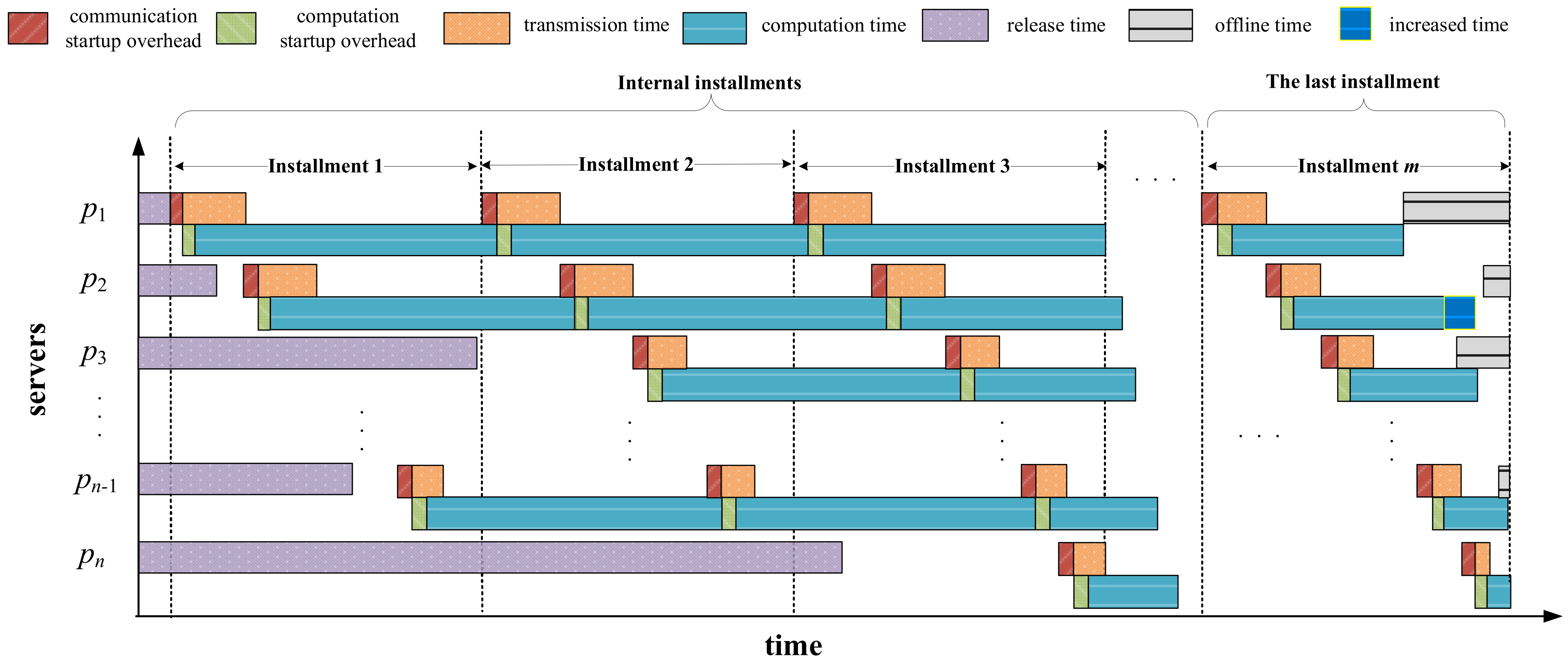
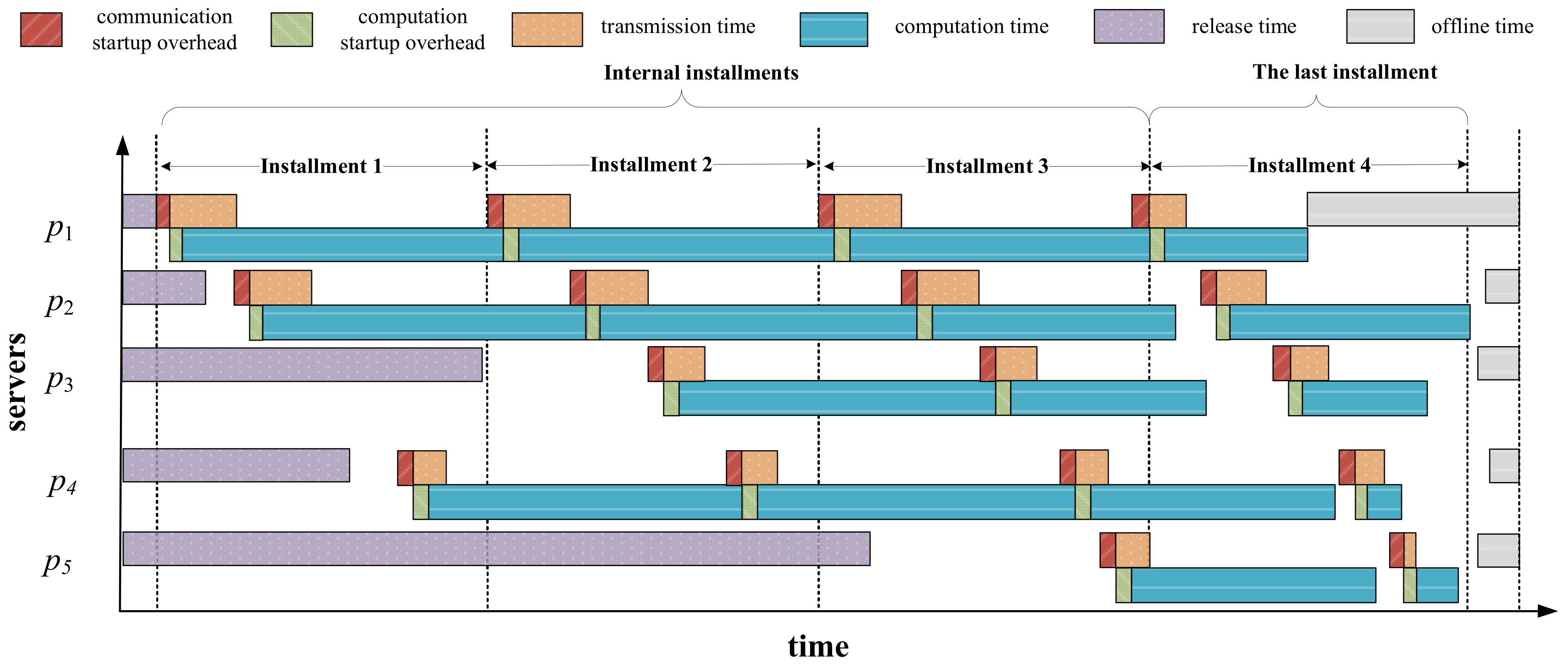
Figure 3 shows a case of multi-installment scheduling before applying the repair strategy. As can be seen from this figure, in the last installment, the completion time of server
has exceeded its offline time. Hence, we have to reschedule the extra part of the load assigned on
to server
, as illustrated in
Figure 4. After being repaired, server
finishes computing when its offline time arrives. Additionally, one can observe from
Figure 4 that although server
has been added with more load to process, it does not violate its offline time constraint. Therefore, we do not need to apply the repair operation on server
.
3.2. Local Search Strategy
After applying the repair strategy, all servers meet their offline time constraints, but the load partitioning scheme in the last installment at this time may not be an optimal solution to our proposed model. In this section, we shall put forward a local search strategy to enable as many servers as possible to finish computing at the same time while satisfying time constraints, thus minimizing the makespan of the entire workload.
The Idea of the local search strategy is to find the servers that finish computing the earliest and the latest, that is, to find the two servers with the largest gap in their completion times, and then balance the amount of load assigned on them to reduce the makespan. It is worth noting that the completion time of the earliest server must not have reached its offline time, because we need to allocate more load on it without violating its time constraint.
Let be the server that finishes computing the earliest and be the latest. After local search, their competition times turn into the same, that is . Let us suppose that the amount of load that needs to be rescheduled from to is . We shall discuss the value of in two scenarios.
The first case is when
, which means that in the distribution sequence of the servers, server
is in front of server
. Then, the following equations hold.
From Equation (27), one can derive the value of
as
To avoid violating the offline time constraint,
should be confined as follows.
It is worth noting that since we allocate more load on server
, it needs more communication time to complete load transmission, which will definitely affect all subsequent servers behind
in the distribution sequence and will increase their completion times. Similarly, we assign less load on server
, so its communication time becomes shorter, which will reduce the completion times of all subsequent servers behind
. Therefore, those servers lying between
and
in the distribution sequence are only affected by
. Their completion times will be changed into the following values.
The servers behind
in the distribution sequence are affected by both
and
. Their completion times will be altered as follows.
Observing Equations (30) and (31), we can come to the conclusion that all servers behind are affected. After local search, there may exist servers that violate time constraints, and thus we still need to apply the repair strategy on them.
Figure 5 shows an example of the case when
. As can be seen from this figure, server
finishes computing at its offline time. Although it has the shortest completion time, server
is not involved in the local search operation since it cannot be assigned more load. Except for
, server
finishes computing the earliest while server
finishes the latest. The load partitions allocated on them should be adjusted according to Equation (29). After load adjustment, the completion time of server
will be enlarged, which can be updated by Equation (30). Meanwhile, the completion time of server
will be affected by both servers
and
, which can be calculated by Equation (31). Servers
and
may violate the offline time constraint, so they need to be verified or even repaired by the repair strategy.
The other case is when
, which means that server
is behind server
in the distribution sequence. Then, the following equations hold.
From Equation (32), one can derive the value of
as follows.
Similarly, to avoid violating the offline time constraint, should be confined according to Equation (29). It is worth noting that since we allocate more load on server , it needs more communication time to complete load transmission, which will definitely affect all subsequent servers behind in the distribution sequence and will increase their completion times. Similarly, we assign less load on server , so its communication time becomes shorter, which will reduce the completion times of all subsequent servers behind .
Those servers lying between
and
in the distribution sequence are only affected by
. Their completion times will be changed into the following values.
Those servers behind
in the distribution sequence are affected by both
and
. Their completion times will be altered as follows.
Different from the first case, when , the completion times of the servers between and are reduced after local search, as can be observed from Equation (34). Hence, they keep obeying the offline time constraint and need not to be repaired. By contrast, according to Equation (35), those servers behind in the distribution sequence may violate time constraints, and thus they need to be verified or even repaired.
Let
and
, respectively, be the updated amounts of load rescheduled on servers
and
after local search. Then, we have
Figure 6 shows an example of the case when
. Similar to
Figure 5, except for server
, which is not involved in the local search operation, server
finishes computing the latest while server
finishes the earliest. The load partitions allocated to them should be adjusted according to Equation (29). After load adjustment, the completion time of server
will be reduced, which can be updated by Equation (34). Meanwhile, the completion time of server
will be affected by both servers
and
, which can be calculated by Equation (35). Different from the case illustrated in
Figure 5, only server
needs to be verified or even repaired by the repair strategy.
3.3. Heuristic Algorithm
The proposed model only involves one set of variables, that is, the load partitioning scheme
for the last installment. To solve this model, we shall put forward in this section a heuristic algorithm, whose framework is given in Algorithm 1.
| Algorithm 1. Heuristic Scheduling Algorithm |
| Input: Workload size , number of installments, parameters of servers, including with . |
| Output: An optimal load-partitioning scheme , where , and . |
| Step 1: Obtain an optimal load partition for internal installments by Equation (7). |
| Step 2: According to Equation (9), obtain the value of , indicating which number of installments each server starts to participate in the internal installments. |
| Step 3: Use Equation (10) to calculate out the amount of load that servers need to undertake in the last installment. |
| Step 4: Initialize load partition for the last installment by Equation (19). |
| Step 5: Apply repair strategy to update according to Equation (24). |
| Step 6: Repeat applying local search strategy to update according to Equation (36) until the completion time of every server is as identical as possible on the premise of meeting its offline time constraint. |
Algorithm 1 first finds an optimal solution to the internal installments through steps 1 and 2. With the solutions of and , Algorithm 1 initializes via steps 3 and 4. In order to meet the time constraints of the proposed model, Algorithm 1 repairs the load partitioning scheme through step 5, and then finds an optimal solution to through step 6. Algorithm 1 stops when the competition time gap between any two servers who finish computing before their offline times is lesser than a small threshold.
4. Experiments and Analysis
In this section, we shall compare the model and algorithm proposed in this paper (denoted as MIS) with the existing single-installment scheduling model and algorithm based on server available times [
36] (abbreviated as SIS), to prove that the proposed model and algorithm can achieve a shorter makespan.
In the following experiments, the total number of servers is set to be 15, that is,
.
Table 2 lists the parameters of the heterogenous networked system, where
is the communication startup overhead of server
,
is the communication time of link
to transmit the unit size of workload,
is the computation startup overhead of server
,
is the computation time of server
to finish computing unit size of workload,
is the online time of server
while
is its offline time. These values listed in
Table 2 are commonly used in the DLT field [
10].
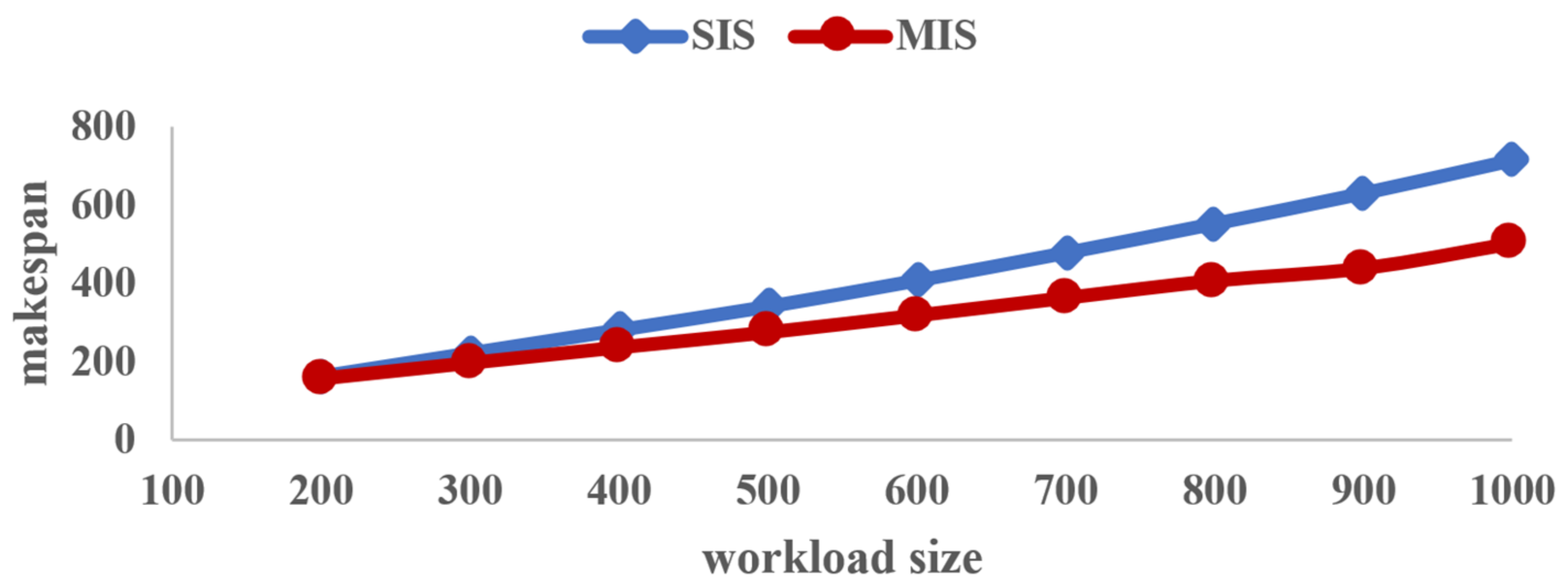
Table 3 gives the makespan obtained by the two algorithms SIS and MIS with different workloads. In order to visually demonstrate their difference,
Figure 7 shows the curve of makespan vs. workload size.
As can be seen from
Figure 7, first of all, no matter how great the workload is, the makespan obtained by the proposed algorithm MIS (represented in red) is always less than that obtained by the compared algorithm SIS (marked in blue). That is to say, our proposed heuristic algorithm can obtain a shorter makespan of workloads and improve the workload processing efficiency when addressing scheduling problems employing heterogeneous servers with arbitrary available times.
Secondly, one can observe from
Figure 7 that with an increase in the workload size, the makespan obtained by either of the two algorithms SIS and MIS becomes larger and larger. Moreover, it is worth noting that the time gap between the two algorithms is greatly increased, which indicates that the proposed algorithm has superior performance in solving large-scale divisible-load scheduling problems in the era of big data.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}