
A Neural Network-Based Random Access Protocol for Crowded Massive MIMO Systems

 , , , and
, , , and
Abstract
:1. Introduction
- (i)
- We propose a GB RA protocol for crowded M-MIMO systems applying an NN at the UEs’ side to assist in self-classification as the strongest competitor or not, allowing the UEs to resolve pilot collisions in a decentralized and uncoordinated manner;
- (ii)
- The offline training procedure of the NN to the RA problem is entirely characterized, including data collection, preprocessing, training, and validation steps. In addition, to avoid excessively complex processing at the devices’ side, we show that a simple MLP with only one hidden layer with five neurons is able to remarkably improve the connectivity performance;
- (iii)
- Extensive numerical results are provided corroborating the performance of the proposed approach, including the performance influence of certain key NN parameters and the robustness against the variation of some network parameters, like the number of BS antennas and transmit power.
2. Materials and Methods
2.1. System Model
2.2. Neural Network Classifier
2.2.1. Database Acquisition
2.2.2. Preprocessing
2.2.3. Neural Network Training
2.2.4. Validation
3. Results and Discussion
3.1. Classification Performance
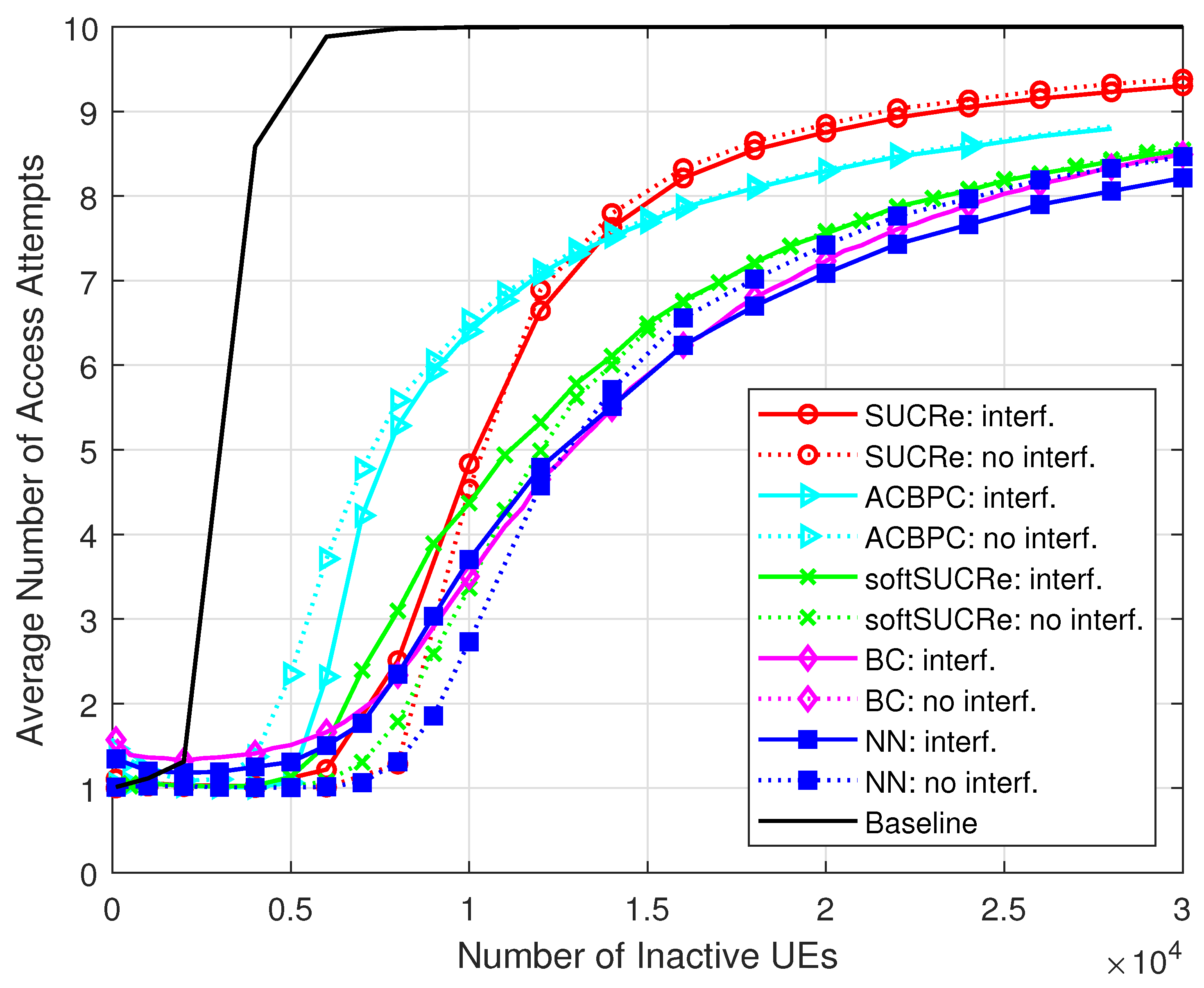
3.2. Connectivity Performance
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 5G | Fifth-generation |
| UE | User equipment |
| RA | Random access |
| SUCRe | Strongest-user collision resolution |
| BS | Base station |
| NN | Neural network |
| B5G | Beyond fifth-generation |
| eMBB | Enhanced mobile broadband |
| M-MIMO | Massive multiple-input multiple-output |
| CF | Cell-free |
| GF | Grant-free |
| GB | Grant-based |
| DL | Downlink |
| UL | Uplink |
| ACB | Access class barrier |
| ACBPC | Access class barring with power control |
| XL-MIMO | Extra-large MIMO |
| BC | Bayesian classifier |
| NN | Neural network |
| MLP | Multilayer perceptron |
| FFAAs | Fraction of failed access attempts |
| ANAAs | Average number of access attempts |
| TDD | Time-division duplex |
| PDP | Payload data pilot |
| ICI | Inter-cell interference |
| MSE | Mean square error |
| SNR | Signal-to-noise ratio |
References
- Chen, X.; Ng, D.W.K.; Yu, W.; Larsson, E.G.; Al-Dhahir, N.; Schober, R. Massive Access for 5G and Beyond. IEEE J. Sel. Areas Commun. 2021, 39, 615–637. [Google Scholar] [CrossRef]
- Marzetta, T.L. Noncooperative Cellular Wireless with Unlimited Numbers of Base Station Antennas. IEEE Trans. Wirel. Commun. 2010, 9, 3590–3600. [Google Scholar] [CrossRef]
- Parkvall, S.; Dahlman, E.; Furuskar, A.; Frenne, M. NR: The New 5G Radio Access Technology. IEEE Commun. Stand. Mag. 2017, 1, 24–30. [Google Scholar] [CrossRef]
- Hoydis, J.; ten Brink, S.; Debbah, M. Massive MIMO in the UL/DL of Cellular Networks: How Many Antennas Do We Need? IEEE J. Sel. Areas Commun. 2013, 31, 160–171. [Google Scholar] [CrossRef]
- Rusek, F.; Persson, D.; Lau, B.K.; Larsson, E.G.; Marzetta, T.L.; Edfors, O.; Tufvesson, F. Scaling Up MIMO: Opportunities and Challenges with Very Large Arrays. IEEE Signal Process. Mag. 2013, 30, 40–60. [Google Scholar] [CrossRef]
- Larsson, E.G.; Edfors, O.; Tufvesson, F.; Marzetta, T.L. Massive MIMO for next generation wireless systems. IEEE Commun. Mag. 2014, 52, 186–195. [Google Scholar] [CrossRef]
- Lu, L.; Li, G.Y.; Swindlehurst, A.L.; Ashikhmin, A.; Zhang, R. An Overview of Massive MIMO: Benefits and Challenges. IEEE J. Sel. Top. Signal Process. 2014, 8, 742–758. [Google Scholar] [CrossRef]
- Björnson, E.; Sanguinetti, L.; Hoydis, J.; Debbah, M. Optimal Design of Energy-Efficient Multi-User MIMO Systems: Is Massive MIMO the Answer? IEEE Trans. Wirel. Commun. 2015, 14, 3059–3075. [Google Scholar] [CrossRef]
- Björnson, E.; Larsson, E.G.; Marzetta, T.L. Massive MIMO: Ten myths and one critical question. IEEE Commun. Mag. 2016, 54, 114–123. [Google Scholar] [CrossRef]
- Fernandes, F.; Ashikhmin, A.; Marzetta, T.L. Inter-Cell Interference in Noncooperative TDD Large Scale Antenna Systems. IEEE J. Sel. Areas Commun. 2013, 31, 192–201. [Google Scholar] [CrossRef]
- Jin, S.; Wang, X.; Li, Z.; Wong, K.K.; Huang, Y.; Tang, X. On Massive MIMO Zero-Forcing Transceiver Using Time-Shifted Pilots. IEEE Trans. Veh. Technol. 2016, 65, 59–74. [Google Scholar] [CrossRef]
- Van Chien, T.; Björnson, E.; Larsson, E.G. Joint Pilot Design and Uplink Power Allocation in Multi-Cell Massive MIMO Systems. IEEE Trans. Wirel. Commun. 2018, 17, 2000–2015. [Google Scholar] [CrossRef]
- Xu, H.; Huang, N.; Yang, Z.; Shi, J.; Wu, B.; Chen, M. Pilot Allocation and Power Control in D2D Underlay Massive MIMO Systems. IEEE Commun. Lett. 2017, 21, 112–115. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, Z.; Dai, L.; Qian, C. Smart Pilot Assignment for Massive MIMO. IEEE Commun. Lett. 2015, 19, 1644–1647. [Google Scholar] [CrossRef]
- Polegre, A.A.; Sanguinetti, L.; Armada, A.G. Pilot Decontamination Processing in Cell-Free Massive MIMO. IEEE Commun. Lett. 2021, 25, 3990–3994. [Google Scholar] [CrossRef]
- Björnson, E.; de Carvalho, E.; Sørensen, J.H.; Larsson, E.G.; Popovski, P. A Random Access Protocol for Pilot Allocation in Crowded Massive MIMO Systems. IEEE Trans. Wirel. Commun. 2017, 16, 2220–2234. [Google Scholar] [CrossRef]
- Bueno, F.A.D.; Yamamura, C.F.; Goedtel, A.; Marinello Filho, J.C. A Random Access Protocol for Crowded Massive MIMO Systems Based on a Bayesian Classifier. IEEE Wirel. Commun. Lett. 2022, 11, 2455–2459. [Google Scholar] [CrossRef]
- Han, H.; Guo, X.; Li, Y. A High Throughput Pilot Allocation for M2M Communication in Crowded Massive MIMO Systems. IEEE Trans. Veh. Technol. 2017, 66, 9572–9576. [Google Scholar] [CrossRef]
- Han, H.; Li, Y.; Guo, X. A Graph-Based Random Access Protocol for Crowded Massive MIMO Systems. IEEE Trans. Wirel. Commun. 2017, 16, 7348–7361. [Google Scholar] [CrossRef]
- Marinello, J.C.; Abrão, T.; Souza, R.D.; de Carvalho, E.; Popovski, P. Achieving Fair Random Access Performance in Massive MIMO Crowded Machine-Type Networks. IEEE Wirel. Commun. Lett. 2020, 9, 503–507. [Google Scholar] [CrossRef]
- Marinello, J.C.; Abrão, T. Collision Resolution Protocol via Soft Decision Retransmission Criterion. IEEE Trans. Veh. Technol. 2019, 68, 4094–4097. [Google Scholar] [CrossRef]
- Han, H.; Li, Y.; Guo, X. User Identity-Aided Pilot Access Scheme for Massive MIMO-IDMA System. IEEE Trans. Veh. Technol. 2019, 68, 6197–6201. [Google Scholar] [CrossRef]
- Han, H.; Fang, L.; Lu, W.; Chi, K.; Zhai, W.; Zhao, J. A Novel Grant-Based Pilot Access Scheme for Crowded Massive MIMO Systems. IEEE Trans. Veh. Technol. 2021, 70, 11111–11115. [Google Scholar] [CrossRef]
- Marinello Filho, J.C.; Brante, G.; Souza, R.D.; Abrão, T. Exploring the Non-Overlapping Visibility Regions in XL-MIMO Random Access and Scheduling. IEEE Trans. Wirel. Commun. 2022, 21, 6597–6610. [Google Scholar] [CrossRef]
- Iimori, H.; Takahashi, T.; Ishibashi, K.; de Abreu, G.T.F.; González G., D.; Gonsa, O. Joint Activity and Channel Estimation for Extra-Large MIMO Systems. IEEE Trans. Wirel. Commun. 2022, 21, 7253–7270. [Google Scholar] [CrossRef]
- Tao, J.; Chen, J.; Xing, J.; Fu, S.; Xie, J. Autoencoder Neural Network Based Intelligent Hybrid Beamforming Design for mmWave Massive MIMO Systems. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 1019–1030. [Google Scholar] [CrossRef]
- Yang, P.; Zhu, J.; Xiao, Y.; Chen, Z. Antenna selection for MIMO system based on pattern recognition. Digit. Commun. Networks 2019, 5, 34–39. [Google Scholar] [CrossRef]
- 3GPP TS 38.321-1; Medium Access Control (MAC) Protocol Specification (Release 16). ETSI: Sophia Antipolis, France, 2020; 3rd Generation Partnership Project (3GPP); Version 16.1.0.
- da Silva, I.; Spatti, D.; Flauzino, R.; Liboni, L.; dos Reis Alves, S. Artificial Neural Networks: A Practical Course; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- 3GPP TR 38.901; Study on Channel Model for Frequencies from 0.5 to 100 GHz. ETSI: Sophia Antipolis, France, 2020; 3rd Generation Partnership Project (3GPP); Version 16.1.0.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Description |
|---|---|---|
| M | 100 | Number of BS antennas in the center and neighboring cells |
| 0.001 | Transmission probability | |
| 0.5 | Probability of trying again in the next RA block | |
| 10 | Number of available RA pilot sequences | |
| 27 dBm | Transmit power of the UEs | |
| q | 27 dBm | Transmit power of the BS per pilot |
| −98.65 dBm | Noise variance | |
| −1 | Number of standard deviations in the bias term | |
| 10 | Number of active users in each neighboring cell | |
| [100, 40,000] | Indicates that in the center cell, evenly distributed in steps of 100 UEs in [100, 1000], and steps of 500 in [1000, 40,000] | |
| Edge SNR | 0 dB | Edge SNR in the center cell |
| 6 | Number of neighboring cells | |
| R | 250 m | Radius of the cells |
| 27 dBm | Transmit power of UEs in adjacent cells | |
| 10 dB | Shadow-fading standard deviation | |
| 10,000 | Number of Monte Carlo realizations | |
| 10 | Maximum number of connection attempts before the UE gives up |
| Recall | Precision | F-Measure | Accuracy | |
|---|---|---|---|---|
| 3 | 0.7414 | 0.8380 | 0.7867 | 0.9719 |
| 4 | 0.7414 | 0.8380 | 0.7867 | 0.9718 |
| 5 | 0.7485 | 0.8355 | 0.7896 | 0.9721 |
| 6 | 0.7567 | 0.8192 | 0.7867 | 0.9713 |
| 7 | 0.7079 | 0.8532 | 0.7738 | 0.9713 |
| 8 | 0.7941 | 0.7925 | 0.7933 | 0.9713 |
| 9 | 0.7763 | 0.8079 | 0.7918 | 0.9718 |
| 10 | 0.7689 | 0.8081 | 0.7918 | 0.9713 |
| Recall | Precision | F-Measure | Accuracy | |
|---|---|---|---|---|
| 0.01 | 0.7738 | 0.8113 | 0.7921 | 0.9718 |
| 0.05 | 0.7556 | 0.8225 | 0.7876 | 0.9716 |
| 0.1 | 0.7280 | 0.8567 | 0.7871 | 0.9720 |
| 0.15 | 0.7617 | 0.8355 | 0.7880 | 0.9714 |
| 0.2 | 0.7485 | 0.8355 | 0.7896 | 0.9721 |


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bueno, F.A.D.; Yamamura, C.F.; Scalassara, P.R.; Abrão, T.; Marinello, J.C. A Neural Network-Based Random Access Protocol for Crowded Massive MIMO Systems. Sensors 2023, 23, 9805. https://doi.org/10.3390/s23249805
Bueno FAD, Yamamura CF, Scalassara PR, Abrão T, Marinello JC. A Neural Network-Based Random Access Protocol for Crowded Massive MIMO Systems. Sensors. 2023; 23(24):9805. https://doi.org/10.3390/s23249805
Chicago/Turabian StyleBueno, Felipe Augusto Dutra, Cézar Fumio Yamamura, Paulo Rogério Scalassara, Taufik Abrão, and José Carlos Marinello. 2023. "A Neural Network-Based Random Access Protocol for Crowded Massive MIMO Systems" Sensors 23, no. 24: 9805. https://doi.org/10.3390/s23249805