1. Introduction
The utilization of analog circuits is prevalent throughout numerous electronic devices, such as communication equipment and control systems. Because their components have poor tolerance, they are more susceptible to interference and influence. According to relevant surveys, approximately 80% of all electronic circuits employed within electronic equipment are digital circuits. While digital circuits account for the majority of electronic circuits, analog circuits continue to make up a small portion, around 20% of the total, resulting in excess of 80% of system faults [
1]. In analog circuit faults, complex faults can directly cause the system to malfunction and are easily detected. Soft faults are mainly caused by abnormal changes in resistance, capacitance, and inductance parameters, and the measurement is complex and challenging [
2]. Since analog circuits are composed of nonlinear and fault-tolerant components, the insufficient number of measurable nodes and measurement uncertainty make fault diagnosis complex. Therefore, realizing soft fault diagnosis at the component level is still challenging. Over the past few decades, numerous scholars have delved into this field, proposing various types of fault diagnostic approaches [
3,
4,
5,
6]. The field of artificial intelligence has experienced remarkable advancement in recent years, enabling the formulation and successful application of various deep learning models for fault diagnosis due to their excellent independent feature extraction capabilities and outstanding complex process generalization capabilities [
7,
8]. Recently, a deep neural network islanding detection technique based on statistical features was proposed in reference [
9], and non-islanding disturbances were classified for hybrid systems based on synchronous and inverter distributed generators, which is a highlight in the field of fault diagnosis. The authors of [
10] propose a novel technique for analog circuit fault detection using the application of image recognition, converting the power spectral density of the output signal into a two-dimensional image and inputting it into a deep convolutional neural network to achieve image classification and achieve the purpose of fault detection. Yu et al. [
11] conducted research on a novel method for fault detection and diagnosis, which is predicated on a fusion of the firefly algorithm, tent chaos mapping, and extreme learning machine. The efficacy of this approach is exceptional in its ability to generalize well in the realm of fault diagnosis. Liu et al. [
12] proposes a fault diagnosis method based on vibration sensor in ellipsoidal-ARTMAP network and differential evolution algorithm.
The remarkable diagnostic performance exhibited by many deep learning models is inherently tied to the acquisition of sufficient and uniformly distributed data samples. Nevertheless, in practical applications, the procurement of sufficient fault samples proves to be a formidable task owing to various reasons such as costs and safety concerns. When problems such as a small number of samples or different data distributions under different working conditions occur, the impact of a particular factor on the efficacy and precision of the neural network-based fault diagnosis system will be significant. The deep learning model requires much data support to exert its powerful capabilities in data modeling and classification identification. It also requires sufficient data coverage under different working conditions to ensure the capability of a deep learning model to extend its knowledge learned and evolve to novel situations, which is evaluated in [
13]. When the limited amount of data is utilized directly for deep learning training, it will lead to extremely serious overfitting, especially not conducive to fault diagnosis. Effective training of deep learning models with small sample datasets requires preprocessing of the data, which is pivotal to achieving optimal training outcomes. The core of small sample fault diagnosis is to resolve the issue of an insufficient number of samples. In the field of fault diagnosis research, using original samples to expand the amount of data or improve data quality is an effective solution. The existing main methods to expand the target sample size are the Synthetic Minority Oversampling Technique (SMOTE), variational autoencoder (VAE) [
14], autoregressive model [
15], and generative adversarial network (GAN) [
16,
17]. Chawla et al. [
18] introduced the SMOTE technique, which increases the quantity of samples available for analysis by finding similar samples near the minority class samples and synthesizing new small samples. However, it should be noted that when the samples are distributed on the edge of the classification, the samples synthesized by the SMOTE method classification boundaries may be blurred. Autoregressive models can perform density estimation on sequence data well, but their computational load is much larger than that of VAE and GAN. The VAE method is a commonly used generative model. Through the hidden features (low-dimensional hidden variables) learned in the input data, these hidden features are sampled and reconstructed, and finally, new data similar to the input data are generated, such as in reference [
19], which introduces a variational autoencoder (VAE) into the fault diagnosis, facilitating data augmentation through the generation of vibration signals. Subsequently, an enhanced fault diagnosis method is proposed, wherein a convolutional neural network is combined with the aforementioned approach to realize improved accuracy and performance. Although the VAE method is trained and the training process is relatively stable, the generated pictures are relatively blurred, and the generated samples lack the capability to capture comprehensive fault information. In addition, the authors of [
20] designed an adversarial transfer network comprising multiple scales based on an attention mechanism that automatically distinguishes various bearing fault states. The TrAdaBoost method is different from other methods of expanding the target sample size. It uses auxiliary datasets for training and applies them to the training of classifiers through weight adjustment. Xiao et al. [
21] used CNN as a classifier, combined with the method of assigning weights to joint training datasets and the weight update of the TrAdaBoost model to achieve accurate fault diagnosis with high precision for small samples. The TrAdaBoost method is flexible and easy to operate when combined with other classifiers but requires a suitable and similar auxiliary dataset, which is difficult to obtain. In addition, classification difficulty increases when there is noise in the dataset itself.
In 2014, Goodfellow et al. [
22] summarized the characteristics of the generative and discriminative models in machine learning and proposed a creative network model-generated confrontation network (GAN). A novel deep learning approach has emerged that can be utilized for the purpose of data augmentation, data generation, data modeling, and other fields. Traditional GAN uses Jensen–Shannon divergence (JS divergence) to quantify the degree of congruence between false images and authentic images. With the in-depth research on the GAN network, researchers found that the network is prone to problems such as network collapse and gradient explosion during the training process, which makes the GAN network challenging to train. In order to address the aforementioned issues, more and more variant algorithms have been proposed. Least Squares Generative Adversarial Networks (LSGAN) [
23] are designed to enhance the objective function of a GAN network, specifically the discriminator, by replacing the cross-entropy loss function with a least squares loss function, making the transfer of gradients more effective and the model’s training process more stable. Liu et al. [
24] advanced a technique that amalgamates variational autoencoding and GAN to glean precise features of real data samples in the context of data scarcity. Wasserstein GAN [
25,
26] effectively substitutes the Kullback–Leibler (KL) divergence and Jensen–Shannon (JS) divergence with the Wasserstein distance in order to accurately measure the distance between the generated distribution and the actual distribution and make the gradient calculation of the generator more accurate. The conditional generative adversarial network (CGAN) [
27] proposes adding conditional information to GAN’s network structure so that GAN can accurately train and generate images of various categories in one model simultaneously and according to different datasets and generation requirements. Similarly, Dixit et al. [
28] used CGAN to generate vibration signals of rotating machines. Then, they used auxiliary classifiers as GAN discriminators in these signals and performed meta-learning to improve the generalization of classifiers’ capabilities for better fault diagnosis. References [
29,
30,
31] go further based on CGAN by adding classifiers and clusters inside GAN to partially or entirely obtain condition information. Then, they conduct model training similar to CGAN, thus partially or entirely removing the limitations of label information on CGAN training. The authors of [
32] propose the use of a temporal generative adversarial network, coupled with an efficient network model, to implement a transfer learning method, displaying excellent levels of effectiveness, reliability, and generalization performance. Deep Regret Analytic Generative Adversarial Networks (DRAGAN) [
33] introduce the no-regret algorithm in game theory and transform its loss function to solve the GAN collapse problem. The authors of [
34] incorporate a discriminator into its network design to resolve the issue of restricted variety within the generated samples. Rad-ford et al. [
35] proposed the introduction of a convolutional neural network in place of the original fully connected network within the architecture of the GAN to develop the deep convolutional generative adversarial network (DCGAN), which significantly improved the generation and generalization capabilities of the GAN network model and provided new ideas for the development of GAN networks. The authors of [
36] have employed DCGAN to convert one-dimensional vibration data into grayscale images, thereby increasing the availability of fault data samples and resolving the issue of inadequate data samples.
The Transformer model [
37] was proposed by Google in 2017. One of the most notable characteristics of this particular model is its departure from network structures typically utilized in RNN and CNN. The Transformer model has gained significant prominence in the realm of machine translation due to its remarkable capabilities. Recently, there has been a growing interest in applying the Transformer model to various fields, such as sequence data prediction, target detection, and image classification, leading to promising outcomes [
38,
39,
40]. The Swin Transformer [
41], proposed by Microsoft Research Asia, has attained superior performance in multiple vision tasks, indicating its state-of-the-art nature. As the number of network layers increases, the attention mechanism may collapse, resulting in a decrease in Transformer model performance rather than an increase. To address this challenge, Touvron et al. [
42] conducted research based on the ViT model and designed a layer scale structure that can also converge when the network is deepened, solving the problem of variance amplification in the residual connection process. A proposed method for fault diagnosis in rotating machinery utilizes intelligent feature self-extraction and transformer neural network techniques [
43]. The multi-scale SinGAN model [
44] is especially adept at generating high-quality kurtosis map images, which can play a pivotal role in effectively training complex machine learning models.
The methods proposed in the above literature have shown good learning capabilities and transfer effects in various unsupervised cross-domain fault diagnosis tasks, providing an essential reference for subsequent research in this field. To enhance the precision, stability, and broad applicability of diagnostic assessments, a set of innovative enhancements have been proposed.
Contributions: Our approach is made possible by the following technical contributions:
- (i)
Using continuous wavelet transform (CWT) can enhance the processing of analog circuit signals in the time–frequency domain, efficiently converting one-dimensional signals into two-dimensional time–frequency images that are advantageous for fault feature selection, leading to improved training speeds and enhanced efficiency;
- (ii)
A data augmentation approach based on DCGAN has been designed, using a generative model to generate convincingly realistic new images, effectively amplifying the image set. The amplified dataset is used to support model training, improving its performance and generalization capabilities, with the aim of addressing the problem of overfitting commonly experienced with small image datasets;
- (iii)
A fast and high-precision diagnosis technology based on the Transformer model is proposed, which greatly shortens the training time and achieves a good diagnosis accuracy–speed trade-off.
The rest of the content is organized as follows: In
Section 2, the theoretical background and the proposed method are outlined.
Section 3 illustrates the validation of the proposed method by detailing the selection of three experimental circuits and the construction and preparation of the fault dataset.
Section 4 delves into the experimental outcomes and analysis. The final section,
Section 5, provides a comprehensive summation of the complete paper.
2. Related Theories
2.1. Continuous Wavelet Transform
Continuous wavelet transform (CWT) can display the time–frequency characteristics of the vibration signal on the image. For a mother wavelet function,
, the Fourier transform satisfies the following equation:
where
denotes frequency, and
denotes Fourier transform of
. Stretch and translate to obtain a family of wavelet functions as follows:
where
,
is the scale factor,
is the displacement factor, and
is the analysis wavelet. The scale factor determines the extent to which the wavelet function can be scaled in the frequency domain, while the displacement factor governs the extent to which the wavelet function can be displaced in the time domain. Combined with the above explanation, the
CWT transform definition of any finite energy signal
is as follows:
where
is the conjugate of
;
is the scalar product of signal
x(
t) and wavelet
.
2.2. Deep Convolutional Generative Adversarial Networks
The concept of adversarial training for GAN networks stems from the field of game theory, and its main network model is composed of a set of generators built by deep networks and another set of discriminators built by deep networks. Deep convolutional generative adversarial networks are an innovation in the basic framework of GAN and are particularly suitable for processing two-dimensional data such as images and three-dimensional data [
45]. Like GAN, the game comprises a generator and discriminator, which engage in competition through their respective operations and ultimately reach a state of Nash equilibrium [
21].
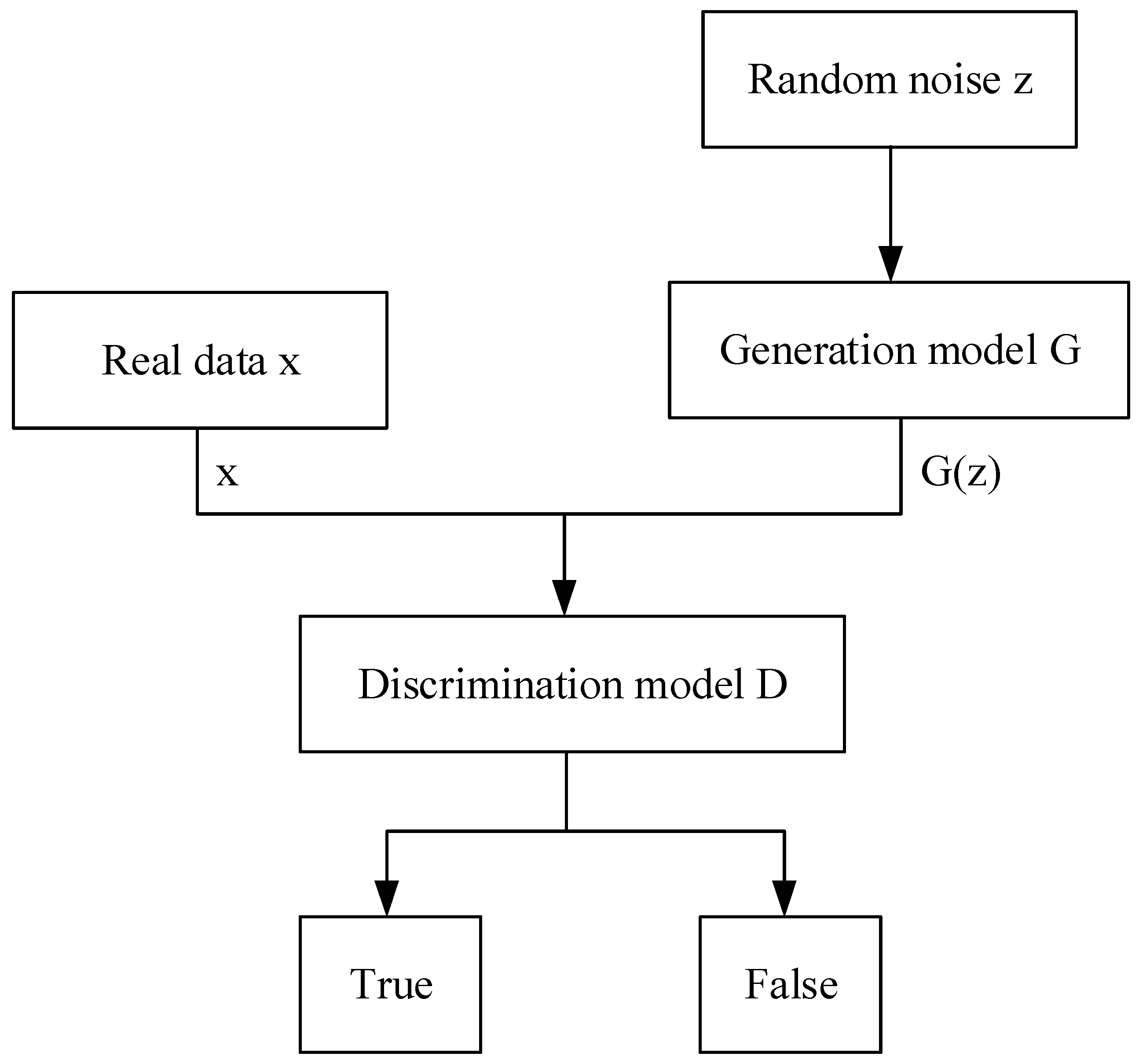
The basic structure is shown in
Figure 1.
z is the input random noise, and
G is the generator.
represents the generated picture,
x is the real data, and
D is the discriminator. The random noise (
z) is inputted into the generative model, and the model parameters are learned. In the generative model, it is gradually converted into the sample output close to the real data. And the discriminative model is responsible for evaluating whether the samples generated by the generator network are close to the real data. The training process for the generator and discriminator involves training them alternately, with the generator endeavoring to deceive the discriminator and the discriminator endeavoring to discern the difference between the generated samples and the authentic data. This process is maintained until the output of the generator network approximates the real data to a degree where the discriminator network cannot distinguish the samples.
Through a consistent process of learning and refining, the generator enhances its capacity to produce sample data. Therefore, the training problem of
G can be expressed as a value function
, which becomes a maximization and minimization problem of
. This can be expressed as follows:
where
is the input of the network comprises real images,
represents the likelihood of real images,
denotes the level of noise present in the image inputted into the generator,
symbolizes a fictitious image generated by the generator, and
signifies the probability of a false image.
Equation (4) is split into two loss function models. In the architecture of the discriminator model, the loss function is given by the following Equation (5):
Among them, the first item on the equation is the real sample’s discrimination result, with the closer it is to 1 indicating a better performance. The second term refers to the newly generated sample’s discrimination result, which should be closer to 0 to achieve optimal performance.
Obtaining the generator loss function follows the same principle as the discriminator loss function and is calculated using Equation (6):
In contrast to the discriminator, the generator only needs to approach 1 on the generated data.
The theoretical basis is analyzed as follows:
Starting from the objective function, since the value function
is continuous, Equation (1) is written in calculus form to express the mathematical expectation as Equation (7):
Assuming that the data generated by the generator
are
, the expressions for the noise point
and the differential
are calculated as (8) and (9), respectively:
Upon the substitution of Equations (7) and (8) into Equation (9), a resultant expression is generated.
Define the generating distribution of the noise input
z as
, then
where
denotes the generating distribution, adding noise to the generator, and we obtain the following:
Evaluating the maximum value of the function
, fixing
G, and taking the partial derivative of
D yields the following:
As can be seen from the expression of , consistency in the distribution of generated virtual sample data and real data is achieved when the latter are deemed congruent and similar; thus, immediately, . The condition is satisfied under this condition ; at this time, the D network has been unable to judge the truth or falsity of the sample data generated by the G network; that is, D has achieved the optimal solution. If and only then , the maximization and minimization problem of has a globally optimal solution; that is, it reaches the Nash equilibrium state. It is possible to stop the training procedure at this point since model G has mastered the actual sample distribution, and the accuracy of model D has remained consistent at 50%.
2.3. Transformer
Transformer, a deep model widely used in natural language processing and image analysis, can efficiently process sequence data, capture features by modeling the dependencies inside the sequence, and improve computational efficiency without a loop structure. And its individual components are analyzed next.
2.3.1. Attention Mechanism
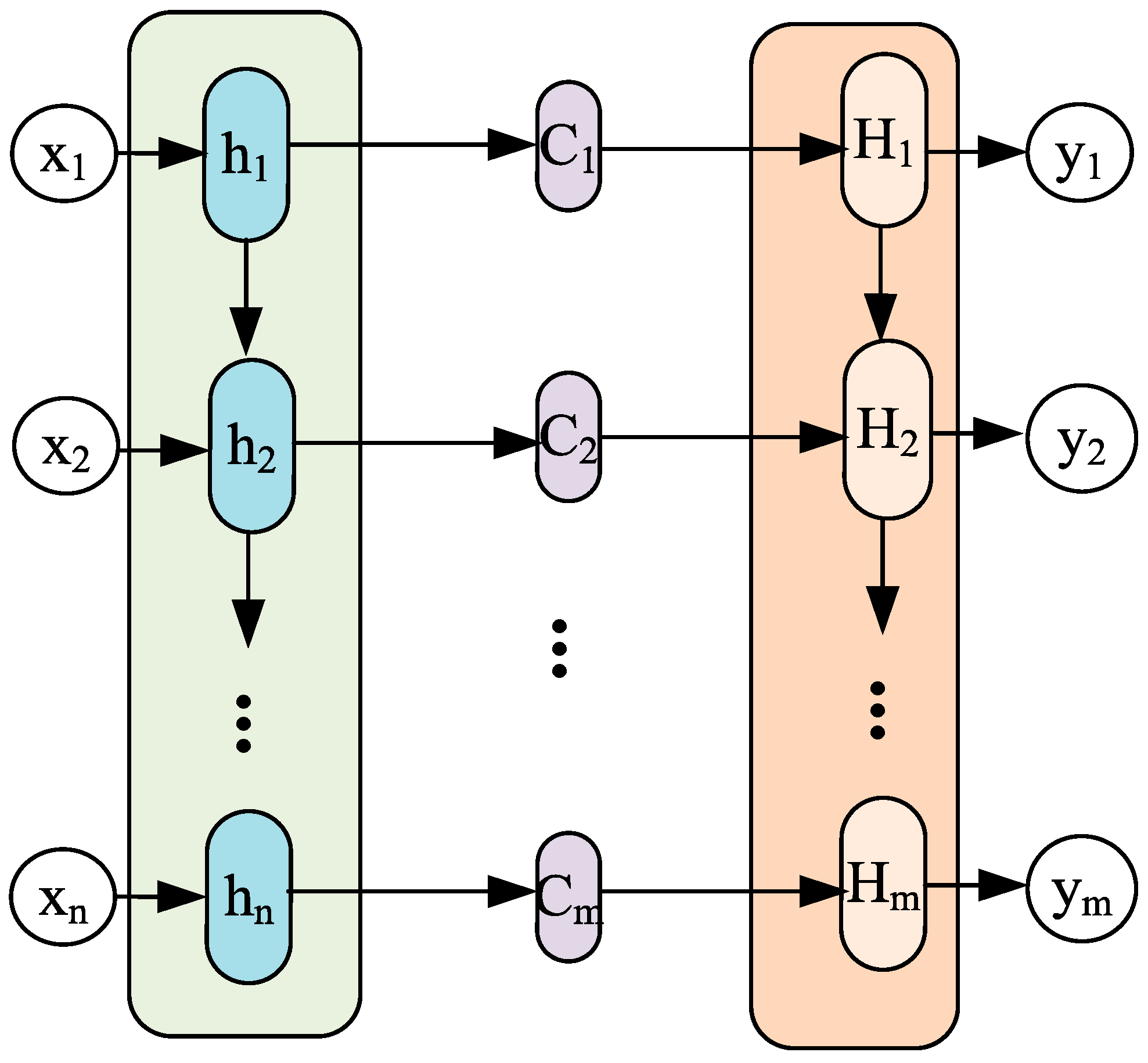
The source of the attention module is to learn from human attention and intuitively explain it by the attention mechanism of human vision. Concretely, machine learning can be viewed as a mathematical computation of data attributes, which takes into account certain weights. These weights are attention. As a member of the attention module, self-attention can be used to calculate the interdependence between different regions inside the image. The common attention mechanism is soft attention (SA). The attention mechanism can be used in any model. This paper presents a novel technique, SA, which is grounded in the encoder–decoder framework. The encoder–decoder framework has gained widespread acceptance in natural language processing and time series prediction. As shown in
Figure 2, the input sequence can be represented as
and the output sequence as
, where the attention result
is calculated by the following formula:
where
is the input data length of the coding layer;
is the hidden layer state of the
input data in the coding layer;
represents the attention distribution coefficient of the
data in the encoding layer when the
value is output by the decoding layer.
is calculated as the following:
where
is the hidden layer state of the
data in the decoding layer, and
is a function. Calculate the similarity of
and
, then the output of the function
is normalized by Softmax to obtain the attention.
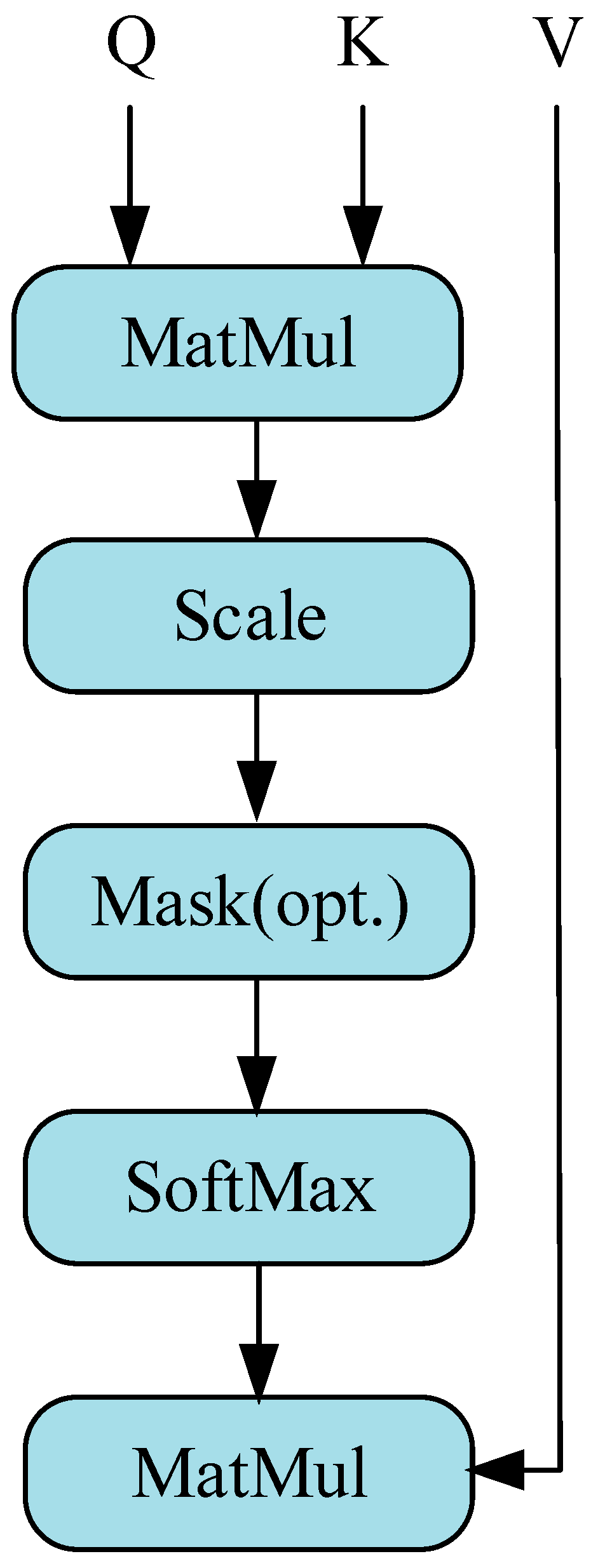
The scaled dot product attention used in ViT is shown in
Figure 3. Denoted by
a sequence of n elements is (
x1,
x2,
…,
xn), and d denotes the embedding dimension of each element. And through the interaction between Query and Key–Value pairs, the self-attention layer achieves dynamic aggregation of information, which is obtained as follows:
The calculation of scaling dot product attention proceeds in the following manner:
where
is the attention score, and
is the dimension of vectors
Q and
K.
is the scaling factor.
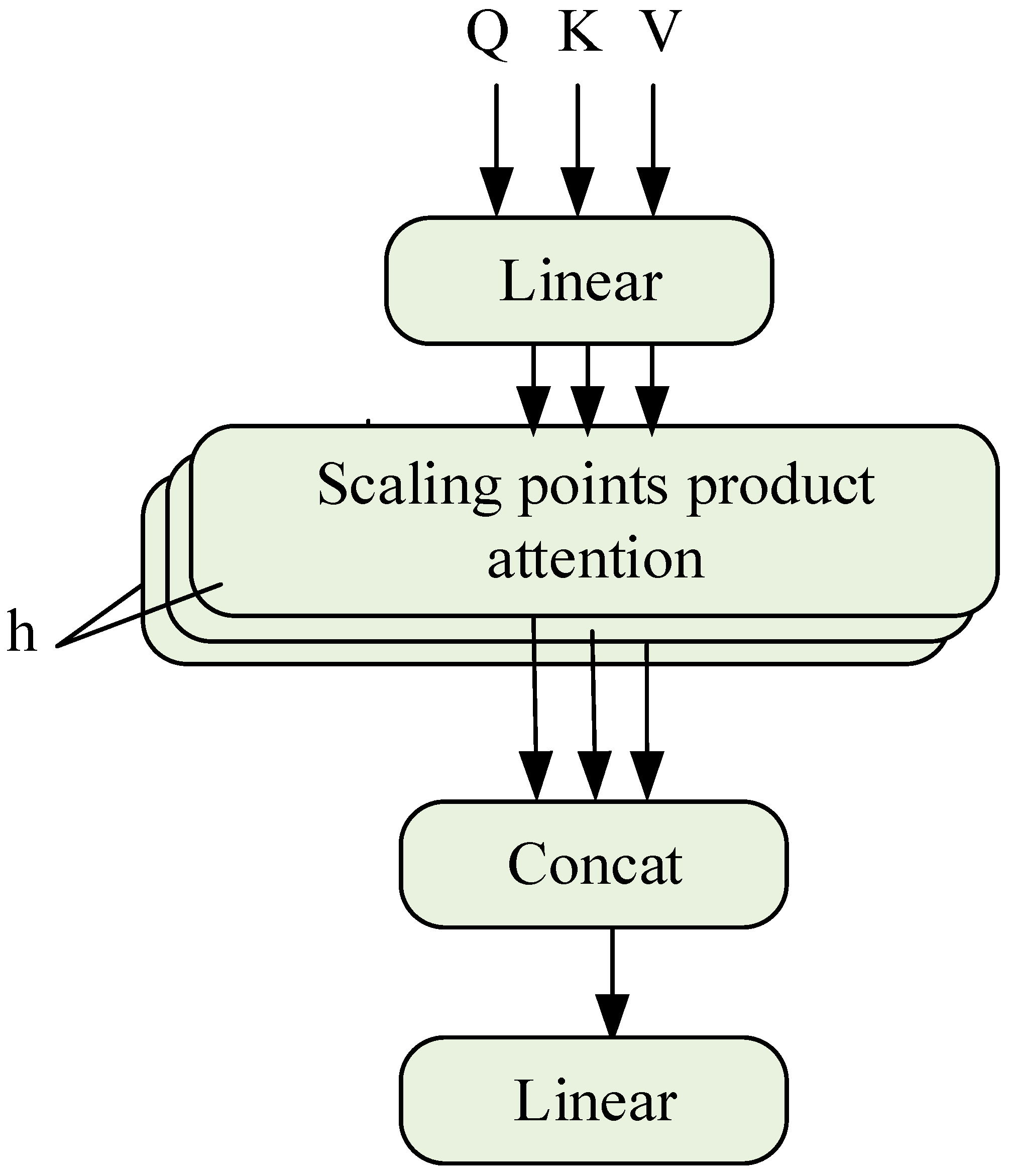
Multi-head attention (MHSA) has multiple independent self-attention layers (heads), each with its own learnable weight matrix, and the calculation process is
, as shown in
Figure 4 and as shown in Equations (18)–(20):
where
refers to the number of attention heads of MHSA,
represents the output vector of each attention head,
is the output projection matrix, and
is the learnable weight matrix.
and
can be regarded as the split under different feature subspaces in single-head attention, and the correlation between features is extracted from multiple angles without increasing additional computational cost. Finally, the information extracted by each self-attention layer is merged to obtain more rich and more comprehensive feature information.
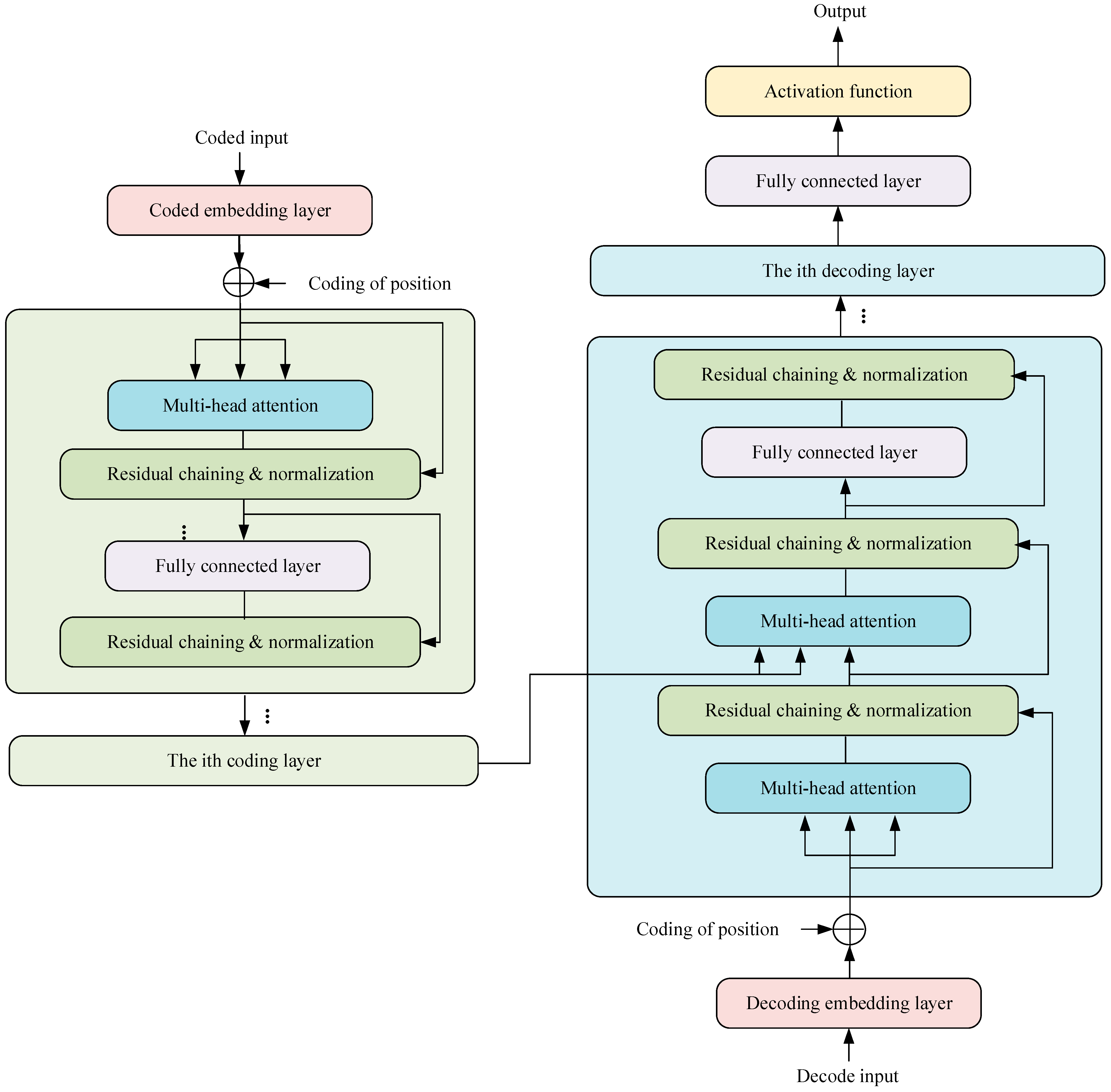
2.3.2. Transformer Model
The Transformer model, illustrated in
Figure 5, consists of an encoding block and a decoding block. The contrast between the decoding layer and the encoding layer lies in the fact that each decoding layer comprises two multi-head attention layers. In the decoding layer, given its two multi-head attention layers, the initial attention layer mirrors that of the decoder layer. Correspondingly, the
K and
V fields of the second attention layer are the respective outputs of the decoding block. Lastly, the regularization layer furnishes the
Q for the attention mechanism of this layer. In addition, the structure of the regularization layer in the Transformer is consistent, which is mainly composed of residual connections and regularization operations:
where
z is the output of the attention or fully connected layer.
2.4. The Proposed Method
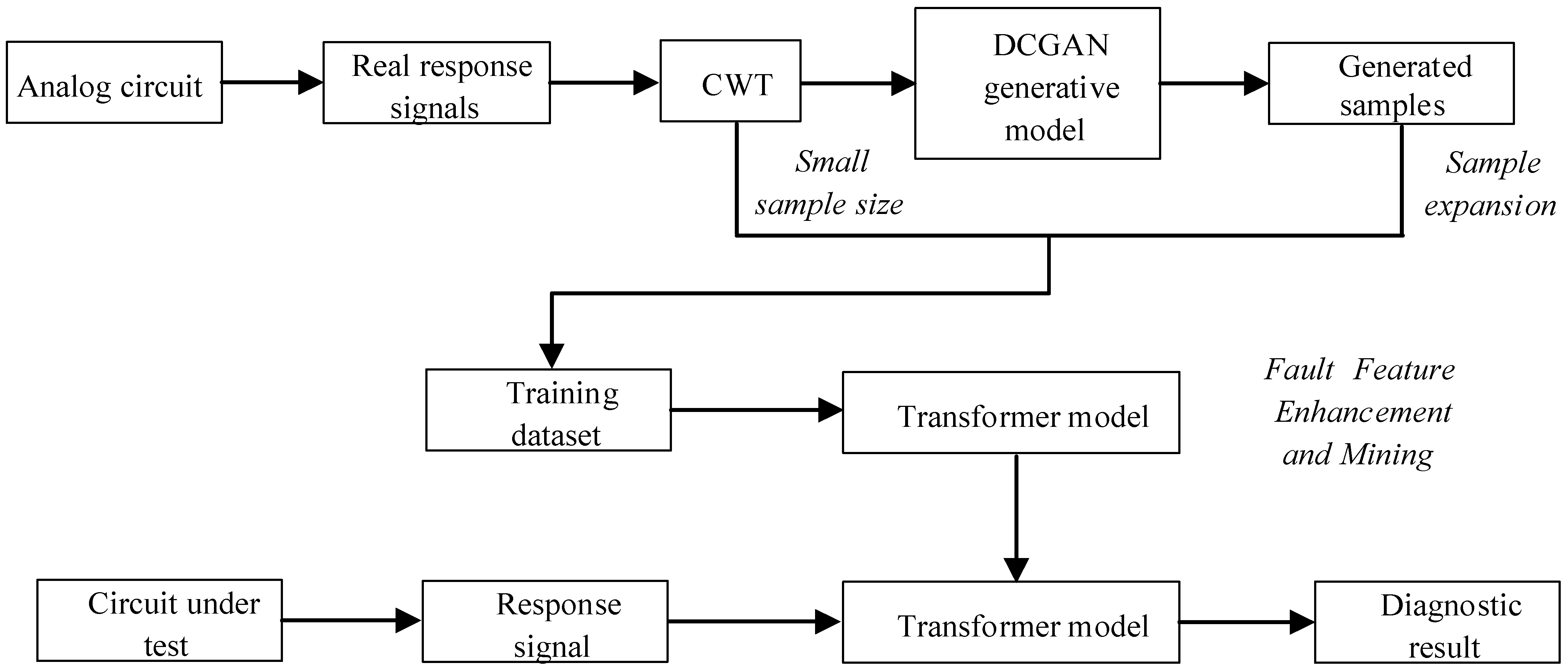
The first step involves collecting the real output voltage signal of the analog circuit. After that, the output signal’s time–frequency characteristics are extracted using the method of CWT. Then, the DCGAN generation model is trained by using the real-time–frequency feature graph, and a new time–frequency feature graph can be generated by inputting the real time–frequency feature graph into the trained DCGAN model. Mixing real time–frequency signals and generated time–frequency signals can be used to train the Transformer model, realize automatic mining and classification of time–frequency features, and finally complete fault diagnosis. The diagram representing the proposed diagnostic strategy’s workflow is displayed in
Figure 6.
The model’s training procedure entails the following sequence of steps:
The first step is DCGAN training: the generator generates new sample data (fake sample) by constantly transforming random noise pictures conforming to a normal distribution. The discriminator network receives the fake sample and the real sample and determines whether the image data correspond to the output image by calculating the probability of the generator. The generator and discriminator engage in a continuous optimization process through adversarial confrontation until the loss function converges. At that point, the generator model is saved, and additional sample data are generated.
The next step involves utilizing the Transformer model to pre-train the newly generated sample data, adjusting the parameters until the model converges and reaches a better evaluation index, and saving the pre-trained model.
Thirdly, use a Transformer to conduct iterative training and testing on the original sample data until the training converges. In the event that convergence has not been achieved, the learning rate, as well as the dimensions and amount of convolutional layers, will be adjusted until convergence is attained.
3. Analog Circuit Experiment and Fault Setting
This section primarily covers topics related to analog circuit examples, fault configuration and data acquisition, signal preprocessing methods, and diagnostic model parameter settings. These are preparatory steps for the subsequent presentation and analysis of the experimental results in
Section 4.
In the process of operating analog circuits, the performance of capacitors, resistors, and other components inevitably deteriorates. Deviations in the actual output signal value from the theoretical value may occur due to various factors, resulting in an uneven result. In general, the device has a normal value for its operation X, tolerance α, and threshold β. The device can still work normally under the condition of working within the tolerance range. If the device works beyond the tolerance range but does not exceed the threshold range, the circuit has a soft fault. In the event that the device parameters exceed the pre-established threshold, the circuit will cease functioning altogether. To ensure the efficacy of the suggested algorithm, three circuits, including the Sallen–Key bandpass filter circuit, the Biquad low-pass filter circuit, and the Thomas filter circuit, were subjected to experimental verification, as illustrated in the accompanying figure.
3.1. Fault Settings
In the field of circuit fault diagnosis, the selection of faulty components is typically determined based on an analysis of which components have a significant impact on the input. This determination is generally guided by the circuit’s transfer function. The specific approach involves conducting sensitivity analysis using circuit simulation software to identify components that have a substantial influence on the circuit’s output. These components are then considered as potential candidates for faults, thus laying the groundwork for subsequent research. If only one device in the analog circuit has a soft fault, it is called a single fault, and its fault settings are depicted in
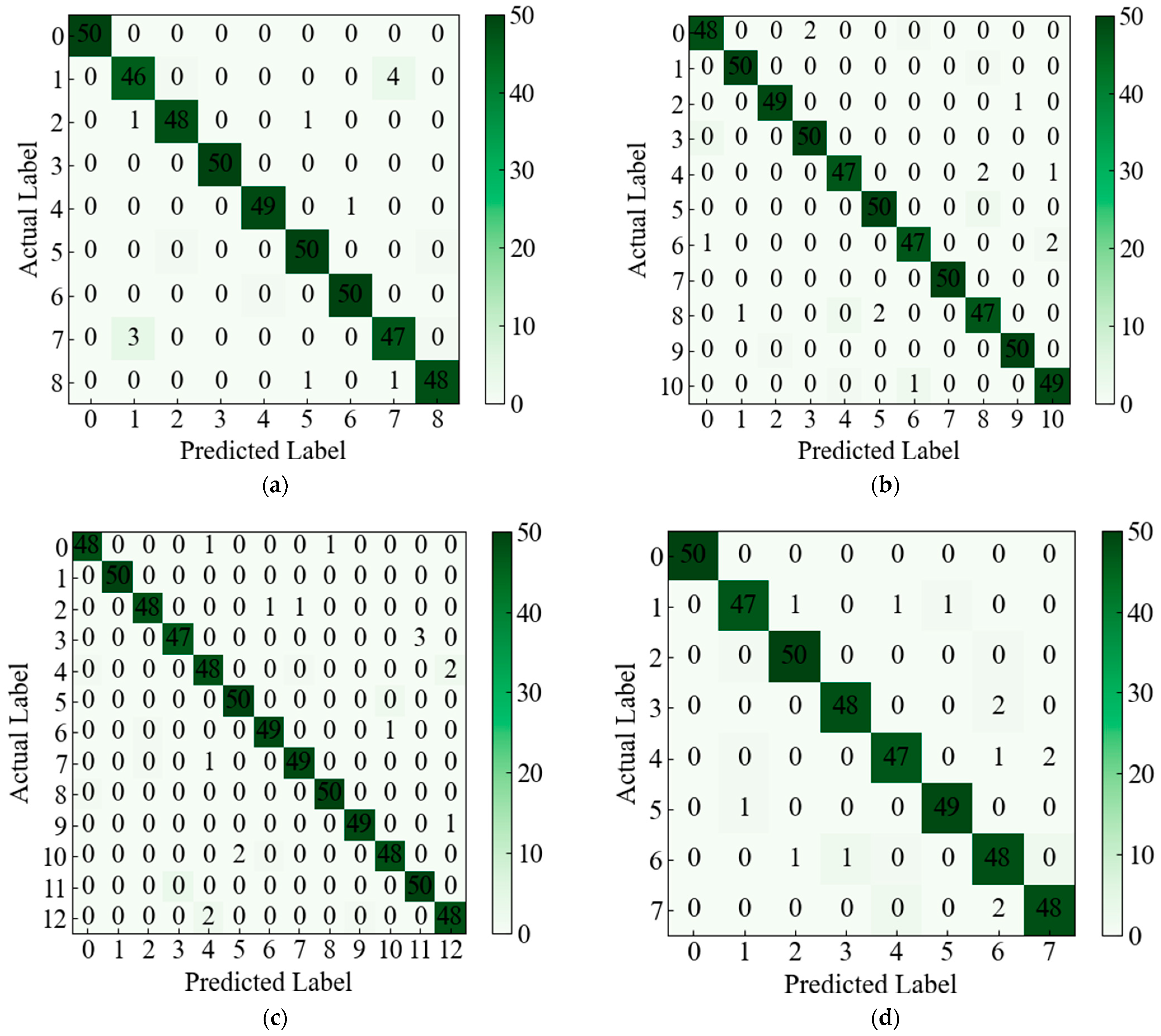
Table 1 and
Table 2. In the event of multiple components experiencing simultaneous failures, it is referred to as a compound fault, wherein the fault signal manifests similar properties to those observed with a single fault. Although the incidence is low, its low feature recognition rate and many fault modes cannot be ignored, and its fault settings are depicted in
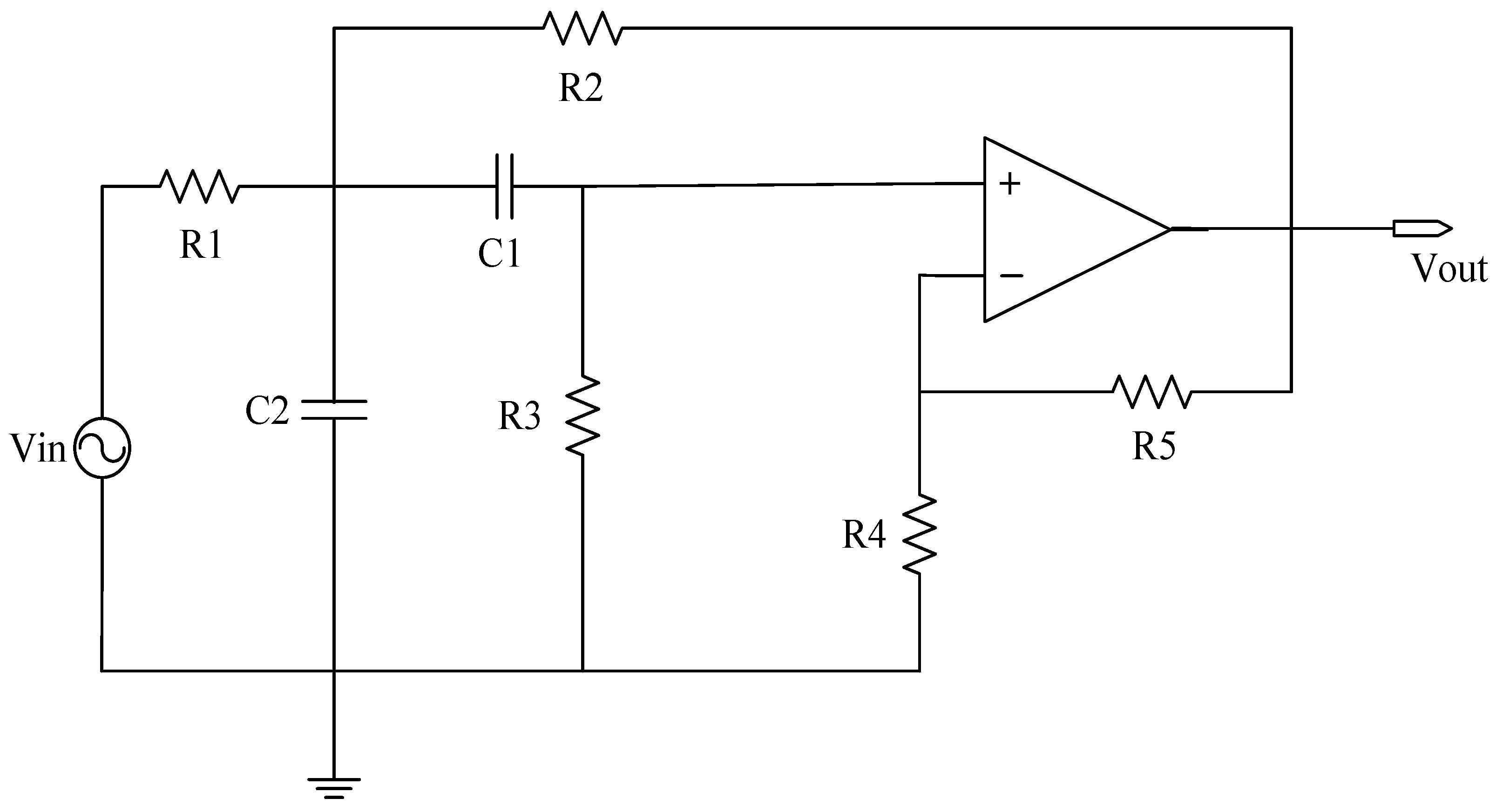
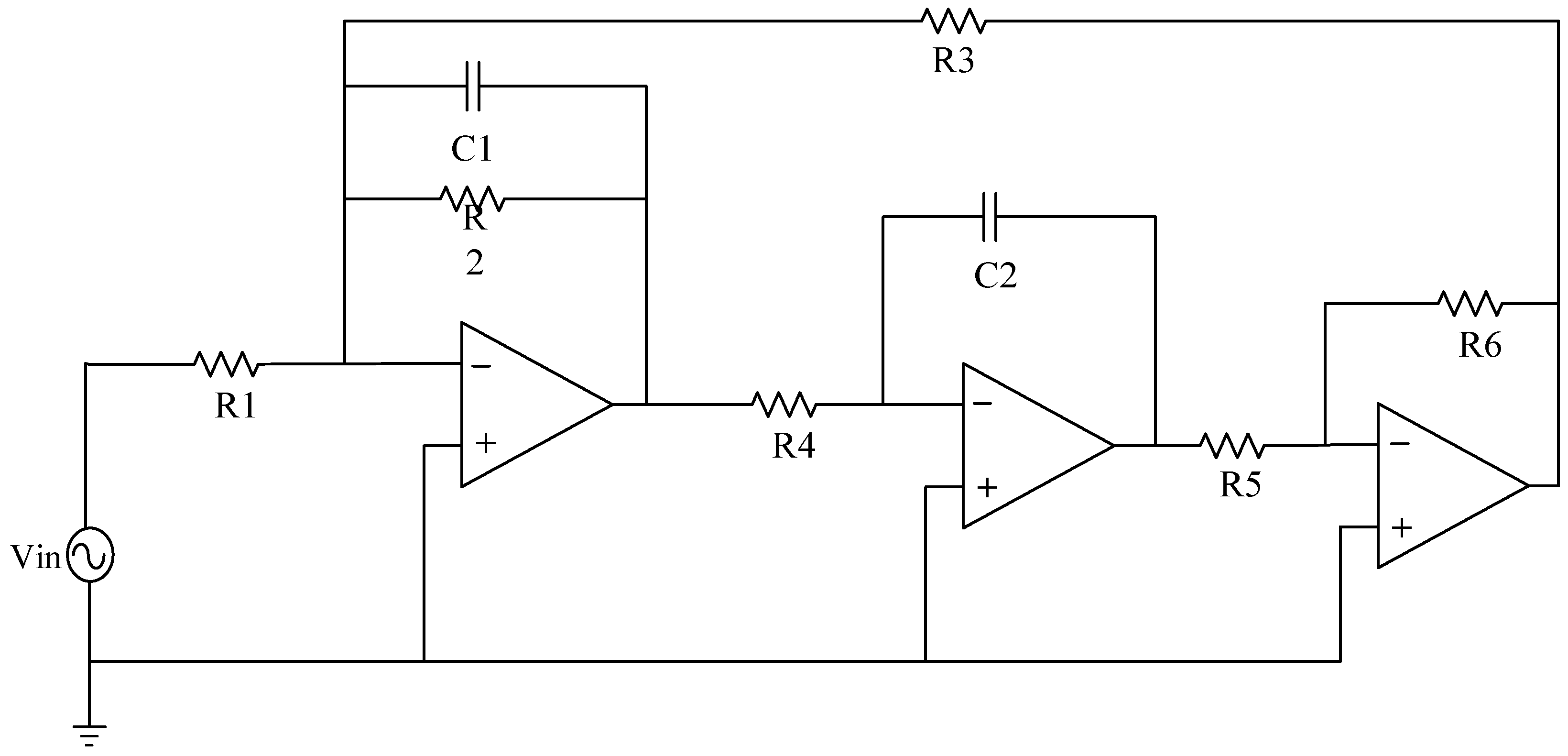
Table 3. In an analog circuit, the component that has a significant impact on the output of the circuit is referred to as the sensitive element. The Sallen–Key bandpass filter circuit, depicted in
Figure 7, exhibits a number of sensitive components, including C1, C2, R2, and R3. The Biquad low-pass filter circuit illustrated in
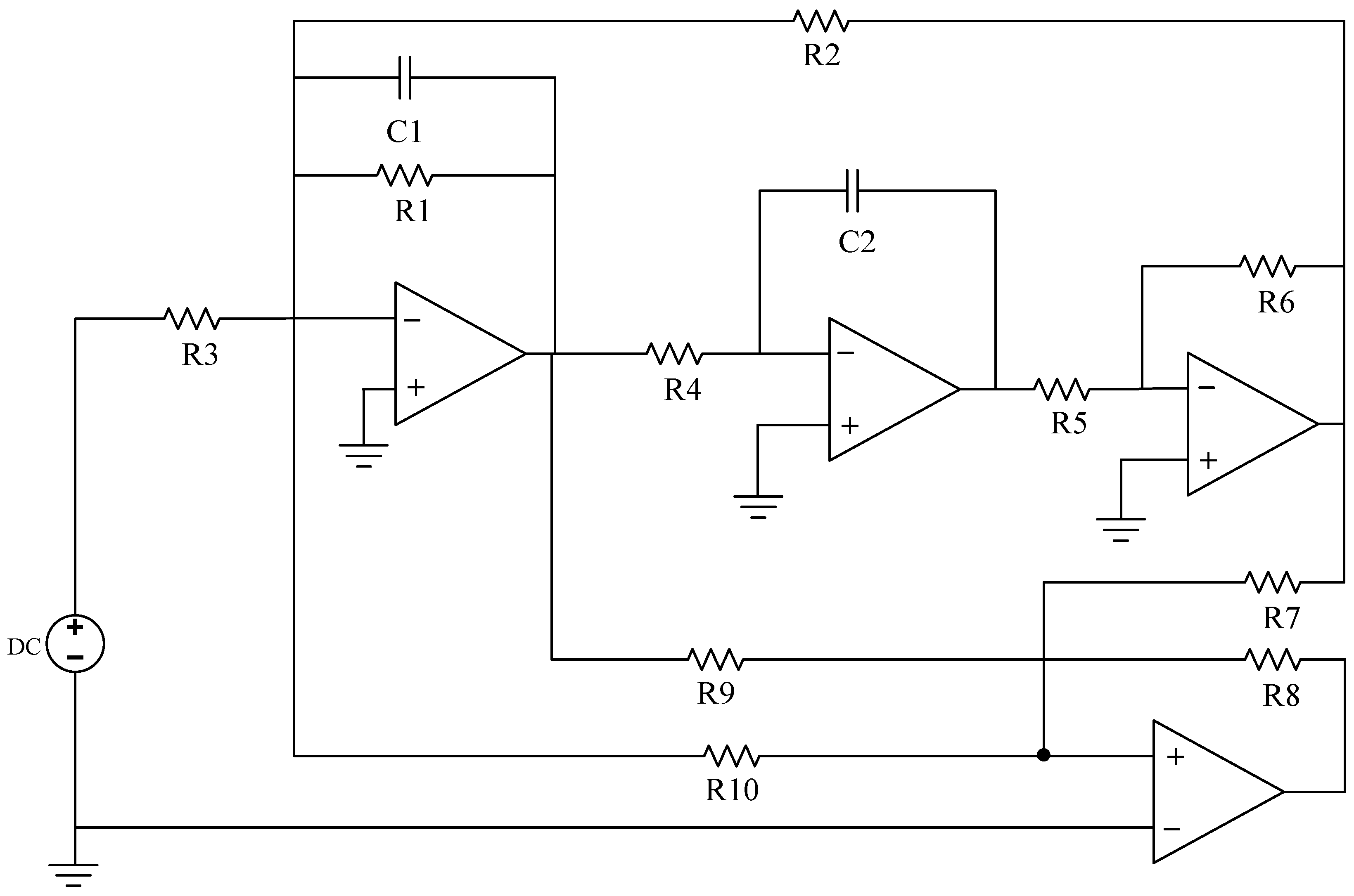
Figure 8 features a number of vulnerable components, including C1, C2, R1, R2, R3, and R4. Lastly, the Thomas filter circuit, shown in
Figure 9, possesses numerous sensitive components, including C1, C2, R3, R4, and R5. To conduct an analog circuit fault test, it is recommended to adjust the device parameter upwards (↑) or downwards (↓) by a specified amount that exceeds the standard value. This measure aims to identify any potential issues within the circuit. The tolerance of the resistance and capacitance of the circuit are 5% and 10%, respectively, and the fault threshold is set to 30%. Specifically, the range of resistance failure in the circuit is encompassed within the limits of [70% X, 95% X]∪[105% X, 130% X]. Likewise, the range of capacitor failure in the circuit is restricted within the bounds of [70% X, 90% X]∪[110% X, 130% X], where X denotes the nominal value of the component.
3.1.1. Sallen–Key Bandpass Filter Circuit
The single fault set has been established to encompass the states {C1↑, C1↓, C2↑, C2↓, R2↑, R2↓, R3↑, R3↓, NF} in a total of nine distinct configurations, as per 0.
Combining the single fault in
Table 1 in pairs to form a compound fault, the parameters of the circuit components remain unchanged, and the complex fault set is set to {C1↑C2↑, C1↓C2↓, C2↑R2↑, R2↓R3↑, R2↓R3↓C1↑, R3↑C1↑C2↓, NF}, which can be in eight states.
3.1.2. Biquad Low-Pass Filter Circuit
Like the Sallen–Key bandpass filter circuit, in the Biquad low-pass filter circuit, the normal values of capacitors C1 and C2 are both 5.00 nF, and the fault value range is [3.50 nF, 4.50 nF]∪[5.50 nF, 6.50 nF]; the normal value of R1, R2 and R3 is 6.20 kΩ, and the fault range is [4.34 kΩ, 5.89 kΩ]∪[6.51 kΩ, 8.06 kΩ]. As previously described, the single fault set is constructed as {C1↑, C1↓, C2↑, C2↓, R1↑, R1↓, R2↑, R2↓, R3↑, R3↓, R4↑, R4↓, NF}, with a total of 13 states, and the composite fault set can be created in eight states: {C1↑C2↑, C1↓C2↓, C2↑R2↑, R2↑R5↑, R1↑R2↑C1↑, R3↑C1↑C2↓, NF}, with a total of eight states.
3.1.3. Thomas Filter Circuit
The single fault set is constructed as {C1↑, C1↓, C2↑, C2↓, R3↑, R3↓, R4↑, R4↓, R5↑, R5↓, NF}, with a total of 11 states. The specific settings are shown in
Table 2.
The composite fault set is created in eight states: {C1↑C2↑, C1↓C2↓, C2↑R3↑, R3↑R5↑, R3↑R5↑C1↑, R3↑C1↑C2↓, NF}, with a total of eight states. And
Table 3 lists the settings.
3.2. Signal Preprocessing
In order to enhance the training capacity of the model and minimize the number of computations required, it is imperative to undertake the process of data preprocessing prior to its collection. As shown in
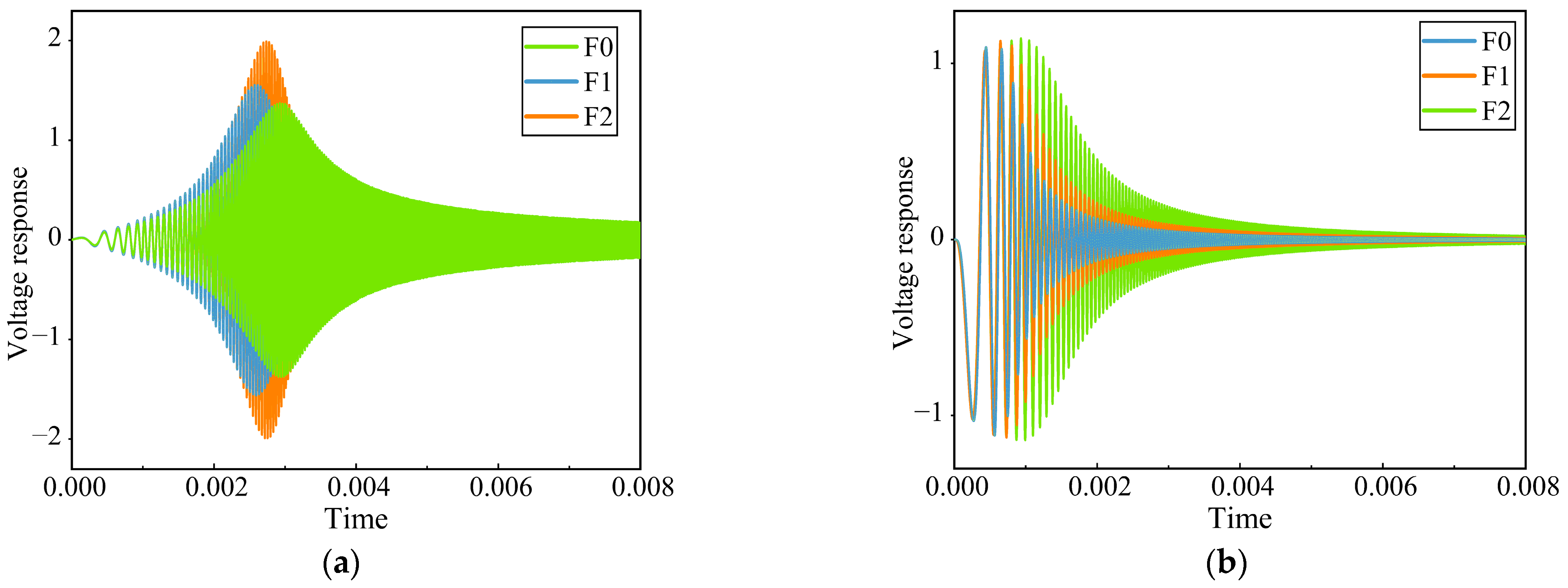
Figure 10, the output voltage signals of the Sallen–Key bandpass filter circuit and the Thomas filter circuit under partial fault conditions are shown.
- A.
Standardized processing
To further standardize the collected data and better train the neural network model, the data of each sample are standardized. The standardization method adopted in this paper is min-max standardization. Its mathematical expression is as follows:
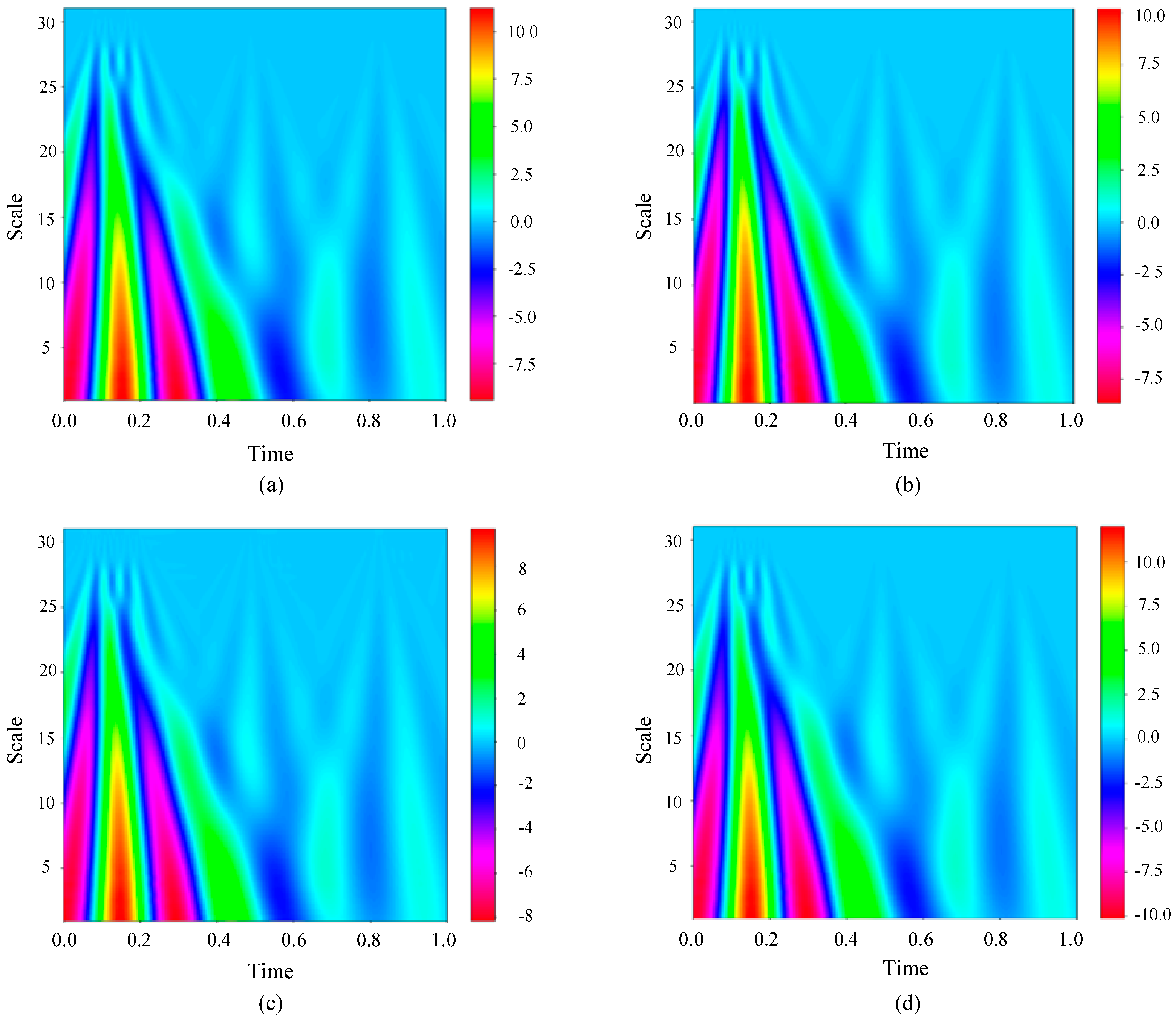
Consider the Sallen–Key bandpass filter circuit as an example. When continuous wavelet transform processing is applied to the output signal, the resulting graph can be seen in
Figure 11.
Upon reviewing
Figure 11, it is evident that the transformations resulting from various fault categories display subtle distinctions in the accompanying images. Therefore, manual classification is difficult, and automatic recognition technology is very necessary to explore the differences between different faults.
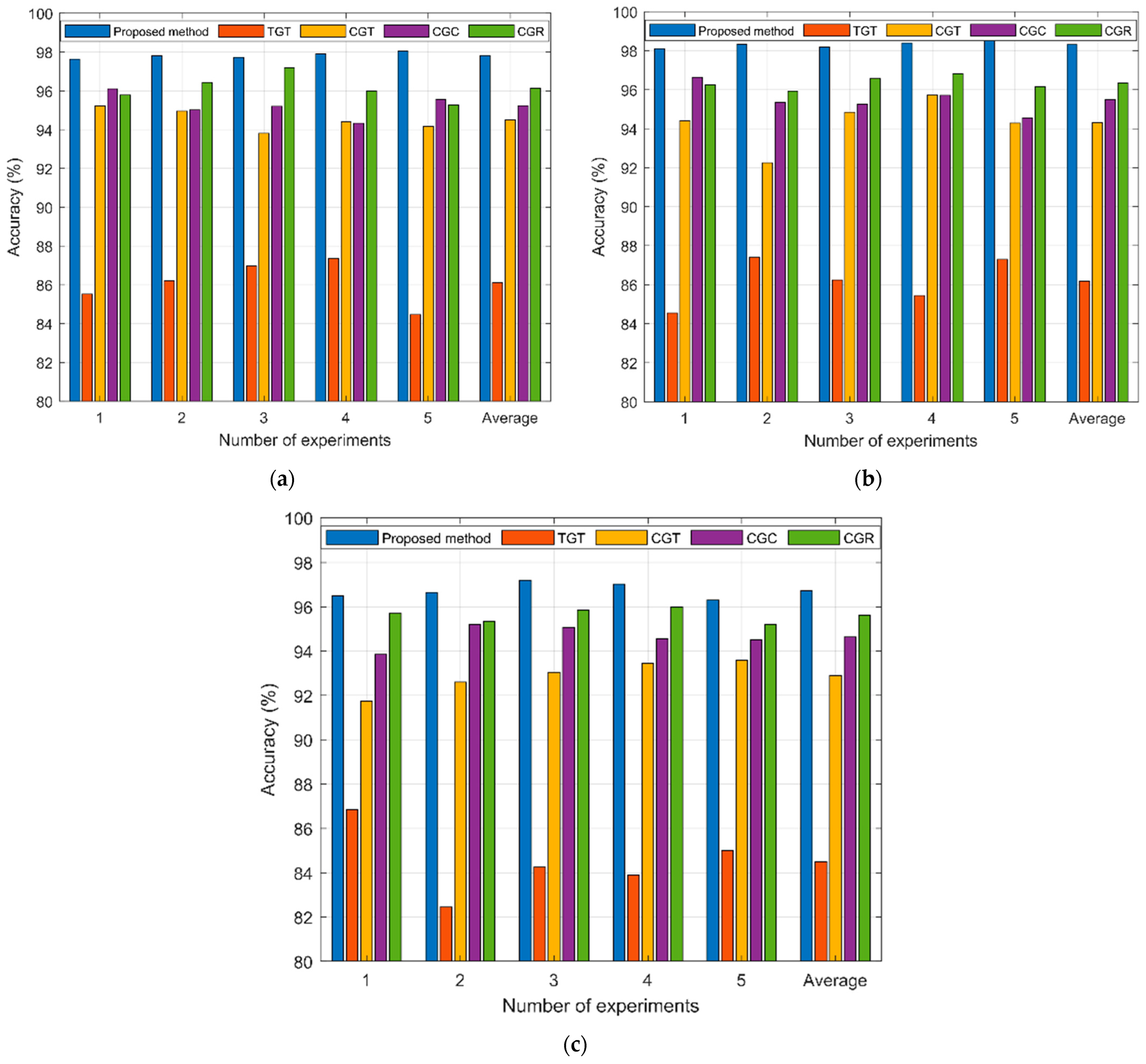
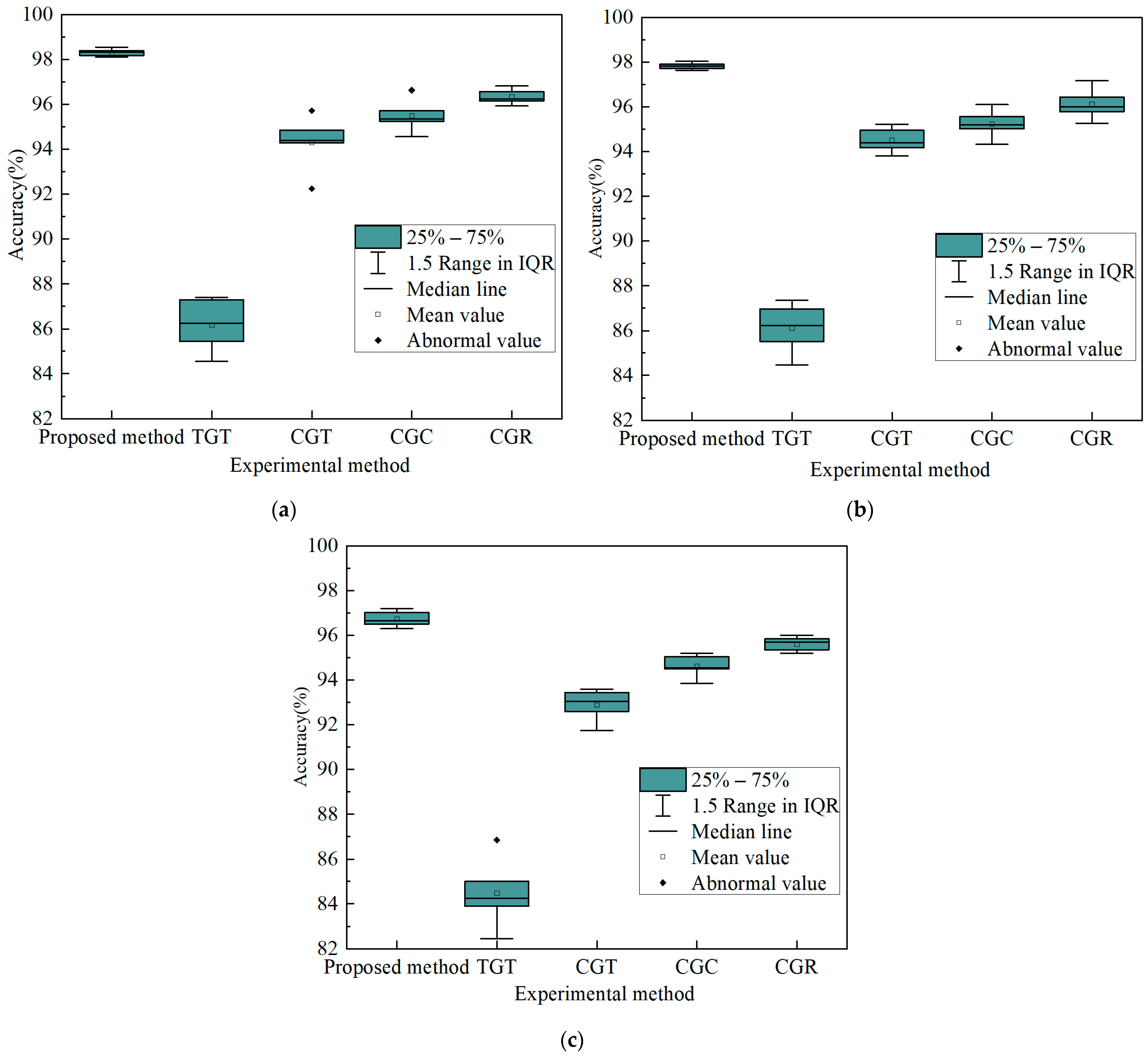
A total of 300 samples were collected for each fault type in both single-fault and multi-fault circuit cases. The samples were subjected to the aforementioned pretreatment procedure. A training dataset of 300 samples was assembled for each fault type, as the size of the data was determined based on a combination of real samples and generated samples with varying mixing ratios. A crucial aspect of the training process is to establish the ratio of real samples to generated samples in order to optimize the performance of the fault diagnosis model.
3.3. Fault Signal Collection
The experimental platform depicted in
Figure 12 demonstrates a viable method for data acquisition. The equipment utilized incorporates an Agilent 33250 arbitrary waveform generator, Agilent 54853 digital oscilloscope, power supply, LabVIEW_2023 Q1 software, National Instruments 1042q data acquisition module, and the circuit under test (CUT). The arbitrary waveform generator creates a sinusoidal scanning excitation signal, which is then recorded using LabVIEW software. The test circuit’s output signal is then collected through the input of the sinusoidal excitation signal under various faults. Since the output signal is periodic, data analysis will involve collecting the signal for 50 cycles and dividing it into 50 samples. Specifically, to obtain accurate data, the first 10ms of the output signal will be collected with the sampling frequency set at 60 kHz and the sampling point set at 600. Each fault type and non-fault state will be assigned 500 labeled samples. Subsequently, the samples will be normalized and divided evenly into five separate subsets for five-fold cross-validation.
3.4. Parameter Settings Involved in the Proposed Diagnostic Strategy
As depicted in
Figure 13, a pragmatic, experimental platform has been developed for data acquisition. It encompasses an Agilent 54853 digital oscilloscope, a circuit under test (CUT), LabVIEW software, an Agilent 33250 arbitrary waveform generator, a National Instruments 1042q data acquisition module, and a power supply.
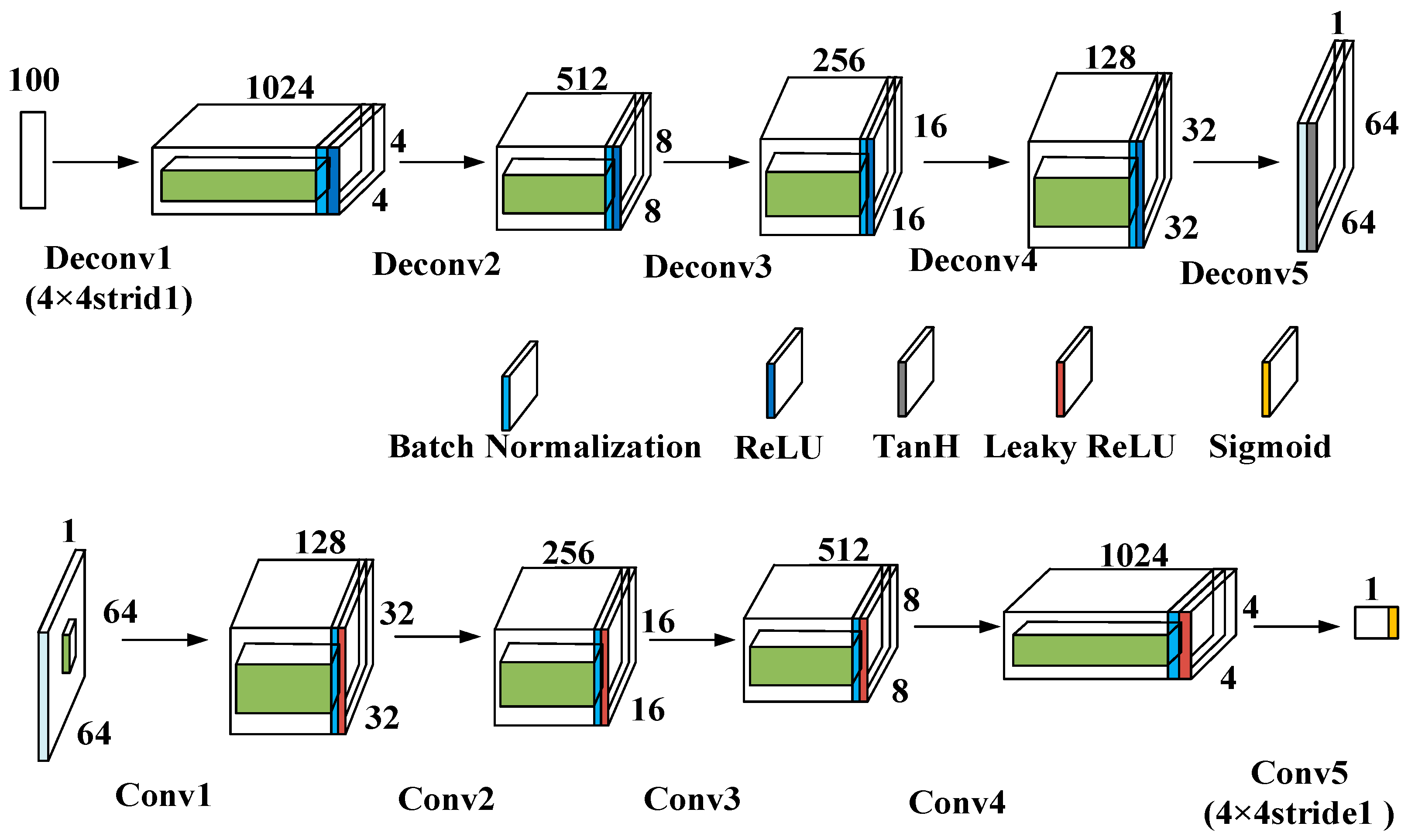
The DCGAN data generation model comprises a generator and a discriminator, both of which are components of the DCGAN architecture.
The DCGAN generator uses five transposed convolutional layers to upsample a 100-dimensional noise vector. The final output is a 64 × 64 × 1 image. Each convolutional layer, when transposed, has a stride of 2 and a 4 × 4 kernel size. The output dimensions of each transposed convolutional layer are as follows: 1024 × 4 × 4, 512 × 8 × 8, 256 × 16 × 16, 128 × 32 × 32, 1 × 64 × 64.
The architecture of the DCGAN discriminator mirrors that of the generator in a symmetric manner. It takes 64 × 64 × 1 images as input and uses five convolutional layers for feature extraction, with a stride of 2 and a kernel size of 4 × 4. The output dimensions of each convolutional layer are as follows: 1 × 64 × 64, 128 × 32 × 32, 256 × 16 × 16, 512 × 8 × 8, 1024 × 4 × 4. The resultant output is remodeled in order to conform to a predetermined shape, subsequently being inputted into a fully interconnected layer, in which the ensuing output value is utilized as the basis for the discriminator’s decision.
The batch size is 64, the learning rate is 0.001, and the model is trained for 50 epochs using the Leaky ReLU activation function. The Adam optimizer is used with a β1 value of 0.5.
In the context of the Transformer diagnostic model, the parameter configuration used in the experiment is as follows: a patch size of 4 × 4, 2 encoder layers, a token dimension of 96, and 12 attention heads. The maximum number of iterations that can occur during the training phase of the model has been set to 50.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}