
Deep Learning Framework for Liver Segmentation from T1-Weighted MRI Images
 ,
,  ,
,  , , ,
, , ,  and
and
Abstract
:1. Introduction
- This research extensively investigates state-of-the-art approaches for precise liver segmentation from T1-weighted abdominal MR scans to facilitate clinicians with AI-driven assistance for liver pathology diagnosis;
- This research investigates the effects of multiple image enhancement techniques for automated liver segmentation tasks from MR scans;
- This research proposes a novel cascaded network for the liver segmentation task that demonstrated state-of-the-art performance compared to the literature;
- The proposed model was deployed in a cloud server for demonstration purposes so that clinicians can directly benefit from the results of this investigation.
2. Materials and Methods
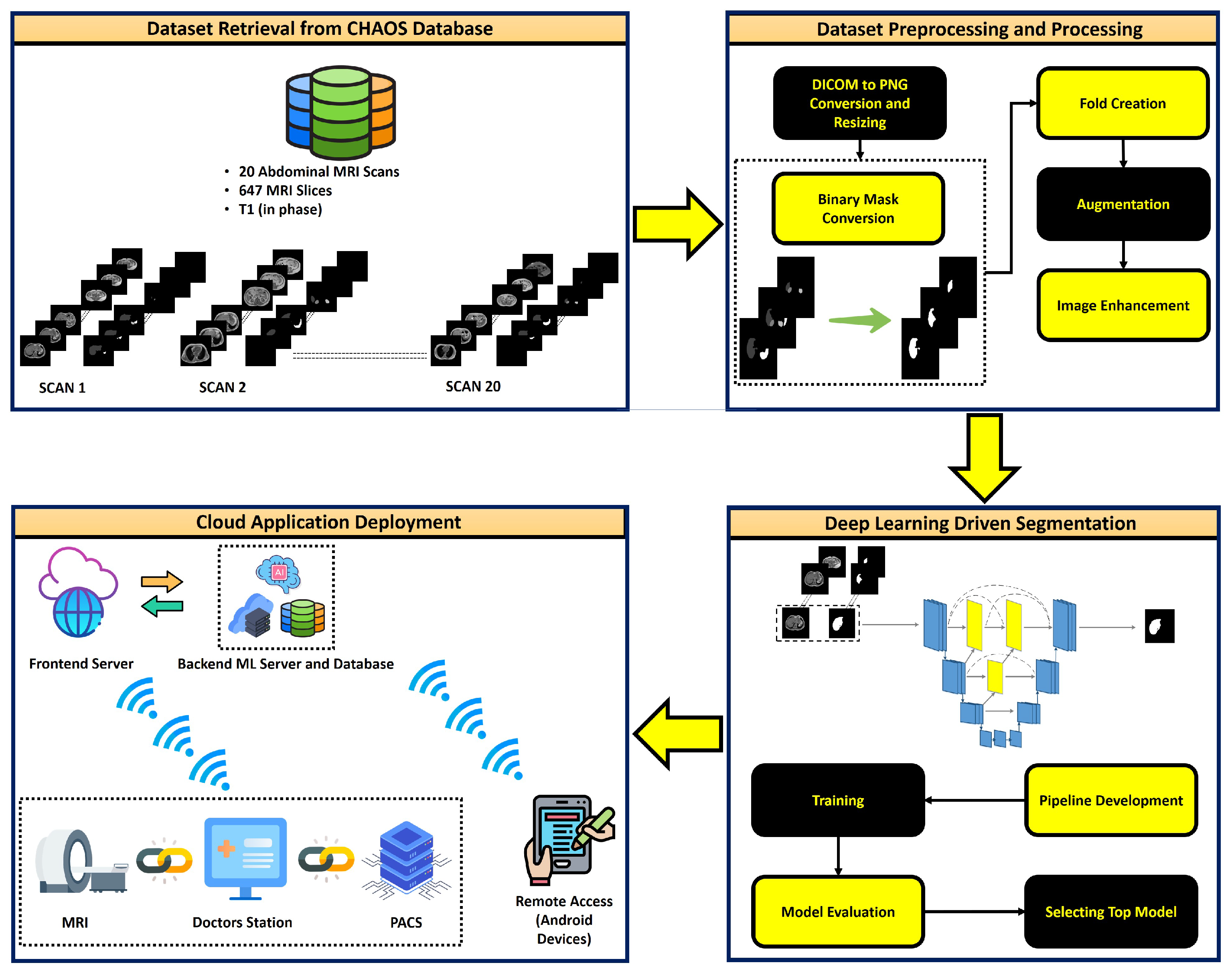
2.1. Dataset
2.2. Selecting Task-Specific Contrast Group
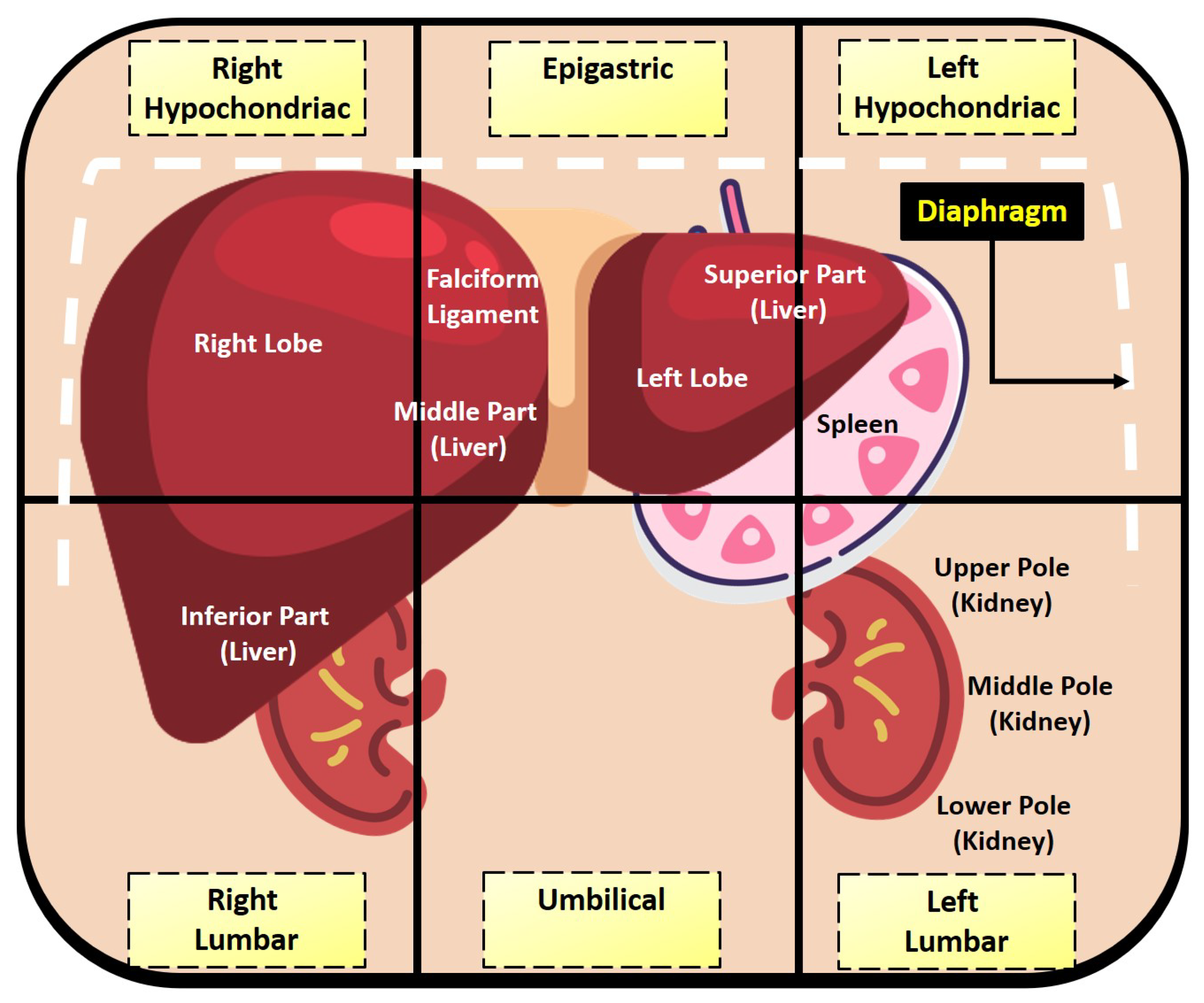
2.2.1. Relevant Abdominal Anatomy
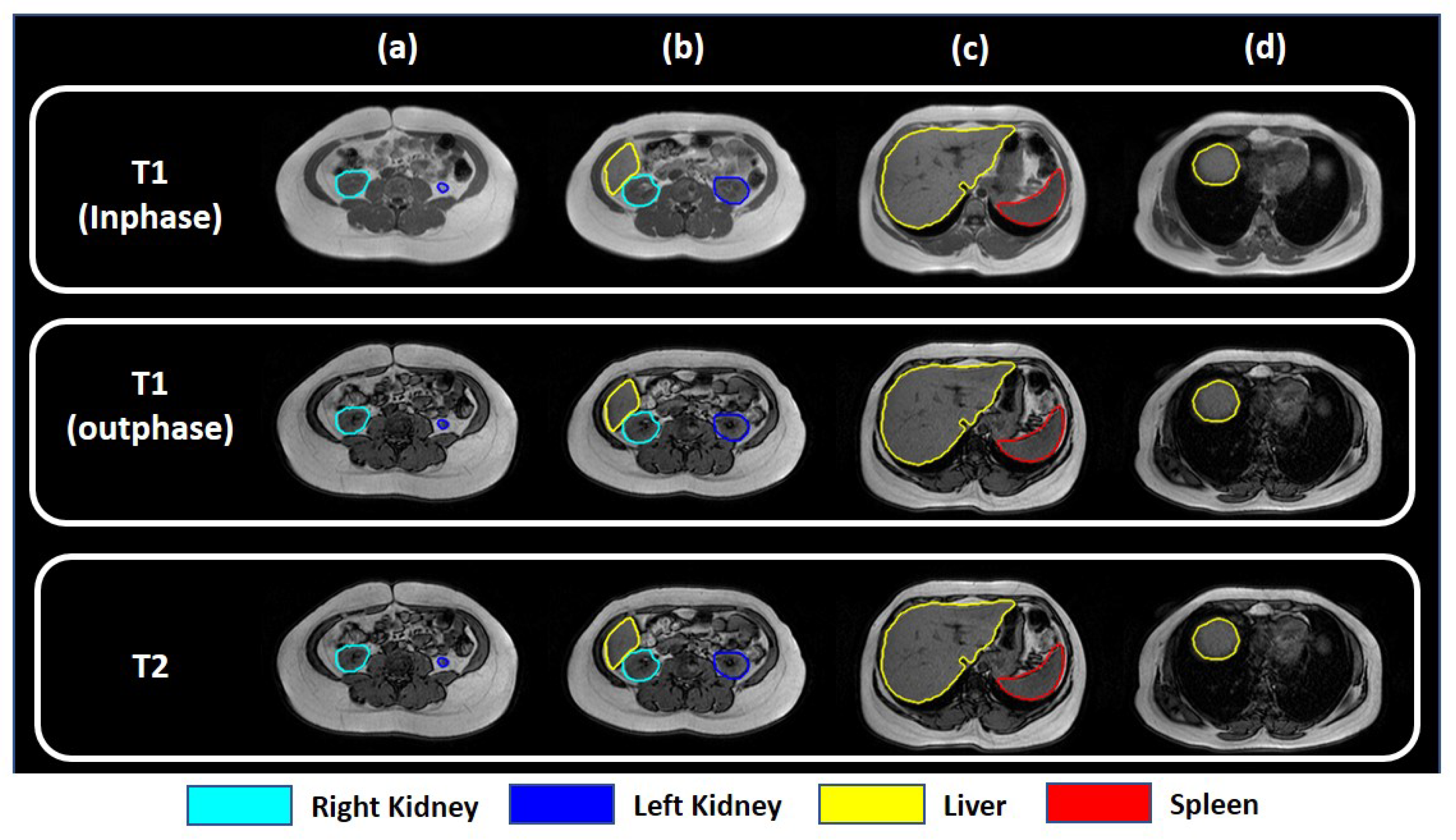
2.2.2. - and -Weighted Images
2.3. Dataset Preprocessing
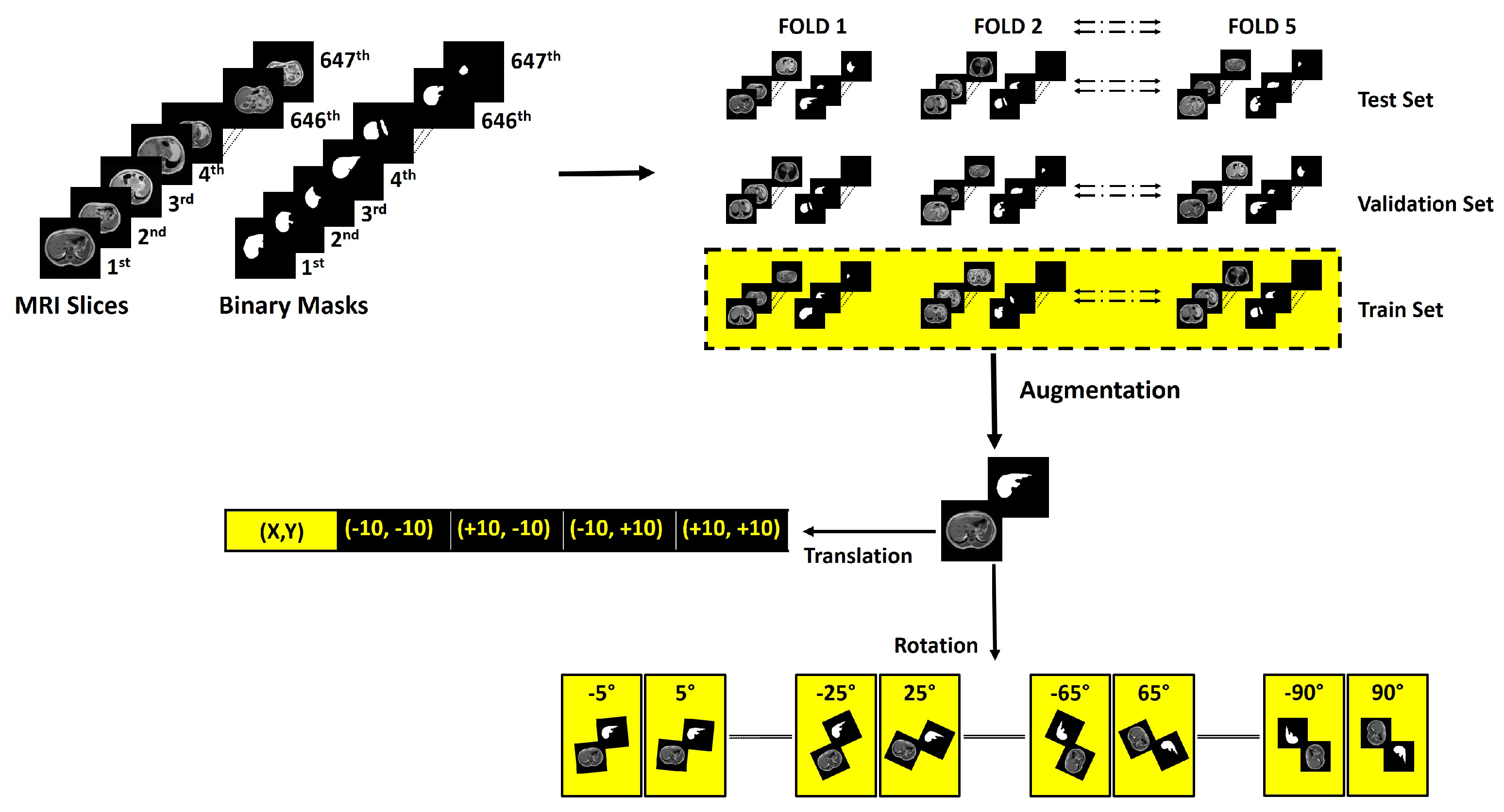
2.3.1. Fold Creation
2.3.2. Augmentation
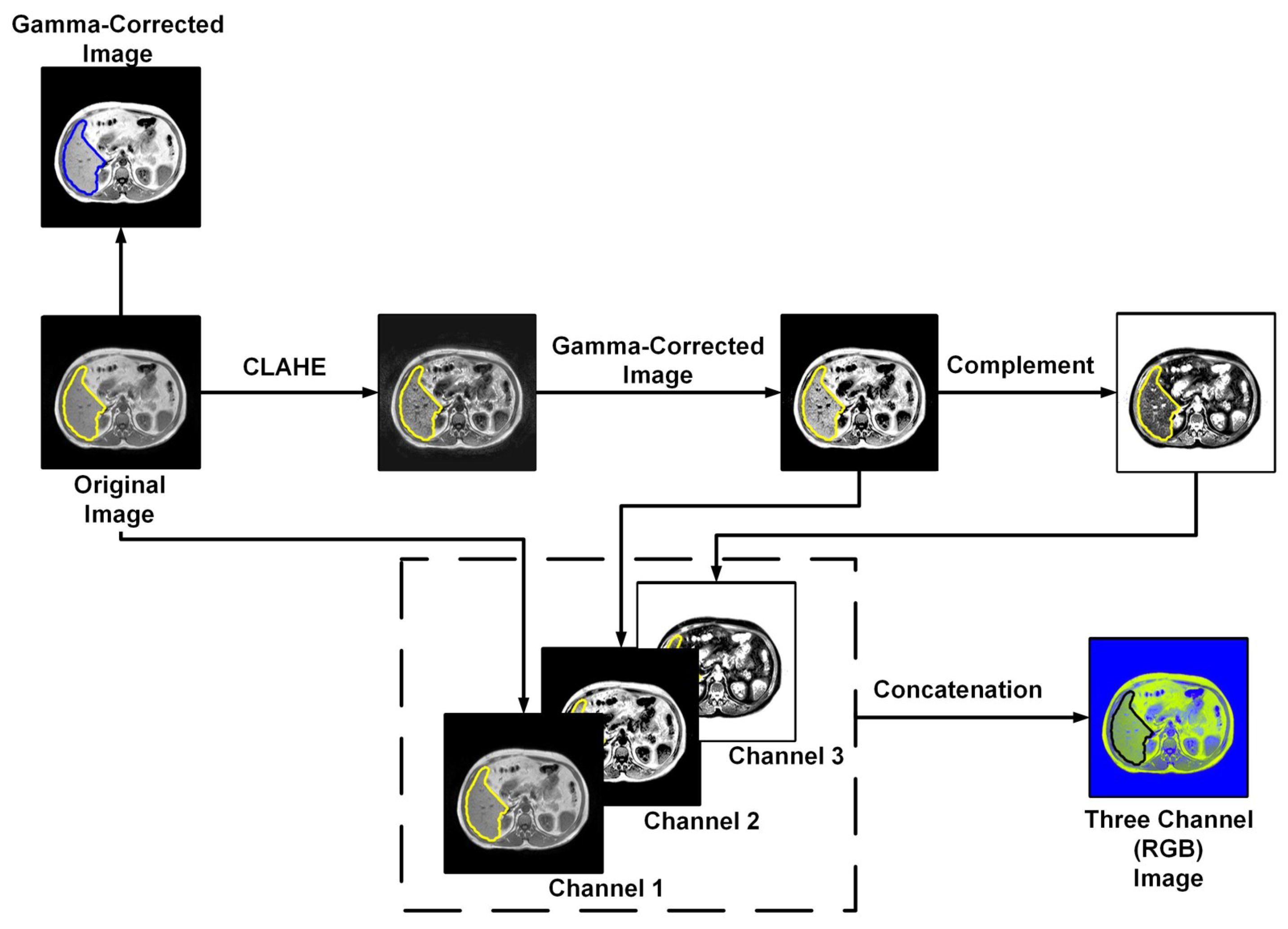
2.3.3. Image Enhancement
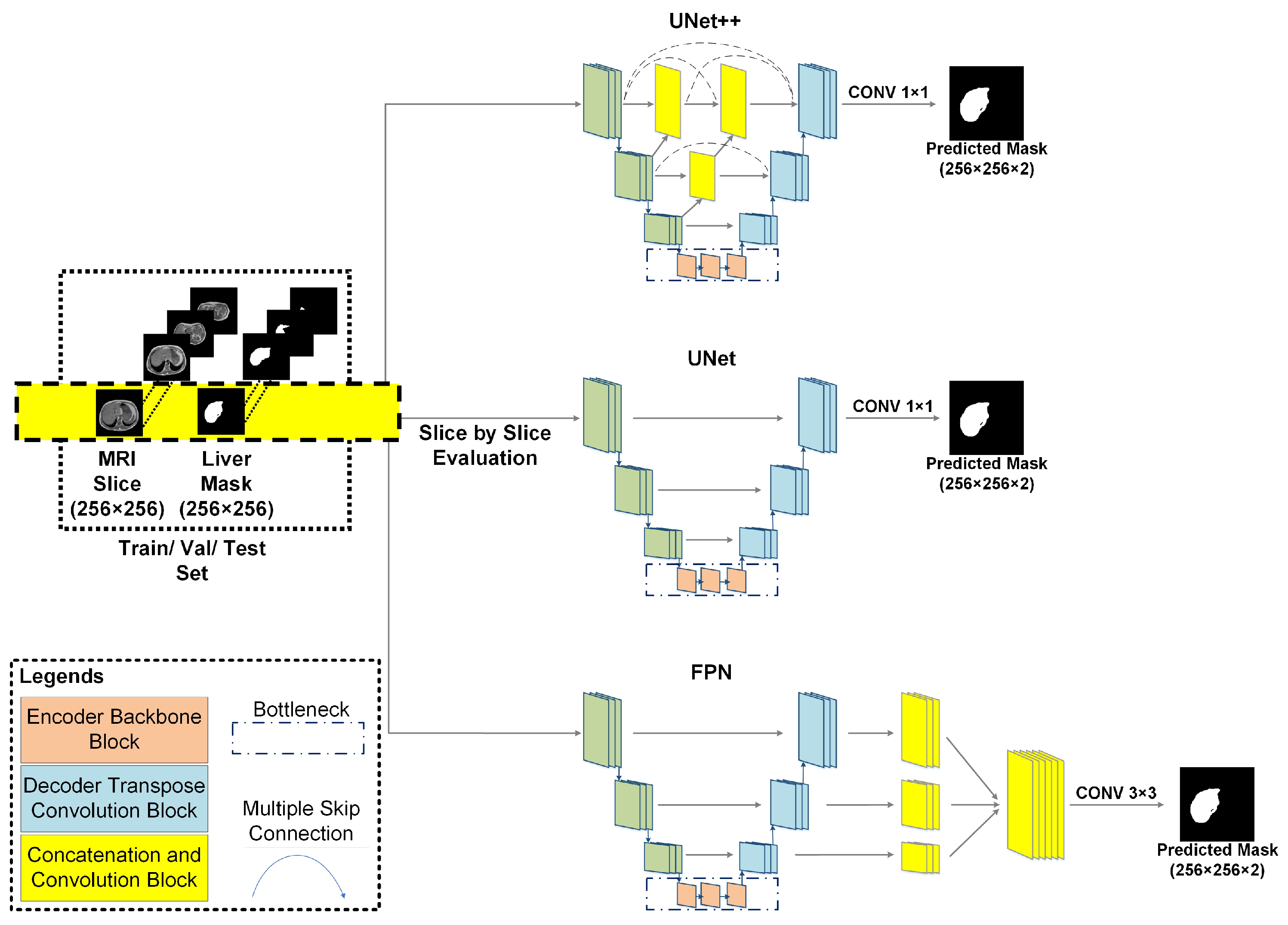
2.4. Deep Neural Networks
2.4.1. UNet
2.4.2. UNet++
2.4.3. Feature Pyramid Network (FPN)
2.4.4. Pretrained Backbones
2.5. Experiments
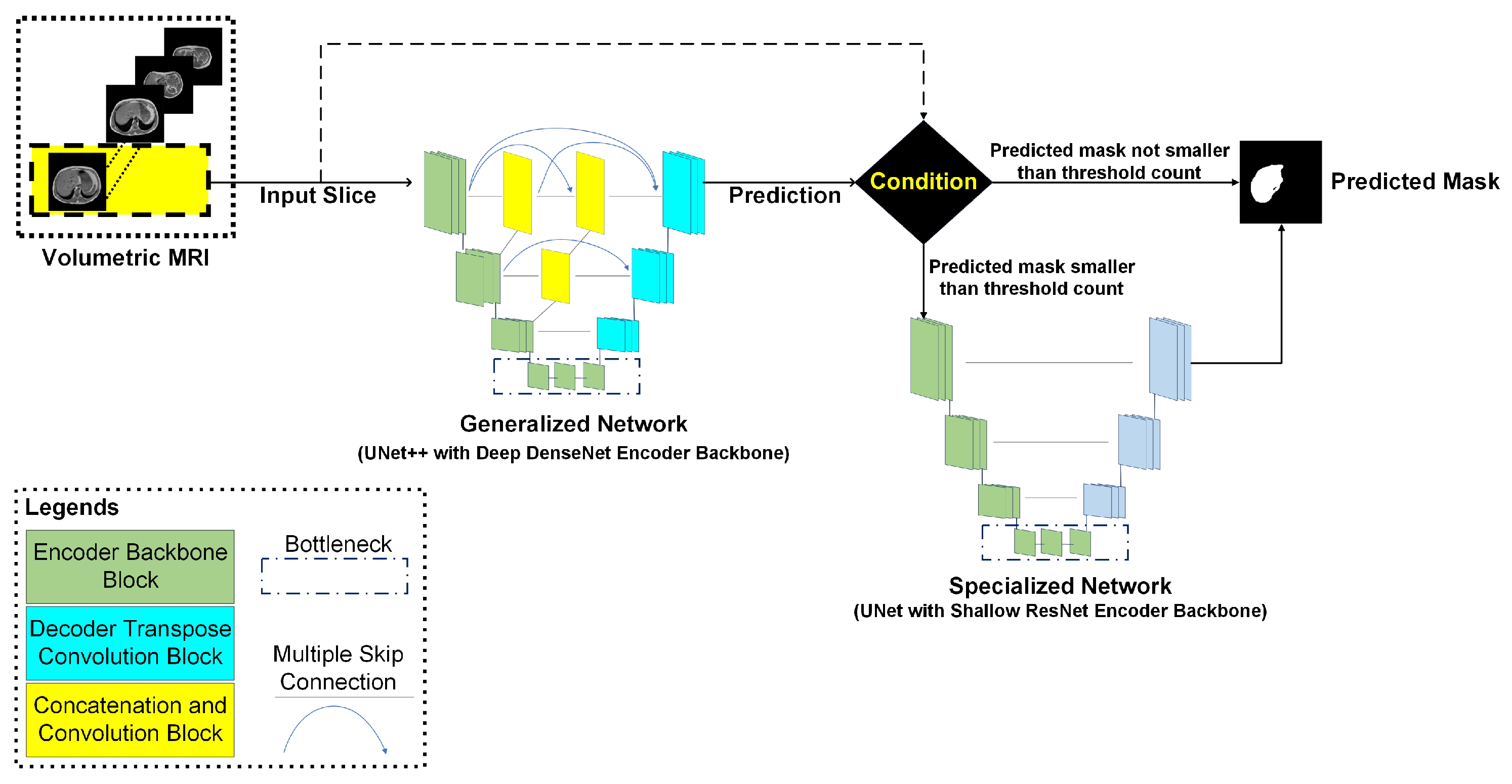
2.5.1. Generalized Model
2.5.2. Specialized Network for Handling Anatomical Ambiguity
2.5.3. Cascaded Network
2.6. Loss Function
2.7. Training Parameters
2.8. Evaluation Metrics
2.9. Cloud Deployment
3. Results and Discussion
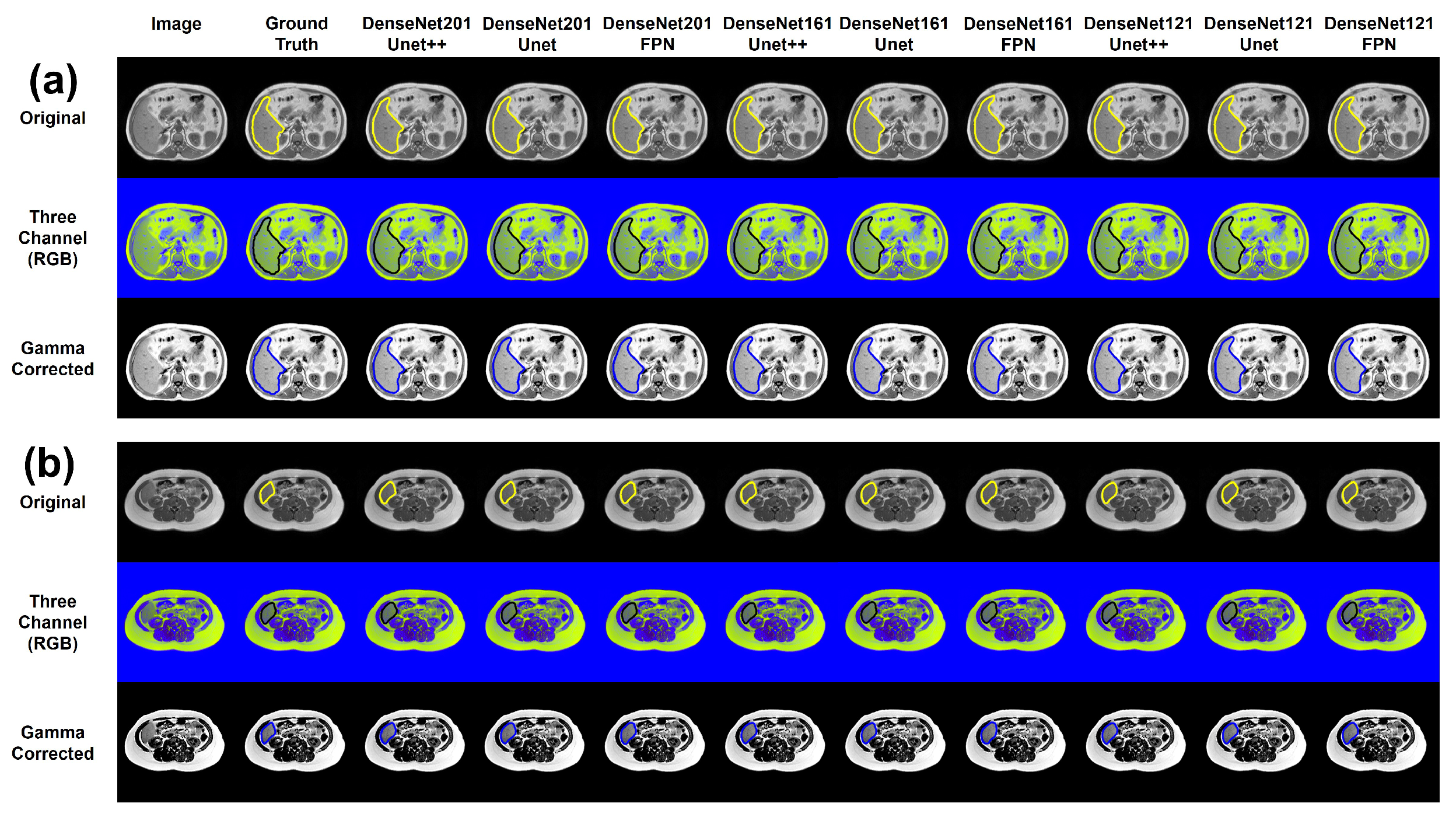
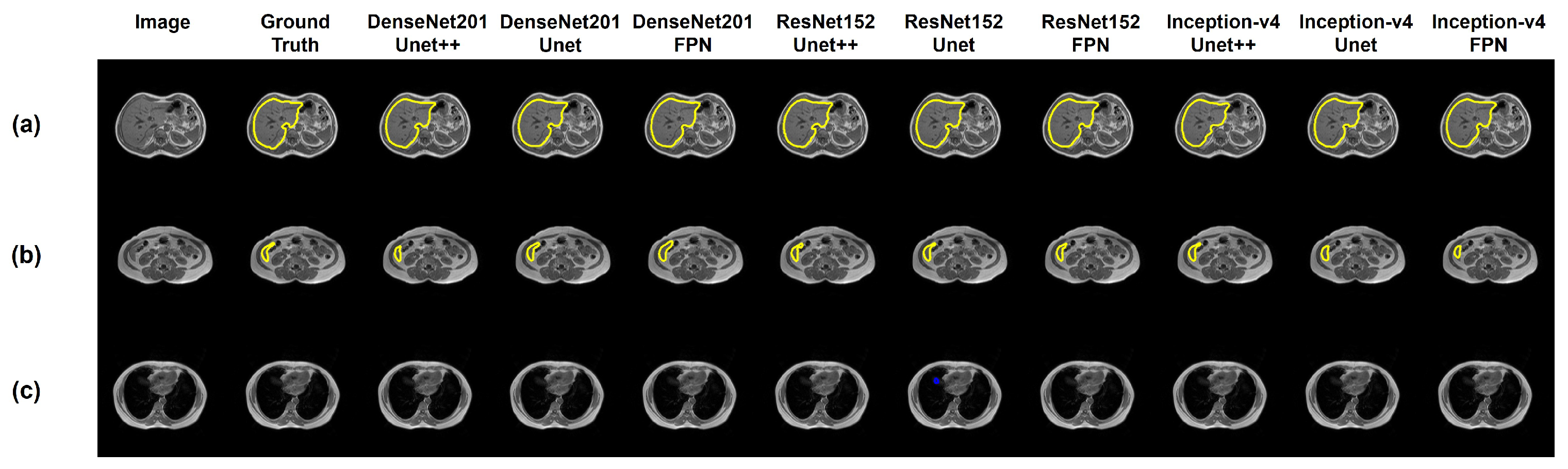
3.1. Generalized Model
3.2. Effects of Image Enhancement for Generalized Model
3.3. Limitation of the Generalized Model
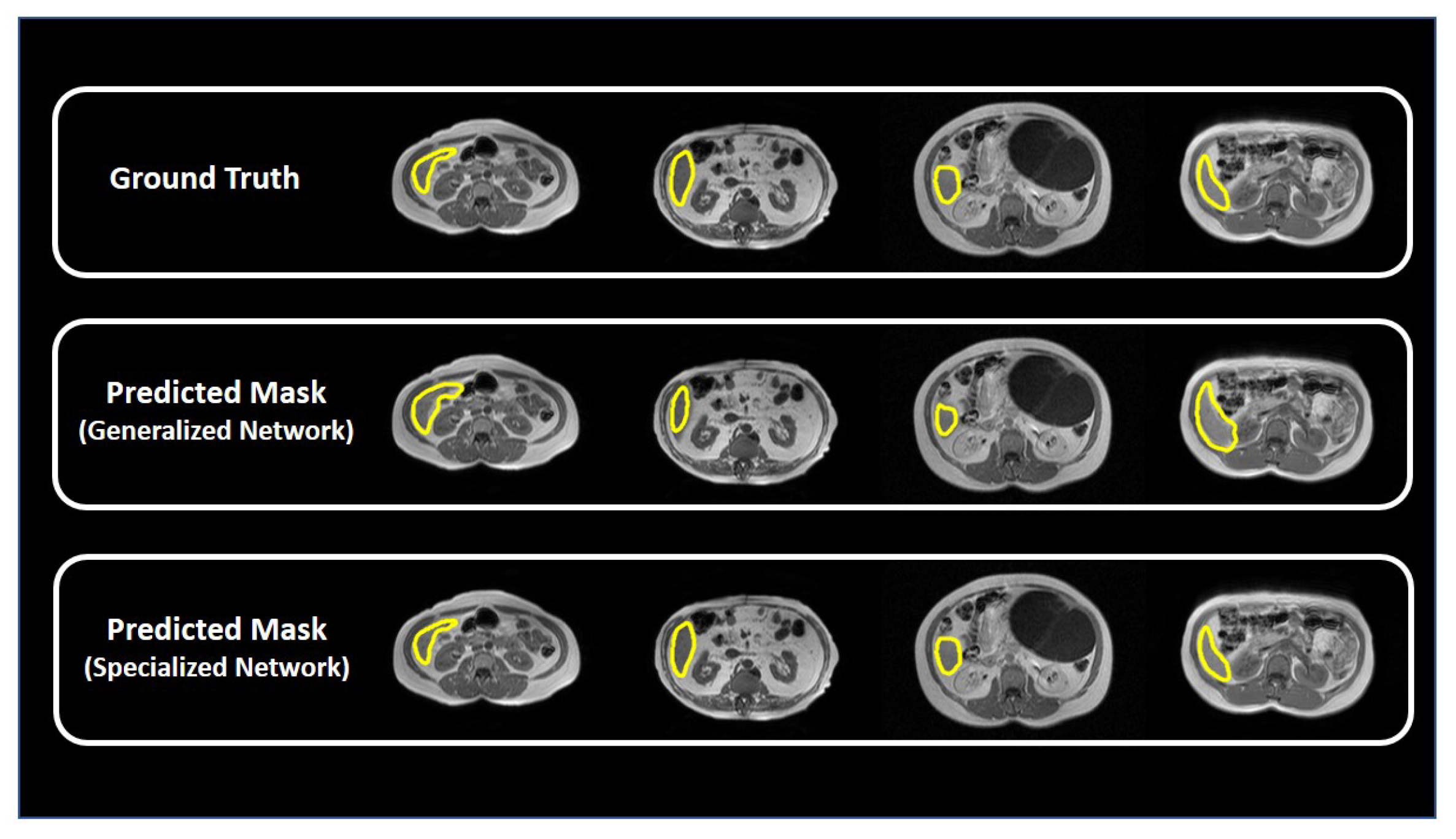
3.4. Specialized Network for Handling Anatomical Ambiguity
3.5. Cascaded Network
3.6. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aggarwal, R.; Sounderajah, V.; Martin, G.; Ting, D.S.; Karthikesalingam, A.; King, D.; Ashrafian, H.; Darzi, A. Diagnostic accuracy of deep learning in medical imaging: A systematic review and meta-analysis. NPJ Digit. Med. 2021, 4, 65. [Google Scholar] [CrossRef] [PubMed]
- Barragán-Montero, A.; Javaid, U.; Valdés, G.; Nguyen, D.; Desbordes, P.; Macq, B.; Willems, S.; Vandewinckele, L.; Holmström, M.; Löfman, F.; et al. Artificial intelligence and machine learning for medical imaging: A technology review. Phys. Med. 2021, 83, 242–256. [Google Scholar] [CrossRef]
- Chen, Z.; Song, Y.; Chang, T.-H.; Wan, X. Generating Radiology Reports via Memory-Driven Transformer. arXiv 2020, arXiv:2010.16056. [Google Scholar]
- Tahir, A.M.; Chowdhury, M.E.; Khandakar, A.; Rahman, T.; Qiblawey, Y.; Khurshid, U.; Kiranyaz, S.; Ibtehaz, N.; Rahman, M.S.; Al-Maadeed, S.; et al. COVID-19 infection localization and severity grading from chest X-ray images. Comput. Biol. Med. 2021, 139, 105002. [Google Scholar] [CrossRef] [PubMed]
- Abbas, T.O.; AbdelMoniem, M.; Khalil, I.; Hossain, M.S.A.; Chowdhury, M.E. Deep learning based automated quantification of urethral plate characteristics using the plate objective scoring tool (POST). arXiv 2023, arXiv:2209.13848. [Google Scholar] [CrossRef]
- Dou, Q.; Chen, H.; Jin, Y.; Yu, L.; Qin, J.; Heng, P.A. 3D Deeply Supervised Network for Automatic Liver Segmentation from CT Volumes. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2016: 19th International Conference, Athens, Greece, 17–21 October 2016; Proceedings, Part II 19. Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Chen, C.; Zhou, K.; Zha, M.; Qu, X.; Guo, X.; Chen, H.; Wang, Z.; Xiao, R. An effective deep neural network for lung lesions segmentation from COVID-19 CT images. IEEE Trans. Ind. Inform. 2021, 17, 6528–6538. [Google Scholar] [CrossRef]
- Chen, C.; Xiao, R.; Zhang, T.; Lu, Y.; Guo, X.; Wang, J.; Chen, H.; Wang, Z. Pathological lung segmentation in chest CT images based on improved random walker. Comput. Methods Programs Biomed. 2021, 200, 105864. [Google Scholar] [CrossRef]
- Hu, P.; Wu, F.; Peng, J.; Liang, P.; Kong, D. Automatic 3D liver segmentation based on deep learning and globally optimized surface evolution. Phys. Med. Biol. 2016, 61, 8676. [Google Scholar] [CrossRef]
- Liu, X.; Song, L.; Liu, S.; Zhang, Y. A review of deep-learning-based medical image segmentation methods. Sustainability 2021, 13, 1224. [Google Scholar] [CrossRef]
- Yang, R.; Yu, Y. Artificial convolutional neural network in object detection and semantic segmentation for medical imaging analysis. Front. Oncol. 2021, 11, 638182. [Google Scholar] [CrossRef]
- Liu, L.; Wolterink, J.M.; Brune, C.; Veldhuis, R.N.J. Anatomy-aided deep learning for medical image segmentation: A review. Phys. Med. Biol. 2021, 66, 11TR01. [Google Scholar] [CrossRef] [PubMed]
- Peng, J.; Wang, Y.; Kong, D. Liver segmentation with constrained convex variational model. Pattern Recognit. Lett. 2014, 43, 81–88. [Google Scholar] [CrossRef]
- Liu, Z.; Song, Y.Q.; Sheng, V.S.; Wang, L.; Jiang, R.; Zhang, X.; Yuan, D. Liver CT sequence segmentation based with improved U-Net and graph cut. Expert Syst. Appl. 2019, 126, 54–63. [Google Scholar] [CrossRef]
- Tang, X.; Jafargholi Rangraz, E.; Coudyzer, W.; Bertels, J.; Robben, D.; Schramm, G.; Deckers, W.; Maleux, G.; Baete, K.; Verslype, C.; et al. Whole liver segmentation based on deep learning and manual adjustment for clinical use in SIRT. Eur. J. Nucl. Med. Mol. Imag. 2020, 47, 2742–2752. [Google Scholar] [CrossRef]
- Kim, K.; Chun, J. A new hyper parameter of hounsfield unit range in liver segmentation. J. Internet Comput. Serv. 2020, 21, 103–111. [Google Scholar] [CrossRef]
- Xiang, K.; Jiang, B.; Shang, D. The overview of the deep learning integrated into the medical imaging of liver: A review. Hepatol. Int. 2021, 15, 868–880. [Google Scholar] [CrossRef]
- Elbanna, K.Y.; Kielar, A.Z. Computed Tomography Versus Magnetic Resonance Imaging for Hepatic Lesion Characterization/Diagnosis. Clin. Liver Dis. 2021, 17, 159. [Google Scholar] [CrossRef]
- Coenegrachts, K. Magnetic resonance imaging of the liver: New imaging strategies for evaluating focal liver lesions. World J. Radiol. 2009, 1, 72. [Google Scholar] [CrossRef]
- Caseiro-Alves, F.; Brito, J.; Araujo, A.E.; Belo-Soares, P.; Rodrigues, H.; Cipriano, A.; Sousa, D.; Mathieu, D. Liver haemangioma: Common and uncommon findings and how to improve the differential diagnosis. Eur. Radiol. 2007, 17, 1544–1554. [Google Scholar] [CrossRef]
- Wang, G.; Zhu, S.; Li, X. Comparison of values of CT and MRI imaging in the diagnosis of hepatocellular carcinoma and analysis of prognostic factors. Oncol. Lett. 2019, 17, 1184–1188. [Google Scholar] [CrossRef]
- Gibbs, J.F.; Litwin, A.M.; Kahlenberg, M.S. Contemporary management of benign liver tumors. Surg. Clin. N. Am. 2004, 84, 463–480. [Google Scholar] [CrossRef]
- Mostafa, A.; Hassanien, A.E.; Houseni, M.; Hefny, H. Liver segmentation in MRI images based on whale optimization algorithm. Multimed. Tools Appl. 2017, 76, 24931–24954. [Google Scholar] [CrossRef]
- Hänsch, A.; Chlebus, G.; Meine, H.; Thielke, F.; Kock, F.; Paulus, T.; Abolmaali, N.; Schenk, A. Improving automatic liver tumor segmentation in late-phase MRI using multi-model training and 3D convolutional neural networks. Sci. Rep. 2022, 12, 12262. [Google Scholar] [CrossRef]
- Zhong, X.; Amrehn, M.; Ravikumar, N.; Chen, S.; Strobel, N.; Birkhold, A.; Kowarschik, M.; Fahrig, R.; Maier, A. Deep action learning enables robust 3D segmentation of body organs in various CT and MRI images. Sci. Rep. 2021, 11, 3311. [Google Scholar] [CrossRef]
- Pandey, P.; Pai, A.; Bhatt, N.; Das, P.; Makharia, G.; Ap, P. Contrastive semi-supervised learning for 2D medical image segmentation. arXiv 2021, arXiv:2106.06801. [Google Scholar]
- Kavur, A.E.; Gezer, N.S.; Barış, M.; Aslan, S.; Conze, P.H.; Groza, V.; Pham, D.D.; Chatterjee, S.; Ernst, P.; Özkan, S.; et al. CHAOS challenge-combined (CT-MR) healthy abdominal organ segmentation. Med. Image Anal. 2021, 69, 101950. [Google Scholar] [CrossRef]
- Mitta, D.; Chatterjee, S.; Speck, O.; Nürnberger, A. Upgraded w-net with attention gates and its application in unsupervised 3d liver segmentation. arXiv 2020, arXiv:2011.10654. [Google Scholar]
- Hong, J.; Zhang, Y.D.; Chen, W. Source-free unsupervised domain adaptation for cross-modality abdominal multi-organ segmentation. Knowl. Based Syst. 2022, 250, 109155. [Google Scholar] [CrossRef]
- Wang, X.; Xiang, T.; Zhang, C.; Song, Y.; Liu, D.; Huang, H.; Cai, W. Bix-Nas: Searching Efficient Bi-Directional Architecture for Medical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part I 24. Springer International Publishing: Cham, Switzerland, 2021; pp. 229–238. [Google Scholar] [CrossRef]
- Mulay, S.; Deepika, G.; Jeevakala, S.; Ram, K.; Sivaprakasam, M. Liver Segmentation from Multimodal Images Using HED-Mask R-CNN. In Proceedings of the Multiscale Multimodal Medical Imaging: First International Workshop, MMMI 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, 13 October 2019; Proceedings 1. Springer International Publishing: Cham, Switzerland, 2019; pp. 68–75. [Google Scholar] [CrossRef]
- Zbinden, L.; Catucci, D.; Suter, Y.; Berzigotti, A.; Ebner, L.; Christe, A.; Obmann, V.C.; Sznitman, R.; Huber, A.T. Convolutional neural network for automated segmentation of the liver and its vessels on non-contrast T1 vibe Dixon acquisitions. Sci. Rep. 2022, 12, 22059. [Google Scholar] [CrossRef]
- Netter, F.H. Section 4: Atlas of Human Anatomy, 3rd ed.; Cambridge University Press: Cambridge, UK, 2003; pp. 239–338. [Google Scholar] [CrossRef]
- Suetens, P. Chapter 4—Magnetic Resonance Imaging. In Fundamentals of Medical Imaging, 2nd ed.; Cambridge University Press: Cambridge, UK, 2017; pp. 64–104. [Google Scholar] [CrossRef]
- de Bazelaire, C.M.; Duhamel, G.D.; Rofsky, N.M.; Alsop, D.C. MR imaging relaxation times of abdominal and pelvic tissues measured in vivo at 3.0 T: Preliminary results. Radiology 2004, 230, 652–659. [Google Scholar] [CrossRef]
- Dimakis, N. Chapter 5—Magnetic Resonance Imaging (MRI). In Introduction to Medical Imaging—Physics, Engineering and Clinical Applications, 1st ed.; Cambridge University Press: Cambridge, UK, 2011; pp. 204–273. [Google Scholar] [CrossRef]
- Rahman, T.; Chowdhury, M.E.; Khandakar, A.; Mahbub, Z.B.; Hossain, M.S.A.; Alhatou, A.; Abdalla, E.; Muthiyal, S.; Islam, K.F.; Kashem, S.B.A.; et al. BIO-CXRNET: A robust multimodal stacking machine learning technique for mortality risk prediction of COVID-19 patients using chest X-ray images and clinical data. Neural Comput. Appl. 2023, 35, 17461–17483. [Google Scholar] [CrossRef]
- Hossain, S.A.; Rahman, M.A.; Chakrabarty, A.; Rashid, M.A.; Kuwana, A.; Kobayashi, H. Emotional State Classification from MUSIC-Based Features of Multichannel EEG Signals. Bioengineering 2023, 10, 99. [Google Scholar] [CrossRef]
- Hossain, S.A.; Rahman, M.A.; Chakrabarty, A. MUSIC Model Based Neural Information Processing for Emotion Recognition from Multichannel EEG Signal. In Proceedings of the 2021 8th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 26–27 August 2021; pp. 955–960. [Google Scholar] [CrossRef]
- Nalepa, J.; Marcinkiewicz, M.; Kawulok, M. Data augmentation for brain-tumor segmentation: A review. Front. Comput. Neurosci. 2019, 13, 83. [Google Scholar] [CrossRef]
- Safdar, M.F.; Alkobaisi, S.S.; Zahra, F.T. A Comparative Analysis of Data Augmentation Approaches for Magnetic Resonance Imaging (MRI) Scan Images of Brain Tumor. Acta Inform. Med. 2020, 28, 29–36. [Google Scholar] [CrossRef]
- Islam, K.R.; Kumar, J.; Tan, T.L.; Reaz, M.B.I.; Rahman, T.; Khandakar, A.; Abbas, T.; Hossain, M.S.A.; Zughaier, S.M.; Chowdhury, M.E.H. Prognostic Model of ICU Admission Risk in Patients with COVID-19 Infection Using Machine Learning. Diagnostics 2022, 12, 2144. [Google Scholar] [CrossRef]
- Mahmud, S.; Ibtehaz, N.; Khandakar, A.; Rahman, M.S.; Gonzales, A.J.; Rahman, T.; Hossain, M.S.; Hossain, M.S.A.; Faisal, M.A.A.; Abir, F.F.; et al. NABNet: A Nested Attention-guided BiConvLSTM network for a robust prediction of Blood Pressure components from reconstructed Arterial Blood Pressure waveforms using PPG and ECG signals. Biomed. Signal Process. Control 2023, 79, 104247. [Google Scholar] [CrossRef]
- TRahman, T.; Khandakar, A.; Qiblawey, Y.; Tahir, A.; Kiranyaz, S.; Kashem, S.B.A.; Islam, M.T.; Al Maadeed, S.; Zughaier, S.M.; Khan, M.S.; et al. Exploring the effect of image enhancement techniques on COVID-19 detection using chest X-ray images. Comput. Biol. Med. 2021, 132, 104319. [Google Scholar] [CrossRef]
- Rahman, T.; Khandakar, A.; Kadir, M.A.; Islam, K.R.; Islam, K.F.; Mazhar, R.; Hamid, T.; Islam, M.T.; Kashem, S.; Mahbub, Z.B.; et al. Reliable tuberculosis detection using chest X-ray with deep learning, segmentation and visualization. IEEE Access 2020, 8, 191586–191601. [Google Scholar] [CrossRef]
- Qiblawey, Y.; Tahir, A.; Chowdhury, M.E.; Khandakar, A.; Kiranyaz, S.; Rahman, T.; Ibtehaz, N.; Mahmud, S.; Maadeed, S.A.; Musharavati, F.; et al. Detection and severity classification of COVID-19 in CT images using deep learning. Diagnostics 2021, 11, 893. [Google Scholar] [CrossRef]
- Khan, M.M.; Chowdhury, M.E.H.; Arefin, A.S.M.S.; Podder, K.K.; Hossain, M.S.A.; Alqahtani, A.; Murugappan, M.; Khandakar, A.; Mushtak, A.; Nahiduzzaman, M. A Deep Learning-Based Automatic Segmentation and 3D Visualization Technique for Intracranial Hemorrhage Detection Using Computed Tomography Images. Diagnostics 2023, 13, 2537. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support (DLMIA ML-CDS); Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-Supervised Nets. In Proceedings of the 18th International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; pp. 562–570. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Wang, S.; Zhang, Y. DenseNet-201-Based Deep Neural Network with Composite Learning Factor and Precomputation for Multiple Sclerosis Classification. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 3341095. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Artificial Neural Networks and Machine Learning—ICANN 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 270–279. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. February. Inception-v4, Inception-Resnet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Jadon, S. A Survey of Loss Functions for Semantic Segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Yi-de, M.; Qing, L.; Zhi-Bai, Q. Automated Image Segmentation Using Improved PCNN Model Based on Cross-Entropy. In Proceedings of the 2004 International Symposium on Intelligent Multimedia, Video and Speech Processing, Hong Kong, China, 20–22 October 2004; pp. 743–746. [Google Scholar] [CrossRef]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 240–248. [Google Scholar] [CrossRef]
- Diederik, P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ketkar, N. Stochastic Gradient Descent. In Deep Learning with Python; Apress: New York, NY, USA, 2017; pp. 113–132. [Google Scholar]
- Ravandi, B.; Papapanagiotou, I. A Self-Learning Scheduling in Cloud Software Defined Block Storage. In Proceedings of the 2017 IEEE 10th International Conference on Cloud Computing (CLOUD), Honololu, HI, USA, 25–30 June 2017; pp. 415–422. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tissue | 1.5 T | 3.0 T | ||
|---|---|---|---|---|
| (msec) | (msec) | (msec) | (msec) | |
| Kidney | 966–1412 | 85–87 | 1142–1545 | 76–81 |
| Liver | 586 | 46 | 809 | 34 |
| Spleen | 1057 | 79 | 1328 | 79 |
| Lipid | 343 | 58 | 382 | 68 |
| Networks | Original | Three Channel | Gamma Corrected | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Architecture | Backbone | Acc. (%) | IoU (%) | DSC (%) | Acc. (%) | IoU (%) | DSC (%) | Acc. (%) | IoU (%) | DSC (%) |
| UNet++ | DenseNet201 | 99.73 | 91.00 | 94.30 | 99.60 | 88.95 | 92.35 | 99.42 | 89.28 | 91.91 |
| DenseNet161 | 99.68 | 89.78 | 93.06 | 99.71 | 89.60 | 92.95 | 99.66 | 87.00 | 90.30 | |
| DenseNet121 | 99.43 | 89.17 | 92.57 | 99.66 | 90.08 | 93.40 | 99.56 | 87.58 | 90.92 | |
| ResNet152 | 99.70 | 89.79 | 93.13 | 99.67 | 87.97 | 91.34 | 99.70 | 89.00 | 92.33 | |
| ResNet50 | 99.70 | 90.42 | 93.81 | 99.68 | 89.54 | 92.98 | 99.66 | 88.13 | 91.64 | |
| ResNet18 | 99.70 | 89.73 | 93.08 | 99.70 | 89.63 | 93.01 | 99.63 | 84.55 | 88.50 | |
| Inception-resnet-v2 | 99.71 | 89.16 | 92.57 | 99.65 | 88.31 | 92.10 | 99.70 | 89.60 | 91.98 | |
| inception-v4 | 99.70 | 87.98 | 91.29 | 99.68 | 89.23 | 92.62 | 99.70 | 89.79 | 92.16 | |
| UNet | DenseNet201 | 99.76 | 89.98 | 93.22 | 99.72 | 88.77 | 92.13 | 99.78 | 88.74 | 92.18 |
| DenseNet161 | 99.57 | 90.48 | 93.84 | 99.43 | 90.08 | 93.60 | 99.45 | 87.58 | 90.92 | |
| DenseNet121 | 99.43 | 89.88 | 93.27 | 99.66 | 89.48 | 92.90 | 99.64 | 87.04 | 90.31 | |
| ResNet152 | 99.69 | 89.46 | 92.97 | 99.67 | 88.66 | 92.25 | 99.67 | 88.91 | 92.35 | |
| ResNet50 | 99.68 | 87.48 | 90.93 | 99.66 | 85.49 | 89.01 | 99.68 | 88.79 | 92.36 | |
| ResNet18 | 99.67 | 88.16 | 91.83 | 99.67 | 86.83 | 90.38 | 99.68 | 88.77 | 92.31 | |
| Inception-resnet-v2 | 99.66 | 87.68 | 91.41 | 99.68 | 88.20 | 91.80 | 99.70 | 87.81 | 91.32 | |
| inception-v4 | 99.68 | 88.64 | 92.34 | 99.70 | 90.68 | 93.47 | 99.62 | 87.89 | 91.71 | |
| FPN | DenseNet201 | 99.65 | 89.45 | 92.83 | 99.36 | 89.50 | 92.97 | 99.47 | 88.33 | 91.87 |
| DenseNet161 | 99.70 | 89.38 | 92.77 | 99.66 | 89.32 | 93.00 | 99.53 | 88.11 | 91.85 | |
| DenseNet121 | 99.47 | 87.52 | 91.08 | 99.47 | 89.39 | 92.94 | 99.71 | 86.91 | 90.49 | |
| ResNet152 | 99.66 | 88.49 | 92.08 | 99.67 | 88.90 | 92.59 | 99.68 | 87.85 | 91.46 | |
| ResNet50 | 99.69 | 89.01 | 92.52 | 99.65 | 88.15 | 91.88 | 99.66 | 88.76 | 92.40 | |
| ResNet18 | 99.68 | 88.33 | 91.91 | 99.66 | 88.10 | 91.95 | 99.67 | 88.58 | 92.33 | |
| Inception-resnet-v2 | 99.61 | 87.03 | 91.46 | 99.67 | 88.17 | 92.08 | 99.65 | 88.52 | 92.39 | |
| inception-v4 | 99.62 | 85.52 | 90.85 | 99.66 | 88.64 | 92.55 | 99.66 | 88.64 | 92.55 | |
| Fold No | Middle Part of Liver (Liver Content: Large) | Superior Part of Liver (Liver Content: Medium) | Inferior Part of Liver (Liver Content: Small) | Upper Part of Kidney (Liver Content: Absent) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Train Set Slice % |
Test Set Slice % | DSC (%) |
Train Set Slice % |
Test Set Slice % | DSC (%) |
Train Set Slice % |
Test Set Slice % | DSC (%) |
Train Set Slice % |
Test Set Slice % | DSC (%) | |
| 1 | 7.74% | 19.38% | 97.03% | 45.63% | 34.89% | 95.33% | 12.71% | 16.28% | 81.95% | 34.12% | 29.46% | 100.00% |
| 2 | 7.73% | 11.63% | 95.75% | 44.36% | 41.86% | 95.11% | 13.25% | 11.63% | 82.64% | 34.66% | 34.88% | 95.55% |
| 3 | 6.69% | 17.83% | 96.17% | 43.43% | 41.86% | 95.20% | 11.79% | 12.40% | 78.13% | 35.85 % | 30.23% | 97.43% |
| 4 | 7.67% | 10.85% | 95.70% | 43.26% | 42.63% | 95.23% | 14.90% | 9.30% | 80.20% | 34.18% | 37.21% | 97.91% |
| 5 | 6.86% | 16.79% | 97.35% | 44.25% | 38.17% | 93.90% | 14.15% | 9.16% | 82.46% | 34.75% | 35.88% | 94.78% |
| Networks | Metrics (Specialized Network) | Metrics ( Best-Performing Generalized Network) | |||||
|---|---|---|---|---|---|---|---|
| Architecture | Backbone | Acc.(%) | IoU (%) | DSC (%) | Acc. (%) | IoU (%) | DSC (%) |
| UNet | ResNet18 | 99.64 | 77.00 | 86.22 | |||
| ResNet50 | 99.81 | 72.06 | 80.94 | ||||
| ResNet152 | 99.78 | 70.00 | 79.73 | ||||
| Inception-resnet-v2 | 99.70 | 72.73 | 81.72 | ||||
| UNet++ | ResNet18 | 99.78 | 71.71 | 78.38 | |||
| ResNet50 | 99.76 | 71.62 | 80.96 | ||||
| ResNet152 | 99.80 | 71.89 | 81.02 | 99.76 | 70.74 | 80.88 | |
| Inception-resnet-v2 | 99.78 | 75.58 | 84.03 | ||||
| FPN | ResNet18 | 99.80 | 71.20 | 82.04 | |||
| ResNet50 | 99.77 | 69.75 | 79.77 | ||||
| ResNet152 | 99.78 | 71.86 | 81.20 | ||||
| Inception-resnet-v2 | 99.80 | 70.92 | 80.41 | ||||
| Experiments | Acc. (%) | IoU (%) | DSC (%) |
|---|---|---|---|
| Generalized Network | 99.73% | 91.00% | 94.30% |
| Cascaded Network | 99.70% | 92.10% | 95.15% |
| Authors | Methodology and Approach | Metric (DSC) |
|---|---|---|
| X. Zhong et al. [25] | Deep action learning with 3D UNet | 80.60 ± 5.30% |
| P. Pandey et al. [26] | Contrastive Semi Supervised Learning Approach with UNet | 85.90% |
| D. Mitta et al. [28] | W-Net with attention gates | 88.12% |
| J. Hong et al. [29] | Source Free Unsupervised UNet | 88.40% |
| X. Wang et al. [30] | Bidirectional Searching Neural Net | 89.80% |
| S. Mulay et al. [31] | Mask R-CNN | 80.00% |
| Geomatric Edge Enhancement based Mask R-CNN | 91.00% | |
| L. Zbinden et al. [32] | nnUNet | 93.60% |
| Proposed | Cascaded Network for Handling Anatomical Ambiguity | 95.15% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossain, M.S.A.; Gul, S.; Chowdhury, M.E.H.; Khan, M.S.; Sumon, M.S.I.; Bhuiyan, E.H.; Khandakar, A.; Hossain, M.; Sadique, A.; Al-Hashimi, I.; et al. Deep Learning Framework for Liver Segmentation from T1-Weighted MRI Images. Sensors 2023, 23, 8890. https://doi.org/10.3390/s23218890
Hossain MSA, Gul S, Chowdhury MEH, Khan MS, Sumon MSI, Bhuiyan EH, Khandakar A, Hossain M, Sadique A, Al-Hashimi I, et al. Deep Learning Framework for Liver Segmentation from T1-Weighted MRI Images. Sensors. 2023; 23(21):8890. https://doi.org/10.3390/s23218890
Chicago/Turabian StyleHossain, Md. Sakib Abrar, Sidra Gul, Muhammad E. H. Chowdhury, Muhammad Salman Khan, Md. Shaheenur Islam Sumon, Enamul Haque Bhuiyan, Amith Khandakar, Maqsud Hossain, Abdus Sadique, Israa Al-Hashimi, and et al. 2023. "Deep Learning Framework for Liver Segmentation from T1-Weighted MRI Images" Sensors 23, no. 21: 8890. https://doi.org/10.3390/s23218890