


CSI Feedback Model Based on Multi-Source Characterization in FDD Systems
 ,
,
Abstract
:1. Introduction
1.1. Background and Motivations
1.2. Contributions
- (1)
- Use dual-path neural networks. Path1 and Path2 learn the channel matrix’s spatial features and temporal properties, respectively. Path1 adopts multiple sensory fields to understand the channel matrix’s spatial characteristics comprehensively, and Path2 combines the Transformer Attention Mechanism with Convolutional Neural Networks to thoroughly learn the temporal properties of the channel information.
- (2)
- Path1 uses multiple sensory fields; Path2 uses the Transformer attention mechanism combined with a convolutional neural network to ensure the learning of temporal relationships while reducing model parameters. The two path feature representations are eventually fused to improve the model’s performance, robustness, and generalization ability.
1.3. Paper Organization
2. System Model
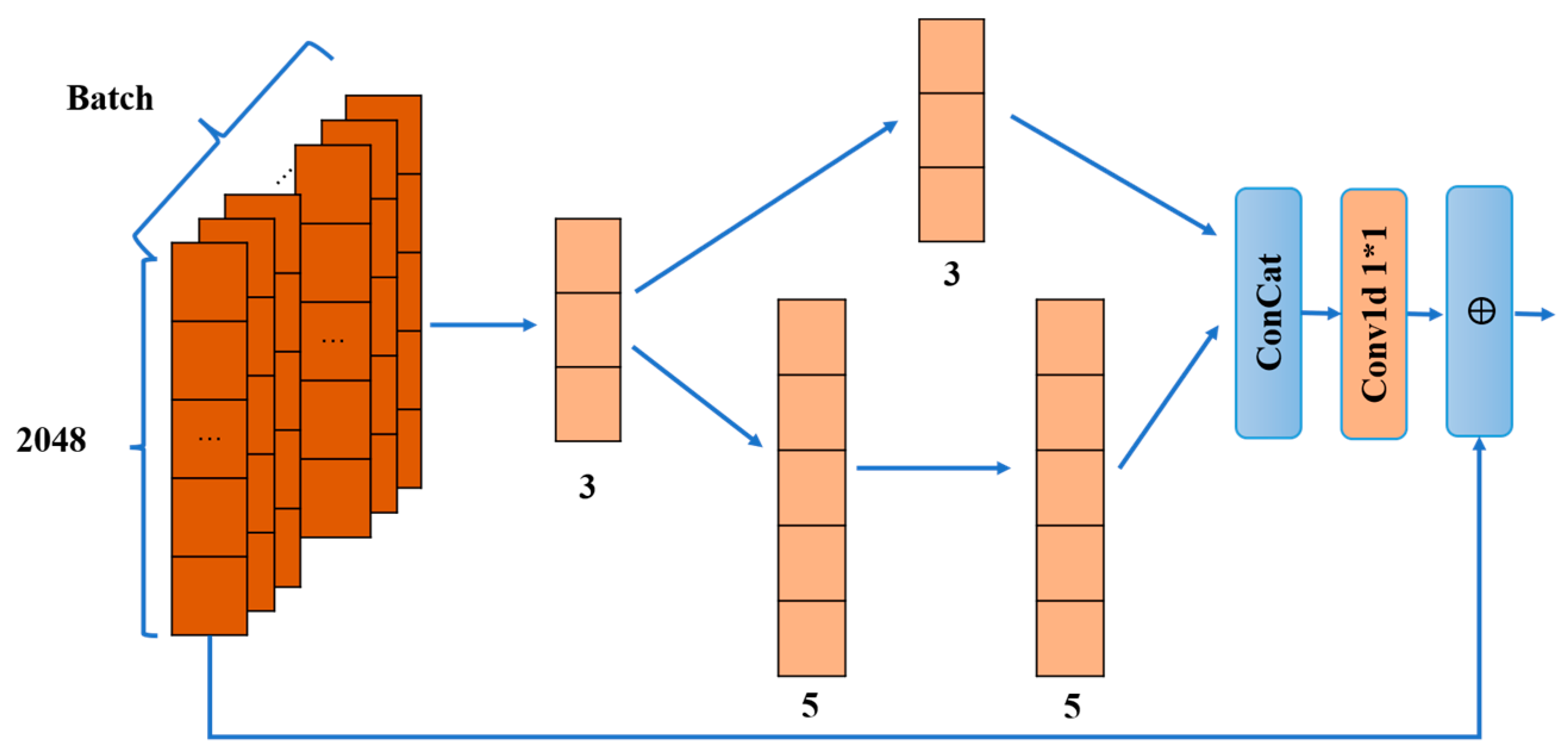
3. Mix_Multi_TransNet Design
3.1. Network Modeling Processes
3.2. Path1
3.3. Path2
3.4. Mix_Multi_TransNet Network Outputs
3.5. Mix_Multi_TransNet Steps
| Algorithm 1: Mix_Multi_TransNet Steps | |
| 1 | Input: |
| 2 | Output: |
| 3 | Initialize: |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | Path1: Path1_E, Path1_D |
| 9 | Path1_E: ; Path1_D: |
| 10 | Path2: Path2_E, Path2_D |
| 11 | Path1_E: ; Path1_D: |
| 12 | |
| 13 | End |
4. Simulation Results and Analysis
4.1. Data Sets, Training Programs, and Assessment Indicators
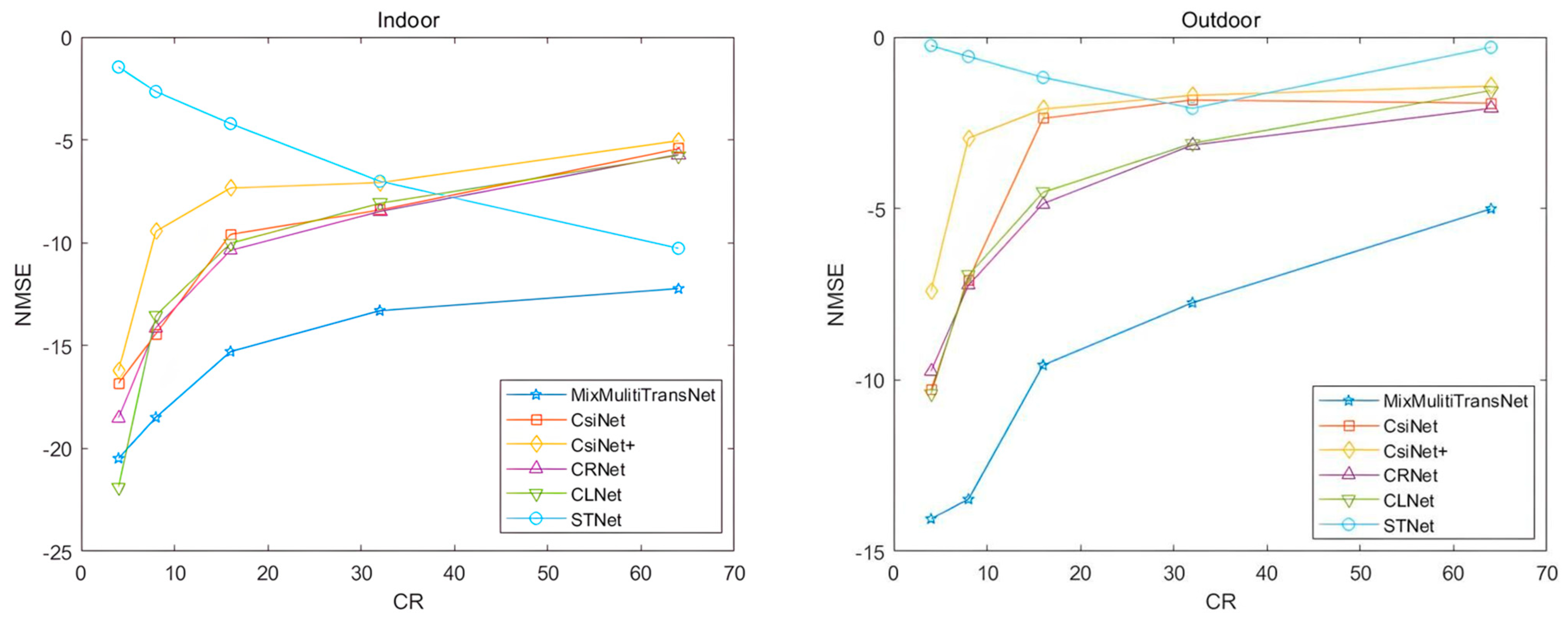
4.2. Mix_Multi_TransNet Network Performance
4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Grachev, M.; Parshin, A.; Parshin, Y. Channel Capacity of the MIMO System under the Action of a Complex of Noises and Correlated Channel Coefficients with Channel Mutual Coupling. In Proceedings of the 2023 Radiation and Scattering of Electromagnetic Waves (RSEMW), Divnomorskoe, Russian, 26–30 June 2023. [Google Scholar]
- Ataloglou, V.G.; Taravati, S.; Eleftheriades, G.V. Metasurfaces, physics and applications in wireless communications. Natl. Sci. Rev. 2023, 10, nwad164. [Google Scholar] [CrossRef] [PubMed]
- Tsiftsis, T.A.; Valagiannopoulos, C.; Liu, H.; Boulogeorgos, A.-A.A.; Miridakis, N.I. Metasurface-Coated Devices: A New Paradigm for Energy-Efficient and Secure 6G Communications. IEEE Veh. Technol. Mag. 2022, 17, 27–36. [Google Scholar] [CrossRef]
- Fujii, Y.; Iye, T.; Tsuda, K.; Tanibayashi, A. A 28 GHz Beamforming Technique for 5G Advanced Communication Systems. In Proceedings of the 2021 23rd International Conference on Advanced Communication Technology (ICACT), PyeongChang, Republic of Korea, 7–10 February 2021. [Google Scholar]
- Tuong, V.D.; Dao, N.-N.; Noh, W.; Cho, S. Dynamic Time Division Duplexing for Green Internet of Things. In Proceedings of the 2022 International Conference on Information Networking (ICOIN), Jeju-si, Republic of Korea, 12–15 January 2022. [Google Scholar]
- Shahramian, S.; Holyoak, M.; Zierdt, M.; Sayginer, M.; Weiner, J.; Singh, A.; Baeyens, Y. An All-Silicon E-Band Backhaul-on-Glass Frequency Division Duplex Module with >24 dBm PSAT & 8dB NF. In Proceedings of the 2022 IEEE Radio Frequency Integrated Circuits Symposium (RFIC), Denver, CO, USA, 19–21 June 2022. [Google Scholar]
- Wan, Q.; Fang, J.; Huang, Y.; Duan, H.; Li, H. A Variational Bayesian Inference-Inspired Unrolled Deep Network for MIMO Detection. IEEE Trans. Signal Process. 2022, 70, 423–437. [Google Scholar] [CrossRef]
- Kang, J.; Choi, W. Novel Codebook Design for Channel State Information Quantization in MIMO Rician Fading Channels with Limited Feedback. IEEE Trans. Signal Process. 2021, 69, 2858–2872. [Google Scholar] [CrossRef]
- Guo, J.; Wen, C.-K.; Chen, M.; Jin, S. AI-enhanced Codebook-based CSI Feedback in FDD Massive MIMO. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, OK, USA, 27–30 September 2021. [Google Scholar]
- Qing, C.; Yang, Q.; Cai, B.; Pan, B.; Wang, J. Superimposed Coding-Based CSI Feedback Using 1-Bit Compressed Sensing. IEEE Commun. Lett. 2020, 24, 193–197. [Google Scholar] [CrossRef]
- Nouri, N.; Azizipour, M.J.; Mohamed-Pour, K. A Compressed CSI Estimation Approach for FDD Massive MIMO Systems. In Proceedings of the 2020 28th Iranian Conference on Electrical Engineering (ICEE), Tabriz, Iran, 4–6 August 2020. [Google Scholar]
- Hoydis, J.; Aoudia, F.A.; Valcarce, A.; Viswanathan, H. Toward a 6G AI-native air interface. IEEE Commun. Mag. 2021, 59, 76–81. [Google Scholar] [CrossRef]
- Qin, Z.; Ye, H.; Li, G.Y.; Juang, B.-H.F. Deep learning in physical layer communications. IEEE Wirel. Commun. 2019, 26, 93–99. [Google Scholar] [CrossRef]
- Wang, T.; Wen, C.-K.; Wang, H.; Gao, F.; Jiang, T.; Jin, S. Deep learning for wireless physical layer: Opportunities and challenges. China Commun. 2017, 14, 92–111. [Google Scholar] [CrossRef]
- Liu, S.; Wang, T.; Wang, S. Toward intelligent wireless communications: Deep learning-based physical layer technologies. Digit. Commun. Netw. 2021, 7, 589–597. [Google Scholar] [CrossRef]
- Elijah, O.; Rahim, S.K.A.; New, W.K.; Leow, C.Y.; Cumanan, K.; Geok, T.K. Intelligent massive MIMO systems for beyond 5G networks: An overview and future trends. IEEE Access 2022, 10, 102532–102563. [Google Scholar] [CrossRef]
- O’shea, T.; Hoydis, J. An introduction to deep learning for the physical layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef]
- Ye, H.; Liang, L.; Li, G.Y.; Juang, B.-H. Deep learning-based end-to-end wireless communication systems with conditional GANs as unknown channels. IEEE Trans. Wireless Commun. 2020, 19, 3133–3143. [Google Scholar] [CrossRef]
- Dörner, S.; Cammerer, S.; Hoydis, J.; Brink, S.T. Deep Learning Based Communication Over the Air. IEEE J. Sel. Top. Signal Process 2018, 12, 132–143. [Google Scholar] [CrossRef]
- Wen, C.-K.; Shih, W.-T.; Jin, S. Deep learning for massive MIMO CSI feedback. IEEE Wirel. Commun. Lett. 2018, 7, 748–751. [Google Scholar] [CrossRef]
- Guo, J.; Wen, C.-K.; Jin, S.; Li, G.Y. Convolutional Neural Network-Based Multiple-Rate Compressive Sensing for Massive MIMO CSI Feedback: Design, Simulation, and Analysis. IEEE Trans. Wirel. Commun. 2020, 19, 2827–2840. [Google Scholar] [CrossRef]
- Lu, C.; Xu, W.; Jin, S.; Wang, K. Bit-Level Optimized Neural Network for Multi-Antenna Channel Quantization. IEEE Wirel. Commun. Lett. 2020, 9, 87–90. [Google Scholar] [CrossRef]
- Lu, Z.; Wang, J.; Song, J. Multi-resolution CSI Feedback with Deep Learning in Massive MIMO System. In Proceedings of the ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020. [Google Scholar]
- Ji, S.; Li, M. CLNet: Complex Input Lightweight Neural Network Designed for Massive MIMO CSI Feedback. IEEE Wirel. Commun. Lett. 2021, 10, 2318–2322. [Google Scholar] [CrossRef]
- Wang, T.; Wen, C.-K.; Jin, S.; Li, G.Y. Deep Learning-Based CSI Feedback Approach for Time-Varying Massive MIMO Channels. IEEE Wirel. Commun. Lett. 2019, 8, 416–419. [Google Scholar] [CrossRef]
- Cai, Q.; Dong, C.; Niu, K. Attention Model for Massive MIMO CSI Compression Feedback and Recovery. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019. [Google Scholar]
- Mourya, S.; Amuru, S.; Kuchi, K.K. A Spatially Separable Attention Mechanism for Massive MIMO CSI Feedback. IEEE Wirel. Commun. Lett. 2023, 12, 40–44. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Liu, L.; Oestges, C.; Poutanen, J.; Haneda, K.; Vainikainen, P.; Quitin, F.; Tufvesson, F.; Doncker, P. The cost 2100 MIMO channel model. IEEE Wirel. Commun. 2012, 19, 92–99. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1/4 | 1/8 | 1/16 | 1/32 | 1/64 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Methods | NMSE | |||||||||
| In | Out | In | Out | In | Out | In | Out | In | Out | |
| Mix_Multi_TransNet | −20.48 | −14.05 | −18.49 | −13.48 | −15.29 | −9.57 | −13.30 | −7.75 | −12.23 | −5.01 |
| CsiNet | −16.83 | −10.28 | −14.43 | −7.08 | −9.59 | −2.37 | −8.41 | −1.84 | −5.43 | −1.93 |
| CsiNet+ | −16.22 | −7.40 | −9.45 | −2.95 | −7.34 | −2.10 | −7.08 | −1.70 | −5.04 | −1.43 |
| CRNet | −18.51 | −9.74 | −14.12 | −7.24 | −10.37 | −4.86 | −8.48 | −3.15 | −5.71 | −2.08 |
| CLNet | −21.88 | −10.42 | −13.54 | −6.95 | −10.03 | −4.53 | −8.08 | −3.10 | −5.76 | −1.56 |
| STNet | −1.46 | −0.25 | −2.65 | −0.57 | −4.21 | −1.18 | −7.01 | −2.08 | −10.27 | −0.30 |
| Training Time(minutes) | ||||||||||
| Mix_Multi_TransNet | 259.16 | 264.07 | 257.14 | 264.41 | 256.26 | 263.81 | 257.50 | 265.93 | 260.86 | 264.80 |
| Batch’s Response Time (milliseconds) | ||||||||||
| 12.27 | 12.24 | 12.23 | 12.21 | 12.24 | 12.23 | 12.24 | 12.25 | 12.19 | 12.18 | |
| Path1 | Path2 | Path1 + Path2 without Convolution | Path1 + Path2 | |||||
|---|---|---|---|---|---|---|---|---|
| In | Out | In | Out | In | Out | In | Out | |
| 1/4 | −13.34 | −8.77 | −8.32 | −2.90 | −15.67 | −9.66 | −20.48 | −14.05 |
| 1/8 | −10.39 | −5.92 | −10.70 | −2.62 | −13.40 | −6.84 | −18.49 | −13.48 |
| 1/16 | −8.33 | −3.46 | −8.58 | −1.29 | −10.35 | −4.30 | −15.29 | −9.57 |
| 1/32 | −5.45 | −2.21 | −6.16 | −2.92 | −7.08 | −2.72 | −13.30 | −7.75 |
| 1/64 | −4.25 | −1.95 | −6.95 | −4.30 | −5.76 | −2.48 | −12.23 | −5.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, F.; Zhao, X.; Zhang, B.; Xiang, P.; Hu, M.; Gao, X. CSI Feedback Model Based on Multi-Source Characterization in FDD Systems. Sensors 2023, 23, 8139. https://doi.org/10.3390/s23198139
Pan F, Zhao X, Zhang B, Xiang P, Hu M, Gao X. CSI Feedback Model Based on Multi-Source Characterization in FDD Systems. Sensors. 2023; 23(19):8139. https://doi.org/10.3390/s23198139
Chicago/Turabian StylePan, Fei, Xiaoyu Zhao, Boda Zhang, Pengjun Xiang, Mengdie Hu, and Xuesong Gao. 2023. "CSI Feedback Model Based on Multi-Source Characterization in FDD Systems" Sensors 23, no. 19: 8139. https://doi.org/10.3390/s23198139