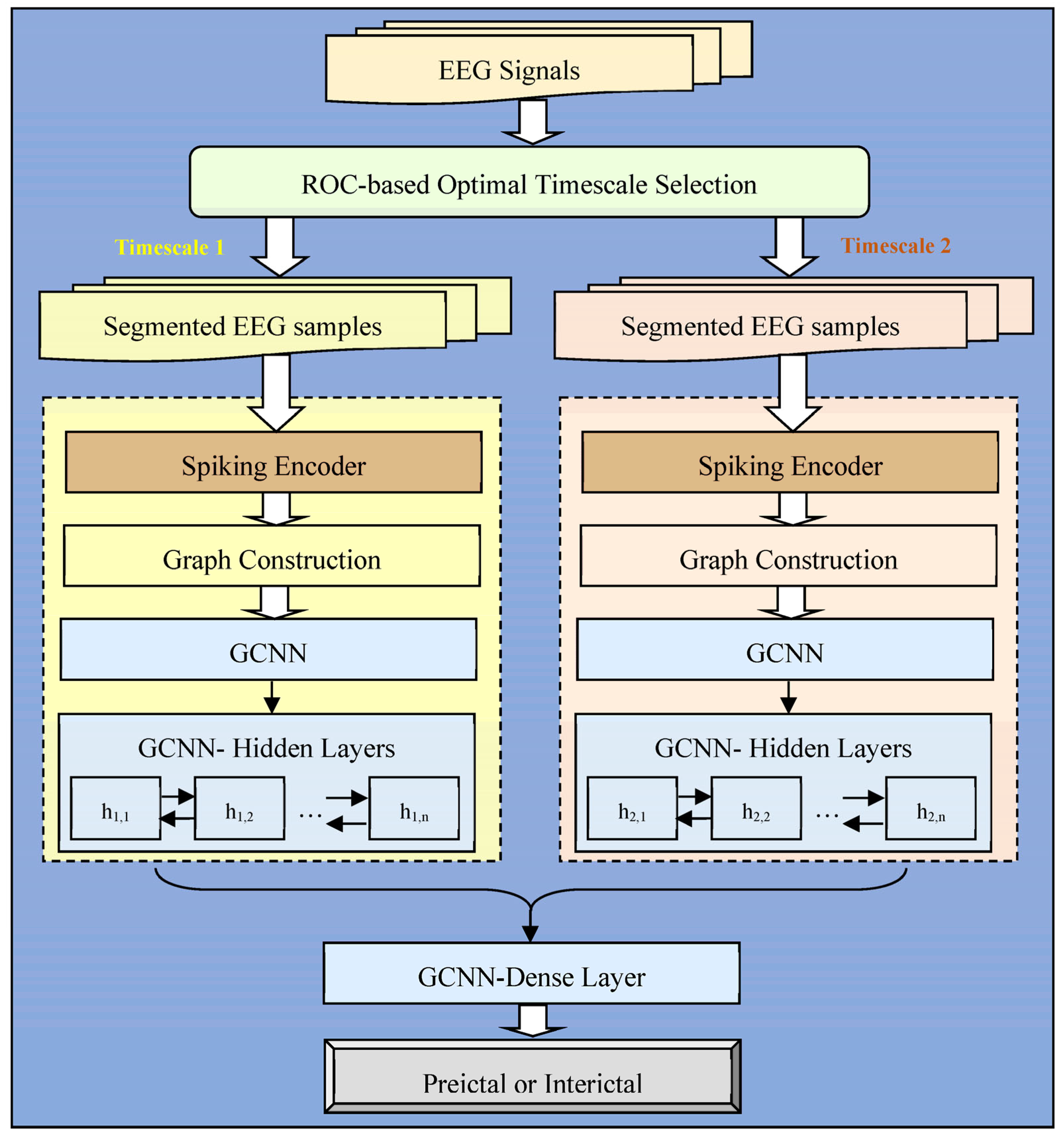
The effectiveness and performance of our proposed model for early epileptic seizure prediction were assessed, and the performance was compared with baseline models and the results of several works recently published in the literature. The experimental models of early epileptic seizure prediction methods were implemented using the Python programming language. The software environment used for this experimental analysis was Python, running on a 64-bit Ubuntu operating system powered by a 3GHz Intel processing unit and 32GB memory.
5.1. Datasets
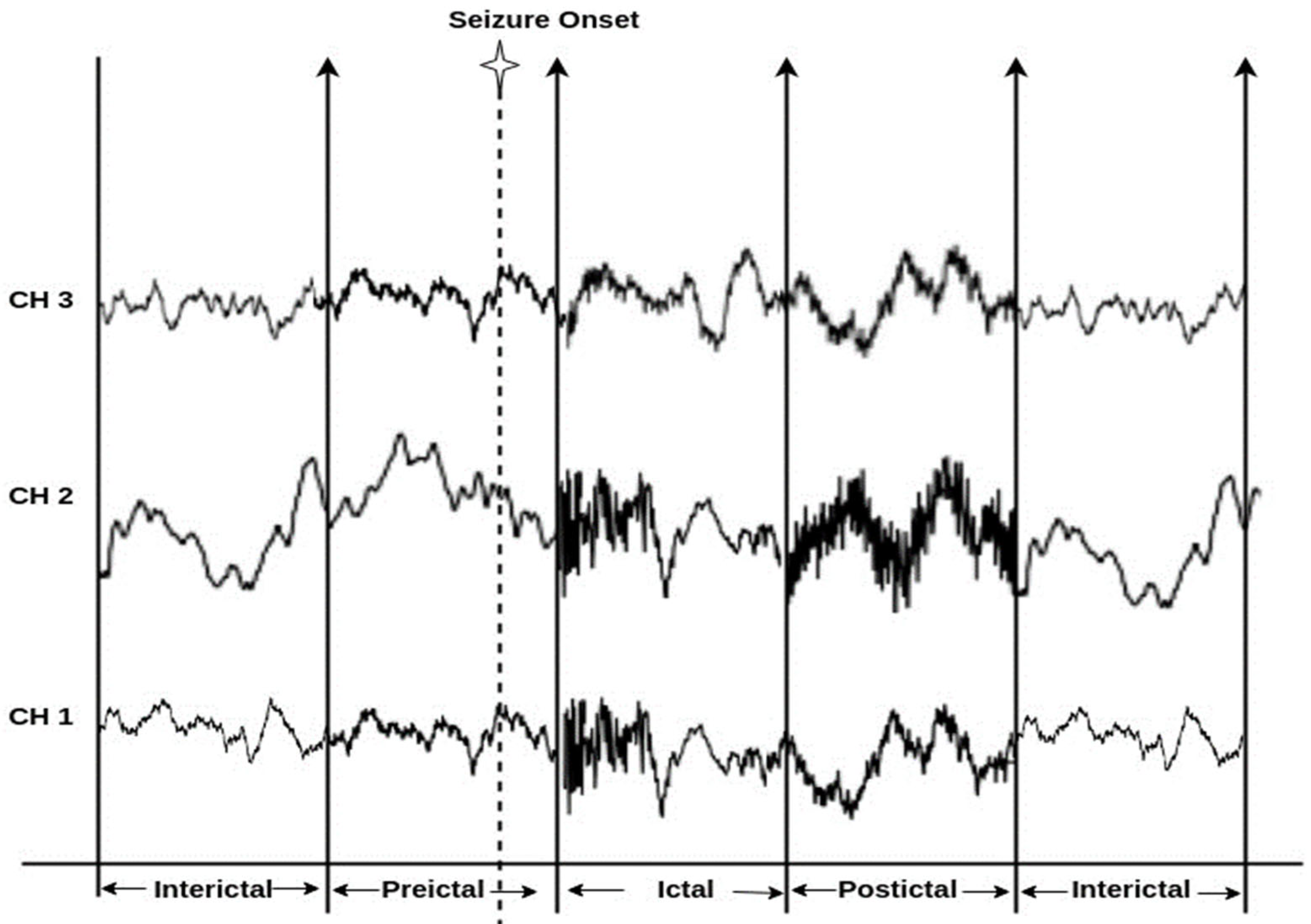
The experiments employed three EEG benchmark datasets, the CHB-MIT scalp EEG dataset, the Bonn EEG dataset, and the New Delhi EEG dataset, to design the FL model for the proposed epileptic seizure prediction method. The datasets were adjusted for the epileptic seizure prediction task by accurately discriminating the preictal class from the interictal or ictal class. The main aim of this work is to perform seizure state prediction by determining the preictal state. Hence, we aim to accurately detect the preictal state on the basis of EEG signals (i.e., the combination of the preictal state with other seizure states like interictal or ictal state). Due to the availability of the preictal and ictal classes only in the benchmark CHB-MIT dataset, an experiment was performed focusing on the discrimination of the preictal and ictal classes, in which the probability of preictal class detection was only addressed when performing postprocessing.
Preprocessed CHB-MIT scalp EEG database: This database was originally gathered through the collaboration of the Children’s Hospital Boston and the Massachusetts Institute of Technology (CHB-MIT), and consists of patients with epileptic seizures that were uncontrollable with medication. This prediction model utilizes the Preprocessed CHB-MIT scalp EEG database [
59], containing separate Comma-Separated Value (CSV) preictal and ictal data files for the purposes of performance evaluation. Patients with an adequate number of preictal and ictal samples were selected in order to fit the problem of epileptic seizure prediction. Due to the availability of only the preictal and ictal classes in the preprocessed CHB-MIT dataset, in this work, the preictal state was discriminated from the ictal state when evaluating this dataset.
Bonn EEG dataset: The University of Bonn provides the Bonn EEG dataset [
60], comprising five distinct folder subsets. There are 100 single-channel EEG epochs in each file, and they are digitized at a sampling rate of 173.61 Hz using 12-bit A/D resolution. Each EEG epoch contains 4097 samples with a duration of 23.6 s. The Bonn dataset comprises EEG observations from a 100-single-channel system. In this case, a single channel refers to the observations recorded from a single electrode only for each channel. In conclusion, the Bonn dataset has 100 channels that belong to the single-channel recording type. In the Bonn EEG dataset, sets C and D are EEG samples with interictal and preictal states, as described in [
5,
61].
New Delhi EEG dataset: The Neurology and Sleep Center (NSC) database [
62] consists of 1024 EEG samples with a duration of 5.12 s, sampled at 200 Hz. Among the three states—ictal, preictal, and interictal—made publicly available in the NSC dataset, in this work, the preictal and interictal classes are considered for evaluating the seizure prediction algorithm.
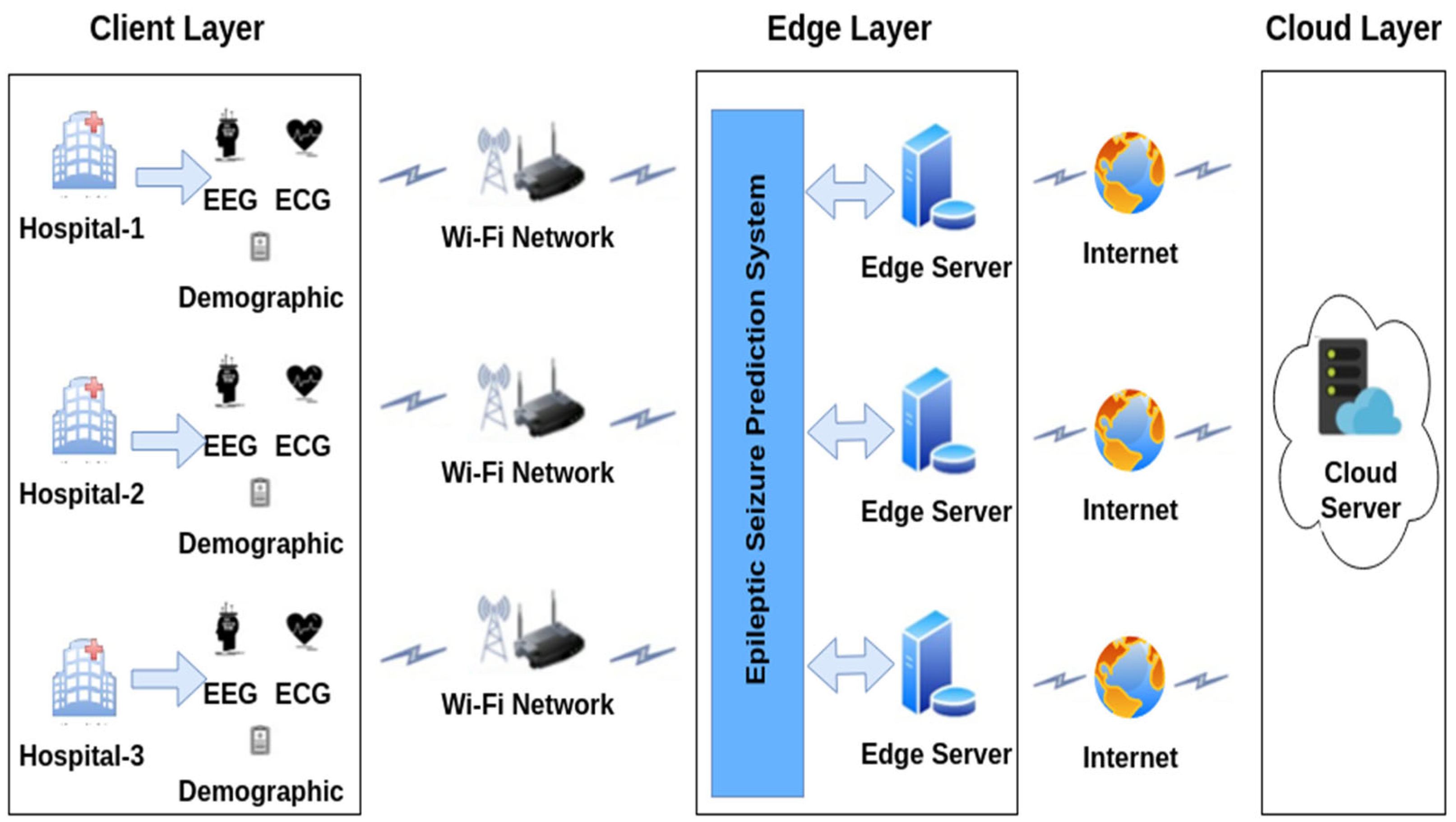
Moreover, experiments were conducted on the patients’ clinical records, including their demographic data and ECG-signal-based HRV features, in order to evaluate ANFIS-based decision making in the postprocessing stage of the proposed system. Owing to the lack of ECG data in the benchmark EEG datasets tested in this work, several HRV features for the ECG signals were modeled with reference to [
53,
54], rather than extracting features from unknown ECG signals. The preprocessing and examination of the ECG signals was outside the research scope of this work. Hence, to prove the influence of the ECG features on decision making with respect to epilepsy, standard ranges of HRV features were synthesized. Furthermore, these three epileptic EEG datasets lack clinical information about each patient. Thus, to test the influence of clinical information on epileptic seizure prediction, patient-specific clinical information was modeled randomly for each dataset.
5.2. Performance Metrics
The experiment utilizes the following evaluation metrics: sensitivity, specificity, accuracy, and false positive rate (FPR) to demonstrate the reliability of the proposed model.
Sensitivity: Sensitivity is the ratio between the number of correctly classified preictal samples and the total number of preictal samples to be classified in a particular class. Sensitivity is also known as recall.
Specificity: Specificity is the ratio between the number of correctly classified interictal samples and the total number of interictal samples actually classified.
Accuracy: Accuracy measures the overall performance of the model at detecting both the preictal and interictal samples.
False Positive Rate: FPR measures the number of false positives over the total test period.
Area Under the Curve (AUC): AUC quantitatively measures the performance of the learning model at discriminating between true positives and true negatives, with a higher AUC score showing better learning model performance.
Relative Accuracy: To measure the algorithm’s performance even on samples with imbalanced classes, relative accuracy is assessed using the prediction ability of the most frequent class in the samples, referred to as the baseline.
where
where
True Positive: Number of correctly detected preictal samples.
True Negative: Number of correctly detected interictal or ictal samples.
False Positive: Number of incorrectly detected preictal samples.
False Negative: Number of incorrectly detected preictal samples.
5.3. Results
In this experimental study, the variation across several baseline models and Existing Epileptic Seizure Prediction (EESP) works was investigated. The baseline models used for comparative purposes were K-Nearest Neighbor (KNN), Decision Tree, Support Vector Machine (SVM), CNN, and LSTM, whereas the EESP works were EESP1 [
24], EESP2 [
25], and EESP3 [
27]. In this experiment, the baseline algorithms were evaluated as classification models for the samples in three benchmark datasets. This section provides the results for the discrimination of the preictal state from the interictal state and the preictal state from the ictal state. In conclusion, the results in the Bonn and NSC datasets were tested on the preictal–interictal samples and the results in the CHB-MIT dataset were tested on the preictal–ictal samples.
Epileptic seizure prediction was realized, and a different anticipation strategy was shown to exist. Thus, the use of a fixed prediction time and the consideration of seizure onset time as a norm become ineffective. This is because the seizure prediction time varies from one patient to another and from one period to another, even for the same epileptic patients. Hence, the testing and evaluation of the seizure prediction algorithm must be conducted on medical cases in real time in order to prove the seizure prediction performance. In conclusion, the solution to the classification problem was evaluated on the basis of the discrimination of preictal state samples from samples of other states to qualify seizure prediction performance in this research work.
In
Table 5, the epileptic seizure prediction performance of the proposed method and is compared with the existing models EESP1, EESP2, and EESP3. The evaluated metrics indicate the performance when discriminating between the preictal and interictal classes, exemplifying seizure prediction performance. The proposed method outperformed the models in
Table 5 and achieved a prediction performance similar to that of the real-time scenario using the Leave-One-Out Cross Validation (LOOCV) method during training. The comparative baseline models and EESP research used k-fold cross-validation and train–test split to evaluate the CHB-MIT, Bonn, and NSC EEG datasets.
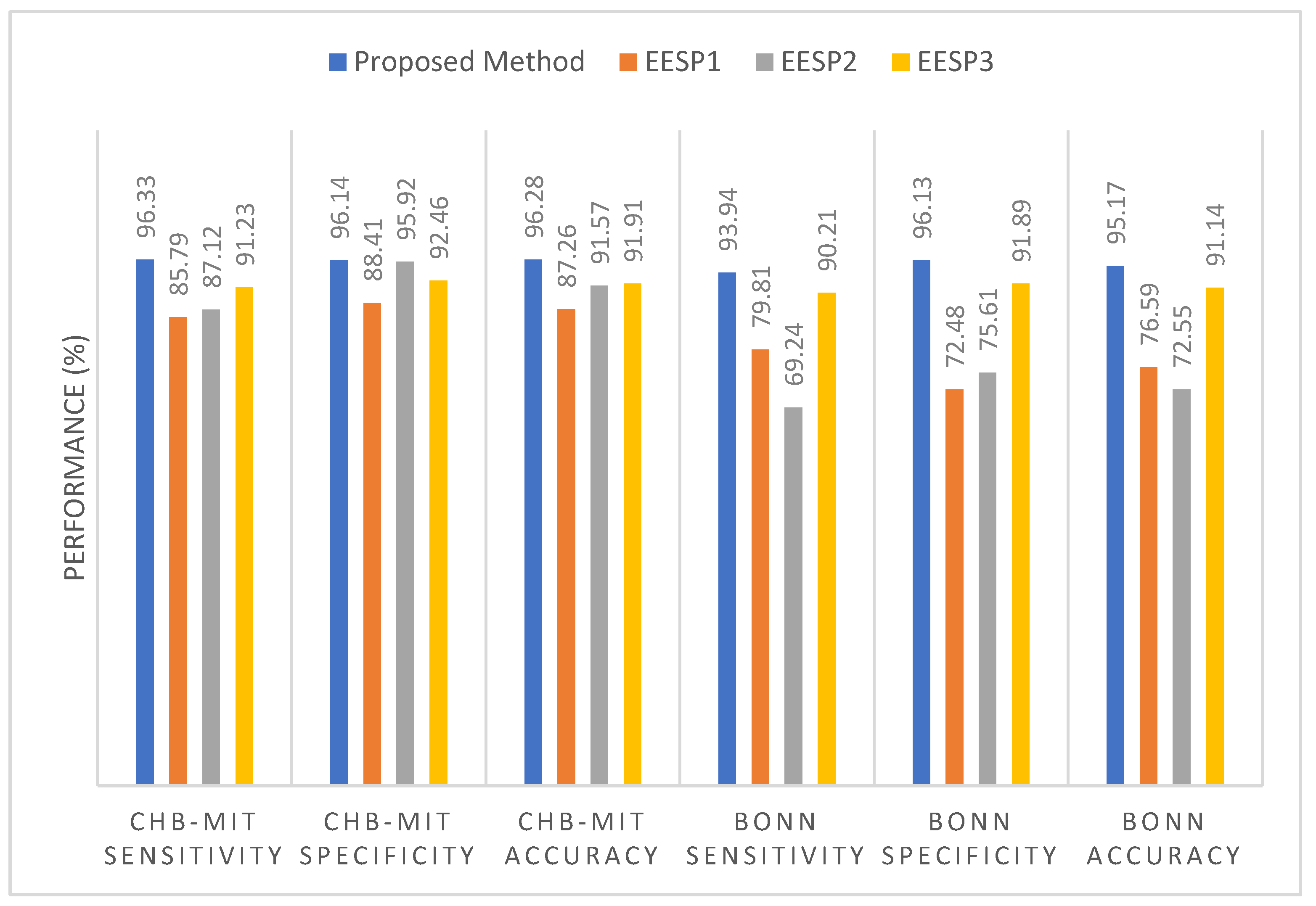
Figure 9 illustrates the comparative sensitivity, specificity, and accuracy of the proposed siezure prediction system with the existing works EESP1, EESP2, and EESP3 on both the CHB-MIT and Bonn EEG datasets. The baseline classifiers of the KNN, Decision Tree, and SVM algorithms had a sensitivity of 54.16%, 82.19%, and 89.39%, respectively, when distinguishing the preictal state from the interictal state while evaluating the CHB-MIT dataset. Under the scenario with the same number of patients and samples, our proposed method outperformed the CNN and LSTM deep learning models, with an accuracy that was 11.46% and 6.8% higher, respectively. Compared to EESP1 on the CHB-MIT dataset, the proposed method obtained a 10.54% higher sensitivity and comparatively minimal false positive rate of 0.094. The sensitivity and specificity of our method were comparatively higher than those of other models, and worked while being tested on two EEG datasets, as depicted in
Figure 9. Moreover, the proposed approach yielded accuracies of 96.28% and 95.17% on the CHB-MIT and Bonn datasets, respectively, which are 4.37% and 4.03% higher than when using the EESP3 approach.
In
Figure 9, the true positive rate and true negative rate were examined in order to validate the performance of the seizure prediction algorithm at detecting the preictal and interictal classes, whereby the assessment of the accuracy metric significantly illustrates the accurate categorization of both epilepsy classes. However, accuracy is not a good metric for assessing the performance of algorithms on the imbalanced data samples in each class. To resolve this, relative accuracy is used to comparatively assess the performance of the seizure prediction algorithm across imbalanced samples with respect to accuracy and baseline values, as illustrated in
Figure 10. In the CHB-MIT dataset, the proposed approach obtained a relative accuracy of 12.87% for an accuracy of 96.28%, which is comparatively higher than the existing works EESP1, EESP2, and EESP3.
As presented in
Table 5, when using the proposed approach on the Bonn EEG dataset, an average sensitivity of 93.94% and an average FPR of 0.044 were obtained. The overall sensitivity, specificity, and accuracy on the NSC dataset reached 91.11%, 94.24%, and 92.72%, respectively. Thus, the proposed model was able to accurately categorize preictal and interictal seizure states in the Bonn and NSC datasets and preictal and ictal seizure states in the CHB-MIT dataset. It can be seen from
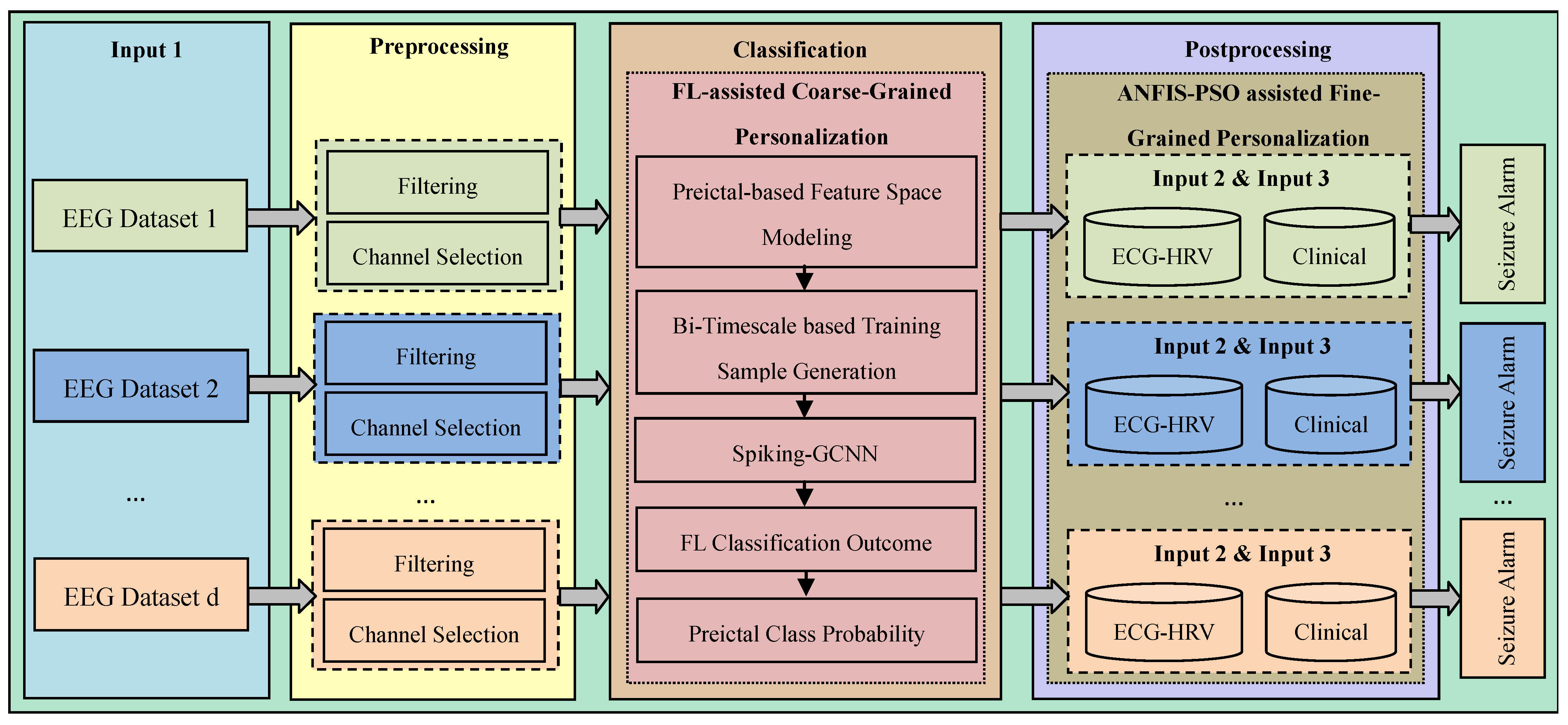
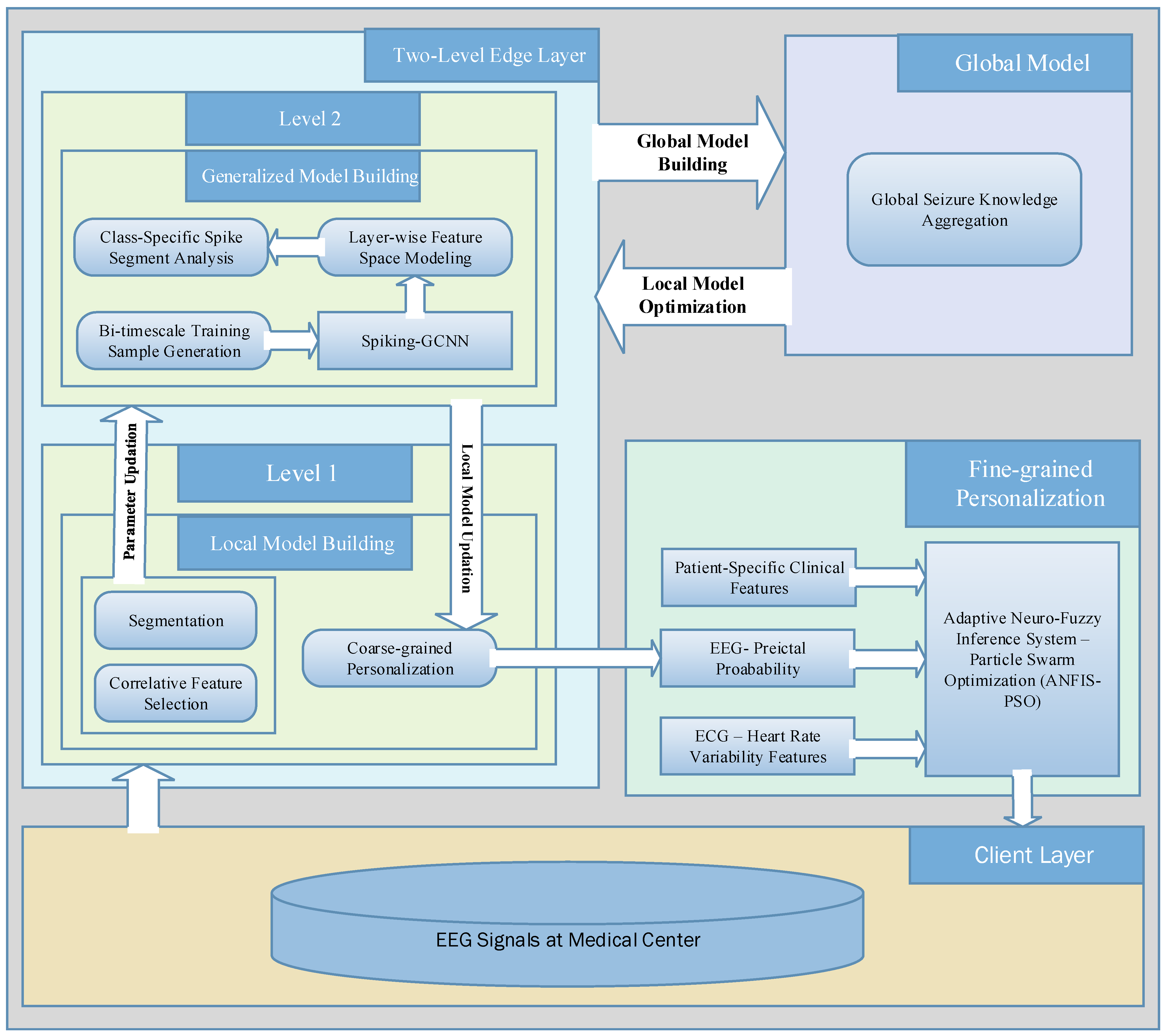
Table 5 that better results were obtained using the proposed method than when using the other methods. Even though EESP3 achieved a true negative rate of 95.23%, which is comparatively higher than the proposed method, the accuracy of the proposed prediction model outperformed that of the existing research by improving the true positive rate. All methods were evaluated on three publicly available EEG benchmark datasets, CHB-MIT, Bonn, and NSC, locally and globally using the FL concept. Deciding which model is better for predicting epileptic seizure is an arduous task due to each method needing to be tested using the limited data of different patients on different datasets. Hence, the generalizability of the proposed method is tested without the need for patient-specific clinical data and ECG data, with reference to the proposed method without using the ANFIS-PSO model, that is, the proposed method using SE, GCNN, and FL.
Furthermore, it is evident from
Table 6 that the combination of the SE, GCNN, FL, and ANFIS-PSO-based epileptic siezure prediction systems provides higher sensitivity of 96.33% and a higher specificity of 96.14% for the CHB-MIT dataset. Additionally, the sensitivity and specificity achieved on the Bonn and NSC datasets are 93.94% and 96.13%, and 91.11% and 94.24%, respectively. As a result, it can be concluded that the recognition of the preictal state was accurately achieved, through the discrimination either of the ictal state, in the case of the CHB-MIT dataset, or of the interictal state, in case of the the Bonn and NSC datasets. However, there is a marginal variation in the performance measures on different EEG datasets, even when the global model parameters are utilized in the proposed method for updating the local model, due to the variations in time definitions, patients, and epileptic patterns. By examining the performance of the baseline models and existing works presented in
Table 6, it is quite apparent that the proposed method yields better results in epileptic seizure prediction on the three different datasets.
Compared to accuracy and specificity, measuring the performance of the detection of the preictal class is extremely important in this research, and sensitivity is a significant measure when validating the epileptic seizure prediction method. Recognition of the preictal state, rather than detecting the interictal and ictal states, is the most crucial process in accurately predicting seizure occurrence, due to the necessity of initializing the warning before the occurrence of a seizure.
Table 6 provides a comparison of the performance of the proposed method when using the centralized and federated approaches. In this research, training using a centralized approach consisted of the learning or processing of one EEG dataset at a time, followed by gradient computation and weight updating. Conversely, the federated approach consisted of processing three EEG datasets at once, followed by averaging the weights of the clients.
By introducing the FL in combination with the SE-GCNN model, this work obtained improvements of 1.56% and 0.51% in sensitivity and specificity, respectively, when testing on the CHB-MIT dataset. This enhancement was due to the adoption of the FL model as the global model and the segment-aware generation of the training sample in the proposed system, facilitating the discrimination between the preictal and interictal states. As mentioned in
Table 6, the centralized approach had the worst sensitivity, specificity, accuracy, and false positive rate among the proposed models. Consequently, the FL model was adopted for the learning process in the proposed epileptic seizure prediction system. Moreover, the proposed system used the ANFIS model in the postprocessing stage, and the results were influenced by the SE, GCNN, and FL models. As a result, the performance of the proposed model demonstrated an increased sensitivity of 96.33%, an increased specificity of 96.14%, and an increased accuracy of 96.28% for the CHB-MIT dataset, as shown in
Table 5. The false positive rate also decreased to 0.032. During postprocessing, the ANFIS-PSO model was tested with different combinations of input data, such as (i) EEG and ECG, (ii) EEG and demographic, and (iii) EEG, ECG, and demographic. The combination of EEG, ECG, and demographic was shown to outperform the other two cases, achieving 91.11% sensitivity and 94.24% specificity on the NSC dataset.
Moreover,
Table 7 presents the performance of the proposed method and EESP2 for each of the individual patients or subjects comprising the CHB-MIT dataset. Among all of the patients in the CHB-MIT dataset, few accomplish comparatively best results; for example, patient CHB03 achieved the highest performance, with a sensitivity of 98.27%, an accuracy of 96.09%, and an FPR of 0.071. In the seizure prediction system, the improvement of all of the metrics, including sensitivity, specificity, FPR, and accuracy, was significant. From the analysis presented in
Table 7, the average of the specificity results for the different patients using the proposed method is 91.24%. The proposed epileptic siezure prediction system using SE-GCNN and the FL model enforces a minimal false positive rate due to the spiking-sequence-based graph construction and the influence of the local model being updated on the basis of generalized patterns. Moreover, the HRV features of seizure activity accompanied by the EEG-based prediction probability greatly facilitates the achievement of higher sensitivity, with 89.84% being achieved across all patients. The performance presented in
Table 7 illustrates that the proposed method ensures stability and maintains the trade-off between the accuracy achieved across all patients and that for a single patient.
The ROC curves and AUC scores of the proposed model when tested on three benchmark datasets are plotted in
Figure 11.
Figure 11 shows that the proposed model can discriminate the preictal samples from the interictal and ictal samples in all three CHB-MIT, Bonn, and NSC datasets. The implementation of the FL model using a three-tier architecture greatly assists the epileptic seizure prediction system in achieving better AUC scores, with 0.896, 0.932, and 0.923 being achieved on the different EEG datasets by updating the local models with the influence of the global model parameters. As a result, the overall ROC-AUC analysis demonstrates the contribution of the proposed method in terms of ensuring the accurate real-time prediction for all of the generalized seizure patients by implementing FL-assisted coarse-grained personalization and ANFIS-assisted fine-grained personalization modeling.
Figure 12 illustrates the ROC curve and the AUC score for each patient when tested on the five patients comprising the CHB-MIT dataset. From the analysis of
Figure 11 and
Figure 12, it can be determined that the proposed epileptic siezure prediction system achieved higher AUC scores, and thus is able to provide accurate seizure predictions for all of the patients, in a patient-specific manner. Among the five epileptic patients tested, the proposed approach was able to accurately predict an epileptic seizure for patient CHB03 with an AUC score of 0.961 on the basis of the discrimination of the preictal state from the ictal samples.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}