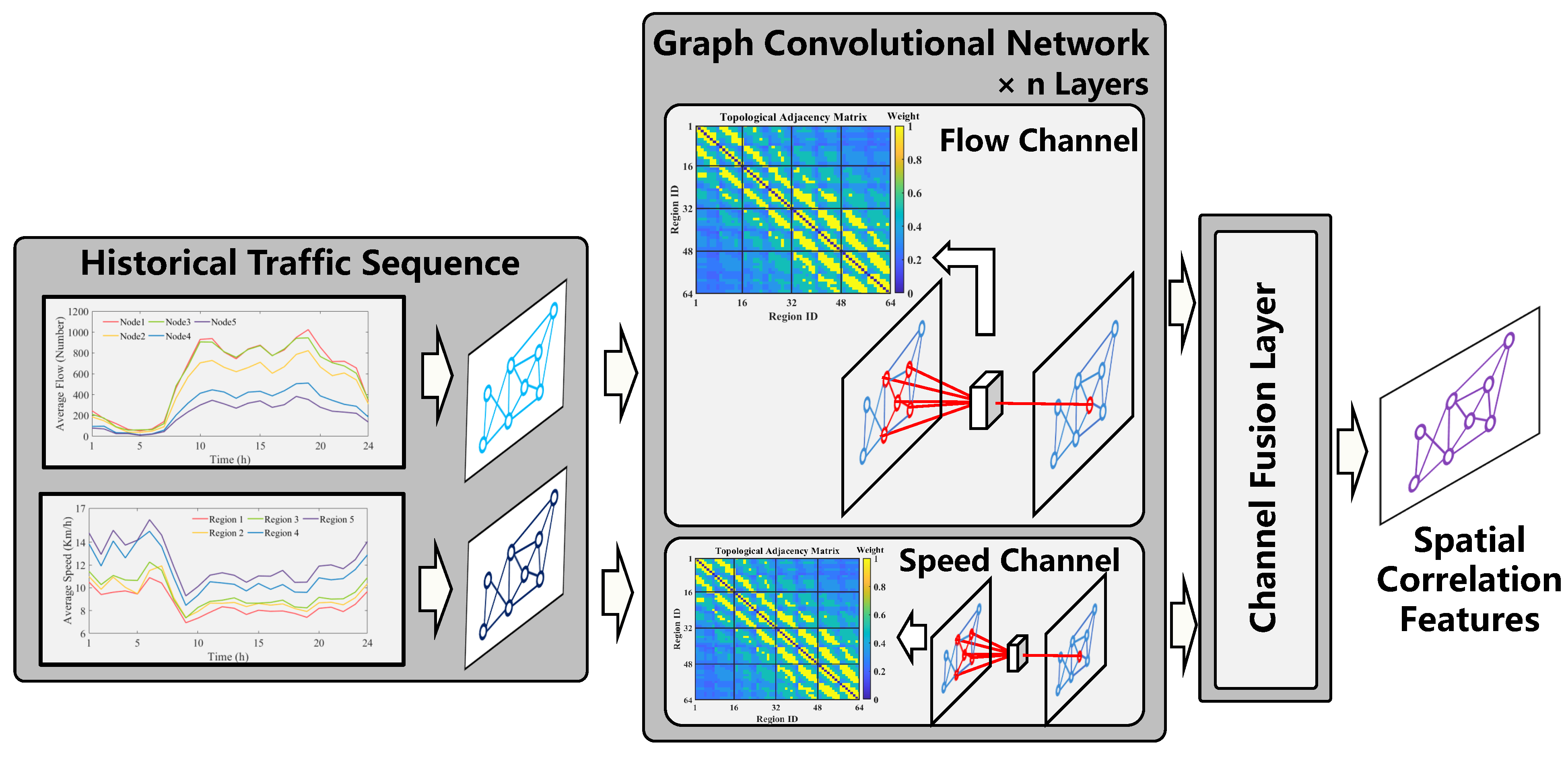
3.2.3. Temporal Correlation Modeling
In this paper, the constructed Graph Transformer is used to extract the temporal-related characteristics of traffic data. Its architecture is shown in
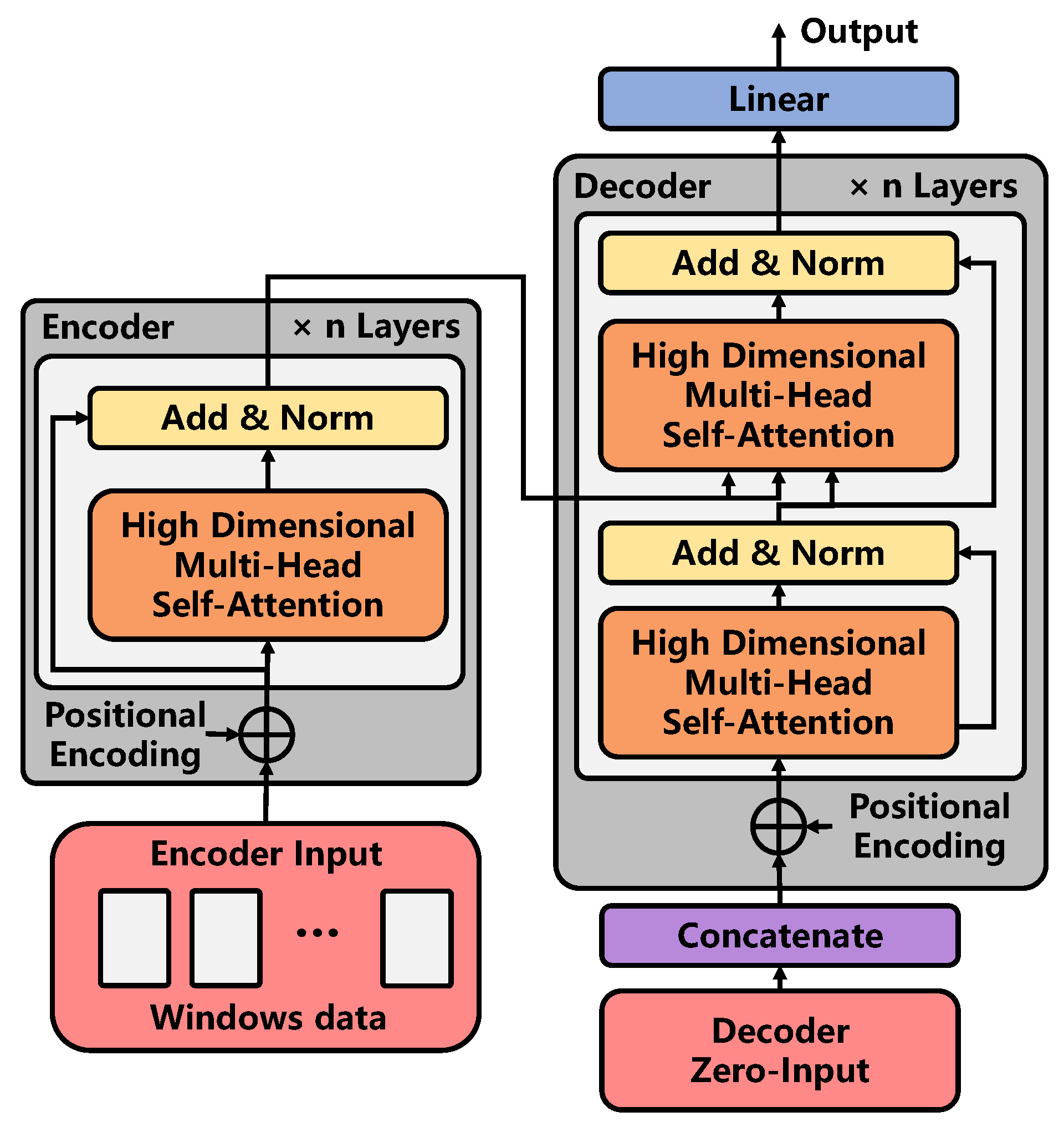
Figure 7. Graph Transformer is composed of an encoder and a decoder. It is based on the improvement of the traditional Transformer. The improvement mainly consists of the following parts:
In conclusion, this paper does not make many improvements to the excellent structure of the Transformer. However, it focuses on the input form of each sub-feature extraction unit and decoder in the structure. The following will be introduced respectively from the Graph Transformer architecture: high-dimensional self-attention mechanism and zero-occupation input of the decoder.
Graph Transformer Architecture:
The architecture of the graph transformer, such as neural transformation models including the Transformer, has an encoder–decoder structure. Here, the encoder maps the high-dimensional historical features of nodes extracted by the Multi-Channel GCN layer to the continuous representation . Here, represents the embedded characteristic dimension of the node. Given z, the decoder is input to the matrix spliced by a partial historical feature embedding matrix and zero-occupation matrix, so as to realize the output of the spatial-temporal characteristics at the future time in one step.
Encoder: The encoder is composed of a stack of
identical layers. Each layer contains a high-dimensional autonomous willpower mechanism. We use the residual connection between different layers, and then normalize the layers. The calculation formula is as follows:
where
and
represent the input and output node characteristics of the sub-layer of the layer
k, respectively.
represents the high-dimensional self-attention mechanism, as shown in this section. In order to facilitate residual connection, all sub-layers and embedded layers in the model maintain dimensions
and
represents layer normalization functions.
Decoder: The decoder is also composed of
stacks of the same layer. In addition to the layer in the encoder, a second layer is inserted, which performs a multi-head attention mechanism on the output of the encoder stack, which is shown in Equation (
13). Similar to the encoder, residual connections are used between each layer, and then, layer normalization is performed. Similar to Transformer, we modify the self-attention layer in the decoder stack to prevent locations from focusing on subsequent locations. This mask, combined with output embedding, ensures that the prediction of
i locations can only rely on known outputs with locations smaller than
i.
where
is the output of the decoder,
represents the intermediate variable in the decoder,
denotes the output characteristics of the encoder at the last layer,
indicates the zero-occupation input of the decoder, see for details in [
30]. The second layer inserted is a high-dimensional attention mechanism
, see below for details.
After the decoder completes the extraction of the temporal feature, the feature data are input to the linear layer to complete the mapping of the feature to all node grades. The calculation process is shown as follows:
where
represents ReLU activation function,
and
represents the mapping weight and offset of the layer, respectively.
is the number of stacked linear layers. Finally, the characteristics of all roads at various grades
are output.
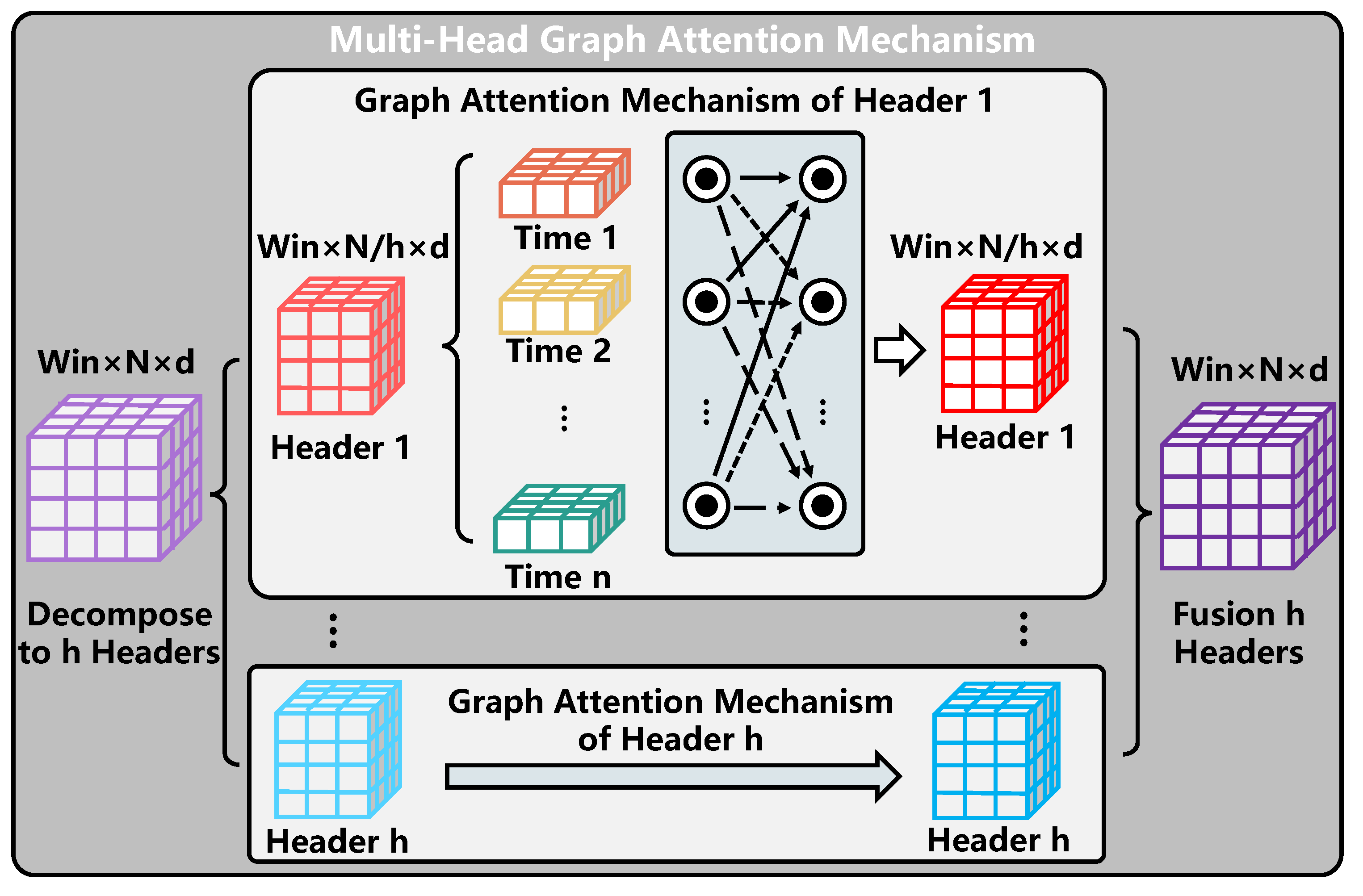
High-dimensional Self-Attention Mechanism:
The conventional multi-head self-attention mechanism obtains the relative relationship between elements through the dot product so that the relative relationship between elements is completely preserved in the feature extraction process of the sequence, and all elements are processed in parallel in the calculation process to improve the calculation efficiency. Considering the high number of features of elements in the sequence, parallel computing in the form of multiple heads can extract the relationship between elements in the sequence from different angles and further increase computational efficiency. Therefore, the multi-head self-attention mechanism is widely used in the feature extraction of sequences.
In this paper, the spatial feature sequence extracted by GCN in different time windows is taken as the input, and each element in the sequence represents the spatial feature in this window. The fusion and feature extraction of spatial features in different time windows are completed using the self-attention mechanism to capture the temporal correlation among them. However, compared with the input data of the conventional self-attention mechanism, the combined sequence of different spatiotemporal features in this paper has a higher dimension. Specifically, compared with the input data of the normal multi-head voluntary mechanism, the input data of the high-dimensional multi-head self-attention mechanism are in the form of a two-dimensional matrix, which increases the dimension of the number of roads. Therefore, this paper improves the conventional attention mechanism and designs a high-dimensional multi-head self-attention mechanism, which is shown in
Figure 8. The specific calculation process is as follows.
We first define the matrix of query, key, and value (
,
and
), and then obtain three functional matrices by performing a linear transformation on the second dimension (i.e., node number dimension) of the embedded traffic data
and decomposing it into multiple heads, as shown in Equation (
15).
where
,
, and
represent the learnable parameter matrix,
h is the number of headers, and
is the header splitting operation of the matrix, that is, the size is converted from
to
. In addition,
,
, and
represent the three functional matrices corresponding to the
i-th header obtained through linear mapping and the splitting operation, respectively.
Then, we further use the dot product attention operation to represent the high-dimensional self-attention layer, as shown in the following.
where
represents the normalized weight matrix between combination
t and combination
,
, and the second dimension is equal to
.
represents the characteristic matrix under the
i-th header. Finally, the final output of the high-dimensional multi-head self-attention mechanism is obtained by splicing and linear mapping of all Matrices corresponding to all header matrices.
The difference between the high-dimensional attention mechanism
and the high-dimensional self-attention mechanism is reflected in the input. The query, key, and value of the high-dimensional attention mechanism can be different inputs. Three functional matrices can be obtained by performing a linear transformation on the second dimension (i.e., node number dimension) of different traffic-embedded data
and decomposing them into multiple heads, as shown in the formula below.
After the linear mapping operation, the corresponding Q, K, V matrices are obtained. The following operations are the same as the above self-attention mechanism and will not be repeated.
Decoder Zero-occupation Input:
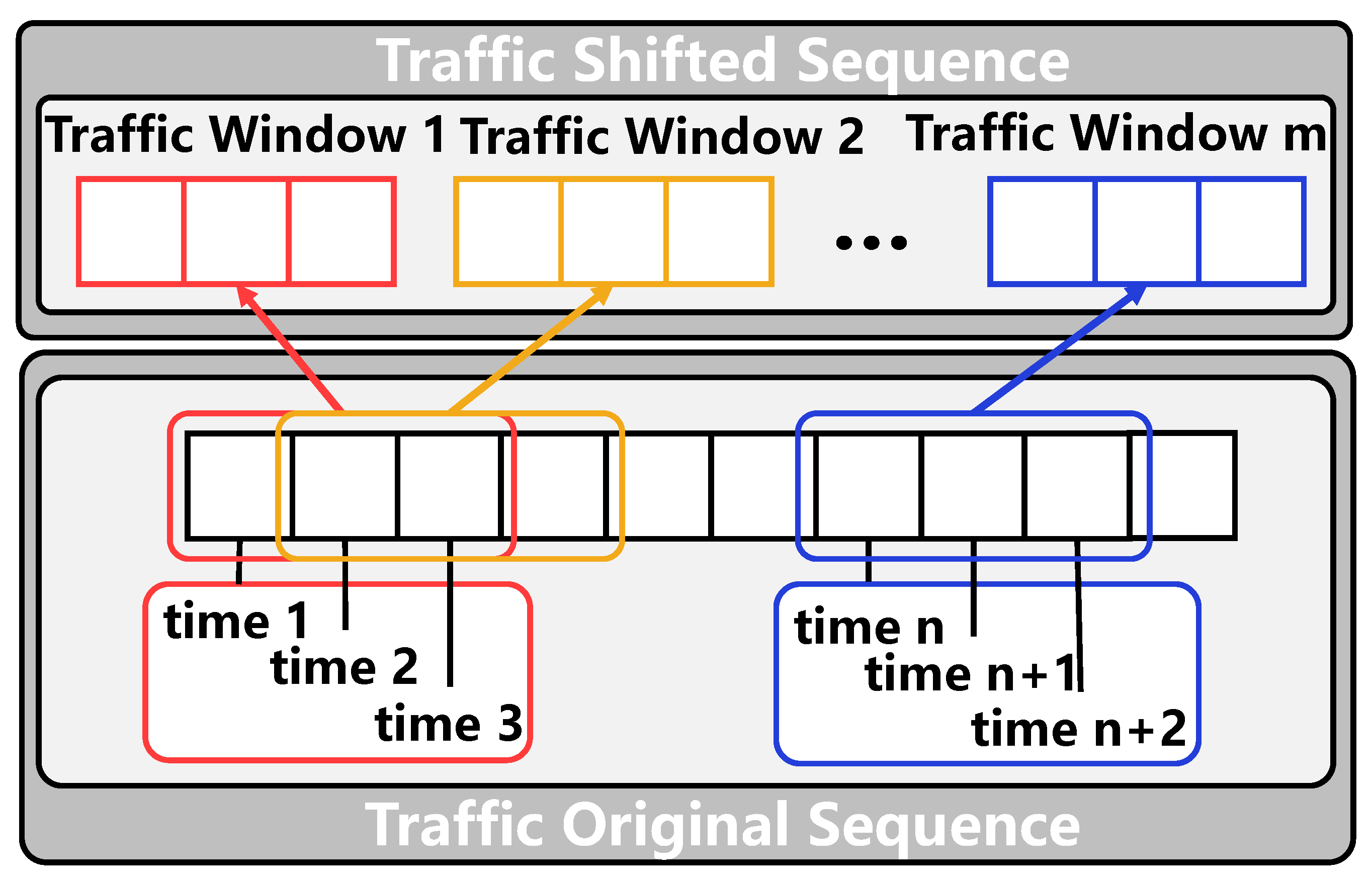
Because the traditional Seq2Seq architecture performs multi-step prediction through continuous self-regression in the decoding process, which reduces the calculation speed in the prediction process. Referring to the experience obtained by the Informer [
30], similarly, we concatenate some historical features with zero vectors as the input of the decoder, as shown in the following.
where
is the starting token and
is the placeholder of the target sequence (set the scalar to 0), which equals the number of the prediction length. The starting token is a sequence of length sampled from the encoder input sequence, which corresponds to a segment before the prediction time. This paper takes the prediction of the next 1 h as an example, the sequence input to the encoder is the node characteristic sequence of five historical time periods. We take the last two time periods of the sequence as the starting token, namely
, and input
to the decoder. Note that the decoder here predicts all outputs in one step, and does not need time-consuming “dynamic decoding” transactions in the ordinary encoder–decoder architecture, which greatly reduces the calculation time.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}