
Robust Estimation and Optimized Transmission of 3D Feature Points for Computer Vision on Mobile Communication Network



Abstract
:1. Introduction
- A new method for 3D keypoint estimation with 3D coordinates from 2D videos without using 3D information such as disparity, depth, 3D mesh, and 3D point cloud;
- A new stereo matching algorithm using the correspondence of a descriptor generated from a SIFT-based 2D keypoint between continuous 2D frames;
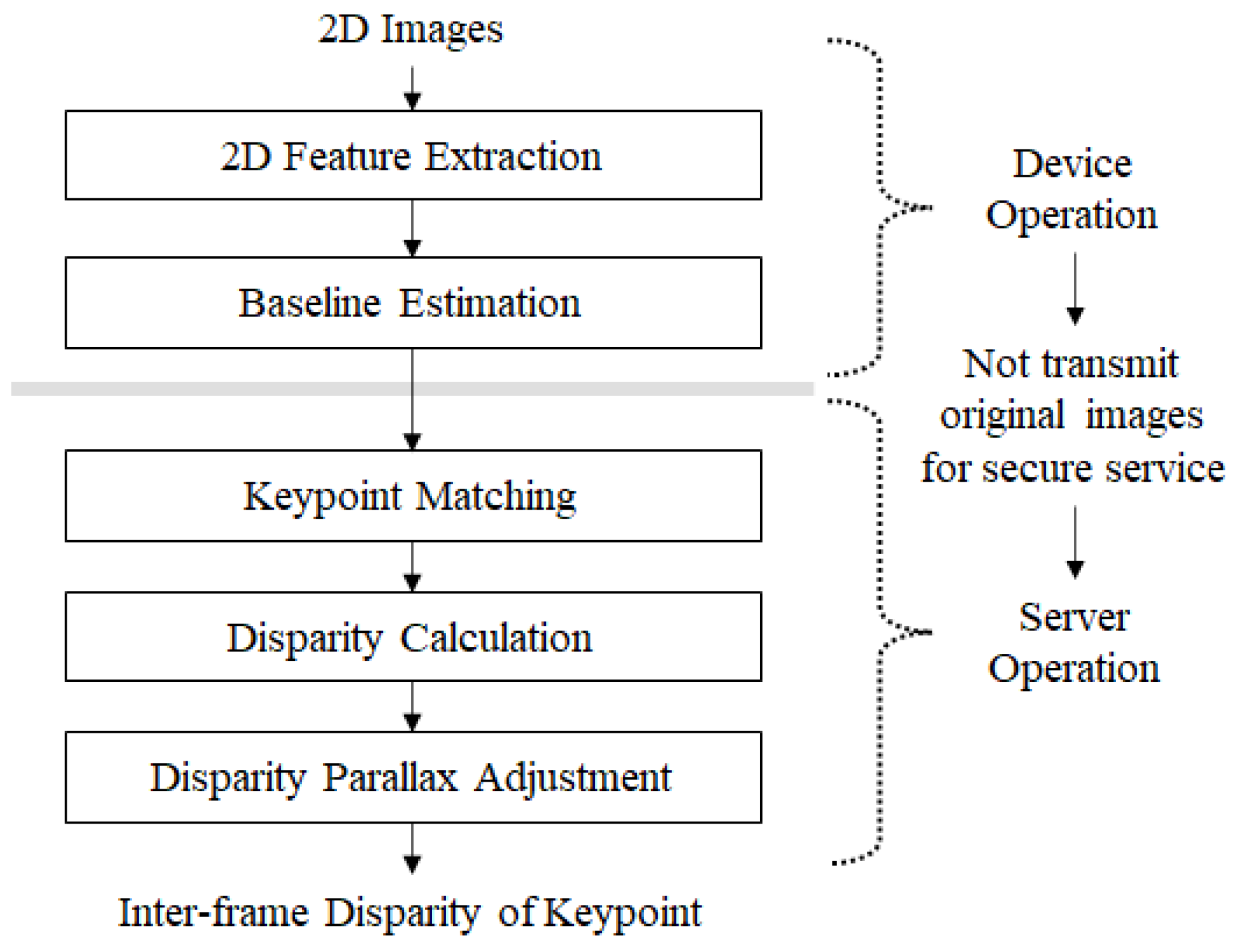
- An AR service with security that does not transmit the user’s private and personal image to the server, instead dealing with 2D keypoints that do not contain real feature information;
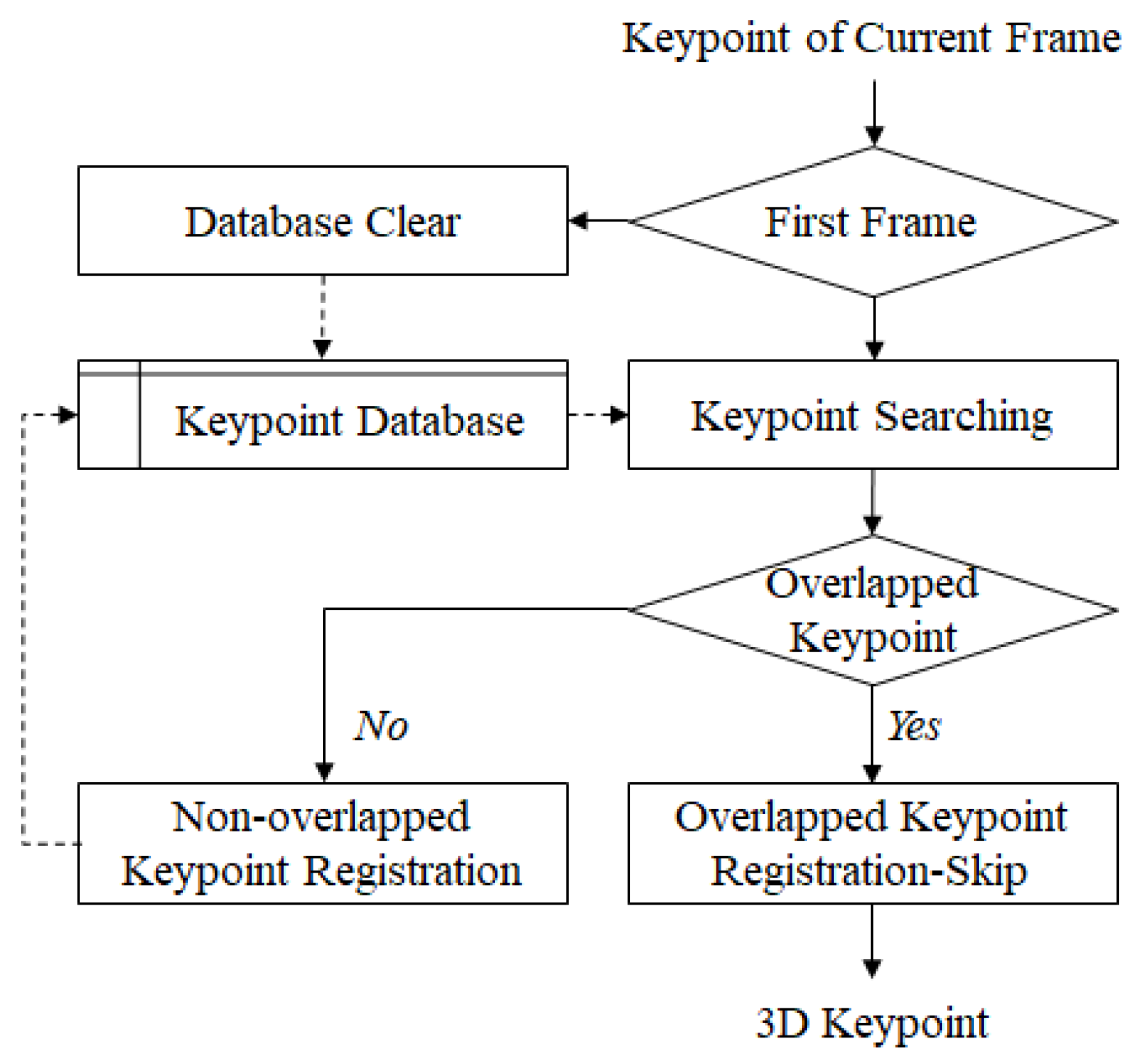
- Efficient database management and minimized data transmission using 2D keypoint overlapping and scene change detection between continuous frames.
2. Related Works
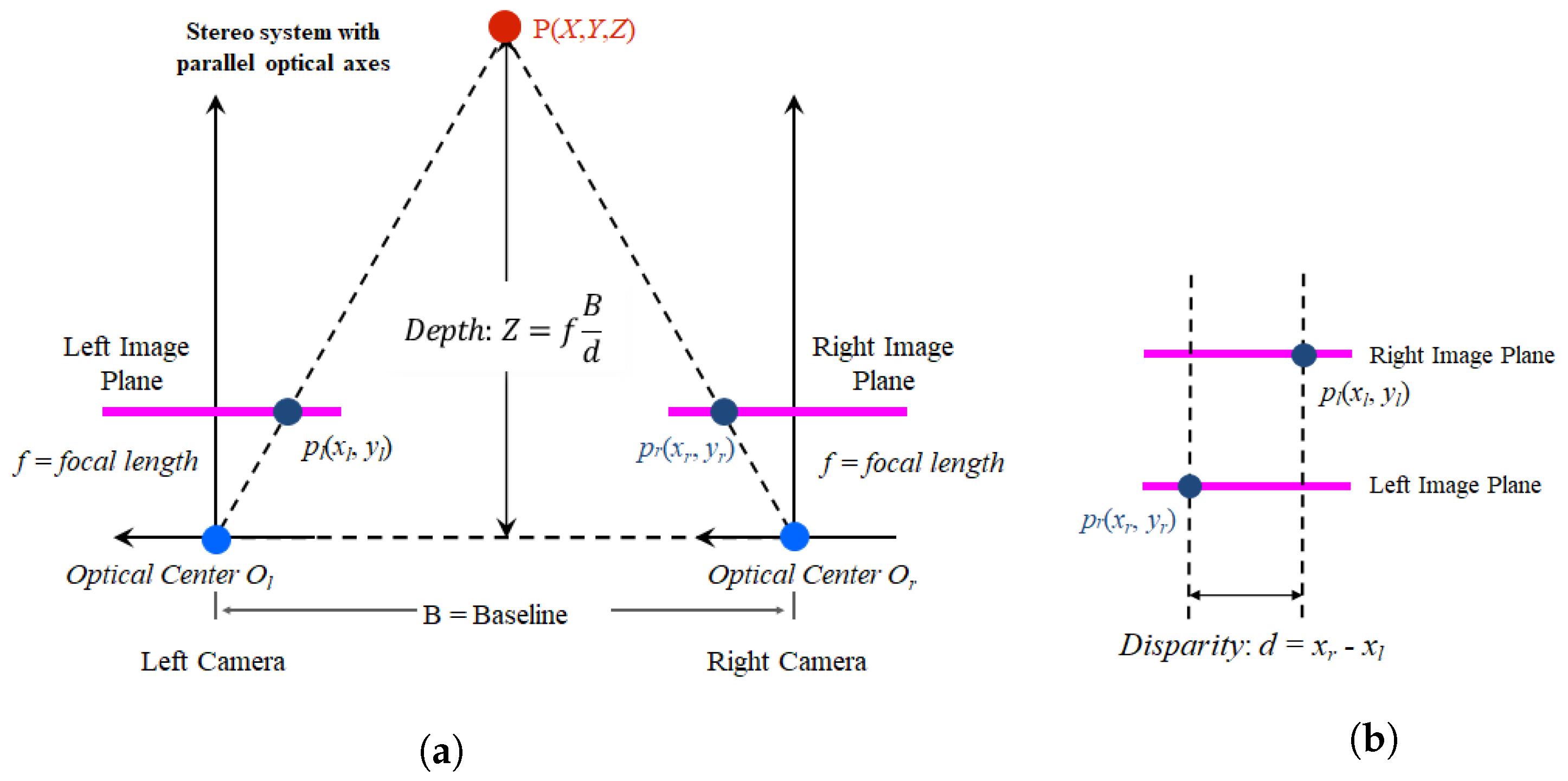
2.1. Stereo Matching
2.2. Feature Extraction
3. 3D Feature Extraction
3.1. Full Process
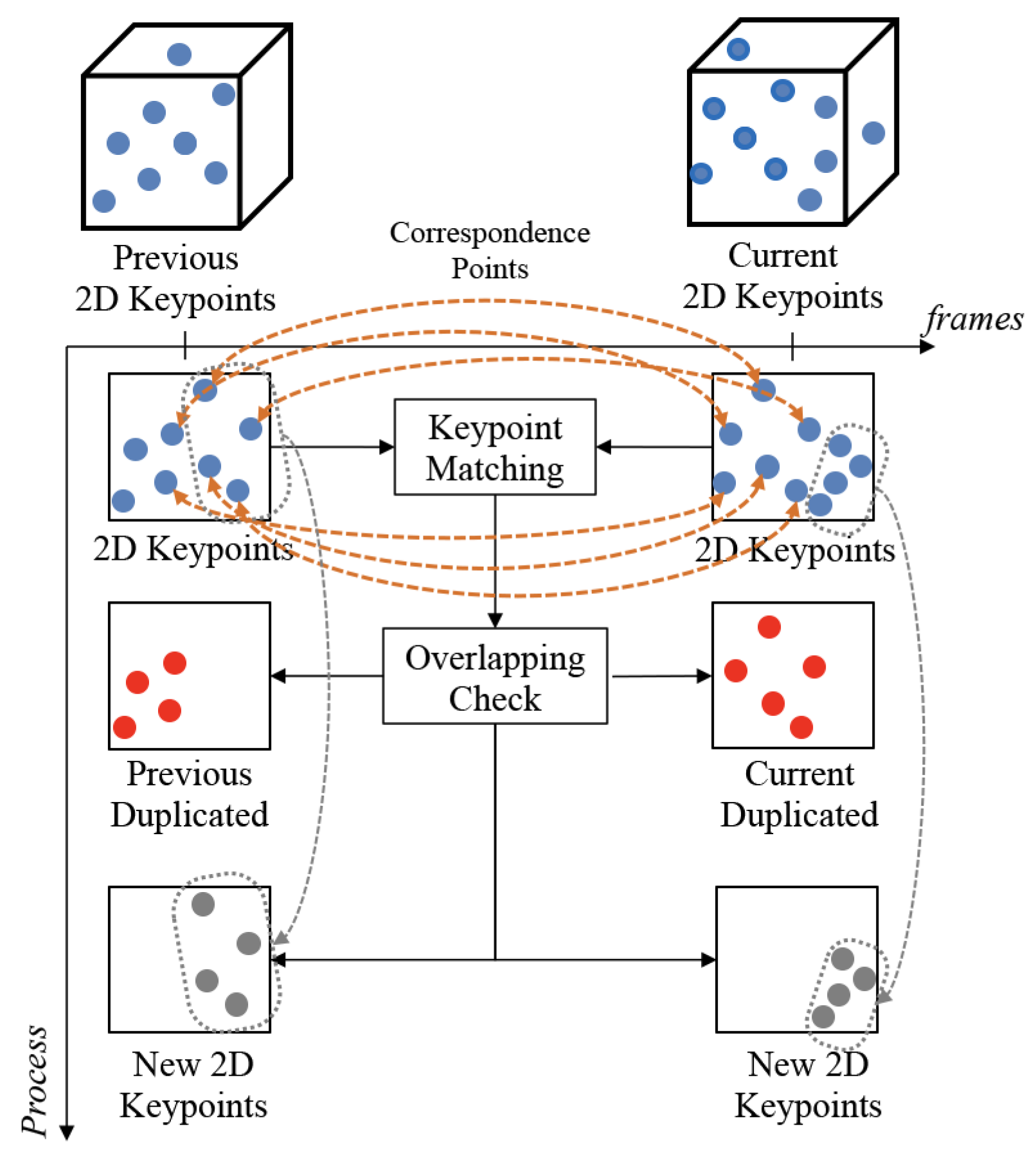
3.2. Keypoint-Based Stereo Matching
3.3. Scene Change Detection
3.4. Keypoint Updating
3.5. 3D Keypoint Generation
4. Experimental Results
4.1. Baseline Calculation
4.2. Result of Keypoint-Based Stereo Matching
4.3. Keypoint Update Result
4.4. Result of Scene Change
4.5. Comparison of Results with TUM Dataset
4.6. Performance Comparison with Previous Study
4.7. Ablation Study
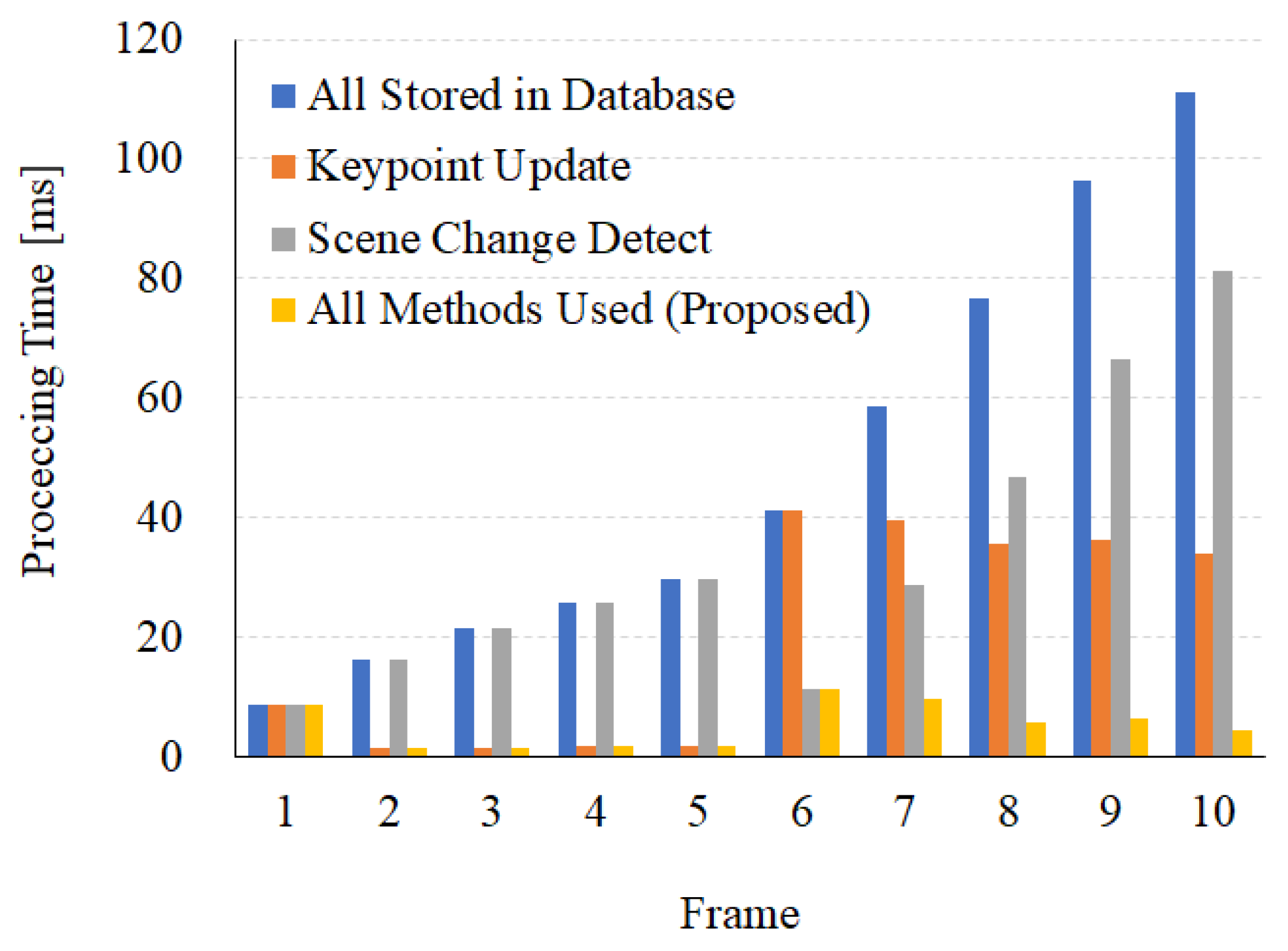
4.7.1. Processing Time
4.7.2. Search Range
4.7.3. Baseline Distance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sipiran, I.; Bustos, B. Harris 3D: A robust extension of the Harris operator for interest point detection on 3D meshes. Vis. Comput. 2011, 27, 963–976. [Google Scholar] [CrossRef]
- Sun, J.; Ovsjanikov, M.; Guibas, L.J. A Concise and Provably Informative Multi-Scale Signature Based on Heat Diffusion. Comput. Graph. Forum 2009, 28, 1383–1392. [Google Scholar] [CrossRef]
- Castellani, U.; Cristani, M.; Fantoni, S.; Murino, V. Sparse points matching by combining 3D mesh saliency with statistical descriptors. Comput. Graph. Forum 2008, 27, 643–652. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.H.; Varshney, A.; Jacobs, D. Mesh Saliency. ACM Trans. Graph. 2005, 24, 659–666. [Google Scholar] [CrossRef]
- Novatnack, J.; Nishino, K. Scale-Dependent 3D Geometric Features. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Khoury, M.; Zhou, Q.Y.; Koltun, V. Learning Compact Geometric Features. arXiv 2017, arXiv:1709.05056. [Google Scholar]
- Tombari, F.; Salti, S.; Di Stefano, L. Unique Signatures of Histograms for Local Surface Description. In Proceedings of the Computer Vision—ECCV 2010, Crete, Greece, 5–11 September 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 356–369. [Google Scholar]
- Sung, M.; Su, H.; Yu, R.; Guibas, L.J. Deep Functional Dictionaries: Learning Consistent Semantic Structures on 3D Models from Functions. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Cohen, T.S.; Geiger, M.; Koehler, J.; Welling, M. Spherical CNNs. arXiv 2018, arXiv:1801.10130. [Google Scholar]
- You, Y.; Lou, Y.; Liu, Q.; Tai, Y.W.; Ma, L.; Lu, C.; Wang, W. Pointwise Rotation-Invariant Network with Adaptive Sampling and 3D Spherical Voxel Convolution. arXiv 2018, arXiv:1811.09361. [Google Scholar]
- Reddy, N.D.; Vo, M.; Narasimhan, S.G. Occlusion-Net: 2D/3D Occluded Keypoint Localization Using Graph Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7326–7335. [Google Scholar]
- Feng, M.; Hu, S.; Ang, M.H.; Lee, G.H. 2D3D-Matchnet: Learning To Match Keypoints Across 2D Image And 3D Point Cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4790–4796. [Google Scholar]
- Ghorbani, F.; Ebadi, H.; Pfeifer, N.; Sedaghat, A. Uniform and Competency-Based 3D Keypoint Detection for Coarse Registration of Point Clouds with Homogeneous Structure. Remote. Sens. 2022, 14, 4099. [Google Scholar] [CrossRef]
- Minaee, S.; Liang, X.; Yan, S. Modern Augmented Reality: Applications, Trends, and Future Directions. arXiv 2022, arXiv:2202.09450. [Google Scholar]
- Sima, A.A.; Buckley, S.J. Optimizing SIFT for Matching of Short Wave Infrared and Visible Wavelength Images. Remote Sens. 2013, 5, 2037–2056. [Google Scholar] [CrossRef] [Green Version]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Mizuno, K.; Noguchi, H.; He, G.; Terachi, Y.; Kamino, T.; Kawaguchi, H.; Yoshimoto, M. Fast and low-memory-bandwidth architecture of SIFT descriptor generation with scalability on speed and accuracy for VGA video. In Proceedings of the IEEE 2010 International Conference on Field Programmable Logic and Applications, Milano, Italy, 31 August–2 September 2010; pp. 608–611. [Google Scholar]
- Microsoft Research Blog, Envisioning Privacy Preserving Image-Based Localization for Augmented Reality. Available online: https://www.microsoft.com/en-us/research/blog/envisioning-privacy-preserving-image-based-localization-for-augmented-reality/ (accessed on 1 December 2022).
- Radke, R.; Andra, S.; Al-Kofahi, O.; Roysam, B. Image change detection algorithms: A systematic survey. IEEE Trans. Image Process. 2005, 14, 294–307. [Google Scholar] [CrossRef] [PubMed]
- Del Fabro, M.; Böszörmenyi, L. State-of-the-art and future challenges in video scene detection: A survey. Multimed. Syst. 2013, 19, 427–454. [Google Scholar] [CrossRef]
- Qiu, Y.; Satoh, Y.; Suzuki, R.; Iwata, K.; Kataoka, H. Indoor Scene Change Captioning Based on Multimodality Data. Sensors 2020, 20, 4761. [Google Scholar] [CrossRef] [PubMed]
- Jang, C.; Lee, S. Scene Detection for Movies and Dramas Using Primitive Scene Analysis. J. Kiise Comput. Pract. Lett. 2013, 19, 601–605. [Google Scholar]
- Park, J.H.; Park, S.Y.; Kang, S.J.; Cho, W.H. Content-Based Scene Change Detection of Video Sequence Using Hierarchical Hidden Markov Model. In Proceedings of the Discovery Science, Sapporo, Japan, 17–19 October 2003; Grieser, G., Tanaka, Y., Yamamoto, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 426–433. [Google Scholar]
- Yoo, J.H.; Seok, H.S.; Zhang, B.T. Bayesian Filtering for Background Change Detection in TVDramas. Comput. Pract. Lett. 2012, 18, 341–345. [Google Scholar]
- Zhou, X.; Karpur, A.; Gan, C.; Luo, L.; Huang, Q. Unsupervised Domain Adaptation for 3D Keypoint Estimation via View Consistency. arXiv 2017, arXiv:1712.05765. [Google Scholar]
- Wu, W.; Zhang, Y.; Wang, D.; Lei, Y. SK-Net: Deep learning on point cloud via end-to-end discovery of spatial keypoints. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6422–6429. [Google Scholar]
- Suwajanakorn, S.; Snavely, N.; Tompson, J.J.; Norouzi, M. Discovery of Latent 3D Keypoints via End-to-end Geometric Reasoning. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Sydney, Australia, 2018; Volume 31. [Google Scholar]
- He, Y.; Sun, W.; Huang, H.; Liu, J.; Fan, H.; Sun, J. PVN3D: A Deep Point-wise 3D Keypoints Voting Network for 6DoF Pose Estimation. arXiv 2019, arXiv:1911.04231. [Google Scholar]
- Liu, X.; Jonschkowski, R.; Angelova, A.; Konolige, K. Keypose: Multi-view 3d labeling and keypoint estimation for transparent objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11602–11610. [Google Scholar]
- Chen, B.; Abbeel, P.; Pathak, D. Unsupervised Learning of Visual 3D Keypoints for Control. In Proceedings of the 38th International Conference on Machine Learning (PMLR 2021), Virtual, 18–24 July 2021; Meila, M., Zhang, T., Eds.; Volume 139, pp. 1539–1549. [Google Scholar]
- Jakab, T.; Tucker, R.; Makadia, A.; Wu, J.; Snavely, N.; Kanazawa, A. KeypointDeformer: Unsupervised 3D Keypoint Discovery for Shape Control. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12778–12787. [Google Scholar]
- Ge, L.; Ren, Z.; Yuan, J. Point-to-Point Regression PointNet for 3D Hand Pose Estimation. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 489–505. [Google Scholar]
- Wei, M.; Zhu, M.; Wu, Y.; Sun, J.; Wang, J.; Liu, C. A Fast Stereo Matching Network with Multi-Cross Attention. Sensors 2021, 21, 6016. [Google Scholar] [CrossRef]
- Jeon, S.; Heo, Y.S. Efficient Multi-Scale Stereo-Matching Network Using Adaptive Cost Volume Filtering. Sensors 2022, 22, 5500. [Google Scholar] [CrossRef]
- Faugeras, O. Three-Dimensional Computer Vision: A Geometric Viewpoint; MIT Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Jang, M.; Yoon, H.; Lee, S.; Kang, J.; Lee, S. A Comparison and Evaluation of Stereo Matching on Active Stereo Images. Sensors 2022, 22, 3332. [Google Scholar] [CrossRef] [PubMed]
- Chang, J.R.; Chen, Y.S. Pyramid Stereo Matching Network. arXiv 2018, arXiv:1803.08669. [Google Scholar]
- Park, J.M.; Song, G.Y.; Lee, J.W. Shape-indifferent stereo disparity based on disparity gradient estimation. Image Vis. Comput. 2017, 57, 102–113. [Google Scholar] [CrossRef]
- Žbontar, J.; LeCun, Y. Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches. arXiv 2015, arXiv:1510.05970. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-End Learning of Geometry and Context for Deep Stereo Regression. arXiv 2017, arXiv:1703.04309. [Google Scholar]
- Harris, C.G.; Stephens, M.J. A Combined Corner and Edge Detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988. [Google Scholar]
- Mikolajczyk, K.; Schmid, C. Indexing based on scale invariant interest points. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 9–12 July 2001; Volume 1, pp. 525–531. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Hu, J.; Chen, R.; An, Y.; Xiong, Z.; Liu, H. Keypoint-Aware Single-Stage 3D Object Detector for Autonomous Driving. Sensors 2022, 22, 1451. [Google Scholar] [CrossRef]
- Liu, L.; Ke, Z.; Huo, J.; Chen, J. Head Pose Estimation through Keypoints Matching between Reconstructed 3D Face Model and 2D Image. Sensors 2021, 21, 1841. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vision 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Volkmann, N.; Zelenka, C.; Devaraju, A.M.; Brünger, J.; Stracke, J.; Spindler, B.; Kemper, N.; Koch, R. Keypoint Detection for Injury Identification during Turkey Husbandry Using Neural Networks. Sensors 2022, 22, 5188. [Google Scholar] [CrossRef]
- Nurzynska, K.; Skurowski, P.; Pawlyta, M.; Cyran, K. Evaluation of Keypoint Descriptors for Flight Simulator Cockpit Elements: WrightBroS Database. Sensors 2021, 21, 7687. [Google Scholar] [CrossRef]
- Hidalgo, F.; Bräunl, T. Evaluation of Several Feature Detectors/Extractors on Underwater Images towards vSLAM. Sensors 2020, 20, 4343. [Google Scholar] [CrossRef] [PubMed]
- Vijayan, V.; Kp, P. FLANN Based Matching with SIFT Descriptors for Drowsy Features Extraction. In Proceedings of the 2019 Fifth International Conference on Image Information Processing (ICIIP), Shimla, India, 15–17 November 2019; pp. 600–605. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the International Conference on Intelligent Robot Systems (IROS), Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7167–7176. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frame | Overlapped Ratio | Updated Ratio | Total | ||
|---|---|---|---|---|---|
| 1 | - | 0% | 1048 | 100% | 1048 |
| 2 | 645 | 74.56% | 220 | 25.44% | 865 |
| 3 | 754 | 77.33% | 221 | 22.67% | 975 |
| 4 | 394 | 72.70% | 148 | 27.30% | 542 |
| 5 | 270 | 64.74% | 147 | 35.26% | 417 |
| Average | 515.75 | 72.33% | 184 | 27.67% | 700 |
| 1 | 2 | 3 | 4 | 5 | Total | |
|---|---|---|---|---|---|---|
| Min | 0.11 | 0.11 | 0.04 | 0.03 | 0.10 | 0.07 |
| Max | 16.32 | 12.56 | 10.21 | 11.33 | 14.62 | 13.00 |
| Average | 7.45 | 6.10 | 5.78 | 4.37 | 6.21 | 5.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-K.; Park, B.-S.; Kim, W.; Park, J.-T.; Lee, S.; Seo, Y.-H. Robust Estimation and Optimized Transmission of 3D Feature Points for Computer Vision on Mobile Communication Network. Sensors 2022, 22, 8563. https://doi.org/10.3390/s22218563
Kim J-K, Park B-S, Kim W, Park J-T, Lee S, Seo Y-H. Robust Estimation and Optimized Transmission of 3D Feature Points for Computer Vision on Mobile Communication Network. Sensors. 2022; 22(21):8563. https://doi.org/10.3390/s22218563
Chicago/Turabian StyleKim, Jin-Kyum, Byung-Seo Park, Woosuk Kim, Jung-Tak Park, Sol Lee, and Young-Ho Seo. 2022. "Robust Estimation and Optimized Transmission of 3D Feature Points for Computer Vision on Mobile Communication Network" Sensors 22, no. 21: 8563. https://doi.org/10.3390/s22218563