
Synergy Masks of Domain Attribute Model DaBERT: Emotional Tracking on Time-Varying Virtual Space Communication

Abstract
:1. Introduction
- We propose a novel sentiment analysis model for an emotional state personalized analysis that incorporates a time-varying prediction approach to emotional tracking on time-varying virtual space communication. The model uses a multidimensional time-varying prediction model to mine information from the user’s historical posting records, thus extracting the user’s sentiment style and the inner pattern of sentiment change.
- We propose a domain-knowledge-enhanced pre-trained encoder that incorporates external knowledge of word sentiment properties into pre-trained language models. It is helpful to use the encoder to extract the representation vector of the text at each time point.
- Our proposed model can improve the ability to predict the user’s emotional state at the current moment. It also can also enhance the capability of semantic modeling and fine-grained differentiation, which outperform various baseline models on multi benchmark datasets.
2. Related Work
2.1. Sentiment Analysis
2.2. Time-Varying Prediction
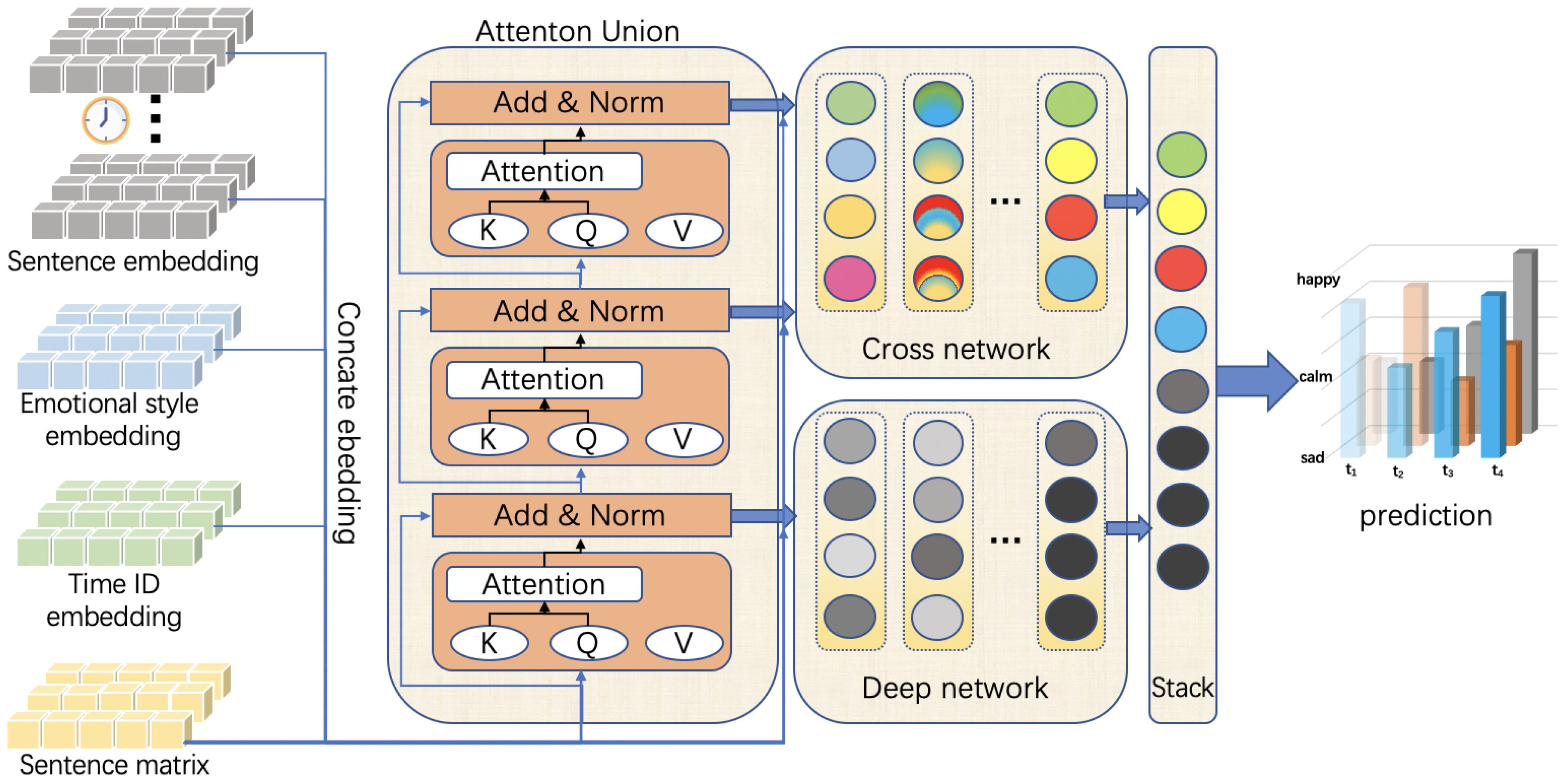
3. Methodology
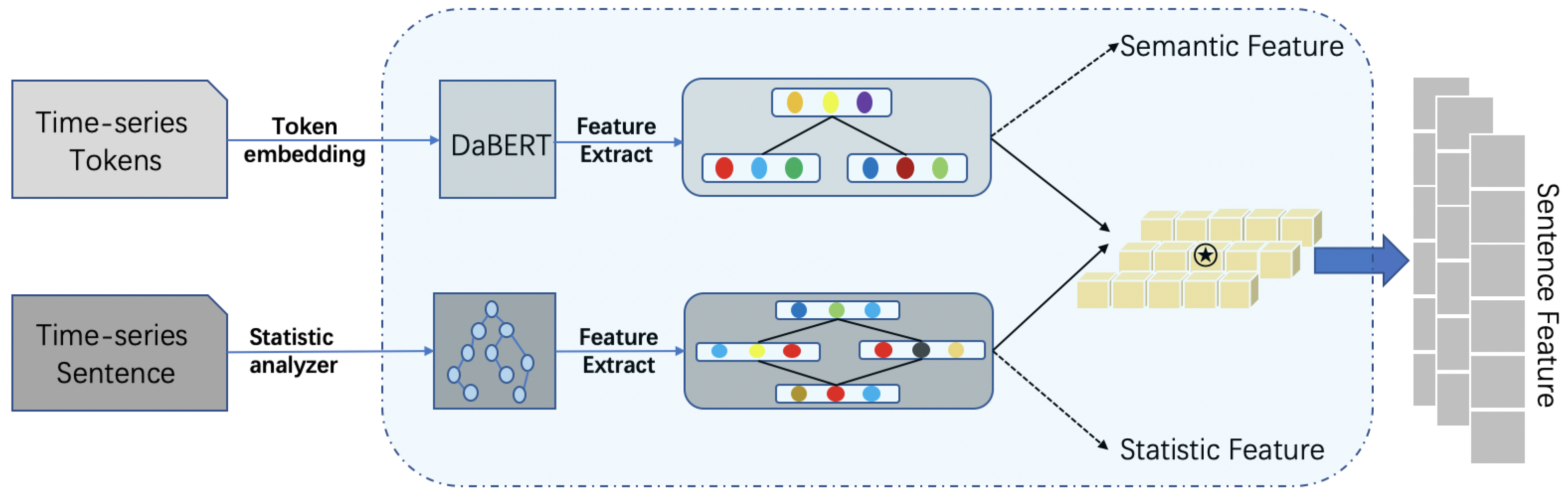
3.1. Domain-Knowledge-Enhanced Pre-Trained Model
- Only_MLM performs only the MLM pre-training task.
- Only_DAM completes only the DAM pre-training task.
- Mix_Separate simultaneously performs the annotation work of DAM and MLM, and the two annotation processes are independent of each other, i.e., the words marked [MASK] may not appear in the domain knowledge lexicon.
- Mix_MLM is annotated with MLM as the primary annotation process, and MLM annotation comes first. If the masked words appear in the domain knowledge lexicon, the corresponding feature attributes are added to the DAM tag sequence.
- Mix_DAM, in contrast to MLM, replaces all words that appear in the domain knowledge lexicon with a [MASK] token. When the number of [MASK] exceeds a certain threshold, some [MASK] are chosen at random to revert to the original words.
- Successive serial training is performed first using the first domain knowledge lexicon for co-training and finally using the second domain knowledge lexicon on the basis of the obtained model parameters.
- Simultaneous parallel training employs multiple domain knowledge dictionaries, each corresponding to a separate DAM model, with a loss function connecting all modules.
- Multi-round mechanism uses just one of the individual DAM modules in each training round.
3.2. Attention-Based Sentiment Time-Varying Prediction Model
- Coarse-grained order sorts the posting records according to the time difference between them and the current moment, from closest to farthest, reflecting the posting’s sequential relationship.
- Fine-grained temporal distances are calculated separately for each text at the time of posting and now, and are marked using time-specific absolute values. This mechanism introduces the text’s absolute time interval distance.
4. Experiments
4.1. Datasets
4.1.1. Sentiment Analysis Based on Time Series Prediction
- To obtain each user’s posting record separately, the raw data were aggregated by user ID.
- The tweet records for each user were sorted by posting time.
- In the experiment, each newly generated record consisted of 1 tweet and n tweets with the most recent posting time, with n set to 8.
4.1.2. Fine-Grained Sentiment Analysis
4.1.3. Domain Knowledge Dictionary
4.2. Implementation Details and Metric
4.3. Automatic Evaluation
- BERT-base: No pre-training in the target task dataset.
- BERT-base + only MLM: Only MLM pre-training task is performed.
- BERT-base + only DAM: Only DAM pre-trainingtask is performed.
- DaBERT: MLM and DAM pre-training tasks are completed.
5. Case Study
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ecemiş, A.; Dokuz, A.Ş.; Celik, M. Temporal Sentiment Analysis of Socially Important Locations of Social Media Users. In Proceedings of the Third International Conference on Smart City Applications, Tetouan, Morocco, 10–11 October 2018; Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–16. [Google Scholar]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification using Machine Learning Techniques. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP 2002), Philadelphia, PA, USA, 6–7 July 2002; pp. 79–86. [Google Scholar]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Bisio, F. Sentic LDA: Improving on LDA with semantic similarity for aspect-based sentiment analysis. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 4465–4473. [Google Scholar]
- Lu, Y.; Mei, Q.; Zhai, C. Investigating task performance of probabilistic topic models: An empirical study of PLSA and LDA. Inf. Retr. 2011, 14, 178–203. [Google Scholar] [CrossRef]
- Lin, C.; He, Y.; Pedrinaci, C.; Domingue, J. Feature lda: A supervised topic model for automatic detection of web api documentations from the web. In Proceedings of the International Semantic Web Conference, Boston, MA, USA, 11–15 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 328–343. [Google Scholar]
- Perotte, A.; Wood, F.; Elhadad, N.; Bartlett, N. Hierarchically supervised latent Dirichlet allocation. Adv. Neural Inf. Process. Syst. 2011, 24. [Google Scholar]
- Muhammad, A.; Wiratunga, N.; Lothian, R. Contextual sentiment analysis for social media genres. Knowl.-Based Syst. 2016, 108, 92–101. [Google Scholar] [CrossRef] [Green Version]
- Akhtar, M.S.; Kumar, A.; Ghosal, D.; Ekbal, A.; Bhattacharyya, P. A multilayer perceptron based ensemble technique for fine-grained financial sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 540–546. [Google Scholar]
- McCann, B.; Bradbury, J.; Xiong, C.; Socher, R. Learned in translation: Contextualized word vectors. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling Long-and Short-Term Temporal Patterns with Deep Neural Networks. In Proceedings of the SIGIR, Ann Arbor, MI, USA, 8–12 July 2018. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Franceschi, J.Y.; Dieuleveut, A.; Jaggi, M. Unsupervised scalable representation learning for multivariate time series. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Sen, R.; Yu, H.F.; Dhillon, I.S. Think globally, act locally: A deep neural network approach to high-dimensional time series forecasting. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Jingying, W.; Shuoqiu, G.; Nan, Z.; Tianli, L.; Tingshao, Z. Chinese mood variation analysis based on Sina Weibo. J. Univ. Chin. Acad. Sci. 2016, 33, 815. [Google Scholar]
- Giachanou, A.; Crestani, F. Tracking sentiment by time series analysis. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 1037–1040. [Google Scholar]
- O’Connor, B.; Balasubramanyan, R.; Routledge, B.R.; Smith, N.A. From tweets to polls: Linking text sentiment to public opinion time series. In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- An, X.; Ganguly, A.R.; Fang, Y.; Scyphers, S.B.; Hunter, A.M.; Dy, J.G. Tracking climate change opinions from twitter data. In Proceedings of the Workshop on Data Science for Social Good, New York, NY, USA, 24–27 August 2014; pp. 1–6. [Google Scholar]
- Ranco, G.; Aleksovski, D.; Caldarelli, G.; Grčar, M.; Mozetič, I. The effects of Twitter sentiment on stock price returns. PLoS ONE 2015, 10, e0138441. [Google Scholar] [CrossRef] [Green Version]
- Shan, Y.; Hoens, T.R.; Jiao, J.; Wang, H.; Yu, D.; Mao, J. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 255–262. [Google Scholar]
- Go, A.; Bhayani, R.; Huang, L. Twitter sentiment classification using distant supervision. CS224N Proj. Rep. Stanf. 2009, 1, 2009. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Asghar, N. Yelp dataset challenge: Review rating prediction. arXiv 2016, arXiv:1605.05362. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Sentiwordnet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Cambria, E.; Poria, S.; Hazarika, D.; Kwok, K. SenticNet 5: Discovering conceptual primitives for sentiment analysis by means of context embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Qin, Y.; Song, D.; Cheng, H.; Cheng, W.; Jiang, G.; Cottrell, G.W. A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction. arXiv 2017, arXiv:1704.02971. [Google Scholar]
- Jin, X.; Yu, X.; Wang, X.; Bai, Y.; Su, T.; Kong, J. Prediction for Time Series with CNN and LSTM. In Proceedings of the 11th International Conference on Modelling, Identification and Control (ICMIC2019), Tianjin, China, 13–15 July 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 631–641. [Google Scholar]
- Li, Y.; Zhu, Z.; Kong, D.; Han, H.; Zhao, Y. EA-LSTM: Evolutionary attention-based LSTM for time series prediction. Knowl.-Based Syst. 2019, 181, 104785. [Google Scholar] [CrossRef] [Green Version]
- Arras, L.; Montavon, G.; Müller, K.R.; Samek, W. Explaining Recurrent Neural Network Predictions in Sentiment Analysis. In Proceedings of the EMNLP 2017, Copenhagen, Denmark, 9–11 September 2017; p. 159. [Google Scholar]
- Ma, Y.; Peng, H.; Khan, T.; Cambria, E.; Hussain, A. Sentic LSTM: A hybrid network for targeted aspect-based sentiment analysis. Cogn. Comput. 2018, 10, 639–650. [Google Scholar] [CrossRef]
- Chen, L.C.; Lee, C.M.; Chen, M.Y. Exploration of social media for sentiment analysis using deep learning. Soft Comput. 2020, 24, 8187–8197. [Google Scholar] [CrossRef]
- Liao, S.; Wang, J.; Yu, R.; Sato, K.; Cheng, Z. CNN for situations understanding based on sentiment analysis of twitter data. Procedia Comput. Sci. 2017, 111, 376–381. [Google Scholar] [CrossRef]
- Alayba, A.M.; Palade, V.; England, M.; Iqbal, R. A combined CNN and LSTM model for arabic sentiment analysis. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Hamburg, Germany, 27–30 August 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 179–191. [Google Scholar]



{kind=link}
{kind=link}
| Model | Accuracy |
|---|---|
| DA-RNN [29] | 0.7613 |
| Bi-LSTM [30] | 0.7719 |
| EA-LSTM [31] | 0.7846 |
| BERT-base | 0.8245 |
| DaBERT | 0.8296 |
| Attn | 0.8471 |
| DaAttn | 0.8503 |
| Model | SST-2(ALL) | SST-2(Root) | SST-5(ALL) | SST-5(Root) |
|---|---|---|---|---|
| RNN [32] | 83.6 | 80.2 | 75.9 | 41.4 |
| LSTM [33] | 85.2 | 82.6 | 80.7 | 42.3 |
| BiLSTM [34] | 86.1 | 84.8 | 83.5 | 45.6 |
| CNN [35] | 85.7 | 85.1 | 84.2 | 46.5 |
| CNN-LSTM [36] | 86.2 | 85.7 | 83.9 | 47.4 |
| BERT-base | 92.7 | 90.9 | 81.3 | 50.4 |
| DaBERT | 94.8 | 92.6 | 85.3 | 53.9 |
| Model | BERT-base | RoBERTa | LSTM | MultiResCNN | DaBERT |
|---|---|---|---|---|---|
| Accuracy | 0.9328 | 0.9331 | 0.9257 | 0.9268 | 0.9461 |
| Model | Accuracy |
|---|---|
| BERT-base | 0.9375 |
| BERT-base + only MLM | 0.9389 |
| BERT-base + only DAM | 0.9491 |
| DaBERT | 0.9567 |
| DaBERT | BERT-Base | Sentiment | Date | Text |
|---|---|---|---|---|
| 0 | 0 | 0 | 2009-05-29 10:56:39 | ’s hair was on fire right now! Ewww it smells |
| 0 | 4 | 0 | 2009-05-29 11:10:19 | Hairspray in hair + lighter&bong = new haircut |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Chen, Z.; Fu, C. Synergy Masks of Domain Attribute Model DaBERT: Emotional Tracking on Time-Varying Virtual Space Communication. Sensors 2022, 22, 8450. https://doi.org/10.3390/s22218450
Wang Y, Chen Z, Fu C. Synergy Masks of Domain Attribute Model DaBERT: Emotional Tracking on Time-Varying Virtual Space Communication. Sensors. 2022; 22(21):8450. https://doi.org/10.3390/s22218450
Chicago/Turabian StyleWang, Ye, Zhenghan Chen, and Changzeng Fu. 2022. "Synergy Masks of Domain Attribute Model DaBERT: Emotional Tracking on Time-Varying Virtual Space Communication" Sensors 22, no. 21: 8450. https://doi.org/10.3390/s22218450