
Shift Pose: A Lightweight Transformer-like Neural Network for Human Pose Estimation

Abstract
:1. Introduction
- An improve residual log-likelihood estimation loss is proposed, and we apply it to 3D human pose estimation.
- Our model is competitive with the heatmap-based model and even better than heatmap-based model for indicating AP50.
- We first find that, with a restricted number of parameters, the lightweight model tends to learn the x- and y-coordinates as priority in 3D human pose estimation, which points toward the direction to improve the performance of future lightweight models in 3D human pose estimation.
2. Relative Work
2.1. Regression-Based HPE
2.2. Lightweight Model
2.3. Transformer
2.4. Real-Time Human Pose Estimation
3. Method
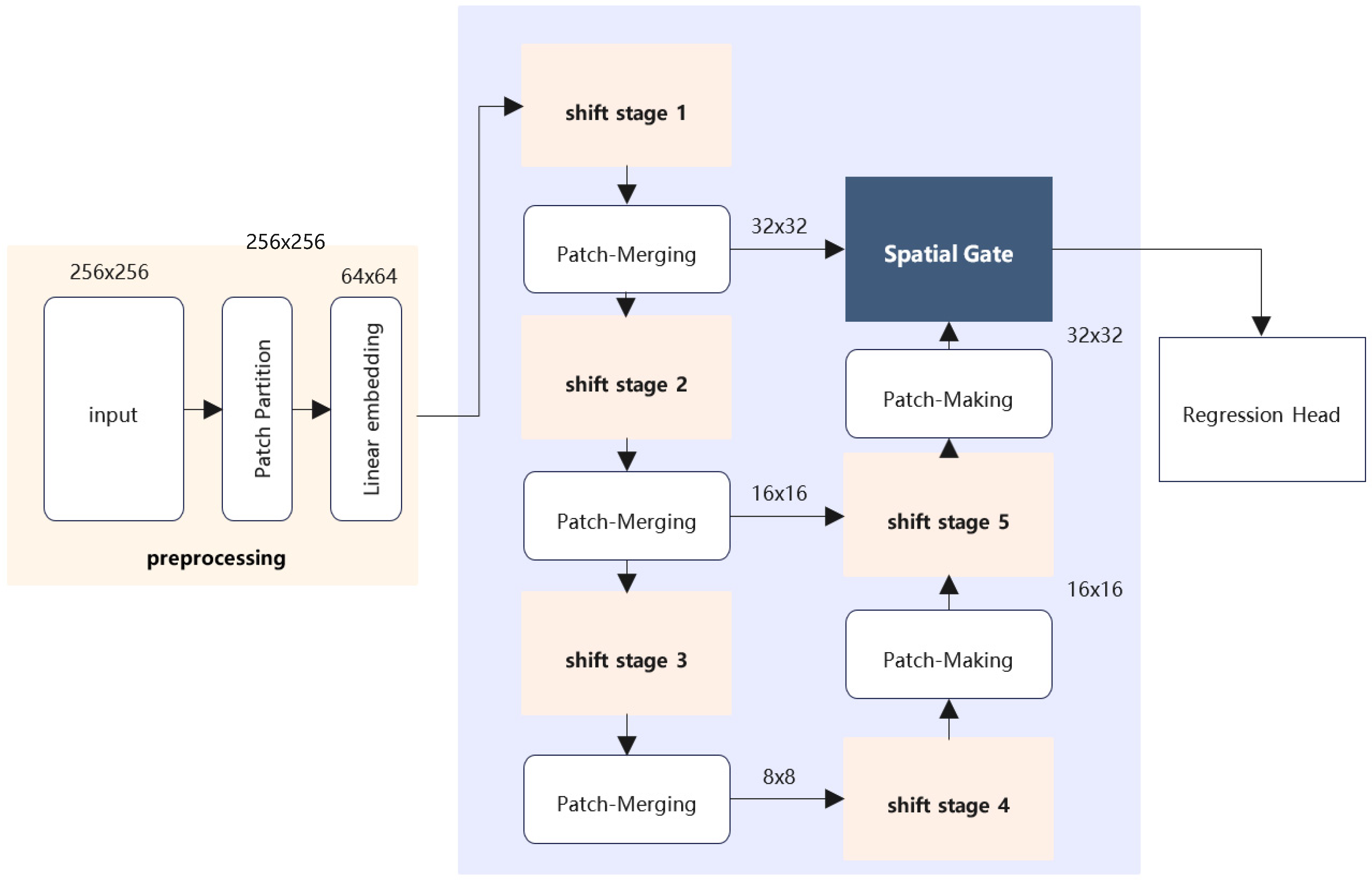
3.1. Overall Architecture
3.2. Bridge–Branch Connection
3.3. Shift Operator
3.4. Patch Merging and Patch Making
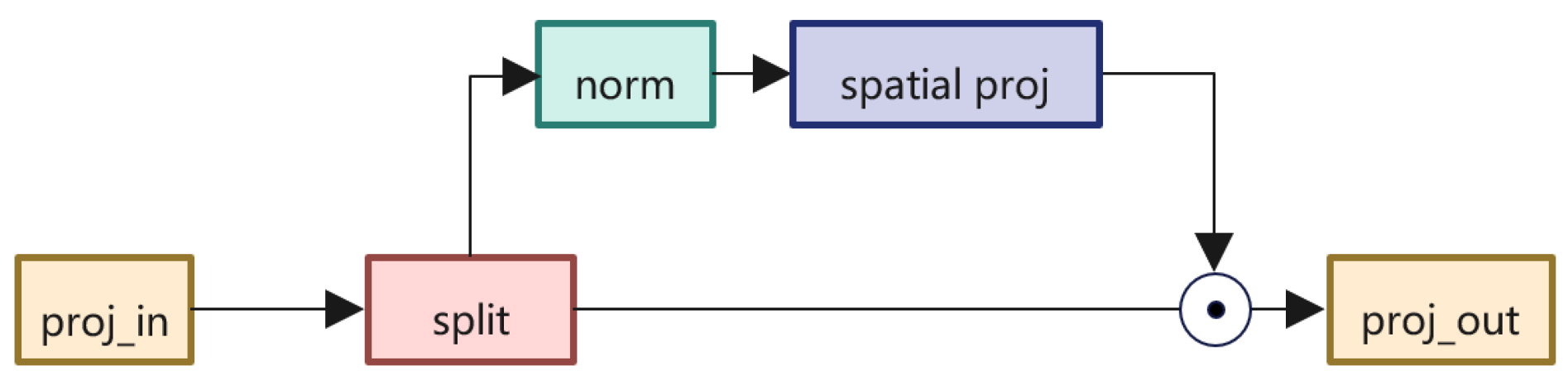
3.5. Spatial Gate
3.6. SimDR
3.7. Residual Log-Likelihood Estimation
4. Experiments
4.1. Details and Environment
4.2. Dataset and Metric
4.3. Results
4.3.1. Result on COCO Dataset
4.3.2. Result in MPII Dataset
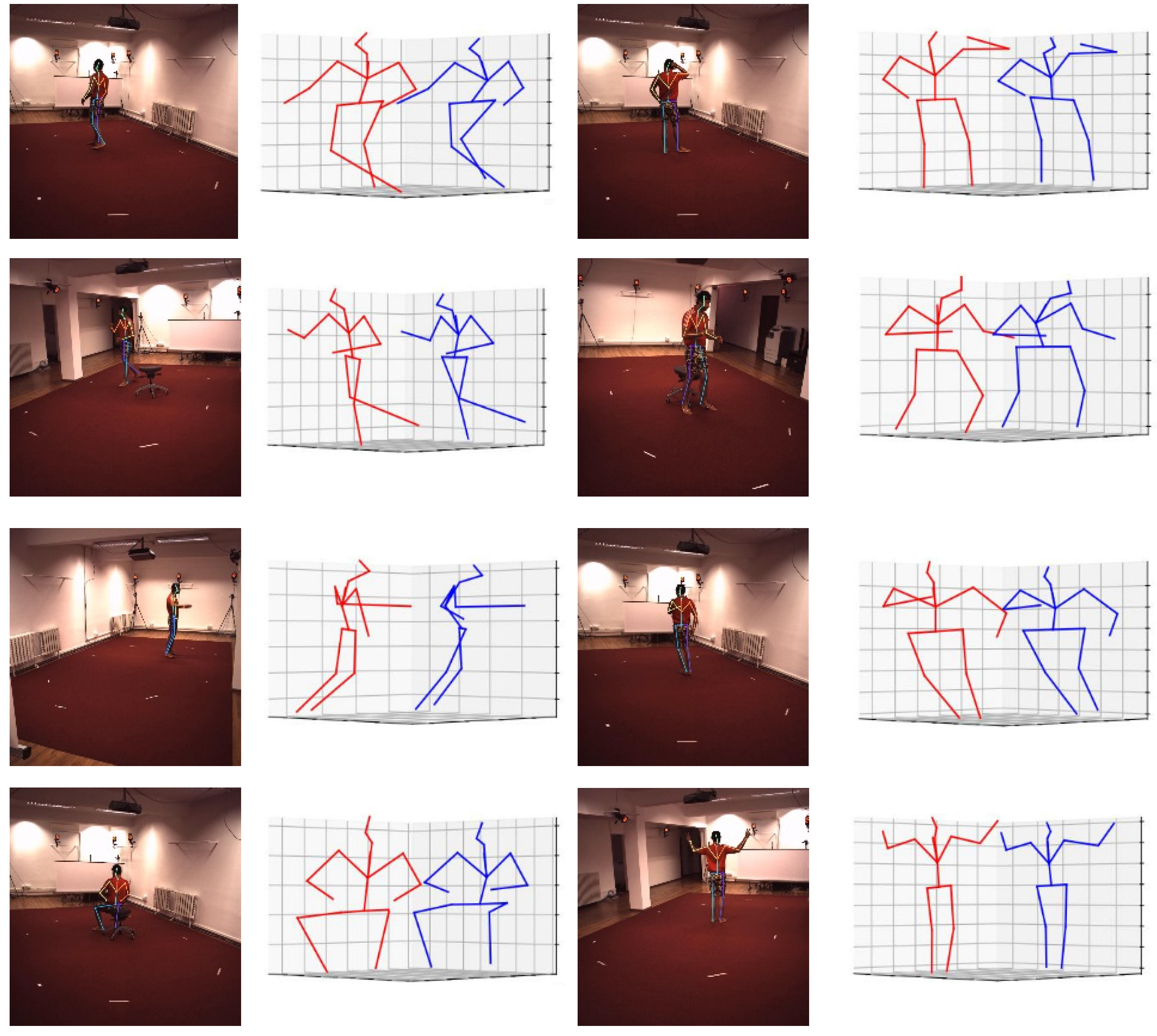
4.3.3. Result on Human3.6M Dataset
- Both our model and ResNet50 obtained a lower error in X and Y than Z.
- Our model performed better than ResNet50 in 2D pose estimation, but the opposite was true in 3D pose estimation.
- The computer resource of ShiftPose-L (dim = 64) has been fully used for 2D pose estimation.
- Limited by the number of parameters, the lightweight model’s capacity for 2D pose estimation began to weaken, while exploiting the depth representation.
- It is better for the lightweight model to predict 3D poses than 2D poses because, generally, the model using 2D poses to predict 3D poses, such as Pose Lift [37], are also lightweight.
4.4. Ablation Study
4.4.1. Plain and Bridge–Branch Structure
4.4.2. Replacement of Shift Block
4.4.3. Improved RLE
5. Discussion
5.1. 3D Pose Estimation
5.2. Stable Training on RLE
5.3. Optimize ShiftPose
5.4. Bottom-Up Method
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jain, A.; Tompson, J.; Andriluka, M.; Taylor, G.W.; Bregler, C. Learning human pose estimation features with convolutional networks. arXiv 2013, arXiv:1312.7302. [Google Scholar]
- Ramakrishna, V.; Munoz, D.; Hebert, M.; Andrew Bagnell, J.; Sheikh, Y. Pose Machines: Articulated Pose Estimation via Inference Machines. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 33–47. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. Human pose estimation via convolutional part heatmap regression. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 717–732. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 4903–4911. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Wei, S.-E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Yang, W.; Li, S.; Ouyang, W.; Li, H.; Wang, X. Learning feature pyramids for human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1281–1290. [Google Scholar]
- Belagiannis, V.; Zisserman, A. Recurrent human pose estimation. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 468–475. [Google Scholar]
- Tompson, J.J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. Adv. Neural Inf. Process. Syst. 2014, 27, 1799–1807. [Google Scholar]
- Luvizon, D.C.; Tabia, H.; Picard, D. Human pose regression by combining indirect part detection and contextual information. Comput. Graph. 2019, 85, 15–22. [Google Scholar] [CrossRef]
- Nibali, A.; He, Z.; Morgan, S.; Prendergast, L. Numerical coordinate regression with convolutional neural networks. arXiv 2018, arXiv:1801.07372. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4733–4742. [Google Scholar]
- Li, S.; Liu, Z.-Q.; Chan, A.B. Heterogeneous multi-task learning for human pose estimation with deep convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 482–489. [Google Scholar]
- Gkioxari, G.; Hariharan, B.; Girshick, R.; Malik, J. R-cnns for pose estimation and action detection. arXiv 2014, arXiv:1406.5212. [Google Scholar]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2d/3d pose estimation and action recognition using multitask deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5137–5146. [Google Scholar]
- Li, J.; Bian, S.; Zeng, A.; Wang, C.; Pang, B.; Liu, W.; Lu, C. Human pose regression with residual log-likelihood estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11 October 2021; pp. 11025–11034. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11 October 2021; pp. 10012–10022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtually Online, 13–15 December 2021; pp. 10347–10357. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. Maxim: Multi-axis mlp for image processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, Louisiana, 19–24 June 2022; pp. 5769–5780. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Liu, H.; Dai, Z.; So, D.; Le, Q.V. Pay attention to mlps. Adv. Neural Inf. Process. Syst. 2021, 34, 9204–9215. [Google Scholar]
- Wang, G.; Zhao, Y.; Tang, C.; Luo, C.; Zeng, W. When shift operation meets vision transformer: An extremely simple alternative to attention mechanism. arXiv 2022, arXiv:2201.10801. [Google Scholar] [CrossRef]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, Louisiana, 19–24 June 2022; pp. 10819–10829. [Google Scholar]
- Wang, Y.; Li, M.; Cai, H.; Chen, W.-M.; Han, S. Lite pose: Efficient architecture design for 2d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, Louisiana, 19–24 June 2022; pp. 1312–13136. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution vision transformer for dense predict. Adv. Neural Inf. Process. Syst. 2021, 34, 7281–7293. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.-T.; Zhou, E. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11 October 2021; pp. 11313–11322. [Google Scholar]
- Gkioxari, G.; Hariharan, B.; Girshick, R.; Malik, J. Using k-poselets for detecting people and localizing their keypoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Ohio, USA, 23–28 June 2014; pp. 3582–3589. [Google Scholar]
- Chen, X.; Yuille, A.L. Articulated pose estimation by a graphical model with image dependent pairwise relations. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Dantone, M.; Gall, J.; Leistner, C.; Van Gool, L. Human pose estimation using body parts dependent joint regressors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3041–3048. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A simple yet effective baseline for 3d human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2640–2649. [Google Scholar]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3d human pose estimation in the wild: A weakly-supervised approach. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 398–407. [Google Scholar]
- Chen, C.-H.; Ramanan, D. 3d human pose estimation = 2d pose estimation + matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7035–7043. [Google Scholar]
- Moreno-Noguer, F. 3d human pose estimation from a single image via distance matrix regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2823–2832. [Google Scholar]
- Wang, M.; Chen, X.; Liu, W.; Qian, C.; Lin, L.; Ma, L. Drpose3d: Depth ranking in 3d human pose estimation. arXiv 2018, arXiv:1805.08973. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; 2021; pp. 13733–13742. [Google Scholar]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-hrnet: A lightweight high-resolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 15–19 June 2021; pp. 10440–10450. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Xiao, B.; Wei, F.; Liang, S.; Wei, Y. Integral human pose regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 529–545. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. Camera distance-aware top-down approach for 3d multi-person pose estimation from a single rgb image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10133–10142. [Google Scholar]
- Li, Y.; Yang, S.; Zhang, S.; Wang, Z.; Yang, W.; Xia, S.-T.; Zhou, E. Is 2d heatmap representation even necessary for human pose estimation? arXiv 2021, arXiv:2107.03332. [Google Scholar]
- Cai, H.; Chen, T.; Zhang, W.; Yu, Y.; Wang, J. Efficient architecture search by network transformation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, Louisiana, 2–7 February 2018. [Google Scholar]
- Fang, H.-S.; Xie, S.; Tai, Y.-W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Input Size | Params | GFLOPs 5 | AP | AP50 | Speed GPU (fps) 4 |
|---|---|---|---|---|---|---|
| Heatmap-based | ||||||
| Simba-Res50 [5] 1 | 256 × 192 | 34M | 8.9 | 70.4 | 88.6 | 48 2 |
| Simba-Res101 [5] | 256 × 192 | 52.6M | 9.3 | 71.4 | 89.3 | - |
| HRNet-w32 [19] | 256 × 192 | 28.5M | 7.1 | 73.4 | 89.5 | 28 2 |
| Lite-HRNet30 [46] | 256 × 192 | 1.8M | 0.31 | 70.4 | 88.0 | 12 2 |
| HRFormer-T [32] | 256 × 192 | 2.5M | 1.3 | 70.9 | 89.0 | - |
| HRFormer-S [32] | 256 × 192 | 7.8M | 2.8 | 74.0 | 90.2 | - |
| Token-Pose-T [33] | 256 × 192 | 5.8M | 1.3 | 65.6 | 86.4 | 42 3 |
| OpenPose [47] | 256 × 256 | 61.8 | 84.9 | |||
| Regression-based | ||||||
| DeepPose [21] | 256 × 256 | 23.6M | 5.4 | 52.6 | 81.6 | 135 3 |
| Res50+RLE [18] | 256 × 256 | 23.6M | 5.4 | 71.3 | 88.9 | 135 3 |
| Res50+SimDR [53] | 256 × 192 | 36.8M | 9.0 | 71.4 | - | 120 3 |
| Res101+SimDR [53] | 256 × 192 | 55.7M | 12.4 | 72.3 | - | - |
| ShifPose-L(ours) | 256 × 192 | 10.2M | 1.6 | 72.1 | 91.5 | 255 3 |
| Model Name | Input Size | Params | GFLOPs | PCKh | PCKh@0.1 | Speed GPU (fps) |
|---|---|---|---|---|---|---|
| DeepPose [21] | 256 × 256 | 23.58M | 4.04 | 82.5 | 17.4 | 135 1 |
| Simba-Res50 [5] | 256 × 256 | 34M | 8.9 | 88.5 | 33.9 | 48 1 |
| Simba-Res101 [5] | 256 × 256 | 56.7 | 10.4 | 89.1 | 34.0 | - |
| HRNet-w32 [19] | 256 × 256 | 28.5M | 17.3 | 92.3 | - | - |
| Lite-HRNet30 [46] | 256 × 256 | 1.8M | 0.43 | 87.0 | - | - |
| TokenPose-L/D6 [33] | 256 × 256 | 21.4M | - | 90.2 | - | - |
| OpenPose [47] | 256 × 256 | - | - | 75.6 | - | 200 |
| ShiftPose-T | 256 × 256 | 2.89M | 0.69 | 75.5 | 17.0 | 945 2 |
| ShiftPose-M | 256 × 256 | 4.16M | 1.00 | 83.7 | 25.0 | 440 2 |
| ShiftPose-L | 256 × 256 | 10.20M | 1.63 | 86.4 | 29.1 | 308 2 |
| Model Name | Input Size | Params | GFLOPs | MPJPE | PA-MPJPE |
|---|---|---|---|---|---|
| ResNet50+RLE [18] | 256 × 256 | 23.8M | 5.40 | 48.6 | 38.5 |
| ShiftPose-L+RLE | 256 × 256 | 10.2M | 1.64 | 73.4 | 53.3 |
| Model Name | PA-MPJPE | MPJPE | Error-X | Error-Y | Error-Z |
|---|---|---|---|---|---|
| ResNet50 [18] | 38.5 | 48.6 | 16.0 | 16.0 | 37.1 |
| ShiftPose-L (dim = 64, patch size = 2) | 42.3 | 52.1 | 17.0 | 17.3 | 42.0 |
| ShiftPose-L (dim = 64, patch size = 4) | 53.3 | 73.4 | 21.5 | 24.4 | 57.7 |
| ShiftPose-L (dim = 128, patch size = 4) | 44.7 | 59.1 | 18.0 | 19.9 | 45.0 |
| Model Name | GFLOPs | PCKh | PCKh@0.1 |
|---|---|---|---|
| Plain | 1.00 | 81.6 | 21.5 |
| Bridge | 1.63 | 86.4 | 29.1 |
| Module | PCKh | PCKh@0.1 |
|---|---|---|
| Without shift | 25.4 | 1.4 |
| With W-MSA | 17.5 | 0.8 |
| With shift | 86.4 | 29.1 |
| Model Name | AP | Speed GPU (fps) |
|---|---|---|
| TokenPose-S + SimDR [53] | 73.6 | 80 |
| Ours | 72.1 | 308 |
| MPJPE | PA-MPJPE | |
|---|---|---|
| 1 | 71.0 | 55.3 |
| 1.5 | 70.2 | 53.9 |
| 2.5 | 66.3 | 51.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Jiang, X.; Dai, Y. Shift Pose: A Lightweight Transformer-like Neural Network for Human Pose Estimation. Sensors 2022, 22, 7264. https://doi.org/10.3390/s22197264
Chen H, Jiang X, Dai Y. Shift Pose: A Lightweight Transformer-like Neural Network for Human Pose Estimation. Sensors. 2022; 22(19):7264. https://doi.org/10.3390/s22197264
Chicago/Turabian StyleChen, Haijian, Xinyun Jiang, and Yonghui Dai. 2022. "Shift Pose: A Lightweight Transformer-like Neural Network for Human Pose Estimation" Sensors 22, no. 19: 7264. https://doi.org/10.3390/s22197264