1. Introduction
Fatigue, weakness, sensory loss, ataxia, and spasticity are among the usual causes of motor impairments due to neurological diseases such as multiple sclerosis (MS) [
1], TBI, spinal cord injury (SCI), and CP, among others. For this reason, physicians often advise people with such impairments to be treated in rehabilitation as a supplement to their background pharmacologic treatment. Spasticity is a motor disorder characterized by a velocity-dependent increase in tonic stretch reflexes (muscle tone) with exaggerated tendon jerks resulting from the hyper-excitability of the stretch reflexes as one component of upper motor neuron syndrome [
2]. Intramuscular injection of BTX-A is a standard treatment for spasticity. It has been shown that BTX-A produces improvements in lower and upper limb function [
3], thereby improving movement such as walking [
4] (see
Figure 1) or fine motor skills. The minimum and maximum dose of BTX-A may vary depending on the muscle that is considered [
5]. Furthermore, the total dose of BTX-A (sum of doses for all treated muscles) should not exceed the recommended amount according to the patient and the considered muscles (i.e., upper limbs and lower limbs).
BTX-A is a relatively expensive pharmaceutical product, and its consumption has increased in recent years [
6,
7]. Although its effect on muscle function is considered reversible, BTX-A treatment presents risks (i.e., undesirable effects), and injection sessions should be spaced by at least 3 months apart. For all these reasons, optimizing BTX-A treatment by choosing the right muscles to be treated and the dose distribution is a complex task of great relevance and requires careful study of the patient’s condition.
In practice, decision-making is based on a patient’s medical history, physical examination, and clinical movement analysis (CMA). CMA consists of studying movement troubles and identifying their plausible causes, based on bio-mechanical interpretation of instrumental measures [
8] (
Figure 2). If certain quality criteria are fulfilled, CMA data are sufficiently reliable for clinical interpretation [
9]. CMA techniques can be used to analyze lower limb movement (e.g., walking, climbing stairs, running, etc.) or fine motor skills. Numerous scientific studies have shown that CMA, especially clinical gait analysis (CGA), provides considerable aid in the assessment and treatment decision for various neurological diseases such as CP [
10], post-stroke hemiparesis [
4], and MS [
11], among others. Camardella et al. [
12] support the idea of using Machine Learning to also predict clinical scores after robot-assisted rehabilitation as a decision-support tool for clinicians.
Artificial intelligence (AI) and machine learning (ML) techniques have become almost ubiquitous in our daily lives by guiding our decisions and providing recommendations. Therefore, it is not surprising that ML approaches are becoming increasingly popular in precision medicine and fulfill an increasing demand for new healthcare solutions, in particular a better understanding of pathological processes. Among AI and ML methods, the deep neural network (DNN) [
13] has already shown spectacular results in aiding clinical decision-making [
14]. The DNN requires a significant amount of data to be properly trained. However, available experimental databases are often limited in size, which makes them impractical to construct DNNs for prediction models. Medical data are often heterogeneous, complex, incomplete, uncertain, multi-modal, and multilevel, drastically decreasing the amount of exploitable data and questioning the development of prediction models [
15]. Machine learning (ML) models must be able to manage data of a different nature describing the patient (images, time series, discrete clinical data, etc.) and link them to data from treatment in nominal, categorical (type of treatment) [
16], and/or discrete (doses) forms. This requires that the model be taught a regression task between the data after and before BTX-A treatment. Since these treatments are often a combination of several factors (e.g., several drug injections), it is necessary to be able to model their interactions. Therefore, we propose a strategy to create multi-task DNN. Indeed, MTL can cope with sparse data problems and build a more robust model by sharing knowledge among different tasks [
17]. MTL has been widely applied in ML and in the biomedical field to address the diversity of the data [
17]. In the CGA literature, several works exploited deep learning (DL) for predicting gait trajectories, most of them on healthy gait. Su et al. [
18] predicted gait trajectories and the five gait phases (loading response, mid-stance, terminal stance, pre-swing, and swing) with a long short-term memory (LSTM) to help in the design of exoskeletons. They employed either 10 or 30 time steps as the input for predicting the next five or ten steps. Twelve people were enrolled in their experiment, and the data were collected using attached inertial measurement units (IMUs) on their body parts. Zhu et al. [
19] used an attention-based convolutional neural network (CNN)-LSTM to forecast the joint trajectories of the knee and ankle, based on lower and upper limb data, for the next 60 milliseconds. Zaroug et al. [
20] constructed an LSTM auto-encoder to forecast linear acceleration and angular velocity trajectories. To predict five or ten steps into the future, they considered several lengths of input time steps (five to 40 steps) of kinematic data of six male participants. Hernandez et al. [
21] proposed a hybrid network combining an LSTM with a CNN (DeepConvLSTM) to estimate kinematic trajectories, reaching an average mean absolute error (MAE) of 3.6°. Jia et al. [
22] constructed a DNN for trajectory prediction using LSTM units and a feature fusion layer. This layer uses EMG and joint angle data. Liu et al. [
23] built a deep spatio-temporal model composed of LSTM units to forecast two-time steps into the future, using the kinematic data of 35 subjects. More recently, Kolaghassi et al. [
24] worked on the pathological gait trajectories of children with neurological disorders. They used two deep learning models, an LSTM and a CNN, to forecast hip, knee, and ankle trajectories. Note that all these studies tackled the prediction of the same gait cycle. The issue we face in this study is much more complex since it is centered on the impact of several treatments (BTX-A) on gait trajectories.
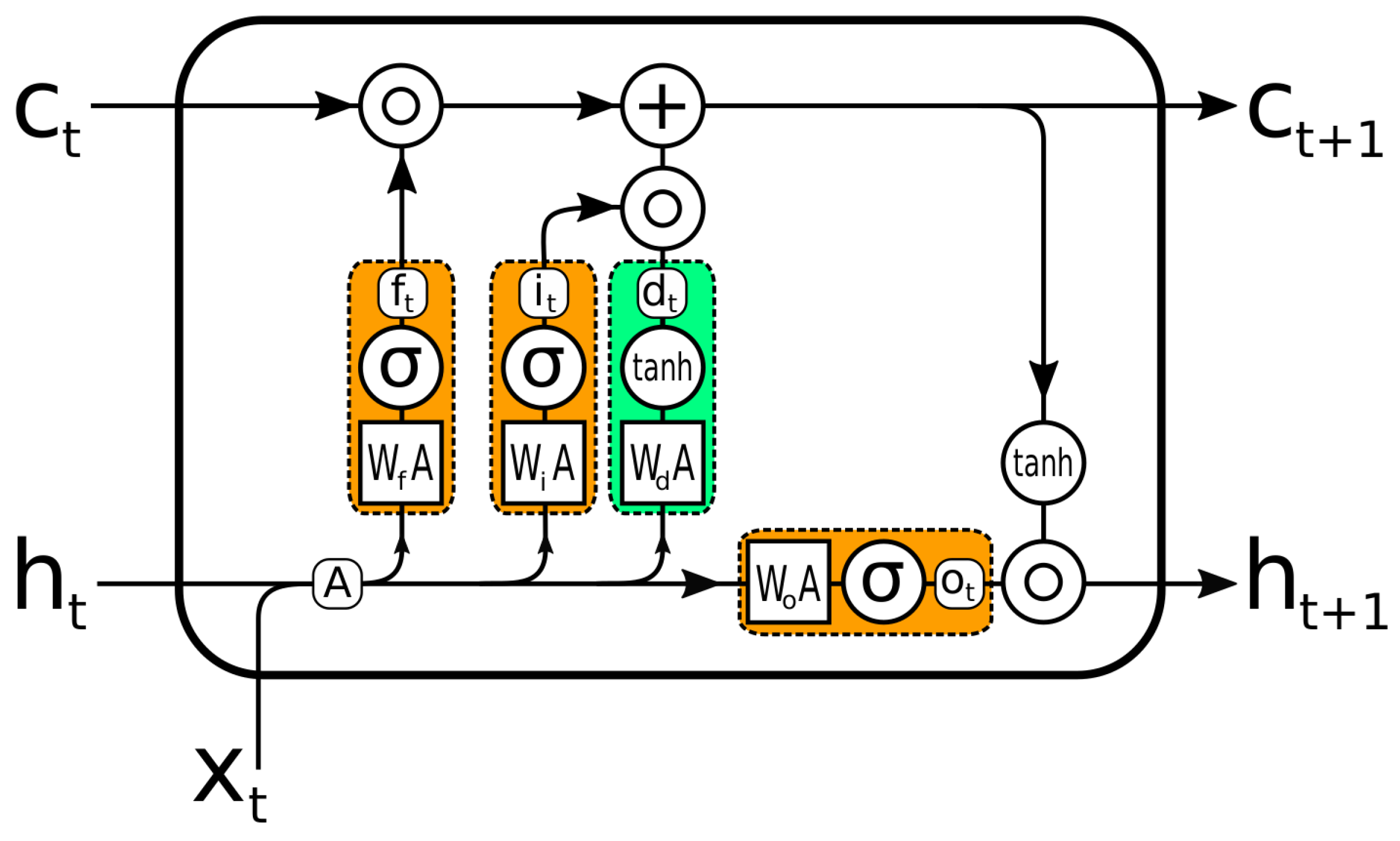
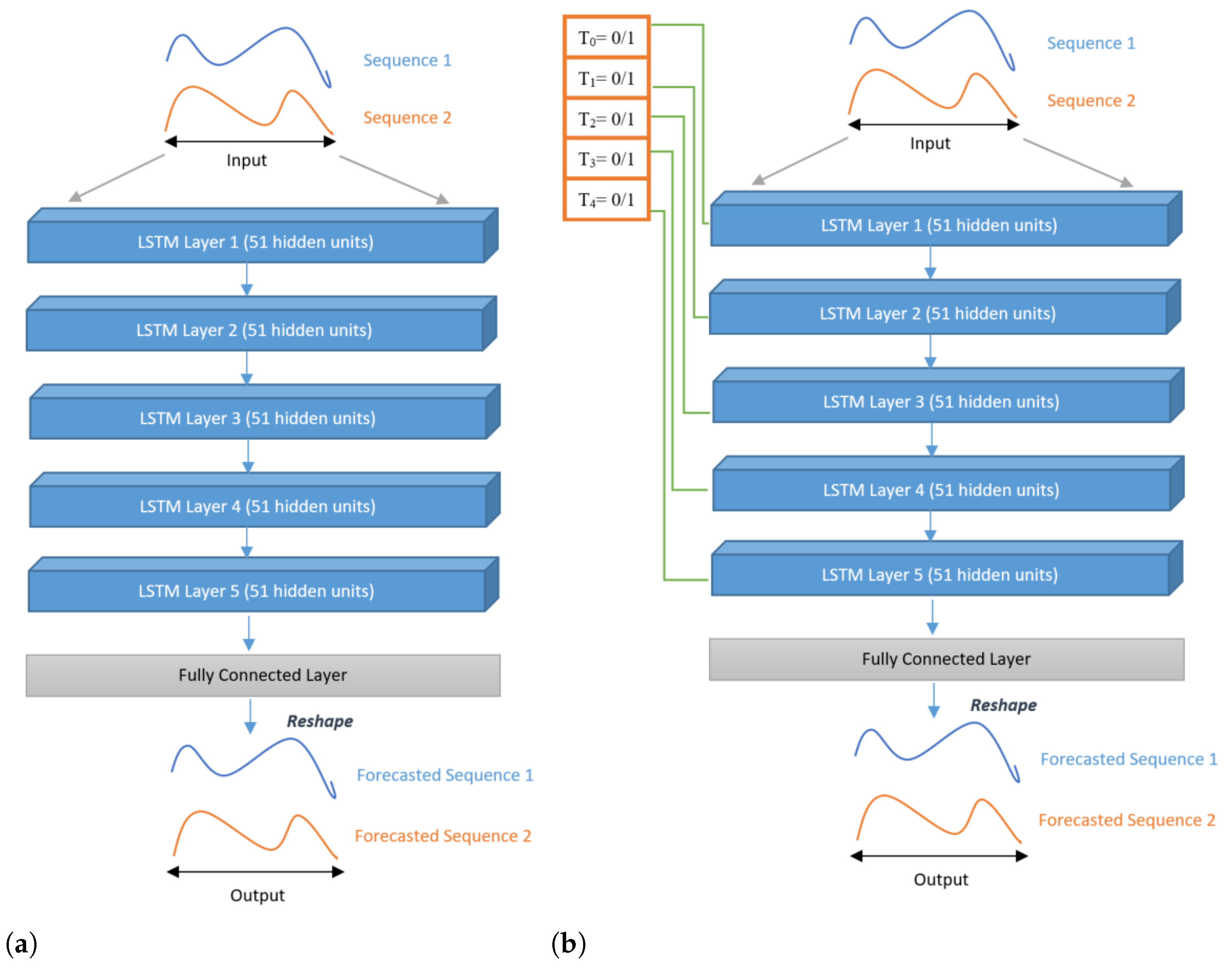
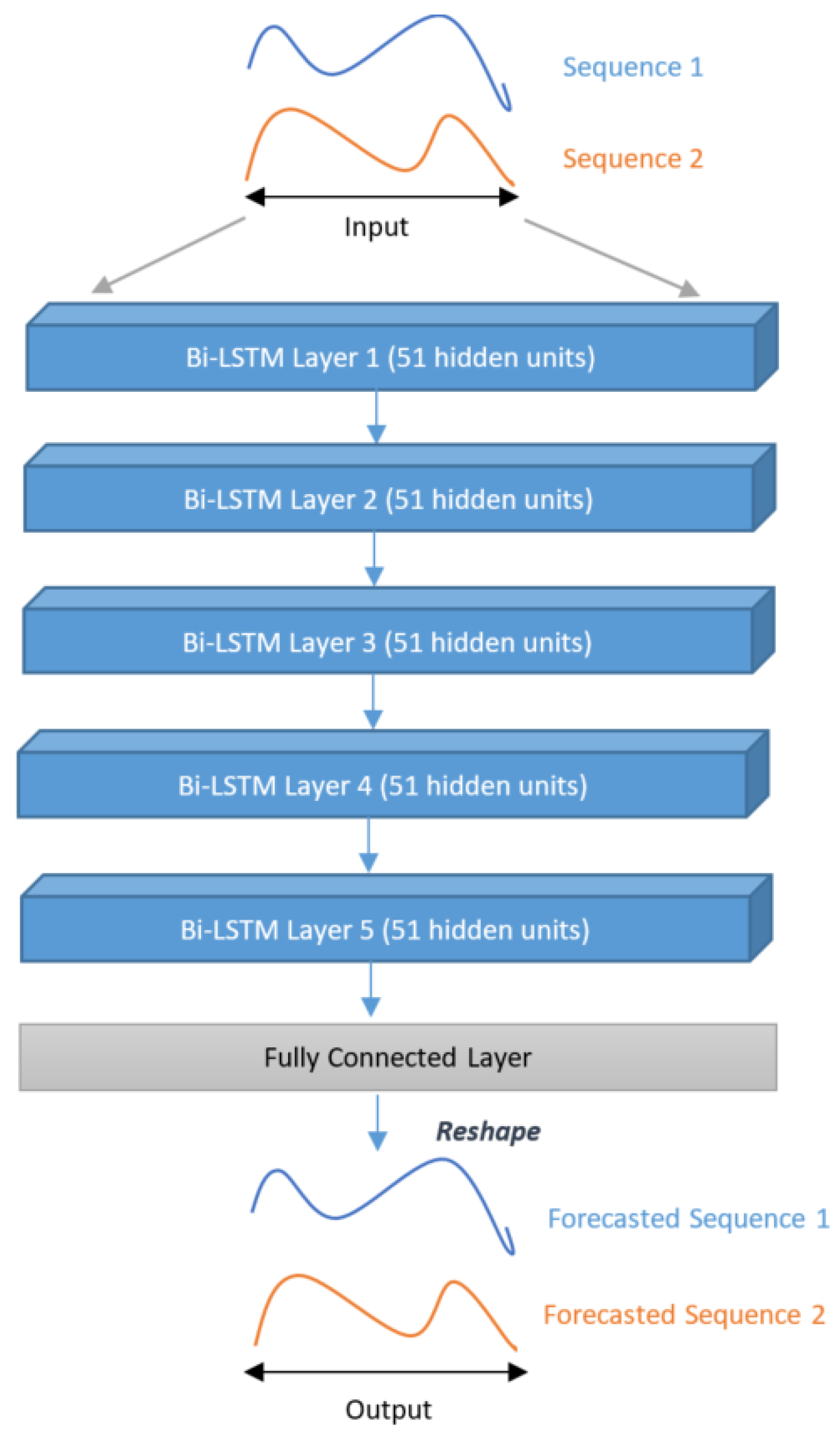
Our contribution consists of proposing a new solution to predict the BTX-A post-treatment gait trajectory of the patient, and possibly the interaction between different treatments. This solution is an MTL architecture, which alleviates the drawbacks previously mentioned: dataset size (number of patients), sample size (number of features), and feature diversity. To the best of our knowledge, this is the first time that MTL has been used for post-treatment gait trajectory prediction. This architecture comprises a collection of LSTM-shaped sub-models, arranged in parallel or series. Each sub-model is used for one treatment, and each treatment corresponds to an injected muscle. These muscles are attached to the left and right knees and ankles. This MTL model learns to map pre-treatment gait sequences to post-treatment sequences. A gating mechanism is proposed with different architectures to control the treatments’ influence on the final prediction.
Section 2 presents the data collection and their characteristics.
Section 2.3 describes, more specifically, the different deep architectures used. The most prominent results are presented in
Section 3. The paper ends with a conclusion and a short discussion.
3. Results
We evaluated Models 1 to 7 on our dataset with the above-mentioned metrics and display the results in
Table 4. The lowest average RMSE values and the highest
scores are displayed in bold; they correspond to the best prediction model according to the diseases reported in
Table 4.
From
Table 4, we noticed that Model 4 outperformed other models in the prediction of post-treatment gait trajectories for patients having MS and TBI. Furthermore, Model 6 performed better for SCI patients than all other architectures. Model 7 outperformed other models of patients having stroke and CP. We noticed that, in all cases, the MTL architectures achieved better performance globally, on both knee and ankle signals.
The following two tables (
Table 5 and
Table 6) report the performance scores of the prediction of gait trajectories for knee and ankle, respectively. In
Table 5, the best prediction for the knee angle was obtained for TBI patients by Model 5 with an average RMSE of 5.60° and
. Furthermore, for all diseases, the MTL architectures outperformed the others. Model 6 gave the best prediction for MS and SCI in terms of RMSE and Model 4 in terms of the
score for the same pathologies. On the other hand, for stroke patients, Model 7 had the best average RMSE, and Model 6 had the best coefficient of determination. In
Table 6, we notice that the best RMSE for the ankle was 3.77°, which is lower than that obtained for the knee (5.60°). However, even though the RMSE was usually lower (thus better) for the ankle, the
scores were usually lower (thus worse) as well. In particular, for stroke, all the
of the ankle angle were negative.
From a different perspective, the following graphs (in
Figure 8 and
Figure 9) illustrate the trajectories (pre-treatment, real post-treatment, predicted post-treatment of the patient, and standard course of an adult) of two patients. The Y-axis represents the ankle dorsiflexion or knee flexion, and the X-axis represents the gait cycle of a patient.
Figure 8 compares the prediction of different models on the knee and ankle joints in a patient diagnosed with CP. These figures differentiate the prediction between the MTL models and others.
Figure 8a–c illustrate the predictions on the knee angles made by Model 1, Model 2, and Model 3, which are not MTL models.
Figure 8d shows the corresponding prediction of Model 7, which is an MTL model. The predictions of post-treatment gait from Model 7 were better than others. In other words, it was closer than that patient’s expected post-treatment gait trajectory (average of all his/her target gait cycles in the training set). On the other hand,
Figure 8e–h compare the prediction of the ankle joint of the same patient.
Figure 8g,h illustrate the prediction of Model 1 and Model 3, respectively.
Figure 8g,h show the predictions of Model 4 and Model 7, respectively, which are MTL models. We noticed that the predicted post-treatment trajectory in
Figure 8g was better than the first two models, which were serial, and we see in
Figure 8h the significant improvement of the prediction at the end of the gait cycle, between 80% and 100%, compared to
Figure 8g. On this patient, the MTL models also performed better on the ankle joint.
Figure 9 compares the trajectories of the knee and ankle joints of another patient diagnosed with MS.
Figure 9a,b, represent the predictions of the knee angles made by Model 1 and Model 2, which are not MTL models.
Figure 9c,d represent the prediction of the knee angles made by Model 4 and Model 6, respectively, which are MTL models. We can see that MTL models had better predictions than the first two. The predicted post-treatment trajectories were closer to the real post-treatment trajectories. Last four
Figure 9e–h compare the trajectories of the ankle joint.
Figure 9e–g represent the prediction of Model 1, Model 2, and Model 3. Although Model 3 is not an MTL model, its predictions were much better than the first two serial models. However, the prediction of the MTL model (Model 5) in
Figure 9h was better than all other models for this particular patient. In general, as proven by
Table 4,
Table 5 and
Table 6, for almost every patient, MTL performed better.
4. Discussion and Conclusions
In this study, we used MTL to design an LSTM model and its variants to predict the post-treatment trajectory of adults with an abnormal gait. To the best of our knowledge, this specific prediction task, which exhibits greater inter- and intra-subject variability compared to the courses of normal adults, has not been addressed before in the literature using MTL.
To forecast the trajectories of the knee and the ankle in the sagittal plane, we used LSTM-based models. LSTM was chosen because it has been successfully applied to sequential data, and it can capture long-term dependencies through its learning [
32]. To better evaluate the performance of MTL on a given problem, we also implemented serial models using LSTM. The RMSE was used to compare the results of both sorts of models. The RMSE of the MTL models was lower for all types of patients (different pathologies). The MTL models also gave the highest
, better explaining the total variance of the target than the serial models. The MTL models performed better than the serial models in our problem of multiple treatment combinations. MTL architectures allow introducing the medical treatment metadata into the model. Instead of performing a simple post–pre regression task, our results imply that introducing the treatment information (i.e., muscles treated by BTX-A) improves performance.
Overall, the best prediction was obtained for TBI using the Bi-LSTM with MTL (Models 4) architecture. The results in
Table 4 show that there was only a 5.24° average difference in actual and predicted trajectories and
. The best maximum average RMSE error between actual and predicted trajectories was 6.24° for stroke patients, using the MTL architecture with gated Bi-LSTM and a convolutional layer (Model 7). For the knee and ankle, the best results were 6.75° (
) and 3.77° (
), respectively, for CP patients. The RMSE was usually higher for the knee than for the ankle despite having higher coefficients of determination. This suggests that the models were able to explain the variance of the knee angle better, but the amplitudes in the knee were higher than in the ankle. Moreover, no proposed model was able to adequately explain the variance of the ankle angle for patients with a stroke (only negative
scores).
4.1. Comparison to Previous Works
Since this is the first time that the whole kinematic signals for knee and ankle on the sagittal plane were predicted for botulinum toxin treatment, it is difficult to compare our performance to other works. Nevertheless, we can compare our methods for the predictions of peak knee and ankle on sagittal planes reported by [
4] for rectus femoris botulinum toxin injection of patients with stroke (
Table 7). In this case, the
score of the proposed method for stroke was better for peak knee flexion, but worse for peak ankle dorsiflexion. Since the compared models were not trained and tested with the same databases, this comparison must be taken with caution.
We also compared our performances to the predictions of the whole postoperative kinematic curves for patients with CP. Even though the proposed methods were not tested on the same databases, these performances were better than the postoperative predictions for CP reported by Galarraga et al. [
16], Niiler et al. [
33], and Niiler [
34], as shown in
Table 7.
4.2. Limitations
Besides the lack of external validation, the main limitation of the proposed models is the relatively small size of the database. DL models usually need large amounts of data to be properly trained. Unfortunately, this is rarely the case in biomedical databases. Another limitation of the model is that it does not consider other aspects of the patient, such as psychological factors, age, stress, and social environment, among others, which play a major role in the rehabilitation and, thus, in the treatment outcome.
4.3. Conclusions
It was concluded from the results that the number of patients and type of disease did not directly affect the model’s performance. More precisely, we can say that inter- and intra-subject variability affected the model’s performance more than the number of patients (samples) and type of disease.
Table 1 gives a detailed description of the number of patients with each disease, and
Table 4,
Table 5 and
Table 6 report the number of training samples. The minimum number of patients was 3 with CP and TBI diseases, while the maximum number of patients was 12 with MS disease. We noticed that the RMSE of CP patients and TBI patients were 6.00° and 5.24°, respectively. On the other hand, the RMSE of MS patients was 5.8°. This showed that having four-times more patients for a given disease than others did not significantly affect the RMSE value.
Finally, Bi-LSTM combined with MTL was highly effective at increasing the total quantity of information accessible to the model, enhancing the context provided to the algorithm. Future work will focus on MTL models with Bi-LSTM networks to exploit more precise information about treatments, such as the dose information, to further enhance the context given to the model.





 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}